
基于实体级遮蔽BERT与BiLSTM-CRF的农业命名实体识别
2022-11-13 07:57韦紫君胡小春陈宁江
农业工程学报 2022年15期
韦紫君,宋 玲,胡小春,陈宁江,3
基于实体级遮蔽BERT与BiLSTM-CRF的农业命名实体识别
韦紫君1,宋 玲2,3※,胡小春4,陈宁江1,3
(1. 广西大学计算机与电子信息学院,南宁 530004;2.南宁学院信息工程学院,南宁 530200;3. 广西多媒体通信与网络技术重点实验室,南宁 530004;4.广西财经学院信息与统计学院,南宁 530007)
字符的位置信息和语义信息对命名方式繁杂且名称长度较长的中文农业实体的识别至关重要。为解决命名实体识别过程中由于捕获字符位置信息、上下文语义特征和长距离依赖信息不充足导致识别效果不理想的问题,该研究提出一种基于EmBERT-BiLSTM-CRF模型的中文农业命名实体识别方法。该方法采用基于Transformer的深度双向预训练语言模型(Bidirectional Encoder Representation from Transformers,BERT)作为嵌入层提取字向量的深度双向表示,并使用实体级遮蔽策略使模型更好地表征中文语义;然后使用双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)学习文本的长序列语义特征;最后使用条件随机场(Conditional Random Field,CRF)在训练数据中学习标注约束规则,并利用相邻标签之间的信息输出全局最优的标注序列。训练过程中使用了焦点损失函数来缓解样本分布不均衡的问题。试验在构建的语料库上对农作物品种、病害、虫害和农药4类农业实体进行识别。结果表明,该研究的EmBERT-BiLSTM-CRF模型对4类农业实体的识别性能相较于其他模型有明显提升,准确率为94.97%,1值为95.93%。
农业;命名实体识别;实体级遮蔽;BERT;BiLSTM;CRF
0 引 言
随着信息化技术的快速发展,农户通过线上智能问答解决线下农业问题已成为趋势。面对庞大的问答数据,如何对数据进行分类、关键词定位、深层语义关系挖掘是实现智能问答的关键,同时也是自然语言处理(Natural Language Processing,NLP)和农业大数据智能研究领域的热点研究方向[1]。命名实体识别[2](Named Entity Recognition,NER)是自然语言处理、智能问答[3]和知识图谱构建[4]等领域的关键技术,其主要任务是从非结构化文本中识别出有意义的名词或短语并加以归类,而农业命名实体识别任务则是识别出农业文本中的相关实体,如农作物品种、病害、虫害和农药名称等。当前中文农业命名实体识别存在以下两方面的问题:一是农业知识数据尤其是标记好的数据集难以获得,导致模型性能和准确率达不到预期效果;二是农业实体命名方式繁杂多变且名称长度较长,并缺乏标准的数据集和构词规范,难以对农业语料进行分词、分类、语义挖掘等操作。
早期的命名实体识别研究大多是基于规则的方法[5-6],先根据特定领域知识手工设计规则并做成词典,然后通过模式匹配等方式来实现命名实体识别。此类方法高度依赖人工设计规则,对语料库与标准构词规范的依赖性很高,难以准确识别构词复杂的命名实体。随着机器学习的应用,开始将命名实体识别任务建模为多分类任务或序列标注任务,训练模型从标记好的数据中学习实体的命名模式,再对未标记数据进行命名实体预测。文献 [7]提出基于条件随机场(Conditional Random Field,CRF)的农作物病虫害及农药命名实体识别方法,利用标注后的数据训练CRF模型并对语料进行分类。文献[8]使用BIO(Begin, Inside, Outside)和BMES(Begin, Middle, End, Single)2种标注方式,根据不同分类进行特征选取,再基于CRF模型对农业命名实体进行识别。上述方法通常需要大规模的标注语料,而中文农业命名实体识别任务的标准语料库难以获得,增加了农业实体的识别难度,影响识别效果。
