
基于改进残差网络的橡胶林卫星影像语义分割方法
2022-11-13 07:15刘秋斌陈方园刘大召
农业工程学报 2022年15期
余 果,刘秋斌,陈方园,刘大召,2
基于改进残差网络的橡胶林卫星影像语义分割方法
余 果1,刘秋斌1,陈方园1,刘大召1,2※
(1. 广东海洋大学电子与信息工程学院,湛江 524003;2. 广东省海洋遥感与信息技术工程技术研究中心,湛江 524003)
为进一步提升现有基于残差的分割模型在测试集上的信息提取能力和验证改进残差优化策略普适性及实现橡胶卫星影像的更优分割,该研究提出了一种通用改进残差策略,以哨兵-2多光谱卫星影像为数据源构建数据集,并使用改进后残差网络ResNet50_ve作为OCRNet模型的骨干网络,实现基于变种残差网络的OCRNet模型(ResNet-ve-OCRNet),使用在ImageNet1k分类数据集上蒸馏好的学生模型作为预训练模型参与ResNet-ve-OCRNet模型的训练。研究结果表明使用层数中等的基于50层残差网络在小尺度卫星影像训练集上各指标收敛效果优于较深层数的101层残差网络,与DeeplabV3、DeeplabV3+、PSPNet模型相比,以ResNet50_ve为骨干网络的OCRNet在验证集上的平均交并比达到0.85,像素准确率达到97.87%,卡帕系数达到0.90。该研究提出的改进残差策略具有一定的普适性可应用到众多主流分割模型上且有评价指标性能增益,从预测图来看,基于改进残差网络(ResNet-ve)的模型抑制了在测试集预测图上的上下文信息缺失问题,能够实现橡胶林卫星影像的更优精确分割。
遥感;深度学习;橡胶林;语义分割;残差网络
0 引 言
语义分割作为经典的计算机图形学问题主要处理图像在像素级别的分类问题,即对每个像素实现逐像素的精确分类[1-2]。传统机器学习方法已被广泛应用于语义分割领域,包含支持向量机(SVM)、随机森林分类器、最近邻法[3-5]。但在高分辨率遥感影像的精细分割上,传统机器学习的分类方法无法处理多尺度信息提取问题[6]。
传统基于全卷积网络(Fully Convolutional Networks,FCN)的语义分割方法(如Unet等)面临着上下文信息缺失的问题[7]。DeeplabV3模型是Chen等[8]提出使用串行或者并行不同膨胀率的空洞卷积(Atrous Convolution)来增大模型感受野以抑制上下文丢失问题。在DeeplabV3+模型中,Chen等[9]引入编码器-解码器结构,使用DeeplabV3模型作为编码器部分,其中Xception作为编码器的骨干网络,另外引入一个解码器模块,通过引入编码器-解码器结构进一步实现模型性能提升。PSPNet模型是Zhao等[10]使用金字塔池化(Pyramid Pooling)模块来抽取4路并行的多尺度上下文信息实现上下文信息增强。OCRNet模型是基于物体区域的上下文信息语义分割方法通过构建上下文信息时显式增强来自同一类物体的像素贡献权重[11]。
为了进一步提升上述经典模型提取上下文信息能力,徐长友等[12]提出了在Deeplabv3+中加入通道注意力机制模块增强高分遥感影像水域的分割效果;王俊强等[13]将Deeplabv3+与CRF(全连接条件随机场)相连接实现了对分割边界信息的优化;赖丽琦[14]将Deeplabv3+的骨干网络替换成MobileNetV2并对Deeplabv3+模型结构进行改进,提升对无人机影像的分割精度;王华俊等[15]将DeepLabv3+的骨干网络替换为MobileNetV2并对不同膨胀率的空洞卷积进行优化组合以提高模型提取精度。当前对经典模型优化可总结为以下三种思路,一是在各模型内部添加模块如添加注意力机制模块;二是在模型末端输出特征图前添加条件随机场提升分割效果;三则是将各模型编码器部分的骨干网络进行改进或者替换。
从相关文献发现,在解决遥感影像分割中,添加条件随机场所带来的精度提升是有限的[16],而添加注意力机制面临着空间信息丢失问题[17]。前两种优化策略思路在优化策略普适能力上不及第三种改进思路。骨干网络作为语义分割任务基本特征提取器,用于提取输入图像特征图,被应用到所有的语义分割模型中[17]。通过对骨干网络改进并复用到诸多模型,可验证这一优化策略的普适能力。
