
基于ADFRN与SAGCN的少样本学习方法
2022-11-11 10:58强梦烨陆琴心晏明昊
无线互联科技 2022年16期
强梦烨,陆琴心,晏明昊
(国网江苏省电力有限公司无锡供电分公司,江苏 无锡 214000)
0 引言
在现实应用场景中,计算机视觉任务的研究首先会遇到难以获取理想的数据集的问题[1-6]。目前,图卷积网络(GCN)已经被成功应用在少样本学习任务上,但这类方法存在着明显的缺陷。随着图卷积网络层数的加深,模型容易出现过拟合的现象[7-9]。基于图卷积网络的少样本研究通常在模型学习过程中仅使用了图像的全局特征,忽略了图像中具有类别判别性的细节信息。为了解决上述问题,本文提出了基于自适应细节特征增强网络(ADFRN)与语义对齐图卷积网络(SAGCN)的少样本学习方法。
1 任务设定
少样本学习通过构造一系列N-way, K-shot的学习任务来模拟缺少数据的场景。每个学习任务包含两部分:支持集和查询集。支持集包含N个不同类别的数据,每一类由K张带标签图像组成。查询集和支持集拥有相同的类别空间,但是每一类包含M个不带标签的图像。支持集和查询集不能有相同的数据。模型先在支持集上进行学习,然后给查询集中的数据预测类别。在模型训练和测试时,分别在训练集和测试集上构造学习任务,模型会在这些学习任务上进行学习。
2 模型
2.1 ADFRN
少样本学习方法大多仅对图像进行简单的卷积操作,利用全局特征预测图像类别。这些方法忽略了图像中具有类别特点的局部细节信息对于分类的帮助。为了有效地利用这些局部细节,本研究设计了ADFRN。网络的结构如图1所示。整个ADFRN网络可以概括为:

图1 自适应细节特征增强网络(ADFRN)结构
r(x)=Rf(g(x),b(g(x),E))
其中,x是输入图像,g是全局特征图,E是指导模型对于输入图像进行细节特征强化的经验知识,b是根据g(x)和E学习到的强化基准,Rf表示特征强化函数,r为细节强化特征图。
由于同类别的物体带有类别鉴别性的局部特征是相似的,因此本研究利用模型已经学习到的关于此类别局部增强特征的知识去指导对新样例进行特征增强。在ADFRN中,类别特征库专门用来存储模型已学习到的知识结构,里面的类别i的对应知识可以表示为:
Qi={Ei,Lci,Ni}
其中,Ei∈Rc×h×w是类别i的平均增强特征图,Lci为类别i的标签,Ni表示已学习到的类别i的样例的数量。在对输入图像进行卷积后,从类别特征库选择和它距离最近的知识作为经验知识。在每次分类后,模型都会计算新的类别平均增强特征。
得到全局特征图g(x)∈Rc×w×h和经验知识E后,利用卷积层对E进行卷积操作,得到一个张量sφ(E)∈Rcp2×h×w,φ是卷积层参数。卷积层的作用是用来学习捕获局部细节信息的卷积核,每个卷积核的边长都为p。对于g(x)中c个通道的同一位置g(x):,i,j,都可以根据sφ(E)去生成一组包含c个可学习的卷积核:
