
雷达装备故障原因知识图谱构建研究*
2022-11-12 11:08谢雨希杨江平孙知建李逸源胡欣
现代防御技术 2022年5期
谢雨希,杨江平,孙知建,李逸源,胡欣 ,2
(1. 空军预警学院,湖北 武汉 430014;2. 中国人民解放军93498 部队,河北 石家庄, 050000)
0 引言
在雷达装备的寿命周期里,装备保障人员记录了大量的故障原因文本资料。但这些文本资料目前只用于统计整理成典型故障案例,并没有得到充分利用。且统计完全依靠人力,结果随人员专业知识和经验的不同而有较大差异。随着雷达装备的发展,装备结构和运行模式越来越复杂,积累的故障原因文本资料越来越多,处理难度越来越高,完全依靠人工处理效率过低。所以需要通过智能化技术将非结构化的故障原因文本组织为结构化的知识,以便快速有效地定位故障部位,获取故障相关信息。对故障的维修和装备性能的分析都有较大帮助。
知识图谱由谷歌于 2012 年 5 月 17 日提出[1],本质上是一种揭示实体与实体以及实体与属性之间关系的语义网络[2]。在诸多领域得到了有效的运用,电力领域将其用于设备健康管理、故障辅助决策等研究[3-5];航空领域将其用于飞机电源、发动机等各系统的故障诊断[6-7];铁道领域将其用于对隧道施工过程的安全管理[8];汽车领域用于构建汽车运维专家系统[9]。因此,通过构建雷达装备故障原因领域知识图谱,不仅能为雷达装备故障原因文本的深入分析,装备故障的定位打下基础,还能实现装备保障文本智能化处理的第一步。
实体抽取也叫实体命名识别,为知识图谱构建中的关键步骤,其效果会对后续步骤产生较大影响。随着预训练模型的发展,中文实体命名识别效果有了较大提升[10]。基于transformer 的双向编码器表示(bidirectional encoder representation from transformers,BERT)作为预训练表征模型的出现,推动了自然语言处理领域的较大发展[11]。BERT 模型出现了一些改进型。广义自回归预训练语言模型(generalized autoregressive pretraining for language understanding,XLNet)由语言建模(language modeling,LM)改进为置换语言建模(permuted language modeling,PLM),摒弃了预测下一句任务(next sentence prediction,NSP)以取得更好的效果,在阅读理解等领域有较好的性能[12]。一种稳健优化的BERT(a robustly optimized BERT,Roberta)将静态掩码改进为动态掩码,在大量数据进行长时间的预训练时,效果更好[13]。