为了进一步提升各模型的上下文信息提取能力和验证改进残差策略的普适性,本文基于哨兵-2和大疆无人机影像数据作为基础数据源,使用残差网络并改进残差作为各模型特征提取的骨干网络,通过对比DeeplabV3、DeeplabV3+、PSPNet、OCRNet四种模型的指标增益,验证基于改进残差的优化策略普适能力,以期为现阶段语义分割模型优化提供新改进思路。
1 材料和方法
1.1 研究区和卫星影像选择
本试验研究区域是粤西的湛江徐闻地区,隶属广东省湛江市,位于中国大陆最南端,南临琼州海峡,与海南岛隔海相望,东滨南海,西濒北部湾,北与雷州市接壤。介于东经109°52′至110°35′,北纬20°13′至20°43′之间,土地总面积1 979.6 km2。徐闻县属热带季风气候,日照充足,太阳辐射能丰富。
该研究试验使用的是欧空局(ESA)Sentinel-2卫星数据,哨兵2由2颗相同的卫星哨兵2号A(Sentinel-2A)与B(Sentinel-2B)组成的卫星星座。哨兵2包含13个波段,范围覆盖了可见光、近红外和短波红外。哨兵2的影像幅宽为290 km,空间分辨率最高可达10 m。选用哨兵影像的原因是相较于其他付费的高分辨率卫星影像如worldview-2,哨兵2免费易得且仅需两幅哨兵2影像即可覆盖徐闻县全境,该研究训练阶段采用的数据是两幅2019年5月18号的无云影像数据(两幅影像成像时间信息编号为20190518T030551,两幅影像的相对轨道编号R075),测试阶段采用的是两幅2020年5月7号的无云影像数据(两幅影像成像时间信息编号为20200507T030539,两幅影像的相对轨道编号R075),使用欧空局Sen2cor插件进行大气校正,导出B11、B8、B5三个波段进行假彩色合成并在ENVI中进行裁剪和融合镶嵌操作。B11、B8、B5相比较于传统可见光波段组合具有更好的目视解译效果,哨兵的B11(短波红外)和B8(近红外)广泛用于农业领域的深绿色植被提取,加入B5植被红边波段可强化对深绿色植被的敏感度。
1.2 标签定义和数据集构建
原始影像面积较大,无法整幅输入网络训练。在徐闻影像上裁切出一个像素尺寸大小为2 256像素×628像素大小的矩形区域作为感兴趣区(Region of Interest,ROI),该影像为3通道24bit色深的影像,设置5种类别(林地、居民点及工矿用地、水域、橡胶林、其他),湛江作为热带季风气候没有草地无需将草地纳入分类范围,而设置林地与橡胶林是因为二者在伪彩色影像上有明显的光谱色泽差异明显需要将二者进行分离。在ArcGIS软件上绘制了各类别对应矢量标签并对标签进行栅格化处理,使用python脚本修改栅格化标签类别灰度值并建立各类别(林地、居民点及工矿用地(后简称为居民地)、水域、橡胶林、其他)与对应灰度值之间(1、2、3、4、0)映射关系,将栅格化标签和矩形研究区影像裁剪成256像素×256像素大小的PNG瓦片数据,按照6:2:2的比例划分成训练集、验证集和测试集,并在2020年5月7号的哨兵2影像上裁剪出一副2 256像素×514像素大小的影像输入网络作为测试,使用Paddleseg建立起类别标签瓦片数据和影像瓦片数据之间的映射关系。数据集构建流程见图1。
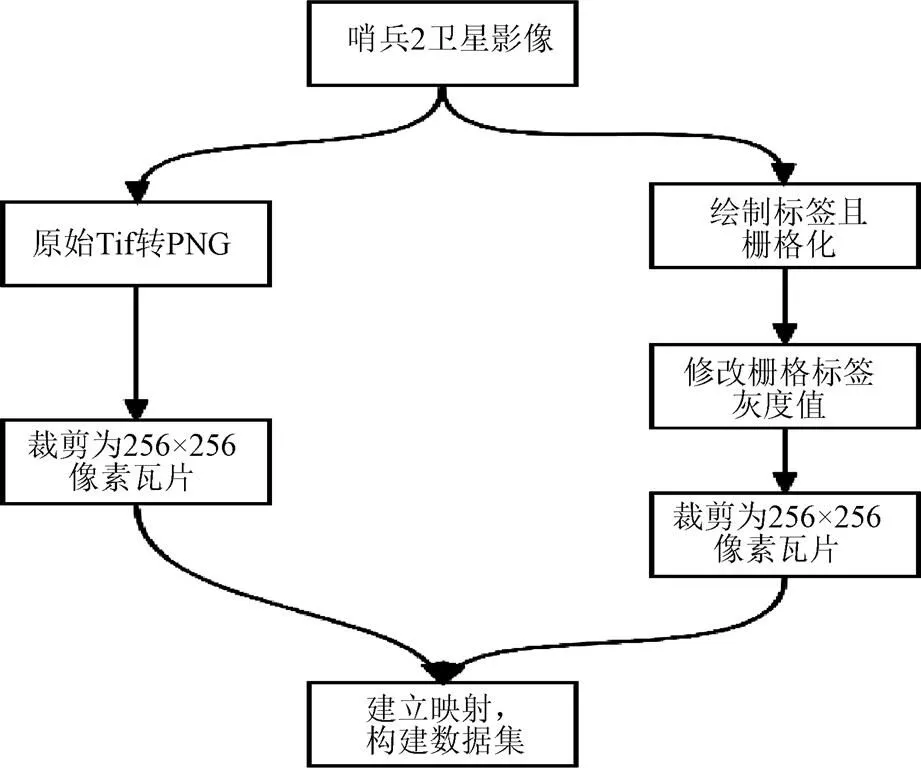
图1 数据集构建流程图
1.3 用于辅助验证的无人机影像
该研究试验使用大疆Phantom 4 RTK拍摄大量橡胶林无人机影像,Phantom 4 RTK摄取的无人机影像为RGB可见光三波段数据,使用Pix4D mapper软件对获得的无人机影像进行空三和点云、纹理处理。处理后的橡胶林无人机正射影像和DSM影像(数字表面模型)主要用于辅助验证和作为卫星影像目视判读依据,无人机影像和DSM影像见图2。

图2 用于辅助验证的无人机影像和DSM影像
1.4 试验平台及模型超参数设置
