
融合细粒度实体类型的多特征关系分类算法
2022-11-20 13:56左亚尧黎文杰
计算机工程与应用 2022年22期
左亚尧,易 彪,黎文杰
广东工业大学 计算机学院,广州 510006
近几年,知识图谱作为人工智能领域的一项热点技术,在理论与应用研究中都取得了令人瞩目的成效,如问答系统[1]、推荐系统[2]、语义搜索[3]等。知识图谱通常用形如<实体1,关系,实体2>的三元组进行表示,分别代表头实体、尾实体以及二者的关系。知识图谱利用三元组中丰富的实体信息和关系信息,构建出一个结构化的语义知识库。而关系分类是构建完整且高质量知识图谱的不可或缺的一步,成为当前自然语言处理中的一个重要任务。其主要聚焦于确定所抽取的实体之间的关系,从而得到可以描述实体关系的知识三元组。具体地,该任务定义为,对于给定实体对e1和e2,以及包含实体对的句子s,从关系集R中匹配出给定实体对存在的关系r。例如,语句“北京是中国的首都”,关系分类致力于抽取出<中国,首都,北京>这一三元组,两个实体之间存在“国家-首都”这样的关系。
传统的关系分类方法主要有两种,基于规则的方法和基于特征向量的方法。这两种方法都需要手动设计特征,复杂度高,耗时长,并且难以捕获文本语义特征,泛化能力差。因而,当前主要基于深度学习展开工作,相对于传统方法,深度学习模型泛化能力更强,人工成本更低,但是仍然存在着不少需要解决的问题。
一方面,循环神经网络(recurrent neural network,RNN)模型[4]与长短期记忆网络(long short-term memory,LSTM)模型[5]利用序列化的结构进行关系分类任务,但仍存在长距离信息依赖问题。而基于卷积神经网络(convolutional neural networks,CNN)[6]的关系分类方法,虽然可以通过增加CNN模型的深度使之能提取长距离的语义信息,但是这种方法所能带来的改进依然有限。
另一方面,随着关系分类研究的发展,虽然用于关系分类的语义特征被不断挖掘,但如何将各种有效的语义特征进行组合,仍没有统一的标准。为此,本文提出一种融合句意、实体及其细粒度类型等多种特征信息的关系分类方法。主要贡献如下:
(1)为丰富关系分类的语义,提出了利用细粒度实体类型信息特征,来丰富实体的语义信息,增强实体与关系的表达。实验表明,该方法能明显提升关系分类任务的效果。
(2)构造了一种基于线性注意力机制的句意学习模型Type-SEBN,其中B是BERT模型,N是Nyströmformer注意力机制,S指代了句意信息,E指代了实体信息,Type指代了实体类型信息。Type-SEBN模型生成较CLS(common language specification)更有效的句意特征,并通过融合该特征,提取更丰富的实体上下文信息。模型在SemEval-2010数据集上实验效果优于现有参考模型,证明了融合多种语义特征在关系分类任务上的有效性。
1 相关工作
针对关系分类这一任务,早期工作主要基于规则和特征工程开展相关研究。近年来,随着深度学习技术的发展,学者们开始探索神经网络模型来求解关系分类任务。如从特征引入方面做改进,程威等[7]通过最短依存路径引入词性、位置和依存关系类型,并基于注意力机制建立BiLSTM(bi-directional long short-term memory)模型;王兴[8]引入WordNet上位词特征、语法关系特征以及词性标注特征。上述方法往往只是利用浅层的神经网络来学习词与词之间的关系,尚未将重心置于实体的深层特征上。
