
时空特征融合网络的多目标跟踪与分割
2022-11-18 06:19刘雨亭张开华樊佳庆刘青山
中国图象图形学报 2022年11期
刘雨亭,张开华,樊佳庆,刘青山
南京信息工程大学数字取证教育部工程研究中心,南京 210044
0 引 言
多目标跟踪与分割(multi-object tracking and segmentation,MOTS)是对视频中出现的多个对象分别进行跟踪和实例级别的分割,是集检测、跟踪和分割为一体的新颖任务(Voigtlaender等,2019a),具有广阔的应用场景,例如安防监控、视频剪辑和智能交通等。但该任务存在巨大挑战,既要克服跟踪过程中多个目标的重叠与遮挡,又要对每个目标进行像素级别的分割。
多目标跟踪与分割问题与两个计算机视觉方向有较大联系,一是多目标跟踪(方岚和于凤芹,2020;王雪琴 等,2017)方向,二者的区别在于对目标的检测和分割的细粒度不同;二是图像的实例分割(林成创 等,2020)方向,图像实例分割着力点在单幅图像的分割,多目标跟踪与分割更侧重于将视频中每一帧分割出的目标联系起来,因此国内外学者的探索研究基本从这两个方向展开。基于多目标跟踪的思路中,Voigtlaender等人(2019a)提出的TrackR-CNN(track regions with convolutional neural networks features)网络是多目标跟踪与分割方向的开山之作,TrackR-CNN将原有的多目标跟踪网络框架中的检测部分替换成了Mask R-CNN(mask regions with convolutional neural networks features)网络,以此获得目标的实例级别分割结果,其他如外观特征提取、帧间匹配依旧沿用多目标跟踪领域的方法。Lin等人(2020)引入改良的变分自编码器(modified variational autoencoder)增强网络特征表达问题,在一定程度上解决了目标遮挡问题。Xu等人(2020)提出PointTrack网络,充分利用多目标跟踪与分割中实力级别前景与背景的特征差别设计网络,将其用于关联匹配阶段,较好解决了目标跟踪轨迹的跳变问题。Porzi等人(2020)提出的MOTSNet(multi-objects tracking and segmentation net)通过引入光流网络进行实例级别的跟踪与分割。综上可以看出,多目标跟踪方法可以通过增加图像的实例分割模型来解决多目标跟踪与分割的问题。另外,基于图像实例分割的角度,Yang等人(2019)提出在Mask R-CNN基础上增加目标外观特征提取分支,通过计算不同帧之间对象的外观特征相似度,再进行匹配来对不同帧之间的同一对象进行关联。Athar等人(2020)提出一个端到端的STEm-Seg(spatio-temporal embeddings for instance segmentation in videos)网络,借鉴图像实例分割领域将实例分割问题视为像素点分配问题的思路来解决多目标跟踪与分割问题,将不同帧的图像通过STEm-Seg网络建模成每个对象符合一个独立的3D高斯分布,根据高斯分布的特点,将不同的像素点分配到不同的实例对象中,该模型最大的亮点在于提出了一个端到端的多目标跟踪与分割的框架。
综上两种思路,多个模型都存在一个问题,即没有充分挖掘连续视频帧中的时空特征与空间特征,而面对视频中目标的遮挡与物体位移变化等一系列复杂问题又需要依靠强时空特征才能解决。如何设计一个充分利用时间维度和空间维度特征的网络仍然是一个亟待解决的问题。为解决以上问题,本文提出一种基于时空特征融合的多目标跟踪与分割网络,达到了良好效果。具体而言,模型分为编码器和解码器两个阶段,在解码器部分设计了空间三坐标注意力模块,从横向、纵向与通道3个方向对特征进行聚合、分离再叠加,尽可能保证每一个角度含有信息的特征能够得到保留,以此挖掘空间特征信息。此外,设计了时间压缩自注意力模块,利用维度压缩的自注意力模块在尽可能小的计算代价下提取关键帧时间特征,再通过高低特征融合得到最后的分割图。
