
面向在线问诊平台的三支推荐方法
2022-11-13 12:17梁建树叶晓庆
西北大学学报(自然科学版) 2022年5期
梁建树,叶晓庆,刘 盾
(1.西南交通大学 经济管理学院,四川 成都 610031;2.西南交通大学 计算机与人工智能学院,四川 成都 611756)
随着“互联网+”的推广和快速发展,就医模式逐渐开始从线下往线上模式倾斜[1-2]。同时,自2020年新冠疫情爆发以来,线下就医的渠道受到极大的阻碍,“足不出户”的线上问诊模式得到更多人青睐。好大夫、丁香医生、春雨医生、阿里健康、京东健康等在线医疗平台能够为用户提供线上疾病咨询服务。作为线下医疗的补充,在线医疗一方面能合理利用全国各城市闲置的医疗资源; 另一方面, 能够缓解线下医院的诊疗负担, 提高医生的诊疗效率[3]。 在线医疗主要有在线问诊、 医药零售、 在线挂号等功能, 其中在线问诊是解决民众就医需求的重要渠道。Ranard等研究发现在线问诊平台可以弥补传统线下就医模式带来的反馈信息匮乏问题, 平台提供的信息对用户了解和评估医院的质量提供了帮助[4]。不仅如此, 在线问诊平台还可以指导用户就医, 让用户和医生、 用户和用户之间得以互动, 进而提高用户体验[5-7]。
然而,随着在线问诊平台上用户规模和医疗资源不断增长,用户想要从海量的医疗数据中寻找合适的医生变得越发困难。一方面,在线问诊平台为用户提供大量的医生信息,用户逐一通过科室、疾病等多层级的属性筛选合适的医生极其耗时;另一方面,用户不一定具有专业的医学知识,清楚自身的疾病状况以及分辨自身疾病所属的科室。基于此,作为一种解决数据过载问题的有效方法,个性化推荐技术能够为用户推荐符合其实际需求的医生,不仅能够提高在线问诊平台中用户的就诊效率,而且可以改善用户的在线体验[8]。一般而言,现有平台主要为用户推荐当前热度高、较多人访问的医生。然而,基于热度的推荐方法会造成马太效应,使得热门医生的工作超负荷,而新医生却难以被关注和发现。
为了满足用户需求,相关研究已开始将个性化推荐技术应用到医生推荐问题中,进而为用户推荐满足其需求的医生。徐守坤和吴伟伟根据用户咨询文本,通过协同过滤的方法为用户推荐满足其个性化需求的医生[9]。刘通将Word2Vec和Kmeans方法融合来解决用户咨询内容与医生聚类中心的相似度比较问题,并为用户推荐高匹配度的专业医生[10]。叶佳鑫等主要考虑了用户与医生的文本向量的相似度来推荐符合用户实际需求的医生[11]。潘有能和倪秀丽通过Labeled-LDA模型训练咨询文本数据,为用户推荐关键词相似度较高的医生[12]。Huang等提出了一种基于协作的医药知识推荐方法,根据医生在历史就诊文本中的医药评分来生成信任因子,并引入协同过滤的推荐算法进行医生推荐[13]。Zhang等基于在线评论,利用矩阵分解技术,预测医生排名得分为用户提供个性化的医生推荐[14]。杨晓夫和秦函书则根据医生所在科室进行精准推荐[15]。
通过对文献的分析和整理, 个性化推荐方法能够有效地解决医患信息过载问题。 然而, 现有研究方法主要从单一数据的视角对用户进行医生推荐, 忽略了医患信息的多源性和多粒度性。 事实上, 用户在实际的决策过程中往往会结合不同数据, 从多粒度、 多维度的视角来筛选适合的医生。 由于在线问诊平台中医生信息来源众多(包括用户反馈、 医生简介、 医院信息等), 这些数据从不同视角、 不同维度、 不同粒层描述医生特征。 医生特征的多粒度划分可以有效帮助在线问诊平台构建医生和用户之间的分级匹配, 是平台实现分级诊断的前提。 其中, 用户咨询文本从较细的粒度描述了医生擅长治疗的病患特征, 用户评价从较粗的粒度描述了医生擅长的疾病领域特征, 而医生简介从更粗的粒度描述了医生所在科室等方面特征。 因此, 平台可以通过筛选相似疾病特征的咨询文本, 为用户推荐合适的医生; 还可以通过比较用户对医生问诊服务的评价和主页简介中医生的专业领域, 为用户推荐其他合适的医生。