ki,j=Sigmoid(sφ*n3(E:,i,j))
其中,sφ表示卷积层,n3表示以E中位置(i,j)为中心,边长为3的领域,*是卷积操作。
考虑到同类别的图像受到客观拍摄条件的影响,导致目标差异较大,为了能够更灵活地捕捉细节的周边信息,受到可变卷积的启发设计了一种自动采样策略。
利用一个卷积层sθ对g(x)和E进行卷积:
O=sθ(con(g(x),E))
其中,con是级联操作,O∈R18×h×w是根据g(x)和E学习到的垂直和水平方向上的偏移量图。对于位置(i,j)上根据O生成边长为3的领域:
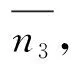
利用ki,j对以g(x):,i,j为中心的区域进行卷积可以得到对应位置的强化基准特征:
b(g(x),E):,i,j=ki,j*np(g(x):,i,j)
利用从E学习到的卷积核对g(x)从通道和空间维度对细节信息进行了捕获和增强。特征图的增强可以用残差网络进行增强:
g(x)t+1=g(x)t+b(g(x)t,E),t=0,...,T-1
r(x)=g(x)T
超参数t的选择将影响到网络的深度,而且学习中涉及了不同种类的数据,使用同一个t是不合适的。因此,本研究引入Neural ODE,将离散化的残差操作转变为ODE方程的求解问题:
最终的强化特征图r(x)可以视作上述方程的解。
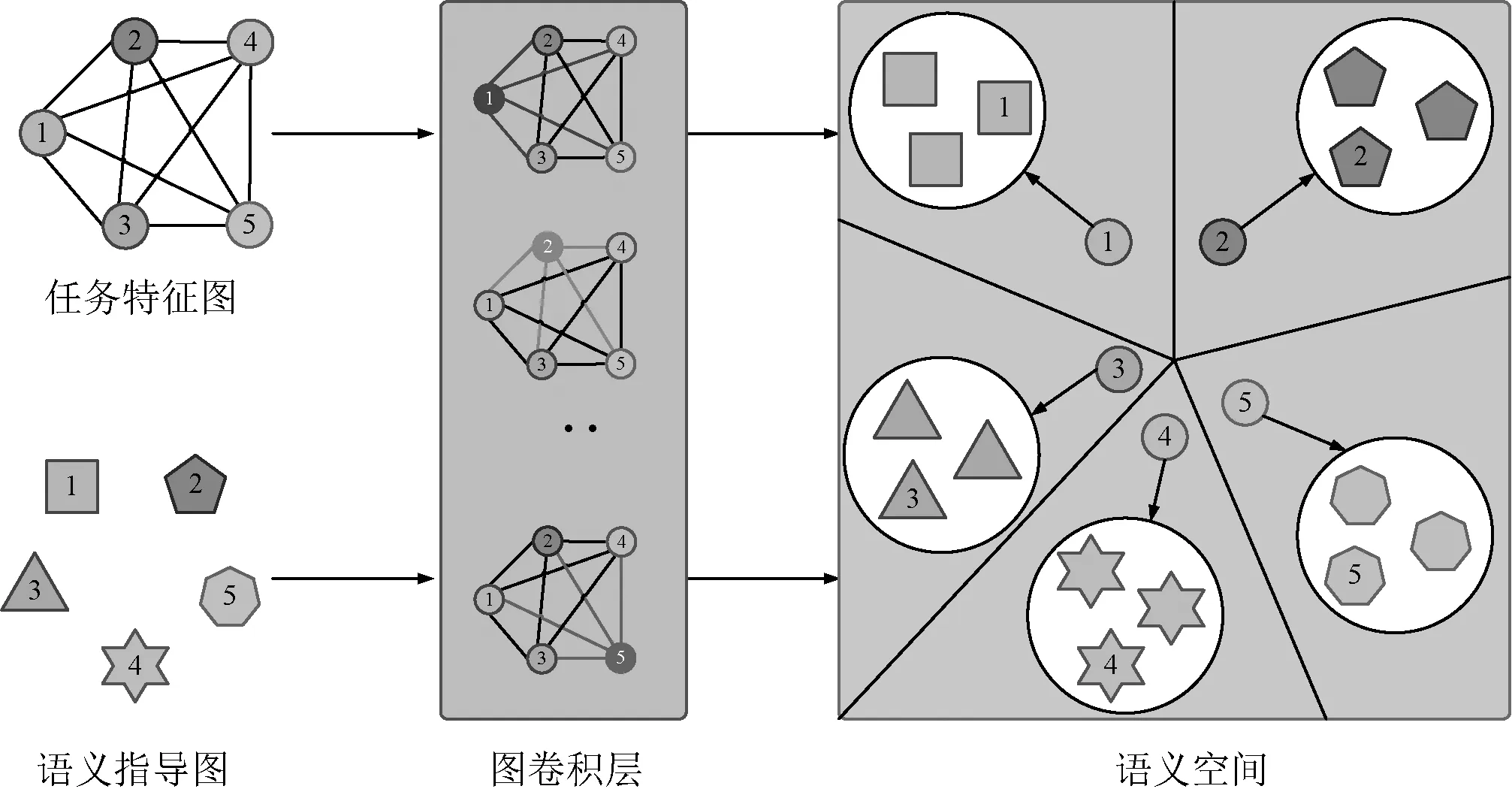
图2 SAGCN语义对齐示意
2.2 SAGCN
得到输入图像的强化特征图以后,利用这些增强特征构造图结构数据,将图结构数据作为语义对齐图卷积网络的输入。图结构数据的初始结点特征和初始边特征表示为:
初始的结点特征与边特征构成了输入SAGCN的初始任务特征图:
tg0={node0,edge0}
任务特征图在SAGCN中每经过一个图卷积层都会对结点特征和边特征进行迭代更新:
其中,μ是激活函数,I是单位矩阵,Y是图卷积层中的可学习的参数,D=diag(di,...dH)是对角矩阵,该矩阵中的每一项:
为了进行语义对齐操作,本研究还需要输入语义指导图到网络中,生成用于语义对齐的语义指导结点特征。初始的语义指导图中仅有sg0={node0}。这些语义参考结点特征在每一层的更新迭代可以表示为:
sgl+1=μ(I(sgl)Yl+1)
其中,I是单位矩阵。
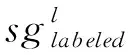
2.3 损失函数
整个模型的损失函数可分为两部分,一个是语义对齐损失Ls,另一个是分类损失Lc。整个模型的损失函数Lm可以表示为:
Lm=Lc+αLs
其中,l是SAGCN网络层数,z表述种类数量,Cz(x)表示x中属于类别z的结点特征中心,ω为欧式距离的平方,λ表示softmax函数,δz是类别z对应的标签指示向量。在本文中,参数α取值均为1。
