
基于决策树特征选择的电子档案资源数字化共享方法*
2022-11-28 09:28张丹,刘欢
自动化技术与应用 2022年10期
张 丹,刘 欢
(1.中国南方电网有限责任公司,广东 广州 510000;2.南方电网数字电网研究院有限公司,广东 广州 510000)
1 引言
电子档案在数据传递的过程易出现泄露、被窃取等问题,数据的隐私安全亟待解决[1]。但是,电子档案资源属于海量数据信息,其分类处理难度较大,电子档案数据的共享安全问题也成为了当下的难点。本文就电子档案资源的数字化共享进行了相应的探究,设计提高数据传输过程中的隐私防护能力。
文献[2]基于Spark MLlib中决策树算法设计了电子档案数据隐私的保护,通过云计算提升了数据挖掘的性能,并对适用于传输方与接收方的设备进行了切分与标注,使同态加密算法与电子档案相结合。然而这种数据共享方法由于过度降低数据的噪声,会给数据的可用性带来不可预估的影响。文献[3]通过一种基于标签相关度的Relief 特征选择算法进行了一个边缘智能计算的共享优化,分析无线网络中的电子资源共享壁垒,实现了网络资源的集中分配,提高了传输与共享的效率与安全性。但是这种方法依赖于服务器的性能,在应用性较差的服务器中无法得到更好的效果。文献[4]基于区块链技术设计了接收方与传输方的权限,并利用协议使得这种共享渠道能够被控制。这种方法虽然提高了电子档案的安全,保护了数据的隐私,但是却需要在系统建立过程中增添不必要的消费,不适合大多数的电子档案保存机构。为了得到廉价、高性能、效率更高的电子档案资源数字化共享方法,本文基于决策树特征选择对以上文献中的算法进行了优化,提出了以下方法。
2 电子档案资源数字化共享方法
2.1 公共信息安全密钥转换
为保证电子档案在共享过程中的安全与隐私,需要在传输之前将其加密,建立公共信息的安全密钥。首先设定一个安全的信息参数ha,将该参数与大素数ka相结合,并共同建立二者共同的属性集合[5]。
式(1)中,Ut表示安全参数与大素数相结合后产生的属性集合循环映射总结构;xta1表示被选中属性单元的前一个单元;xta2表示属性集合中被选中的属性单元;xta3表示被选中属性单元的后一个单元[6]。此时就形成了集合中的属性群组,此时的全局安全公钥也应被设定在属性群组中,以便数据中转的云中心对任意一个公钥进行加密[7]。此时安全公钥的输出结构为:
式(2)中,Gxag可以表示任意一个安全公钥中的属性单元;G1ag表示安全公钥中的第一个属性单元,同理Gnag表示安全公钥中的最后一个属性单元。每一个安全公钥可以生成自身的安全私钥,由算法进行用户身份的判定,并提供一个随机数,作为私钥的生成属性,其结构为:
式(3)中,Gxag表示安全公钥中的任意一个输出单元;δi表示在进行身份判定时需要由用户提供验证码的随机数;表示得到的私钥结构[8]。得到的私钥可以当作一种被隐秘执行数据传输行为的密文,在公钥Gxag的访问中以明文生成随机向量,并在转换成密文后计算线性密文的结构:
2.2 电子档案决策树分类编码提取
