
加强类别关系的农作物遥感图像语义分割
2022-11-18 05:35董荣胜马雨琪刘意李凤英
中国图象图形学报 2022年11期
董荣胜,马雨琪,刘意,李凤英
桂林电子科技大学广西可信软件重点实验室,桂林 541004
0 引 言
农作物遥感图像语义分割旨在对农作物遥感图像进行像素级分类,将图像分割为具有不同语义标识的区域。对农作物遥感图像进行语义分割能精准、快速地获取农作物的面积以及分布情况,这对监测农作物面积、长势或灾害,识别农作物类型,评估农作物产量等方面有着重要的研究意义(炼晨,2021)。
图像分割是遥感技术中一个重要应用。国内外学者对图像分割技术展开了大量的研究。传统的图像分割方法有阈值分割法、区域分割法和边缘检测法等。阈值分割法由于其方法简单且稳定,广泛应用在图像分割技术中(刘硕,2020)。其中Otsu法(Otsu,1979)是一种对阈值选择相对合理、分割效果较好的方法。它根据图像的灰度特性,将图像分成前景和背景两个部分,然后计算出一个最佳阈值,使得前景和背景的区分度达到最大。但Otsu法没有考虑像素的空间分布以及目标和背景占比不平衡的情况。这使得阈值选择受限,而区域分割法可以弥补这一点。区域生长法(Adams和 Bischof,1994)是区域分割中常用的方法,本质是根据一定规则将相似的像素不断聚合形成大区域块实现分割(王秋萍 等,2019)。但该方法会造成图像的过分割(侯红英 等,2019)。与区域分割法不同,边界分割法可以利用不同区域之间的像素或灰度检测出区域边缘,以此分割图像。常用的边缘检测微分算子有Roberts(Roberts,1963)、Sobel和Prewitt(Prewitt,1970)等。传统的图像分割技术只能针对一些简单场景中的物体,对于地物复杂的海量遥感图像,耗时长且效果并不理想,需要新的方法来解决。
随着大规模数据集的出现,深度学习技术在图像语义分割领域越来越具优势。基于深度学习的语义分割,是对每个像素进行分类。相比传统方法,深度学习具有兼顾速度和精度的优势。Shelhamer等人(2017)运用全卷积网络(fully convolutional networks, FCN)将全连接层替换为卷积层后提取图像的卷积特征,用反卷积层恢复特征图的尺寸,保留了输出图像的空间信息。Ronneberger等人(2015)提出U-Net网络结构。U-Net采用一种编码—解码网络,将编码器中的空间信息和解码器中的语义信息结合,以恢复在下采样中丢失的空间细节。Chen等人(2018)在DeepLab网络中添加了金字塔池化模块(atrous spatial pyramid pooling,ASPP),用来提取感受野不同的特征信息。Zheng等人(2020)提出FarSeg网络,通过前景—场景关系模块学习场景与前景之间的关系,关联与前景相关的上下文以增强前景特征,用来解决遥感图像中背景类内存在的差异。同时,利用前景感知优化抑制背景中的无关信息,将网络集中于前景,从而减轻前景背景不平衡问题。
一些学者将注意力机制引入到语义分割网络中捕获像素间的长距离相关关系,从全局信息中提取出更重要的信息,以达到更好的分割效果。Hu等人(2018)应用SE(squeeze-and-excitation)注意力模块学习通道特征间的相关性,并给每个通道分配不同权重,以强调有用的通道特征,抑制无关的通道特征。Woo等人(2018)提出的CBAM(convolutional block attention module)模块结合了空间和通道注意力机制,涵盖了更丰富的特征。Hou等人(2021)在CA(coordinate attention)模块通过嵌入位置信息到通道注意力中,以获取跨通道的方向与位置信息,使网络能更准确地定位并识别目标区域。
伴随着人工智能和计算机视觉技术的广泛应用,一些学者开始将基于深度学习的图像分割技术应用到农作物遥感图像分割中,并取得较好的效果。Pena等人(2019)将SegNet(Badrinarayanan等, 2017)用于农作物分割中,相比传统的机器学习算法有了大幅度的提升。张诗琪(2020)搭建了基于农作物分类识别的GoogLeNet(Szegedy等,2014)和U-Net两种深度学习网络,将卷积方式改为深度可分离卷积,减少卷积参数量并进一步提升网络运行效率。徐馨兰(2020)针对农作物遥感图像提出ELGNet语义分割网络,在EfficientNet(Tan和Le,2020)网络中添加了一种基于全局与局部交互的模块,降低了长距离信息损失,优化了网络的学习能力。
尽管上述网络取得了较好的成果,但是没有针对农作物遥感数据集中存在的问题做进一步处理,这些问题主要体现在以下3个方面:1)不同类别的样本数量差异很大且分布极不平衡,如背景类的样本多,其他类别的样本少。这会导致网络训练过拟合、鲁棒性差。2)部分样本中不同农作物的外形特征相似度高,使得网络难以分辨外形相近的不同农作物。如玉米与薏仁米外形相似,图1(a)中网络将玉米错误分类为薏仁米,图1(b)中薏仁米被错误分类为玉米。而相同农作物的外形特征差异性大,使得网络将同种农作物错误分类为其他农作物。如图1(c)中网络将薏仁米错误分类为烤烟。3)农作物在农用地上的分布通常相邻,且农用地中的地物信息复杂多样,干扰信息多。这会导致相邻农作物的边界分割不准确。如图1(d)中薏仁米与玉米的边界不清晰,与烤烟的边界不完整。

