
基于改进YOLOv5s的列车车厢客流密度检测方法研究
2022-11-11 01:15董承梁汪晓臣
铁路计算机应用 2022年10期
张 馨,董承梁,汪晓臣,田 源
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2.北京京港地铁有限公司 运营工程部,北京 100068)
北京、上海等城市地铁日客流量均突破千万人次,大规模的客流冲击给城市轨道交通(简称:城轨)运营带来诸多安全风险。实时准确地检测车厢客流能为及时调整行车调度计划、引导站厅内客流等提供数据支撑。
传统的列车车厢客流密度检测多采用物理传感器检测方式,包括压力传感器、红外检测装置、热敏传感器等[1]。其中,压力传感器将经过的乘客重力转换为电信号来统计客流,由于乘客重量不一,这种检测方式准确性较差;红外和热敏检测装置分别通过红外热成像和热辐射转化原理检测客流密度,但在客流密度较大、乘客相互重叠的情况下,两种设备的检测精度均受到影响。近年来,随着各类图像数据库的建立和图形处理器(GPU,Graphics Processing Unit)的快速发展,深度学习技术得到了广泛的研究和应用,基于深度学习的方法也被应用于客流密度检测中[2]。例如,基于城轨列车车载闭路电视监控(CCTV,Closed-Circuit Television)系统实现对车厢的实时监控,再通过深度学习模型对列车车厢客流进行精准检测。
Sun等人[3]提出了一种基于YOLOv3(You Only Look Once v3)增强模型的人流密度估计方法,分别用头部集和身体集训练得到两个模型,在推理时将这两个模型的输出结果进行融合,但该方法增加了计算成本、延长了推理时间;S.Ren等人[4]提出了Faster RCNN模型,能够通过训练好的模型实时检测图像中目标框的数量,进行人群计数,但在高度遮挡场景中,该方法准确度较差;Liu等人[5]在Faster RCNN的基础上进行改进,提出了一种检测和回归相结合的人群计数模型DecideNet,该方法准确度有所提升,但依然存在两阶段检测模型计算量大、内存需求高,难以应用于嵌入式设备的问题。
目前,在各种深度学习目标检测模型中,YOLOv5因其模型轻量、容易部署、推理速度快而广泛用于各类实时性要求较强的应用中[1]。其中,YOLOv5s更适用于客流密度检测这一准确性和实时性的要求均较高的应用。针对城轨列车车厢场景中存在的人群密集、乘客间相互遮挡等问题,本文提出了一种基于改进YOLOv5s模型的列车车厢客流密度检测方法,有效提高了检测精度和效率。
1 基于YOLOv5s的客流密度检测模型
1.1 YOLOv5概述
