
基于LightGBM和处方数据的番茄病害诊断方法
2022-11-08 02:20丁俊琦赵聃桐张领先
农业机械学报 2022年9期
徐 畅 丁俊琦 赵聃桐 乔 岩 张领先
(1.中国农业大学信息与电气工程学院, 北京 100083; 2.北京市植物保护站, 北京 100029)
0 引言
作物处方数据包含作物信息、环境信息、病害信息及其诊断知识,同时基于宿主、病原体和环境的传统流行病学和植物病理学知识为处方数据分析提供了新的研究视角。如何有效挖掘作物处方数据多源信息间的内在关系以及辅助精准诊断是一个亟待解决的问题。
基于处方数据挖掘的作物病害诊断问题可转化为计算机领域的多分类解决方法。机器学习模型在分类方面具有计算时间短、精度高、可移植性强的优点[1]。而现实中数据量的不断增加和数据的多元化,尤其是作物处方数据的复杂性和专业性,使传统的分类算法不能很好地满足现有数据的处理以及实际问题的解决需求。集成学习模型在分类问题上显示出了极大的优势[2],利用基础算法的多样性可以提高集成模型的分类准确率、泛化能力和鲁棒性[3]。传统的Boosting[4]算法(如GBDT和XGBoost)需要对每一个特征扫描所有的样本点来选择最佳的切分点,因此在效率和可扩展性上不能再满足相应的需求。为了解决在大样本、高维度数据环境下算法耗时长的问题,LightGBM[5]使用了如下两种解决方法:梯度单边采样(Gradient-based one-side sampling,GOSS),对样本进行采样来计算梯度,而不是使用所有的样本点计算梯度;互斥特征捆绑(Exclusive feature bundling,EFB)方法将某些特征捆绑在一起降低特征的维度,并非对所有的特征进行扫描,从而使得寻找最佳切分点的消耗减少。因此可以在大幅降低样本处理时间复杂度的基础上,保证LightGBM的精度稳定或提升[6]。目前,LightGBM模型已成功应用于不同领域[7-9]。