也有学者从特征提取的视角开展相关研究,刘峰等[9]认为多数模型所采用的单层注意力表达特征较为单一,引入了多头注意力机制,旨在从不同的空间上获取句子更多层面的信息,从而提高关系分类的效果;Hong等[10]考虑到特征之间存在依赖关系,对类之间的关系进行了相关探索,提出了一种新的多标签分类方法,用于关系分类的特征之间还存在重要性差异的问题;Zhong等[11]针对标签对之间可能存在重要性不同的现象,提出了标注重要性的概念,并计算出与多项式分布一致的每个实例的标注重要性程度;Zhu等[12]引入了语义权重,该权重由实体和依赖树中单词之间的最短路径的长度计算得出,使用双向门控循环神经网络(gated recurrent neural network,GRU)将关系定义编码为关系的上下文表示。此类方法并不能对句子的语义进行有效的学习,导致对实体的表达不准确,产生错误的分类。
最近,预训练模型BERT(bidirectional encoder representation from transformers)在NLP领域的多项任务中都取得不错的效果,在关系分类中也受到了极大的关注。Wu[13]和张东东[14]等通过BERT模型学习实体信息与句意信息并将其用于关系分类,但他们着眼于研究粗粒度实体类型;万莹等[15]提出基于信息增强BERT的关系分类,利用BERT获取句子特征表示向量。然而,BERT获取特征的方法还存在不足,一方面用BERT学习到的CLS句意特征不够丰富,造成关系分类的语义缺失;另一方面,BERT将句子按字生成向量,此操作会将噪声传入关系分类阶段,从而降低关系分类的精度。
为了有效地提取句子的语义信息,减少噪音的影响,本文采用BERT对所有的词进行向量编码,然后通过注意力机制,提取出有效的句意特征。此外,为了让模型更好地识别一个实体,本文还提出了基于细粒度的关系实体类型特征学习方法,利用impSpaCy实体类型分类标准,对所有的实体进行进一步的分类,再由Type-SEBN模型计算出所有同类的实体向量,并对其求平均得到细粒度实体类特征向量,最后将其放入神经网络,挖掘出深层的实体类特征。Type-SEBN模型融入了实体、句意、实体类型等三方面的特征,使实体及其之间的关系具有更加丰富的语义信息,从而有效地进行实体之间的关系分类。
2 Type-SBNE模型
2.1 模型思路
Type-SEBN模型在引入一个细粒度实体类型信息的基础上,融合了句意特征和实体特征。将一个句子放入BERT模型预训练后,分别通过三个子任务,获得实体特征、句意特征、实体类型特征。并将所取得的三种特征融合,得到复合语义特征,通过对复合语义特征进行学习,从而执行关系分类任务。整个训练过程如图1所示。
2.2 实体信息学习
在关系抽取任务中,头实体信息和尾实体信息是一种约束信息。通过提取出头、尾实体信息就可以推断出一些关系类型,减少筛选范围。在对实体信息学习之前,先将语料放入BERT中预训练。BERT模型是一个语言表征模型,经过海量数据训练而成,已被学者验证了在诸多NLP任务中有不俗的效果。本文也使用BERT模型对词向量进行编码。
首先根据要求对数据集做相关处理,所有的句子均标注出头实体、尾实体的起始与终止位置。例如可将句子“Their<head>composer</head>has sunk into<tail>oblivion</tail>.”中的头实体“composer”与尾实体“oblivion”用“<head>”“</head>”“<tail>”“</tail>”形式标注出来,Type-SEBN模型利用此标注辅助后续实体信息的抽取与实体向量的生成。同时,为了有效区别不同的句子,Type-SEBN模型在句子之前增加了[CLS]标志,以标注并区分出句子的起始位置。
学习过程如图1所示。假定输入的句子为s,句中的两个实体依照先后顺序分别定义为e1和e2。经由BERT模型处理后,输出为B,令Bi至Bj为实体e1的字向量编码,令Bm至Bn为实体e2的字向量编码,每个实体的向量最终由其字向量的均值来表示。得出实体向量后,经由tanh操作激活,并将实体向量分别接入一个全连接层,全连接层处理后,学习出其头实体特征向量H1和尾实体特征向量H2,该过程如式(1)、(2)所示:
