
种子动态萌发表型分析算法的研究和软件实现
2022-11-21 03:34:00赵建华周洁戴杰丁国辉徐凌翔关雪莹周济
南京农业大学学报 2022年6期
赵建华,周洁,戴杰,丁国辉,徐凌翔,关雪莹,周济,4*
(1.南京农业大学前沿交叉研究院/作物表型组学交叉研究中心,江苏 南京 210095; 2.南京农业大学人工智能学院,江苏 南京 210031;3.浙江大学农业与生物技术学院,浙江 杭州 310029; 4.英国国立农业植物研究所/英国剑桥作物研究中心,剑桥 CB3 0LE,英国)
种子是高等植物生存、传播和繁衍的一种基本形式,既具有抵御不利环境的形态结构和生理特征[1],也是维护种质资源的重要形式[2]。种子保存了植物关键遗传信息,亦被称为“农业芯片”,对衡量作物品质和农业生产都具有重要意义[3]。种子在合适的环境下萌发和出苗,根据其萌发特征可分为吸胀(imbibition)、萌动(radicle emergence)和发芽(seedling)3个阶段,包括种子因吸水体积膨胀的吸胀阶段,胚根、胚芽向外生长突破种皮的萌动阶段(protrusion,俗称“露白”),胚根长与种子等长或胚芽长为种子 1/2长的发芽阶段(germination)[4]。种子发芽是种子生活力(viability)和活力(vigor)的基本表征,量化分析其萌发过程中的关键性状,为了解不同作物的生存、生长、产量形成及遗传完整性提供了重要依据[5]。特别是在全球环境变化加剧的今天,胚根突破种皮的时间和胚芽生长速率等性状[6]以及相关趋性[7]往往体现了植物的抗逆性和适应环境的能力。因此,通过对幼根(radicle)、胚芽(embryonic shoot)和子叶(cotyledon)的表型分析,可为判断种子在不同环境下的活力提供依据,进而为研究作物早期萌发、出苗和品质等重要农艺性状提供表型组信息[8]。
当前大规模种子萌发表型鉴定仍主要依靠人工观察,限制了萌发试验的监测频率、规模和准确性,因此植物研究领域对自动化表型获取和高通量鉴定的需求日益增长[9]。近年来,国内外学者结合计算机视觉和机器学习对种子萌发表型分析进行了很多有益尝试。例如:Halcro等[10]利用图像处理、k均值聚类算法和高斯混合方法采集种子的颜色、大小和形状特征数据;SeedExtractor[11]和phenoSeeder[12]可以在单一背景下自动化获取单个种子的二维、三维形态数据,但分析速度受限于数据采集和处理算法;Vlaminck等[13]利用ImageJ来测量水稻幼芽特征数据,但分析准确性和通量受限于软件平台;GERMINATOR[14]通过胚根和种皮之间颜色的对比度快速鉴定发芽,但只能应用于相对简单的萌发图像;RGSES[15]通过图像处理获得种子颜色、形状、纹理等特征,并结合人工神经网络技术来预测水稻种子发芽趋势,但准确性相对较低;SeedGerm[16]表型平台利用计算机视觉分析,根据幼根生长鉴定发芽和种子发芽率,进而通过表型性状鉴定油菜品种的遗传差异和对萌发调节蛋白磷酸酶(HAI3)在染色体上完成定位,但不能对交错幼根进行分割和动态分析;SeedQuant[17]结合深度学习和计算机视觉统计发芽种子,但该算法不能对发芽后的种子继续动态监测;GrowScreen-Agar[18]利用匹配滤波器对未交错重叠的拟南芥幼苗根冠进行定量分析,并获得根系结构数据,但在幼根互相遮挡情况下的分析准确率较低;Gong等[19]基于语义分割算法分割水稻幼苗根系,但只能对单个种子进行分析,且对种子排列要求较高;RootNav2.0[20]利用卷积神经网络从图像中获取复杂根系结构,精确分割根系,但算法计算复杂度高,很难应用于对种子幼根根系的大规模分析。