为了保证电子档案信息的安全,使用上文中的方法将所有信息全部转换成密文形式,此时想要及时准确地将需要的数据传输给接收方,就需要构建一个电子档案的分类标准,对其进行区域划分。首先构建一个以电子档案为中心的决策树,这个决策树需要将所有被收集的样本完全举例,然后计算其中重叠的部分,并通过数学方法判断决策分类的误差。假设样本集合的个数为xi,训练样本为xi={x1,x2,…,xn},其中xi表示n个训练样本中的任意一个数值[10]。在样本中有特征值为ζi,每一个样本都有一个特征值,则特征值的集合可以表示为ζi={ζ1,ζ2,…,ζn},ζi表示特征值中的任意一个样本特征。在档案资源的特征分类中,通常有三种类别,可以通过决策树建立如图1所示的分类依据。
在每一个信息增益的节点,都会有一个特征对其进行总结,此时的电子档案样本分类期望为:
式(5)中,Esn表示电子档案资源数字化的决策树自动分类期望;Pi表示任意样本被分类为类别i 的概率[11-12]。当子集的离散值为Sx时,其在值域Y中划分的熵值可以表示为:
式(6)中,Exf表示当子集的离散值为Sx时,值域Y划分的熵值;x1f表示第一个子集样本的离散分值,同理xnf表示第n个子集样本的离散分值;xn表示子集样本的个数。此时的特征分类中,电子档案信息A的信息增益可以表示为:
式(7)中,TA表示电子档案A 的划分类别,Esn表示决策树分类的第一个属性编码;Exf表示决策树分类的第二个属性编码[13-14]。综合以上两个属性编码,就能够得到该电子档案在决策树中的具体分类位置。
2.3 公共密钥解密参数计算
在得到了上文设计的电子档案决策树分类编码之后,就可以将中央处理器云端中的数据传递到接收设备中,此时需要进行公共密钥的解码工作。想要解码,就要根据上文中公共密钥的加密操作计算相应的解码参数。假设发送方受到的随机数为xi,其发送方的身份ID为Ix,接收方的身份ID为Iy,则可以得到解码工作的收获因子为:
式(10)中,Txu表示接收方Iy在解密私钥构件时得到的明文数据;b2xj表示该私钥构件在决策树分类编码中的具体位置;U-μ表示权值属性。如果Txu能够被成功解译,则表明以上步骤共享成功;若Txu不能被成功解译,则表明共享失败。
3 实验研究
3.1 实验准备
在得到上文中设计的电子档案数字化共享方法之后,还需要进行测试与检验,以便观察该共享方法的性能。在此过程中,将该共享方法与常规的三种方法相对比。将计算机设备分为用户终端与数据云端,其中用户终端用于接收电子档案共享信息,数据云端用于提供共享资源[17]。由一台服务器作为电子档案资源的发送方,经过数据加密后,转移至中央处理器的云平台,该平台是所有电子档案的共享中心。电子档案的接收方通过这个共享中心接收数据,经过数据解密处理后,收到相关档案信息。如果电子档案没有通过中央处理器接收数据,而是直接由数据发送方转移至数据接收方,就很容易被另外的恶意对象入侵,并窃取数据信息。本次实验主要对四种数据共享方法的隐私保护能力进行测试,通过档案信息转移的敏感度计算算法的效能。
式(11)中,ηb表示算法对数据共享的保护能力量化结果,通常以百分数的形式表示;Bn表示档案信息的敏感类别阈值;ai表示第i个经过转移的电子档案的频数效率;bi表示完成电子档案转移的第i 个频数估计效率。在这个百分比的计算中,ηb的值越大,其结果越差,ηb的值越小,则表明分布估计越贴近理想数据,其结果越好。本文综合以上计算,对四种数据共享方法进行测试。