基于上述分析,本文从医患数据的多源性和多粒度两个视角出发,着重考虑推荐过程的不确定性,提出一种面向在线问诊平台的多步骤三支推荐方法。首先,针对现有研究中医生推荐数据单一性问题,本文考虑医患信息的多源性,通过Word2Vec和LDA等技术对多源数据进行学习,挖掘医生特征,构建多粒度的医患推荐信息。其次,考虑到推荐过程中的不确定性问题,引入三支决策思想,构建三支医生推荐方法。最后,将多粒度的医患推荐信息和三支决策思想融合,实现面向多源数据的多步骤三支医生推荐。
1 相关工作
1.1 在线医生推荐
已有关于在线医生推荐的研究主要关注两个方面:医患特征挖掘以及医生推荐。在医患特征挖掘上,现有研究主要通过文本挖掘技术探究医生用户的潜在特征信息。Bekhui等利用NLP相关技术,从在线医疗平台论坛中提取医生领域的关键词[16]。Chen通过对医患双方进行聚类来获取医生和用户特征[17]。Liu等通过注意力机制模型,构建一种新的深度网络,用以学习中文医疗平台中咨询文本的语义特征[18]。在医生推荐研究上,Abacha和Zweigenbaum基于医疗命名体识别方法,对医学问题和文档进行深入分析,给出了一种基于相似用户特征的医生推荐方法[19]。Naderi等通过使用统一的医学语言系统和自然语言处理技术,提出一种基于医生领域匹配的医生推荐方法[20]。Yang等探讨了一个基于用户医疗信息需求、问答记录内容和医生背景信息的深度学习问答推荐框架,来提高医生推荐的精确度[21]。
基于上述分析,当前研究存在一定的局限性。一方面,现有文献大多通过单一的数据源进行特征提取,忽略了医患数据的多源性和多粒度性;另一方面,现有方法主要关注推荐结果的精度和质量,忽略了推荐的多样性和覆盖率。从用户的角度来看,推荐系统应推荐用户需要的医生;从平台的角度来看,推荐系统也需要实现平台资源的合理分配。因此,本文将基于医患数据的多源性和多粒度性,以提高推荐质量和推荐覆盖率为研究目标,构建在线医生推荐模型。
1.2 文本特征挖掘
文本特征挖掘是从自然语言提取特征的过程,是各种语言处理任务的基础。根据不同的研究方法,可以分为传统的词袋模型、主题模型和深度学习模型3类。相对于传统的词袋模型,基于主题模型更关注语言处理过程,它通过从文档中发现的潜在主题并为其提供低维的特征表示,在文本特征提取中取得成功的应用。LDA是一种经典的层次概率主题模型[22],其核心思想是把主题中的词作为文本的部分特征,每个主题都由这些词组成。由于LDA模型能够有效提高文本语义分析的准确性,因而被广泛运用在提取医疗平台中文本特征的工程中[23-24]。基于深度学习的文本表示模型主要聚焦于人工神经网络的文本表示,其代表性方法为Word2Vec技术。Word2Vec生成词向量的基本思想来自NNLM (神经网络语言模型,neural network language model),它通过使用稠密、低维的实数向量来表示1个单词,每个维度代表了词语所包含的某个方面的潜在特征,能够表征有价值的句法和语义特征。此外,Word2Vec[25]使用具有单个隐藏层的神经网络来训练加权参数,并将采样窗口中单词的贡献率设置为目标函数。由于在线问诊平台中,医患数据都以文本数据为主, 因此,Word2Vec被广泛地应用于医患特征的挖掘中[10-11]。
