
基于数据分析的共享电动汽车PMP项目启动风险管理研究
2022-11-17 07:50:42褚玉飞
现代信息科技 2022年20期
褚玉飞
(常州法商委员会,江苏 常州 213000)
0 引 言
TM 公司现在面临市场同质化竞争激烈的情况下市场占有率和利润大幅度下降,公司计划在现有产品结构上启动一个新项目——投放一种新型电动共享汽车来提高竞争力。项目风险管理结构是根据PMP 项目风险管理体系来建立。通过前期的市场调研,计划在城市CBD、工业区和市郊这三个区域中选择最适合的一个最优区域作为一期项目投放区域,待其产生良好的效果后依次投放其他两个区域,以便形成良好的项目循环投放效果。
TM 公司在项目启动风险管理阶段通过专家讨论识别出用户的年龄和收入是新型电动共享汽车项目能否取得成功的关键风险因素。在这两个因素上TM 公司又开展德尔菲技术和引导技术分析得出新型共享电动汽车的一期项目在工业区投放可能好于CBD 和市郊。为更好的识别该项目的风险,TM 公司希望通过公司以往项目形成的经验数据,通过聚类分析技术进行量化分析得出结论。据此TM 公司在以往的共享项目中收集了2 084 个用户的收入和年龄数据进行分析,希望能找出这些数据背后的规律和现象来解决项目启动阶段的风险管理问题,减少损失,增大收益,技术路线如图1所示。

图1 技术路线图
1 聚类分析流程
1.1 聚类数据处理
聚类数据处理首先考虑的是使用共享电动汽车人群的年龄和收入的变动风险,这两个风险变量将影响共享电动汽车投放的区域选择。据此,PMP 项目启动风险管理的的属性信息就是就人的年龄和收入。其次,如表1所示,从企业前期项目中提取使用过共享电动汽车客户的年龄和收入信息,这些信息主要来自企业以往项目的过程资产。