本试验硬件平台使用16 G内存,Intel Core i7-10750H CPU,Nvidia 2070 8 G显卡,软件平台基于Windows10 19043版本 64位操作系统,使用conda安装百度深度学习框架的PaddlePaddle 2.1版本,python环境为3.7.9结合PaddleSeg 2.3套件。4个模型的超参数设置如下,4个模型的训练参数batch_size设置为2,使用带动量的SGD优化器、动量大小为0.9、L2正则化大小为0.000 1,学习率衰减策略为多项式衰减(Polynomial Decay),初始学习率为0.002 5,衰减率为0.9,最终学习率为0,损失函数为交叉熵损失函数(CrossEntropyLoss)。本试验对于每种网络进行20 000次迭代(iters),迭代训练周期 iters 最大值为1 000,每200次iters之后在验证集上进行评估,若连续2 000次iters的评价指标都不再升高,则采用提前终止模型训练的策略(Early Stopping)结束模型训练。
1.5 研究方法
ResNet为2015年提出的网络模型[18],有5型(ResNet18、ResNet34、ResNet50、ResNet101、ResNet152,它们基本结构相同,区别在于网络层数不同)被广泛应用于计算机视觉领域,常用做各种网络模型的骨干网络(backbone)。本文预试验部分比较使用ResNet50_vd和ResNet101_vd作为DeepLabV3、DeepLabV3+、PSPNet、OCRNet四种模型的骨干网络,发现分割小尺度影像数据集宜使用50层的ResNet50_vd。之后比较基于本文提出的ResNet50_ve作为以上4种模型骨干网络,在上述模型训练阶段,需使用迁移学习方法启动模型训练和加速模型训练,经过消融试验比较得出适合分割橡胶林卫星影像的模型且验证了改进残差策略的普适性和上下文信息提取能力。
1.5.1 标准残差网络与ResNet_vd
标准ResNet网络如图3所示,由输入、输出和中间卷积部分组成,中间卷积部分由4个stage组成。输入部分是由一个步长为2的7×7卷积(Conv)模块和一个步长为2的3×3最大池化(MaxPool)模块组成;卷积层中每一个stage都由一个下采样模块(DownSampling)和若干个残差块(Residuals)组成,残差块结构与下采样模块结构相同(但残差块中所有模块步长为1)。残差块数量决定了残差网络最终层数。下采样模块由路径A(Path A)和路径B(Path B)加权连接而成。在下采样模块路径A中,由2个步长为1的1×1卷积包含一个步长为2的3×3卷积模块,这种结构形式被称为甚深瓶颈结构(Deeper Bottleneck Architecture,DBA),一个××(高度为,宽度为,通道数为)的特征图经过甚深瓶颈结构之后,特征图高度和宽度缩小至原来的1/2,通道数增至原来的四倍为4C。
He等[19]提出ResNet的一系列衍生网络,其中ResNet_vd的改进策略是在标准残差(见图3)下采样模块路径B的前端添加一个步长为2的2×2均值池化(AvgPool)模块(见图4a),本文残差网络模型选取ResNet_vd。
对于本文试验需先从5型ResNet_vd中确定适合分割橡胶林的ResNet_vd层数,选取中小尺度影像数据集应用最广泛的101层和50层ResNet_vd进行预试验,比较二者间指标差距。
1.5.2 改进型ResNet_vd(ResNet_ve)残差网络
本文骨干网络分别挑选101层的残差网络(ResNet101_vd)和50层的残差网络(ResNet50_vd)比较二者在橡胶林影像分割上的评价指标差距,发现基于ResNet50_vd的模型性能优于基于ResNet101_vd的模型,确定ResNet50_vd作为后续试验的基线网络(baseline)。
其次,为了进一步提升基线网络性能,受到甚深瓶颈结构和Tong He的改进思路启发,本文使用2个步长为1的1×1卷积包含一个步长为2的2×2最大池化(MaxPool)模块重构下采样模块路径B(见图4b),因同一stage中的残差块和下采样结构相同,使用相同的改进策略应用到同一stage的残差块路径B中,将4个改进后的stage重新连接,修改激活函数为PReLU,构成改进后的ResNet-ve网络。最后在基于ResNet_ve骨干网络的4种模型的训练阶段,通过迁移学习将ResNet50_vd在ImageNet1k分类数据集上蒸馏得到的学生模型作为预训练模型,注入权重参数给ResNet_ve骨干网络以启动4种模型。
