
深度学习在水下成像技术中的应用(特邀)
2022-11-26 03:41谢俊邸江磊秦玉文
光子学报 2022年11期
谢俊,邸江磊,秦玉文
(广东工业大学信息工程学院,先进光子技术研究院,广东省信息光子技术重点实验室,广州 510006)
0 引言
党的十九大报告中指出“坚持陆海统筹,加快建设海洋强国”。壮大海洋经济、加强海洋资源环境保护、维护海洋权益事关国家安全和长远发展。建设海洋强国,不断提升我国开发海洋、利用海洋、保护海洋、管控海洋的综合实力,是全面建设社会主义现代化强国的重要组成部分[1]。水下成像技术是海洋光学和水下光学学科的重要研究方向之一,是我们认识海洋、开发利用海洋和保护海洋的重要手段。水下光学成像技术因其能够直观有效探测水下环境的优势,奠定了其在水下地貌成像、海洋资源勘探、生物群种监测、水下目标探测、水下考古发掘等领域的关键地位。由于复杂的水下环境及水体特殊的物理化学特性导致利用传统光学成像方法在水下所成图像存在各种退化问题,如水体对光的散射和吸收效应导致水下图像模糊、颜色失真、对比度低、光照不足等,水中悬浮颗粒物或气泡造成的“海洋雪”效应导致图像出现亮点或虚假特征等[2]。
针对上述问题,水下成像技术中发展了包括水下图像增强技术、水下图像复原技术、水下偏振成像技术、水下关联成像技术、水下光谱成像技术、水下压缩感知成像技术、水下激光成像技术及水下全息成像技术等等一系列研究手段,以提升水下成像质量,尽可能多地获取更多水下信息。水下图像增强技术可对水下退化图像进行颜色校正、增加对比度;水下图像复原技术基于物理模型对水下图像进行恢复,可获得更加真实的恢复结果;水下偏振成像技术利用物体和背景的不同偏振特性来滤除背景散射噪声;水下关联成像根据探测光路与参考光路的差异重建水下图像,去除环境影响;水下光谱成像技术利用光谱信息进行目标的识别和区分;水下压缩感知技术利用单像素成像灵敏度高、成像对采样值不敏感的特点,获得远距离、低噪声的水下图像;水下激光成像技术利用激光的单色性及穿透性来滤除背景光噪声及进行远距离成像;水下全息成像技术通过数字全息技术获取水下微生物的折射率、位置信息等。上述方法能在一定程度上解决传统水下光学成像的问题,但在多种退化因素共存的环境下,某种方法通常只能解决水下图像某方面的退化问题,成像效果依然有限。此外,上述方法也各有不足,如水下图像增强容易导致图像过饱和,水下图像复原的物理模型依赖经验选取,水下光谱成像技术数据量过大、处理费时等,上述传统水下成像方法的进一步优化发展较为困难。
得益于计算机硬件技术的快速发展,深度学习近年来发展迅猛。作为基于数据驱动的方法,神经网络具有非常出色的图像特征提取能力、非线性拟合能力及泛化能力,在图像分类、目标识别、图像超分辨率等领域中取得巨大成功。这一方法被引入水下成像领域,与传统水下成像技术相结合,在水下图像去模糊、去雾、去噪等任务中表现出色。本文阐述了传统水下成像技术原理及发展现状,并系统综述了基于深度学习的水下成像技术研究进展,以期能够帮助相关研究人员梳理水下成像技术的发展趋势及存在问题。
1 水下成像技术
1.1 水下图像退化模型
大气与水体环境之间的显著密度差,使得光波在两种环境介质中的传播特性存在明显差异,导致水下成像过程与陆上成像过程的显著不同。海水或湖水中存在较多分布不均的浮游生物和悬浮颗粒,对接触到的光会引起较强的散射和吸收效应,其中散射又可分为前向散射与后向散射,前者是目标物反射光到达成像设备前受水体微粒影响,传播方向发生小角度偏离的现象,主要表现为点光源扩散,产生离焦模糊,造成目标信息的缺失,图像不清晰;后者是未经目标物反射的环境光直接被微粒反射进入成像设备的现象,会引入较多的成像噪声,使图像失真。同时,水下环境中散射又包含单次散射和多次散射,当水体无杂或杂质较少时,光波经过一次散射过程到达接收器,称为单次散射;当水体浑浊,杂质颗粒分布密集时,光波往往需要经过多次散射才能到达相机,称为多次散射。散射作用导致图像产生对比度低、模糊和雾化等特征。此外,海水对光波存在吸收作用,使得原本的光能量在传播过程中不断减弱,到达成像设备的光与最初的目标反射光存在显著差异,加之海水对不同波长的光的吸收存在差异,对红光的吸收尤为明显[3-4],如图1(a)所示,最终造成水下图像的严重失真和蓝绿色偏。光波在水下传播时发生衰减,其过程遵循Lambert-Beer定理,表示为

式中,Er和E0表示原始光辐射能量与水下传播距离为r时的光辐射能量,c为水体衰减系数。
此外,在深水、浑浊水域还存在光线不足的问题,成像时需要使用人造光源补光,非均匀光照可能导致图像出现亮斑及明暗不均等问题。
水下成像过程如图1(b)所示。
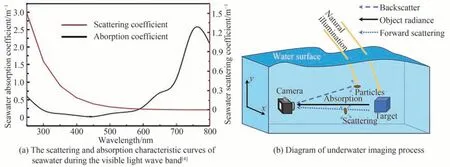
图1 水下图像退化原理Fig.1 Principle of underwater image degradation
水下成像中的图像退化模型一般采用Jaffe-McGlamey提出的成像模型(Image Formation Model,IFM)[5]来表示
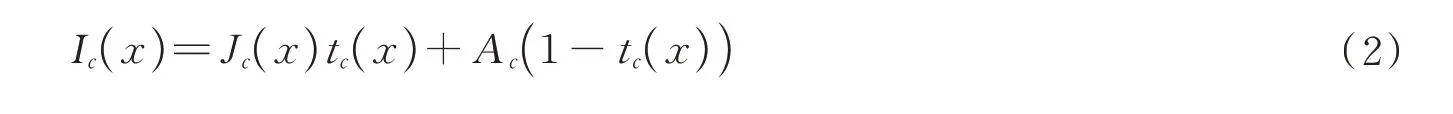
式中,Ic(x)为使用相机在水下拍摄获得的图像,x为图像中任一像素,下标c表示图像中红(Red,R)、绿(Green,G)、蓝(Blue,B)三个颜色通道,Jc(x)表示原始无失真图像,tc(x)为图像在通道c的透射率,与光波在海水中的吸收和反射有关,Jc(x)tc(x)表示经目标反射后到达相机的光强,Ac为背景环境中光强,Ac(1-tc(x))表示未经目标反射而进入相机的杂散光。其中,透射率tc(x)为

式中,β(λ)为光波的衰减系数,是其在水下环境中的吸收系数和散射系数之和,随光的波长λ改变,d(x)为目标与相机之间的距离。由式(3)可知,透射率与成像距离呈指数关系,距离越远,透射率越小,即越远的区域图像质量下降越严重[6]。
1.2 水下成像技术分类
一般来讲,水下成像技术可分为声学成像技术和光学成像技术两大类。水下声学成像技术可进行远距离成像,但由于其分辨率较低,易受外部环境干扰等原因,成像质量往往不高,应用范围较为有限。而水下光学成像技术可获得直观的水下图像,成像分辨率高,成像速度快,操作简便,在水下成像中获得广泛应用。在本文中,我们将水下成像特指为水下光学成像。
水下成像技术按照技术途径差异分为图像处理和图像重建两种。图像处理是对相机拍摄的图像进行数字图像处理以提升图像质量的方法,包括以空间域法、变换域法、颜色恒常性法等为代表的数字图像增强技术,以及以多通道融合技术、基于先验的图像复原法等为代表的数字图像复原技术。图像重建则主要指充分利用光波的强度、光谱、偏振等多维度信息,结合光波在水下传输过程的物理模型,最终实现水下目标的重建和成像的方法,包括水下偏振成像、水下关联成像、水下光谱成像、水下压缩感知成像、水下激光成像、水下全息成像等,如图2所示。
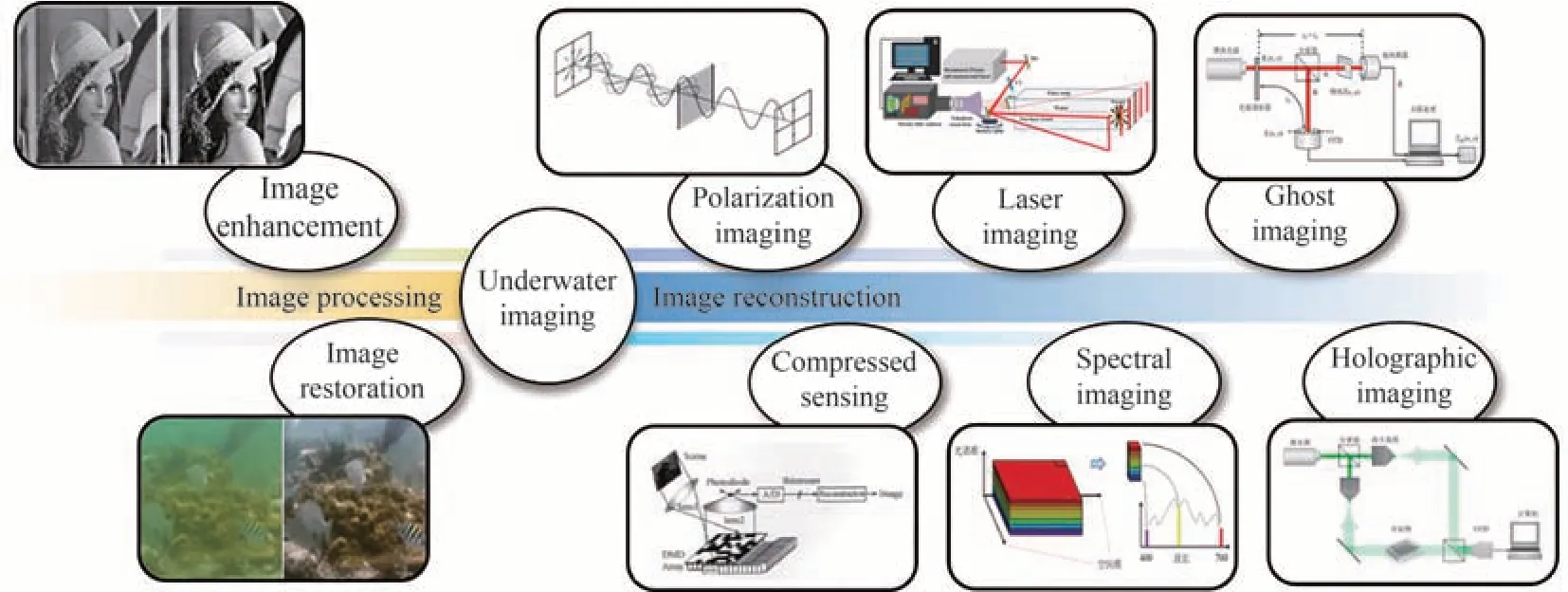
图2 水下成像技术分类Fig.2 Classification of underwater imaging
2 深度学习
深度学习技术近年来在计算机视觉、自然语言处理、无人驾驶等领域获得广泛应用,尤其在计算机视觉领域,卷积神经网络(Convolutional Neural Network,CNN)被广泛用于提取图像的特征信息,通过衡量损失函数、优化网络参数,以“端到端”方式实现图像增强、图像重建等目标。下面重点对CNN进行介绍。
2.1 CNN主体结构
在深度学习技术发展中,先后出现多层感知机(Multilayer Perceptron,MLP)、CNN、以及生成对抗网络(Generative Adversarial Network,GAN)等多种不同结构的经典网络,分别用以完成不同的任务并具有不同的效果。1)MLP作为早期的网络结构之一,是一种前向结构的人工神经网络,包含输入层、输出层、隐藏层,其中的节点采用全连接或局部连接的方式连接,需要计算大量参数,效率较低;2)CNN是深度学习的重大突破之一,广泛应用于计算机视觉领域,采用卷积层替代MLP中的全连接结构,凭借卷积运算的稀疏连接、参数共享、平移不变等特性大大降低了网络参数量和计算量,极大提高了图像处理效率。早期CNN由卷积层和全连接层依次连接组成的单链骨架构成,如图3(a)。全卷积网络(Full Convolutional Network,FCN)在骨架结构基础上,利用卷积层替代全连接层,实现“端到端”的模型,如图3(b)。U型卷积神经网络(U-Net)从FCN发展而来,由下采样和上采样形成对称的U型结构,辅以通道间的跳跃连接,可实现全局特征与局部特征的结合,更好地利用细节信息,实现端到端的图像处理,此外U-net还可以利用数据增强在样本数据较少时进行训练,在医学影像处理等方面上有较大帮助,如图3(c);3)GAN由生成网络和判别网络两部分组成,训练时采用博弈思想,将生成网络生成的图像与真实图像交予判别网络判别真伪,训练判别网络,并将结果返回生成模型用于增强损失函数,训练生成网络。经过不断训练,生成网络和判别网络的能力不断提升,最终获得能生成所需图像的生成网络,常在缺乏或无法获得相应数据时用于生成图像。
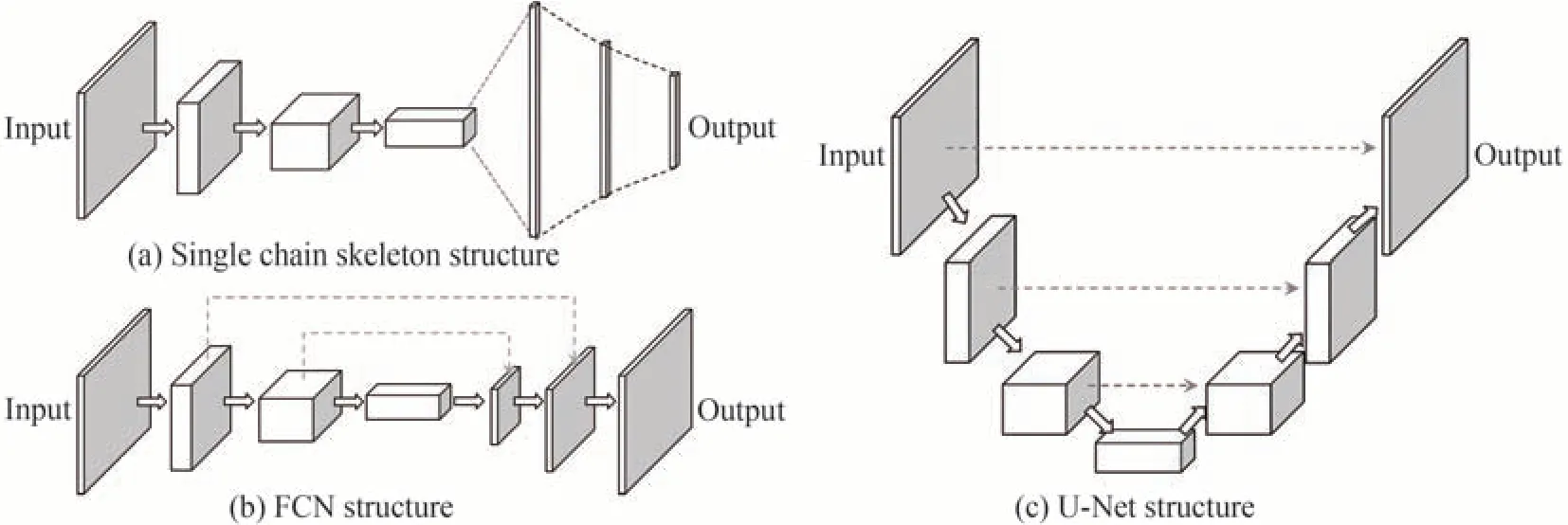
图3 CNN网络结构Fig.3 CNN structure
2.2 CNN组成
尽管CNN有多种不同网络主体结构,但其基本结构都包括:1)全连接层、卷积层:用于图像特征提取,得益于卷积运算的稀疏连接、参数共享、平移不变等特性,卷积神经网络具有更高效的特征提取能力;2)池化层:用于下采样,对图像信息进行滤波和高层特征提取;3)激活函数:增加网络的非线性拟合能力,包括整流线性单元(Rectified Linear Unit,ReLU)、Sigmoid、Tanh等函数;4)损失函数:衡量处理结果与所给标签的接近程度,值越小表明越接近。图像处理中常用最小绝对值偏差(又称L1损失函数)、均方误差(Mean Square Error,MSE)、结构相似性(Structural Similarity,SSIM)等损失函数,图像分类中常用交叉熵损失函数(CrossEntropy);5)优化器:反向传播时用于优化网络各层参数,常用优化算法有随机梯度下降算法(Stochastic Gradient Descent,SGD),自适应矩估计(Adaptive Moment Estimation,Adam)等。
2.3 CNN的细节优化
在CNN主体网络结构基础上,还可以向其中添加以下细节,以进一步优化网络性能和效率:1)跳跃连接:将神经网络中某一层的输出跳跃连接至其他层,作为其输入的一部分,可将网络中某一层的特征向后传输至更深层,避免深层网络在参数更新时出现的梯度爆炸和梯度消失问题,能加快网络训练的收敛速度,常用于残差网络中;2)多尺度信息融合:包括多尺度输入融合,多分支通道融合,多尺度特征融合等,能够将不同感受野的信息以串联方式传递给下一层网络,有利于增强网络对高层特征及细节的探测;3)稠密连接:与跳跃连接相似,将网络中每一层的输入与之前所有层的输出在维度上进行特征融合,以最大化利用特征信息,但密集链接会增加训练过程计算量,降低运算效率;4)注意力机制:可分为软注意力机制和硬注意力机制[7],软注意力考虑全局,在图像特征(空间或通道)分出旁路对输入特征进行降维,学习特征映射的权重分布,再将其与原图像相乘,得到具有不同权重的(空间或通道)特征,常用于图像处理网络中[8-9]。而硬注意力是一个随机过程,某一时刻只关注一个特征信息。
2.4 CNN的应用过程
应用CNN处理问题之前,需要对网络进行设计及训练。CNN主要依靠人为经验进行主体结构选取及细节添加,网络训练依靠仿真模拟、实验记录或实地获取的数据集进行。在训练过程中,从数据集中取出样本数据输入CNN,经过全连接层/卷积层等模块处理后得到输出,输出通过损失函数计算与样本标签的差距,并利用优化算法进行反向传播优化网络参数,完成一次网络训练,随后从数据集中取出下一组样本进行下一次网络训练。训练过程中根据损失函数是否能收敛至目标值来判断网络设计是否合理及是否完成训练,若无法收敛或损失函数无法降低至目标值则需要对网络超参数或者结构进行进一步修改。将网络训练好后,需要利用验证集验证网络对新数据的处理效果,若神经网络在验证集上表现不佳则要对网络进行修改并重新进行训练直至收敛。训练好并通过验证的网络即可用于目标数据处理。
3 深度学习在水下成像技术中的应用
3.1 水下图像增强技术
水下图像增强技术主要使用计算机数字图像处理的手段来对水下图像进行调整以提升视觉效果。目前,已有大量图像增强算法被提出,并且均可获得较好的视觉效果。图像增强算法主要可以分为传统图像增强算法和基于CNN、GAN等的深度学习方法两大类。
3.1.1 传统图像增强方法
传统图像增强方法包括空间域法、变换域法、颜色恒常性法等。
1)空间域法是在空间域对图像像素进行操作,以改善图像视觉效果的方法,包括灰度变换、直方图均衡、拉伸等手段[10]。直方图均衡化是空间域法中最常使用的方法,将集中分布的灰度直方图均衡至全局,增加物体与背景的灰度差。在整体偏暗的水下环境中,将图像进行直方图拉伸通常可改善光照过暗的不足,取得较好的显示效果,但直方图均衡化也容易造成过饱和,细节丢失等问题。王新伟等[11]针对上述问题,提出一种自适应设置阈值的双平台自适应图像增强算法,提高了水下图像对比度和亮度;王龑等[12]在直方图均衡化基础上提出相对全局直方图拉伸图像增强方法,对图像RGB三通道进行自适应直方图拉伸并转换到CIE-Lab颜色域进行拉伸优化,避免基于像素值重分布的盲目增强,提升了图像视觉效果;黄冬梅等[13]在RGB与CIE-Lab颜色模型中对图像进行自适应直方图拉伸,并针对不同水体进行动态参数优化,获得清晰水下图像。
2)在图像频率域中,高频分量通常代表灰度梯度较大的物体边缘区域;低频分量通常代表图像中较为平坦的背景区域[14]。变换域法是将原始图像利用傅里叶变换、小波变换、颜色空间变换等手段转换到对应域后,进一步进行滤波等处理并进行反变换以获得增强图像的方法。例如,KASHIF I等[15]将RGB图像对比度拉伸之后转换至HSI域进行饱和度和强度拉伸以增加色彩真实度;蓝雷波等[16]将水下原始RGB图像与完成拉普拉斯高通滤波处理后的图像进行HSV颜色空间转换,用原图饱和度分量改变处理后图像的HSV颜色空间饱和度分量,以达到纠正饱和度分量的目的,最终获得清晰、色彩恢复良好的图像;VASAMSETTI S等[17]提出一种基于小波的水下图像透视增强技术框架,在图像RGB通道上应用离散小波变换生成两个分解系数,通过修改系数改善颜色和局部对比度,并依此重建RGB通道灰度图像,提高水下计算机视觉任务的准确性。
3)颜色恒常性法利用目标颜色因光照条件改变而改变时,人们对其表面颜色的直觉仍然保持不变的特性,将目标图像还原回标准光照下的色调以获得较好的视觉效果,包括白平衡、Retinex法等。白平衡是消除环境对物体造成的色偏影响,保持物体在不同光照情况下所获得的图像颜色一致的方法,在水上环境中可起到较好的颜色校正效果,但由于水下图像颜色严重退化,传统白平衡方法效果较差。针对该问题,王文等[18]提出采用改进的白平衡方法,对图像的RGB通道进行[0,255]范围的仿射变换,使其尽可能占据较大的灰度范围,从而得到更符合视觉效果的水下图像;ANCUTI CO等[19-20]提出水下白平衡以补偿光波选择性衰减,根据对比度、显著特征和曝光度确定融合权重,并据此将白平衡矫正后的图像和局部自适应直方图均衡图像进行融合,产生了具有更好全局对比度和细节信息的增强图像。Retinex法基于视网膜大脑皮层理论,即目标颜色由目标对不同波长光波的反射能力决定,人眼感知的目标亮度取决于环境照明和目标表面对光的反射。2008年,JOSHI K R等[21]提出使用Retinex方法对图片进行处理,一定程度上改善了水下图像的视觉效果;张明明等[22]根据Retinex光照反射模型和图像构成理论设计了一种基于光照分量的多尺度优化估计方案,近似把图像光照分量等价于透射率图像,并提出比例融合方法,使所获得的透射率图像更加接近于实际;张彩珍等[23]针对传统算法引起的色偏和失真问题,提出一种基于差异通道增益和多尺度Retinex算法的水下图像增强算法,采用改进的灰度世界算法得到不同颜色通道的增益比,加大补偿水介质对红光的吸收部分,使RGB图像的色彩比例修复为近似真实的比例,避免信息丢失。如图4所示,该算法能有效增强各环境中的水下图像,恢复图像的细节信息。