番茄是一种病害高发的作物[10],有效防治病害是番茄种植中的重要工作[11]。对此,本文以番茄病毒病、番茄晚疫病、番茄灰霉病3种常见病害为研究对象,构建基于LightGBM的番茄病害智能诊断模型,探索一种针对处方多维大数据特点的番茄病害诊断方法。
1 诊断模型建立
基于LightGBM和处方数据的番茄病害诊断流程如图1所示。主要步骤如下:①获取番茄病害处方原始数据。②选取实验数据。③对数据进行统计分析,了解不同区域、不同生长期番茄病害发展情况。④对数据进行预处理(编码等)。⑤利用RFECV和GDBT结合的方法进行特征选择。⑥将优选后的特征作为诊断模型的输入,比较8种常见分类模型,以最优模型作为番茄病害诊断模型。⑦输出最终诊断结果并计算准确率。
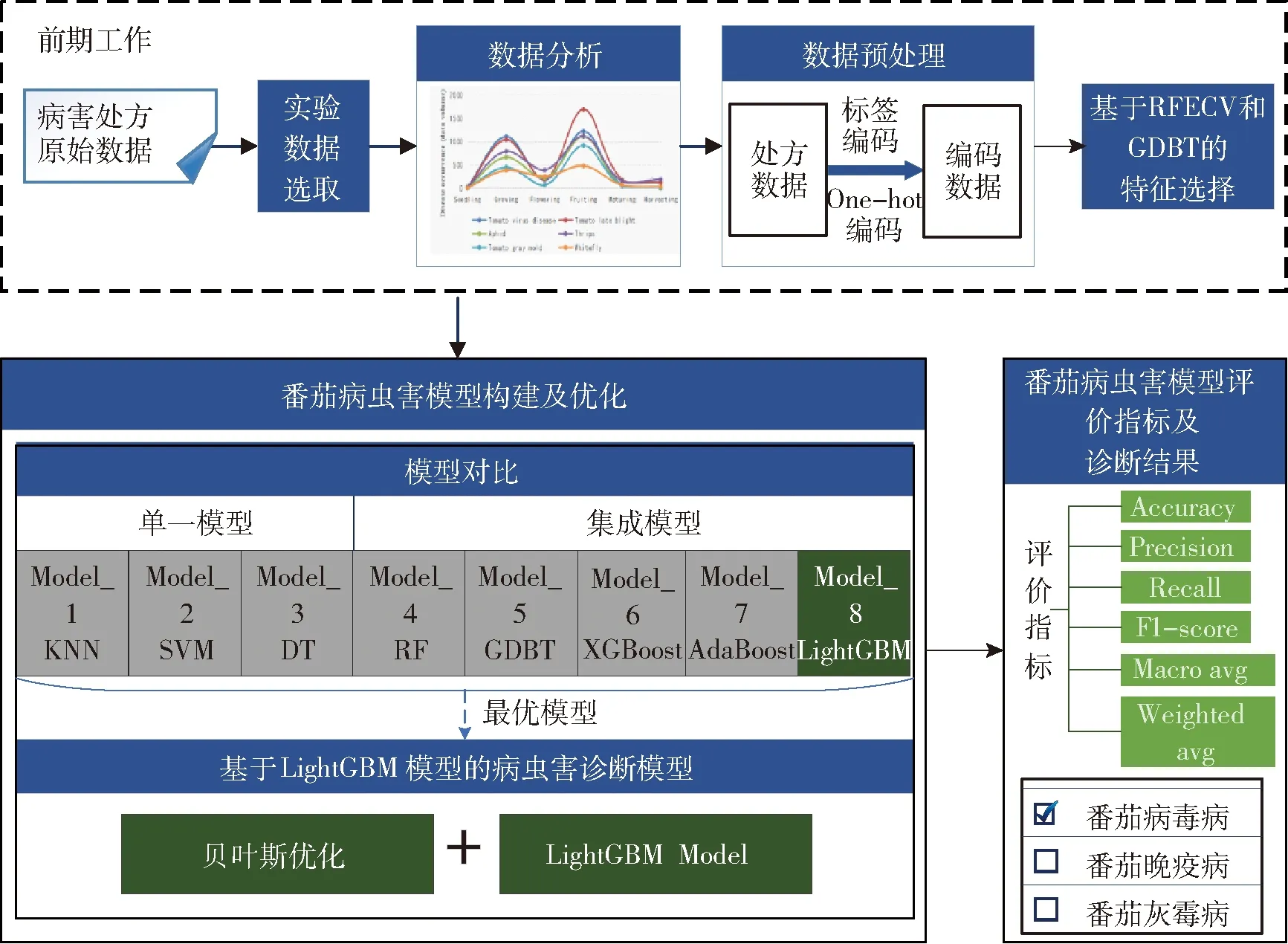
图1 基于LightGBM和处方数据的番茄病害诊断流程Fig.1 Flowchart of tomato disease diagnosis based on LightGBM and prescription data
1.1 作物病害处方数据集构建
本研究数据来源于北京市植物保护站提供的处方数据库。北京市在全国首次引入国际应用生物科学中心的植物智慧解决方案和植物诊所先进理念,先后建立植物诊所115家,服务范围覆盖京郊161个乡镇,覆盖率达到88.95%。以植物医生开具处方的形式为生产者提供病害智慧诊断和防控技术咨询。植物诊所依托病害动态防控解决方案库和标准化处方形成机制,植物医生现场面对面为农户开具病害诊断防控处方。基于双向信息流的原则,开出包括问诊农户、植物诊所、作物和症状、诊断结果和防控建议的标准化处方。同时遵循有害生物综合治理(Integrated pest management,IPM)原则,包括预防在内,以物理防控、生物防控为主的绿色、综合防控配套措施。