本文主要贡献如下:1)设计了一种空间三坐标特征注意力单元,充分融合空间维度的特征信息,该模块可以从不同角度有效挖掘出特征上空间区域之间的联系,突出含有重要信息的区域;2)设计了一种时间压缩自注意力单元,在尽可能减少计算量的前提下,该模块用于突出关键帧的信息,补充模型的时序信息,使被遮挡的对象可以通过与前后未遮挡帧间产生联系,有效解决视频中对象被遮挡问题;3)提出一种通过3D卷积网络融合上述的时空表示的端到端的网络,可以同时进行多目标跟踪与分割任务,在两个数据集上进行了相关的实验,数据集相关的指标结果表明,对比现有的同期算法,本文方法具有良好的多目标跟踪与分割效果。
1 时空特征融合网络

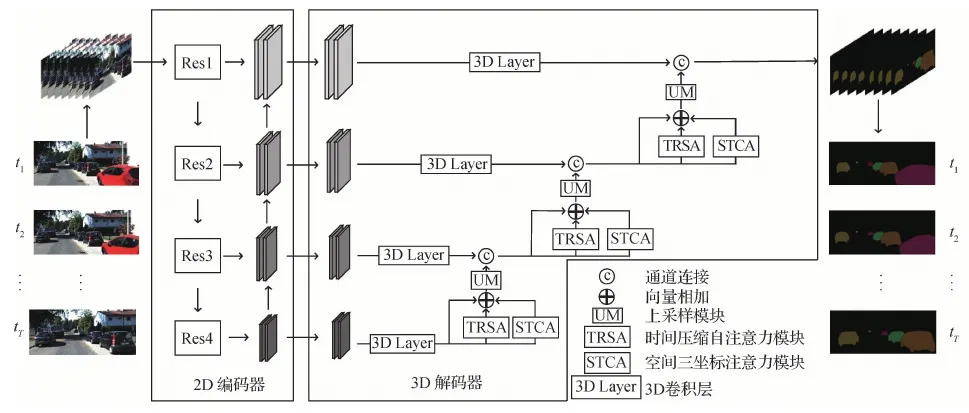
图1 STFNet结构Fig.1 STFNet structure diagram
如图2所示,STCA模块作为coordinate attention(Hou等人,2021)的注意力增强版本,弥补了coordinate attention的一些缺陷,原始版本只考虑了横向与纵向的注意力权重,这样会使注意力机制只考虑局部信息,而忽略了通道这一维度的信息分布,STCA增加了通道方向的注意力机制,并且设计了不同通道融合,这能够更好地从不同角度保留有效信息和丢弃无用信息,具体表示为
F32_STCA=fSTCA(F32_conv3d)
(1)

图2 空间三坐标注意力模块Fig.2 Spatial tri-coordinate attention (STCA)
式中,fSTCA表示STCA模块,F32_conv3d表示由3D卷积层得到的32倍下采样特征,F32_STCA表示经过STCA模块后的空间注意力深层特征,维度与F32_conv3d相同。
图3展示了时间压缩自注意力模块(time reduction self-attention,TRSA),TRSA是从时间维度上对不同特征进行选择,以此解决多目标跟踪与分割中频繁出现的目标遮挡的情况。本文认为关键帧指的是分割对象未被遮挡的视频帧,该模块设计初衷是能够使网络更加关注关键帧的对象信息,弱化遮挡帧的信息。其表示为
F32_TRSA=fTRSA(F32_conv3d)
(2)
式中,fTRSA表示TRSA模块,F32_KFTA表示经过TRSA模块后的关键帧注意力深层特征,维度与其输入相同。在F32_conv3d分别输入到STCA模块与TRSA模块时,参考ResNet的shortcut方法,也同样将F32_conv3d输入与STCA模块输出、TRSA模块输出直接融合,输入到下一步的卷积层中,即
F16_hf=fUM(F32_conv3d+F32_STCA+F32_TRSA)
(3)


图3 时间压缩自注意力模块结构图Fig.3 Time reduction self-attention structure diagram (TRSA)
1.1 空间三坐标注意力模块(STCA)
图2展示了本文设计的空间三坐标注意力单元的结构,该模块受到Fu等人(2019)提出的DANet(dual attention network)与coordinate attention(Hou等人,2021)的启发,DANet为双注意力网络,由位置注意力模块和通道注意力模块组成。而coordinate attention从横向与纵向两个方向对重要的特征加以关注。考虑到这些网络对目标特征的关注都缺少全面性,本文设计了空间三坐标注意力模块,从横向、纵向与通道3个方向对特征进行聚合、分离再叠加,尽可能保证每一部分含有信息的特征能够得到保留,使网络从多个角度对重要特征进行关注。
如图2所示,对于特征维度为C×T×W×H的特征图F,先将时间维度与通道维度互换,再分别对其横向、纵向与通道向进行平均值池化操作,编码3个坐标方向的信息用于后续提取权重系数,具体为
Fh=fhp(F)
Fv=fvp(F)
Fc=fcp(F)
(4)