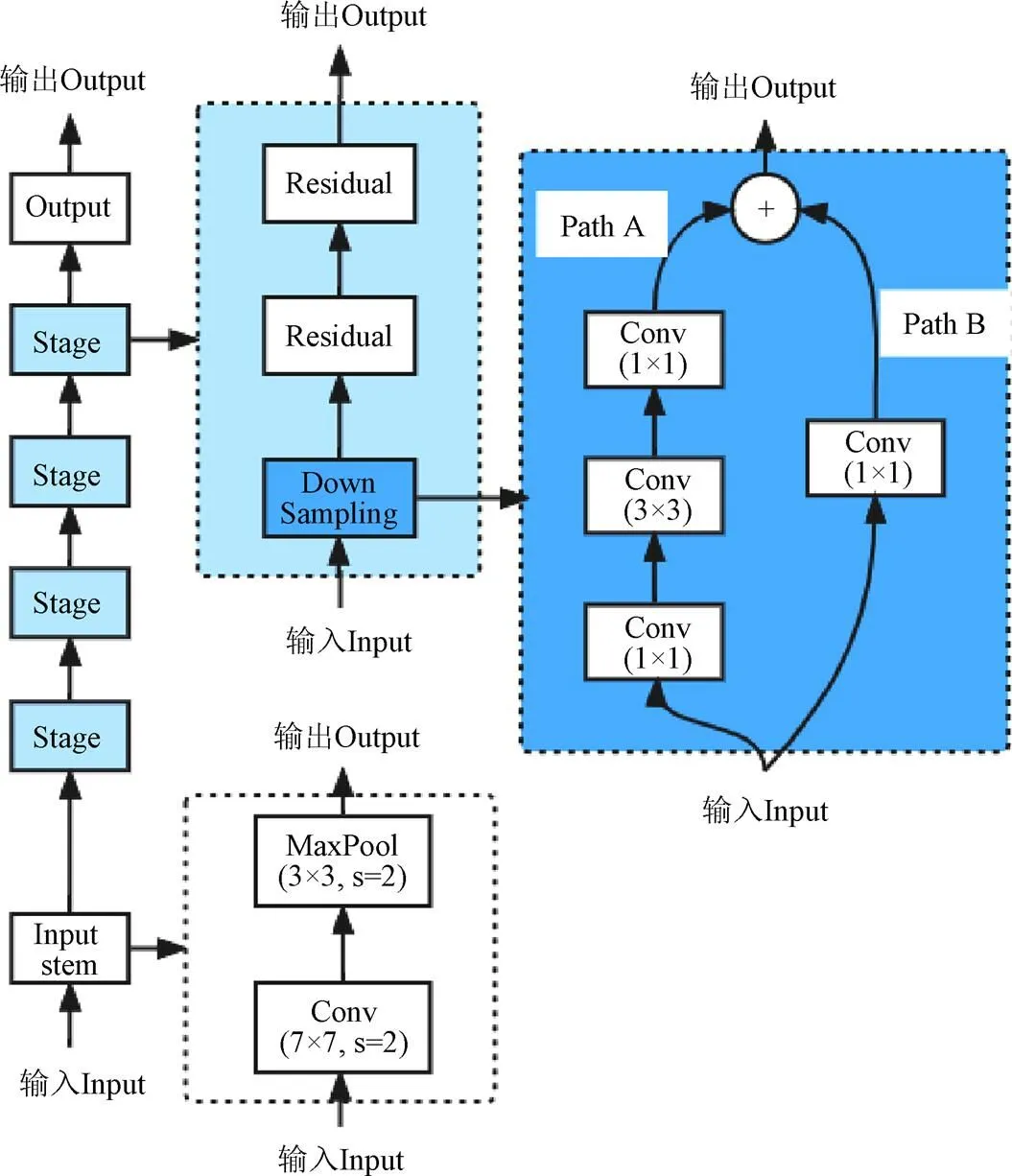
图3 ResNet的结构图
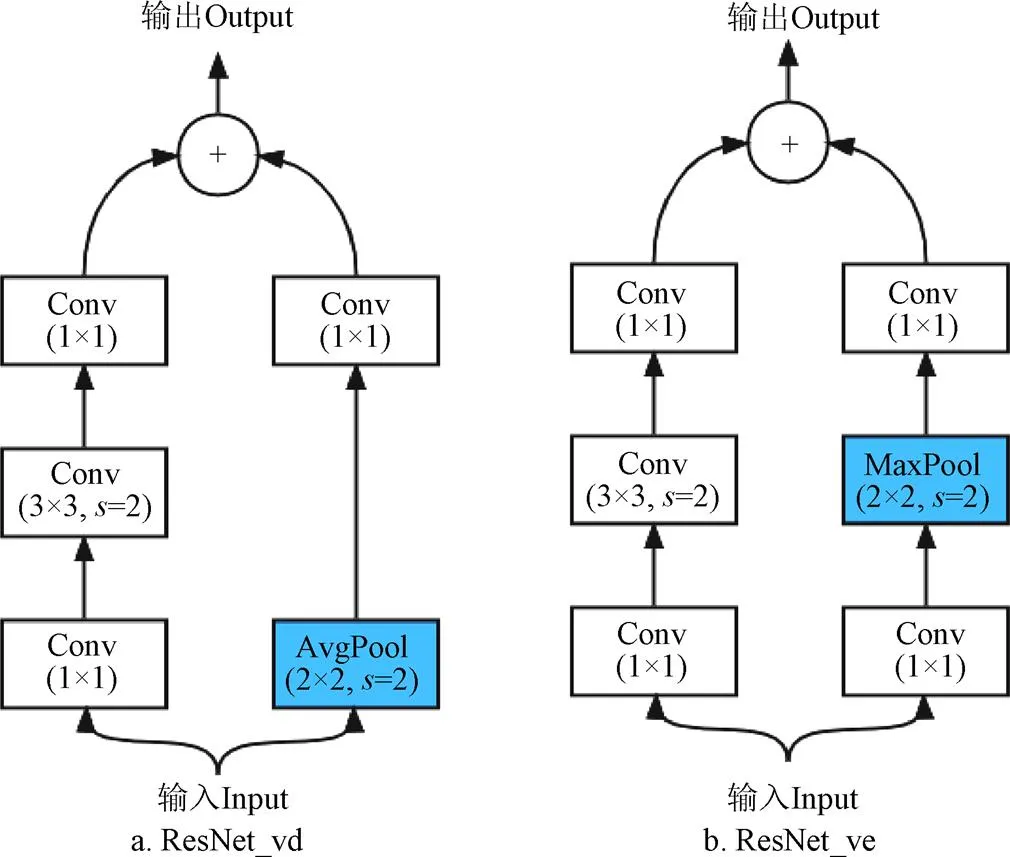
图4 ResNet_vd和ResNet_ve的对比图
1.5.3 SSLD蒸馏策略和迁移学习方法启动模型训练
在超大数据集上训练产生的模型具有很强的泛化能力,但这些超大模型的网络权重参数无法直接用于启动本文模型的训练,需要将这些这些超大数据集上训练出的大模型进行压缩以启动本文模型的训练和加速本文模型的训练速度,压缩后的模型通过迁移学习(Transfer learning)可加快本文模型的训练速度,其中知识蒸馏[20]是指使用教师模型(teacher model)去指导学生模型(student model)学习特定任务,保证小模型在参数量不变的情况下得到较大的性能提升获得与大模型相似的精度指标。本文使用一种简单的半监督标签知识蒸馏方案(SSLD,Simple Semi-supervised Label Distillation),SSLD基于已有蒸馏方案[21-25]在ImageNet22k分类数据集上使用ResNeXt101为教师模型进行蒸馏训练得到学生网络ResNet_vd,将蒸馏后的学生网络在ImageNet1k数据集上微调,将微调后的学生模型作为基于ResNet_ve的四种模型的预训练模型,在4种模型训练时注入网络权重参数,加速4种模型训练,迁移学习的流程图如图5所示。
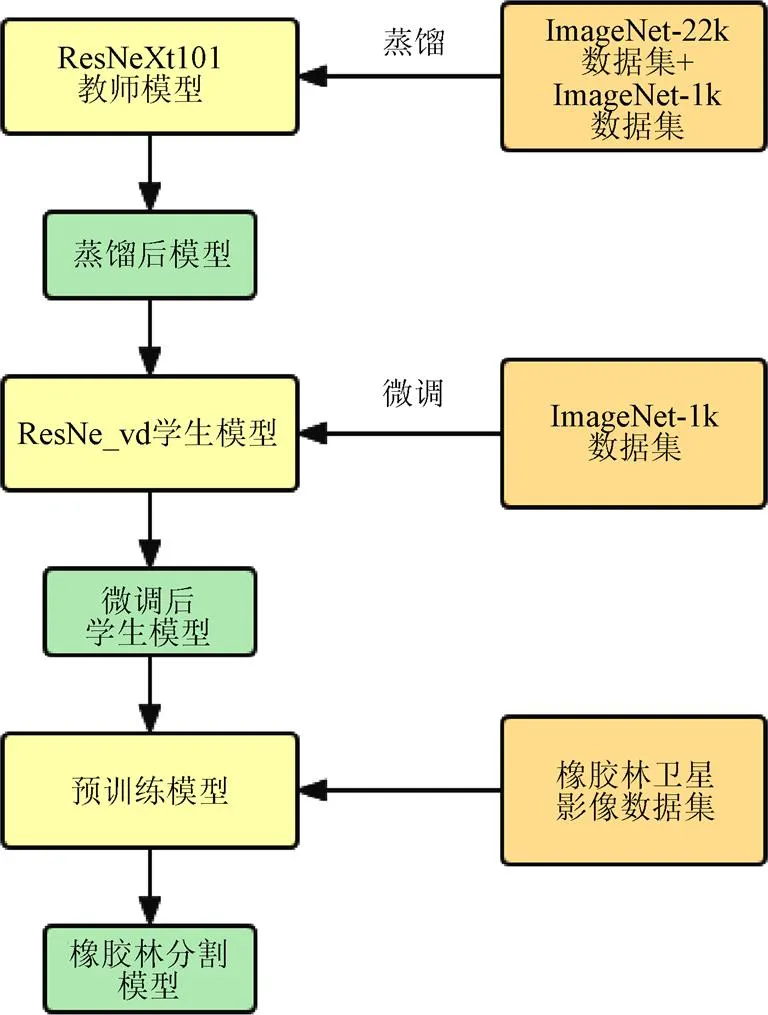
图5 SSLD蒸馏以及迁移学习流程图
1.6 评价指标
像素准确率(Pixel Accuracy,PA):计算正确分类的像素数量与所有像素数量的比例,取值范围在0~1之间。
平均交并比(mean Intersection-over-Union, mIoU):计算像素真实值和像素预测值两个集合的交集与二者并集的比例,取值范围在0~1之间。
卡帕系数(Kappa coefficient)用于衡量模型像素真实值和像素预测值两个集合是否具有一致性的指标,取值范围在0~1之间。
以上有两指标涉及到真实值与预测值之间的关系,可使用二阶混淆矩阵(Confusion matrix)表征真实值与预测值二者间关系,对于多分类(类)问题可使用×二阶混淆矩阵,下列计算公式中p代表×维二阶混淆矩阵第类被识别成第类的像素个数,、为对应混淆矩阵中第类和第类,P为求解Kappa的中间量。
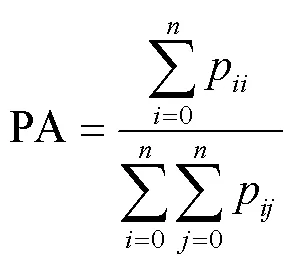
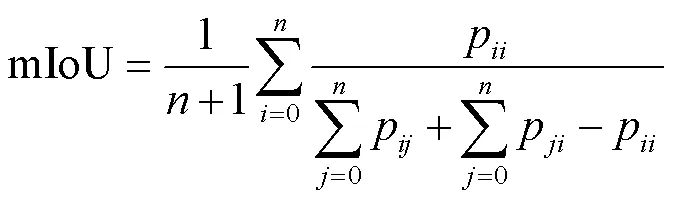
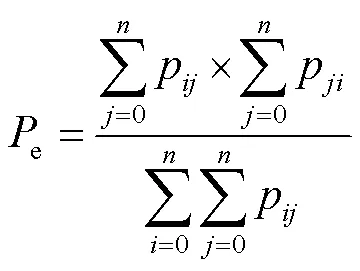
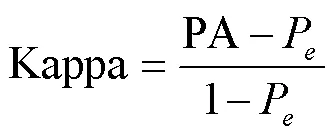
2 结果与分析
本文通过消融试验迭代20 000次分别比较了基于ResNet50_vd和ResNet101_vd作为骨干网络的4种网络模型,在ImageNet1k数据集上使用了简易的半监督知识蒸馏策略进行预训练之后,将蒸馏后学生模型的网络权重参数迁移学习到4种模型,基于两种ResNet_vd的4种网络训练阶段的mIoU和Pixel Accuracy变化曲线见图6,在验证集上各评价指标结果及训练集预测所消耗时间和各网络训练参数见表1。
2.1 残差网络层数的确定
本文试验首先使用广泛应用的50层残差(ResNet50_vd)和101层残差(ResNet101_vd),针对本文试验采用小尺度的徐闻卫星影像数据集,需比较得出适用于本次分割任务的残差网络层数。综合表1和图6数据经过对比发现,在训练阶段相较于101层的模型,使用50层残差的4种模型的PA和mIoU曲线更加平滑,且使用了ResNet101_vd的4种模型在三大评价指标上都不及基于ResNet50_vd的4种模型,故使用50层的残差网络作为后续试验的基线网络。