图4 不同算法处理前后的效果[23]Fig.4 Effects of different algorithms before and after processing[23]
3.1.2 基于深度学习的图像增强方法
作为数据驱动方法,深度学习可以在没有先验条件情况下从原始图像和退化图像中学习高层语义特征并对退化图像进行还原,在图像增强中具有非常出色的表现。
2017年,CNN被用于解决水下图像退化问题。PEREZ J等[24]提出一种基于CNN的水下图像增强方法,该方法使用降级和恢复的水下图像作为训练数据对实现模糊图像和清晰图像间的端到端转换;WANG Y等[25]提出端到端水下图像增强框架(UIE-net),如图5(a)所示,用CC-Net子网络输出不同通道的颜色吸收系数,用于校正水下图像颜色失真,用HR-Net子网络输出光衰减投射图,用于增强水下图像的对比度,而UIE-Net由于采用像素破坏策略提取图像局部区域的固有特征,极大地加快了模型收敛速度,提高了准确率;ANWAR S等[26]使用在室内环境中产生的合成水下图像数据库训练卷积神经网络(UWCNN),联合MSE和SSIM作为模型损耗,在保留目标原始结构和纹理信息的同时可重建出清晰水下图像,并在各种水下场景中使用真实及合成水下图像验证了该模型的通用性。
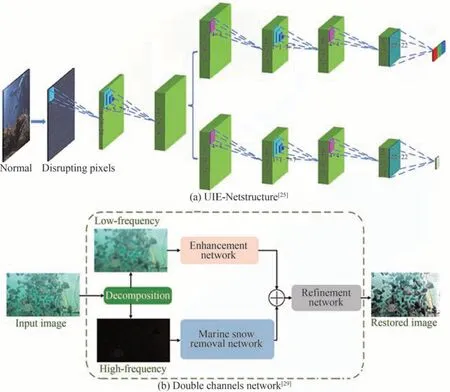
图5 深度学习应用于图像增强Fig.5 The applications of deep learning in image enhancement
针对人工光源导致水下成像照明不均的问题,CAO X等[27]将原始图像建模为理想图像和非均匀光层的叠加并将其从原图中分离,用扩张卷积代替传统的池化层,扩大接受域,并设计特征损失、平滑损失和对抗损失作为损失函数来解决颜色漂移和细节模糊问题,在非均匀光照识别中获得了更高精度;DUDHANE A等[28]提出端到端广义深度网络,利用深度可分离卷积滤波器和密集残差网络进行颜色相关特征等通道特征提取,并使用稠密残差网络进行水下图像去雾,最终实现不同类型水下图像增强,结果如图6(a)所示;WANG Y Q等[29]提出一种集成双通道的端到端网络模型,通道一利用残差密集网络模块对图像低频层进行色彩校正和去雾,通道二采用局部残差学习策略去除图像高频层中的白色海洋雪,并采用细化模块进一步改善通道联合结果,如图5(b)所示;HUANG Y F等[30]将RGB图像经过色彩校正后转换到YCbCr颜色空间,在亮度通道上使用多尺度递归网络去模糊并将其与未处理的Cb,Cr通道进行重组,获得去雾的高质量图像,结果如图6(b)所示。

图6 神经网络用于图像增强结果Fig.6 Image enhancement effect by neural networks
在深度学习方法中,往往难以获得水下环境的清晰图像,因此无法形成训练数据集。GAN[31]可以通过无监督训练生成逼真水下图像或者进行风格迁移将陆上图像转化为水下图像,被用于解决数据集缺乏的问题。LI J等[32]基于GAN提出WaterGAN,如图7所示,用陆上图像和深度图像通过生成器合成水下图像,将其与真实水下图像对判别器和生成器进行训练,使其能生成模拟水下环境的图像。但WaterGAN模拟生成的水下图像环境较为单一,无法涵盖非均匀光照和浑浊水体等环境。
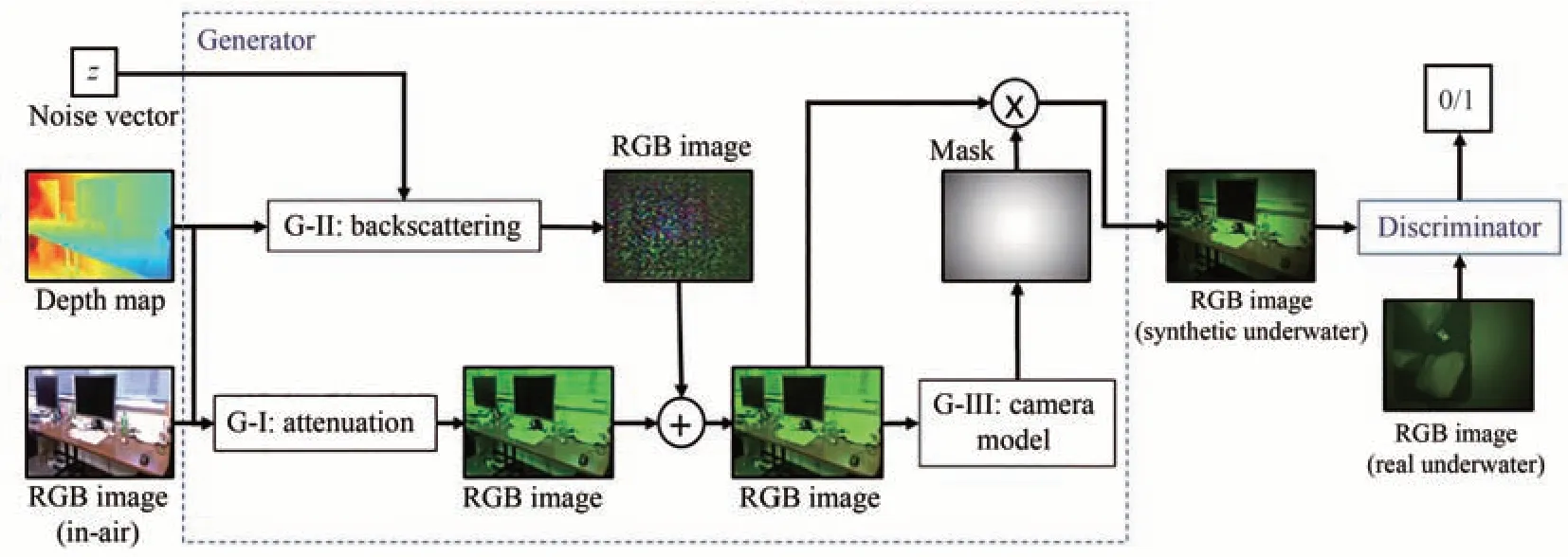
图7 WaterGAN模型[32]Fig.7 WaterGAN model structure[32]
在风格迁移上,循环一致对抗网络(Cycle-Consistent Generative Adversarial Networks,CycleGAN)[33]可通过域转换将陆上图像转变为水下风格的图像来获得水下数据集。例如,FABBRI C等[34]依据CycleGAN提出基于U型结构的UGAN,利用CycleGAN生成的水下图像对UGAN进行训练,训练后的UGAN可将模糊的水下图像转换为高分辨率的图像;LI N等[35]根据CycleGAN和条件生成对抗网络(Conditional GAN,cGAN),提出水下多风格生成对抗网络(UMGAN),利用混合对抗系统和非配对方法从陆上图像生成逼真水下图像。此外,他们还利用风格分类器和条件向量将陆上图像转换为水下图像,在指定的浊度或水体风格下可保留陆上图像的主要内容和结构信息;ZONG X等[36]则在CycleGAN基础上提出局部周期一致生成对抗网络,采用局部鉴别器和全局鉴别器来增强网络的稳定性和适应性;LI C Y等[37]提出的Cast-GAN通过激励边缘和颜色在白色光源下向辐射方向增强,来调整发生器的损失函数,以解决水下图像增强问题。然而,使用GAN的样式转换能力生成数据集效率较低,因为一个训练良好的GAN只能生成一种类型的水下风格。为此,LI C等[38]直接从简化的水下IFM合成水下图像,用于训练UWCNN网络,而YIN X等[39]在IFM模型基础上增加非均匀光照项,合成的图像用于FMSNet恢复图像,实现了更好的恢复效果。
除用于生成数据集外,GAN还可用于图像增强处理。ISLAM M J等[40]利用FABBRI C等[34]生成的水下图像数据集到FUnIE-GAN网络中,获得较好的图像增强结果;王德兴等[41]则通过向GAN加入Inception模块和Residual模块以克服网络梯度消失和过滤器尺寸选择问题,实现不同尺度特征信息的融合,恢复结果如图8所示。与普通GAN相比,该方法能有效提升图像清晰度、颜色校正和对比度方面的视觉效果。

图8 IRGAN图像恢复结果[41]Fig.8 Image restoration results[41]
目前,传统图像增强方法在水下图像处理中的应用有一定效果,但受限于水体环境与大气环境的差异,其应用效果有限。空间域法可增加物体与背景灰度差,调整过暗环境,但在画面光照不足或有明显亮斑时,容易放大噪声、引入伪影;变换域法可通过滤波等方式去除图像噪声,但对低对比度和边缘特征不明显图像处理效果较差;颜色恒常性法通过先验假设将目标图像还原回标准光照下的色调来调整图像色彩,较大程度上依赖先验假设,受水体复杂环境影响,难以进行准确先验估计。此外,单一传统处理方法无法兼顾水下图像的噪声及颜色失真等多重问题,通常需要多种方法联合使用,需对图像进行多次处理,耗时且不同方法应用顺序对结果影响大。深度学习方法利用大量数据学习水下退化图像-恢复图像的仿射变换,对水下图像进行去噪、颜色校正、对比度提升等操作,直接获取恢复效果较好的图像,避免了传统方法繁杂的多步处理过程。与此同时,神经网络学习端到端的映射方式,无需对环境进行先验估计,避免引入先验误差,较传统方法可取得更好效果。但深度学习方法当前也存在网络训练费时、单一网络对不同水体的泛化能力不足、缺乏高质量数据集、计算复杂、实时性差等问题。表1中给出了传统水下图像增强技术和基于深度学习的方法的特点比较。
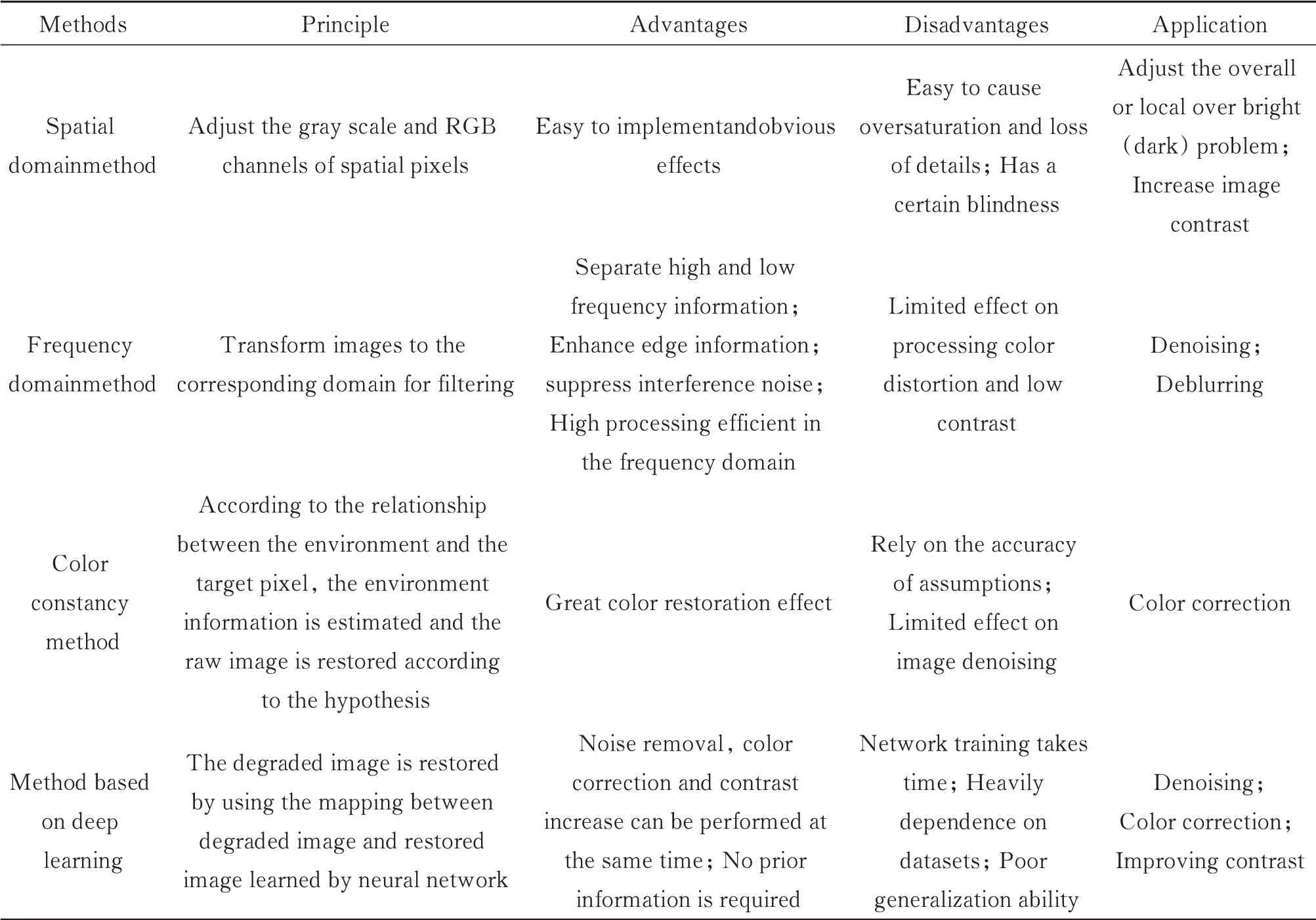
表1 传统水下图像增强技术方法与基于深度学习的方法总结Table 1 Summary of traditional underwater image enhancement methods and deep learning methods
在未来,水下图像增强将以深度学习方法为主,主要解决网络轻量化、泛化和数据集增强等问题。此外,将最新发展的多种神经网络引入水下图像增强方面,也是未来发展方向之一。
3.2 水下图像复原技术
水下图像复原技术通过分析水下成像机理和光传播的基本物理原理,通过构建图像退化的物理模型,利用水体衰减因子、散射系数、透射率等一系列先验信息反演出真实场景,进而得到退化前的图像。在参数估计上,根据Jaffe-McGlamey提出的IFM模型,最重要的待估计参数为透射率和环境光。因此,水下图像复原可以近似理解为水下图像透射率和环境光估计问题[6]。为了从图像中得出先验信息,需要借助一系列手段获取先验知识。近些年,已有多种基于不同先验的水下图像复原方法被提出,这里将数字图像复原从基于先验的复原方法和深度学习方法两方面进行总结。
3.2.1 基于先验的复原方法
基于先验的复原方法通过不同的先验或假设提取图像特征,然后利用这些特征估计透射率(Transmission Map,TM)和环境光(Background Light,BL),从而实现图像复原。较为典型的方法是暗通道先验算法(DarkChannelPrior,DCP),由HE K等[42]在2011年提出并用于图像去雾。统计发现,无雾图像中的局部区域存在一些像素,这些像素中至少有一个颜色通道的亮度值非常非常低,被称为暗通道,并以此来计算图像透射率,反演出去雾图像。DCP除在普通图像处理中应用较多外,在水下图像处理中也受到广泛应用。例如,CHIANG J Y等[43]利用DCP补偿传播路径上的颜色衰减,对水下传播路径上的雾霾现象和波长衰减差异进行了修正;ZHAO X等[44]提出从水下图像背景颜色推导水体固有光学特性的方法,采用传统DCP算法对R通道的透射率进行估计,并利用衰减系数间的关系从R通道估计GB彩色通道的透射率。水下图像重建和陆上图像重建有一定的相似性,故DCP在水下环境下也有一定效果。但DCP在陆上图像的应用关注RGB通道中灰度值的差别,默认三个通道中的透射率都相同。而水下环境中,由于不同水体对光波有不同程度的吸收,如海水对红光吸收较强等,所以传统DCP在水下环境中的效果较差,随后很多改进的DCP算法被提出。针对红色通道衰减严重,DCP主要受R通道影响的问题,DREWS J P等[45]提出水下暗通道先验算法(UDCP),只考虑GB通道来消除红色的影响;LU H等[46]针对浑浊水体蓝色通道偶尔会出现灰度值最低的情况,提出一种RB双通道计算透射率和使用加权中值滤波去除光晕的方法;ZHENG L等[47]针对传统DCP泛用性差的问题,在所有通道都以最高速率衰减基础上考虑了不同水体类型的光谱剖面,提出一种广义的水下暗通道先验方法,以对不同水体类型下的图像传输进行稳定估计;GALDRAN A等[48]提出一种红色通道先验方法估计水下图像的透射率,并引入模糊图像的饱和度信息对传输图进行调整,提高了图像整体色彩的真实性;CARLEVARIS B等[49]根据水下图像中R通道和GB通道的衰减差异,提出场景估计最大强度先验方法,利用R通道最大强度与GB通道最大强度的差值,以及颜色通道间最大差异来定义传输图,最终较好地描述图像深度;ZHAO X等[50]利用DCP与MIP来估计BL,通过在暗通道中选取0.1%最亮的像素及在输入图像中选取红蓝或红绿差值最大的像素作为全局背景光,保证估计的鲁棒性,同时消除了部分前景中蓝色或绿色物体的干扰;PENG Y T[51]等则认为DCP、UDCP、MIP等方法只考虑RGB通道可能导致错误深度估计,提出一种利用图像模糊来测量场景深度的方法,基于场景深度越深,水下图像越模糊的假设,通过原始图像与多尺度高斯滤波图像的差值估计像素模糊图,经过最大滤波后获得粗略深度图,最后使用CMR和引导滤波器对深度图进行细化;此外,PENG Y T等[52]还提出利用光吸收来估计更准确的背景光和水下场景深度,恢复了各种类型复杂场景下的水下图像;WANG Y等[53]提出了一种基于自适应颜色补偿和双传输估计(ACDTE)的图像恢复方法,采用颜色-色调自适应方法确定水下图像的色调,并采用四叉树分解方法估计全局水体光照,能有效校正图像颜色偏差。
3.2.2 基于深度学习的图像复原方法
深度学习同样在图像恢复中有广泛应用。在Jaffe-McGlamey提出的IFM模型中,图像恢复最重要的任务是估计TM和BL参数,基于先验的方法依赖先验信息的可靠性,而先验信息多依靠人为选取,可靠性较低。深度学习以数据驱动的方式获取水下图像与相关参数之间的关系,可获得更稳健、更准确的估计[54]。DING X[55]等采用带增益因子的自适应颜色校正算法对图像进行颜色校正,并通过CNN估计颜色校正后水下图像的BL和TM;CAO K等[56]搭建简化和精细两个网络分别对NYU数据集合成的水下图像进行BL和TM估计,网络结构如图9所示,该方法估计的参数恢复效果优于现有的基于IFM的图像恢复方法;YIN X等[39]则利用改进的IFM合成水下图像对,并将其用于FMSNet学习图像映射。
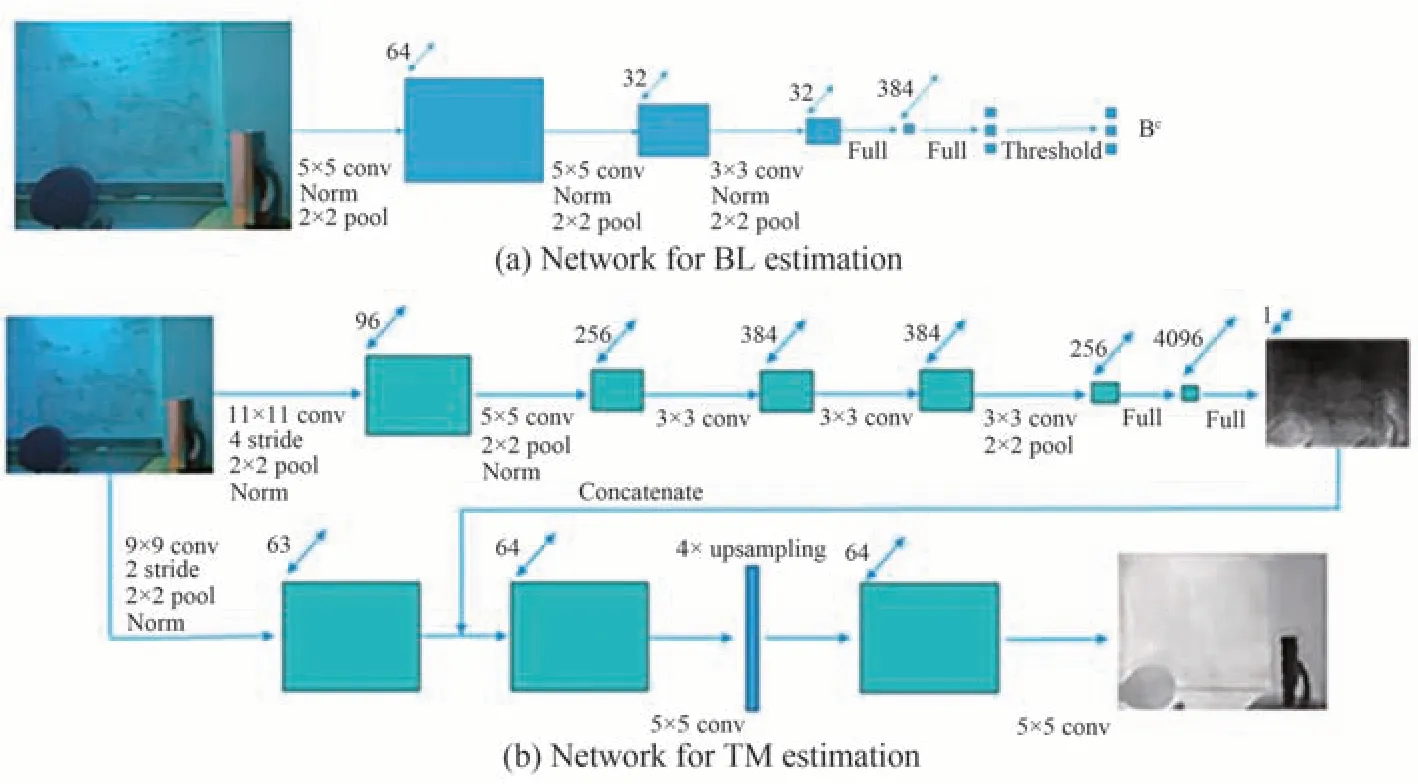
图9 神经网络用于参数估计[56]Fig.9 Neural network for parameter estimation[56]
WANG K等[54]利用透射估计网络(T网络)和全局环境光估计网络(A网络)对TM和BL进行估计,其中T网络采用跨层连接和多尺度估计来防止晕影和保留边缘特征;PAN P W等[57]提出了一种水下图像去散射的多尺度迭代网络,基于金字塔分解方法,使用卷积神经网络估计传输映射TM,然后使用自适应双边滤波器对估计结果进行改进,结果如图10(a)所示。
除利用网络从图像中估计参数外,还可以将网络与水下模型结合获取相关参数。例如,LIN Y F等[58]针对现有深度学习方法没有充分考虑水下物理畸变过程的问题,提出在水平恢复阶段将水下物理模型嵌入网络中,估计衰减系数作为水型信息的特征表示,并与深度图联合估计传输图,在垂直恢复阶段利用带有衰减系数优先注意块的稠密网络校准垂直失真图像的RGB通道特征图,最后通过CHIANG J Y等[43]的网络恢复图像,结果如图10(b)所示;BARBOSA W V等[59]利用对比度、锐度、边界完整性等特征来获得多目标函数IQM,式(4),并以式(5)作为损失函数对CNN进行优化,将优化后网络得到的TM参数用于图像恢复,其处理流程如图11所示。