图1 可视化示例Fig.1 Visualization examples ((a) the first misclassification of similar classes;(b) the second misclassification of similar classes; (c) misclassification of the same class; (d) unclear boundary)
基于此,本文提出一种加强类别关系模块的语义分割网络CRNet(class relation network)以解决上述问题。该网络由编码器、类别关系模块和解码器组成。编码器使用ResNet-34(He等,2016)作为主干网络,自底向上逐步下采样以提取图像中的特征,并通过特征金字塔结构自顶向下将不同阶段的特征图进行结合,以融合低阶的空间信息和高阶的语义信息。在类别关系模块中,引入一种新的类别特征加强注意力模块(class feature enhancement,CFE),分别对编码器中每个阶段的特征进行学习,获取其中不同农作物间的语义特征差异和同种农作物间的相关性,以增强对不同农作物语义特征的识别能力,缓解了因为农作物的特征类间差异小、类内差异大导致的错分问题。解码器将不同尺度的特征图融合并还原至初始分辨率,充分结合各个尺度的特征信息来进行最终的分类,能使分割后的相邻农作物的边界更加清晰、完整。同时为了缓解数据不平衡问题,本文通过数据增强,减少背景类的样本占比来扩充其他类别的样本数量,并进一步引入一种类别平衡损失函数(class-balanced loss, CB loss)(Cui等,2019)以解决数据不平衡问题。
本文的主要贡献有如下3个方面:1)提出了一种用于农作物遥感图像语义分割的网络CRNet;2)提出了类别关系模块,并引入CFE注意力模块,以增大不同农作物的语义差异和相同农作物特征的相关性。3)本文通过数据增强和CB损失函数缓解了背景和农作物的样本不平衡的问题。
1 网络模型
将图像进行数据增强操作后,输入到CRNet网络中。CRNet网络由编码器、类别关系模块和解码器构成,如图2所示。编码器首先通过主干网络ResNet-34提取特征,然后使用特征金字塔结构逐步融合从高阶到低阶的特征。类别关系模块采用3层并行结构,分别利用类别特征加强注意力模块CFE学习不同尺度特征中的相关关系。最后解码器将它们融合并通过上采样恢复图像分辨率。
1.1 数据增强
由于农作物遥感图像数据集中地物数量不平衡且样本数量不足,网络容易出现过拟合的问题。针对此类问题,本文对样本数据进行处理。如图3所示,在数据预处理阶段使用任意的水平翻转、垂直翻转、缩放、亮度调整和对比度调整等图像增强方式以及数据增广来降低不同种类农作物样本数量的差距,丰富数据的多样性。
1.2 加强类别关系的分割网络CRNet
1.2.1 编码器
编码器由作为主干网络的ResNet-34和特征金字塔结构(feature pyramid network,FPN)(Lin等,2017)组成。见图2(a)。主干网络详细结构如表1所示,初始层替换成ENet(efficient neural network)(Paszke等,2016)的初始层,由1个核为3×3、步长为2的卷积层和1个核为2×2、步长为2的池化层拼接组成。作为基本组成单元的残差块由2个核为3×3的卷积层组成。每经过一个阶段,特征图尺寸下采样至一半,同时通道维度加倍,以保持信息量不变。