1.3 三支决策
三支决策[26]理论是在决策粗糙集理论的基础上发展而来的,主要被用于处理延迟决策的不确定性问题。由于传统的二支决策可能会导致较高的误分类成本。因此,三支决策在此基础上提出了延迟决策策略[27],以规避在信息不足的情形下做出错误决策带来的严重后果。在现实的决策过程中,信息的多粒度性会增加决策处理过程。基于此,本文引入序贯三支决策方法,从粒计算的视角处理和实现多粒度信息下的多步骤决策过程。具体而言,在每一步骤中,当现有信息充分时,可以直接做出接受或拒绝的决策;而当前信息无法支持其做出决策时,可以将对象划分到边界域中,在下一个步骤中获得其他信息后再对其进行决策。
一般而言,在传统推荐问题上,推荐模型都是基于二支决策模型,即推荐和不推荐。为了处理推荐中的不确定性问题,三支决策的思想被引入推荐系统中,以解决传统推荐过程“非好即坏”的不足。Zhang等将三支决策引入到协同过滤的推荐系统中,提出三支推荐规则制定方法,并将其应用在智慧城市的推荐当中[28]。进一步地,考虑到多粒度信息下的多步骤推荐, Ye和Liu将序贯三支决策引入到推荐系统中,构建了一种新的动态三支推荐系统,以解决静态的二支推荐的局限性[29]。可以看到,针对在线问诊平台中的医生推荐,多步骤的三支决策推荐能够解决多粒度信息下的推荐过程,并有效解决医生推荐过程中面临的实际问题。
2 面向在线问诊平台的三支推荐方法
下面,开始着手对多粒度的医患推荐数据的清洗、整理和分析。考虑到在线问诊平台的数据整合过程需要爬取用户咨询文本和用户评论、挖掘用户需求、搜集医生简介信息,以及获取医生多粒度特征。因而,本小节从医患数据的多源性和多粒度性出发,提出一种面向在线问诊平台的多步骤三支医生推荐方法,其总体研究框架如图1所示。

图1 面向在线问诊平台的三支推荐方法的构架图
2.1 基于多源数据的在线医患特征挖掘

(1)
2.1.2 基于用户评论的医生特征挖掘 由于在线问诊平台允许用户对已完成的医疗服务进行评价并形成历史记录,用户通常会在众多历史评论中寻找自己关心的话题,进而选择好评率高、专业能力强、服务态度好的医生。因此,首先需要对用户评论进行语言处理和主题提取。本文主要采用LDA方法来分析用户评论的主题数,并挖掘评论中的主题信息。为了更详细地说明LDA,图2给出了LDA的图模型。假设有K个主题ζ=ζ1:k,每个主题都满足Dirichlet分布,则每个用户评论的文档wn*的生成过程可表示为:
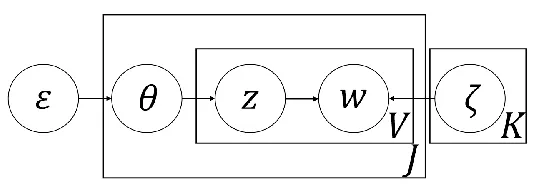
图2 LDA的图模型
1) 每个主题的分布θn满足
θn~Dirichlet()。
2) 对于文档wn*中的每个单词wnv,
a)主题分配zjv满足znv~Multinomial(θn);
b)词满足wnv~Multinomial(ζznv)。
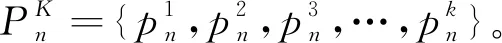
(2)
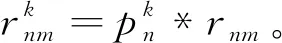
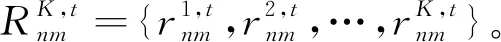