植物医生开具的所有处方经过“植物医生填写录入—区级数据管理员初步协调验证—市级数据管理员二次协调验证”的三级数据验证程序,合格率达 90%以上,并导入处方数据库,处方开具流程如图2所示。目前已经形成了127种病害绿色防控技术体系及20余万条处方数据知识库。
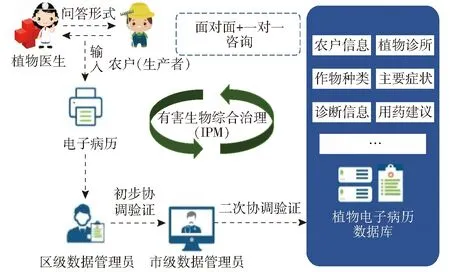
图2 处方开具流程Fig.2 Prescribing process
本研究以番茄病毒病、晚疫病、灰霉病3种病害作为研究对象,选取2019年3月25日—2020年11月19日番茄多种病害处方数据作为作物病害处方信息的数据源。每条处方数据包含所属区、时间、发育阶段、受害部位、发生面积、发生比重、主要症状、问诊记录、田间症状分布、诊断结果、开具农药名称、开具农药数量等共计7 344条处方数据,每种病害统计结果如表1所示。
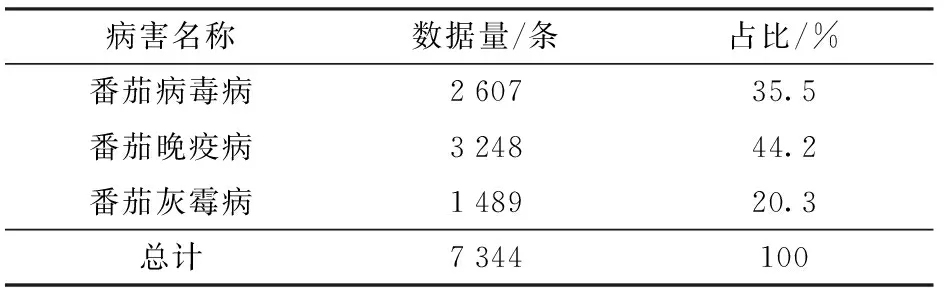
表1 实验数据统计结果Tab.1 Experimental data statistical results
1.2 实验数据预处理
本研究数据预处理流程包括对源数据文件整理、转换,数据清洗(删除重复值、缺失值处理、一致化处理和异常值处理),数据统计,最后对输出数据进行编码(标签编码和One-hot编码),如图3所示。
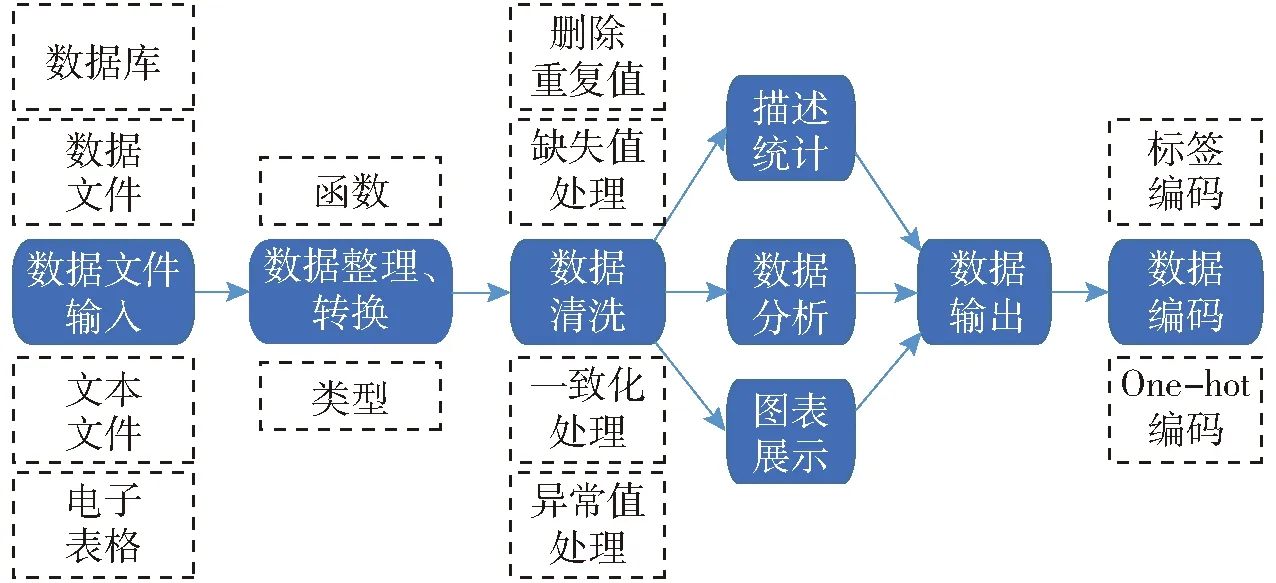
图3 处方数据预处理流程图Fig.3 Prescription data pre-processing flowchart
1.2.1文本数据标签编码
根据对处方数据的分析,将所属区域属性对应的顺义、海淀、延庆、密云、怀柔、平谷、通州、朝阳、昌平、丰台、大兴、房山12个区标注为R1~R12,将发育阶段属性对应的苗期、生长期、开花期、结果期、成熟期、收获期6个阶段标注为标签S1~S6,将发生比重属性对应的轻度发生、中度发生、重度发生3个比重标注为标签P1~P3。