图10 神经网络用于图像恢复Fig.10 Neural network for image restoration
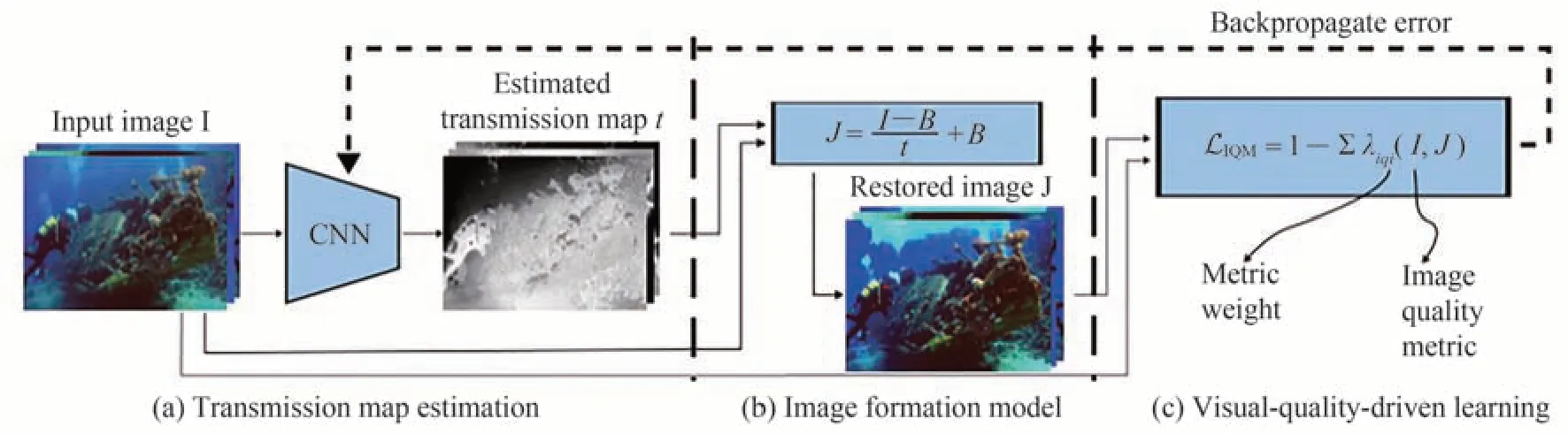
图11 两步学习法示意图[59]Fig.11 Diagram of our two-stage learning[59]

此外,针对缺少水下图像数据集的问题,UEDA T等[60]提出一种基于深度神经网络的水下图像恢复算法,创建了一个拥有大量清晰和退化图像对的数据集,并从RGB-D图像中生成10种不同衰减系数的退化水下图像。将其与清晰图像对放入UWCNN中进行训练,取得了较好的水下图像合成效果。
总体上,基于先验的图像恢复方法采用不同的先验或假设对水下模型的参数进行估计,得到水体退化模型,然后反演得到退化前的图像,这种基于物理模型且考虑了水体光照条件和光学特性的方法相较于图像增强更具有针对性和方向性,避免盲目增强,可达到更好的恢复效果。但该方法受水体性质和拍摄条件影响较大,同一水体在不同拍摄条件下所得图像不同,容易影响先验条件的选取。而图像恢复效果依赖先验条件的准确性,只有在先验条件符合水下图像的水体环境时,才能得到较好的恢复效果,但人为选取的先验条件存在人为判断误差,因而无法保证恢复效果。此外,在复杂的水体环境中,物理模型会出现偏差及更多限制因素,使先验条件的估计变得更加困难。深度学习技术的出现可在一定程度上解决上述问题,通过对图像参数的——映射学习,神经网络得以对图像参数进行直接估计,避免了复杂的先验假设过程及人为经验引入的误差,同时可对不同水体的参数进行估计,具有先验方法不具备的泛化性。但深度学习方法的恢复效果依赖于训练数据集的质量,目前的数据集多是由人工合成,与真实数据有较大差异,影响了实际使用中的效果。此外,现有网络无法足够准确地估计参数且耗时相对较长[13],恢复图像往往存在伪影,因而现有的基于深度学习方法还有待进一步发展。基于先验的图像恢复方法与基于深度学习的方法总结如表2所示。
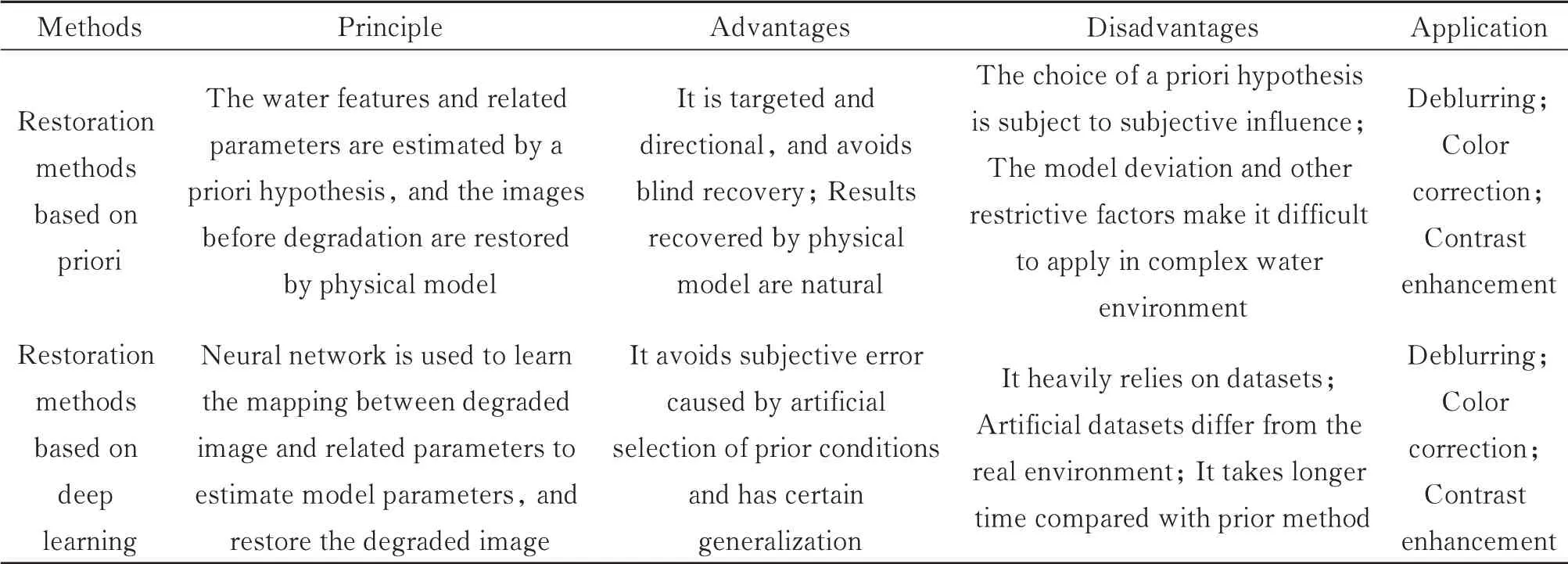
表2 基于先验的图像恢复方法与基于深度学习的方法总结Table 2 Summary of image restoration methods based on priori and deep learning
3.3 水下偏振成像技术
光波在与物质作用过程中,其偏振特性会随物质特点的不同而发生改变,利用偏振信息的这种改变可以获得物质的形状、材料、纹理等信息[61]。偏振成像技术通过挖掘散射光场偏振信息,分析图像中目标与背景偏振特性的变化趋势,估算目标信息光和背景散射光偏振特性的联系与差异,反演目标信息光和背景散射光的光强变化,进而去除背景散射光,实现清晰成像。基于目标的偏振特性,能够快速实现对伪装目标的探测和识别等。
水下偏振成像技术主要包括水下偏振差分成像技术、被动水下偏振成像技术和主动水下偏振成像技术,以及最近发展较快的基于深度学习的偏振成像技术。
3.3.1 水下偏振差分成像技术
传统水下偏振差分成像技术利用背景散射光与目标反射光的偏振特性差异来抑制背景散射光[62]。在差分成像中,认为浑浊水体具有去偏振效应,背景散射光可视为非偏振光,而携带目标信息的目标信号光视为偏振光。通过在成像设备前加一偏振镜并进行旋转可获得偏振方向相互正交的目标强度分布I||与I⊥的关系为

式中,B||和T||表示后向散射光B与目标信号光T亮度最大的偏振图像,B⊥和T⊥表示后向散射光与目标信号光亮度最暗的偏振图像,即包含最多与最少目标信号光的图像,而后根据背景散射光与目标信号光的偏振特性可得

通过将式(6)中两式相减即可消除背景散射光,得到目标恢复图像Ipd

在实际中,背景散射光与目标信号光通常不是理想的非偏振光和完全偏振光,而是具有不同偏振度的部分偏振光,仅靠传统偏振差分成像技术无法完全消除背景散射光的偏振部分。此外,传统偏振差分成像技术采用机械式检偏器,无法实时成像。对此,管今哥等[63]设计了一套基于Stokes矢量的计算偏振差分实时成像系统,如图12(a)所示,利用Stokes矢量S=[I,Q,U,V]T对光偏振态进行了完整描述,计算偏振差分成像方法表示为

式中,γ为权重系数,Q为0°与90°偏振方向光的强度差值,U代表45°与135°偏振方向光的强度差值。当γ=1/tan(2α)时,背景可通过共模抑制作用完全消除,成像结果如图12(b)所示。

图12 基于Stokes矢量的计算偏振差分成像[63]Fig.12 Computational polarization difference imaging systems based on Stokes vector[63]
WANG J等[64]提出基于偏振图像周期性积分的水下图像恢复方法,通过在一个完整的图像强度变化周期中获取不同偏振方向的偏振图像,并将其叠加后作为偏振光在偏振方向维度上的强度积分,最后计算每个像素的偏振度,得到清晰的偏振差分图像Ipd(x,y),表示为

式中,Iθ(x,y)是偏振图像中(x,y)处的光强度,Iθ+90(x,y)是偏振度相差90°的光强度。
水下偏振差分成像技术利用正交偏振图像的差异性来滤除背景散射噪声,仅需两幅正交偏振子图像即可实现对背景散射光的消除,实现方式简便,但在水体浑浊度高且环境复杂的条件下成像效果改善有限。
3.3.2 水下被动偏振成像技术
水下被动偏振成像技术通过采集两幅偏振态正交的偏振子图像,根据背景散射光和目标信息光偏振特性的差异,利用水下光传输模型重建清晰的场景图像[4]。目前,水下被动偏振成像技术多采用SCHECHNER Y Y等[65]提出的被动水下偏振成像模型,表示为

式中,IO为探测器接收到的目标信息光,IT为探测器接收到的总光强,Imax和Imin为探测器通过旋转偏正片获取的偏振子图像,前者背景散射光强最大,后者背景散射光强最小,p为背景散射光的偏振度,IB为探测器接收到的背景散射光表示无穷远处的背景光散射强度,同时有(1-e-βz),即接收到的背景散射光强受散射系数β和距离z影响。该模型的重点在于分离背景散射光和目标信息光。
SCHECHNER Y Y等[65]在提出该模型时认为目标信息光的偏振度远比背景散射光的偏振度小,因而可忽略不计,而HUANG B等[66]认为物体的辐射也会对偏振产生影响,因此研究了遮蔽光(Veiling Light)偏振和物体亮度对水下成像形成的影响,并提出利用目标信号偏振差恢复水下图像的方法,在模型中引入了中间图像K(x,y)和偏振正交差分信号ΔD(x,y),见图13,并给出了两者的变换关系式
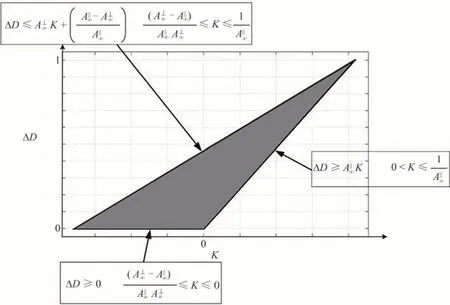
图13 K(x,y)和ΔD(x,y)关系图[66]Fig.13 The relationship between K(x,y)andΔD(x,y)[66]

式中,a和b为大于0的优化系数,a用于调整尺度,b用于调整指数函数的基值,通过调整参数使关系曲线位于下图中灰色范围内来推导场景的透过率,实现清晰成像。
GU Y等[67]针对从目标反射光在传播过程中发生散射引起偏振变化的问题,利用水体固有光学特性获取目标偏振特性,并将水下成像的波束扩展函数(BSF)推广至偏振波束扩展函数,通过蒙特卡洛仿真和实验,得到简化的水下极化成像模型;卫毅等[4]在SCHECHNER Y Y等[65]提出的模型基础上,考虑水体背景散射光的传输特性,分析场景深度信息与散射光的物理关系,建立了基于深度信息的水下Lambertian反射模型,即
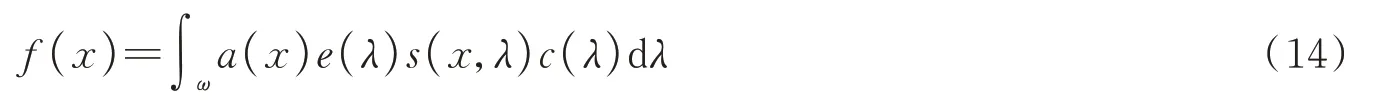
式中,f(x)为探测场景中物体表面上某一点颜色,λ为光波波长,ω为光谱范围,x为场景中像素点位置,a(x)为场景中不同位置的深度信息,e(λ)为光源分布,s(x,λ)为空间中某点对某一波长的反射率,c(λ)为相机的感光系数。该模型描述了能量相同、波长不同的目标光经水体传输后到达探测器的能量不同,能在无先验条件前提下实现无色彩畸变的水下目标场景清晰成像,结果如图14所示。