利用深度神经网络自主学习深层语义特征,为命名实体识别任务提供了更多可借鉴的方法[9]。循环神经网络(RNN,Recurrent Neural Network)+CRF和卷积神经网络(CNN,Convolutional Neural Network)+RNN+CRF 2种网络结构开始被广泛应用于命名实体识别任务。RNN+CRF结构[10-11],将带有语义信息的字符嵌入输入到RNN(如双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)、双向门控神经网络)中,进一步学习文本的长序列语义特征;再使用CRF输出全局最优的标注序列。文献[12]利用连续词袋模型预训练字向量,并引入文档级注意力机制获取实体间的相似信息,基于BiLSTM-CRF模型构建农业命名实体识别框架,解决农业中分词不准确和实体标注不一致的问题。文献[13]针对渔业领域命名实体长度较长的特点,使用长短时记忆网络(LSTM,Long Short-Term Memory)学习长距离依赖信息,并将标记信息融入CRF模型,构建Character+LSTM+CRF渔业实体识别模型,解决渔业实体较长造成识别效果较差的问题。CNN+RNN+CRF结构[14-15],通常是在RNN+CRF结构的基础上,先利用CNN提取具有汉字偏旁部首特征信息的部首嵌入,再将部首嵌入与带有语义信息的字符嵌入相结合作为最终的输入,同时考虑中文字符的部首信息和语义信息。文献[16]采用基于部首嵌入和注意力机制的农业病虫害命名实体识别模型,将部首嵌入与字符嵌入结合作为输入,采用不同尺寸窗口的卷积神经网络提取不同尺度的局部上下文信息,基于BiLSTM-CRF框架对农业病虫害实体进行识别,缓解了农业中内在语义信息缺失的问题。上述方法均使用Word2Vec[17-18]模型作为嵌入层,而Word2Vec输出的是上下文无关的浅层特征向量,因此无法表征一词多义。中文里不少词汇都具有一词多义,并且中文农业命名实体具有构词复杂和实体长度较长的特点,因此字符的位置和上下文依赖信息至关重要,而上述方法无法充分考虑以上2种信息,就会影响识别效果。预训练语言模型(BERT[19]、ERNIE[20]等),通过预训练字向量的深度双向表示,进一步提高了命名实体识别的性能。文献[21]基于外部词典和BERT模型,利用特征向量拼接的方式融合字级特征和词典特征对农业领域的5类实体进行识别,提高了农业命名实体识别的性能。该方法利用外部词典来辅助提取词级特征,但基于词典提取的词级特征向量是固定的,即对于具有一词多义的词汇来说其不同语义得到的是相同的特征表示,因此并不能很好的区分其间的语义差异。并且基于词典的方法具有一定的局限性,不能很好地处理输入句子中出现词典中不存在的词。文献[22]采用基于BERT+BiLSTM+Attention模型,利用BERT预训练字向量,再融合BiLSTM与注意力机制去重点关注文本中的主要特征,解决中医病历文本有效信息识别和抽取困难的问题。文献[23]采用融合注意力机制与BERT+BiLSTM+CRF模型,利用BERT提高模型语义表征能力和使用注意力机制计算序列词间相关性,解决渔业标准定量指标识别准确率不高的问题。上述方法针对特定领域和具有明显实体特征的命名实体识别效果较好,但不同领域的实体特征间存在差异,并且在农业中存在具有边界模糊特点的命名实体,因此无法将以上方法直接应用于农业领域。
基于以上农业命名实体识别任务中缺少标准语料库、模型无法充分表征中文语义和名称长度较长的实体识别准确率低的问题,本文做了以下工作:1)基于权威农业信息网站的相关信息,构建一个中文农业命名实体识别语料库;2)使用预训练语言模型BERT作为嵌入层,从无标签的文本中预训练出字向量的深度双向表示,并根据中文的特点改进原有的语言遮蔽方法,使用实体级遮蔽策略让模型对文本中的完整实体进行遮蔽和预测,使模型更好地表征中文的语义;3)使用焦点损失函数缓解样本分布不均衡问题,提高模型对难识别样本的识别能力;4)使用BiLSTM-CRF模型作为下游任务模型,将BERT中获取的字向量深度双向表示序列输入到双向长短时记忆网络(BiLSTM)中做进一步的语义编码,学习文本的长序列语义特征;最后通过CRF层输出概率最大的标注序列,实现农业命名实体的准确识别。并通过对比试验,验证本文方法对中文农业命名实体的有效识别。
1 数据集构建
1.1 数据获取
本文语料是在各大权威农业信息网站(如中国作物种质信息网、中国农业信息网、中国农业知识网等)爬取的包含农作物病虫害、农作物品种和农药品种相关的文本。原始数据中包含大量非结构化数据,因此在数据标注前对原始数据进行预处理,包括非文本数据、链接及特殊字符删除和去停用词等操作,从而得到一个规范的语料库。该语料库包含37 243个农业领域的中文句子,29 790个农业类实体,共约180万个中文字符。其中训练集、验证集和测试集按7:2:1的比例进行分配。语料库信息如表1所示。

表1 语料库信息
1.2 标注体系