在以ResNet50_vd为骨干网络的4种模型的变化曲线中,DeepLabV3与DeepLabV3p的mIoU和kappa性能相当,像素准确率上DeepLabV3p相比较DeepLabV3增加0.55个百分点,但二者不及PSPNet和OCRNet。相较于PSPNet,OCRNet在mIOU上领先0.04,在Kappa上领先0.02,像素准确率上领先0.51个百分点,在验证集上推理速度快了22 s。综合各项指标,基于ResNet50_vd的OCRNet在4种模型中的综合表现最优。
2.2 基于ResNet50_vd与ResNet50_ve的4种模型比较
后续试验选取50层的残差网络作为基线网络,通过迁移学习ResNet50_vd在ImageNet1k分类数据集蒸馏后的模型参数,比较本研究提出的基于ResNet50_ve(见表1)的4种模型在验证集上的各项指标数据,表中数据表明使用ResNet50_ve为骨干网络4种模型中OCRNet模型在三项指标上都达到了最大值,在验证集推理速度和参数量上仅次于基于ResNet50_vd的OCRNet。
相较于ResNet50_vd,使用了ResNet50_ve的4种模型都有不同程度的性能提升。在mIoU上,DeepLabV3提升0.03,DeepLabV3p提升0.05,PSPNet提升0.03,OCRNet提升0.01。在Kappa上,DeepLabV3提升0.02,DeepLabV3p提升0.03,PSPNet提升0.01,OCRNet提升0.01。在Pixel Accuracy上,DeepLabV3提升0.34个百分点,DeepLabV3p提升0.55个百分点,PSPNet提升0.29个百分点,OCRNet提升0.04个百分点。
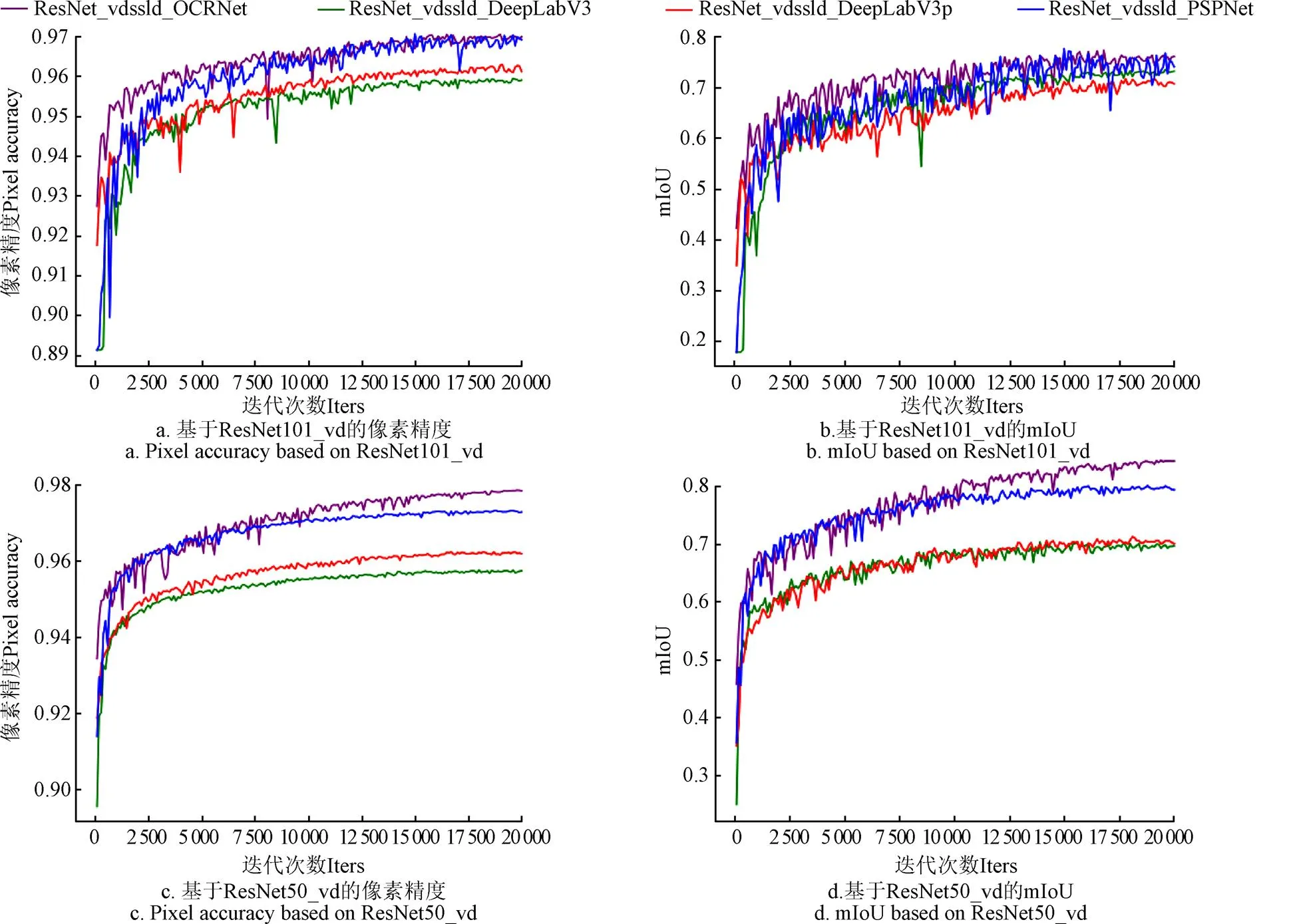
图6 基于ResNet_vd的四种模型在训练阶段的平均交并比(mean Intersection-over-Union, mIoU)和Accuracy曲线图
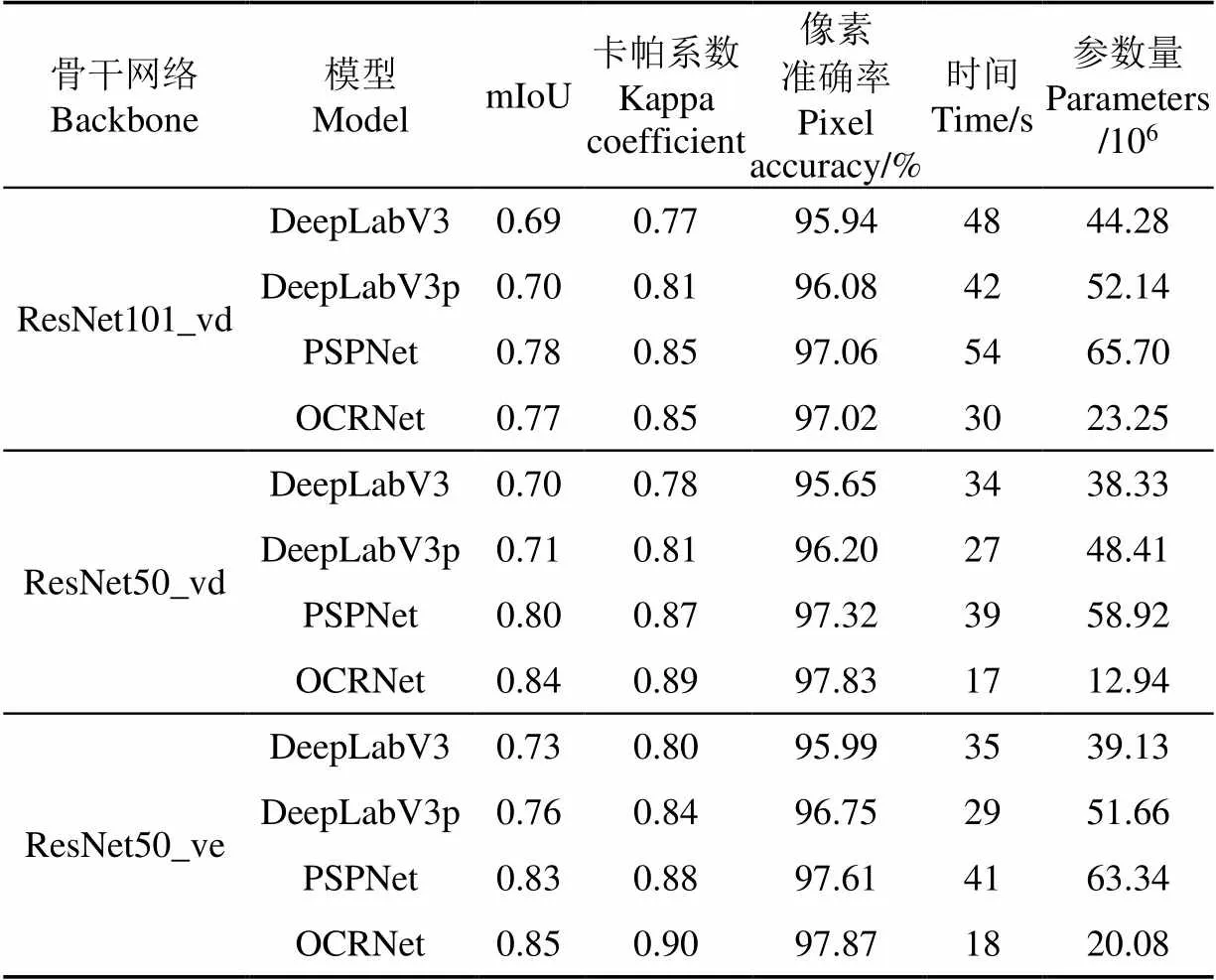
表1 ResNet_vd和与ResNet_ve的四种模型的比较
2.3 基于ResNet50_vd与ResNet50_ve的分割图比较
为验证改进残差模型的泛化能力和对图像的分割效果,分别使用基于ResNet50_ve的OCRNet和DeepLabV3p模型以及基于ResNet50_vd的OCRNet和DeepLabV3p模型预测一张2256×514大小的影像,由于研究区较大橡胶林分散,在预测图上裁剪部分以展示模型的分割结果。从表1数据可得,以ResNet50_ve为骨干网络的OCRNet在验证集上的平均交并比达到0.85,像素准确率达到97.87%,卡帕系数达到0.90。
图7中基于ResNet50_vd的DeepLabV3p和OCRNet模型分割林地和水域有较明显的边缘上下文信息丢失问题,而基于ResNet50_vd的DeepLabV3p更是没有分割出橡胶林的内部边界且在多地类中都有信息丢失,分割效果较差。在使用ResNet50_ve为骨干网之后,在林地、水域地类上有明显的上下文信息增强。在预测橡胶林、水域、林地这些拓扑封闭且光谱色泽匀度一致的地类,上述模型具有一定的分割效果,但在分割居民地这类没有严格封闭的拓扑学边界地类时,以上分割模型均有待提升。综合对比基于ResNet50_vd的DeepLabV3p的两种模型的预测图,使用基于本文提出的ResNet50_ve的模型在上下文信息提取能力上有一定程度提升。
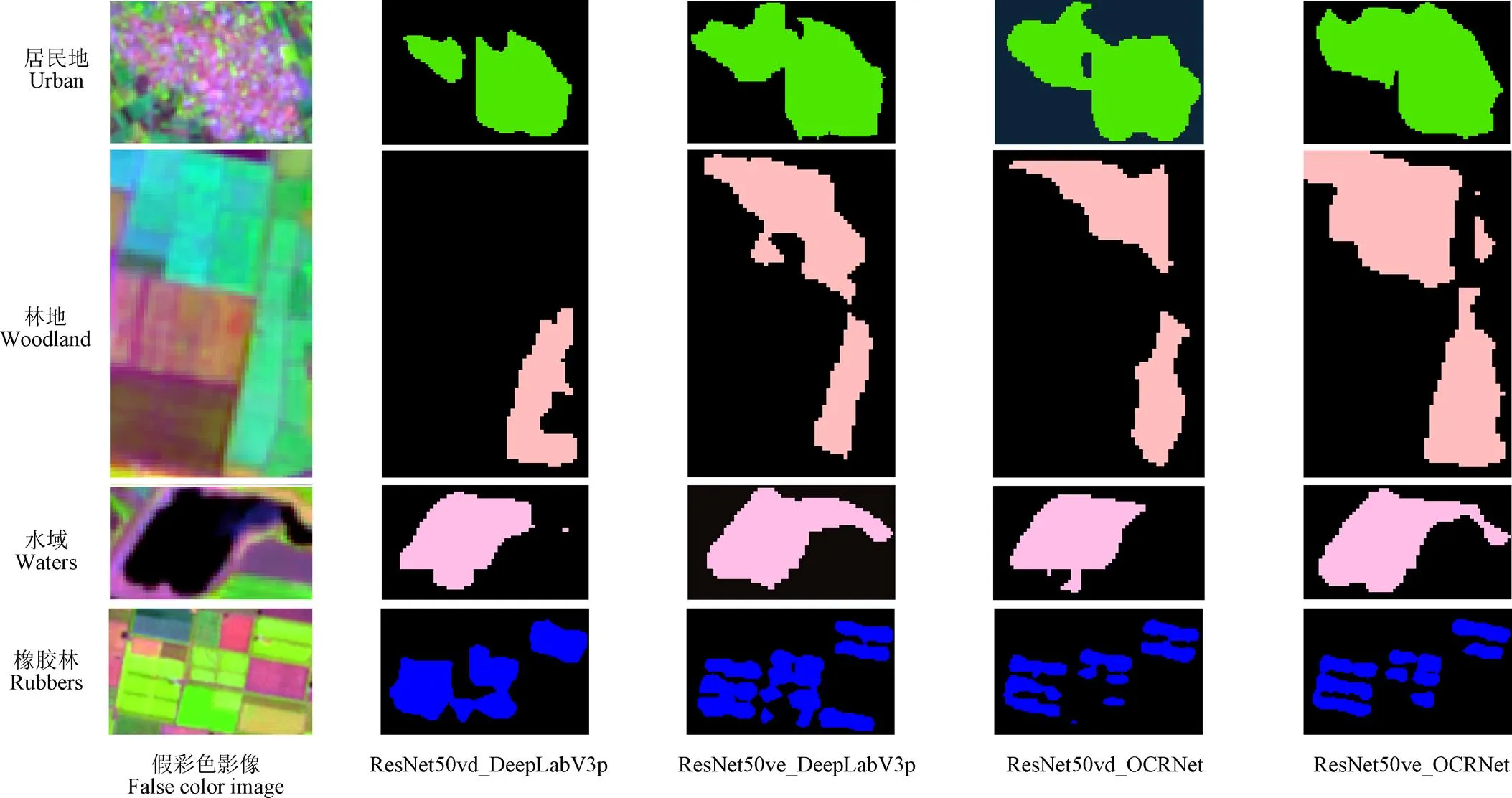
图7 基于ResNet50_vd和ResNet50_ve的DeepLabV3p和OCRNet模型的分割图比较
3 结 论
为了进一步提升经典分割模型提取上下文信息能力,本文提出了一种基于改进残差的优化思路,在比较确定适用本文研究的残差网络层数后,对比使用ResNet50_vd和ResNet50_ve的4种模型在验证集上的指标数据,通过上述试验得到以下结论:
1)通过比较基于ResNet50_vd和ResNet101_vd的4种模型指标差异,在小尺度卫星影像数据集上宜使用层数中等的50层骨干网络。使用ResNet50_vd为骨干网络的OCRNet模型中在验证集上的平均交并比、卡帕系数、像素准确率、推理速度和参数量上优于基于ResNet101_vd和ResNet50_vd的其他模型。