YOLOv5网络结构分为输入(Input)、主干(BackBone)、瓶颈(Neck)及输出(Prediction)4部分:输入端采用了Mosaic数据增强、自适应锚框及自适应图片缩放3种方法,用于增强模型对小目标的检测效果并提高推理速度;BackBone网络中采用了Focus和跨阶段局部网络(CSPNet,Cross Stage Partial Network)结构;Neck网络中采用了特征金字塔网络(FPN,Feature Pyramid Network)+路径聚合网络(PAN,Path Aggregation Network)结构;在输出部分,采用了复杂交并比(CIoU,Complete Intersection over Union)作为边界框的(Bounding box)损失函数及非极大值抑制(NMS,Non-Maximum Suppression)方法。根据网络深度和宽度的不同,YOLOv5分 为YOLOv5s、YOLOv5m、YOLOv5l、YOLOV5x 共4种,其中,YOLOv5s的网络宽度和深度最小,参数量仅有7.2 M、因此速度最快,更适用于本文的客流密度检测应用。YOLOv5s网络结构,如图1所示,输入图像为经数据增强及自适应缩放等操作后得到的608×608×3的图像,定义BackBone中Focus结构使用32个卷积核,设计了两种CSPNet架构CSP1_X和CSP2_X,分别应用于BackBone和Neck中。

图1 YOLOv5s网络架构
1.2 模型建立
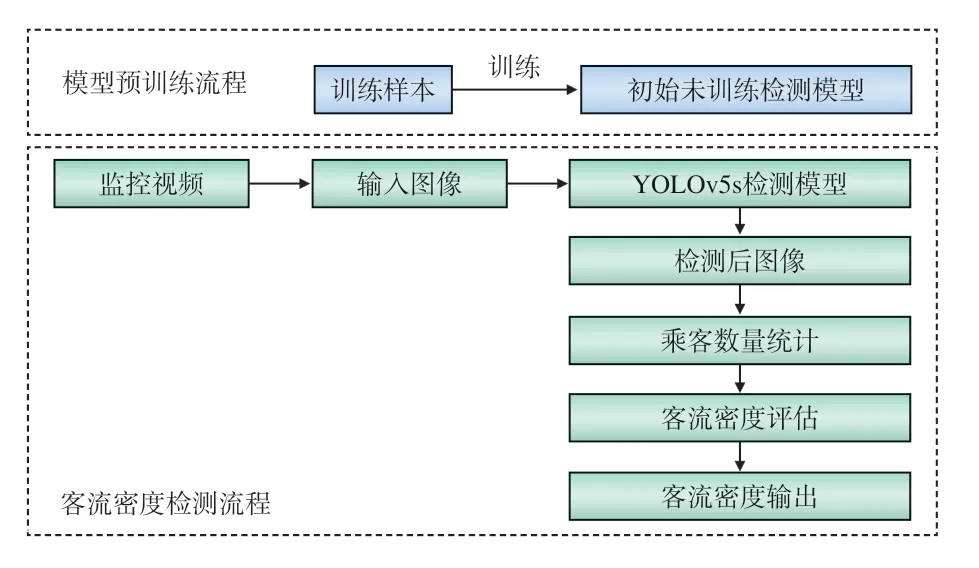
图2 模型建立流程
2 模型改进
2.1 特征融合网络改进
在Neck网络中,YOLOv5s采用的是FPN+PAN结构,如图3所示,自顶向下传递深层的强语义特征,再通过自底向上的路径增强方式,将浅层的强定位特征传上去,缩短了信息路径。但FPN+PAN结构中,存在只有一条输入边的节点未进行特征融合的情况,因此,在特征融合网络中相较于其他的节点其贡献较小。为降低计算成本且融合更多特征,文献[6]提出了一种加权的双向特征金字塔网络(BiFPN ),去掉两个只有一条输入边的节点,并添加了一条连接原始输入节点及其同水平输出节点的额外的边,如图4所示。
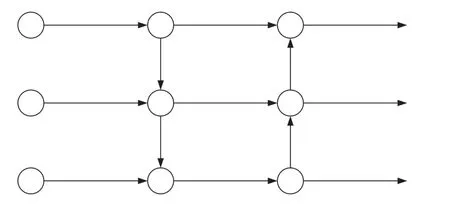
图3 FPN+PAN结构示意
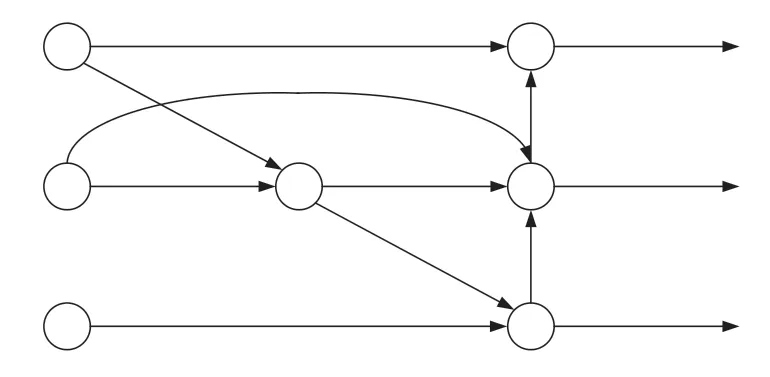
图4 BiFPN结构示意
为更有效地融合不同层级的特征,提高检测精度,本文使用BiFPN结构代替YOLOv5s原本的FPN+PAN结构实现特征融合功能,改进后的YOLOv5s网络结构如图5所示。
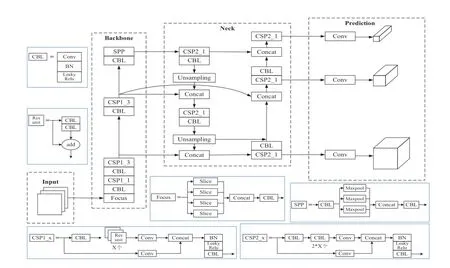
图5 改进后的YOLOv5s网络结构
2.2 损失函数改进