图14 浅海被动水下偏振成像探测方法[4]Fig.14 Passive under water polarization imaging detection method in neritic area[4]
被动水下偏振成像技术主要应用于有自然光照射的水下环境,如浅海环境。在水体较为浑浊的情况下,一般只考虑水下场景的前向散射光分量和后向散射光分量,当自然光源难以满足成像要求时,仍需要人造光源进行补光。
3.3.3 水下主动偏振成像技术
水下主动偏振成像技术采用主动式宽波段偏振光源对水下场景进行照明,光源发出的光波经过水体衰减和吸收后,由完全偏振光变成部分偏振光,通常用于照明不足的深海环境。水下主动偏振成像模型由TREIBITZ T[68]在2009年提出,可用式(15)和(16)表示。

式中,为目标信息光,̂为背景散射光,pscat为背景散射光的偏振度,pobj为目标信息光的偏振度,Imin为获得的具有最小可见后向散射的图像,Imax为具有最大可见散射的图像。有别于水下被动成像忽略目标信息光的偏振度,水下主动成像由于目标信息光的偏振特性在水下更为明显,因而不可忽略目标信息光的偏振度。韩平丽等[61]针对水下光学成像忽略前向散射光导致探测能力下降的问题,提出利用图像刃边法估计前向散射光的退化函数,建立后向散射光偏振估计模型去除后向散射光,并采用逆卷积恢复清晰场景图像,结果如图15。

图15 水下不同物体的恢复结果[61]Fig.15 Recovery results of different underwater objects[61]
封斐等[69]在SCHECHNER Y Y[65]的模型基础上,提出对后向散射光偏振度进行全局估计的偏振成像复原算法,表示为
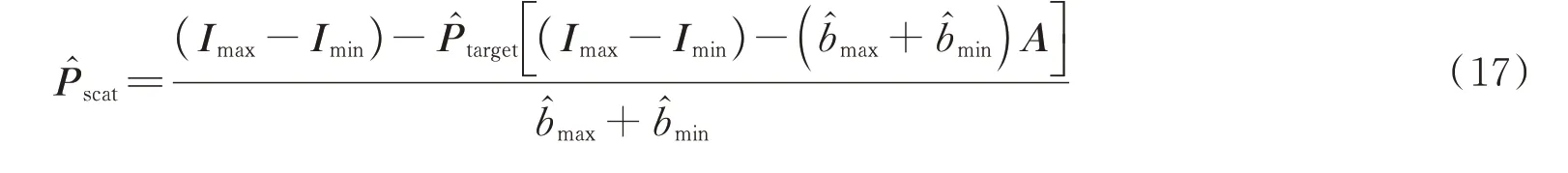
式中,̂scat为背景散射光偏振度的估计,和分别为后向散射光亮度最亮和最暗图的估计,P̂target为目标散射光偏振度,Imax和Imin为成像系统获取的最亮和最暗的正交图像。该方法以单一值代替整个像面信号光的偏振度,对传统水下偏振成像技术对背景散射光的估计误差有一定修正,能有效复原水下高偏振度物体;WEI Y等[70]提出考虑空间变化偏振特性的偏振散射成像方法,认为从目标反射的光对每个像素有自己的偏振度(Degree of Polarization,DOP)和偏振角(Angle of Polarization,AOP),根据偏振子图像中后向散射光强度的变化特性,计算后向散射光全偏振部分的强度信息,可以准确估计目标信息,恢复的结果如图16所示。

图16 水下不同物体的恢复结果[70]Fig.16 Recovery results of different underwater objects[70]
水下主动偏振成像技术引入目标对入射偏振光的影响,利用目标与背景对入射偏振光的退偏作用差异对两者进行分离,复原图像质量优于水下被动偏振成像,但对同时包含高低偏振度物体的情况复原结果较差,且相关性分离对算法的鲁棒性提出较高要求。
3.3.4 基于深度学习的水下偏振成像
深度学习能够从数据集中提取物体的底层特征,转换为高层语义特征并进行学习,最后对新输入数据进行处理。偏振具有明显的特征标志[62],可与深度学习技术进行深度结合。基于深度学习的水下偏振成像方法利用神经网络对偏振设备获取的偏振图像进行恢复。例如,LI X等[71]设计了一种残差稠密网络(PDRDN)对强噪声背景下的水下偏振图像进行去噪处理,结果如图17(a)所示;HU H[72]等利用模拟图像对密集连接网络进行训练,并对0°,45°和90°的偏振图像及光强图像进行恢复,结果如图17(b)所示,基于偏振信息的图像恢复效果优于仅基于强度信息的图像恢复效果。

图17 神经网络用于水下偏振图像恢复Fig.17 Neural network for polarimetric underwater image recovery
ZHANG R等[73]在密集U-Net的基础上,提出四套不同结构的网络模型,如图18所示,将偏振信息流和灰度信息流在网络中不同位置进行汇合,用于水下偏振图像的恢复,并与未结合偏振信息的网络模型进行对比,恢复结果见图19。结果表明,在混浊水体下,结构合理的神经网络模型中加入偏振信息可以获得更好的恢复效果,同时,将灰度图像和偏振图像放在神经网络的最前端有利于图像恢复。
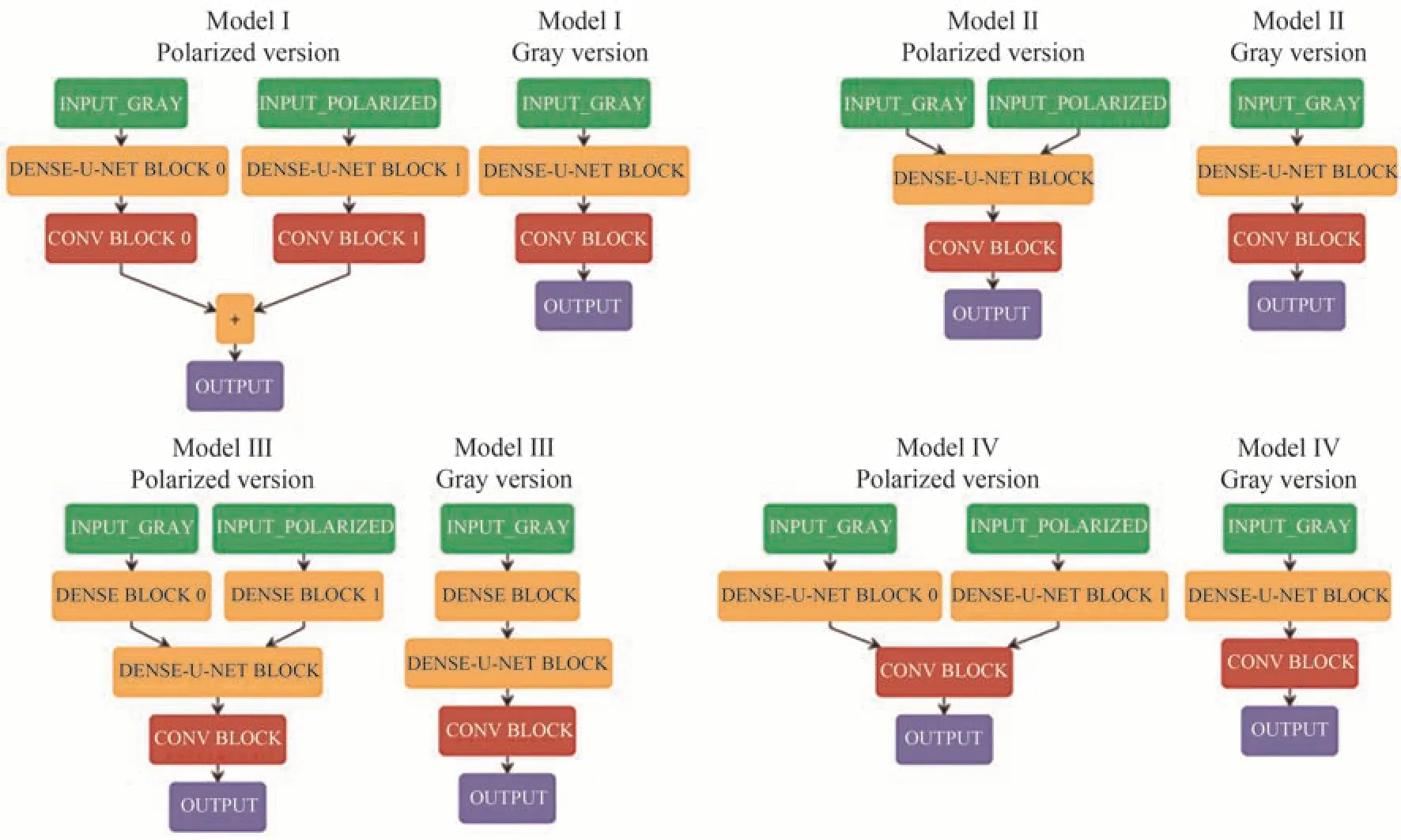
图18 四种偏振-光强信息汇合模型及其对照模型结构[73]Fig.18 Four kinds of polarization-intensity information confluence models and its comparative versions[73]

图19 原始图像及八种模型恢复结果对比[73]Fig.19 Comparison between raw images and restoration results of eight models[73]
传统水下偏振成像方法利用物体和水体背景的偏振差异来滤除背景散射噪声,在实际应用中取得了一定效果,且方法简单,容易实施。但也存在偏振差分成像模型过于简单,需要手动选取背景区域等诸多不足;被动偏振成像中,Schechner模型不适于高浓度散射环境,且需要均匀环境光场条件,在实际情况中较难应用;主动偏振成像在目标物与背景偏振度差异较小或包含多种偏振度的目标物时,复原效果有限。总体上,在传统偏振成像恢复图像研究中,只使用了少量偏振图像,模型复杂度较低,无法利用多张偏振图像所包含的信息,且大多偏振方法集中于去散射,而在提升图像质量方面缺少合适的理论模型。而神经网络凭借其优良的拟合能力可从多张图像中充分提取信息,逼近各种复杂函数,并对图像去噪之外的其它方面进行处理,能一定程度上弥补水下偏振成像的不足。但同时,深度学习方法在理论可解释性方面以及对数据集的要求方面等使其仍然处于探索阶段,需要进一步研究该方法在复杂偏振度环境下的应用。三种水下偏振成像方法与基于深度学习方法的总结如表3所示。

表3 水下偏振成像方法与基于深度学习的方法总结Table 3 Summary of underwater polarization imaging methods and deep learning-based methods
3.4 水下关联成像技术
关联成像,又称鬼成像(Ghost Imaging,GI),是近年来发展起来的一种新型成像技术,通过计算光场的二阶或者高阶关联函数来获取待测物的图像信息[74],原理如图20所示。其成像过程为:激光器发出的激光经过光源调制器后生成散斑光场,通过分束器分成探测光路和参考光路,探测光经过探测物体后被桶探测器接收,参考光不经过物体直接被电荷耦合器件(Charge-Coupled Device,CCD)接收,通过对CCD和桶探测器采集的信息使用关联算法解算可重构出目标图像。从光学理论上可得出,当探测光路和参考光路长度相等时,重构出的待测物图像效果最好[75]。

图20 关联成像原理示意图Fig.20 Schematic diagram of ghost imaging
早期的关联成像需要依靠纠缠光源才能实现,而BENNINK R S[76]等提出的赝热光源鬼成像方法证明了鬼成像采用经典光源也能实现,扩大了鬼成像的应用范围;SHAPIRO J H[77]等提出的计算鬼成像(Computational Ghost Imaging,CGI)去掉了参考光路,采用空间光调制器(Spatial Light Modulator,SLM)或数字微镜设备(Digital Mirco-Mirror Device,DMD)来获得可控的赝热光场,仅需一路光路即可完成关联操作,虽然无参考光路,但仍具有良好的成像能力,结构如图21所示。
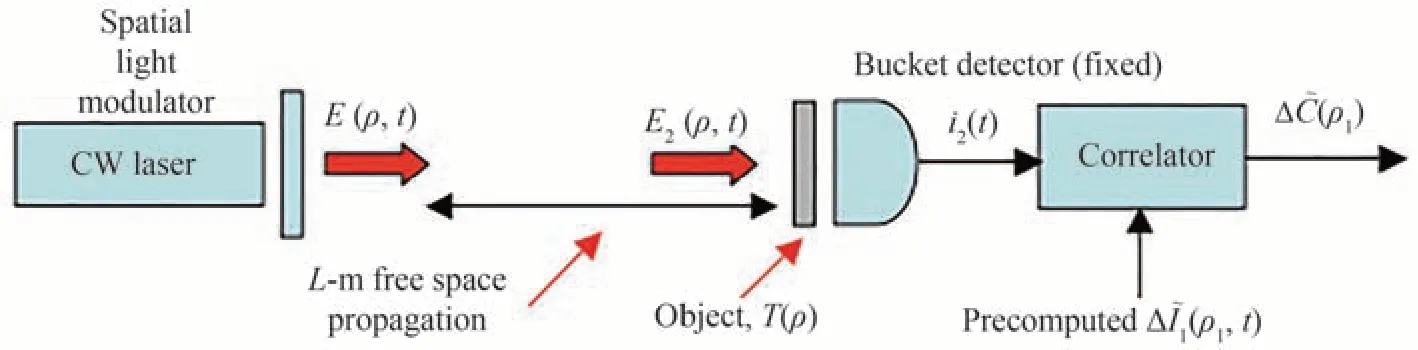
图21 计算鬼成像系统结构[77]Fig.21 Structure of CGI[77]
近年来,CGI在陆上图像中的优异表现使其在水下成像领域也受到广泛应用,LE M等[78]将CGI应用于不同角度和不同浑浊度的水下环境,相较于传统光学成像,水下CGI有更宽、更大范围的视角,即使在较大的成像角度下也能进行无失真重建。此外,传统成像方法在水下环境中成像质量明显下降,而水下CGI在足够高的采样帧数的条件下,仍能获得目标图像,表明水下CGI在较为极端的情况下仍是一种较好的成像方案。FERRI F等[79]针对CGI成像质量较差的问题提出差分鬼成像(Differential Ghost Imaging,DGI),利用测到的差分信息来消除成像过程中引入的环境噪声,可以显著提高信噪比;ZHANG Y[80]等利用不同透射率的目标,对比研究了水下传统鬼成像(Traditional Ghost Imaging,TGI)和水下CGI图像重建的效果。结果表明,在相同的实验条件下,DGI算法可以获得比TGI更清晰的目标图像,随着测量数量的增加,DGI成像结果的清晰度可以进一步提高,但TGI却没有显著改善。此外,对于高透光率目标,DPI恢复的图像比TGI恢复的图像质量更高,但在物体透光率低的情况下,桶形探测器收集的强度降低造成两者的差异性减弱。
为了获得清晰的重建图像,鬼成像通常需要进行多次采样,且只有当采样数据量达到一定条件后才能获得清晰的目标图像。但大量数据的采集和存储需要耗费巨量时间,影响这一技术的实时性[74]。KATZ O等[81]针对该问题提出基于压缩感知(Compressive Sensing,CS)的鬼成像方法(Compressive Ghost Imaging,CSGI),不仅比TGI缩短一个数量级的信息采集时间,还能显著提高重建图像信噪比;ZHANG Y等[82]将CSGI和DGI用于低照度环境下的水下成像实验,在相同数量的采样条件下,CSGI可进一步提高图像质量;WANG T等[83]提出一种基于CS和小波增强的哈达玛水下鬼成像方法,建立基于全变分正则化先验的CSGI模型,然后在亚奈奎斯特采样率下获得二值和灰度目标的高质量图像,并采用增广拉格朗日乘子算法恢复目标图像。
CSGI虽然利用稀疏特性在低采样情况下能够重构目标图像,但同时增加了图像算法的计算资源和时间复杂度,无法满足图像实时重建要求。虽然CSGI在一定程度上可达到降采样目的,但要获得高质量重建图像仍需要大量测量数据[84]。近年来,深度学习逐渐被用于鬼成像以解决上述问题。LYU M等[85]提出基于深度学习的鬼成像(Ghost Imaging using Deep Learning,GIDL),利用传统GI重建的一组图像和相应的地面实物图训练深度神经网络学习感知模型,证明GIDL相比CSGI有更快的采样速度,更好的成像质量,以及极低采样率下更好的重建结果;WANG F等[86]利用神经网络直接从桶型检测器记录的总反射光强度重建目标图像,在低采样率下可比传统GI和CSGI有更高的重建效率,所需的数据量更少;LI F Q等[87]提出的基于深度学习的偏振鬼成像方法可在1ms内重建图像,即使在高散射条件下也有很好的效果,且有着比传统方法更低的采样率及更好的稳定性。由此可见,深度学习可以在一定程度上解决CSGI所面临的问题。
除加快GI采样和重建速度外,深度学习还被用于提高GI水下成像质量。WU H等[88]采用密集块和跳跃连接来替代WANG F等[86]所提出网络中的残差块,提出用DAttNet网络从一维光强序列中直接恢复目标图像,重建的水下图像质量优于CSGI方法,结果如图22所示;LI F Q[87]对比了GIDL和CSGI在不同采样率和不同散射介质浓度中的重建图像质量,证明在较高的散射体密度下,GIDL相比CSGI可以从噪声中分离出目标物,结果如图23所示。