式中,fhp、fvp和fcp分别表示横向、纵向和通道向的平均池化操作,Fh、Fv和Fc表示不同方向平均池化后的特征,其维度分别为Fh∈RT×1×1×H、Fv∈RT×1×W×1和Fc∈RT×C×1×1。接下来,分别对3个特征进行两两融合,以横向与通道向融合为例,先对其进行维度上的连接,再利用1×1卷积降维的思想,将其输入到1×1卷积中进行特征融合,同时也减少计算量,再使其经过批标准化层和激活函数层。整个过程可以表示为
Fhc=δ(fconv_1([Fh,Fc]))
(5)
式中,[·,·]表示向量连接操作,fconv_1表示1×1卷积层,δ表示ReLU激活函数,Fhc表示融合了横向与通道向的注意力特征,其维度为Fhc∈RT/r×1×(H+C),其中,r表示与SE Net(Hu等,2021)中相同的压缩率,取r= 16,主要用来控制模块大小,降低计算量。同样,可得Fhv∈RT/r×1×(H+W),表示融合了横向与纵向的注意力特征,Fvc∈RT/r×1×(W+C)表示融合了纵向与通道向的注意力特征。完成两两方向的特征融合之后,接下来,对Fhc、Fhv和Fvc分别进行分离操作。分离操作可以得到每个方向单独的注意力特征,再将相同方向的注意力特征叠加,最后,经过 sigmoid 函数得到各方向的权重作为最后的加权使用,表达式为
Ghf=σ(fhf(split(Fhc)+split(Fhv)))
Gvf=σ(fvf(split(Fhv)+split(Fvc)))
Gcf=σ(fcf(split(Fhc)+split(Fvc)))
(6)
式中,split(·)表示分离操作,fhf、fvf和fcf表示1×1卷积层,用于将压缩的维度还原成原始维度,σ(·)表示sigmoid函数。通过式(6),最终得到的横向、纵向和通道向的注意力特征分别为Ghf∈RT×1×1×H、Gvf∈RT×1×W×1和Gcf∈RT×C×1×1。最后,空间三坐标注意力模块的输出表示为
Y=F×Ghf×Gvf×Gcf
(7)
第2.4 节消融实验证明,与不带 STCA 模块的网络相比,加入 STCA 模块并且结合多层次特征融合的方式可以带来较大的性能提升。
1.2 时间压缩自注意力模块(TRSA)
图3为本文设计的时间压缩自注意力模块,设计该模块的初衷是为了充分利用3D解码器的结构特点,对于时间维度的信息进行选择性提取,这是以往多目标跟踪与分割模型未考虑的,本文模型受Transformer(Vaswani等,2017)和non-local neural networks(Wang等,2018)的启发,着重关注时间维度上的特征,并且原始non-local网络计算量巨大,本文设计的TRSA模块通过两个方面降低维度,大幅减少了计算复杂度与内存占用。
如图3所示,对于维度为C×T×W×H的特征图F,该模块先通过3个1×1×1的3D卷积,卷积层的目的就是降低维度至Td,Td=T/2,对除时间维度以外的维度进行融合,得到3个维度为Td×CWH的矩阵,然后对其分别进行降维,使用conv1卷积降维成Td×S维,S根据输入特征大小不同进行调整,这样可以大幅减少后期的矩阵运算量。接着,对其中两个矩阵进行转置操作,再将未转置矩阵与转置矩阵相乘,得到S×S维的矩阵,再经过softmax函数,得到注意力权重,与S×Td维特征相乘,可以得到S×Td维向量,再经过升高维度,维度重排与1×1的3D卷积还原为维度为C×T×W×H的特征。
第2.3节的定性分析和第2.4 节的消融实验表明,与不带 TRSA模块的网络相比,加入 TRSA 模块可使网络在跟踪与分割目标时对遮挡的目标更为鲁棒,因此给最后结果带来较大的性能提升。
2 实验结果分析
2.1 实验设置
测试数据集为YouTube-VIS(YouTube video instance segmentation)(Yang等,2019)和KITTI MOTS(multi-object tracking and segmentation)(Voigtlaender等,2019a)。针对YouTube-VIS数据集,本文联合YouTube-VIS和COCO(common objects in context)进行训练(对COCO训练集,本文仅使用与YouTube-VIS数据集重合的20个对象类),输入图像块的尺寸设置为 640×1 152 像素,沿用MaskTrack R-CNN中的评价指标AP(average precision)和AR(average recall)来评价模型跟踪与分割的性能。