3 实验
3.1 数据集与实验设定
为了验证本文提出的模型的有效性,本研究在常用的少样本学习数据集miniImageNet上进行实验,实验过程中使用Adam SGD优化器对模型的参数进行优化,权重衰减设为5e-4,模型的初始学习率设为0.35。
3.2 实验分析
在数据集miniImageNet上的实验结果如图3所示。本文方法在数据集miniImageNet上的表现要好于现有的方法。在处理5-way,5-shot学习任务时,本文方法的优势更加明显。当使用WRN-28作为Backbone时,在数据集miniImageNet上取得的准确率比现有方法中表现最好的文献[1]还要高出1.03%。当使用Res-12作为Backbone时,在数据集miniImageNet上的准确率和文献[6]以及文献[7]相比高出了3.15%。
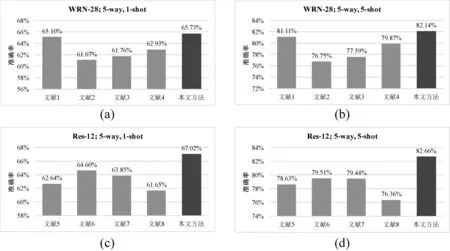
图3 miniImageNet数据集实验结果
经消融性实验可得,GCN的深度为4层,SAGCN深度为8层。在对特征不进行强化时,在数据集miniImageNet上使用SAGCN的准确率比使用一般GCN的准确率分别高出了5.82%和6.93%,证明了语义对齐操作能够防止过拟合现象。当仅使用GCN进行分类时,对局部细节加强后,在数据集miniImageNet上准确率提升了2.71%,表明对细节信息的增强对分类能起到一定的促进效果。当同时对图像的局部细节特征进行加强并在GCN中引入语义对齐的操作,本研究提出的模型才能发挥最大的优势。和GCN相比,引入语义对齐能够在结点特征的迭代更新过程中始终让同类别的结点具有相似的特征分布,较好地克服了过拟合问题。
4 结语
本文提出的基于ADFRN与SAGCN的少样本学习方法,能够根据已经学习到的经验知识,自动预测能够从空间和通道维度捕获有价值的具有类别特点的局部细节信息的卷积核,强化其捕获局部细节信息的能力。利用Neural ODE根据每一类数据的特点,来求解其强化特征图。通过构建图结构数据,在SAGCN中对结点与边特征进行迭代优化,同时利用语义对齐过拟合。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
数学物理学报(2018年1期)2018-03-26
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
大连民族大学学报(2015年2期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
电子设计工程(2014年12期)2014-02-27
食品科学(2013年8期)2013-03-11
外语学刊(2011年1期)2011-01-22