表1 项目企业过程资产
根据项目目的需求对以上数据进行筛选,考虑的是性别和年龄的变动对项目启动是否存在风险,所以提取该两类数据变量进行聚类分析。但原始数据较为繁杂和琐碎,也不是所有数据都存在内在联系,如果在收集数据的过程中如存在非数字化数据就要对数据进行数字化变量处理。本文所选择的聚类分析软件是现行可靠的分析软件Python,据此,在收集数据的过程中都将考虑数据是否能够被Python 读取而进行数据处理。
1.2 聚类数据分析
1.2.1 定义TM 公司在PMP 项目启动风险管理的问题
目前共享电动汽车企业难以实现大规模投车的主要原因之一是处于对成本的焦虑——重资产运营。共享电动汽车采购单价和维护成本高,决定了对投放区域选择必须是根据需求精准投放。如果TM 公司在项目启动阶段没有经过完成的项目启动风险管理分析,投放效果达不到既定的项目目标的话,那么同时属于固定资产的共享电动汽车也会就折旧一项给企业带来较大的支出,而如果没有产生足够的现金流量将会造成企业的经营形成恶性循环,这样的投放实际就是在制造损失。所以TM 公司在项目启动阶段就投放区域的考虑一定要结合项目自身的需求去挖掘市场潜力,而不是盲目投放,以量取胜的粗糙战略。
首先考虑的是共享电动汽车使用人群的年龄对使用情况影响。通常理解上接收新鲜事物对年龄段较低的用户接受起来较强,而年龄较高的用户接受起来较弱,但针对共享电动汽车也是这样情况?其次考虑的是共享电动汽车使用人群的收入对使用情况的影响。根据当前共享电动汽车的发展特点,投放区域的选择主要集中在城市核心商圈、写字楼等CBD 区域,而忽略市郊、工业区等人流量大,理论上收入一般的地方。但消费能力强代表着有自有车辆的可能性也较高,他们不一定会选择共享电动汽车,所以对于使用共享汽车的需求是不是也并不会有那么高的需求。而生活在市郊或者偏离市中心较远的工业区的人没有自有车辆的可能性较高,是不是具有刚性的开车通勤需求?基于这样的考虑TM 公司在项目启动阶段必须要对这样的问题进行详细、周密的研究,将年龄和收入的变化作为项目启动阶段的风险因素进行考虑,识别风险,进而制定相应的风险应对策略促使项目成功。
因此,在TM 公司项目启动阶段,需要尽快在企业内部过程资产的数据中精准预测新用户增长未来对边际利润贡献类型的趋势,通过这种精细化的分析,可以帮助企业制定有效、全面的项目章程,在项目启动过程中让各方干系人明白项目的痛点和难点,从而提升项目目标实现的最大可能性。
1.2.2 TM 公司在PMP 项目启动风险管理过程中数据收集和清洗
在数据收集和清洗阶段,首先要考虑聚类分析所需数据的质量和数据对象处理描述数据的问题。关于数据质量,数据采集的过程是根据项目整体的需求进行采集的,所得数据源多种多样。但是要尽量避免收集过程中的异常数据的产生,这些异常数据如果较多将会影响聚类分析的效果。虽然聚类分析可以通过离群点将这些异常的数据去除,但是异常数据本身也有分析的价值,它所代表的异常风险也是项目必须考虑的。但是异常是数据本身性质的改变,所以我们要考虑高质量的数据是去除自身错误的数据。关于数据对象处理描述数据的问题,TM 公司项目启动风险管理提出描述数据的问题,所以本文定义数据属性是年龄和收入。TM 公司在企业过程资产中提取2 084 条数据,需要对数据质量进行一次校对,所以要对数据全面进行一次描述观察,如果发现异常数据或者重复数据都要进行去除,这就是聚类分析的前提,对数据进行清洗整理的过程。去除异常数据这样可以避免无效数据带来的影响,也可以去除数据迭代分析中不必要的决策影响。如表2所示,在得到聚合的数据后,需要对数据进行一个宏观的数据的描述观察,观察这些数据有无异常,并判定这些数据是自身错误的数据还是数据自身属性的变化。
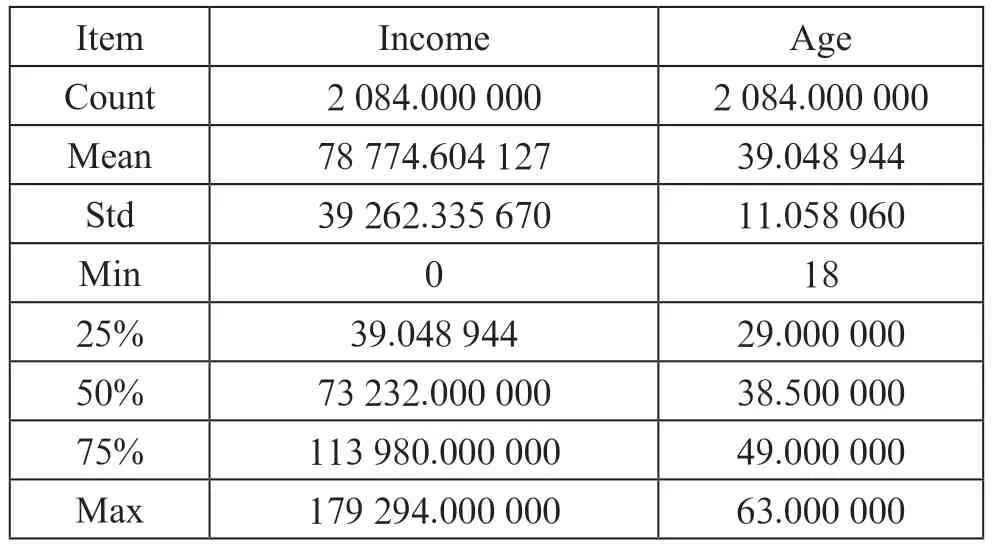
表2 数据描述
从表2我们可以对清洗后的数据可以得出结论:在对收集的2 084 个数据中进行初步的的评估我们可以发现:收入(income)和年龄(age)的平均数、最大数和最小数、四分位数比较正常,并没有出现数字异常过高或过小的情况;在最小数的收入(income)项目出现了零,说明有数值是空的,需要进行清洗。
在对数据进行一场清洗后,我们得到表3,在表中我们可以发现在最小数的收入(income)项目中的值不再为零,而是一个比较正常的数值。