图2 本文方法CRNet的结构框架图Fig.2 The framework of the proposed method CRNet ((a) encoder; (b) category relation module; (c) decoder)

图3 数据增强示例Fig.3 Examples of data enhancement ((a) original image; (b) flip horizontal; (c) flip vertical; (d) scaling; (e) lightness adjustment; (f) contrast adjustment)

表1 特征提取网络结构Table 1 Network structure of feature extractors
在特征金字塔结构中,最后一个阶段的输出特征图S5经过2倍双线性插值法上采样后,与上一个阶段的输出特征图S4逐元素相加,进行特征融合后得到特征图U3。以此类推,逐步特征融合得到特征图U2和U1。
深层网络通过下采样不断增大感受野,能提供丰富的语义信息,但在下采样的过程中丢失了大量农作物的空间细节信息,使得网络在上采样时无法还原农作物的位置信息,降低了图像分割的准确率。通过特征金字塔结构,将高阶语义特征与低阶空间特征进行跨尺度融合,降低下采样带来的信息损失,并在参数数量基本不变的情况下,生成了表征能力更强的特征,使编码器提取出更为清晰的农作物边界,提升了图像的分割精度。
1.2.2 类别关系模块
针对农作物遥感图像地物信息复杂、农作物类间差异小、类内差异大的问题,本文引入类别关系模块,通过CFE注意力模块学习农作物之间的相关关系,获取同种类农作物特征之间的相关性,以及不同种类农作物特征之间的差异性。
如图2(b)所示,类别关系模块由3层平行结构组成。由编码器输出的3个层级的特征分别经过1×1卷积层后,通道维度降为5。这里的1×1卷积层可以视为一个分类器,将全局特征映射到5个通道中,与分类类别一一对应,每个通道即可代表一个类别的特征。之后,每个层级的特征图分别输入CFE注意力模块。
CFE注意力模块包含通道注意力和空间注意力。通道注意力机制学习不同通道,即农作物之间的语义差异,并为每个类别分配不同的权重;加强位置信息的空间注意力机制对空间中的上下文信息进行编码,获取每个通道中像素之间,即同种农作物特征之间的相关关系,并为每个像素分配不同的权重。该模块可以获取不同类别中更具分辨性的特征,增大了不同农作物间的特征差异;同时,使得相同类别的特征中包含更丰富的上下文信息,有利于降低对于同种农作物的错误分类。
1.2.3 类别特征加强注意力模块
受CA模块和CBAM模块的启发,本文提出了一种类别特征加强注意力模块(CFE),其由通道注意力机制和加强位置信息的空间注意力机制组成。
1)通道注意力模块。通道注意力模块通过引入通道注意力机制学习每个通道,即每个类别的特征之间的相关关系并为它们分配权重,以强调相关性强的类别的特征,抑制相关性弱的类别的特征,从而增加不同类别特征之间的区分度。如图4(a)所示,具体过程如下。
给定特征图x∈RC×H×W,分别通过全局平均池化和全局最大池化,在空间维度上对通道信息进行编码,同时对全局上下文信息建模,得到每个通道的全局特征。
全局平均池化对特征图在空间维度上进行压缩,以聚合农作物的空间信息。在第c个通道上的全局平均池化计算为
(1)
式中,H和W分别表示特征图的高度和宽度,xc(i,j)表示第c个通道的坐标为(i,j)的特征值。特征图x经过全局平均池化后,得到xcg∈RC×1×1。
全局最大池化可以收集农作物独特的特征,在通道上保留更多的纹理信息。在第c个通道上的全局最大池化计算为
(2)
式中,H和W分别表示特征图的高度和宽度,特征图x经过全局最大池化后,得到xcm∈RC×1×1。
为了充分利用全局信息,将xcg和xcm分别通过1×1卷积层进行建模,在每个卷积操作后都附加批量归一化(batch normalization,BN)层(Ioffe和Szegedy,2015),对数据进行标准化处理,以提高训练效率,增强网络泛化能力,减少过拟合。再通过ReLU(rectified linear units)激活函数层(Glorot等,2011),增加网络的非线性表达能力,改善梯度消失问题,加快梯度下降收敛的速度,之后分别得到两个特征图x1和x2。计算式为
x1=δ(BN(F1(g(xc))))
(3)
x2=δ(BN(F1(m(xc))))
(4)
式中,F1为1×1卷积变换函数,BN表示批归一化处理,δ表示ReLU激活函数。
接着,将x1和x2逐元素相加,并通过sigmoid激活函数生成一个权重向量,用以给各通道分配权重。将其与输入x进行逐通道相乘,得到输出特征图x′。至此完成对通道域注意力信息的权重重标定,即增加相关通道上特征的权重,如农作物的外形特征,减少无关通道上特征的权重,如无关的背景。
特征图中不同通道的重要性不同,重要的特征被加强,不重要的特征被减弱。该过程表示为
x′=σ(F1(x1)+F1(x2))⊗x
(5)
式中,F1为1×1卷积变换函数,σ表示sigmoid激活函数,⊗表示对应元素相乘,特征图x′∈RC×1×1。
2)加强位置信息的空间注意力模块。在增强位置信息的空间注意力中,通过学习空间中水平和竖直方向上的上下文信息片段,使特征图中每个像素都与水平或竖直方向建立联系。从而增加了农作物的空间特征,如农作物的形状、分布等,加强了同种农作物间的关联。如图4(b)所示。