高效学习对令牌替换进行准确分类的编码器(efficiently learning an encoder that classifies token replacements accurately,ELECTRA)用一个生成器产生掩码的预测值分布,经过采样后作为输入传给判别器来判断每个位置上的符号是否被置换过,具有较高的学习效率[14]。但XLNet 和Roberta 模型使用了10 倍于BERT 模型的丰富语料来提升训练效果,使得训练时间更长。ELECTRA 由于训练中需要保存的中间结果较多,所以对硬件要求较高;多任务学习时,需要对超参数进行调整。为减少参数的量,提升训练速度,通过矩阵分解和参数共享对BERT 模型进行改进的一种轻量的BERT(a lite BERT,ALBERT)模型被提出[15]。所以本文选择以ALBERT 作为预训练模型,再结合注意力机制,双向门控循环单元(bidirectional gated recurrent unit,BiGRU)和 条 件 随 机 场(conditional random fields,CRF)构成了 Att-ALBERT-BiGRU-CRF 模型,通过该模型进行实体命名识别,用以构建雷达装备故障原因领域知识图谱。
1 雷达故障原因文本
通过对大量雷达故障原因文本的研究,发现文本主要有以下特点:
(1)文本包含了大量雷达领域的专有名词和专业术语。例如方位信号,常规分词方法会将该词分为“方位”和“信号”2 部分,与实际语义不符。
(2)文本中的实体存在词语嵌套的情况。如末级功放组件,实体的界限模糊。
(3)同一故障部位或故障现象存在不同描述,如“不跟踪点迹”和“不跟点”、“分显”和“分显示器”。
(4)对数字、字母和汉字相结合的实体,如80 MHz 时钟,±12 V 电源,A/D 脉压板等,需要结合上下文语境进行识别。
(5)文本信息存在错字的情况,如“感温包”写成“感应包”等,使得信息难以被准确识别。
由于文本的以上特点,运用常规分词方法难以进行有效分析。所以本文通过构建雷达故障原因领域知识图谱,为后续故障原因文本的有效分析利用打下了良好基础。
2 构建知识图谱
2.1 构建框架
本文采用模式层和数据层相结合的方法。首先,采用自顶向下的方式设计知识图谱的模式层也叫本体层,定义模式层中关系,形成概念层次结构。之后,在模式层的指导下,自底向上构建数据层。在分析了雷达故障原因文本特点后,通过知识抽取模型,抽取实体及其关系,然后将抽取出的知识进行融合,通过知识图谱的底层存储方式,完成与概念节点间的映射。形成雷达故障原因知识图谱。具体流程图如图1 所示。

图1 雷达故障原因知识图谱构建流程Fig.1 Construction process of radar fault cause knowledge graph
2.2 模式层构建