其中,W1、W2是权重矩阵,b1、b2是偏差向量。Type-SEBN模型令W1=W2以及b1=b2,使得W1与W2、b1与b2共享相同的参数,矩阵W1∈ℝd×d,W2∈ℝd×d,即W1、W2拥有同样的尺寸,公式中的d是BERT的隐藏状态大小。
2.3 句意信息学习
BERT模型采用了标准的Scaled-Dot Attention注意力机制,该注意力机制可以表示为式(3):
其中,Q,K,V∈ℝn×d,n、d与自注意力机制中的n、d相对应。
由于BERT采用的标准自注意力的时间复杂度为O(n2),且直接采用[CLS]作为句意向量会损失其语义信息,因此本文针对BERT模型提出一种优化方案,通过组合Nyströmformer注意力机制来更好地提取句子的语义表征。Nyströmformer的结构由Nyströmformer线性自注意力层和前馈神经网络层组成,其中自注意力层的时间复杂度为O(n)且性能比标准自注意力机制层好。
对于句子s,经过BERT编码后得到字向量为B={B1,B2,…,Bn},其中n为句子的字个数。将B={B1,B2,…,Bn}输入到Nyströmformer中,首先经过其内部的线性自注意力层学习句子内部的语义联系,其中该线性自注意力层可以表示为式(4):
其中,dq是K1的维度,其作用是归一化处理;Softmax函数是对输入元素进行概率映射;Q,K,V∈ℝn×m分别表示query、key、value,它们是对注意力机制有效性的分数表示,而Q1、K1分别是对Q、K的平均池化处理,而Q={q1,q2,…,qm},K={k1,k2,…,km},则其相关公式如式(5)~(12)所示:
其中,WQ、WK、WV是在训练中学习得到的权重矩阵,假设n能整除m,则有l=n/m。
在线性自注意力层学习得到词语之间的语义信息H(1),之后将语义信息H(1)输入到前馈神经网络融合语义信息。前馈神经网络层由式(13)计算:
其中,tanh为激活函数,采用Dropout方法缓解过拟合问题,以随机丢弃一些单元的参数。
通过线性自注意力层和前馈神经网络层可以学习到词语较为浅层的语义信息H(1),再将H(1)输入到叠加了若干个线性自注意力层与前馈神经网络层的Nyströmformer,以学习较为深层的句意信息H3。
2.4 实体类型信息学习
在SemEval-2010数据集上实验发现,同属于一类的实体往往具备相似的关系,利用这一特性,可以进一步提高模型的泛化能力。因此考虑按类型学习实体信息并从中抽取共性信息,即实体类型信息。在涉及未登录实体时,可以通过实体对的实体类型信息辅助预测关系类型。如图2所示,Type-SEBN模型对于包含“关羽”与“青龙偃月刀”和“吕布”与“方天画戟”等句子进行了学习,从中获取“人类”与“工具类”这两个实体类之间有“使用”关系,在遇到数据集中未出现的实体对“李逵”与“板斧”时,可以根据“人类”与“工具类”的类型信息预测出两实体之间存在“使用”关系,假设同种类型的词向量在构成上会有较为相似的分布。例如,在语句“X是带柄的农具”中,在X处填入“锄头”或者“铲子”都合乎句意。而经BERT模型编码的词向量会学习到所编码单词的上下文信息,因此“锄头”与“铲子”在词向量上应该较为接近。
基于同类型实体的词向量具有相近的分布表示这一假设,同种类型的词向量在构成上会有较为相似的分布。定义已经标注好的实体数据集E={e1,e2,…,en},其中ei代表数据集中的第i个实体,n为实体的数量。通过使用预训练模型BERT来嵌入实体数据集E,可以得到实体嵌入向量数据集E′={e′1,e′2,…,e′n},其中e′i表示第i个实体的向量表示。然后将每个实体类内的所有实体的实体向量进行相加平均,得到每个实体类的向量表示ET={et1,et2,…,etm},其中m为实体类型的个数,其具体计算公式如式(14)与式(15)所示。类向量生成过程如图3所示。
其中,eti代表第i种实体类型向量,ej为Ai集合中实体,e′j为ej实体的向量表示,||Ai是属于第i种实体类型的数量,Ai表示实体为第i种实体类型的集合。