(3)
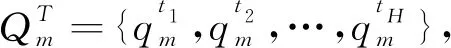
2.2 基于三支决策的多步骤推荐方法
传统的医生推荐是二支决策模型,采用推荐和不推荐两种策略。然而,在二支推荐过程中,错误的推荐可能会产生高昂的决策成本。基于此,本文引入三支决策的思想,对不确定的事件采取延迟推荐策略。给定两个阈值α和β,三支推荐系统基本结构如表1所示。

表1 三支推荐系统
相比于二支推荐模型,三支推荐模型对不确定的事件采用延迟推荐手段。具体而言,当已有推荐信息不充分,难以做出接受或拒绝判断时,采用延迟推荐策略,等待收集更多有用的数据信息再进行推荐。这种通过加入更多的推荐信息进行延迟推荐的方法,使边界域中的医生逐渐被进一步划分和推荐,进而实现了多步骤推荐。
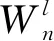

(4)
(5)
通过上述分析可以看到,面向多源数据的多步骤三支推荐方法适用于医患信息来源众多的在线问诊平台,从多粒度视角来看,随着推荐信息的增加,医生会被进一步划分。推荐系统从多源的数据信息为用户进行医生推荐,随着推荐信息的逐步加入,能够推荐给用户的医生数量也会变得更多。
2.3 面向在线问诊平台的三支推荐方法
针对在线问诊平台中医患信息的多源性和多粒度性及推荐过程中的不确定性,本文拟融合用户咨询文本、用户评论和医生简介,挖掘医生特征等数据,构建一种基于三支决策思想的多步骤医生推荐方法(3WD-msDRec),其核心技术路线如图3所示。
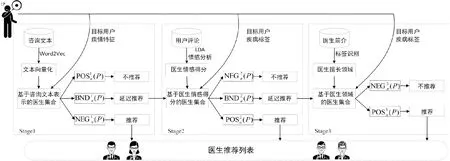
图3 基于三支决策思想的多步骤医生推荐方法(3WD-msDRec)
图3考虑了用户咨询文本、用户评论和医生简介3种不同信息源。由于每个阶段考虑的信息源不同,随着信息源的不断增加,为用户推荐的医生也更为丰富。基于此,多步骤的三支医生推荐可分为3个阶段,其对应的推荐信息集合分别记为G1,G2和G3。
在第1阶段中,通过对咨询文本的语义挖掘获取医生特征记为G1。目标用户un的咨询文本dn和以往就诊医生vm的用户文本dm通过Word2Vec向量化表示。这里,通过余弦相似度计算目标用户和咨询文本之间的语义相似度,将相似的以往用户推荐给目标用户,即
(6)
若两个文本之间相似度较高,则可以为目标用户推荐其就诊过的医生。进一步地,定义第1阶段的医生推荐得分为
Score(P1|(un,vm))=sim(dn,dm)
(7)
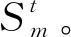
(8)
(9)

基于上述分析,面向在线问诊平台的多阶段三支推荐方法可以根据每个步骤中医生推荐得分,并在给定的阈值(αl,βl)下对候选医生集合进行如式(5)的推荐规则,最终形成对不同目标用户的医生推荐列表,具体的算法伪代码如算法1所示。第1阶段注重于从相似文本的角度进行考量,寻找与目标用户有相似病征的以往用户,并将他们咨询过的医生推荐给目标用户。当第1阶段推荐的医生数量小于N时,将继续通过第2阶段为用户推荐医生。而第2阶段侧重于从用户评价、用户满意度的角度进行考量,向目标用户推荐满意度较高的医生。第3阶段则是在前面两个阶段推荐的医生数不足的情况下,根据目标用户的疾病标签从医生简介中进行推荐。
算法1多步骤的三支医生推荐方法(3WD-msDRec)
