
基于多模型融合的电子商务客户流失预测模型研究
2022-11-21 02:04:46马文斌陈硕峰
无线互联科技 2022年17期
马文斌,陈硕峰
(广西财经学院 教务处,广西 南宁 530007)
0 引言
随着互联网的进一步普及,网上购物已经成为人们购买产品和服务的一种更重要的方式。根据第48次《中国互联网络发展状况统计报告》显示,截至2021年6月,我国网民规模达10.11亿,网络零售成为消费新引擎,上半年交易规模达6.11万亿元。但是,电子商务客户是典型的非契约客户[1],其关系终止难以有效判断,具有不确定性,流失率较高。
客户是企业的核心竞争力,提高客户留存率是保持其竞争力的有效途径。客户流失预测是客户留存的重要手段,也是客户管理关系的重要环节。如何建立预测精准的客户流失预测模型是当前学术界和行业界关心的问题。
当前研究主要将客户流失预测视为一种两类分类问题,利用机器学习方法构建预测模型。根据使用方法的不同,主要分为以下两方面。
一是基于统计学的预测方法。此类方法简单高效,具有较好的可解释性,如Pareto/NBD模型[2]、逻辑回归[3]、贝叶斯分类器[4]等,但是其泛化能力较差。
二是基于人工智能的方法。支持向量机[5-8]、神经网络[9-12]、随机森林[13-14]等人工智能方法具有较好的泛化能力,进一步提高了客户流失预测模型的分类能力。
借助先进的人工智能方法,上述客户流失预测方面的研究取得了一定的进展,但在电子商务客户流失预测方面的研究还不多,且多采用单个模型进行预测,对流失预测的识别能力有限。
为提高电子商务客户流失预测的精确率,基于集成学习思想,提出一种融合多个模型的流失预测模型。该模型以多个准确率较高的分类方法为基分类器,以投票法为集成策略。实验结果表明,相比单个预测模型,该模型具有更好的预测能力。
1 多模型融合的客户流失预测模型
集成学习是机器学习中一个重要的研究方向,其基本结构是先构建多个基分类器,然后利用适当的组合策略将它们的结果进行整合,常可获得比单个分类器更好的泛化能力。为提高客户流失预测的准确度,本文基于Bagging集成思想,选择多个泛化能力强且存在差异性的模型进行融合,以期获得更好的预测结果。模型结构图如图1所示。

图1 模型结构
本文模型首先将电子商务客户数据划分为训练集和测试集,然后利用随机欠采样方法对训练集进行类别再平衡,获得类别平衡的新训练集,接着在平衡训练集上学习多个基模型,最后利用投票法将所有基模型的输出进行融合,形成最终的预测结果。
2 实验结果与分析
2.1 数据预处理
客户流失预测是在客户的历史行为数据上提取、选择客户特征,并运用分类预测算法建立预测模型,预测客户未来的状态。本文实验所用的电信客户行为数据来源于Kaggle网站,共有5 630个样本,包含流失客户948个,非流失客户4 682个,两类客户的比例基本为1∶5,数据类别不平衡。原始数据共有18个特征,其中连续型特征13个,类别型特征5个,部分特征存在缺失值。通过填充缺失值、异常值处理、one-hot变换等数据预处理后,共取得34个可用特征。为便于评估预测模型性能,将数据随机划分为训练集和测试集,其中训练集占比80%,测试集占比20%。由于数据类别不平衡,文中实验采用随机欠采样方法对训练集进行类别平衡处理。