3.2 档案隐私保护性能测试
为了检测不同数据量电子档案的数据转移敏感度,构建三个数据库,其中数据库A的电子档案数据量为10MB,数据库B 的电子档案数据量为100MB,数据库C 的电子档案数据量为1 000MB。下文的实验测试结果,主要是对数据共享过程中四种方法保护档案内容能力的概述,将文中设计的方法作为实验组,将常规的三种档案共享方法作为对照组分别为文献[2]提出的基于Spark MLlib的电子档案资源共享方法、文献[3]提出的基于标签相关度的电子档案资源共享方法以及文献[4]提出的基于区块链技术的电子档案资源共享方法,得到实验结果如图2所示。
在图2中,被圆形覆盖的曲线表示电子档案数据量为10MB时的数据转移敏感度,被叉号覆盖的曲线表示电子档案数据量为100MB 时的数据转移敏感度,被三角形覆盖的曲线表示电子档案数据量为1 000MB时的数据转移敏感度。根据四幅图像可知,随着档案传输总量的增加,各曲线都在呈不同程度的上升趋势,且数据量越大,数据转移敏感度越高。其中实验组在整个档案传输总量由0~100%的过程中,数据转移敏感度最低。为了得到更准确的数据,重复进行上述实验操作,反复10次,得到如表1所示的实验结果,再通过计算平均值的方式使实验结果排除偶然数据的干扰。
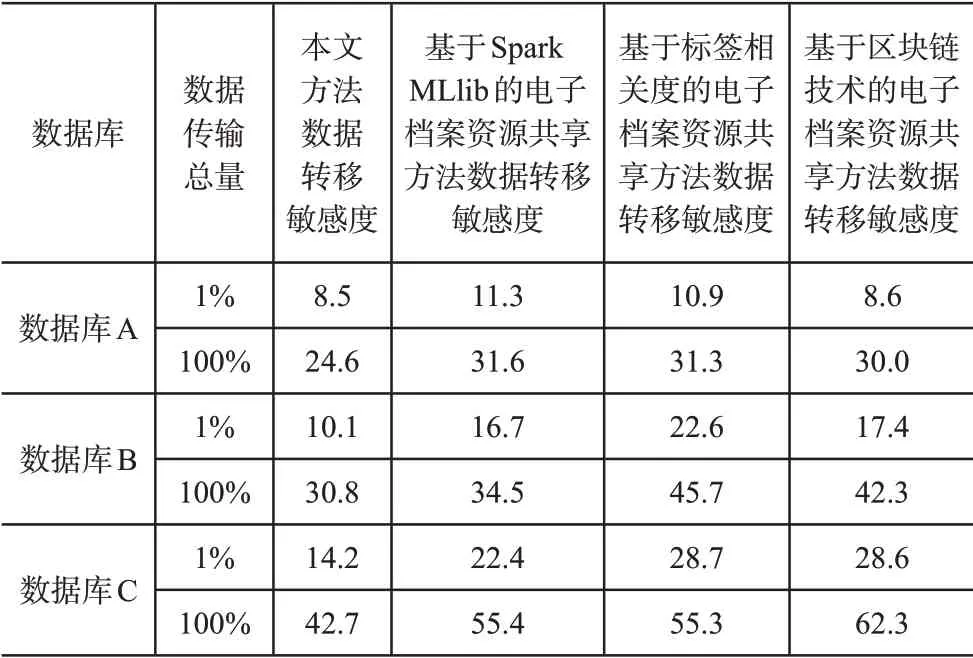
表1 数据结果
如表1所示,实验组在共享10MB、100MB、1 000MB数据档案的过程中,其数据转移敏感度平均值分别为16.55、20.45、28.45。对照组1在共享三类不同数据量的电子档案过程中,其数据转移敏感度平均值分别为21.45、25.6、38.9。对照组2在共享三类不同数据量的电子档案过程中,其数据转移敏感度平均值分别为21.1、34.15、42。对照组3在共享三类不同数据量的电子档案过程中,其数据转移敏感度平均值分别为19.3、29.85、45.45。在四种算法中,只有实验组的数据转移敏感度最低,因此可知:实验组中基于决策树自动特征选择的电子档案资源数字化共享方法拥有更好的数据隐私保护能力,在数据转移过程中,不易被窃取档案信息。而对照组的三种方法在此方面的性能均低于本文中设计的共享方法。
4 结束语
为使得电子档案的资源能够在被严格保密的同时加强流通性,需要设计更具应用价值的数据共享方法,使数据在被第三方云平台传递时能够不被恶意程序盗用。本文围绕决策树特征选择进行了密钥的分类标准,并将其应用在档案的传输中,加强了电子档案的保密效果,提高了数据共享的安全性。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
科学与信息化(2019年28期)2019-10-21
知识就是力量(2018年10期)2018-10-18
中国新通信(2017年18期)2017-10-22
成长·读写月刊(2017年4期)2017-05-16
科学与财富(2016年32期)2017-03-04
科技与创新(2014年11期)2014-08-21
决策与信息·下旬刊(2013年1期)2013-03-11
商场现代化(2009年16期)2009-06-22