将句子中的两个实体按先后顺序分别定义为e1和e2,由实体e1和e2获得对应的实体类向量et1和et2。再将et1和et2送入全连接层,得到更深层的实体类特征向量et′1和et′2,计算公式如式(16)与式(17):
其中,W为共享的权重矩阵。
2.5 特征融合
由实体特征、句意特征和实体类型特征组合,得到复合语义特征。对于任意一个句子s,放入到模型中,可以得到头实体特征H′1、尾实体特征H′2和句意信息特征H′3,在通过头实体和尾实体可以计算得到头实体类型特征et′1、尾实体类型特征et′2,将这些得到的所有特征输入到前馈神经网络层中得到复合语义特征Z,其计算公式如式(10):
其中,concat(·)的作用是将向量拼接起来,Wz是权重矩阵,tanh(·)是激活函数。
最后,将得到的复合语义特征馈入到Softmax层,具体计算过程如式(19)所示:
3 实验
3.1 实验设置
3.1.1 数据集及衡量指标
本文使用的数据集是SemEval-2010 Task 8数据集[16]。该数据集出自于语义测评比赛(sematic evaluation,SemEval)在2010年发布的第八项任务——名词对语义关系的多维分类,并被广泛应用于关系分类领域。该数据集总共包含10 717条语句实例,其中训练数据总共包含8 000条语句实例,测试集总共包含2 717条语句实例。SemEval-2010 Task 8数据集中除了“其他类”外,所有的数据分布都较为均匀,基于该数据集的关系分类实验也会因此具有较为充足的可信度。
对于实验结果评测,采用macro-averaged F1评价模型性能。具体计算过程如式(20)~(23)所示:
3.1.2 实验参数设置
实验参数的设置主要是为了使模型达到最佳性能。实验过程中为了减少过拟合现象造成的影响,训练过程中引入了Dropout策略,模型采用Adam优化器进行优化,具体参数设置如表1所示。
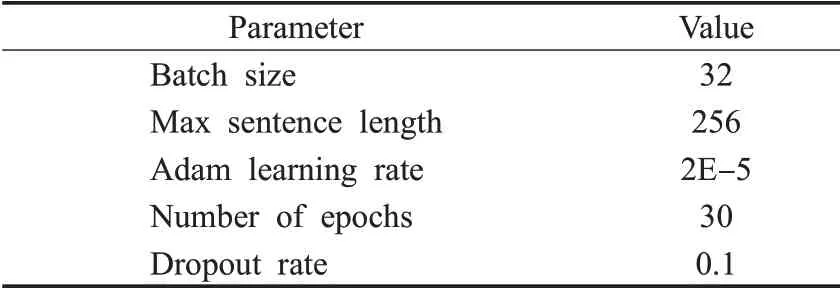
表1 参数设置Table 1 Parameter settings
3.2 实验结果与分析
Type-SEBN的F1变化如图4所示,由于BERT模型本身是经过了大量语料进行预训练操作,本模型在一开始便取得不低的F1。随着模型训练轮次的增加,模型逐渐趋于收敛,并且此时实验获得了最高88.61%的F1值。
将Type-SEBN与一些在SemEval-2010 Task 8[16]数据集上实验的方法进行比较,包括支持向量机(support vector machine,SVM)[17]、CNN+Softmax[18]、CR-CNN(classifying relations by ranking with convolutional neural networks)[19]、Attention CNN[14,20]、Att-Pooling-CNN[21]、Att-RCNN(attention based RCNN)[22]、RNN[23]、MVRNN(matrix-vector recursive neural networks)[24],模糊认知图(fuzzy cognitive map,FCM)[25]、Entity Attention Bi-LSTM[26]、双向GRU Attention模型(BiGRU-attention,BGRU-Att)[27]和R-BERT[13]。如表2所示,Type-SEBN模型效果优于其他参考模型。
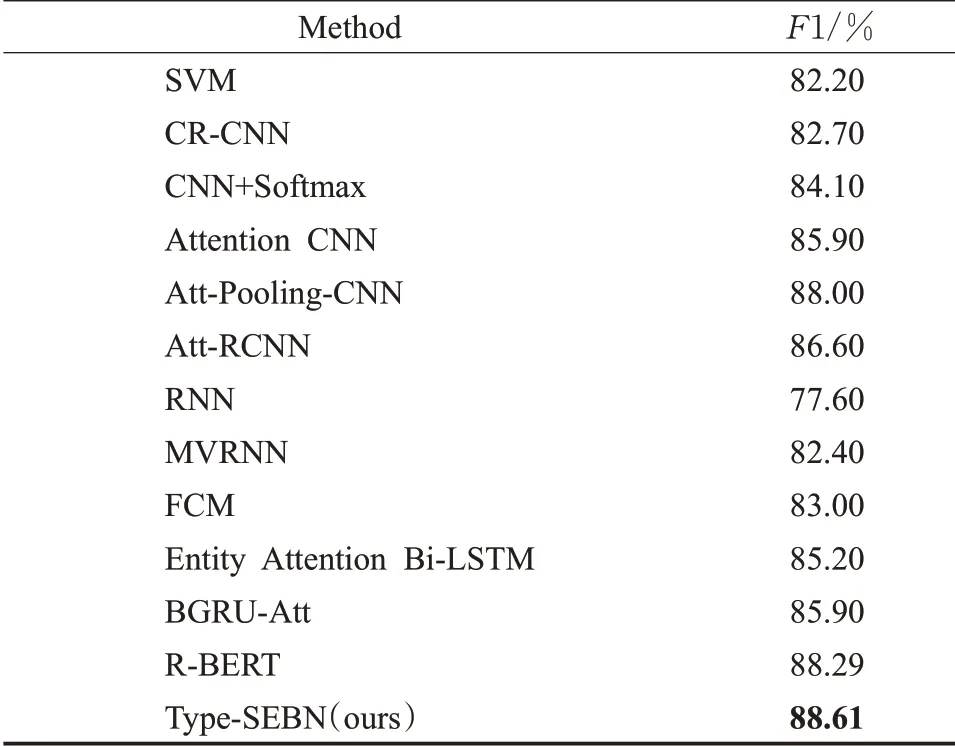
表2 Type-SEBN模型与其他参考模型的效果比较Table 2 Comparison of effect of Type-SEBN model with other reference models