针对KITTI MOTS数据集,本文在KITTI MOTS训练集上进行训练,输入图像块的尺寸设置为 544×1 792像素,沿用TrackR-CNN中的评价指标sMOTSA(soft multi-object tracking and segmentation accuracy)、MOTSA(multi-object tracking and segmentation accuracy)、MOTSP(multi-object tracking and segmentation precision和IDS(ID switch)来评价模型跟踪与分割的性能。采用随机翻转、视频逆序和图像亮度增强等方法进行数据增强。对于所有实验,使用ResNet-101作为网络的骨干网络,并使用在COCO训练集上训练的Mask R-CNN(He等,2017)预训练模型的权重对骨干网络进行初始化,解码器网络权重使用随机初始化权重的方法。
随机选取连续帧的参数T= 8,最小训练批次大小设置为 1。网络参数使用 SGD(stochastic gradient descent)优化器,其动量为0.9。使用3个损失函数进行训练,分别是用于学习特征嵌入向量的Lovsz Hinge损失函数(Berman等,2018)、用于学习方差值的smoothness损失函数和用于生成实例中心热图的L2损失。初始学习率设置为1E-3,并且每个 epoch 学习率呈指数衰减。本文利用 Pytorch 框架在 1 块 GeForce RTX 3090 GPU上进行模型训练与测试。
2.2 定量分析
表1是本文算法与其他先进的多目标跟踪和分割算法在YouTube-VIS数据集进行比较的结果。这些算法包括OSMN MaskProp(efficient video object segmentation via network modulation)(Yang等,2018)、FEELVOS(fast end-to-end embedding learning for video object segmentation)(Voigtlaender等,2019a)、IoUTracker+(Yang等,2019)、OSMN(Yang等,2018)、DeepSORT(Wojke等,2017)、MaskTrack R-CNN(Yang等,2018)、SeqTracker(Yang等,2018)、STEm-Seg(spatio-temporal embeddings for instance segmentation)(Athar等,2020)和CompFeat(comprehensive feature aggregation)(Fu等,2020)。可以看出,本文算法在AP和AR指标上都取得最好成绩。相比其他大多数算法而言,本文算法未使用第1帧信息、现成的检测框架或额外的光流信息,而是一套集检测、跟踪和分割于一体的端到端的框架。

表1 YouTube-VIS 验证集结果Table 1 YouTube-VIS validation results /%
表2是本文算法与其他先进的多目标跟踪和分割算法在KITTI MOTS数据集进行比较的结果,这些算法包括UnOVOST(unsupervised offline video object segmentation and tracking)(Luiten等,2020)、TrackRCNN(Voigtlaender等,2019a)和STEm-Seg(Athar等,2020)。在汽车类的跟踪和分割中,本文网络在sMOTSA、MOTSA和MOTSP指标上取得了第2名的成绩,而第1名的TrackRCNN既使用了检测框架又使用了额外的ReID网络,无法实现端到端训练。在IDS指标上本文的STFNet取得了最好的结果。IDS表征的是跟踪轨迹错误切换的指标,这说明本文融合时空特征的网络结构对目标遮挡起到了作用。在行人类别中,本文结果在各指标上都取得了最好的结果。