表3 数据描述
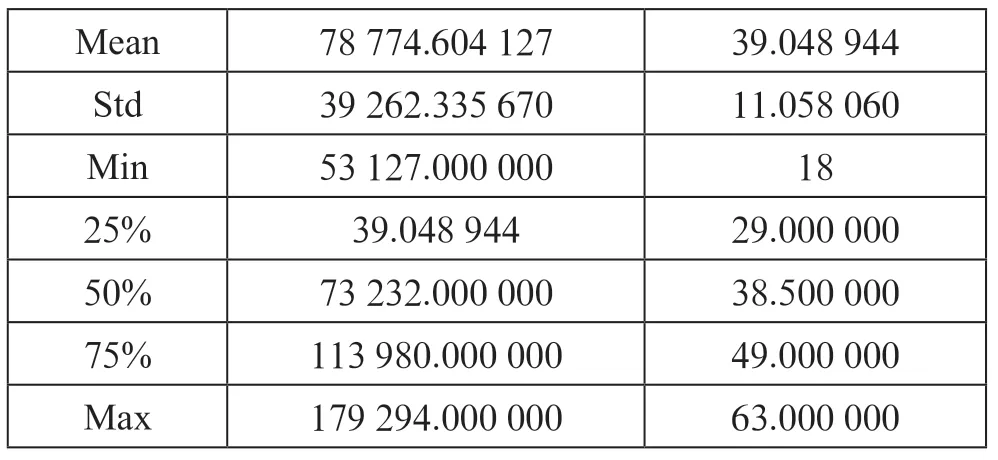
Mean 78 774.604 127 39.048 944 Std 39 262.335 670 11.058 060 Min 53 127.000 000 18 25% 39.048 944 29.000 000 50% 73 232.000 000 38.500 000 75% 113 980.000 000 49.000 000 Max 179 294.000 000 63.000 000
聚类分析数据标准化阶段。在数据评价体系中,数据类型、数据属性和统一的量纲是首要考虑的问题。如果数据的这些属性存在异常变化,分析数据自身的质量都不能保证,那么聚类的结果将也不能获得保证,所以要对数据进行标准化的处理。数据标准化处理是聚类分析的前提,只有将数据统一类型,统一属性,统一量纲,那么在其后的聚类分析上才能高效进行分析,得出的聚类分析结果也有较大的可靠性,也是对聚类分析的结果进行分析时可以排除数据自身质量造成的不必要的干扰。
其次在标准化过程中,假如出现某一数据集a 的数据数值都比较小,数据的范围在0.1 到1 之间,我们可以看出这一数据集的数据变化很小。但是我们又发现另一数据集b 的数据值很大,数据的范围都是1 到100 之间,我们可以看出这一数据集的数据变化很大。据此,在聚类分析计算距离的时候,数据集b 的作用就比数据集a 的作用要大,其聚类的结果的作用也大。本文选用的K-Means 聚类中选择欧几里德距离计算距离,数据集又出现了上面所述的情况,就一定要进行数据的标准化,即将数据按线性比例在特定的区间内变化。关于收入和年龄的标准化公式为:(收入-收入均值)/收入标准差;(年龄-年龄均值)/年龄标准差。表4呈现是数据标准化后的情形。
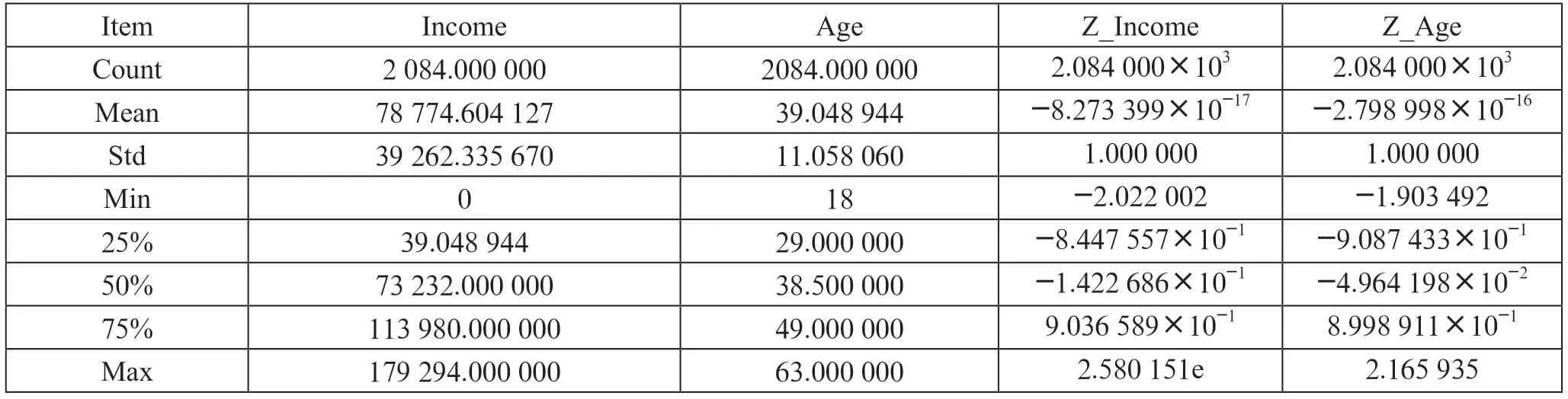
表4 收入和年龄标准
1.2.3 基于K-means 算法的聚类分析
在对聚类分析需求的数据进行清洗后在进行聚类分析之前,必须了解下列的数据的特性才能更好的进行聚类分析,更好的分析聚类结果。
首先是聚类分析的数据规模。数据样本的规模越大,所得的聚类分析结果就会越趋近于数据背后的规律和现象,这也是一切数据分析的基础。如果数据样本不够大,那么相对于样本的分析的结果可能存在相似性。