2)通过比较基于ResNet50_vd和ResNet50_ve的4种模型指标差异,本文提出的改进残差策略具有一定普适性可适用于多种主流网络,使用ResNet50_ve为骨干网络的模型在指标性能上都有不同程度提升,其中使用ResNet50_ve为骨干网络的OCRNet平均交并比达到0.85,像素准确率达到97.87%,卡帕系数达到0.90,为本文试验最优。
3)通过比较基于ResNet50_vd和ResNet50_ve的DeepLabV3p模型和OCRNet预测图,使用改进残差的语义分割方法可以抑制模型在预测图边缘易出现的上下文信息丢失问题。
[1] 李梦怡,朱定局. 基于全卷积网络的图像语义分割方法综述[J]. 计算机系统应用,2021,30(9):41-52.
Li Mengyi, Zhu Dingju. Overview of image semantic segmentation methods based on fully convolutional networks[J]. Computer System Applications, 2021, 30(9): 41-52. (in Chinese with English abstract)
[2] 程擎,范满,李彦冬,等. 无人机航拍图像语义分割研究综述[J]. 计算机工程与应用,2021,57(19):57-69.
Cheng Qing, Fan Man, Li Yandong, et al. A review of semantic segmentation of UAV aerial images[J]. Computer Engineering and Applications, 2021, 57(19): 57-69. (in Chinese with English abstract)
[3] 王春雷,卢彩云,李洪文,等. 基于支持向量机的玉米根茬行图像分割[J]. 农业工程学报,2021,37(16):117-126.
Wang Chunlei, Lu Caiyun, Li Hongwen, et al. Image segmentation of corn stubble row based on support vector machine[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(16): 117-126. (in Chinese with English abstract)
[4] 陈利燕,林鸿,吴健华. 融合随机森林和超像素分割的建筑物自动提取[J]. 测绘通报,2021(2):49-53.
Chen Liyan, Lin Hong, Wu Jianhua. Automatic extraction of buildings by combining random forest and superpixel segmentation[J]. Bulletin of Surveying and Mapping, 2021(2): 49-53. (in Chinese with English abstract)
[5] 杜伟杰,于晋伟,杨卫华. 基于超像素和最近邻图合并的彩色图像分割[J]. 中北大学学报(自然科学版),2021,42(3):265-274.
Du Weijie, Yu Jinwei, Yang Weihua. Color image segmentation based on superpixel and nearest neighbor graph merging[J]. Journal of North University of China (Natural Science Edition), 2021, 42(3): 265-274. (in Chinese with English abstract)
[6] 徐淑萍. 基于支持向量机的图像分割研究综述[D].鞍山:辽宁科技大学,2008.