在计算候选框损失函数的回归损失部分时,YOLOv5s采用了CIoU,以重叠面积、中心点距离及长宽比3项因素作为评估标准,对候选框进行全面评估。但在城轨列车车厢场景中,客流量大时人群密集大、乘客间遮挡情况严重,各目标间距离较近且重合度较高,仅依靠CIoU计算回归损失可能会导致不准确的定位。
本文受文献[7]启发,定义了一种损失函数计算方式,来解决检测目标相互遮挡的问题,忽略预测框与其他非最佳匹配的真实框之间的关系,只期望在距离和面积两方面预测框和对应真实框尽可能地重合,本文定义的损失函数计算公式为

其中,LDis为预测框与其最匹配的真实框间的距离损失;LGIoU为预测框与其最匹配的真实框间的重叠面积损失。
距离损失LDis的计算公式为
“‘活力老人’是目前日间托管机构的主要群体,但对家庭、社会来说,更需要解决的可能是对失能、半失能老人的照护,但在这些业务的开展上,社区养老中心每走一步,都像摸着石头过河,困难很多。”张振美说。
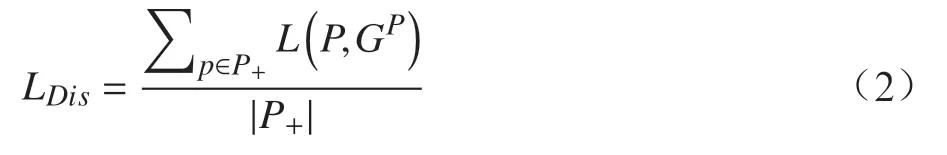
式中,各预测框与其最匹配的真实框间距离L的计算采用欧式距离;P为预测框;P+为所有预测框P的集合;|P+|为集合P+中预测框的数量;GP为与P最匹配的真实框,即在所有真实框的集合G+中,与P的IoU值最大的真实框,。
重叠面积损失LGIoU采用GIoU作为评估标准,其计算公式为
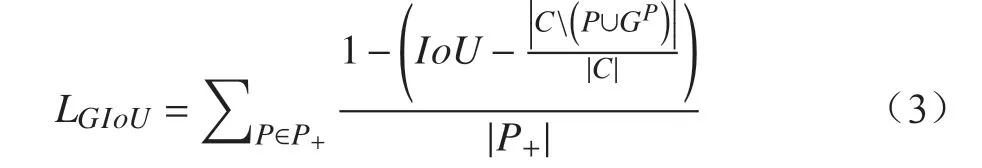
式中,C为预测框P与真实框GP最小的矩形封闭对象;IoU为预测框P与真实框GP的交并比值,。
2.3 NMS方法改进
YOLOv5s在消除冗余框时,采用了NMS方法,但在车厢客流密度检测这类密集目标检测的应用中,正确的预测框很可能因与得分最高的预测框重叠面积较大而被错误地删除,且检测效果受阈值大小影响,不恰当的阈值设置可能会导致检测效果较差。针对NMS存在的上述问题,文献[8]提出了一种Soft-NMS方法,不直接删除预测框,而是根据与得分最高预测框的IoU值调整原本的得分。
然而,当预测框与最高得分预测框相距较远且IoU值较低时,盲目降低预测框的得分值并不合理;当相距较近且IoU值较高时,Soft-NMS不能直接令与最高得分预测框完全重叠的预测框得分降为零,可能导致重叠框剔除不完全的情况。针对上述问题,本文提出了一种结合NMS和Soft-NMS的冗余框消除方法D-NMS,根据距离,选择其中一种方法重新计算预测框得分,具体流程如图6所示。
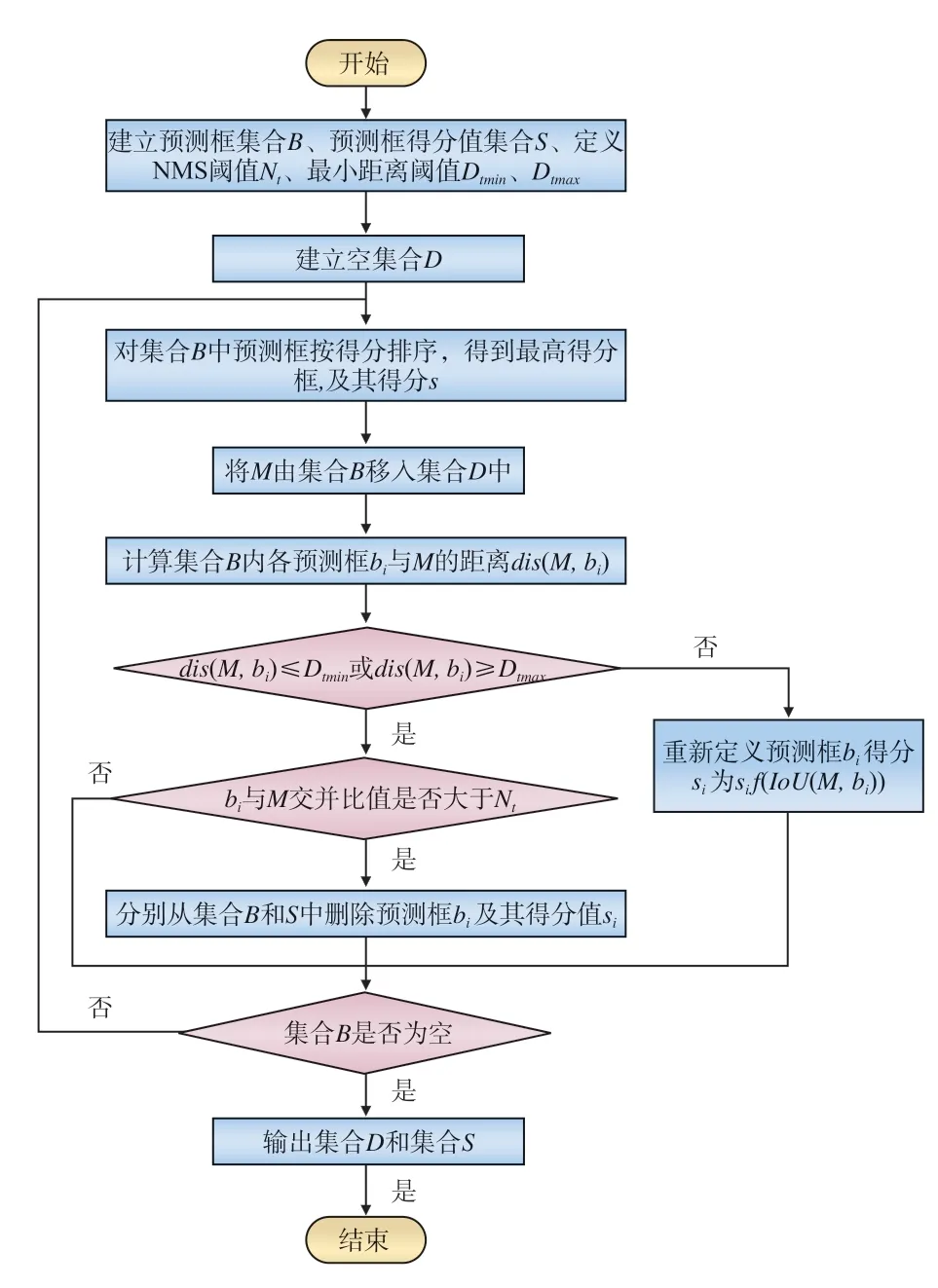
图6 D-NMS算法流程
其中,当前预测框bi与最高得分预测框M的距离dis(M,bi)=d/c,d、c的定义如图7所示,图7中灰色框与黑色框分别表示当前预测框与得分最高的预测框,d为两框中心点距离,c为两框最小外接矩形对角线长度;f(IoU(M,bi))为Soft-NMS采用的高斯惩罚函数,其计算公式为


图7 预测框间距离示意
3 实验及结果分析