1.2.2文本数据One-hot编码
One-hot编码是将类别变量转换为机器学习算法易于处理的数据,有利于进行损失函数或准确率计算。由于生产者对于受害部位、主要症状和田间症状分布的描述展示为多项选择,因此对以上3个属性的多选值进行One-hot编码,将受害部位的根、茎基部、茎、嫩叶/树枝、叶片、花、果实/谷粒、整株植物、嫩芽10个选项值和萎蔫、矮化、落叶、花叶、水疱状、腐烂等27个选项值以及局部分布、分散分布、线条分布、田地边缘、均匀分布等9个选项值进行编码。
1.3 特征选择方法
在作物病害处方数据集中,大量无关、冗余或噪声特征的存在不仅会带来维数升高的问题,还会直接影响分类器性能[12]。特征选择通过删除无关的冗余数据,为提高学习准确性提供了一个有效的解决方法,可以有效减少计算时间[13]。常用的特征选择方法可以分为过滤式(Filter)、封装式(Wrapper)和嵌入式(Embedded)[14]。而Wrapper方式的优势在于将特征选择问题转化为特征子集搜索问题,采用学习器分类性能作为特征子集的评价标准[15]。GDBT是一种迭代的决策树算法,通过多轮迭代降低偏差,达到提高分类精度的目的[16]。结合子算法的优势,混合方法通常比传统方法更稳健,因此可以作为本研究处方数据的特征选择方法。
选取Wrapper方式的递归特征消除(RFE)与交叉验证结合(RFECV)的方法对作物病害处方数据特征进行提取。 此时的交叉验证(CV)为不同列(特征)的组合求均值,用于求得最优的特征数量。RFECV算法对具体作物病害处方数据特征提取分为2个阶段:①RFE阶段:将编码后的原始处方数据作为模型的输入变量,通过不断训练GDBT模型,根据feature_importances_属性对特征进行重要性评级,每次训练完成后删除最不重要的一个或多个特征,然后对筛选出的特征集合再次进行训练,直到遍历完整个特征集,最终筛选出重要的特征变量个数为d。