目前尚无以分割交叉幼根为目标的种子动态萌发表型检测的相关研究,也未发现针对从萌发到胚根出现生长的整个过程来构建量化监测平台的报道。针对现有分析软件算法在这一研究方向上的不足之处,本研究借鉴SeedGerm的开源软件包[16]和AirMeasurer的动态表型分析算法[21],创新地提出了基于幼根分割、根尖点追踪的种子萌发动态表型分析算法。此外,还利用Python编程语言和图像处理、机器学习等开源软件库设计了数字化性状提取软件包,对幼根动态分割和根尖点追踪等表型分析难题开展有益研究,为今后大规模自动化检测关键种子萌发表型组提供参考。
1 材料与方法
1.1 种子萌发试验设置
种子萌发试验图像数据于2020年5月至8月完成采集。以小麦(Triticumaestivum)萌发试验为例,在发芽盒底部放置双层蓝色滤纸,并在滤纸上方放置A3尺寸的深蓝色或深红色发芽纸。研究采用3个弱筋小麦品种,分别为‘扬麦25’‘宁麦26’和‘淮麦30’,于2019年收获,保存期为1年。如图1所示:每个品种选取18粒(6行3列)麦粒放置于蓝色发芽纸上,并将固定体积的水加入滤纸中,静置2 h,待滤纸均匀吸收水分后开始种子萌发试验,发芽盒内温度保持22~24 ℃,湿度为99%。拍摄和人工试验数据采集周期为7 d。
1.2 算法技术路线
在获取图像序列后,本研究构建了自动化分析流程,其技术路线如图1-a所示。首先,对输入图像序列(图1-b)完成预处理,即通过图形用户界面(graphic user interface,GUI;图1-c)中的颜色空间(color space)获得种子的前景和背景蒙版(mask)。然后,根据种子蒙版获得种子萌发初始性状,如种粒长度、宽度等;再通过种子二维骨架追踪种子尖点,获得种子萌发早、后期的相关性状,如幼根根长、幼根生长速率等。最后输出种子萌发性状的量化分析结果,并存储在纯文本CSV文件中。
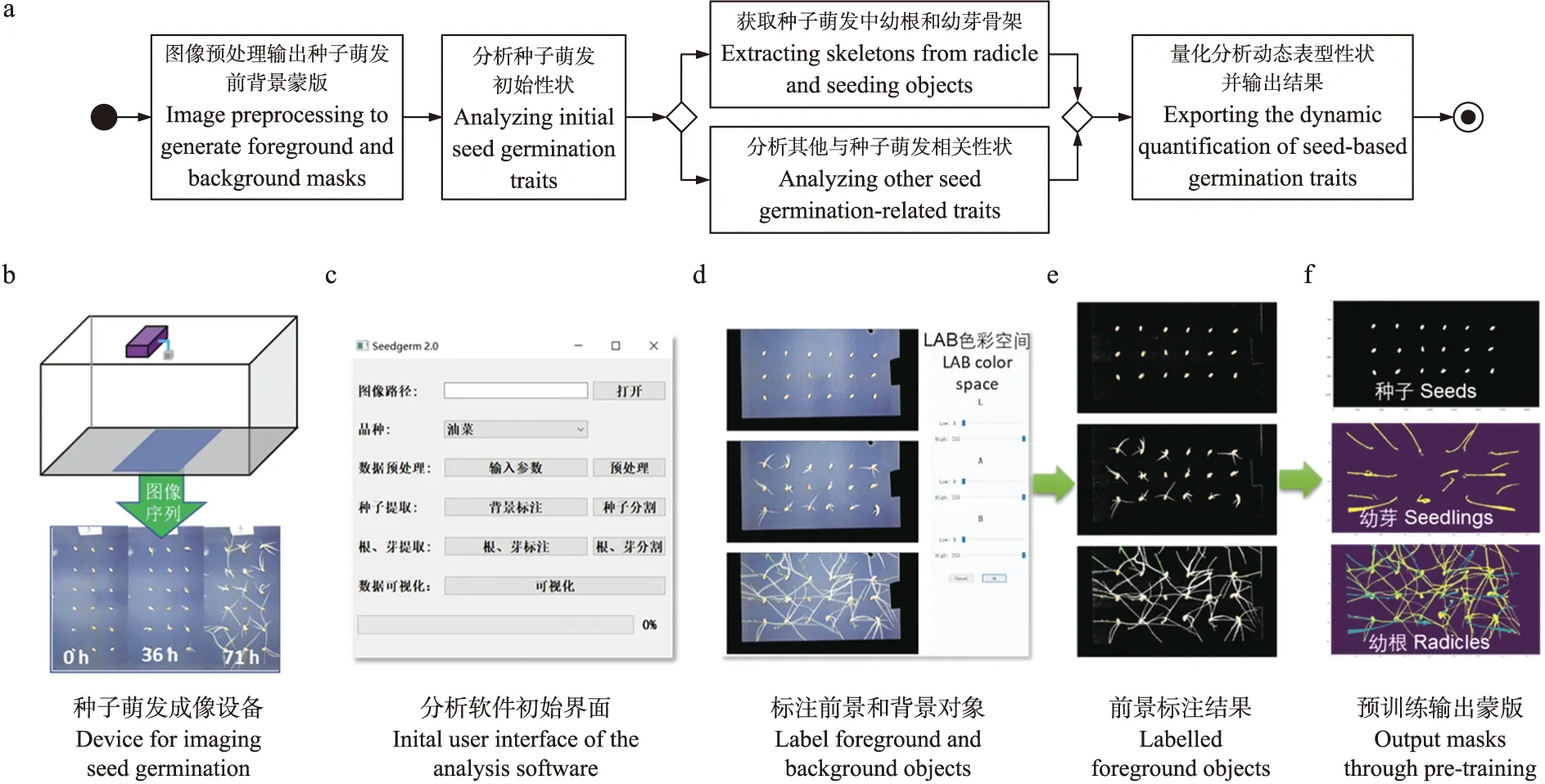
图1 技术路线(a)、数据获取(b)、分析软件界面(c)以及前背景标注(d、e)和预训练结果(f)Fig.1 Technical roadmap of research(a),data collection(b),graphic user interface(GUI)of the analysis software(c),data labelling of foreground and background objects(d,e),and pre-training results(f)
1.3 萌发时间序列图像采集