Xv Shuping. Survey of Study on Image Segmentation Based on SVM[D]. Anshan:University of Science and Technology Liaoning, 2008. (in Chinese with English abstract)
[7] 段嘉鑫. 基于上下文信息的图像分割结果质量评价方法研究[D]. 成都:电子科技大学,2021.
Duan Jiaxin. Research on The Quality Evaluation Method of Image Segmentation Results Based on Context Information[D]. Chengdu:University of Electronic Science and Technology of China, 2021. (in Chinese with English abstract)
[8] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. arXiv preprint arXiv:1706.05587, 2017. https://arxiv.org/abs/1706.05587 (2017-06-17)[2022-05-23]
[9] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 801-818.
[10] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2881-2890.
[11] Yuan Y, Chen X, Wang J. Object-contextual representations for semantic segmentation[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow. 2020: 173-190.
[12] 徐长友,樊绍胜,朱航. 采用通道域注意力机制Deeplabv3+算法的遥感影像语义分割[J]. 控制工程,2022,3(8):1-8.
Xu Changyou, Fan Shaosheng, Zhu Hang. Remote sensing image semantic segmentation using channel domain attention mechanism Deeplabv3+ algorithm[J]. Control Engineering of China,2022,3(8):1-8. (in Chinese with English abstract)
[13] 王俊强,李建胜,周华春,等. 基于Deeplabv3+与CRF的遥感影像典型要素提取方法[J]. 计算机工程,2019,45(10):260-265,271.
Wang Junqiang, Li Jiansheng, Zhou Huachun, et al. Extraction method of typical elements of remote sensing image based on Deeplabv3+ and CRF[J]. Computer Engineering, 2019, 45(10): 260-265, 271. (in Chinese with English abstract)
[14] 赖丽琦. 基于DeeplabV3+的无人机遥感影像识别[J]. 林业调查规划,2021,46(3):11-16,62.
Lai Liqi. Recognition of UAV remote sensing image based on DeeplabV3+[J]. Forestry Survey and Planning, 2021, 46(3): 11-16, 62. (in Chinese with English abstract)
[15] 王华俊,葛小三. 一种轻量级的DeepLabv3+遥感影像建筑物提取方法[J/OL]. (2022-03-08) [2022-05-23]自然资源遥感:1-8.