本文采用BIO体系对语料进行标注,共设计9个标签,分别是“B-CROP”、“I-CROP”、“B-DIS”、“I-DIS”、“B-PEST”、“I-PEST”、“B-PC”、“I-PC”、“O”。其中“B”表示实体名称的开始,“I”表示实体名称的内部,“O”表示非实体部分。实体类型表示如下:“CROP”表示农作物品种,“DIS”表示农作物病害,“PEST”表示农作物虫害,“PC”表示农药品种。语料标注示例如图1所示。标注后的数据集有29 790个命名实体,其中农作物实体11 057个,农药实体8 121个,病害实体4 505个,虫害实体6 107个。
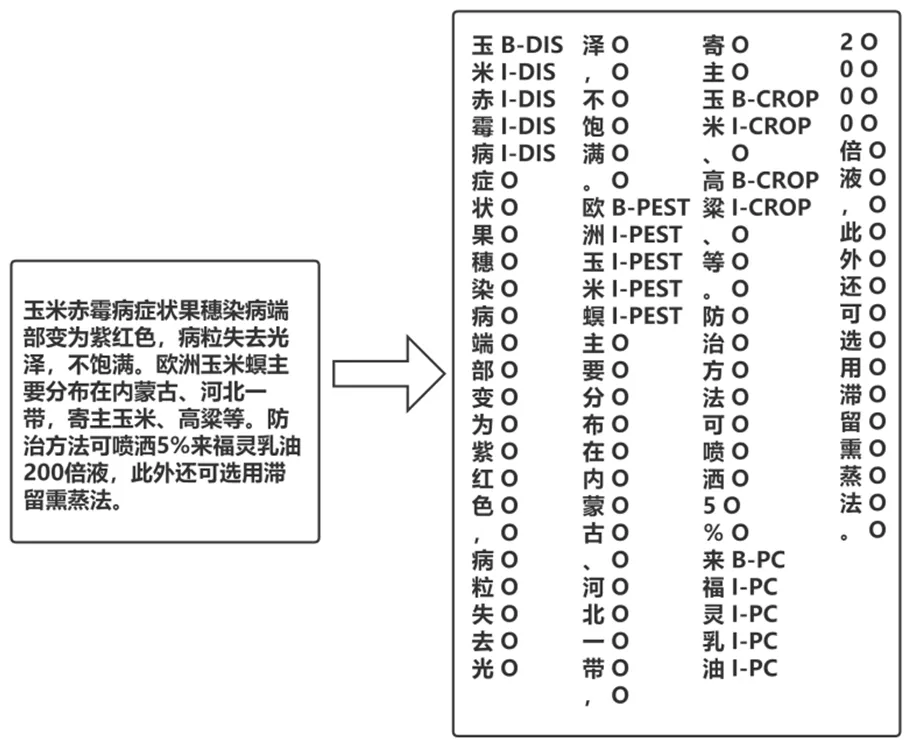
图1 语料标注示例
2 农业命名实体识别方法的设计
2.1 方法流程及模型架构
农业命名实体识别方法流程如图2所示,该方法主要分为中文农业命名实体识别语料库构建、预训练和下游NER模型训练3个部分。该方法在预训练中根据中文语义的特点改进了语言遮蔽方法,使用实体级遮蔽策略代替单个字符遮蔽策略,使训练得到的模型能够更好地表征中文语义。

图2 农业命名实体识别方法流程
使用EmBERT-BiLSTM-CRF模型实现中文农业命名实体识别任务,模型由输入层、BERT层、BiLSTM层和CRF层4部分组成。其中BERT层用于生成字向量的深度双向表示;BiLSTM层用于挖掘文本的长序列语义信息,使模型充分考虑上下文语境;CRF层用于学习标注约束规则,并对BiLSTM的输出进行标注合法性检验,最终输出全局最优的标注序列,模型输出的不是独立的标签序列,而是考虑规则和顺序的最佳序列。模型结构如图3所示。
2.2 BERT层和实体级遮蔽策略
BERT[19]是基于Transformer[24]的深度双向预训练语言模型,能够通过对所有层的上下文进行联合调节,从无标签文本中预训练出特征的深度双向表示,使特征向量可充分表征上下文语义信息,可有效解决传统Word2Vec模型无法解决的一词多义问题。多数中文农业实体的命名方式繁杂多变且名称长度较长,其识别过程中,每个字符的位置和语义信息是关键。BERT模型的输入表示由字符的位置嵌入、段嵌入与token嵌入3种特征嵌入表示求和来构建的,充分考虑了字符的位置信息。预训练期间使用遮蔽语言模型,使训练得到的特征向量携带上下文语义信息,因此本文使用BERT作为模型的嵌入层。

图3 EmBERT-BiLSTM-CRF模型结构
为训练出深度双向表示,采用对输入文本进行随机遮蔽的方式,让模型预测那些被遮蔽的字符。BERT原有的遮蔽方法是使用单个[MASK]标志对文本中的单个字符进行遮蔽,但中文的一个实体往往是由多个中文字符组成的,如果依然使用原有的遮蔽方法则无法将整个实体完整遮蔽,导致模型在预测被遮蔽词时会产生偏差,从而无法准确预测。因此本文将改进BERT原有的语言遮蔽方法,使用实体级遮蔽策略(Entity-level Masking,EM)对中文文本进行遮蔽。EM首先对文本进行中文分词和利用实体词典进行实体分析,然后使用多个连续的[MASK]标志对整个中文实体进行遮蔽,再让模型预测完整实体中被[MASK]标志替换的所有字符,获得实体级的特征信息,从而缓解在进行中文预测时因语义不完整造成的偏差。在训练过程中,模型对全文中的实体进行随机遮蔽,组成所有被遮蔽实体的中文字符共占全文总字符的15%。被选中遮蔽的实体中,80%被连续的[MASK]标志替换,10%被语料库中任意的实体替换,10%保持不变。EM方法如图4所示,示例如表2所示。

注:x1~ xn表示输入序列中的字符。[MASK]表示当前字符被遮蔽。

表2 实体级遮蔽示例
由于使用了遮蔽策略,训练过程中Transformer编码器并不知道将预测哪些字符或哪些字符已经被替换,所以保留了所有字符的上下文分布表示,使每一个字符最终携带其上下文语义信息。并且实体级遮蔽策略能让模型学习到实体级的特征信息,对于不同语义的同一实体或一个句子中不同位置的同一实体都能产生不同的特征向量,从而有效缓解中文中一词多义的问题。
2.3 BiLSTM层
农业领域的实体命名中有不少病害和虫害实体长度为8个或以上中文字符,例如“水稻东格鲁病毒病”、“水稻菲岛毛眼水蝇”、“水稻显纹纵卷叶螟”等;农药实体长度为7个或以上中文字符,例如“丁硫克百威乳油”、“吡虫啉可湿性粉剂”等。农业命名实体具有较大的上下文长距离依赖性,因此利用BiLSTM网络学习文本的长序列语义特征。


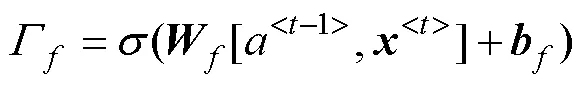
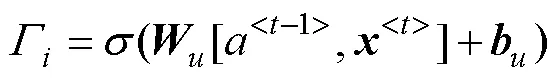




LSTM[27]只能捕获当前时刻状态之前的信息,无法捕获之后的信息,因此无法同时考虑文本的上下文语境。双向长短时记忆网络(BiLSTM)[28-29]由前向LSTM和后向LSTM构成,前向LSTM利用上文的信息来预测当前词,后向LSTM利用下文的信息来预测当前词,因此可同时利用文本上下文信息,学习文本的长序列语义特征,提高模型的识别能力。