模式层是知识图谱的核心,用于限定概念及概念之间的关系。
本文在雷达装备保障领域专家的帮助下提炼出了领域相关概念类型及关系的定义,用以形成知识体系。雷达故障原因知识图谱的模式层由故障时机、故障部位和故障现象三要素以及它们之间的相互关系构成,如图2 所示。

图2 雷达故障原因知识图谱模式层Fig.2 Scheme layer of radar fault cause knowledge graph
2.3 数据层构建
数据层的构建主要包含3 个部分:第1 部分是知识抽取,主要是在模式层概念的引导下,从各类数据源中提取实体和关系;第2 部分是知识融合,是为消除歧义,对抽取的知识进行整合,主要包括实体消歧和共指消解;第3 部分是知识更新,为保证知识图谱的质量,在应用中对知识进行更新。
2.3.1 知识抽取
由于雷达故障原因本文实体类型较少,实体之间的关系也较少,且同一对实体之间只存在一种关系或无关系的情况。所以本文采用流水线式的先抽取实体再抽取关系的方法。在完成实体抽取之后,再将关系抽取问题转化为分类问题。
(1)实体抽取
雷达故障原因本文所包含的实体如表1 所示。

表1 命名实体类别及示例Table 1 Named entity categories and examples
目前的预处理模型,ELECTRA 具有最好的效果,但ELECTRA 对长文本更加友好。由于雷达故障原因文本为字符在50 以内的短文本,所以本文选择不仅参数量少,且同样性能较好的ALBERT 作为预训练模型。 结合注意力机制,构成了Att-ALBERT-BiGRU-CRF 模型,如图 3 所示。
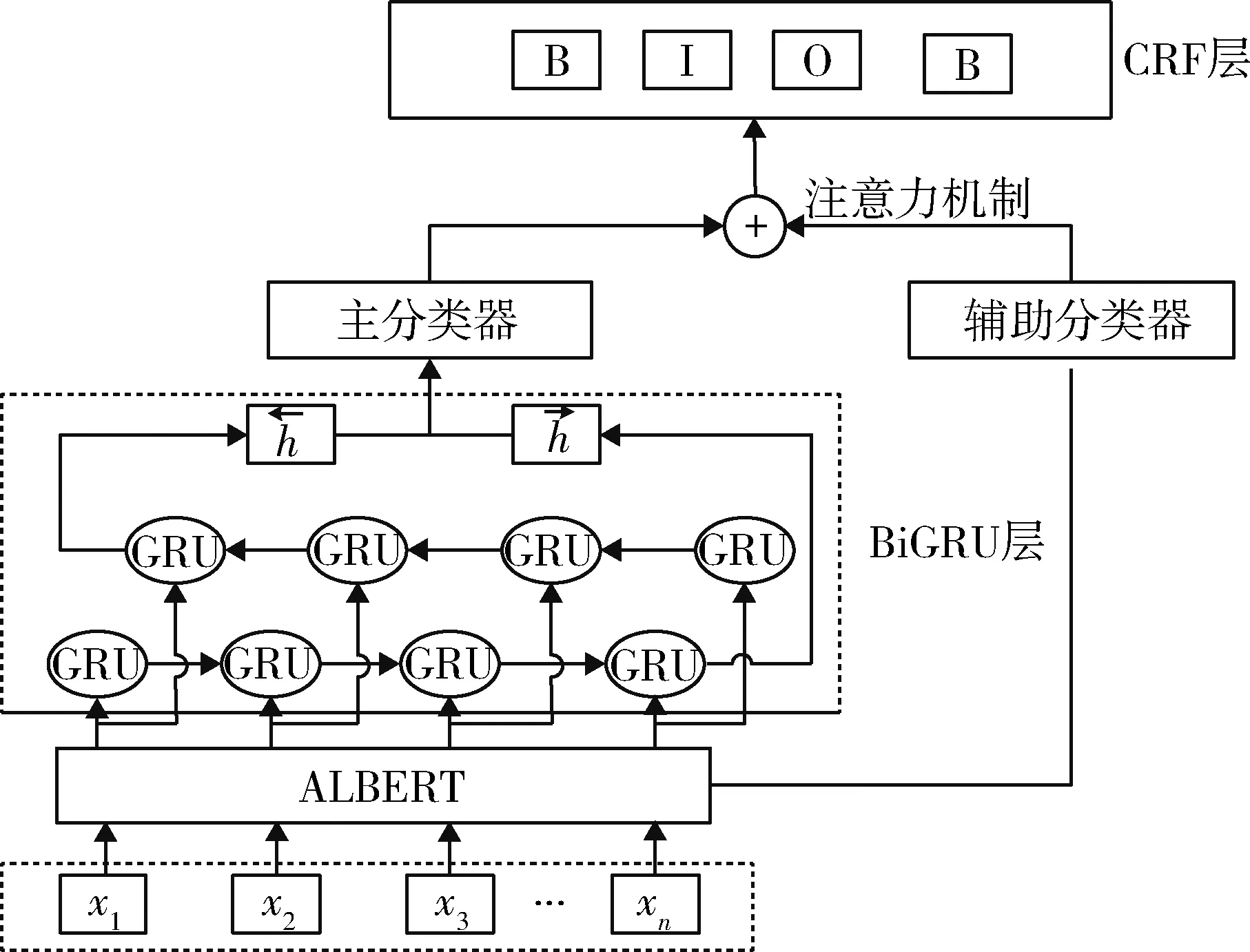
图3 Att-ALBERT-BiGRU-CRF 模型结构Fig.3 Structure of Att-ALBERT-BiLSTM-CRF model
模型主要包括ALBERT、BiGRU、基于注意力机制的辅助分类器和CRF 4 个模块。首先,将文本输入ALBERT 预训练模型,以获取文本的字向量,同时提取重要特征。然后,输入BiGRU 层进行训练,得到进一步的上下文特征。在BiGRU 层的输出结果中,通过注意力机制,引入ALBERT 层输出文本特征作为辅助。最后,通过CRF 层,得到最终的输出序列。
ALBERT 是瘦身版的BERT。改进主要体现在:通过对字向量的参数因式分解以及跨层参数共享来减少参数的量;用句子顺序预测(sentence order prediction,SOP)代替NSP,以避免主题预测而只关注句子的连贯性;删除dropout 层,使得模型更加简化。