Input:用户集U={u1,u2,…,un,…,uN},医生集V={v1,v2,…,vm,…,vM},推荐信息G1,G2,…,Gl,…,Gh,医生推荐得分Score(pl|(un,vm)),所需医生推荐数量N,各阶段阈值(αl,βl)且1≤l≤h-1;

1:∥步骤1.初始化参数
4:l=1
5:∥步骤2.多步骤三支推荐过程
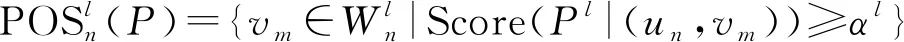

13:else
15:endif
17:l=l+1
18:endwhile
19:∥步骤3.二支推荐过程
23:endif
3 实验结果及分析
3.1 数据收集
为了验证本文所提推荐方法的有效性,本文从好大夫在线网站(haodf.com)上爬取了从2016年到2020年心理咨询科和内科2个科室的用户咨询文本、用户评论、医生简介等原始数据,其具体信息如下:
1) 心理咨询科室数据集:包括咨询文本共11万条,320位医生及其主页简介,医生评论2.1万条。经过数据整理和清洗,删除评论不足10条的医生,且文本单词数少于10个字的评论、简介和咨询文本,保留了89 000条咨询文本,250位医生以及10 699条评论。此外,通过统计分析得到心理咨询的疾病标签46个。
2) 内科数据集:与心理咨询科室不同,内科科室之中门类繁多,它由消化内科、心血管科、内分泌科、变态反应科等子科室组成。因此,在爬取内科科室数据时重点爬取了上述4个子科室中的咨询文本、用户评论、医生简介等数据。经过数据清洗后,保留了113 255条咨询文本,499位医生以及19 888条评论。此外,通过统计分析得到内科的疾病标签88个。
接下来,在实验设计中将80%的咨询文本作为训练集,用于训练Word2Vec模型和用于匹配文本的相似度,剩下20%的样本作为测试集进行实验分析。
3.2 实验评价指标
这里,采用推荐精度、推荐平均精度、归一化折损累计增益和推荐覆盖率4个评价指标来验证本文所提出推荐方法的有效性。
1)推荐精度

(10)
2) 推荐平均精度
平均精度反映了推荐系统中给用户推荐相关项目排名的能力,平均精度越高,最终推荐的列表中医生的排名也就越靠前。平均精度计算公式如式(11)~式(12)所示。
(11)
(12)
考虑到每个用户最终只与一个医生成功匹配,因此,x=X=1。position(x)表示推荐成功的医生在推荐列表中的位置,而没有推荐成功的用户AP(i)=0。
3) 归一化折损累计增益
折损累计增益(DCG)主要考虑了推荐系统中排序的结果,排名靠前的项目增益更高,对排名靠后的项目进行折损。归一化折损累计增益(nDCG)则是对不同用户的指标进行归一化,最后,对每个用户取平均得到的最终分值,其计算公式如式(13)所示。
(13)
其中:ρ为推荐列表中医生的排序位置;reli表示第i个医生为某用户的问诊医生。在医生推荐的情境下,1个医生就诊1个用户,即reli={0,1}。因此,理想的排序结果应为就诊医生排在推荐列表的第1位,即IDCG=1。
4) 推荐覆盖率
覆盖率反映了推荐系统覆盖项目的能力,覆盖率越高,表明最终推荐的列表中能够覆盖的医生越多,它由式(14)计算,其中V为医生集合。
(14)
3.3 基准方法
进一步地,为了验证本文提出的医生推荐系统(3WD-msDRec)的有效性,本文以下面3种方法作为基准算法。
1) DP-bRec (doctor popularity based recommendation):基于医生热度的推荐方法是现存医疗网站上主要使用的推荐方法,该方法是将热度排序高的医生推荐给用户。