2.4 焦点损失函数
构建语料库时,数据为基于爬虫技术从网络中爬取的各种文本信息,数据存在一定的随机性,导致语料库通常存在样本分布不均衡的问题。例如语料库中某一种标签的样本数量远多于其他标签的样本数量,导致训练过程中损失函数的分布失衡,使模型在训练过程中倾向于样本数量多的标签,造成样本数量少的标签的识别性能较差。
为了缓解样本分布不均衡带来的问题,本文利用焦点损失函数[30](Focal Loss,FL)在训练过程中平衡样本的权重,通过减少易识别样本在损失函数中的权重,让模型更关注于难识别样本。FL在交叉熵损失函数的基础上加入权重参数和调制因子来平衡样本分布,算法见公式(7)。
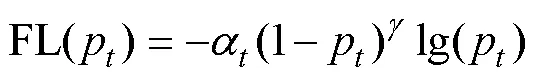

2.5 CRF层
BiLSTM的输出相互独立,无法考虑相邻标签之间的信息,直接使用BiLSTM的输出结果预测标签容易出现非法标注的问题,如表3所示。因此,本文在BiLSTM层之上加入CRF层来缓解标注偏置问题,从而提高序列标注的准确性。利用条件随机场[31](CRF)在训练数据中自动学习标注的约束规则,例如标注序列只能以“B-”或“O”开头,不能以“I-”开头;实体标注序列只能以“B-”开头,不能以“O”或“I-”开头;标注序列“B-label1 I-label2 I-label3...”中的labe1、label2、label3...应该为同一种标签等,CRF将学习到的约束规则在预测时用于检测标注序列是否合法。

表3 非法标注序列示例
序列标注中,CRF不仅考虑当前时刻的观察状态,也考虑之前时刻的隐藏状态,因此能够充分利用相邻标签之间的信息,使最终的输出不是独立的标签序列,而是考虑规则和顺序的最佳序列。设={1,2,3,…,x}为输入的观察序列,={1,2,3,…,y}为对应的输出标注序列,CRF层在给定需要标注的观察序列的条件下,计算整个序列的联合概率分布,最终输出一个全局最优的标注序列,算法见公式(8)。

3 试验与结果分析
试验数据集采用第1小节构建的农业命名实体识别语料库,其中训练集、验证集和测试集的比例为7:2:1。采用实体级遮蔽策略的BERT模型(EmBERT),网络层数为12层,隐藏层维度为768,多头注意力机制中自注意力(Self Attention)头的数量为12。下游模型中使用的双向长短时记忆网络(BiLSTM)的隐藏层维度(lstm_dim)为128。为预防过拟合同时提高模型的泛化能力,在模型中引入了Dropout[32]机制。
3.1 试验设置
试验过程中需要优化调整的参数主要有学习率(learning_rate)、失活率(dropout_rate)、批处理规模(batch_size)和迭代次数(epochs)。学习率过大容易导致模型的损失增大、准确率降低;学习率过小则容易导致模型的收敛速度下降,因此合适的学习率是模型整体获得良好性能的保证。失活率是模型训练时神经元不更新权重的概率,用于防止模型过拟合,通常失活率设置为0.5。批处理规模即每批次训练的样本数量,其在一定程度上影响模型的数据处理速度和收敛精度;batch_size过大模型容易收敛到一些较差的局部最优点上,batch_size过小则容易导致模型不收敛或需要很大的epochs才能收敛。epochs为模型进行全数据训练的次数(如1个epoch表示模型完整训练一次),通常需要多个epochs来保证模型获得最好的学习效果。经过多次对比试验得到的最优参数设置如下,使用Adam[33]优化器,learning_rate为7e-5,dropout_rate为0.5,batch_size为32,epochs为150。
3.2 评价指标
试验采用召回率、准确率和1值来衡量模型的性能,评价指标计算公式如下:



式中TruePositive为准确识别的农业实体个数,ActualPositive为数据集中存在的农业实体总数,PredictPositive为识别出的农业实体总数。
3.3 结果与分析
面向农业领域4类实体(农作物、农药、病害、虫害),利用构建的农业命名实体识别语料库,设置3组对比试验验证分析本文提出的农业命名实体识别方法的有效性。
1)不同遮蔽策略性能的比较分析
为验证实体级遮蔽策略对提高中文农业命名实体推理和识别能力的有效性,分别对不使用遮蔽策略(No Masking)的模型Word2Vec+BiLSTM+CRF、使用字符级遮蔽策略(Word-level Masking(Chinese character))的模型Word-level Masking BERT+BiLSTM+CRF和使用实体级遮蔽策略(Entity-level Masking)的模型Entity-level masking BERT+BiLSTM+CRF进行对比试验,试验结果如表4所示。