BiGRU 模型用于字符的标签序列运算。GRU模型由 Kyunghyun Cho 等提出[16],由门控制信息传递,是长短期记忆网络(long short term memory,LSTM)的简化模型,具有相似效果[17]。由于每个隐藏单元都是独立的重置门和更新门,BiGRU 将学习到不同时间范围的依赖,并且参数较少,计算较为简单,所以本文选用BiGRU 模型输出结果作为Attention 层主分类器的输入。
由于ALBERT 可以获得丰富的语义信息,所以引入ALBERT 层输出结果作为辅助,与能获得上下文信息的BiGRU 相结合,更有利于序列标注。Attention 层的主要作用是衡量特征权重,对有帮助的信息增加权重,对干扰信息减小权重[18]。本文将2部分的输出结果通过Attention 层结合起来,是为了让对于序列标注更重要的特征获得更大的权重。本文选择由余弦距离改进而来的皮尔逊距离,作为Score 函数,来计算两部分输出的相关性[19]:
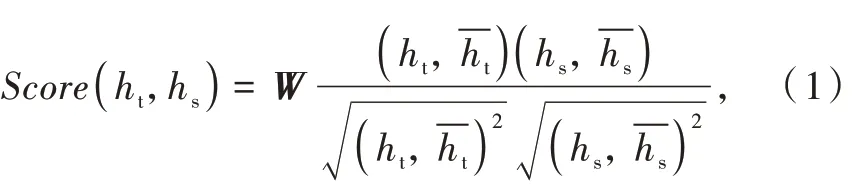
式中:ht为 ALBERT 层输出结果;hs为 BiGRU 层输出该函数计算出两部分的特征权重后,通过向量相乘得到新的特征作为CRF 层的输入。
虽然BiGRU 层考虑了上下文语义信息,但没有考虑标签之间的相互关系。所以本文采用CRF 来优化标注结果[19]。最终CRF 层输出序列的标签为输出概率最大的标签集合。
(2)关系抽取
关系抽取主要是从数据源中提取实体之间的关系。本文通过提取出的实体对对关系进行分类,主要分为表2 所示类型。如此,将关系抽取问题转化为分类问题。将所有实体两两组合,形成实体对,筛选出表2 中的所有实体对,然后对实体对进行关系分类,就可得到实体间的所有关系。
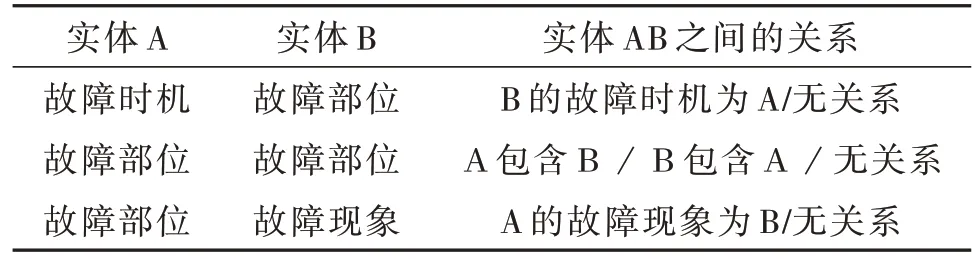
表2 实体间的关系类型Table 2 Relation types of entities
采用ALBERT-BiGRU-Att 作为分类模型,加入注意力机制是为了让模型给与分类相关的信息更多的关注度。模型结构如图4 所示。
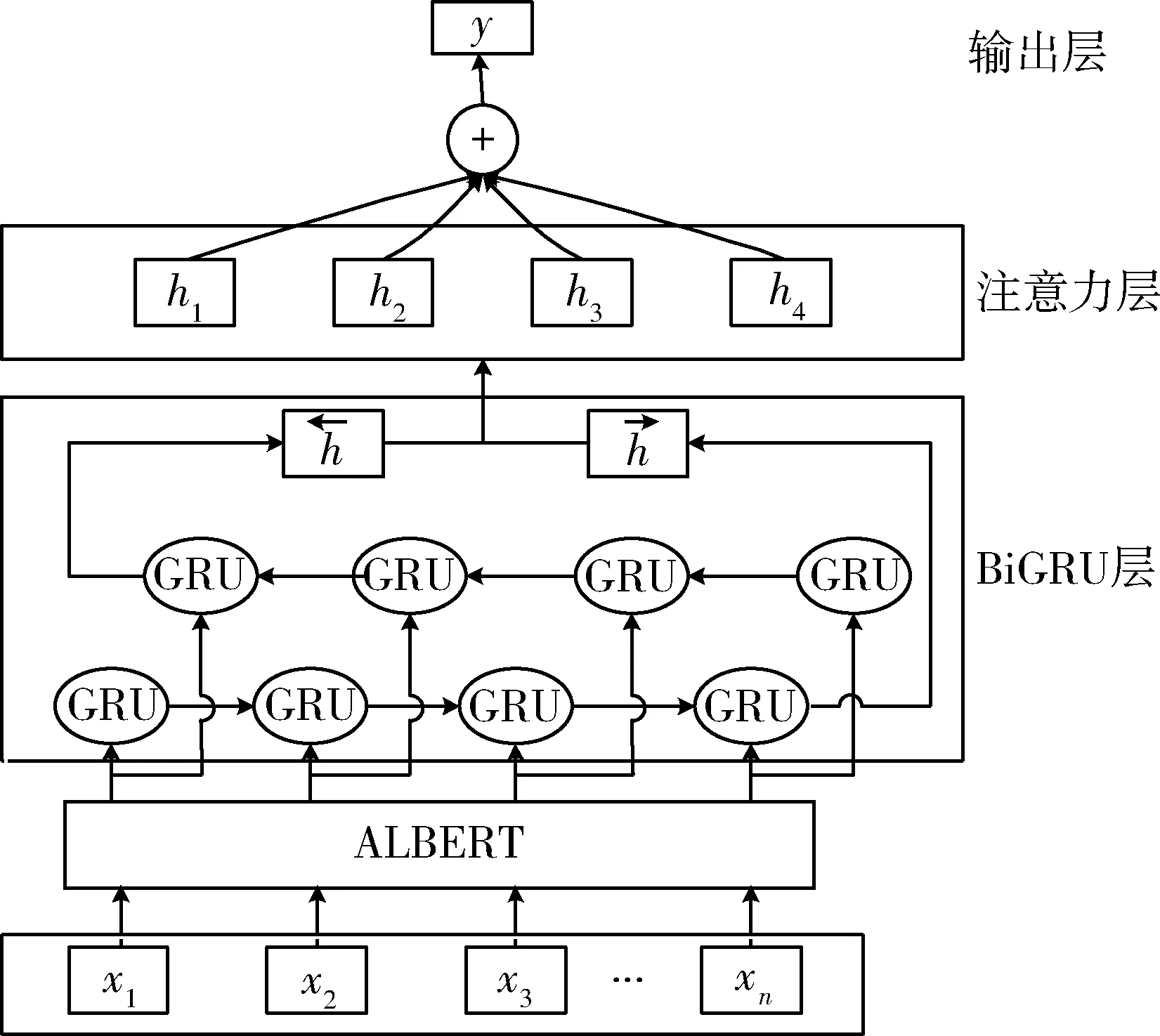
图4 ALBERT-BiGRU-Att 模型结构Fig.4 Structure of ALBERT-BiGRU-Att model
通过赋予对关系分类有重要作用的字更高的权重,来提高模型的准确率。
2.3.2 知识融合
知识融合中的实体消歧部分主要是对相同描述不同含义的实体进行区分。共指消解是将具有相同含义不同描述的多个实体进行合并。由于本文的数据源雷达故障原因文本属于雷达专业领域,从中抽取出的实体含义范围较窄,专业性较强,所以实体歧义的问题基本不存在。但由于撰写人员的专业素质各不相同,存在较多的共指问题。为了解决上述问题,使用开源的中文自然语言处理工具Synonyms 进行数据融合,Synonyms 被誉为最好用的中文同义词词库。