3.1 实验数据集
本文采用CVC05-PartOcclusion行人检测数据集与自制地铁车厢乘客数据集进行实验,来验证本文改进的YOLOv5s方法的有效性。
CVC05-PartOcclusion行人检测数据集来自CVC行人检测数据库,是一个部分被遮挡的行人数据集。按7∶3划分训练集和测试集,训练集共包含415张图像,测试集包含178张图像。
自制数据集为采集的地铁车厢图像,对图像中乘客头部进行标注后得到包含不同客流密度情况的图像,共185张。按7∶3的比例划分训练集和测试集,训练集包含130张图像,测试集包含55张图像。
3.2 数据处理
为满足YOLOv5s模型检测格式,数据集中每条标注数据的内容应依次为标注物类别数字代号、标注框中心点横坐标、标注框中心点纵坐标、标注框宽度、标注框高度,且标注框中心点坐标值、标注框宽度值及高度值均为经归一化处理后的值。因此,需对数据集的标注数据进行归一化处理。
CVC05-PartOcclusion行人检测数据集的官方标注数据格式为标注物类别名称、标注框左上角横坐标、标注框左上角纵坐标、标注框宽度、标注框高度,其中,标注框左上角坐标值、宽度值及高度值均以像素为单位。需对标注数据进行如下处理:(1)将标注物类别名称替换为对应的数字代号;(2)根据标注框左上角坐标及标注框宽高计算标注框中心点的坐标值,并用中心点坐标替换左上角坐标;(3)将坐标值及宽高值进行归一化处理。
自制数据集采用LabelImg标注工具,选择YOLO标签格式进行标注,得到符合YOLOv5s模型检测格式要求的标注数据。
3.3 评价指标
本文共采用F1-Score、AP50及AP50:5:95共3个评价指标来评估算法的性能。
(1) F1-Score
F1-Score为精准率P和召回率R的调和平均,综合考虑了这两个指标,F1-Score值越大,模型质量越高。其计算公式为。
(2) AP50
平均精度(AP,Average Precision)值通过计算PR曲线,即将召回率R设置为横轴,精准率P设置为纵轴所构成的曲线的面积得到,AP值越大,模型越能同时保持较高的准确率和召回率。AP50为IoU阈值设置为50%时的平均检测精度,是针对单一类别的精度。AP50值越大,模型质量越高。
(3) AP5:5:95
AP50:5:95为IoU阈值取值从50%到95%,步长为5%时,所有AP的均值。该指标能够综合衡量不同IoU阈值下模型的性能,AP50:5:95值越大,模型质量越高。
3.4 实验结果分析
分别应用原YOLOv5s模型与改进后的YOLOv5s模型在CVC05-PartOcclusion行人检测数据集及自制地铁车厢乘客数据集上进行训练。实验运行环境为:CPU为Intel i7-1065G7,GPU为NVIDIA GeForce MX350,内存为10 G,操作系统为Windows10,开发语言为Python,使用了Pytorch深度学习框架,具有支持动态修改的优势。