表4 不同遮蔽策略试验结果
由表4可看出,使用实体级遮蔽策略的模型性能最好,准确率达到了94.56%。此外,使用实体级遮蔽策略相较于使用字符级遮蔽策略,模型的准确率、召回率和1值分别提高了2.59、1.7和2.15个百分点;相较于不使用遮蔽策略,模型的准确率、召回率和F1值分别提高了5.79、2.08和4个百分点。不使用遮蔽策略时,模型输出的字向量不包含上下文语义信息,难以解决一词多义的问题,因此模型识别性能相对较弱,准确率仅为88.77%。使用字符级遮蔽策略,通过对文本中的字符进行随机遮蔽,再让模型预测被遮蔽的字符,使编码器保留了每个字符的上下文分布表示,通过利用上下文信息在一定程度上解决了一词多义的问题,因此模型识别性能有较好的提升,准确率为91.97%。与字符级遮蔽策略相比,实体遮蔽策略是对文本中的完整实体进行随机遮蔽,再让模型预测被遮蔽实体中所有被[MASK]标志替换的中文字符,使模型可以学习到完整的实体级语义信息,提高对中文语义的推理和表征能力,因此模型的性能得到了进一步的提升,准确率为94.56%。
2)不同损失函数性能的比较分析
为验证焦点损失函数对提高中文农业命名实体识别能力的有效性,分别利用不同损失函数在EmBERT-BiLSTM-CRF模型上进行消融试验,试验结果如表5所示。
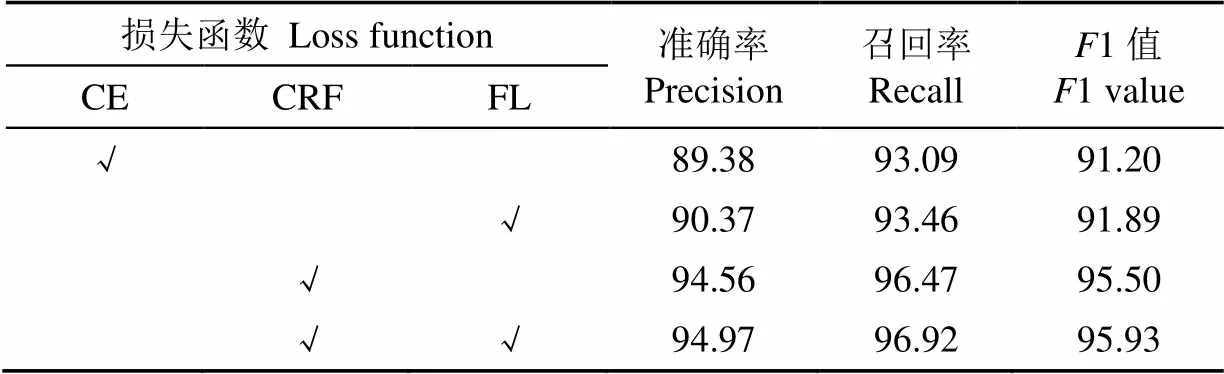
表5 不同损失函数试验结果
注:CE为交叉熵损失,CRF为条件随机场损失,FL为焦点损失。“√”表示模型中用到的损失函数。
Note: CE is the cross entropy loss, CRF is the conditional random field loss, FL is the focal loss. “√” indicates that the loss function is used in the model.
由试验结果可看出,使用CRF损失+FL的模型识别性能最好,1值为95.93%。其中,使用交叉熵损失(Cross Entropy,CE)的模型在样本分布不均衡时,损失函数的分布发生倾斜,使模型在训练过程中倾向于样本数量多的标签,导致样本数量少的标签的识别效果较差,模型的整体识别性能较差,1值为91.20%。使用焦点损失(FL)的模型,在CE的基础上加入权重参数和调制因子来在增大数量少的标签样本在损失函数中的权重,让模型在训练过程中倾向于难识别样本,提高了模型对难识别样本的识别能力,缓解了样本分布不均衡导致数量少的标签样本识别效果较差的问题,因此相较于CE其识别性能有所提升,模型1值为91.89%。使用CRF损失的模型,通过计算标签间的转移分数来建模标签转移路径,然后训练模型最大化真实路径的概率,让模型利用相邻标签的信息来输出最优的标注序列,因此相较于单独使用CE和FL的模型,其识别性能有较大提升,模型1值达到95.50%。使用CRF损失+FL的模型涵盖了CRF损失和FL的优点,不仅能缓解样本分布不均衡带来的问题还能利用相邻标签之间的信息,因此其识别性能优于上述所有模型,模型1值为95.93%。同时本文通过对FL中和的不同取值进行对比试验,由试验结果得出=0.25,=2.0时模型获得最优性能,试验结果如表6所示。

表6 FL不同α和γ的试验结果
注:为权重因子,为聚焦参数。
Note:is the weighting factor,is the focusing parameter.
3)不同模型性能的比较分析
为验证EmBERT-BiLSTM-CRF模型对中文农业命名实体识别的性能,分别与BiLSTM、LSTM-CRF[13]、BiLSTM-CRF[28]和BERT-BiLSTM-CRF模型进行对比试验,试验结果如表7所示。由试验结果可看出,本文模型的识别性能优于其他对比模型。
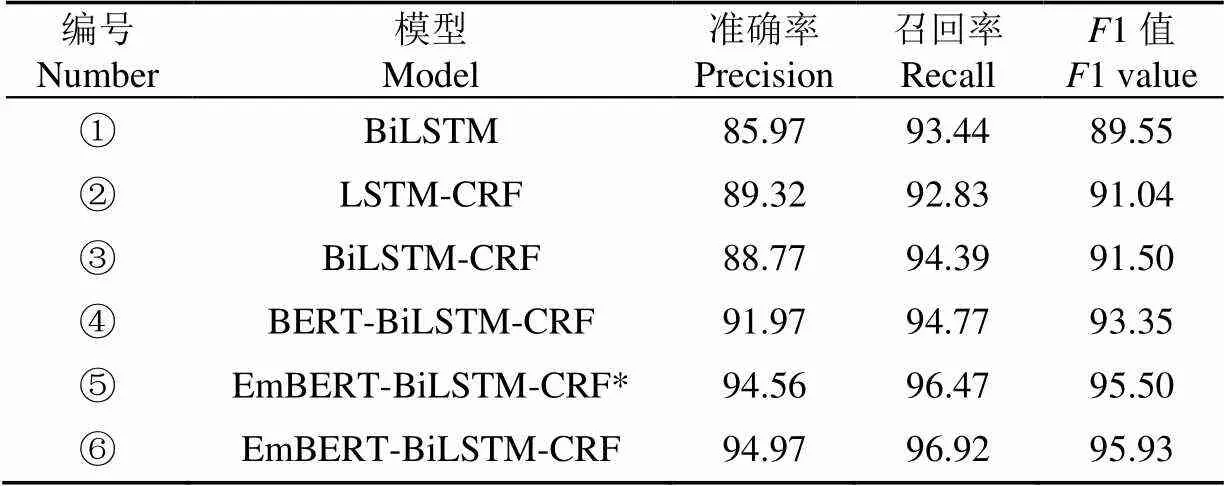
表7 不同模型试验结果
注:EmBERT-BiLSTM-CRF*为使用了实体级遮蔽策略但没有使用FL的模型。EmBERT-BiLSTM-CRF为使用了实体级遮蔽策略和FL的模型。
Note: EmBERT-BiLSTM-CRF* is a model that uses an entity-level masking strategy but does not use FL. EmBERT-BiLSTM-CRF is a model that uses an entity-level strategy and FL.