2.3.3 知识更新
随着时间的推移和雷达装备的发展,雷达型号和故障原因均在不断更新。所以,知识图谱中的知识也需要更新。更新包括模式层和数据层2 方面:对模式层的更新主要是在当从新的数据源中获得了新的概念时,需要将新的概念更新到模式层中;对数据层的更新主要是在没有新概念而只是获得了新的实体或者关系时,采用增量更新的方式[20],向现有知识图谱中添加新知识。除了新增外,对失效知识的删减也属于知识更新的一部分,这部分工作通过邀请专家定期对知识图谱中知识的有效性进行评估来完成。
3 实验与结果分析
3.1 实体命名识别
3.1.1 实验环境配置与参数设置
本文实验基于windows 操作系统,硬件配置为AMDRyzen5 3600CPU,16G 内存,显卡为 RXT 3070 8G,软件环境为PyTorch1.10.0+cu113。
通过实验确定模型参数中迭代次数的值。迭代次数对模型性能的影响如图5 所示。
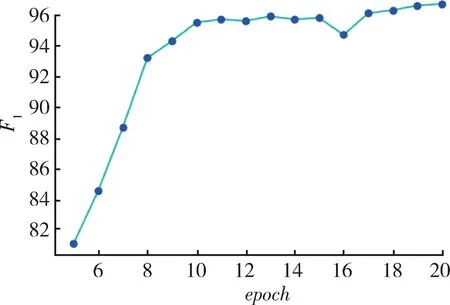
图5 迭代次数对模型识别效果的影响Fig.5 Effect of the number of epoch on the recognition effect of the model
随着迭代次数的增加,模型的准确率会随之增加,当迭代次数达到10 后,F1值趋于稳定,所以本文选择迭代次数为10。最大序列长度为64,批尺寸为16,学习率为 5×10-5,字向量维度为 100,注意力输出维度为100。
3.1.2 评价指标
选择准确率P、召回率R 和F1值作为评价指标,指标值越高,代表模型的准确率、召回率和综合性能越好。指标值的计算以实体数为计量单位。

3.1.3 数据准备
对来自不同单位的2 398 份故障原因文本进行实体识别,将待识别的实体分为故障时机、故障部位(故障分机、故障单元和故障元器件)和故障现象。对文本中的实体进行人工标注,将2 398 份文本按9∶1 的比例随机划分为训练集和测试集。
3.1.4 实验结果及分析
为验证本文Att-ALBERT-BiGRU-CRF 模型的有效性,设置对比实验。每种模型的识别结果软件截图如图6 所示。
图 6 中,GZSJ 表示故障时机,GZFJ 表示故障分机,GZDY 表示故障单元,GZYQJ 表示故障元器件,GZXX 表示故障现象。实验结果对比如表3 和图7所示。

表3 不同模型实体命名识别结果对比Table 3 Comparison of different entity recognition methods %

图6 不同模型的实体命名识别结果Fig.6 Result of different entity recognition methods