应用经训练得到的两种模型对测试样本进行测试,得到的检测结果对比如图8、图9所示,其中,图8(a)和图9(a)为应用原YOLOv5s模型的检测结 果;图8(b)和 图9(b)为 应 用 改 进 的YOLOv5s模型的检测结果;图8(c)和图9(c)为检测前图像;图8(d)和图9(d)为改进后模型检测时识别到的原模型未识别到的检测目标。

图8 CVC05-PartOcclusion行人检测数据集测试结果对比

图9 自制地铁车厢乘客数据集测试结果对比
综上,应用改进后的YOLOv5s模型进行检测的结果能识别出部分原YOLOv5s模型无法识别出的被遮挡的目标,检测结果更为准确,更适用于城轨列车车厢这类人群密集、遮挡严重的环境。
为验证本文提出的改进后的YOLOv5模型与原YOLOv5模型相比性能有无提高,依据F1-Score、AP50、AP50:5:95这3项评价指标对比两种模型的检测性能,结果如表1和表2所示。

表1 改进模型与原模型在CVC05数据集上的检测性能对比

表2 改进模型与原模型在自制数据集上的检测性能对比
由表1、表2可知,在CVC05数据集上,改进后的模型较原模型F1-Score指标提高了0.5%,AP50指标提高了2.8%,AP50:5:95指标提高了4.7%;在自制数据集上,改进后的模型较原模型F1-Score指标提高了0.5%,AP50指标提高了0.9%,AP50:5:95指标提高了6.3%。因此本文提出的改进模型能有效提高检测精度,性能更好。
4 结束语
本文提出了一种基于深度学习的车厢客流密度检测方法,采用了改进的YOLOv5s模型对车载CCTV系统监控进行实时检测,在列车车厢人群密集、遮挡严重的情况下,能更准确地识别车厢中的乘客目标。本文对特征融合网络结构进行优化,以融合更多特征;重新定义了损失函数,以在遮挡情景中更可靠地评估检测结果;为避免客流密度较大时将真实目标框误删除,对消除冗余框的NMS方法进行了改进。最后,在CVC05数据集及自制数据集上进行了对比实验,实验结果表明,本文改进的YOLOv5s
模型能有效解决遮挡问题,检测精度较改进前明显提高,证明了本文方法的有效性,可应用于城轨列车车厢客流检测技术领域。
猜你喜欢
环球时报(2022-12-12)2022-12-12
粉末冶金技术(2021年3期)2021-07-28
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
四川文学(2020年11期)2020-02-06
专用汽车(2016年9期)2016-03-01
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
汽车维修与保养(2014年7期)2014-04-18