图4 CFE模块Fig.4 The CFE block ((a) channel attention module; (b) spatial attention module
首先将特征图x′进行重排,得到x′w∈RW×H×C和x′h∈RH×C×W,然后通过全局平均池化,得到水平和竖直方向上的全局上下文表示。在第W个通道上的全局平均池化计算为
(6)
式中,H和C分别表示特征图的高度和宽度,x′w(i,j)表示水平方向上坐标为(i,j)的特征值。特征图x′w经过水平方向上的全局平均池化后,得到xwg∈RW×1×1。
在第H个通道上的全局平均池化计算为
(7)
式中,C和W分别表示特征图的高度和宽度,x′h(i,j)表示竖直方向上坐标为(i,j)的特征值。特征图x′h经过竖直方向上的全局平均池化后,得到xhg∈RH×1×1。
为了充分利用水平方向和竖直方向上的特征图的信息,将上述两个特征图在通道维度上进行拼接,得到一个维度为(W+H)×1×1的张量。然后通过1×1卷积层对其进行建模,得到张量f。计算过程可表示为
f=F1([xwg,xhg])
(8)
式中,[·,·]表示沿通道维度的拼接操作,F1为1×1卷积变换函数。

(9)
式中,i∈(1,H),j∈(1,W),H和W分别表示特征图的高度和宽度,σ表示sigmoid激活函数,x′为经过通道注意力机制输出的特征图,y为最终输出的特征图。
1.2.4 解码器
如图2(c)所示,解码器包含3层轻量级解码结构。每层分别将不同尺度的特征图上采样至统一尺寸并进行特征融合,使输出特征图包含不同尺度的上下文信息,便于网络识别不同尺度的农作物特征,提高对于农作物边界的分割准确度。
每一层轻量级解码结构如图5所示,特征图通过1×1卷积层后,采用双线性插值法上采样至256×256像素的分辨率。
最后将3层特征图通过逐元素相加进行特征融合,通过2倍上采样生成与输入图像尺寸相同的输出特征图,使用1×1卷积作为像素级分类器,得到最终的预测图。

图5 轻量级解码结构Fig.5 Decoder structure
1.3 损失函数
为了进一步缓解类别不平衡问题,引入CB 损失函数来替代传统的交叉熵损失函数(cross entropy,CE loss)。类别平衡损失处理不平衡数据集的方法主要是通过引入一个与每个类的样本数成反比的加权因子,以平衡损失。类别平衡损失函数计算为
(10)
式中,En表示样本的有效数量,ny表示类别y的标签数量。p是预测类概率。β= 0对应没有重新加权,β→1对应于用反向频率进行加权。L(p,y)为常用的损失函数,本文采用的是Focal损失函数(Lin 等,2020)。
2 实验与分析
实验包括CRNet在Barley Remote Sensing数据集(https://tianchi.aliyun.com/dataset/dataDetail?Spm=5176.12281978.0.0.76944054SUIPaL&dataId=74952)上的消融实验以及与现有网络的对比实验。
2.1 数据集介绍
实验使用的Barley Remote Sensing数据集源于阿里天池的“县域农业大脑AI挑战赛”。如图6所示,该数据集为 2019年无人机航拍的贵州省兴仁市的农作物高分辨率遥感图像,其光谱为可见光波段(RGB)。数据集将训练样本分为5类:薏仁米(标记 1)、玉米(标记 2)、烤烟(标记 3)、建筑(标记 4)以及其他(标记 0)。