相关参考模型中,较为值得注意的模型是Entity Attention Bi-LSTM、Att-RCNN、Att-Pooling-CNN等。其中,Att-Pooling-CNN证实了CNN模型在结合了有效的注意力机制后,确实可以获取比较重要的关系类型特征。而采用多头注意力机制的Entity Attention Bi-LSTM模型也取得不错的效果。多头注意力机制的引入是为了模型能够捕获到不同方面上的重要特征,相比单头的注意力机制在改进模型的多种特征提取上具有较大的优势。纵观相关参考模型,可以看出不少模型会通过引入注意力机制来改进模型的性能。对多组增加注意力机制与未增加注意力机制的模型进行对比,可以发现引入了注意力机制的模型的表现更好,验证了优化注意力机制是改进深度学习模型的一个有效方法。通过实验对比,可直观看出Type-SEBN模型优于参考模型,验证了采用BERT模型结合Nyströmformer对句意信息、实体信息、实体类型信息的复合语义特征的学习是一个有效的关系分类方法。
3.3 消融实验
本文在消融实验中设置了SEBN-No-Sentence、SEBN-No-Entity、SEBN、Type-SEBN四种实验配置,通过控制变量法,有效地测评出不同的特征对关系分类任务的影响。
(1)SEBN-No-Sentence:仅使用实体特征进行关系分类。
(2)SEBN-No-Entity:仅使用语义特征进行关系分类。
(3)SEBN:融合实体特征和语义特征进行关系分类。
(4)Type-SEBN:融合实体特征、语义特征以及外部引入的实体类型进行关系分类。
每个实验融合哪些特征,具体如表3所示。
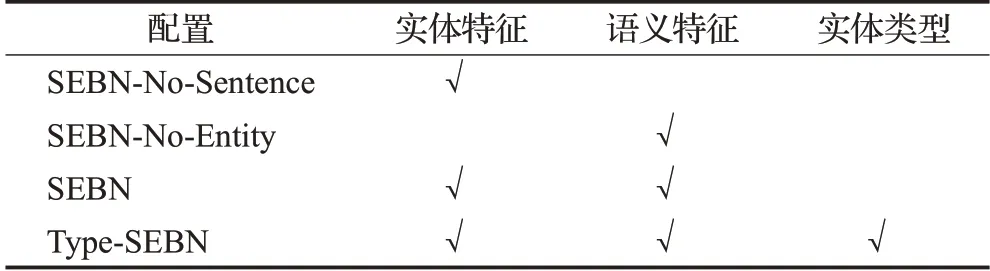
表3 参数消融与实验结果Table 3 Parameter ablation and experimental results
由表4可知,Type-SEBN模型的F1值达到了88.61%,效果最好。通过对比可知实体信息、句意信息、实体类型信息有助于提升关系分类的结果,这三个特征对于关系分类任务都是有效特征,每个特征都有效地提高了关系分类的准确率。如图5所示,由于四种配置的收敛轮次不同,为了便于分析,本文取了四种配置在最终的20轮次中的表现作为对比。从图5可以看出,四种配置在经过多轮学习之后模型逐渐收敛,并且在最终收敛阶段,Type-SEBN、SEBN、SEBN-No-Entity、SEBN-No-Sentence这四种配置在关系分类任务的表现上依次递减。从四种配置在图中的对比可以看出SEBN-No-Sentence的效果比SEBN-No-Entity差,这一结果验证了在BERT模型的学习中,句意信息在关系分类实验的影响力比实体信息的影响力大。此外,从图中可以看出SEBN-No-Entity与SEBN-No-Sentence收敛速度相比另外两种配置要快,在一定程度上说明复合程度较低的语义特征,模型学习所耗费的时间较短。

表4 Type-SEBN消融模型的效果比较Table 4 Comparison of effect of Type-SEBN ablation models
4 结束语
针对目前关系分类任务中语义信息不够丰富或无关分词引入噪声的问题,本文在BERT预训练模型的基础上结合注意力机制,实现有效句意信息的提取。此外,还提出实体类向量学习方法,用以捕获同类实体的共性信息,进一步提高分类模型的泛化能力。通过融合实体信息、实体类型信息和句意信息,构建Type-SEBN模型,实现关系分类。本文对于得出的三个特征向量进行连接,然后将结果送入全连接层进行关系分类。由于实体类信息、语义信息、实体信息这三个特征对于关系分类的重要性不一样,后续工作可以考虑在全连接层之前加入注意力机制,更好地权衡这三个特征的重要性,从而进一步提升分类效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
人间(2015年21期)2015-03-11