2) W2V-TextRec:该方法是以用户咨询文本为数据源,经过Word2Vec训练,将与以往用户文本咨询过文本相似度最高的医生推荐给目标用户的推荐方法[11]。
3) Labeled-LDADRec:该方法是以用户咨询文本为数据源,通过LDA主题模型把训练得出的关键词作为医生专业领域的标签,并将标签相似度较高的医生推荐给目标用户的推荐方法[30]。
3.4 实验结果分析
3.4.1 算法比较分析 首先,为了验证本文所提算法在4个评价指标的有效性,利用Word2Vec和LDA模型对在线问诊平台中的数据进行处理。一方面,在训练Word2Vec的过程中,将词向量的维度设置为250,迭代次数设置为10次。另一方面,借鉴文献[31]对医生评论进行主题提取的结果,对用户评论进行LDA主题模型训练,设定K=4。 进一步地, 假设所需医生推荐数N=10,表2和表3展示了阈值α和β在不同组合变化下,推荐精度、覆盖率、MAP和nDCG的实验结果。
通过表2和表3可以看出,推荐精度、MAP和nDCG随着α和β的取值变小而表现更为有益。对于覆盖度来说,α的取值区间位于0.65~0.85表现较好。为了兼顾4个指标的表现,选取(α1,β1)=(0.65,0.3)。在第1阶段推荐中,当文本的相似度≥0.65,将其归到正域,并且向用户推荐该文本咨询的医生;当文本相似度介于0.3~0.65时,将该医生归到边界域,即延迟推荐;剩下的医生便进入负域,不向用户推荐。类似地,第2阶段选取(α2,β2)=(0.8,0.4)。

表2 α和β组合变化下推荐精度和覆盖度的实验结果(N=10)
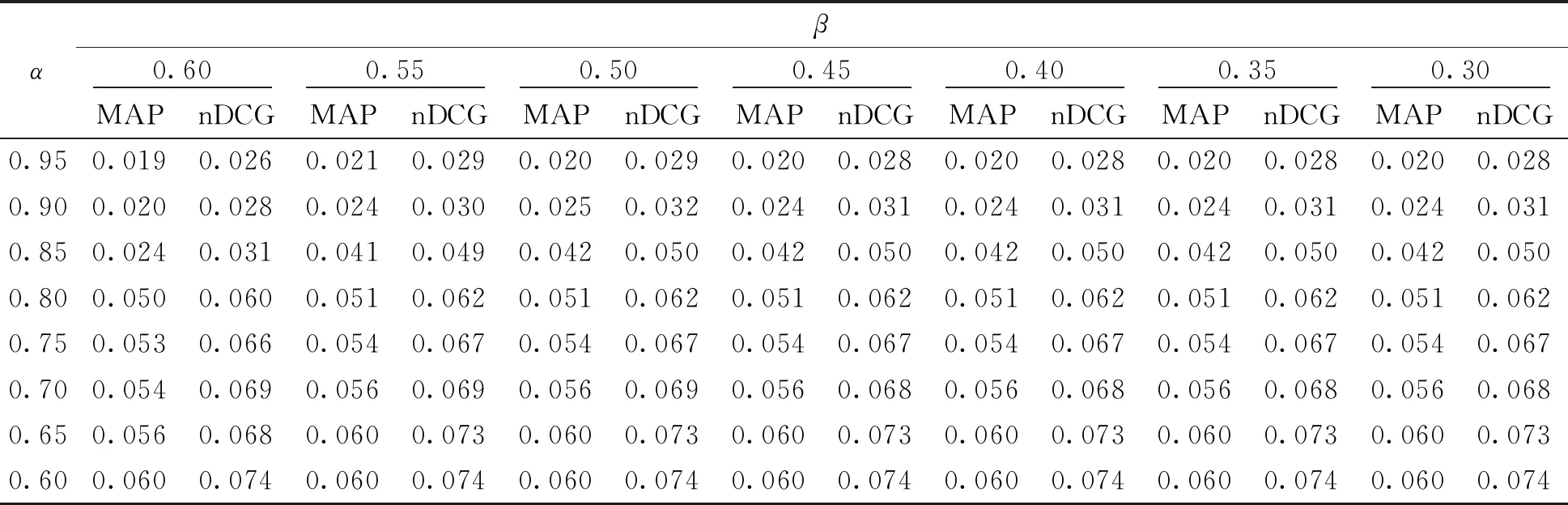
表3 α和β组合变化下MAP和nDCG的实验结果(N=10)
进一步地,在确定好阈值后,将本文提出的3WD-msDRec方法与3种基准方法进行实验分析,相关比较结果如图4和图5所示。
一方面,由图4A可知,在心理咨询数据集上,3WD-msDRec的推荐精度都优于其他基准方法。由图4B和图4C可以看出,3WD-msDRec方法在MAP和nDCG两个指标上的表现优于其他基准方法。通过图4D可以得到,当N≤25时,DP-bRec方法的覆盖率最低,3WD-msDRec方法的覆盖率最优。当N≥30时,Labeled-LDADRec方法的推荐覆盖率比3WD-msDRec方法表现更好,不过3WD-msDRec方法的覆盖率也达到了90%以上,与最优方法表现相差甚微。
另一方面,通过图5可以发现,3WD-msDRec方法在两个数据集上的表现是一致的。此外,综合图4和图5发现,3WD-msDRec方法在内科数据集的推荐精度、MAP和nDCG的结果表现比心理咨询数据集的表现要高出10%左右。总而言之,本文所提方法在推荐精度和覆盖度上总体都优于其他基准方法,而且从平均精度和nDCG两个指标来看,3WD-msDRec方法具有良好的推荐质量。
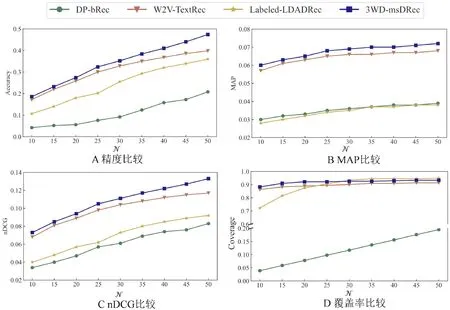
图4 与基准方法结果对比图(心理咨询科室)

图5 与基准方法结果对比图(内科科室)
3.4.2 不同数据源组合比较分析 其次,为了探索所提方法使用多种数据源进行多粒度医生推荐的优异性,进一步将本文所提方法与不同数据源组合推荐方法做对比分析,使用单一数据源进行的医生推荐为单粒度医生推荐,使用两个数据源则为两个医生粒度特征的医生推荐,相关实验结果如图6和图7所示。