由表3 和图7 都可以看出后3 个模型的识别效果更佳,特别是对于故障元器件的识别效果,有明显提升。由于实际故障原因文本里对故障元器件的描述较少,导致训练样本较少,所以BiLSTM 和BiLSTM-CRF 模型对故障元器件实体的识别效果不太理想。而加入了ALBERT 预训练模型之后,效果大为改进。因为ALBERT 预训练模型相当于事先预训练好的通用模型,在领域运用时,只需加入少量的领域训练数据,精加工模型,就能适用于不同的专业领域。加入了注意力机制的Att-ALBERTBiGRU-CRF 模型效果更佳,因为本文中的实体存在一定复合词嵌套情况,注意力机制的加入更有利于对这类实体的识别。

图7 不同模型实体命名识别效果Fig.7 Result of different entity recognition methods
3.2 关系抽取
3.2.1 实验模型参数和评价指标
模型参数设置迭代次数为10。最大序列长度为 64,批尺寸为 32,学习率为 5×10-5,字向量维度为100,注意力输出维度为100。
使用准确率P、召回率R 和F1值作为评价指标,指标值越高代表模型性能越好。
3.2.2 实验结果与及分析
实体间关系抽取实验结果如表4 所示。

表4 实体间关系抽取实验结果Table 4 Results of entity relation extraction %
模型在所有关系类别上总的F1值为92.44%。模型对无关系类型的抽取效果较差,因为在实际的数据中,无关系类型较少,训练数据所占比例较小。
将识别出的实体和抽取出的关系构建了雷达故障原因知识图谱,部分如图8 所示。

图8 某雷达故障原因知识图谱(部分)Fig.8 Knowledge graph of a radar fault cause(part)
4 结束语
本文运用模式层和数据层相结合的方式构建了雷达故障原因知识图谱。针对雷达故障原因文本的特点,运用Att-ALBERT-BiGRU-CRF 模型,对文本中的实体进行了抽取。实验证明,该模型在标注集样本量较小的情况下,能较好地识别出故障原因文本中的命名实体,对由复合词组成的实体也有较好的识别效果。运用ALBERT-BiGRU-Att 模型对实体间的关系进行了抽取,通过识别出的实体和实体之间的关系建立了雷达故障原因领域知识图谱,为后续的智能化处理打下了基础。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
电子制作(2019年15期)2019-08-27
小学生学习指导(低年级)(2018年12期)2018-12-29
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
火控雷达技术(2016年3期)2016-02-06