为高质量提取种子萌发性状,完整记录整个萌发试验过程,本研究对置于半透明塑料发芽盒中的多个种子进行连续拍摄,拍摄间隔为1 h,以时序图像方式记录种子萌发过程。拍摄使用PiCamera高清摄像头(Sony IMX477 sensor,Japan;5M像素),拍摄图像最大分辨率为2 592×1 944,摄像头由运行于树莓派微型单板计算机(PiFoundation,UK)的Python软件控制(图1-b)。基于时序的小麦种子图像分辨率为 2 130×1 130像素(垂直×水平),每次试验共采集150~160张图像,记录7 d的小麦种子萌发过程。
1.4 图像处理和机器学习的软件实现
性状分析算法结合了自动化图像处理、图论和监督式机器学习,通过编程语言Python(3.70)完成算法和各子功能的软件实现。其中使用的开发程序库包括:图像处理库scikit-image(0.17.2)和OpenCV-Python(4.4.0.46);机器学习库scikit-learn(0.23.2);科学数据处理库NumPy(1.19.4)、Pandas(1.2.3)和SciPy(1.5.4);图形界面库PyQt5(5.15.2)。以上开发均通过PyCharm集成开发环境(integrated development environment,IDE)完成源代码编写和测试,以下提及的各类函数均基于上述软件开发库完成相应软件实现(software implementation)。
针对本研究在背景分割时使用的机器学习部分,算法首先自动选择图像序列中位于前、中、后3个时间点的图像作为训练样张,然后通过用户拖动GUI界面(图1-d)的滑杆对不同颜色空间中的前背景对象进行初始分割(图1-e)。在得到前景和背景蒙版后,将不同萌发阶段的前景和背景蒙版所包含的像素通过红、绿、蓝(Red-Green-Blue,RGB)和色相、饱和度、明度(Hue-Saturation-Value,HSV)2个颜色空间(共 6个通道)作为机器学习的训练样本数据集,再通过用户选择的监督式机器模型进行学习。最后将训练后的前、背景分割模型应用到整个图像序列,为后续的性状分析提供动态蒙版(图1-f)。
1.5 人工检测和算法评估
在建立人工真实数据集(ground truth dataset)时,使用ImageJ软件对140张随机选取的萌发图像进行人工测量,获得种粒长、宽、周长、面积、种子露白时间、幼根根长、幼根根生长速率、种子发芽时间、幼芽芽长、幼芽面积等性状。将算法获取的关键性状数据如幼根根长、幼根生长速率和幼芽芽长与人工真实数据对比完成数理统计,并使用分析结果中的决定系数R2和均方根误差(root mean square error,RMSE)作为算法获取性状的评价指标。根据决定系数R2确定算法数据和人工数据的线性回归关系,R2越高表示 2种数据间的关联性越高,RMSE越低表示模型误差越小。相关工作通过微软Excel(V16)的数理统计函数集完成。通过IDE性能分析(Python profiler),本算法处理单张小麦图像(5 MB)的平均用时为90~100 s,处理1个小麦图像序列(150~160张)用时210~220 min,占用内存667 MB,程序运行时间和内存消耗与图像序列大小呈线性关系。
2 结合监督式机器学习和自动化图像处理的种子萌发表型分析
2.1 图形用户界面(GUI)