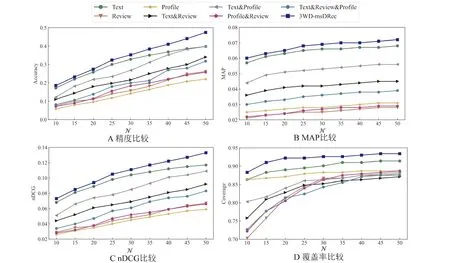
图6 不同数据源结果比较图(心理咨询科室)

图7 不同数据源结果比较图(内科科室)
通过图6和图7可以发现,3WD-msDRec方法在各指标的表现都优于其他数据源组合推荐的方法。相比其他数据源组合推荐进行的不同粒度医生推荐方法,采取了3个不同数据源进行多粒度的3WD-msDRec方法在推荐精度、MAP和nDCG上优势明显。此外,3WD-msDRec方法在覆盖率的表现也优于其他方法,这在一定程度上验证了本文所提出方法的有效性。综上所述,通过对推荐精度、MAP、nDCG和覆盖率4个指标的分析,相比其他基准方法及其他数据源组合推荐方法,本文提出的方法在提高推荐精度的同时,还提高了推荐的覆盖率。
3.4.3 结果可视化分析 最后,为了清晰刻画面向多源数据的多阶段可视化推荐过程,分析采用多源数据进行推荐的合理性和有用性,本文从心理咨询科室数据集中随机选取10名用户, 为他们推荐得分排名前50位的医生(N=50)。 对于不同用户, 为其推荐医生的信息来源是不同的。 图8统计并展示了10位用户在咨询文本、用户评论和医生简介3种不同信息源的医生推荐数量。

图8 10名用户可视化推荐过程
图8中,绿色柱状代表通过咨询文本进行医生推荐的数量,红色柱状代表通过用户评论进行医生推荐的数量,而蓝色柱状代表通过医生简介进行医生推荐的数量。由图8可以发现,用户6、用户7和用户9只需要利用咨询文本来推荐就能满足其需求,即经过第1阶段就终止推荐。用户5和用户8需要咨询文本和用户评论,第2阶段就可以结束推荐。其他用户则同时需要3个信息源的数据,进行3个阶段的推荐。图8的结果证实了本文所提出研究方法的合理性和有用性,同时说明在问诊平台推荐中多信息源的重要性。
4 结语
考虑到在线问诊平台中医患信息的多源性和多粒度性,以及推荐过程中的不确定性问题,本文提出了一种面向在线问诊平台的多步骤三支推荐方法,通过挖掘多源数据中的医患特征,利用多粒度的推荐信息,构建了一种多步骤三支医生推荐方法。本文通过爬取好大夫网站上的医患数据对所提方法进行有效性验证。实验结果表明,本文所提方法不仅能够提高医生推荐精度,同时还提高了推荐的覆盖率,具有良好的应用价值。而且,本文方法作为在线问诊平台中医生推荐的方法,它从多个维度、多个角度以及多个粒度为用户进行的推荐,有着良好的语义解释性。此外,本文方法还能在一定程度上缓解医生配置不均衡的问题,具有较好的理论价值和实际意义。在未来研究中,笔者会进一步探索将深度学习的技术引入到在线问诊平台中的相关模型与方法,通过数据处理和分析,将多源医生特征进行融合,挖掘医生的多粒度特征,实现医患的精准匹配。
猜你喜欢
天中学刊(2022年5期)2022-11-08
医院管理论坛(2022年8期)2022-10-14
佳木斯大学学报(自然科学版)(2022年3期)2022-06-27
婚育与健康(2021年5期)2021-07-06
电脑爱好者(2018年14期)2018-08-05
新作文·高中版(2017年6期)2017-07-06
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
科技与企业(2015年12期)2015-10-21
电脑爱好者(2015年20期)2015-09-10