BiLSTM模型的输出相互独立,在进行标签预测时会出现标注偏置问题,因此其识别效果相对较差,模型1值为89.55%。LSTM-CRF和BiLSTM-CRF模型在LSTM和BiLSTM模型的基础上增加了CRF层,通过学习标注约束规则和利用相邻标签的信息,获得一个全局最优的标注序列来缓解标注偏置问题,与模型①相比,增加了CRF层的模型②③识别效果有所提升,1值分别为91.04%、91.50%。BERT-BiLSTM-CRF模型在BiLSTM-CRF模型的基础上引入了BERT预训练语言模型作为嵌入层,使模型更充分的考虑了字符的位置信息和上下文语义信息,与模型①②③相比其识别效果有所提升,1值为93.35%。
EmBERT-BiLSTM-CRF*模型不仅使用了BERT作为嵌入层学习字符的深度双向表示,并且根据中文语义的特点改进了语言遮蔽方法,使用实体级遮蔽策略(EM)对文本中的实体进行完整的遮蔽和预测,使模型能更好地表征中文语义,其识别效果相较于模型①②③④有了较大提升,1值为95.50%。EmBERT-BiLSTM-CRF模型在EmBERT-BiLSTM-CRF*的基础上引入焦点损失函数来缓解样本分布不均衡问题,通过增大数量少的标签样本在损失函数中的权重,让模型在训练过程中更关注难识别样本,提高模型对难识别样本的识别能力,模型的识别效果优于上述所有模型,1值为95.93%。试验验证了在中文农业命名实体识别的过程中,字符的位置信息和提高模型对实体完整语义的推理能力,对于农业实体的准确识别起到重要作用。
图5为不同模型对于农业领域4类命名实体识别的效果。从图5中可以看到,在所有实体类别中各个模型对农作物、农药和虫害实体的识别效果相对较好,对病害实体的识别效果相对较差。通过分析得到,虫害和农药实体的识别效果较好是因为农药实体大多以“剂”、“乳油”等字词结尾,虫害实体大多以“虱”、“虫”、“蝉”、“蚜”等字结尾,这两类实体均具有较为明显的实体特征,从而使模型对于这两类实体的识别效果较好。农作物实体的长度相对较短,大多为2至3个中文字符,因此模型对农作物实体特征的捕获更完整,对其识别效果也相对较好。病害实体中存在一些类似于“水稻倒伏”、“小麦混杂退化”、“花生烂种”等实体特征不太明显的实体,并且大多数病害实体存在实体嵌套的现象,例如“玉米圆斑病”、“水稻恶苗病”、“水稻东格鲁病毒病”等,这使得模型对于病害实体识别的效果相对较差。本文的EmBERT-BiLSTM-CRF模型对病害实体的识别准确率均高于其他几个模型,说明使用实体级遮蔽策略对实体进行完整遮蔽和预测,使模型更充分地捕获和表征字符的完整语义信息,从而提高农业命名实体的识别效果。

图5 不同模型对4类农业命名实体识别结果
4 结 论
本文针对中文农业命名实体长度较长且命名方式繁杂多变,导致识别准确率较低的问题,提出基于EmBERT-BiLSTM-CRF模型的农业命名实体识别方法。通过使用BERT(Bidirectional Encoder Representation from Transformers)预训练语言模型作为嵌入层,充分考虑字符的位置信息和上下文语义信息,并根据中文语义的特点改进了BERT原有的语言遮蔽方法,使用实体级遮蔽策略让模型对中文实体进行完整遮蔽,学习获得实体级的特征信息,从而缓解模型在预测时因语义不完整造成的偏差,增强模型对中文语义的表征能力。同时在训练过程中使用焦点损失函数,增大数量少的标签样本在损失函数中的权重,提高模型对难识别样本的识别能力。利用双向长短时记忆网络学习文本的长距离依赖信息,再使用条件随机场去获得全局最优标注序列,使得整个模型的识别效果得到了明显提升。模型的准确率为94.97%,召回率为96.92%,1值为95.93%。由于农业实体中存在着实体嵌套和实体特征不明显的问题,因此本文的下一步研究方向将着重于对实体特征不明显、实体边界模糊的实体的识别方法的研究。
[1] 金宁,赵春江,吴华瑞,等. 基于BiGRU_MulCNN的农业问答问句分类技术研究[J]. 农业机械学报,2020,51(5):199-206.
Jin Ning, Zhao Chunjiang, Wu Huarui, et al. Classification technology of agricultural questions based on BiGRU_MulCNN[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(5): 199-206. (in Chinese with English abstract)
[2] Li J, Sun A, Han J, et al. A survey on deep learning for named entity recognition[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, 34(1): 50-70.
[3] Mollá D, van Zaanen M, Smith D. Named entity recognition for question answering[C]// Proceedings of the Australasian Language Technology Workshop 2006, Carlton, Vic, Australasian Language Technology Association, 2006: 51-58.