鉴于开源软件包SeedGerm[16]界面交互能力不强,本研究使用功能更齐全的PyQt5开发包[22]搭建种子萌发表型分析软件的GUI。GUI集成了本研究的分析算法,可对多物种种子萌发图像序列进行批量处理,输出关键萌发性状的量化分析和数字化提取结果,包括种子的长、宽、面积、周长,种子露白时间、萌发时间,幼根长度、幼根生长速度,幼芽长度等。通过初始界面(图1-c),用户可在“图像路径”选择图像序列,在“品种”下拉列表选择作物种类(如油菜、小麦或棉花等)。在“数据预处理”定义参数,如滤纸面板数量、发芽试验面板中种子的行列数、开始和结束图像序号(默认值为所选图像序列的第一和最后一张图像)。在“种子提取”的“背景标注”下拉列表中可选择颜色空间(例如,LAB颜色空间,L代表亮度,A和B代表颜色分量;HSV颜色空间,H代表色调,S代表饱和度,V代表亮度),并通过调整滑杆位置(图1-d)对背景进行高效人工标注(图1-e),获得基于像素的前背景训练集。
在“种子分割”下拉列表中,可选择3种为分割幼根幼芽重新训练的监督式机器学习算法,如K近邻[23](K-Nearest Neighbor,KNN)、支持向量机[24](Support Vector Machine,SVM)和随机森林[25](Random Forest,RF)。不同机器学习算法可对不同质量图像的前景(种子、幼根和幼芽)、背景(发芽纸)的像素簇分别学习,进而得到不同时期种子萌发的像素特征及其蒙版(图1-e)。若需对幼根、幼芽特征信息单独提取,用户还可在“根、芽提取”部分对获取的种子蒙版进行操作,提高建立训练集的效率。
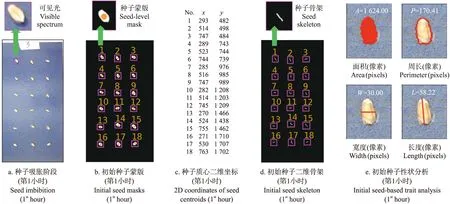
图2 种子萌发初始性状(如穗粒和吸胀特征等)分析(第1小时)Fig.2 Phenotypic analysis of initial seed germination traits such as grain phenotypes and imbibition in the first hour
2.2 种子萌发初始性状分析
以下算法解析以对小麦种子萌发性状的量化分析和数字化提取为例展开介绍。对小麦种子萌发初始阶段的性状分析从第0小时开始,种子经历吸胀到达露白阶段初期。如图2所示:通过一系列图像处理算法完成对初始萌发性状的量化分析。首先,从GUI端口获取输入的RGB图像(图2-a)和用机器学习算法处理后得到前景(即种子)、背景(即发芽纸和发芽盒)蒙版。然后,利用SciPy库的label函数和regionprops函数对种子蒙版(图2-b)进行筛选,测量并记录每粒种子的质心坐标(橙色)及其编号(黄色)。虽然种子在吸胀过程中由于自身滚动导致质心位置变化,但在1 h内(拍摄间隔),种子质心位置变化较小,可通过对比2张相邻图像中种子的质心坐标完成种子的定位(图2-c)。
基于获取的种子质心,使用thin算法提取种子的二维骨架(图2-d)。若二维骨架的长度变长(超过种子长度1/3)且监测区域中出现白色像素,则判断种子进入露白阶段。对种子的初始性状分析还包括种子面积、种子轮廓长度(即种子周长)、种子宽度和长度(图2-e)。这些初始性状测量基于像素,可通过测量放在发芽盒中的标尺(如图2-a白色标签)完成从像素到公制(如mm)的转换。
2.3 种子萌发早期性状分析和幼根根尖追踪算法