Wang Huajun, Ge Xiaosan. A lightweight DeepLabv3+ remote sensing image building extraction method[J/OL]. Remote Sensing of Natural Resources: 1-8. https://www.cgsjournals.com/article/doi/10.6046/zrzyyg.2021219 (in Chinese with English abstract)
[16] 宋青松,张超,陈禹,等. 组合全卷积神经网络和条件随机场的道路分割[J]. 清华大学学报(自然科学版),2018,58(8):725-731.
Song Qingsong, Zhang Chao, Chen Yu, et al. Road segmentation by combining fully convolutional neural networks and conditional random fields[J]. Journal of Tsinghua University (Natural Science Edition), 2018, 58(8): 725-731. (in Chinese with English abstract)
[17] 任欢,王旭光. 注意力机制综述[J]. 计算机应用,2021,41(S1):1-6.
Ren Huan, Wang Xuguang. A review of attention mechanism[J]. Computer Applications, 2021, 41(S1): 1-6. (in Chinese with English abstract)
[18] 郭玥秀,杨伟,刘琦,等. 残差网络研究综述[J]. 计算机应用研究,2020,37(5):1292-1297.
Guo Yuexiu, Yang Wei, Liu Qi, et al. Review of residual network research[J]. Computer Application Research, 2020, 37(5): 1292-1297. (in Chinese with English abstract)
[19] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[20] He T, Zhang Z, Zhang H, et al. Bag of tricks for image classification with convolutional neural networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 558-567
[21] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[EB/OL]. (2015-03-09) [2022-05-23] arXiv preprint arXiv:1503.02531, 2015, 2(7). https://arxiv.org/abs/ 1503.02531
[22] Bagherinezhad H, Horton M, Rastegari M, et al. Label refinery: Improving imagenet classification through label progression[EB/OL]. (20118-03-07) [2022-05-23] arXiv preprint arXiv:1805.02641, 2018. https://arxiv.org/abs/1805.02641
[23] Yalniz I Z, Jégou H, Chen K, et al. Billion-scale semi-supervised learning for image classification[EB/OL]. (2019-03-02) [2022-05-23] arXiv preprint arXiv:1905.00546, 2019. https://arxiv.org/abs/1905.00546
[24] 邵仁荣,刘宇昂,张伟,等. 深度学习中知识蒸馏研究综述[J]. 计算机学报,2022,45(8):1638-1673.
Shao Renrong, Liu Yuang, Zhang Wei, et al. A survey of knowledge distillation in deep learning[J]. Chinese Journal of Computers, 2022, 45(8): 1638-1673. (in Chinese with English abstract)
[25] 孟宪法,刘方,李广,等. 卷积神经网络压缩中的知识蒸馏技术综述[J]. 计算机科学与探索,2021,15(10):1812-1829.
Meng Xianfa, Liu Fang, Li Guang, et al. Review of knowledge distillation in convolutional neural network compression[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1812-1829. (in Chinese with English abstract)
Semantic segmentation method for rubber satellite images based on improved residual networks
Yu Guo1, Liu Qiubin1, Chen Fangyuan1, Liu Dazhao1,2※
(1.,524003,;2.,524003,)
Rubber has been one of the most important cash crops in recent years. It is of great practical significance to segment the satellite images of rubber plantations using deep learning for agricultural refinement. In this study, a novel strategy was proposed to improve the residual network and its variant (ResNet-ve) for the segmentation. The study area was taken as the Rubber Plantation in Xuwen County, Zhanjiang City, Guangdong Province of China. The dataset was constructed using the Sentinel-2 multispectral satellite images as the data source. The OCRNet was used to incorporate an improved residual network. Inspired by Deeper Bottleneck Architectures proposed by Kaiming He, the modification strategy was established to modify path B in the Down Sampling module of each stage in the ResNet_vd middle layer. Specifically, the mean pooling module with 2×2 steps of 1 was replaced with a most-valued pooling module with 2×2 steps of 1, and then to add a 1×1 convolution before (called Deeper Bottleneck Pooling Architectures-like). The same modification strategy was applied to the other residual modules of the same stage, after which these modules were sequentially cascaded to form the improved stage. After that, the activation function was modified into the PReLU function to compare the network performance of the backbone network using the improved ResNet_ve. The improved residual network ResNet50_ve and basic ResNet50_vd network were used as the backbone networks of the four models. Among them, the student model was obtained to distillate the ResNet50_vd on ImageNet1k classification dataset using migration learning. A pre-trained model was then injected into the network training weight parameter for the modified ResNet_ve backbone network and ResNet_vd baseline backbone network to start the four networks. The results show that the ResNet50_vd network with the medium number of layers converged better than the ResNe101_vd network with the deeper layers on the training set of small-scale satellite images, and the OCRNet network on ResNet50_vd outperformed the DeeplabV3, DeeplabV3+, and PSPNet networks in all aspects. The OCRNet network with ResNet50_vd was used as a baseline for the subsequent experiments. The OCRNet with ResNet50_ve as the backbone network was achieved in the mIoU of 0.85, pixel accuracy of 97.87%, and a Kappa coefficient of 0.90 on the validation set. Therefore, an OCRNet with ResNet50_ve as the backbone network presented the best fineness of the internal boundary of the prediction graph among the four networks. There were also the least amount of time resources and the least number of parameters among the four networks. The OCRNet with the ResNet_ve as the backbone network was increased by 0.01 in the mIoU, and 0.01 in the Kappa coefficient, compared with the OCRNet with the ResNet_vd as the backbone network. By contrast, the accuracy metrics of the other three networks cannot be improved much using the ResNet_ve as the backbone network. The other three networks only improved the index data, in terms of the Kappa coefficient and mIoU index. Among them, the most obvious improvement was achieved in the DeepLabV3p. The OCRNet model with the improved residual network used the contextual and the deepest pixel features for the weighted splicing without the contextual information loss, while explicitly enhancing the pixel contributions from the same class of objects. As such, the background noise cannot be introduced, when extracting the multi-scale information. Thus, better performance was achieved in the accurate extraction of rubber distribution.
remote sensing; deep learning; rubber forest; semantic segmentation; residual network
10.11975/j.issn.1002-6819.2022.15.022
TP751
A
1002-6819(2022)-15-0204-08
余果,刘秋斌,陈方园,等. 基于改进残差网络的橡胶林卫星影像语义分割方法[J]. 农业工程学报,2022,38(15):204-211.doi:10.11975/j.issn.1002-6819.2022.15.022 http://www.tcsae.org
Yu Guo, Liu Qiubin, Chen Fangyuan, et al. Semantic segmentation method for rubber satellite images based on improved residual networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(15): 204-211. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.15.022 http://www.tcsae.org
2022-05-23
2022-07-29
广东省自然科学基金(2019A1515110840)
余果,研究方向为语义分割在农业遥感领域的应用。Email:yg9655@icloud.com
刘大召,教授,研究方向为农业遥感及应用。Email:llddz@163.com
猜你喜欢
热带作物学报(2022年6期)2022-07-08
现代青年·精英版(2021年11期)2021-12-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
当代水产(2019年11期)2019-12-23
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
知识经济·中国直销(2017年5期)2017-06-15
浙江农业学报(2016年7期)2016-06-15
中国学校体育(2014年11期)2014-05-10
新课程学习·中(2013年3期)2013-06-14