图6 Barley Remote Sensing数据集样本Fig.6 Samples of the Barley Remote Sensing dataset
数据集为4幅大尺寸遥感高分辨率图像,平均大小1.8 GB。尺寸从18 576×68 363像素~55 128×49 447像素,不可直接将其作为神经网络的输入。
将图像裁剪为多个512×512像素的子图。裁剪后,数据集共有11 750幅子图,其中训练集含有9 413幅图像,测试集含有2 337幅图像,训练集和测试集的比例约为4 ∶1。图7所示为5种类型的部分图像和标签,其中薏仁米与玉米的外形差异小、与烤烟的分布特征相似度高;薏仁米和玉米的类间差异大;并且周围地物结构具有复杂性。
如图8所示,该数据集中不同农作物的数量分布不均,是一个典型的类别不平衡的样本。其中其他占比达到76.3%,而农作物占比仅为4.4%、6.6%和10%,使得学习到的农作物特征不足,导致网络的泛化能力减弱,难以训练出合适的网络。为了解决该问题,本文在对高分辨率农作物遥感影像进行裁剪时,减少了其他类别占比大的图像的数量。
2.2 实验环境及参数设置
实验环境使用的深度学习框架为Pytorch1.7,开发环境为Python3.8,操作系统为Ubuntu 18.04.3 LTS,GPU选用一张GeForce RTX 2080 Ti,显存大小为11 GB。
实验参数设置如下:输入图像为512×512像素;批尺寸为10;迭代次数为100;权重衰减为 0.000 5;初始学习率为0.000 5;优化器采用Adam算法,动量参数为0.9。同时引入poly衰减策略来调整学习率,即
(11)
式中,lr为本轮学习率,lrbase为初始学习率,e为当前迭代次数,enum是最大迭代次数,p为0.9。

图7 Barley Remote Sensing数据集子图样本Fig.7 Samples of the Barley Remote Sensing Dataset’s subgraph ((a) else; (b) flue-cured tobacco; (c) barley rice; (d) corn; (e) building; (f) ground truth 0; (g) ground truth 1; (h) ground truth 2; (i) ground truth 3; (j) ground truth 4)
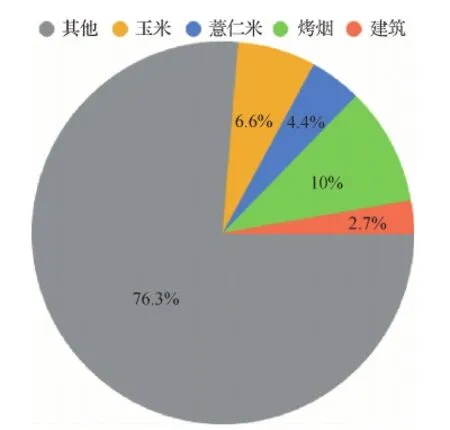
图8 样本类别不平衡Fig.8 Category imbalanced sample
2.3 评价指标
为评估图像语义分割方法的性能,除了运行时间、内存大小外,主要是从语义分割的准确性进行衡量。常用的性能评价指标主要包括交并比(intersection over union,IoU)、平均交并比(mean intersection over union,MIoU)和总体精度(overall accuracy,OA)。
设测试数据集中总共有k个类,pii表示第i类数据中被标记为第i类的数量,pij表示第i类数据中被标记为第j类的数量,pji表示第j类数据中被标记为第i类的数量,N为图像中像元总数。
1)交并比IoU表示分割结果与其真实值的重合度,计算为
(12)
2)平均交并比MIoU是语义分割的标准度量。在每个类别上计算IoU值后,求和再平均,即
(13)
3)总体分类精度OA等于被标记正确的像素占总像素的比例,计算为
(14)
2.4 不同注意力模块的消融实验
为了验证本文提出的注意力模块的有效性,在 Barley Remote Sensing数据集上对未添加注意力模块以及添加不同注意力模块进行测试。实验结果如表2所示。