其次是聚类分析需求数据的稀疏性。稀疏数据是指数据值通常是缺失或者是空值,这些稀疏数据虽然描述的数值不完成,但是其本身的数据类型和属性是没有问题的,依然可以通过数据挖掘后进行处理得出有效的结论。
最后是聚类分析需求数据的尺度属性。数据的计量尺度有定序尺度、定类尺度、定比尺度和定距尺度,其中定类尺度和定序尺度是本文数据清洗中选用的方式,因为这两种方式主要用于定量分析,其余的两种方式主要用于定性分析。如年龄和收入,在数据实际的尺度计量中可能存在不同的尺度属性。如果数据集中的数据存在数据尺度混淆,就将可能影响聚类分析的准确性,因为这也将影响簇内与簇之间的距离和相似性分析。
综上所述,本文进行聚类分析考虑的是年龄和收入对项目启动的影响,其中年龄用的是岁,收入用的元,在使用欧几里得距离相似性的分析技术,则年龄数值因为范围较小,所以对聚类的影响比较小,结果是在进行聚类分析中是将以数值范围较大的收入作为聚类主要考虑的因素。因此我们必须考虑将数值标准化,来消除尺度不同造成的影响,其有效方式是数值减去均值,再除以标准差,每个数据属性将进行标准化。
1.3 共享电动车PMP 项目启动风险管理识别的结果
1.3.1 数据初步可视化
从图2可以看出,在簇的外围有一些异常的数值,这些数据远离簇的质心,即远离簇的整体,看上去极不协调,这就是离群点。正常情况如果这些数据是异常值就应当去除,不然将会影响聚类分析的效果,如果这些异常值是本身属性的变化,可以考虑单独分析这些异常值的背后原因,找出潜在的风险。比如分析项目资源的异常投入,我们就可以通过聚类把这些异常的点找出来,分析其背后形成的原因,而不是覆盖在正常的项目资源需求中,所以在项目执行过程中可以把离群值单独作为一类风险来分析。
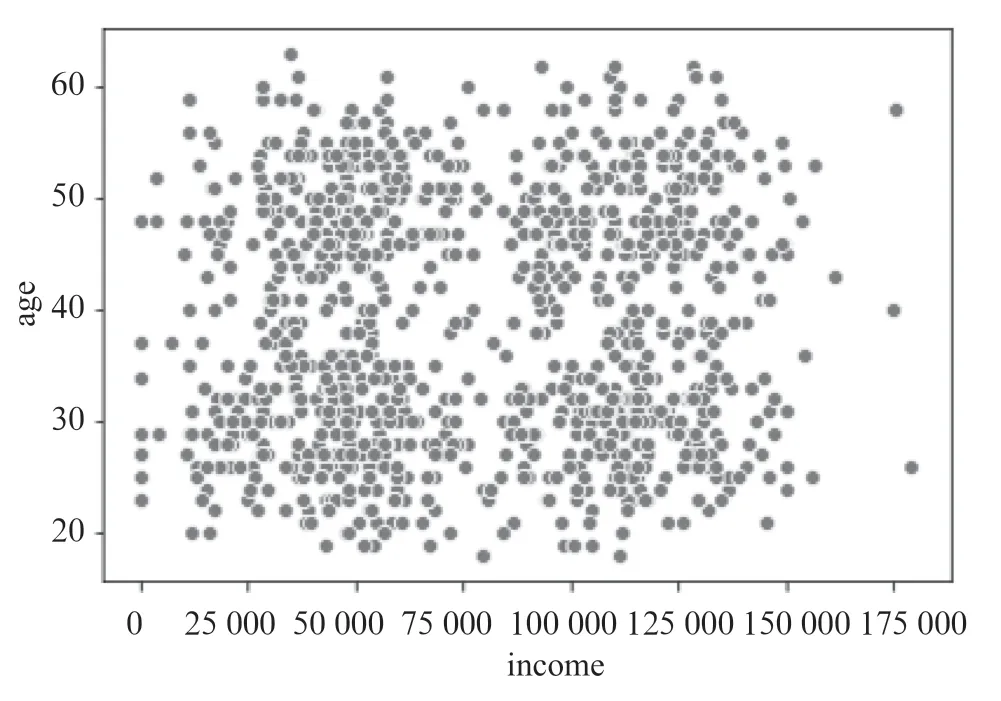
图2 数据初步可视化
据此,我们在PMP 项目启动阶段的风险分析中,这些异常离群点对我们分析的作用不是特别大,只是个别数据本身有错误或者一些和普通数据相比的个别突出数据,对PMP 项目启动阶段的风险分析并没有什么价值,所以在剔除这些离群点后,进行如下的聚类分析:
(1)群体分成2 类进行分析结果如图3所示。