表2 KITTI MOTS 验证集结果Table 2 KITTI MOTS validation results
2.3 定性分析
图4展示了本文STFNet在两个数据集上定性分析的部分实验结果。可以看出,本文算法在面对目标互相遮挡和背景遮挡情况下具有优越的性能。例如图4(a),STFNet利用了跟踪目标在未被遮挡的图像帧中的信息,保持住了原来的轨迹,这就是本文提出的时空特征融合模型的作用,即能够通过未遮挡帧的信息弥补被遮挡帧的信息。同样的情况出现在图4(b)中,本文算法在目标经过多次遮挡后依然能保持目标的原始轨迹,并且在图4(b)中可以明显看到,当两个相似对象空间位置相近时,本文算法由于有着空间三坐标注意力机制的作用,在这种情况下依然能很好地分割出每个目标。图4(c)(d)展示了STFNet对目标轮廓良好的分割效果,反映了STCA模块对空间信息挖掘的作用,通过使网络自动有选择地忽略背景信息与提取前景信息来做到分离前后背景。

图4 定性描述部分实验结果Fig.4 Qualitative description of some experimental results((a) KITTI MOTS 0006;(b) KITTI MOTS 0016;(c) YouTube-VIS 28;(d) YouTube-VIS 98)
2.4 消融实验
对本文网络中的STCA和TRSA模块以及STCA改进前的CA(coordinate attention)模块进行消融实验。实验结果如表3所示,所有数据是在KITTI MOTS的汽车类上进行跟踪和分割的结果。首先是CA模块的效果,表中第2行对比第1行可知,CA模块对网络跟踪和分割的效果影响较小,对原本的baseline几乎没有影响,表明CA模块对关键上下文信息的关注度不够,没有达到提取关键特征的设计要求,而本文提出的STCA模块对网络效果有着较好提升,相较原本的基准模型提升了0.5%,由此可见,STCA模块弥补了CA模块的不足,通过3个方向的注意力模块成功捕获了关键特征。然后是TRSA模块,性能也提高了0.3%,主要是因为TRSA模块充分利用了3D卷积解码器的特点,关注重要的关键帧信息,因此可以较好地提升跟踪与分割的性能。最后是本文整个网络,融合了STCA模块和TRSA模块,即融合了时空特征,显而易见,取得了最好的结果。

表3 消融实验Table 3 Ablative study
3 结 论
提出一种时空特征融合的多目标跟踪与分割网络的算法,实现了高精度的多目标跟踪与分割,并且可以一定程度抵抗目标遮挡等问题。网络首先通过骨干网络提取出不同分辨率图像的特征;然后从低分辨率的特征开始,通过空间三坐标注意力模块和时间压缩自注意力模块,得到获得关键信息关注的空间特征和获得关键帧信息的时间特征,并将两者与原始特征融合;随后通过3D卷积层与较高分辨率的特征进行融合,利用3D卷积的效果反复聚合不同层次的特征,得到融合多次既有关键时间信息又有重要空间特征的特征图,从而得到最后的跟踪和分割结果。实验结果表明,本文算法在YouTube-VIS 数据集上的各项指标都取得了最优结果,在KITTI MOTS数据集上多项指标也取得了最优结果。
然而,多目标跟踪与分割依然是一个充满挑战的新方向,存在缺少更多的相关数据集和缺乏领域独特方法等问题,尤其是现有的多目标跟踪与分割算法大多沿用多目标跟踪算法的思路,但在如何充分利用像素级别的分割标注上并没有较好的相关工作,这其实是两个方向的一个根本区别。因此,本文后续将进一步研究如何将实例级别的分割标注更加充分地利用到这个新方向上,以此改善算法性能。
猜你喜欢
当代陕西(2022年4期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年22期)2021-01-18
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
中华诗词(2019年7期)2019-11-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