表2 类别关系模块中未添加以及添加不同注意力的结果对比Table 2 Comparisons results of adding different attention models or not on classes relation module /%
实验表明,在网络中添加注意力模块比未添加注意力模块的MIoU和OA有所提高。在网络中添加CFE注意力模块比添加CBAM或CA注意力模块的MIoU和OA分别提高了3.84%和2.36%、2.95%和2.33%,证明了CFE注意力模块的有效性。
如图9所示,为了增加注意力模块的可解释性,本文对训练后的网络进行热力图(heatmap)可视化,该技术将网络对注意力关注的区域用热力图的方式表现出来,热力图中偏红色和黄色区域表示被分配较大的权重。对于第1幅热力图,CBAM注意力关注了无关的背景区域且没有分割出左下角的玉米;CFE注意力分割了完整的农作物,并抑制无关背景。对于第2幅热力图,未添加注意力的网络对于边界的分割不完整并且没有关注到农作物的细节特征。CFE注意力突出了农作物的外形特征;对于第3幅热力图,CA注意力没有关注到农作物;CFE注意力不仅关注到了农作物的全局分布,也关注到了局部细节。

图9 未添加及添加不同注意力模块的热力图比较Fig.9 Comparison of heatmap among adding different attention models or not ((a) original images; (b) ground truth labeling; (c) no attention mechanism; (d) CBAM; (e) CA; (f) CFE(ours))
2.5 不同损失函数的消融实验
为了减少类别不平衡对实验结果产生的负面影响,本文选用多个损失函数做对比实验。如表3所示,使用CB损失函数的结果要优于CE、BCE和Focal损失函数。其中,使用CB损失函数的MIoU和OA比使用Focal、BCE、CE损失函数分别提高了2.73%和1.81%、1.76%和1.26%、1.59%和1.7%。由此说明了CB损失函数可以缓解样本不平衡问题,改善分割结果。

表3 不同损失函数的结果对比Table 3 Comparisons results of different loss functions on performance /%
2.6 CRNet与经典网络的对比实验
为了验证本文网络的有效性,在Barley Remote Sensing数据集上进行大量对比实验。对比网络有 LinkNet(Chaurasia和Culurciello,2017)、PSPNet(pyramid scene parsing network)(Zhao等,2017)、DeepLabv3+、FarSeg、STLNet(statistical texture learning network)(Zhu等,2021)和FPN。如表4所示,CRNet在MIoU和OA上为68.89%和82.59%,与LinkNet、PSPNet、DeepLabv3+、FarSeg、STLNet、FPN相比分别提高了7.42%和4.35%、4.86%和2.6%、4.57%和3.01%、4.36%和2.5%、4.05%和2.45%、3.63%和1.85%。在玉米、薏仁米和建筑上的IoU均达到了最优。
图10给出了网络在测试集上的可视化实验结果。可以发现6种比较网络均存在不同程度的错分和边界划分不清。对于第1幅测试图,由于其他类和玉米相似,不易区分,6种网络均把其他类错分成玉米或建筑。对于第2幅测试图,由于玉米和薏仁米的类间差异小,4种网络把左下角的薏仁米错分为玉米。对于第3幅测试图,由于薏仁米的类内差距大、分布不同,6种网络均把薏仁米错分成烤烟或其他。对于第4幅测试图,4种网络划分的边界不清晰不完整。对于第5幅测试图,6种网络均未能正确地分割出建筑和其他类。相比于其他网络,CRNet的分割效果与真实标签相近,能够区分出外形相似的不同农作物以及识别出差异较大的同种农作物,并且分割出完整清晰的边界,说明本文网络具有较好的分割效果。
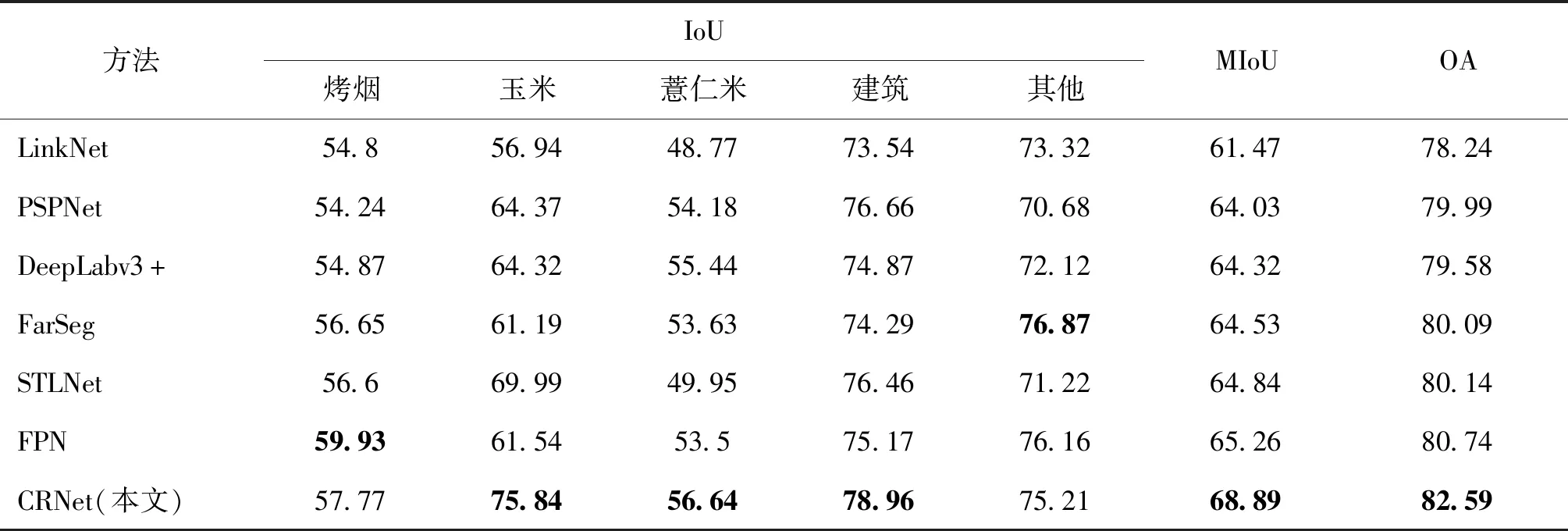
表4 在 Barley Remote Sensing 数据集上不同方法的结果对比Table 4 Comparisons results of different methods on Barley Remote Sensing Dataset /%