2.2 基准模型与参数设置
为评估本文方法的预测能力,实验采用XGBoost、LightGBM和随机森林3种泛化能力较强的方法作为本文方法的基模型,并与支持向量机、决策树等5种方法一起作为对比的基准模型。8种基准算法的实现主要使用基于Python的机器学习框架Scikit-Learn,xgboost和lightgbm,数据预处理主要使用Pandas数据分析库。5种方法的参数设置如表1所示。

表1 方法参数设置
2.3 评价指标
由于电子商务客户数据是不平衡数据,因此准确率并不能作为不平衡数据分类性能的评估指标。实验采用F1值、召回率(Recall)、精确率(Precision)作为客户流失预测模型的性能评估指标。召回率表示被正确识别的流失客户占实际流失客户的比例,召回率越高,说明对流失客户的预测越准确;精确率表示被正确识别的流失客户占识别为流失客户的比例;F1值是关于召回率、精确率的综合指标,其值越大,代表模型的综合分类能力越强。根据表1,召回率、精确率、F1值的计算公式如下:
(1)
(2)
(3)
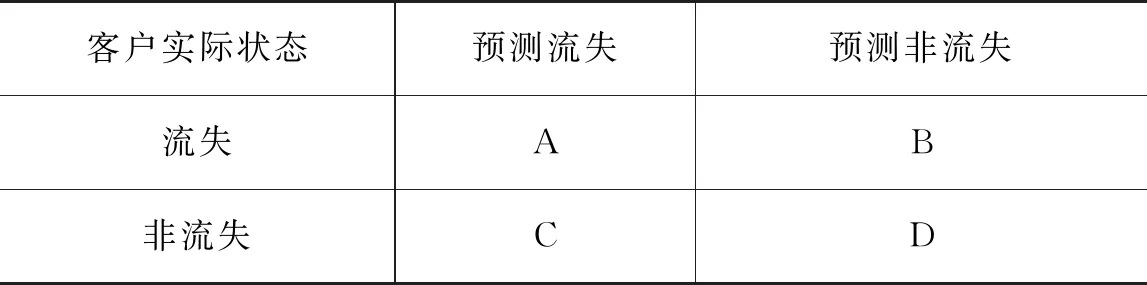
表2 混淆矩阵
2.4 实验结果
表3是各个方法的评价指标对比,由表中数据可知,本文方法在3个指标上均有较好的表现。在F1值、Precision上均取得最高值,比XGBoost等对比算法平均高出8.45%,9.22%;在Recall上,与XGBoost、LightGBM持平,高于其余6种方法。总体而言,多模型融合后进一步提高了模型的预测能力,有助于企业对流失客户做出更为精准的措施。
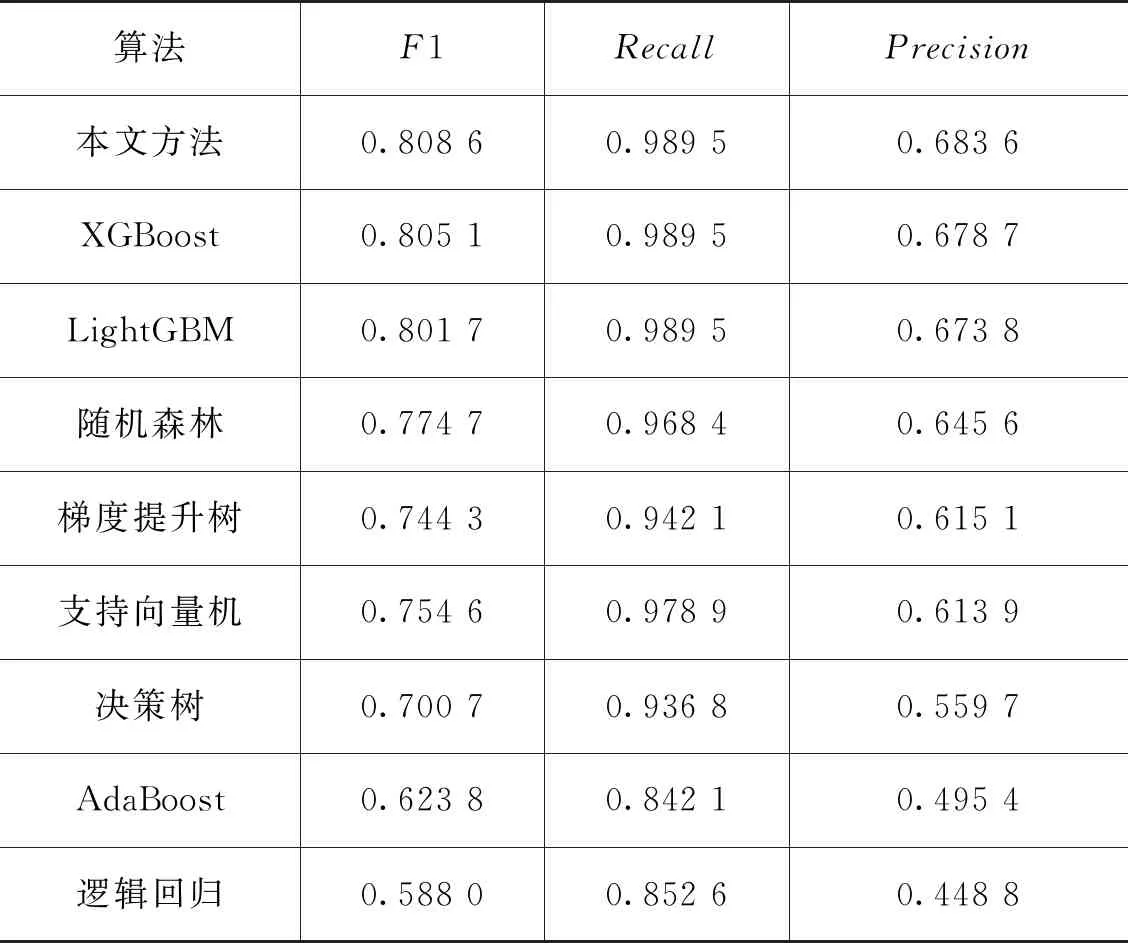
表3 评价指标对比
3 结语
客户流失预测是一个不断发展的问题,过去的研究成果解决了客户流失预测领域的一些重要问题,但仍存在一些不足。例如面对复杂度较高的电子商务客户流失数据,单个模型的预测能力有限,很难取得理想的预测结果。为此,本文基于Bagging思想,提出一种基于多模型融合的电子商务客户流失预测模型,该模型通过集成多个分类准确度高、差异度高的单一模型的输出结果,获得更好的预测结果。实验结果表明,与随机森林等模型相比,该模型拥有更好的预测效果,有助于降低客户流失率,提高企业的经济效益。由于条件所限,未能在大规模数据上验证文中提出的方法,下一步的研究中,搜集更大规模的数据用于分析预测大数据环境下的电子商务客户流失问题。
猜你喜欢
知识经济·中国直销(2018年10期)2018-11-06 07:46:52
电子测试(2018年1期)2018-04-18 11:52:35
现代营销(创富信息版)(2018年2期)2018-02-10 05:20:50
池州学院学报(2017年5期)2018-01-23 02:54:42
知识经济·中国直销(2017年7期)2017-07-24 14:12:42
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
公民与法治(2016年12期)2016-05-17 04:14:03
现代商贸工业(2016年35期)2016-04-09 06:59:14
山东青年(2016年2期)2016-02-28 14:25:41