在种子萌发早期,种子幼根还未发生交叉。幼根根尖追踪算法对这一时期的种子幼根进行的性状分析主要集中于露白时间、萌发时间、幼根长度变化等性状。算法流程如图3-a所示,首先对种子萌发图像(图3-b)进行前背景分割,获得每粒种子的质心坐标和编号(图3-c),然后提取每粒种子及其幼根的二维骨架(绿色;图3-d),分析其形态特征。再通过SciPy中的binary_hit_or_miss算法获得骨架端点,将距离质心远的端点作为幼根根尖点,并在追踪算法中记录根尖点坐标(红色;图3-e)。同时,将根骨架沿法线方向到根轮廓的2倍距离作为幼根直径。最后,对本图获得的种子根尖点(淡黄色;图3-f)与前一张图像中对应的种子根尖点(红色;图3-f)坐标进行比较,并根据不同时间点的根尖点坐标重建幼根骨架,并根据重建的骨架长度计算幼根生长速率(图3-f)。
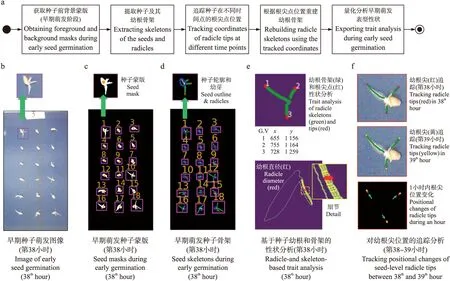
图3 分析流程(a)和早期萌发(激活新陈代谢阶段)的种子性状分析(第38小时)(b—f)Fig.3 Analysis workflow(a)and phenotypic analysis of seed-based traits at the reactivation of metabolism phase(38th hour)(b-f)
2.3.1 幼根根尖点追踪算法本研究原创的根尖点追踪算法能够用于重建幼根骨架,并获得幼根根长和幼根生长速率。算法对未露白种子i以初始化有向图Gi(V,E)(空集)表示,当种子露白后以第1次检测到的根尖点坐标Ci,j初始化Gi的顶点Gi.V,并将Gi.E的边集合设置为空集,即没有根骨架。如式(1)所示:
Gi(V,E)={Gi(V,E)|Gi.V=Ci,j,Gi.E=∅, ifCi,j≠∅ andGi(V,E)=∅}
(1)
式中:i(1~n,n为发芽试验种子总数)为种子序号,j(1~m,m为序列图像的总数)表示该图像在图像序列中的序号;G.V表示有向图的顶点集合,存放幼根骨架当前根尖点坐标,其中“.”表示对有向图G中成员数据的调用;G.E表示有向图的边集合,即幼根二维骨架集合;Ci,j为第j张图像中检测到的第i粒种子的根尖点集合。
2.3.2 幼根重建算法根据第j张图像检测到的第i粒种子及其对应的根尖点集合Ci,j,与第j-1张图像(前一张图像)中相应的第i粒种子及其对应的根尖点集合Ci,j-1,遍历同一粒种子i在前后2张图像中的根尖点集合里的根尖点元素Tk,i,j∈Ci,j和Tk,i,j-1∈Ci,j-1,其中k(1~K,K表示此根尖点集合Ci,j中根尖点总数)为根尖点k在种子i在图像j里的根尖点集合中的序号。计算Tk,i,j和Tk,i,j-1的距离是否小于20像素(根据图像分辨率获取的经验阈值)。同时,计算相对应的根尖点Tk,i,j-1和Tk,i,j构成的向量和重建骨架的夹角是否大于120°。若以上2项条件均符合,算法将连接2个根尖点Tk,i,j和Tk,i,j-1,以重建线段作为2个根尖点间的幼根骨架,并添加到有向图的重建根骨架集合Gi.E中。第i个种子在图像j上检测到的根尖点及对应幼根骨架重建完成后,用Ci,j替代并更新该种子的有向图集合Gi.V。如式(2)所示:
(2)
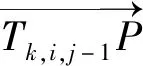