[4] 吴赛赛,周爱莲,谢能付,等. 基于深度学习的作物病虫害可视化知识图谱构建[J]. 农业工程学报,2020,36(24):177-185.
Wu Saisai, Zhou Ailian, Xie Nengfu, et al. Construction of visualization domain-specific knowledge graph of crop diseases and pests based on deep learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(24): 177-185. (in Chinese with English abstract)
[5] Hanisch D, Fundel K, Mevissen H T, et al. ProMiner: Rule-based protein and gene entity recognition[J]. BMC Bioinformatics, 2005, 6(1): 1-9.
[6] Kim J H, Woodland P C. A rule-based named entity recognition system for speech input[C]// Sixth International Conference on Spoken Language Processing, Beijing, China, ISCA, 2000: 521-524
[7] 李想,魏小红,贾璐,等. 基于条件随机场的农作物病虫害及农药命名实体识别[J]. 农业机械学报,2017,48(S1):178-185.
Li Xiang, Wei Xiaohong, Jia Lu, et al. Recognition of crops, diseases and pesticides named entities in Chinese based on conditional random fields[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(S1):178-185. (in Chinese with English abstract)
[8] 王春雨,王芳. 基于条件随机场的农业命名实体识别研究[J]. 河北农业大学学报,2014,37(1):132-135.
Wang Chunyu, Wang Fang. Study on recognition of chinese agricultural named entity with conditional random fields[J]. Journal of Agricultural University of Hebei, 2014, 37(1): 132-135. (in Chinese with English abstract)
[9] Zhai F, Potdar S, Xiang B, et al. Neural models for sequence chunking[C]//Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, California, USA, AAAI, 2017: 3365-3371.
[10] Gridach M. Character-level neural network for biomedical named entity recognition[J]. Journal of Biomedical Informatics, 2017, 70: 85-91.
[11] Dong C, Zhang J, Zong C, et al. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition[M]//Natural Language Understanding and Intelligent Applications. Cham: Springer, 2016: 239-250.
[12] 赵鹏飞,赵春江,吴华瑞,等. 基于注意力机制的农业文本命名实体识别[J]. 农业机械学报,2021,52(1):185-192.
Zhao Pengfei, Zhao Chunjiang, Wu Huarui, et al. Research on named entity recognition of Chinese Agricultural based on attention mechanism[J]. Transactions of the Chinese Society for Agricultural Machinery, 2021, 52(1): 185-192. (in Chinese with English abstract)
[13] 孙娟娟,于红,冯艳红,等. 基于深度学习的渔业领域命名实体识别[J]. 大连海洋大学学报,2018,33(2):265-269.
Sun Juanjuan, Yu Hong, Feng Yanhong, et al. Recognition of nominated fishery domain entity based on deep learning architectures[J]. Journal of Dalian Ocean University, 2018, 33(2): 265-269. (in Chinese with English abstract)
[14] Shen Y, Yun H, Lipton Z C, et al. Deep active learning for named entity recognition[C]//Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, Canada, Association for Computational Linguistics, 2017: 252-256.
[15] 李丽双,郭元凯. 基于CNN-BLSTM-CRF模型的生物医学命名实体识别[J]. 中文信息学报,2018,32(1):116-122.
Li Lishuang, Guo Yuankai. Biomedical named entity recognition with CNN-BLSTM-CRF [J]. Journal of Chinese information Processing, 2018, 32(1):116-122. (in Chinese with English abstract)
[16] 郭旭超,唐詹,刁磊,等. 基于部首嵌入和注意力机制的病虫害命名实体识别[J]. 农业机械学报,2020,51(S2):335-343.
Guo Xuchao, Tang Zhan, Diao Lei, et al. Recognition of chinese agricultural diseases and pests named entity with joint adical-embedding and self-attention mechanism[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(S2): 335-343. (in Chinese with English abstract)
[17] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013.09.07) [2022.06.29]. https://doi.org/10.48550/arXiv.1301.3781.
[18] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]// Advances in Neural Information Processing Systems, Lake Tahoe, US: MIT Press, 2013, 26: 3111-3119.
[19] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 2019: 4171-4186.
[20] Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integration[EB/OL]. (2019.04.09) [2022.06.29]. https://doi.org/10.48550/arXiv.1904.09223.
[21] 赵鹏飞,赵春江,吴华瑞,等. 基于 BERT 的多特征融合农业命名实体识别[J]. 农业工程学报,2022,38(3):112-118.
Zhao Pengfei, Zhao Chunjiang, Wu Huarui, et al. Recognition of the agricultural named entities with multi-feature fusion based on BERT[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(3): 112-118. (in Chinese with English abstract)
[22] 杜琳,曹东,林树元,等. 基于BERT与Bi-LSTM融合注意力机制的中医病历文本的提取与自动分类[J]. 计算机科学,2020,47(S2):416-420.
Du Lin, Cao Dong, Lin Shuyuan, et al. Extraction and automatic classification of TCM medical records based on attention mechanism of BERT and Bi-LSTM[J]. Computer Science, 2020, 47(S2): 416-420. (in Chinese with English abstract)
[23] 任媛,于红,杨鹤,等. 融合注意力机制与BERT+ BiLSTM+CRF模型的渔业标准定量指标识别[J]. 农业工程学报,2021,37(10):135-141.
Ren Yuan, Yu Hong, Yang He, et al. Recognition of quantitative indicator of fishery standard using attention mechanism and the BERT+BiLSTM+CRF model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(10): 135-141. (in Chinese with English abstract)
[24] Ashish V, Noam S, Niki P,et al.Attention is all you need[C]//Advances in Neural Information Processing Systems, Long Beach, California, USA, Curran Associates Inc, 2017: 6000-6010.