图22 不同采样率下CSGI和GIDL的重建结果[88]Fig.22 Reconstruction results of CSGI and GIDL at different sampling rates[88]
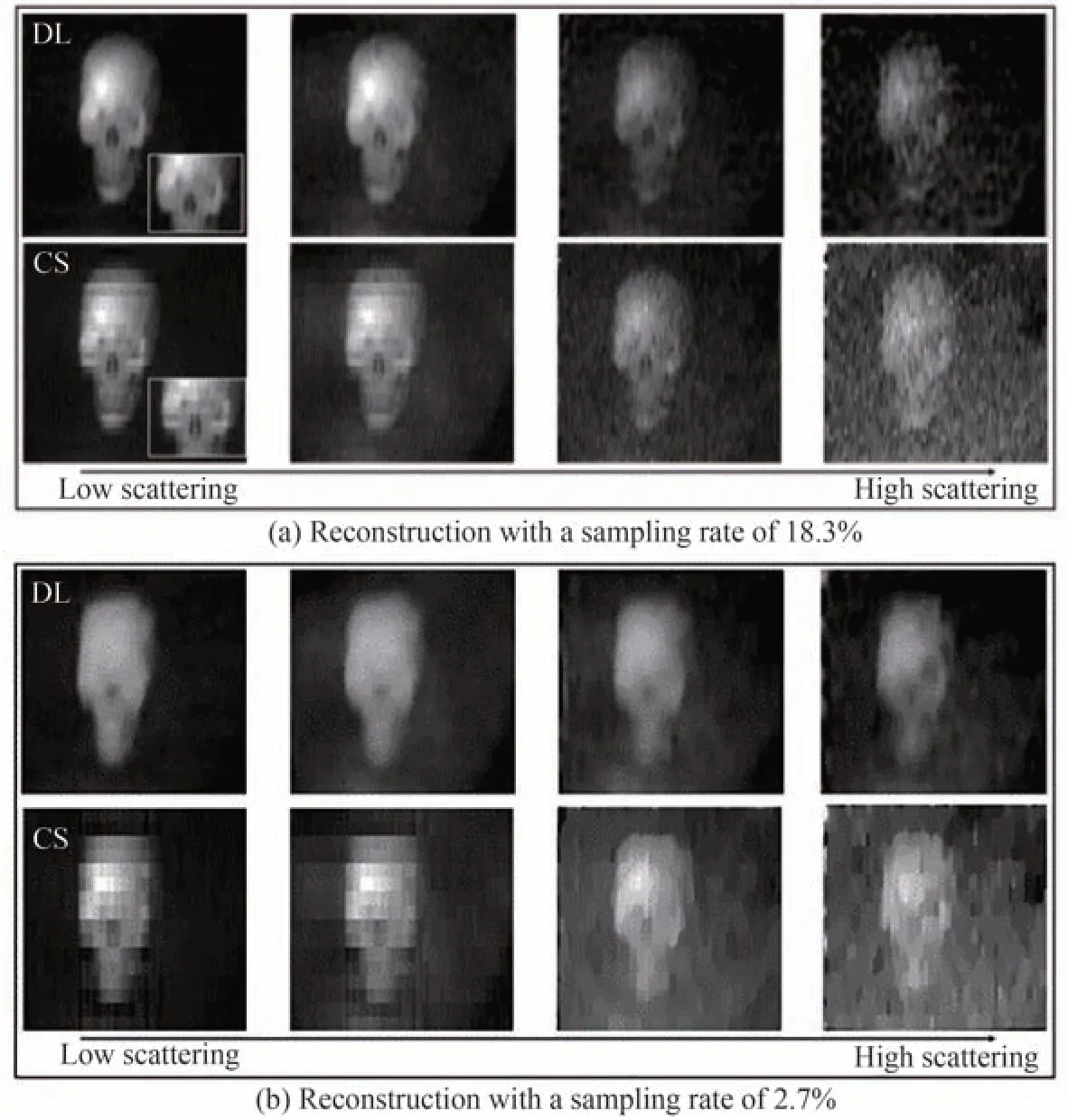
图23 不同浓度下的基于深度学习和基于压缩感知重建结果[87]Fig.23 Reconstruction results based on DL and CS methods at different concentrations[87]
YANG X等[84]提出基于GAN的鬼成像(UGIGAN),用于对桶探测器收集的反射光强进行水下图 像 重 建,并 与DLGI和PDLGI[86]的 重 建 结 果 进 行了对比,证明UGI-GAN可进一步提升图像质量,重建结果边缘轮廓相对清晰,目标细节视觉效果较好,同时对水下模糊和光强较低的情形有更好的稳定性,能实现高质量图像重构,结果如图24所示。
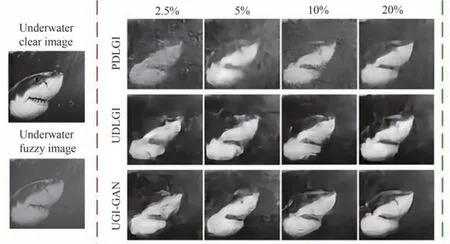
图24 比较UGI-GAN、UDLGI和PDLGI在不同采样率(2.5%,5%,10%,20%)下的仿真结果[84]Fig.24 Comparison of simulation results of UGI-GAN,UDLGI,and PDLGI at different sampling rates[84]
鬼成像利用光场的二阶相干性进行成像,具有穿透散射介质和抗湍流干扰的能力,有着良好应用前景,但其过于庞大的信号采集量和计算量,使其成像速度远不如传统成像,在实际应用上受限。在此基础上,标准正交模式、CGI被提出用于提高信噪比,CSGI用于降低采样率,加快成像速度,但CS技术本身需要大量的计算、时间复杂度依然较高。为此,深度学习可凭借其强大的非线性拟合能力建立从桶探测器到复原图像的直接映射,将重建过程交予神经网络完成,避免了CS重建过程的复杂计算,可提高重建效率。实验表明,深度学习方法可重建更低采样率下的图像,并且在相同采样率下有着更高的成像质量,因而相对传统方法具有更大优势。不同鬼成像方法成像特点如表4所示。

表4 不同鬼成像方法与基于深度学习的方法总结Table 4 Summary of different ghost imaging methods and methods based on deep learning
在未来,对网络进行进一步轻量化探索并使之与CGI、DGI等结合以提高效率并提升图像质量将成为重要的发展方向之一。
3.5 水下光谱成像技术
光谱成像技术是一类将成像技术与光谱技术结合的多维信息获取技术,通过成像光谱仪在电磁波谱的可见光、近红外和红外等波段区域获取研究对象的多个二维空间图像信息和一维光谱信息,构成三维数据立方体,经过处理能够获得目标物的空间、辐射、光谱信息,如图25。与几何成像仪相比,光谱成像仪在获得目标形态图像的同时,还能够得到空间可分辨单元的光谱特征[89]。
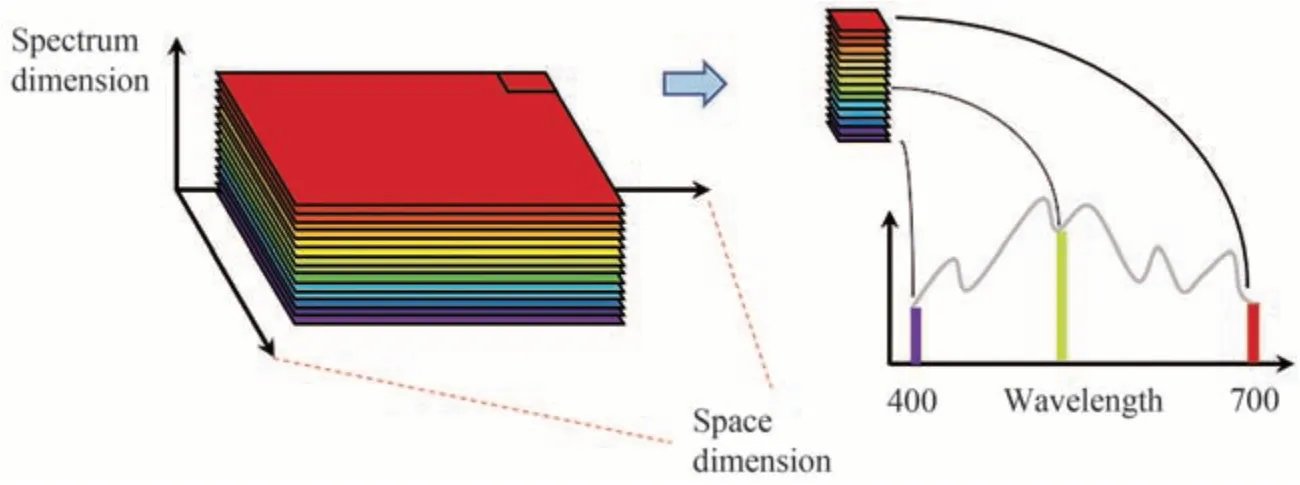
图25 高光谱图像数据立方体Fig.25 Hyperspectral image data cube
根据分辨率的不同,可将光谱技术分为多光谱技术(Multispectral,MS)和高光谱技术(Hyperspectral,HS)[90]。其中多光谱技术在电磁波谱的紫外、可见光和近红外部分使用10~20个波段,光谱分辨率大于5 nm。高光谱基于相同原理,使用数百个波段,比多光谱有更高的光谱分辨率,可提供具有1 nm光谱分辨率的波长[91]。虽然多光谱技术的光谱分辨率不如高光谱技术,但多光谱技术有更高的空间分辨率[92]。根据采集图像的方式不同,光谱成像技术又可以分为摆扫式、推扫式与凝视式[89]。摆扫式光谱成像仪中,采用线性排列的光电探测器探测某一瞬时视场内目标点的光谱分布,同时采用扫瞄镜对目标表面进行横向扫描,纵向扫描则依靠运载成像仪的载具进行机械运动来完成。推扫视光谱成像仪利用面阵探测器同时记录目标上排成一行的多个相邻像元的光谱,面阵探测器的一个维度用于记录目标的空间信息,另一维度用于记录目标的光谱信息,空间第二维可由载具移动来实现。在凝视式光谱成像中,通常采用单色器或者点调谐滤波器实现光谱通道的切换,利用探测器采集不同光谱通道的图像,实现图像信息和光谱信息的获取。
在水下光谱成像技术的应用上,挪威科技大学与Ecotone公司合作研制了一台水下高光谱成像装置(UHI),并将其搭载在三脚架、水下推车和移动平台上对海底进行高光谱探测[93];2013年,JOHNSEN G等[94]利用其在欧洲北部海域和大西洋海域等地区进行了海底生物相关的光谱测绘,并对太平洋深处海洋沉积物进行了光谱成像;2016年,该机构首次将UHI搭载在水下机器人(Autonomous Underwater Vehicle,AUV)上进 行 实 地 探 测[91];2017年,CHENNU A等[95]开 发 了 一 种 潜 水 员 可 操 作 的 水 下 高 光 谱 成 像 探 测 系 统(HyperDiver)(图26),使用彩色相机替换了原有的灰度相机[96],用于获取海底生物及地形剖面的高分辨率的彩色和高光谱图像,结果如图27所示;2017年,FOGLINI F等[97]使用UHI进行水下光谱成像探测,探测后将探测结果应用光谱角(Spectral Angle Mapping,SAM)监督分类方法进行分类,结果如图28所示。

图26 HyperDiver水下高光谱成像探测系统及组成[95]Fig.26 HyperDiver UHI system and its components[95]

图27 HyperDiver获取的海洋高光谱数据图像[95]Fig.27 A multi-faced dataset from HyperDiver[95]
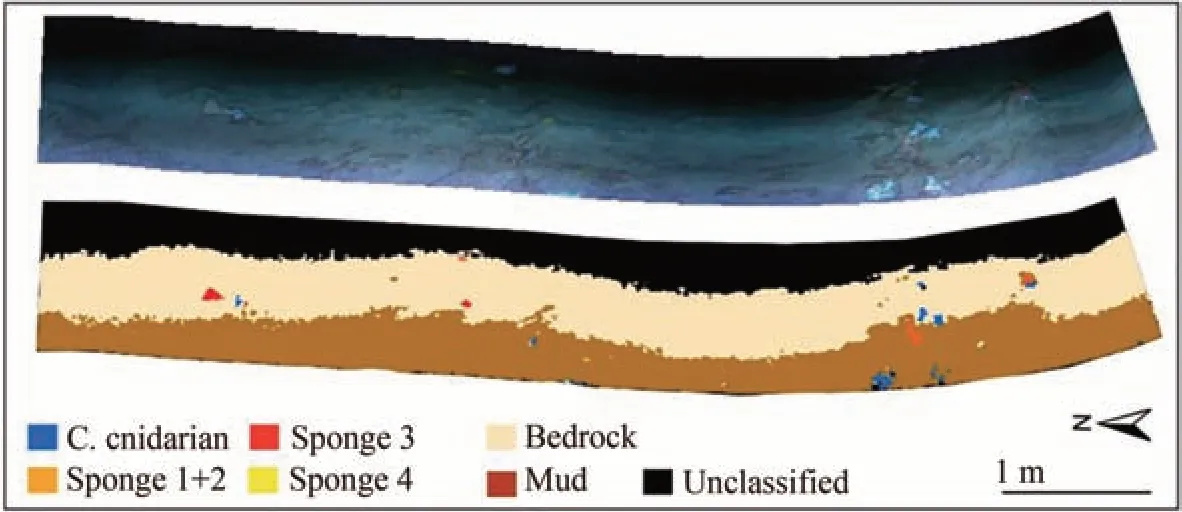
图28 UHI探测获得的海底彩色图像及SAM分类结果[97]Fig.28 Color image of the seabed from UHI and SAM classification[97]
在国内,魏贺等[89]研制了一套基于轮转滤光片的水下光谱成像系统,将31个半高全宽为10 nm的窄带滤光片安装在两个滤光轮上,两个滤光轮独立运行,成像时,将不同滤光片切换到成像光路上,以实现不同波段的光谱图像,如图29(a)所示。通过使用基于色彩恢复的多尺度Retinex图像增强算法对获取的不同窄带波段的图像进行增强,最后进行彩色合成并计算信息熵,结果如图29(b)所示,与空气中的图像对比结果表明,该方法可以明显提高水下图像的色彩还原效果。
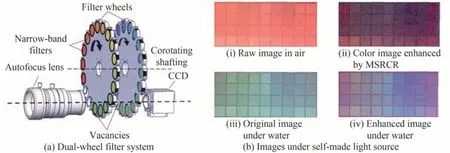
图29 基于轮转滤光片的水下光谱成像技术[89]Fig.29 Underwater spectral imaging with filterwheel[89]
LIU H B等[98]设计了一款基于多色照明的多光谱成像系统(TuLUMIS),如图30(a)所示,利用可调谐的LED作为光源在400~700 nm波段获取8个波长段,用于不同波段的成像,通过辩色实验证明了该系统具有优于传统RGB相机的辩色能力,将其用于远洋动物的MSI原位观测获得了较好结果,如图30(b)。

图30 基于多色照明的多光谱成像系统[98]Fig.30 A tunable LED-based underwater multispectral imaging system[98]
郭乙陆等[99]设计了一套凝视型光谱成像仪及配套的水下光源与水下激光测距系统,同时提出了包含光谱图像预处理算法的水下光谱图像重建算法,实现了清水10 m以内400~700 nm波段的光谱成像及测距;FU X等[100]提出约束目标最佳折射率(Optimal Index Factor,OIF)的波段选择(CTOIFBS)方法,以选择感兴趣目标的波段子集,构建了集成最佳波段子集的凝视型水下光谱成像系统,如图31(a),并使用约束能量最小化(Constrained Energy Minimization,CEM)目标检测算法检测海底海参,结果如图31(b)所示。

图31 集成最佳波段子集的凝视型水下光谱成像系统[100]Fig.31 Staring underwater spectral imaging system with optimal waveband subset[100]
光谱成像获取的数据立方体可通过与目标物体的先验光谱信息进行匹配,对水下物体进行识别,或通过水体吸收、散射等光谱分辨特性变化对水体进行建模,探测成像距离等[101-102]。但要实现目标物的精确定位和分类识别,仍需要清晰的水下图像,一般采用图像融合方法,将获取的具有高空间分辨率的多光谱图像(High-Resolution Multispectral,HRMS)和具有低空间分辨率的高光谱图像(Low-Resolution Hyperspectral,LRHS)进行融合,获得既具有高光谱分辨率又具有高空间分辨率的图像[103]。LRHS和HRMS图像融合大致可以分为两类:传统融合方法与基于深度学习的融合方法。传统融合方法又可分为矩阵分解的方法和基于张量表示的方法[104]。其中,矩阵分解基于高光谱解混技术,主要包括端元谱的提取和丰度图的计算两个步骤,端元谱提取是将非负的高光谱数据矩阵分解为两个非负的矩阵,可在不进行纯像元假设的情况下,识别出光谱的端元,同时估计出相应的丰度,将端元矩阵和丰度矩阵相乘后得到高分辨率的融合结果。ZHANG Y等[105]根据YOKOYA N等[106]提出的基于耦合非负矩阵分解(CNMF)的图像融合算法,提出利用最小端元单纯形体积和丰度稀疏约束的CNMF对HS和MS图像进行耦合解混,融合图像由HS图像解混得到的端元特征矩阵和MS图像解混得到的分数丰度矩阵相乘得到。基于张量表示的方法将HS看成一个三维张量,通过稀疏Tucker分解将HS分解为三维核心张量及二维三模态字典,随后将高空间分辨率的高光谱图像分割成若干块,对其进行聚类,分成相应的图像块集合,并通过张量稀疏编码从集合中提取核心张量,最后将核心张量与二维三模态字典相乘得到融合图像[92]。基于深度学习的融合方法利用神经网络在非线性关系表示和高层次图像特征提取的优势,来简化图像融合过程,如CNN无需单独的图像变换和融合规则即可进行图像融合[107]。近年来提出了许多基于DL的光谱图像融合方法,PALSSON F[108]等提出利用三维卷积神经网络(3D-CNN)融合HS和MS得到高分辨率高光谱图像的方法,通过将网络中的卷积核等模块扩展至三维来获取三维光谱特征,并在融合前利用主成分分析(Principal Components Analysis,PCA)对HS图像进行降维以减少计算时间,在模拟数据集上实验的结果证明该方法具有较好的融合和抗噪效果;Yang等[109]提出了一种包含融合单元和空间注意单元的空间深度注意网络(DAN),利用HRMS图像提供低层次特征和网络解码结构提取高层次特征,经过空间注意网络对高频特征进行滤波后,添加到融合单元中得到重构的HRHS图像,重建图像具有较高的空间质量和光谱质量;GAO J等[110]提出自监督的HS和MS图像融合的网络,结构和信息流如图32所示,该网络将LRHS(X)与HRMS(Y)图像通过格拉姆-施密特变换(GSA)获得的伪HRHS图像(ZT)作为输入,经过神经网络获得初始输出(Z),然后在Z与上采样LRHS图像(X↑)之间构造优化项(18)约束谱精度,在Z与ZT之间构造另一优化项(19)约束空间精度,通过使用两个优化项优化网络参数,获得具有高空间和高光谱精度的图像。
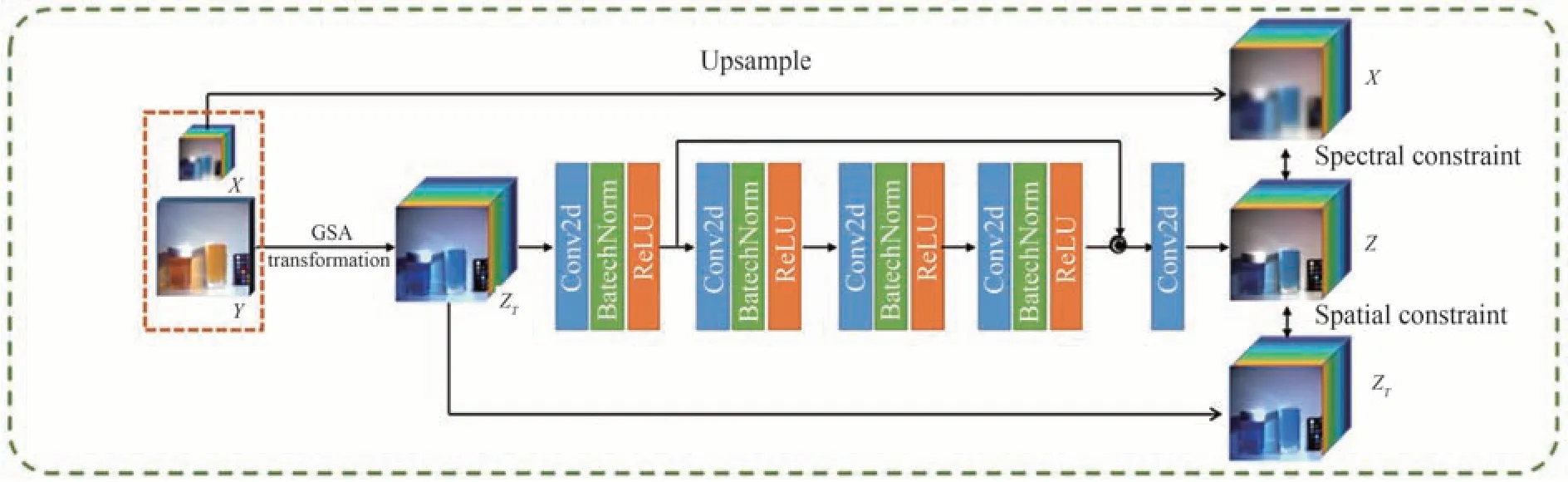
图32 自监督光谱图像融合网络[110]Fig.32 Self-supervised hyperspectral and multispectral image fusion network[110]