算法对序列中所有图像中的根尖点都重复上述操作,可对图像序列中所有可测种子的根尖点完成追踪并重建幼根二维骨架。IDE性能分析结果显示,此部分算法对每张图像的处理时间为25~35 s,运行时间随图像数量增加而线性增加。
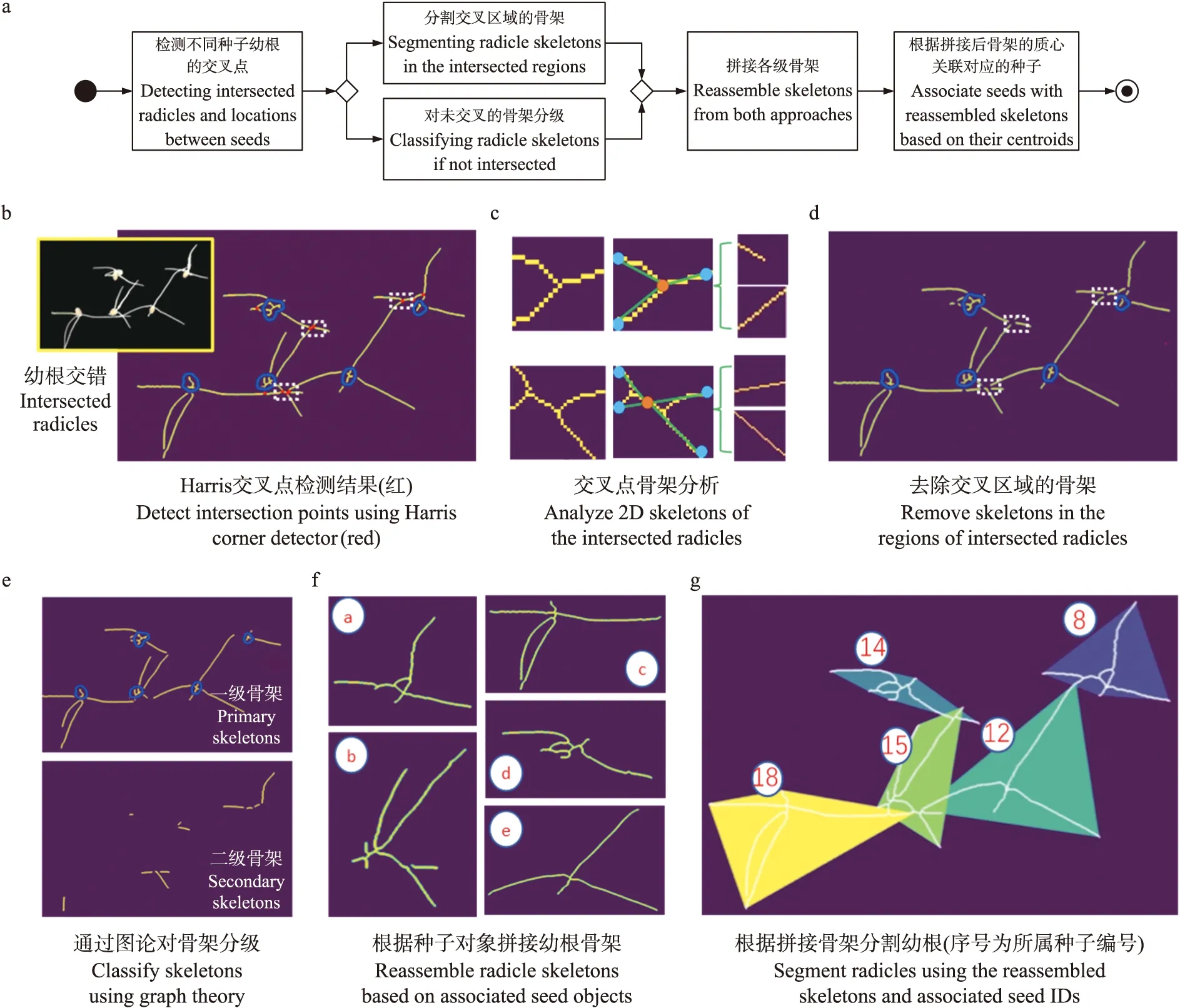
图4 分析流程(a)和基于图论分割、重建重叠的种子幼根骨架(b—f)Fig.4 Analysis workflow(a)and segment overlapped radicle skeletons using graph theory and skeleton reconstruction techniques(b-f)
2.4 对复杂种子幼根的分割和追踪
在种子萌发后期,种子幼根将出现较复杂的交叉重叠现象。针对这一问题,算法首先分割交叉的幼根骨架,再根据每粒种子的根尖点坐标完成动态追踪,按时序重建每粒种子对应的幼根骨架。算法流程如图4-a 所示,其中对交叉重叠幼根的分割算法主要分为二维骨架分解和重建2部分。
2.4.1 幼根骨架分解算法对重叠种子幼根骨架进行Harris角点检测[26],筛选合适的角点(2种,分别为“十”字交叉点、“人”字交叉点)作为幼根交叉点(图4-b红色像素区域),选择交叉点上下左右各8像素作为交叉区域。分析交叉区域骨架,分为2种情况:如图4-c所示,第1种是包含1个交叉点和3个端点的“人”字交叉点;第2种是包含2个交叉点和4个端点的“十”字交叉点。对于第1种幼根交叉方式,分割方法为:连接交叉点(橙色)和3个端点(天蓝色),构建3个向量;分别计算向量间夹角([0°,180°])的余弦值,余弦值越小表示夹角越大,连接夹角最大的2个端点构建1条幼根骨架,连接剩下的端点和交叉点构建另一条幼根骨架。对于第2种交叉方式,算法分割方法为:取2个交叉点连线的中点作为新交叉点(橙色),从新交叉点到4个端点(天蓝色)连线作为4个向量;计算向量之间的夹角,连接夹角最大的2个端点作为1条幼根骨架,连接剩下的2个端点作为另一条幼根骨架,并分别保存分割后的2条幼根。
去除交叉区域后剩余幼根骨架不存在交错重叠(图4-d),因此可根据其是否与种皮部分(图4-d,深蓝色)连接分为一级骨架和二级骨架(图4-e)。将交叉点区域骨架分解后加入二级骨架集合。
2.4.2 基于种子的幼根骨架重建算法遍历并计算二级骨架和一级骨架之间距离最近的2个端点,计算2个端点之间线段的距离和2个端点之间线段与一级骨架的夹角。若距离小于距离阈值(即20像素)且夹角大于角度阈值(即120°),则将该二级骨架拼接到对应的一级骨架中。通过以上方法可将全部的一、二级骨架重新拼接(图4-f),并根据不同种子的质心和所在骨架区域对应的种子序号,完成重叠幼根的分割和种子归属分析(图4-g)。根据种子序号和分割交错的种子根骨架,再运用2.3节中的幼根根尖追踪和骨架重建算法,可追踪某粒种子对应的所有幼根根尖点,并基于时序完成幼根骨架的重建。
2.5 种子萌发后期性状分析