图10 不同方法在 Barley Remote Sensing 数据集上的图像分割效果Fig.10 Image segmentation effects of different methods on Barley Remote Sensing Dataset((a) original images; (b) ground truth labeling; (c) LinkNet; (d) PSPNet; (e) DeepLabv3+; (f) FarSeg; (g) STLNet; (h) FPN; (i) CRNet)
表5是6种网络的参数量和推理速度的对比结果。推理速度在单张2080 Ti GPU下进行测试,输入分辨率为512×512像素。CRNet的参数量和推理速度分别为21.98 M和68帧/s。相较于LinkNet和FPN,CRNet的参数量和推理速度有所增加,但在MIoU和OA方面比LinkNet 提高7.42%和4.35%,比FPN提高3.63%和1.85%。CRNet在参数量、推理速度、MIoU和OA方面,均优于PSPNet、DeepLabv3+、FarSeg和STLNet。说明本文网络的性能更好。

表5 不同方法的参数量和推理速度对比结果Table 5 Comparison of different methods in terms of the number of parameters and inference speed
3 结 论
本文针对农作物遥感图像中类别不平衡以及部分样本中不同农作物特征相似、相同农作物特征差距大的问题,提出了一种加强类别关系的农作物遥感图像语义分割网络CRNet。在预处理阶段,减少类别占比大的图像,并进行数据增强和增广处理,以减小不同样本数量的差距,丰富数据的多样性。CRNet网络通过主干网络ResNet-34对图像进行特征提取,然后利用金字塔结构有效地捕获农作物的多尺度特征。在类别关系模块中通过CFE注意力模块增大不同农作物之间的区分度,加强同种农作物内在的关联性。在解码器中通过融合不同尺度的农作物特征,使网络保留更多的细节和边界信息。除此之外,网络采用CB损失函数以改善样本类别不平衡的问题,提高分割精度。
在Barley Remote Sensing数据集上进行了大量的实验,验证了CFE注意力模块和CB损失函数的有效性,表明CRNet网络相对于其他语义分割方法在农作物语义分割方面更具有优势。但本文方法仍有需要改进的地方: 1)CRNet网络分割出的地物边界有的不是很平滑,部分类别的MIoU偏低。在接下来的工作中,可以改进损失函数,重点关注边界的分割;优化网络模型,提高部分类别的准确率。2)CFE注意力模块的结构比CBAM和CA注意力模块的结构更复杂,使得CRNet网络参数量较多,推理速度更慢。后期研究将进一步对CFE注意力模块进行优化,在不降低网络准确性的前提下,改进注意力结构,提高网络的速度。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2021年16期)2021-11-26
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