式中,↓n代表下采样,↑n代表上采样。
光谱成像获取研究对象二维空间图像信息和一维光谱信息,并依此来获得目标物的空间、辐射、光谱特性,对目标进行识别分类等。在水下光谱数据的获取上,可通过棱镜、光栅、滤光片等结构获得不同光谱波段的图像,其中最简单常用的结构为滤光片,但获取的光谱波段数有限,可使用可调滤波器获得全光谱图像。在水下光谱数据的使用上,可使用物体先验光谱信息进行目标识别,或对环境光谱信息对水体物理特性进行建模,而将图像融合获取高光谱及高分辨率的图像具有清晰直观的优点。在众多融合方法中,基于深度学习的光谱融合方法相较于传统的矩阵分解和张量方法具有无需迭代、快速、鲁棒性好等优点,但其也存在如需要大量数据对网络进行训练,在数据的光谱频带数、空间分辨率和光谱覆盖率不同时,一种数据上训练得到的神经网络无法泛化到其它类型数据等缺点,因而还有待继续发展。此外,光谱融合在水下图像上的应用研究还较少,具有广阔的发展前景。传统MS和HS融合方法与基于深度学习的方法总结如表5所示。
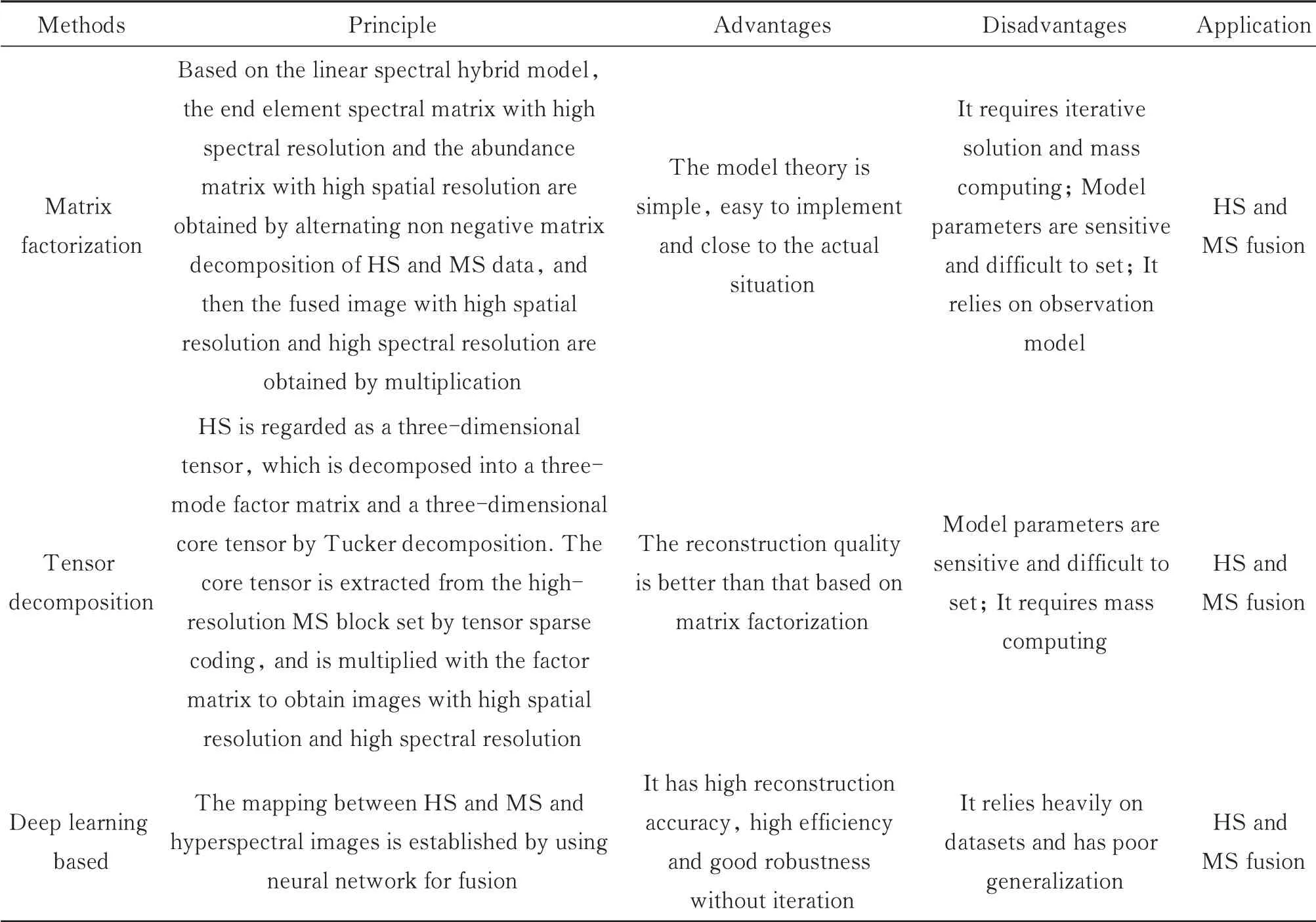
表5 传统MS和HS融合方法与基于深度学习的方法总结Table 5 Summary of traditional MS and HS fusion fusion method and deep learning-based method
3.6 水下压缩感知成像技术
压缩感知理论(Compressed Sensing,CS)是研究人员针对传统信号采集时大量获取数据,而在随后的信号处理过程中,为降低硬件压力,通过数据变换和压缩抛弃大量数据的矛盾行为提出的一种新的采样方式,由DONOHO D L等[111]于2006年提出,它指出在信号本身是可压缩的,或在某个变换域下表现出稀疏性时,将变换得到的高维信号投影到低维空间上只需要用一个与变换基不相关的测量矩阵即可,随后求解一个优化问题就能重构出原始目标信号。与传统的需要采样率大于两倍信号带宽的奈奎斯特采样定理不同,压缩感知理论采样速率仅由信息的结构和内容来决定[112],并且可在远低于奈奎斯特采样率的情况下,将信号的采样过程和压缩过程同步完成,在采样的过程中即完成信号中所含信息的提取,包括信号的稀疏表示,测量矩阵构造和信号重构算法三个部分[111-113]。
在压缩感知的应用层面,最受关注的是基于该理论的而研制的单像素成像系统(Single-PixelImaging,SPI),不同于使用数百万个像素传感器的CCD或CMOS像素化传感器相机,该成像系统仅使用一个光子探测器对图像进行少于像素点的测量,并恢复出原始图像。2008年,美国莱斯大学开发出世界上第一台单像素相机[114],系统原理图见图33。工作时,图像经过透镜照射在DMD上,将图像与DMD掩膜的乘积反射给单点传感器,传感器将数值转换为数字信号传送到PC进行图像恢复。在SPI中,存在有DMD放置在物体前的结构光检测和DMD放置在物体后的结构化照明方式,如图34[115],但两者是等效的[116-117]。而在水下成像中,由于需要克服复杂的水体环境,通常采用结构化照明的方式。
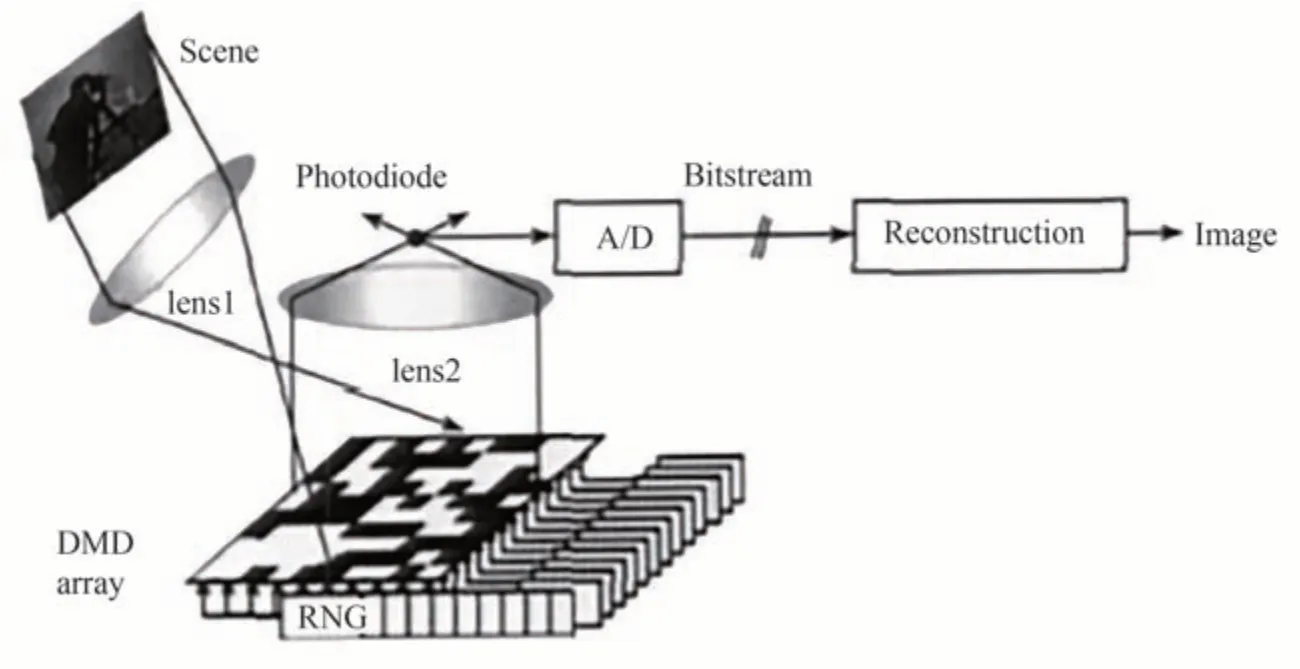
图33 单像素相机结构图[115]Fig.33 The structure of single pixel camera[115]
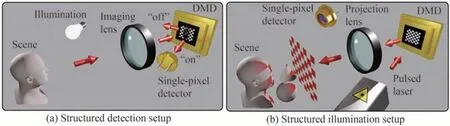
图34 单像素成像系统[116]Fig.34 Single-pixel imaging system[116]
SPI系统中,核心元件是用于调制图像的空间光调制器数字微镜阵列(DMD),不同的调制图像影响着单像素成像的质量和效率[118]。早期SPI使用随机图案对照明光场进行强度调制,并将其与单像素相机获取的探测值进行相关运算,重建出物体图像。但这种方式需要进行远多于重建图像像素数的采样次数,才可恢复出质量较好的图像,若采样次数较少,则恢复的图像质量较差。近年来提出了确定掩膜的单像素成像技术,可解决恢复图像质量差的问题[119],如离散余弦变换单像素成像[120]、小波变换单像素成像[121]、Hadamard单像素成像(Hadamard Single-PixelImaging,HSI)[122]和傅里叶单像素成像(Fourier Single-Pixel Imaging,FSI)[123]等,它们均采用完备的正交变换基底图案进行空间光调制,可以很好地恢复物体图像。此外,自然图像在一些变换域,如Hadamard域、傅里叶域、离散余弦域、小波域等具有良好的稀疏性[119],可通过选取变换域中较大的系数,以低采样率的方式重建出高质量的图像,解决采样和重构时间长的问题。其中,HSI和FSI为应用较多的经典SPI技术。HSI使用Hadamard基掩膜调制光场,获取目标图像的Hadamard谱,并通过应用逆Hadamard变换重建目标图像。吕沛等[124]构建了水下压缩感知单像素相机系统框架结构,将Hadamard矩阵随机列变换生成的矩阵用作采样矩阵,使用凸集交替投影法重构算法进行图像重构,结果表明,该系统能适应水下环境,比传统SPI系统有更好的成像距离及更短的采样时间;CHEN Q等[125]提出基于CS的水下SPI系统(CS-basedSingle-PixelImaging,CSSI),将8×8的随机矩阵和Hadamard矩阵用作掩膜,采用CS方法重构不同分辨率的二维物体,实验结果表明,CSSI能有效减少采样次数,加快数据获取过程,相较于随机矩阵,Hadamard矩阵在物体重构上具有更显著的效果,还可有效减弱水体浑浊的影响;YANG X[126]等对比了CSSI,HSI及FSI在浑浊水体下的成像效果,结果表明HSI在高混浊水体的分辨率和抗干扰能力方面优于其他SPI模式和传统成像技术,最高可在90NTU的情况下清晰观测水下物体。
FSI基于傅里叶分析理论,利用傅里叶基底图案调制空间光场,根据单像素探测器获取的光强值计算出物体图像的傅里叶变换谱,最后通过逆傅里叶变换重构出物体图像。FSI在成像中有较多应用[127-128],但水下单像素傅里叶成像尚未得到深入研究,水体散射效应对水下FSI成像质量的影响也较为缺乏。YANG X等[129]针对水体前向散射导致传统SPI散斑图分布产生畸变的问题,提出基于水退化函数补偿的水下FSI系统,与传统SPI系统不同,该系统根据测量到的目标空间谱位置设计正弦结构图,并将其作为散斑图照射目标,根据系统接收的的空间频谱,拟合水降解函数,反求目标的真实空间频谱分布,最后利用傅里叶反变换,重构出目标的图像,如图35所示,结果表明,水下FSI相对传统FSI有更好的抗水体正向散射能力和较高的空间分辨率。

图35 传统FSI重构结果与FSPI恢复结果[129]Fig.35 Reconstruction results by traditional FSI and FSPI[129]
FSI有较高的成像质量和成像效率,但FSI在重建图像时通常采用从低频到高频的采集策略,容易出现高频细节丢失,图像含有振铃伪影(RingArtifact)等问题[130]。此外SPI存在测量时间与重建图像质量之间的权衡问题,为了获得完美重建需要重建图像像素1.5~2倍的测量次数,花费较多测量时间,若通过欠采样的方式重建图像,会导致图像模糊和环形伪影,针对这些问题,传统方法要做出实质性改进较为困难。对此,研究者们将深度学习在图像恢复中的优势应用到SPI中,RIZVI S等[131]改进深度卷积自动编码器网络[132]并利用其学习欠采样图像和地面真实图像之间的端到端映射,实现低采样率下的图像重建,提高效率的同时,还去除了FSI重建带有的噪声和伪影,优于传统FSI方法;HU Y等[130]针对FSI丢失高频细节的问题,提出基于Wasserstein生成对抗网络(WGAN)和梯度惩罚(GP)的快速图像重建网络(GAN-FSI),在生成对抗网络的基础上,连接额外的生成器以提高重建图像的保真度,仿真和实验结果如图36所示,在低采样率的情况下,GAN-FSI仍能很好地恢复图像,并保有相当细节。

图36 GAN-FSI与FSI在不同采样率下的重建结果[130]Fig.36 Reconstruction results of GAN-FSI and FSI at different sampling rates[130]
上述重建方法以欠采样的图像作为网络输入,获得重构图像,而在实际应用中,还有以照明图案序列和采集的单像素强度信号作为输入,重建出目标图案的方法。WANG F等[85]提出端到端的神经网络(EENet),用于将单像素传感器采集的一维强度信号直接恢复为二维图像,经模拟数据训练后,可在6.25%的采样率下重建高质量的图像;LI M等[133]提出结合改进的超分辨卷积神经网络(SRCNN)[134]的水下SPI系统(CS-SRCNN),如图37所示,该网络以来自SPI系统的m维压缩原始数据作为输入,经TV正则化迭代处理后获取低分辨率分量(Low Resolution,LR),通过双三次插值对LR分量进行放大,随后经过卷积层提取LR特征,最后通过5×5的卷积层进行特征传递,重建高分辨率特征图像(High Resolution,HR),经过训练可在60NTU浊度的情况下,以29%的采样率重构图像,但重构的图像仍存在模糊的问题。
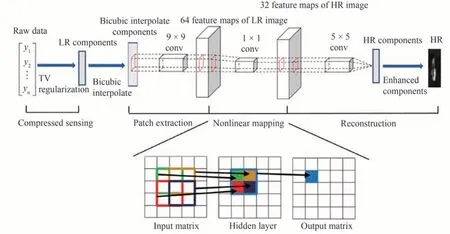
图37 CS-SRCNN网络结构[133]Fig.37 CS-SRCNN network structure[133]
目前,受水体复杂环境的影响,SPI在水下环境中的应用以及与深度学习结合的水下SPI成像方法仍然较少。而在现有深度学习与SPI结合的方法中,由于一维的单像素强度信号中蕴含重建目标图像所需的信息,所以目前主流方法多采用深度学习直接对一维SPI强度信号进行解析,重建图像。但该方法从一维信号重建二维图像是线性过程,采用神经网络容易出现过拟合现象,且神经网络存在的适应性和鲁棒性问题也会对最终结果造成较大影响,此外深度学习方法还存在需要大量数据集,训练时间长的问题。对此,黄威等[135]研究发现,通过简单的线性回归结合压缩感知的方法完全可以重建高质量目标图像,并且这一方式在训练样本不足和环境背景复杂的情况下重建的图像质量要优于深度神经网络,但在采样率过低的情况下,深度学习方法仍具有优势。因而在重建图像时,需结合实际情况,采取合适的重建方法,以获得最优的重建结果。不同SPI重建方法与基于深度学习的方法总结如表6所示。
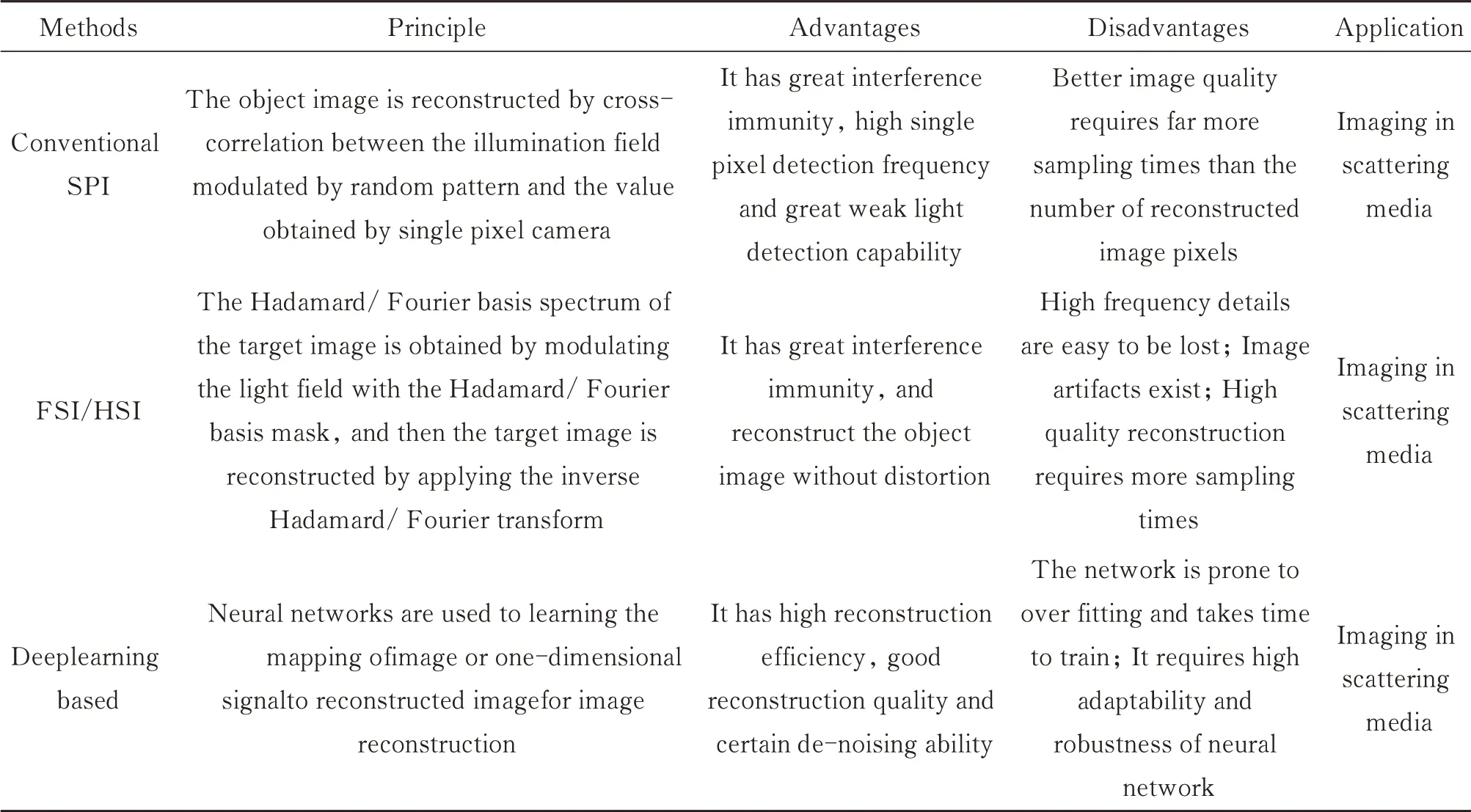
表6 不同SPI重建方法与基于深度学习的方法总结Table 6 Summary of different SPI reconstruction methods and methods based on deep learning
3.7 水下激光成像技术
传统水下成像方式采用高灵敏度的相机在水下自然光或人造光源下进行拍摄或录像,这种方式应用简单且发展成熟,但受限于水体对光波的严重吸收和散射,获取的图像大多对比度低、清晰度不足,且对于浑浊水体,成像距离也大大受限,因此具有高能量、短脉冲且强方向性的激光光源备受关注,加之470 nm~580 nm波长的蓝绿激光在水中传输时衰减较其它波段小很多[136],因而基于蓝绿激光的水下激光成像技术逐渐兴起并日益完善。水下激光成像技术利用主动激光光源对水下目标进行照明,同时用相机接收反射光并利用成像设备对目标进行成像,可获得水下目标二维乃至三维的图像。目前水下激光成像技术主要分为扫描成像技术与非扫描成像技术两大类[137]。
扫描成像技术包括激光同步线扫描技术(Laser Line Scanning,LLS)与条纹管激光成像技术(Streak Tube Imaging Lidar,STIL)。同步扫描水下成像技术利用水体后向散射光强相对于光照中心轴迅速减小的特点,将成像目标光和散射光在空间上进行分离。具体过程为:系统发射器射出准直线阵激光,通过旋转反射镜控制激光束扫描方向,并利用高灵敏度窄视场的接收器跟踪接收反射光完成成像,同时利用同步扫描技术逐点扫描完成探测与整体图像重建。早期的LLS技术采用连续激光作为光源,容易受到视场重叠区域及环境散射光引起的噪声影响,因此研究人员将探测器与激光扫描装置分开放置,减少被照明水体与接收器视场的交叠,从而减少后向散射光进入接收器,提高成像信噪比,如图38所示。此外,若将连续激光器替换为脉冲激光源,将常规接收器替换为选通型接收器,可构成激光线扫描成像系统(PG-LLS)[138],可进一步增加成像距离。MOORE K D等[139]对比了CW-LLS与PG-LLS的成像能力,结果表明当视场角为30 m rad时PG-LLS对提高成像距离与目标对比度具有明显优势。