在萌发后期,种子扎根扶叶,胚芽鞘向上竖起。此时对种子发芽性状的量化分析主要集中于幼根长度、根生长速率和幼芽长度等性状。算法流程如图5-a所示,首先根据萌发图像(图5-b)进行前背景分割,对每粒种子的质心坐标和二维骨架完成初始分析(图5-c)。针对种子幼根骨架交错重叠问题,利用2.4节算法分割幼根骨架,从机器学习算法获取的幼根、幼芽蒙版(图5-d)中提取幼根(绿色)和幼芽(蓝绿色)的二维骨架,基于骨架尖点坐标获得幼根、幼芽的长度和生长速率(图5-e)。利用convex_hull_image算法获得幼根的凸包(convex hull),以凸包中的像素总数作为凸包面积,即为根面积。利用种子幼芽蒙版的像素总数作为幼芽的面积。并通过图像中标尺完成从像素到毫米的转换。

图5 分析流程(a)和后期萌发(即种子萌发至幼苗发育阶段)的种子性状分析(b—e)Fig.5 Analysis workflow and phenotypic analysis of seed-based traits during the seed germination(a)and seedling development phases(b-e)
3 结果与分析
软件处理完图像序列后,会生成相关性状的CSV文件,初始性状包括:种粒的长度、宽度、周长、面积。萌发早期性状包括:露白时间、根长、根直径、根面积、根生长速率、发芽时间。萌发后期包括:芽长、芽面积、芽直径以及对幼根持续追踪后的根长、根直径、根面积、根生长速率。若图像中包含标尺,算法会将长度单位从像素转换为毫米。
3.1 种子幼根追踪算法在动态表型分析中的应用
以图像序列3中第16号种子为例(图6-a),种子露白前持续分析种粒性状(图6-b白色轮廓)。种子露白后,按时序获得幼根长度和生长速率等性状(图6-b粉色)。根据追踪结果可以发现,随着胚根生长,第28小时胚根长与种子等长,标记种子发芽;第40小时,种子出现2条次生胚根;第60小时,根系出现交叉。基于时序对所有种子的根骨架重建效果如图6-c所示,表示第1~72小时幼根生长过程(深蓝色为第1小时,深红色为第72小时)。
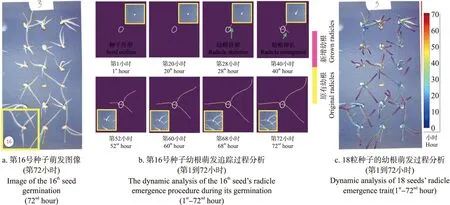
图6 种子幼根萌发性状动态分析Fig.6 Dynamic analysis of the seed-based radicle emergence trait
3.2 萌发性状量化分析与人工数据对比
以小麦为例,‘扬麦25’‘宁麦26’和‘淮麦30’(分别记为G1、G2及G3)的图像序列均有3个重复,关键性状量化分析结果如图7-a、b、c所示,3个小麦品种分别在第56、40、23小时开始露白,此后根长、幼根生长速率和幼根面积稳定增长。其中,‘淮麦30’的幼根生长速率和幼根面积增加较快,体现了较好的萌发性。第120小时左右,‘宁麦26’的幼芽生长速度加快,并快速超越其他2个品种,体现了良好的出芽能力。
将不同重复中获得的根长、芽长、根生长速率的数据通过线性回归分析与人工测量数据进行对比,获得的决定系数R2分别为0.922(n=188粒种子,P<0.001,RMSE=1.727)、0.719(n=191粒种子,P<0.001,RMSE=0.406)、0.897(n=115粒种子,P<0.001,RMSE=2.726)。相关性分析结果表明(7-d、e、f),算法计算的幼根和幼芽性状数据与实际性状数据显著相关,算法能较精确提取小麦种子的萌发性状数据。
3.3 算法在不同作物种子萌发试验中的应用