[25] Hasim A, Andrew S, Françoise B. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition[J]. Computer Science, 2014, 4(1):338-342.
[26] Felix A, Jürgen S. Lstmrecurrent networks learn simple context-free and context-sensitive languages[J]. IEEE Transactions on Neural Networks, 2001, 12(6): 1333-1340.
[27] Hammerton J. Named entity recognition with long short-term memory[C]//Proceedings of the Seventh Conference on Natural language learning at HLT-NAACL 2003, Edmonton, Canada, Association for Computational Linguistics, 2003: 172-175.
[28] Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks[C]//2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, IEEE, 2013: 6645-6649.
[29] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. Computer Science, 2015, 4(1): 1508-1519.
[30] Lin T, Priya G, Ross G, et al. Focal Loss for Dense Object Detection[C]// 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, IEEE, 2017: 2999-3007.
[31] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]// Proceedings of the 18th International Conference on Machine Learning 2001, San Francisco, CA, USA, Morgan Kaufmann Publishers Inc, 2001: 282-289.
[32] Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[33] Kingma D, Ba J. Adam: A method for stochastic optimization[C]// Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, 2015: 1-15.
Named entity recognition of agricultural based entity-level masking BERT and BiLSTM-CRF
Wei Zijun1, Song Ling2,3※, Hu Xiaochun4, Chen Ningjiang1,3
(1.530004; 2.530200,;3530004; 4.530007)
An intelligent question-answering of agricultural knowledge can be one of the most important parts of information agriculture. Among them, named entity recognition has been a key technology for intelligent question-answering and knowledge graph construction in the fields of agricultural domain. It is also a high demand for the accurate identification of named entities. Furthermore, the Chinese named entity recognition can be confined to the location and semantic information of characters, due to the long length of agricultural entity and complex naming. Therefore, it is very necessary to improve the recognition performance in the process of named entity recognition, particularly for the sufficient capture of character position, contextual semantic features, and long-distance dependency information. In this study, a novel Chinese named entity recognition of agriculture was proposed using EmBERT-BiLSTM-CRF model. Firstly, the Bidirectional Encoder Representation from Transformers (BERT) pre-trained language model was applied as the layer of word embedding. The context semantic representation of the model was then improved to alleviate the polysemy, when pre-training the depth bidirectional representation of word vectors. Secondly, the language masking of BERT was enhanced significantly, according to the characteristics of Chinese. An Entity-level Masking strategy was utilized to completely mask the Chinese entities in the sentence with the consecutive tokens. The Chinese semantics was then better represented to alleviate the bias caused by incomplete semantics. Thirdly, the Bidirectional Long Short-Term Memory Network (BiLSTM) model was adopted to learn the semantic features of long-sequence using two LSTM networks (forward and backward), considering the contextual information in both directions at the same time. The long-distance dependency information of text was then captured during this time. Finally, the Conditional Random Field (CRF) was used to learn the labelling constraint in the training data. Among them, the learned constraint rules were used to detect whether the label sequence was legal during prediction. After that, the CRF also utilized the information of adjacent labels to output the globally optimal label sequence. Thus, the output of the model was a dependent label sequence, but an optimal sequence was considered the rules and order. A focal loss function was also used to alleviate the unbalanced sample distribution. A series of experiments were performed to construct the corpus of named entity recognition. As such, the corpus contained a total of 29 790 agricultural entities after BIO labelling, including 11 057 crops, 8 121 pesticides, 4 505 diseases, and 6 107 pest entities, in which the training, validation, and test set were divided, according to the ratio of 7:2:1. Four types of agricultural entities from the text were identified, including the crop varieties, pesticides, diseases, and insect pests, and then to label them. The experimental results show that the recognition accuracy of the EmBERT-BiLSTM-CRF model for the four types of entities was 94.97%, and the F1 score was 95.93%. Which compared with the models based on BiLSTM-CRF and BERT-BiLSTM-CRF, the recognition performance of EmBERT-BiLSTM-CRF is significantly improved, proved that used pre-trained language model as the a word embedding layer can represent the characteristics of characters well and the Entity-level Masking strategy can alleviate the bias caused by incomplete semantics, thereby enhanced the Chinese semantic representation ability of the model, so that enabling the model to more accurately identify Chinese agricultural named entities. This research can not only provide arelatively high entity recognition accuracy for tasks such as agricultural intelligence question answering, but also offer new ideas for the identification of Chinese named entities in fishery, animal husbandry, Chinese medical, and biological fields.
agriculture; named entity recognition; entity-level masking; BERT; BiLSTM; CRF
10.11975/j.issn.1002-6819.2022.15.021
TP391
A
1002-6819(2022)-15-0195-09
韦紫君,宋玲,胡小春,等. 基于实体级遮蔽BERT与BiLSTM-CRF的农业命名实体识别[J]. 农业工程学报,2022,38(15):195-203.doi:10.11975/j.issn.1002-6819.2022.15.021 http://www.tcsae.org
Wei Zijun, Song Ling, Hu Xiaochun, et al. Named entity recognition of agricultural based entity-level masking BERT and BiLSTM-CRF[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(15): 195-203. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.15.021 http://www.tcsae.org
2021-12-20
2022-06-29
国家重点研发计划课题(2018YFB1404404);广西重点研发计划项目(桂科AB19110050);南宁市科技重大专项(20211005)
韦紫君,研究方向为自然语言处理。Email:1034268781@qq.com
宋玲,教授,研究方向为物联网及大数据计算。Email:731486203@qq.com
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
小学生学习指导(低年级)(2019年12期)2019-12-04
中国外汇(2019年18期)2019-11-25
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