图38 LLS结构示意图Fig.38 LLS structure
在水下成像的应用中,Kaman公司于1988年研制出机载探测激光雷达“魔灯”[140],采用线扫描蓝绿激光器与选通增强相机构成的PG-LLS成像模式,搭载在直升飞机上,用于海上120~460 m处对水下12~61 m的水雷探测工作;FOURNIER G R等[141]研发的机械同步扫描水下激光成像系统以氩离子激光器为光源,通过旋转角锥棱镜可得70°视场角;MOORE K D等[139]研制了一套名为L-Bath的激光线扫描成像系统,以Nd:YAG脉冲激光为发射器,线阵CCD为接收器,通过接收信号形成的图像信息和激光光束的发射角信息分析目标点的位置和强度,进而获得目标的强度图像和距离图像。华中科技大学研制了具有扫描和高速数据存储功能的机载海洋激光雷达系统CALYT,实现了激光单点水下扫描成像,在南海海域进行的测试表明该系统可达到60 m左右的探测水深[142-143];2009年,金伟其等[138]搭建了线激光与条纹管的LLS成像系统,进行有关波面形状获取以及校正技术的研究。
LLS将探测器与激光扫描装置分开放置,减少了视场交叠,但同时增加了系统体积,对此,KITAJIMA Y等[144]采用5线激光阵列光源和传统CMOS相机模拟LLS成像过程,利用感兴趣区域(Region-of-Interest,ROI)函数,将CMOS相机的视场均匀划分为5个子区域,由顺序触发的线性激光器同步照明,减小了光源与相机之间的共同体积。但过多的线性激光器的数量限制了去散射效果,且导致准直复杂、系统繁琐以及由ROI拼接图像引起的照明不均匀问题。此外,与LLS系统的光电倍增管或条纹管接收机相比,传统CMOS相机的灵敏度要低得多,严重限制了系统的距离探测性能。对此,WU H[145]提出激光场同步扫描(LFS),去掉了LLS的机械扫描装置,采用MEMS器件控制激光扫描过程,通过扫描过程与CMOS相机的滚动快门曝光同步的方法来减少光源与相机间的交叠体积,得到具有更高的对比度和CSNR的图像。YANG Y等[146]用RGB三激光器代替LLS的单一激光器,实现了三维数据和彩色数据的采集。
激光同步扫描成像技术通过减小视场重叠的方法来减少散射光的影响,但由于需要不断对目标进行扫描,仍无法避免传输光路上的微粒造成的散射,可以通过减小视场角的方式避免,但会造成扫描时间增加,成像效率降低。同时,在同一场景下对同一目标的成像中,成像时间与成像精度成反比,因而过长的成像时间也会造成图像精度降低,需要合理选择视场角,在尽可能减少散射影响的同时,提高成像效率。
条纹管激光成像是水下扫描成像的另一方法,也是水下三维成像的经典方法,利用条纹管将脉冲激光在发射器与目标之间的往返时间还原为目标的距离像,再加上CCD获取的二维图像来重建出三维图像,免去了距离选通三维成像中对距离的复杂计算。具体工作过程为:激光器发射出激光,被分束器分为两束,一束用于正常获取二维图像,另一束用于条纹管获取距离信息,该束激光到达目标并从目标处反射后,经狭缝变为宽度一致的一维信号,并经过透镜组到达光电阴极,被转换为与光信号时序一致的电信号,电子在加速电压加速后进入偏转系统,偏转系统上加有随时间线性变化的斜坡电压,将不同时刻进入的电子沿垂直于狭缝的方向分开,经微通道板(Microchannel Plate,MCP)增强后打在荧光屏上,获得对应的条纹图像,该条纹即目标场景表面的复现,如图39[147]。一次成像仅可获取被照明物的方位与距离二维信息,通过载体机械移动不断扫描即可实现目标的三维成像。由于条纹管采用高压偏转扫描,因此可区分时间间隔极短的电子束条纹,实际检测能力可达ps级[148]。
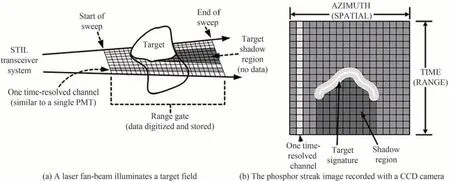
图39 条纹管成像原理[147]Fig.39 Principle of streak tubeimaging[147]
在条纹管成像的应用上,最早是由KNIGHT F K等[149]研制出单狭缝条纹管并利用其实现了16×16像素的三维成像,随后ASHER G等[147]利用基于多狭缝条纹管技术的64×64像素的激光雷达(STIL),对水下水雷目标进行成像,具有良好的应用潜力。2002年ANDREW J N等[150]将STIL成像系统装载在水下载体上,对海底地貌及水雷状目标进行了三维成像[151-153],结果如图40所示,表明成像系统具有良好的水下三维成像能力。ROGER S等[153-155]研制的机载激光水雷探测系统以条纹管激光雷达为核心,可对近水面的水雷进行探测与定位,探测深度可达40英尺,可快速对大片海域进行检测。
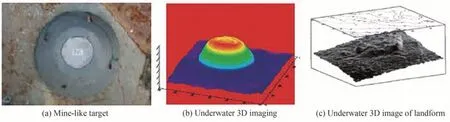
图40 条纹管三维成像结果[151-153]Fig.40 Results of streak tube 3D imaging[151-153]
GAO J等[156]开发了一种基于条纹管相机的闪光激光雷达,将其安装在船头,以推扫方式对海面波场和水下目标进行测量,获得了具有较高的帧率和分辨率的波场和水下图像,可用于水下障碍物的探测;徐国权等[157]设计研制了一套水下三维成像增程激光雷达系统,采取调Q技术与F-P腔产生峰值功率高和输出能量高的高频激光脉冲,在清水环境中能获取到13 m处直径9 mm的目标细节,在浊水环境中的信号处理增程能力达到81.4%,相对距离分辨误差为0.01 m,具有较高分辨率及成像精度。LI G等[158]研发了一种调制亚纳秒激光雷达,激光源由1064 nm主振荡功率放大器和倍频模块组成,可在在532 nm处输出87.6 MJ的能力,条纹管摄像机用作信号接收装置。经实验,该雷达能够获取20 m水下目标清晰的三维和四维图像,空间分辨率为9 mm,如图41所示。此外,混合激光雷达系统的使用也提高了水下探测距离。

图41 激光雷达在清水中20米距离的目标成像[158]Fig.41 The target imaging with the distance of 20 m in clear water was recorded by the lidar-radar[158]
条纹管成像技术具有系统集成度高,成像速率快,保真度高,极高的时间和距离分辨率,探测视场大,图像分辨率高等优点。但同时,作为一种扫描方法,需要对目标进行多次探测,容易造成低成像精度,或者需要采用多狭缝条纹管或条纹管阵列来弥补。此外,条纹管成像技术对运动目标的成像难度较大,成像系统时间短,无法满足长时间摄像需求。目前,条纹管成像技术逐渐成熟,其发展也逐渐向研发具有更高能量和频率的激光器方向发展。
非扫描成像技术采用扩束的脉冲激光对目标进行一次照射成像,具有成像速度快的优点,但激光能量分散,只能进行小视场成像。距离选通技术是非扫描成像的经典技术,其核心器件为脉冲激光器和选通相机,通过控制脉冲激光发射时间与选通相机快门开启时间的先后来调控目标光的接收与散射光的分离。具体过程为:脉冲激光器产生脉宽极短的激光脉冲,通过水体到达目标物,经目标物反射后再次经过水体到达选通相机,在脉冲发射并到达相机前,相机快门处于关闭状态,光波在传递过程受水体影响产生的散射无法进入相机,如图42(a)所示。当激光脉冲到达相机的瞬间,相机快门打开,并保持一段时间(选通时间),接收目标反射光,随后关闭,如图42(b)所示,选通时间通常略长于激光脉冲脉宽,在保证接收到目标信息光的前提下,尽可能减少后向散射光进入相机。由于脉冲激光脉宽极短,所以通常将增强型电荷耦合器件(ICCD)作为成像设备。
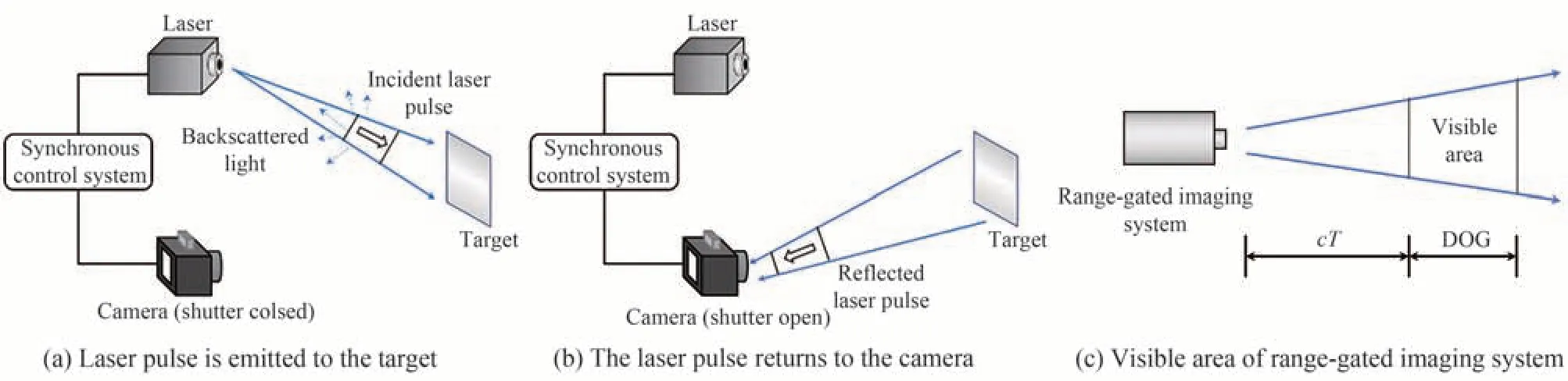
图42 水下激光距离选通成像系统工作原理Fig.42 The principle of underwater range-gated imaging system
在成像过程中,从激光器发出激光脉冲到相机快门打开之间有延迟时间2T,该延迟时间决定了系统成像距离cT,激光脉冲宽度τ及选通时间t决定了系统的选通深度(Depth of Gating,DOG)。如图42(c)。因此,可通过调节延迟时间实现不同距离成像,调节脉冲宽度及选通时间实现不同成像深度。当且仅当目标处于系统视场范围内,且同时处于系统的选通深度内时才可被成像,因而可以大大减小后向散射光的影响。同步控制技术是距离选通的成像系统的核心技术,控制好激光脉冲与相机快门的良好协同是选通技术的关键,通常需要根据激光器与目标物的距离确定延迟时间、根据景深确定脉冲宽度。当需要改变成像距离或改变景深时,需要改变相应的延迟时间及脉冲宽度。LIU W等[159]研究了快门控制信号、开启时间(早/晚)与图像对比度的关系,提出在成像系统不饱和的情况下,当快门控制与激光脉冲最优匹配时,成像质量最佳,且在脉冲到达时,滞后开门是有利的,开门时间为激光脉冲宽度的1~3倍时,可获得最优图像。
水下距离选通成像技术凭借对光散射效应的抑制,成为水下成像的重要手段之一,受到广泛应用。目前国外研制出的经典水下距离选通成像系统主要有:加拿大国防研究所(DRDC Valcartier)研发的三代LUCIE系列产品[160-163],搭载在ROV上,可实现200 m水下成像,在滨海水质下探测距离可达15 m,深海水质下探测距离50 m;美国SPARTA公司研制的See-Ray距离选通系统[164],在5.6倍衰减长度下可识别分辨率板,极限情况可进行6.4倍衰减长度的探测;MCLEAN E A等[165]研发出激光脉冲宽度低至120 ps,可获得6.5衰减距离的分辨率板图像的水下距离选通系统;TAN C S等[166]在距离选通成像系统基础上增加选通图像的自适应融合,结果表明该方法可增加距离选通系统的成像景深,等等。国内典型的有中科院西安光机所研制的水下电视摄像系统SS-1000[167],可在50 m水深处工作;北京理工大学与北方夜市公司合作研制的纳秒级增强型选通CCD,可实现泳池环境下距离目标49 m处的分辨力靶标成像[168];华中科技大学将研制的距离选通水下激光成像系统用于船池中6 m和12 m远的黑底白字的字母“E”成像,结果如图43所示[169]。

图43 水下目标成像图[169]Fig.43 Images of underwater target[169]
除二维成像外,距离选通还广泛用于三维成像中,与二维距离选通成像不同的是,三维距离选通需要利用接收器探测到的光强计算出距离图r(x,y),再根据强度图I(x,y)可进行目标的三维重建。李东等[170]利用CCD探测到的像素点的强度通过质心法求解出距离图,结合强度图完成目标的三维重建;黄子恒[171]提出点除法计算距离的方法,根据目标相对于成像系统的距离范围,选定两组选通门参数,并计算两者回波强度-距离函数的比值,获得灰度值与距离的对应关系;RISHOLM P等[172]通过差分延迟扫描曲线的峰值估算距离,即一个像素(光敏区)单位时间内检测到最多光子的点代表到目标的距离,得到三维图像;在实际应用上,丹麦国防所研制出的高精度距离选通相机[173],可在几秒内构造出三维图像。
距离选通成像技术凭借对选通相机对后向散射光的抑制,较其他方法有一定的优势,但在许多不同距离都存在感兴趣的目标时,距离选通仍无法避免后向散射带来的影响,需要与图像处理方法结合消除过多的散射光。此外,距离选通系统的造价高昂,操作复杂,分辨率及帧率有限,限制了其在具体环境中的应用。
目前,水下激光成像与深度学习方面的结合应用较少,主要是由于水下激光成像技术可直接生成可视图像,而对可视图像的去雾、去噪、滤波等属于数字图像处理的范畴,因而目前大多基于深度学习的水下激光成像技术都是对激光成像已获得的图像进行处理,如张清博等[174]利用改进的具有跳跃结构和空洞卷积的生成对抗网络对水下激光图像进行修复,去除后向散射光及噪声;ZHOU L等[175]利用骨架结构的CNN进行浑浊水体条件下的激光成像图像的恢复;ILLIG D W等[176]利用去噪自动编码器对浑浊水图像进行滤波去噪;袁清钰[177]利用CNN对条纹图像进行高斯特征学习并以此拟合高斯模型恢复条纹图像等,其本质上都是数字图像处理的范畴。而利用神经网络从光强度图像计算出深度图并恢复出三维图像可能成为深度学习在水下激光成像的应用之一。
目前,二维水下激光成像技术逐渐发展成熟,现阶段主要由二维成像向三维成像方向发展,三维图像具备更丰富的信息,是目前成像技术的重要发展方向之一,但目前国内外的水下三维成像结果仍不理想,能够得到清晰的三维图像的方法大多存在耗时长,假定过多,需要先验知识,泛用性不足等缺陷,需要辅以数字图像处理技术。未来该项技术需要向缩短成像时长,提高成像精度,提高适应性等方向发展。此外,硬件也是水下激光成像技术的发展方向之一,如研发具有更高发射能量和频率的激光器,但过高的研究成本也是限制其发展及工程应用的原因之一,因此,在未来,提升激光发射器性能的同时,如何控制成本以实现更广泛的应用也是需要考虑的问题。不同水下激光成像方法总结如表7所示。