虽然本算法基于单子叶植物须根系研发,为提高算法的泛化能力,设计算法时也考虑了双子叶植物直根系的幼根特征。以棉花(Gossypiumbarbadense)和油菜(Brassicanapus)为例,通过简单参数调整后,本算法还可动态分析这2种作物的幼根根长性状。棉花幼根根长的动态分析结果(图7-g)显示,3个棉花品种的露白时间相差不大,第2个品种(G2)的幼根生长略快。油菜幼根根长的分析结果(图7-h)显示,第6个品种(G6)露白时间较晚,幼根在萌发前期生长较慢,在萌发后期生长加速;第5个品种(G5)的幼根在萌发前期生长较快,在后期生长速度减缓。
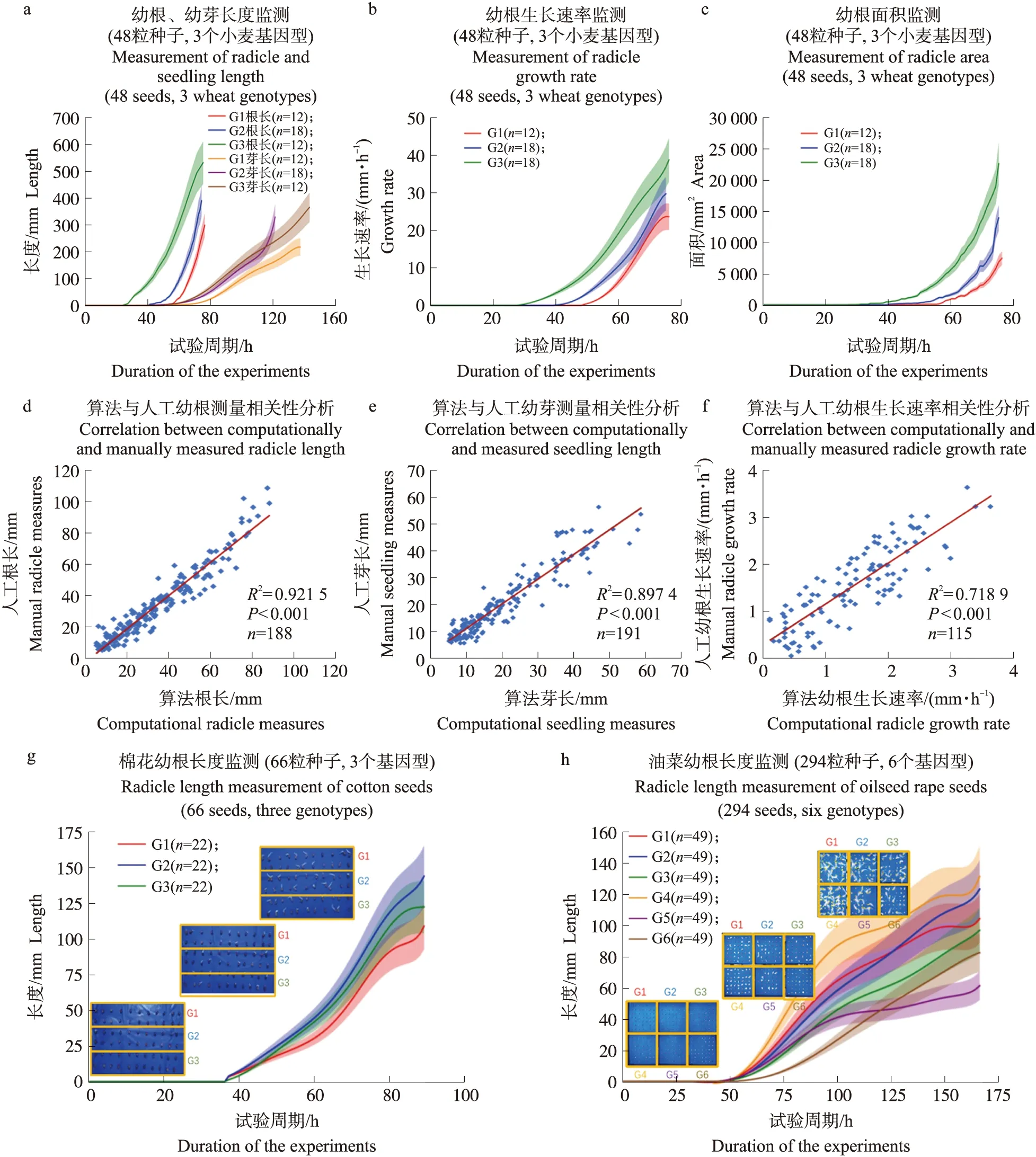
图7 性状量化分析结果(a—c)、线性回归分析结果(d—f)、算法应用(g、h)Fig.7 The result of traits quantitative analysis(a-c)and linear regression analysis(d-f)nd the application of dynamic detection algorithm(g,h)
4 结论
1)本研究提出的种子动态萌发表型检测算法结合了自动化图像处理技术、图论和机器学习算法,即利用监督式机器学习算法进行图像前背景分割,用于不同品种不同背景的试验图像;利用自动化图像处理算法获取基于形状和颜色空间的性状,进而通过图论算法解决图像处理和机器学习算法无法解决的根尖点追踪和交叉根分割等问题,提取种子萌发过程中的关键动态性状。在种子相互遮挡或根系交叉情况下,种子动态萌发表型监测算法仍能对关键表型(如幼根和幼芽生长)进行持续监测,为作物遗传育种和关键表型分析提供量化依据和智能化解析技术,为大规模种子萌发表型分析研究提供了新算法。
2)虽然本算法对关键动态性状如幼根长、幼根生长速率、幼芽长的分析达到92.2%(n=188)、71.9%(n=191)和89.7%(n=115)的相关性,但特征提取精度仍有提升空间,后续将围绕这一点展开研究。
3)目前已针对小麦、棉花和油菜3种作物完成了预试验,后续将会扩展应用场景,将算法泛化,应用到更多作物上去。本研究表明,分割交叉幼根骨架算法对本文提到的2种交叉方式的分割效果较好,但未针对更复杂的交叉场景进行研究。在今后的研究中,我们将尝试更多计算机视觉算法,提高算法在复杂幼根交叉情况下的分割效果,更准确测量幼根生长速率,并进一步提高算法的泛化性和鲁棒性。
猜你喜欢
现代青年·精英版(2022年4期)2022-05-31 21:08:07
电子乐园·上旬刊(2022年5期)2022-04-09 22:18:32
少男少女·小作家(2021年3期)2021-08-06 03:06:37
意林原创版(2020年10期)2020-11-06 04:46:58
中国新技术新产品(2020年5期)2020-05-06 03:36:28
作文周刊·小学一年级版(2019年20期)2019-06-27 00:34:14
现代园艺(2017年21期)2018-01-03 06:41:32
中国康复理论与实践(2015年10期)2015-12-24 05:42:44
医学研究杂志(2015年5期)2015-06-10 06:43:26
现代检验医学杂志(2015年5期)2015-02-06 01:42:20