图3 群体分成2 类进行分析
(2)群体分成4 类进行分析结果如图4所示。

图4 群体分成4 类进行分析
(3)将群体分成5 类进行分析结果如图5所示。

图5 群体分成5 类进行分析
(4)将群体分成6 类进行分析结果如图6所示。

图6 群体分成6 类进行分析
1.3.2 聚类分析后确定最优分类
在TM 公司本次共享电动汽车投放项目启动风险识别聚类分析可以看出:根据图3聚类虽然分为2 类,但在聚类的效果上明显呈现出4 类的一个分布情况;因此如图4所示将群体分成4 类进行聚类分析,簇的边界比较清晰的呈现出4个分类;在考虑是否有最优分类情况下,继续迭代进行5 类和6 类的聚类分析,尝试找出是否有最优的分类,如图5和6 所示,此两种聚类形成的簇都是交替存在于是将群体分成4 类的簇当中。据此,将群体分成4 类进行分析是当前适合的聚类分布。
根据聚类分析最优分类的聚类选择,本次TM 公司选择将群体分为4 类进行年龄和收入的数据分析如表5所示。从表5可以发现收入分为2 档,1 和3 为一档:0~8 万元,0 和2 为一档:8 万~18 万元,而这两档收入在使用共享汽车的频次上并没有带来明显的差异,说明收入并不是决定是否使用共享汽车的主要因素。

表5 收入
从表6可以发现年龄分为2 档,0 和3 为一档:18 岁~39岁中青年,1 和2 为一档:40~60 岁中老年,从图上看出共享汽车的使用者年龄并没有明显的差异,说明年龄也不是适合影响共享汽车使用的主要因素。

表6 年龄
2 结 论
从k-means 聚类分析进行共享电动汽车投放区域的聚类分析结论上看,我们并没有发现年龄和收入是影响用户使用共享汽车的决定因素。鉴于此,TM 在该项目管理是需要考虑别的因素对项目的影响。另一方面页说明,在现今数据爆炸的时代,PM 项目管理的数据分析多维度和多方向的的迭代分析,因为数据和市场一直是动态的变化,只有精准定位影响项目启动风险的数据,才能减少和控制是PMP 项目启动风险管理,也为PMP 项目启动风险管理提供一种分析工具和方法。
猜你喜欢
汽车维修与保养(2021年8期)2021-02-16 00:28:32
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
动漫星空(兴趣百科)(2019年3期)2019-03-07 07:47:46
中国化肥信息(2018年3期)2018-01-30 06:56:43
知识经济·中国直销(2017年3期)2017-04-16 03:07:53
海外星云(2016年17期)2016-12-01 04:18:42
太空探索(2016年5期)2016-07-12 15:17:55
现代企业(2015年4期)2015-02-28 18:48:39
时代英语·高三(2014年5期)2014-08-26 17:01:17
环球时报(2014-08-02)2014-08-02 08:26:42