表7 不同水下激光成像方法总结Table 7 Summary of different underwater laser imaging methods
3.8 水下全息成像技术
全息成像是利用光波干涉原理同时记录物体光波的振幅与相位信息(全息图),然后利用衍射原理再现物体的光波信息的技术,其概念最早由英国科学家Dennis Gabor提出。目前,全息术已获得广泛应用,出现了计算全息、数字全息、相关全息等;按光路结构不同,又有同轴、离轴、微离轴全息等;而按所使用的光源的不同,又有相干光全息和非相干光全息等。目前,在成像领域中,数字全息技术是应用得最多的全息技术,采用CCD等取代了传统光学全息中的记录介质,实现了记录与再现的数字化。传统光学全息成像的过程是:通过调整光路,将物体反射或者透射的光波与参考光波进行干涉,在记录介质(干板等)上形成全息图,然后使用合适的光波照射全息图,使其发生衍射,产生与原物光波相同的新光波,即再现像。数字全息技术与之类似,只是将记录介质改为CCD或CMOS相机,记录离散的光强分布,再现过程通过计算机完成,需要采用相应的算法对再现像进行重建,如菲涅耳变换法、卷积法等,如图44所示。
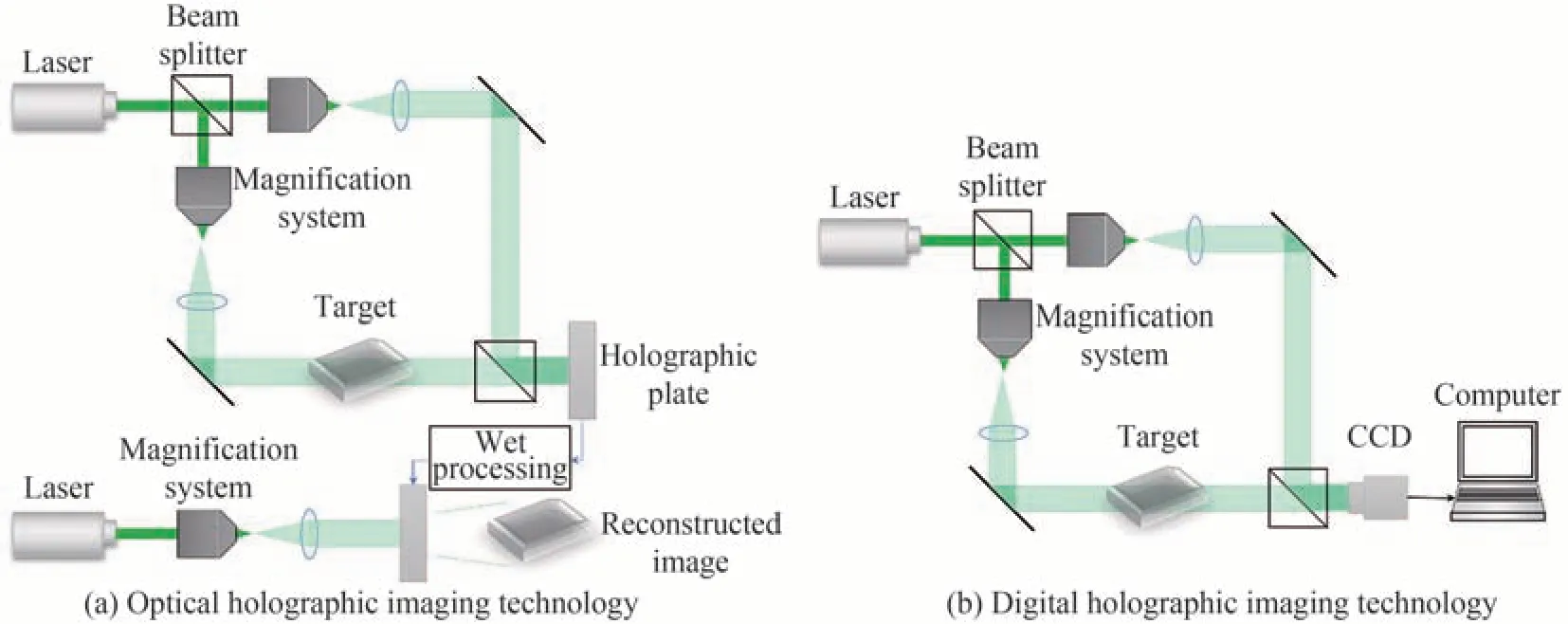
图44 全息成像结构示意图Fig.44 Holographic imaging structure diagram
数字全息技术具有以下优点:1)数字化的记录与再现过程,避免了光学全息中显影、定影等物理过程,可以实时进行图像获取与处理;2)数值重建时可实时获取物体的振幅与相位信息;3)在计算机中进行处理,便于后续图像处理与数据传输等。目前,在全息成像的应用中,数字全息技术凭借与传统光学全息技术的相似性及与计算机技术结合的优势,在传统全息技术的几乎所有应用领域均有所使用,包括显微成像、定量相位成像(Quantitative Phase Imaging,QPI)、三维空间的粒子和流量测量、生物体的三维成像及识别、全息信息加密等[178-182]。而在水下成像的应用中,全息技术凭借其非入侵性,以及能够以在自由流样中获取微米至厘米范围内粒子的三维空间分布的优点,在水下显微成像中应用广泛,通常用于水体状态分析。KNOX C[183]首次证明了全息技术在海洋应用技术的潜力,BEERS J R等[184]在实验室中首次实现了水下同轴全息成像,随后KNOXI C将[185]其用于实地记录海洋浮游生物,可记录大于10 μm的微生物;KATZ J等[186]开发了一种能够在同轴和离轴模式之间切换的远程可操作内联潜水全息相机,用于水下微粒成像;2000年,ROBERT B O等[187]开发出第一个数字原位全息系统,可分辨5 μm大小的水下微粒;JERICHO S K等[188]开发出使用点源照明的全息显微镜,用于原位记录海洋生物;MALKEI E等[189]提出了自动化处理全息图的方法,但处理500 mL样品的全息图仍需要5 h。
在近期水下全息成像技术发展中,成像效率大大提高,一台仪器可以在10 min的垂直剖面上记录9000张全息图[190]。除此之外,水下全息成像技术还向原位探测、多功能集成、缩小体积、轻量化重建算法等方向发展。目前水下全息成像系统不仅可进行原位水下微粒成像,还集合了探测分析功能,可用于探测分析水体粒子沉降速度,粒子方向、微生物分布,并对水体微粒进行分类等。GRAHAM G W等[191]论证了全息术在研究沿海海洋悬浮泥沙粒径分布和沉降速度方面的适用性;CROSS J等[192]基于湍流与粒径关系,研究了颗粒的再悬浮并使用全息数据来识别悬浮粒子物质;Wang等[193]研制的数字直列全息系统(DIH),可高分辨率记录一系列粒子和浮游生物图像,实现悬浮物的监测与分析,同时实现了悬浮物和浮游生物的目标识别分类;NAYAK A R等[194]将全息系统与声学多普勒测速仪、CTD和其他仪器进行组合,用于海洋粒子方向的总和测量,同时量化颗粒方向;DYOMIN V等[195]将水下数字全息相机(Digital Holographic Camera,DHC)与其它如水文物理传感器等结合探测,在不采样的情况下获取浮游生物数据,省去取样、固定和储存探针以及随后在实验室中进行处理的常规和耗时的阶段;MOORE T S等[196-197]使用全息技术来实际描绘浮游植物群落组成。
在缩小体积及轻量化方面,MALLERY K等[198]研制了一种的数字同轴全息系统(DIHM),装载在自动两栖载体上,如图45所示,可实现自动成像,DIHM总体积仅5×5×13 cm3,可在原位以每秒1帧的速度记录大小为2.3 mm×2.3 mm(2048×2048像素)的图像,但会引入较多的噪声,需要进行补偿;DYOMIN V等[199]研发的一款微型IDHC数字相机,体积为32×14×14 cm3,质量为9 kg,搭载在水生生物探测器上,可对浮游生物浓度、个体的平均大小和分布以及水的浑浊度进行获取,且与实际网捕法相比差距不超过23%。

图45 基于自动机器人的DIHM系统[198]Fig.45 Robot-driven DIHM[198]
全息重建是全息成像中必不可少的一部分,用于产生与原物光波相同的新光波,但在同轴全息重建时,会产生虚假的物象叠加到重建的光场中,造成孪生像,需要对目标进行多次测量采集多张同轴全息图进行迭代重建,使重建值在迭代中收敛到真实相位,或改用离轴全息术,通过二维傅里叶变换进行滤波去除孪生像,最后通过菲涅耳衍射法等进行重建,但两种方法都需要花费较多时间及计算成本,而深度学习的引入为上述问题提供了新的解决思路[200-201]。相较于需要先验知识对图像进行重建,及需要对新图像进行迭代优化的传统方法,基于深度学习的重建方法可以利用大量的数据对重建问题施以潜在约束,同时,通过网络学习优化,还可实现实时重建[202],大大提高了重建效率。2017年,SINHA A等[203]提出端到端的神经网络进行同轴全息图像重建;次年,WANG H等[204]利用神经网络直接从单张全息图重建物体相位,免去了预处理与去除零阶和孪生像所需的相位去包裹计算,提高了重建效率;之后,王凯强等[205-206]构建了Y型卷积神经网络Y-net并成功应用于离轴数字全息图的数值重建,并进一步提出了一种针对单次曝光共光路双波长数字全息图的深度学习数值重建方案Y4-net,解决了双波长全息图在频域存在的难以避免的串扰问题,成功实现由单张数字全息图同时重建获得两个波长全息图的复振幅信息。
而在水下成像中,基于深度学习的成像方法可获得更好的成像质量,SHAO S等[207]利用深度学习从全息图重建三维粒子场,并通过迁移学习方法来减少对新全息图数据集的训练要求,结果比早先的深度学习方法[208]重建的图像具有更高的粒子浓度和更高的定位精度,且重建速度比正则化体积重建(RIHVR)[209]快30倍以上。除此之外,深度学习方法还可用于直接从全息图进行信息提取,避免了复杂的重建过程。SHI Z等[210]利用YOLOv2对4种浮游生物的全息图进行分类识别,精确度可达94%;GUO B等[211]利用骨架结构的CNN网络对10种浮游微生物的同轴全息图进行分类,在测试数据集上可达93.8%的准确率,应用概率滤波器后,准确率可进一步提升,并可在实际海洋环境中使用。但上述利用深度学习直接从全息图进行微生物分类识别的方法仅适于较小的成像体积,在微粒相对靠近相机时,衍射图案与目标形状相类似,因而易于识别,但当粒子离相机较远(较大成像体积)时,衍射图案不再与微生物类似,分类识别效果较差。对此,COTTER E等[212]提出全息图局部重建的方法,将深度学习技术用于筛选具有可检测目标的全息图,然后对全息图中待检测目标进行检测框选,流程如图46(a),最后利用黄金分割搜索算法重建和聚焦检测到的衍射图案,结果如图46(b)。该方法利用局部重建的方式取代全局重建,将1 mm聚焦精度所需的重建次数从1000次减少到31次,大大减少了重建和聚焦的迭代次数,同时将重建时间缩短至全局重建的1%,且可检测大部分大于0.1 mm的微粒,极大地提高了重建效率。傅里叶变换重建与基于深度学习的重建方法总结如表8所示。

图46 从水下数字全息图中快速提取聚焦目标[212]Fig.46 Rapidly extract focused targets from underwater digital holograms[212]
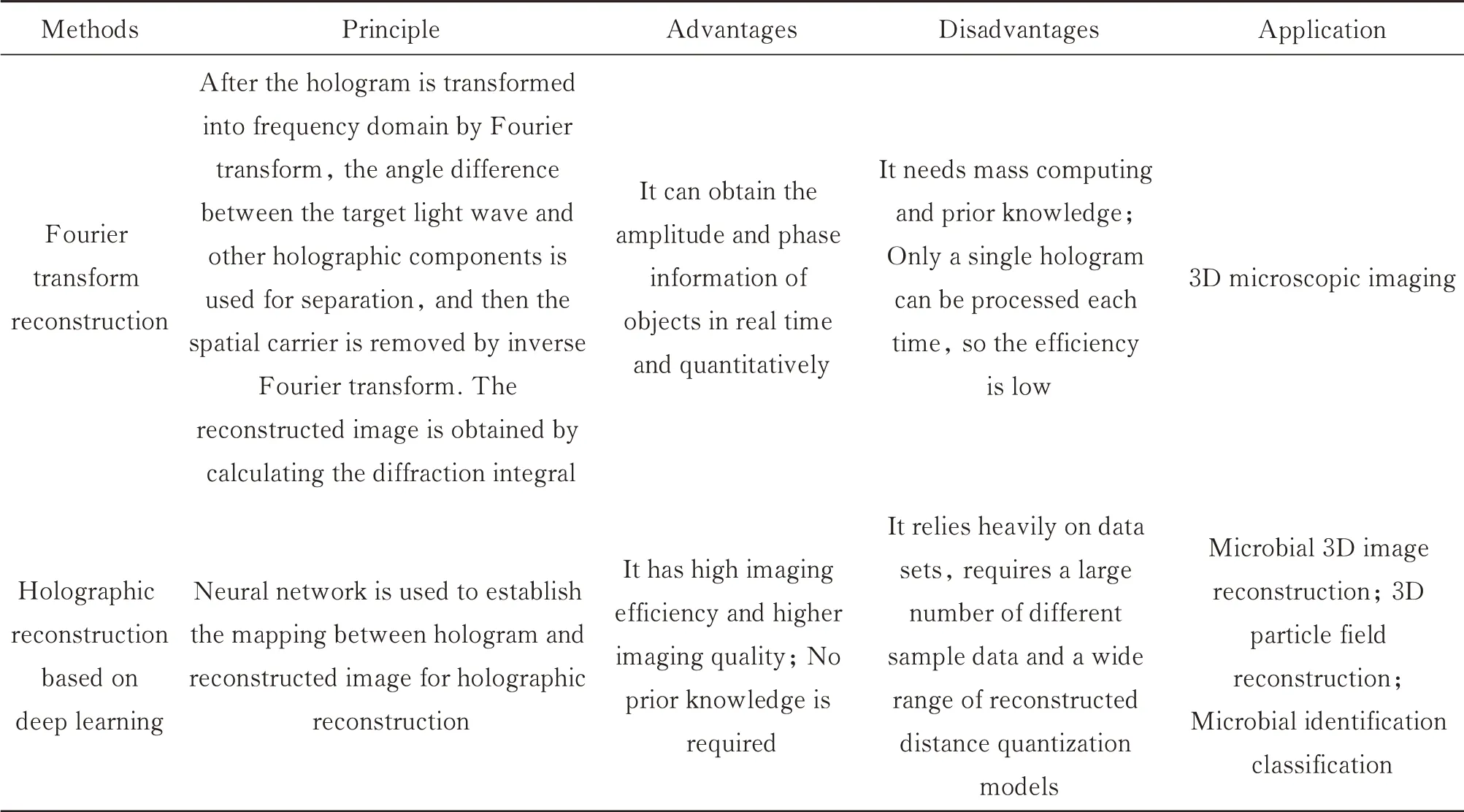
表8 傅里叶变换重建与基于深度学习重建方法总结Table 8 Summary of Fourier transform reconstruction and reconstruction based on deep learning
目前,深度学习技术在水下全息成像中主要用于全息图的目标识别和微生物直接分类,但作为一种数据驱动的方法,需要大量数据集支撑,尤其是对全息图像直接进行分类的方法,需要包含有相关微生物的庞大数据集,但目前仍然存在缺少高质量数据集的问题,且复杂的水下环境又限制了数据的获取和数据集的构建,因而在水下全息成像的应用并没有陆上成像那么广泛。此外,将深度学习用于水下微生物直接分类的方法仅对在焦平面上的微生物有较好的识别效果,对离焦的微生物分类效果仍有待提高。因而在未来,创建一个大型可用的多种水下微生物数据集,其中包含有原始全息图像及聚焦后的图像,以及如何提高对离焦的微生物分类识别效果,将会是深度学习技术在水下全息成像应用中的重要发展方向。
3.9 小结
第三节总结了传统成像方法和与深度学习结合的成像方法在水下环境中发展现状与应用情况。此处,针对所有与深度学习结合的成像方法进行对比总结,按照应用领域、网络结构、损失函数和所解决的问题不同,表9给出了神经网络在水下成像中的使用情况统计结果,其中加粗字体表示常用网络和损失函数。从表中可以看出,CNN与MSE为主要的网络模型与损失函数,一方面是针对图像处理类问题,CNN中的卷积模块可对图像进行快速特征提取,同时避免MLP过多的参数带来的计算复杂度增加,节省计算资源,另一方面是CNN简单的结构使其容易搭建及修改,加上残差连接、跳跃连接等优化细节,简单网络也可实现较好的图像处理效果。此外,由于深度学习在水下成像中的发展仍处于早期阶段,不及在陆上成像中的发展,因此许多深度学习的最新技术尚未应用于水下成像中,当前使用较多的仍是单链CNN网络。MSE作为经典的损失函数,具有公式简单,鲁棒性好,泛用性强的优点,在图像处理中受到广泛应用,此外,研究人员还将MSE与其它损失函数联合使用,以不同系数进行组合,以获得更好的网络训练效果。
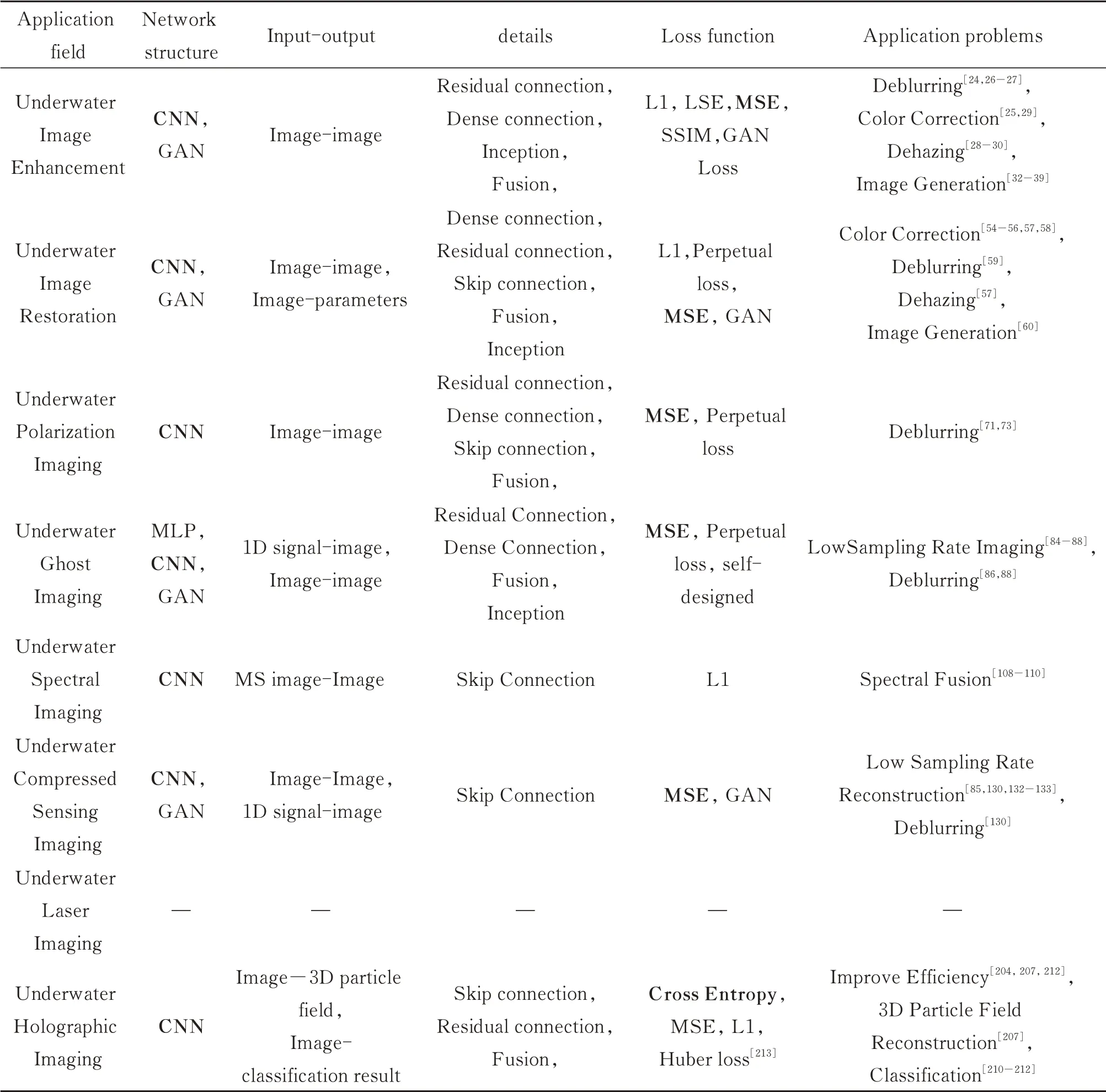
表9 深度学习在在水下成像中的应用总结Table 9 Application of deep learning in underwater imaging
4 总结与展望
本文从水下成像技术的应用背景出发,概述了水下成像的典型模型,总结了深度学习在水下环境中与图像增强、图像恢复、偏振成像、关联成像、光谱成像、压缩感知成像、激光成像、全息成像等应用的结合特点,并对其进行了总结。但是,深度学习在水下成像中的应用尚有许多问题亟待解决:
1)水下图像数据集不足。深度学习方法目前的主流仍是有监督学习,需要大量数据对神经网络进行训练,但水下成像受限于设备和水体环境因素,较难获得质量较好的包含清晰和退化图像的数据集,目前大多实验室的数据集是通过人工模拟的水下环境,如在缸中倒入牛奶以模拟水下浑浊环境等,该方法虽能一定程度上模拟水下环境,但与实际复杂的水下环境如海洋环境甚至是深海环境仍有较大差距。因此,建立真实、高质量且数据量充足的水下环境数据集具有重大意义。
2)神经网络的泛化能力较差。目前多数神经网络只能稳定增强或重建某一水体的水下图像,或是水下图像中的某一特性,如果要泛用至其它水体环境或其它退化特性,需要利用相应的数据集对网络重新进行训练,甚至需要修改网络结构。如果同时增强或重建具有多个退化特性的水下环境容易在增强或重建某个特性时引入其它噪声、伪影等。此外,GAN网络及风格迁移在生成水下数据集也存在仅能生成一种类型的水下图像,效率低下的问题,因而提高神经网络的稳定性和泛化能力同样具有重要意义。
3)网络的可解释性不足。神经网络可拟合未知的映射关系解决正向或者逆向问题,如水下图像恢复和退化图像合成,但目前神经网络的搭建、细节的优化仍主要依赖经验或者是盲目试验,缺乏指导性方法,效率较低,同时不利于网络向轻量化、泛用化方向发展。神经网络是如何建立起模型的映射关系及如何解释相关物理机制并优化网络仍是数据驱动算法面临的问题之一。
目前,深度学习在水下成像中的应用取得了一定的进展,但仍处于初级阶段。水下成像中的许多问题,如水下退化模型与深度神经网络匹配的深层物理机制等仍有待挖掘,如何更好地把握神经网络的特性并将其与水下成像深入结合,并进一步用于解决水下成像的实际问题,将是未来水下成像技术研究的趋势。
猜你喜欢
物理学报(2022年23期)2022-12-14
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中国惯性技术学报(2020年2期)2020-07-24
成都信息工程大学学报(2019年4期)2019-11-04
电子制作(2019年12期)2019-07-16
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