②CV阶段:对于数量为d的特征集合,其所有子集的个数为2d-1,将所有由不同特征数量构成的子集依次输入GDBT分类器,根据最高分类准确率输出的特征子集即为最优特征子集。RFECV算法流程图如图4所示。
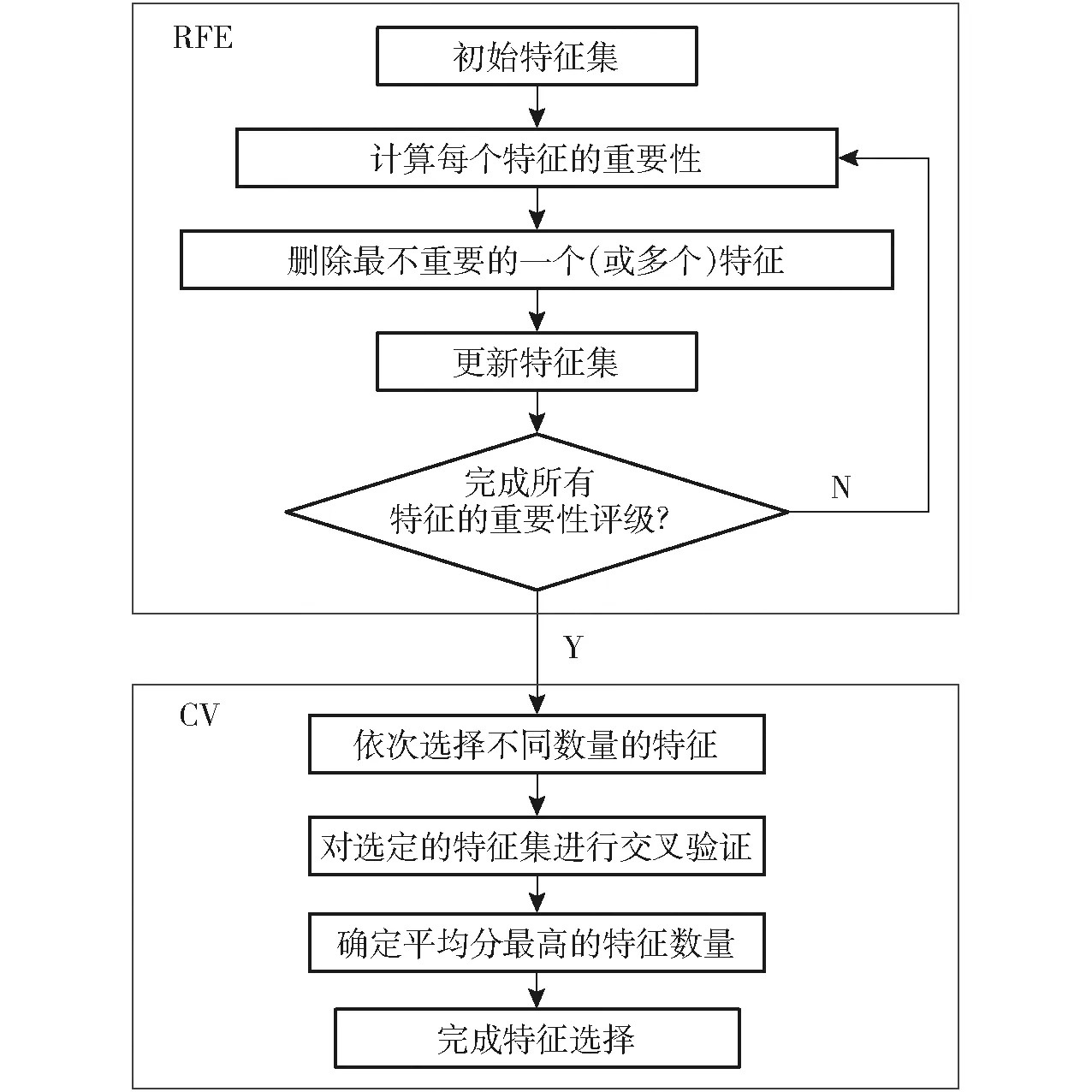
图4 RFECV算法流程图Fig.4 Flowchart of RFECV
1.4 基于LightGBM和处方数据的番茄病害诊断模型
1.4.1LightGBM算法
集成学习方法是指将多个学习模型组合,以获得更好的处理效果,使组合后的模型具有更强的泛化能力。LightGBM是基于Boosting的集成量级高效梯度提升树,具有高效、低内存、高准确率的优点,同时支持并行化学习,可以处理大规模数据。LightGBM相比于其他的Boosting集成方法,增加了梯度单边采样(GOSS)和互斥特征绑定(EFB)算法。
GOSS算法的主要思想是:从减少样本角度,排除大部分小梯度的样本,仅用剩下的样本计算信息增益。由于梯度大的样本点会贡献更多的信息增益,为了保持信息增益评估的精度,GOSS保留所有的梯度较大的实例,在梯度小的实例上使用随机采样。
EFB算法的主要思想是:从减少特征角度,将互斥特征绑定在一起,保证信息完整性的同时提升计算效率。对于如何合并互斥特征的问题,LightGBM的解决办法是利用直方图(Histogram)算法,将连续的特征离散化为k个离散特征,同时构造一个宽度为k的直方图用于统计信息(含有k个bin)。利用直方图算法无需遍历所有数据,只需要遍历k个bin即可找到最佳分裂点。
1.4.2基于贝叶斯优化算法的模型参数优化
贝叶斯优化算法[17](Bayesian optimization algorithm,BOA)是用于求解表达式未知的函数极值问题的方法,在参数组合寻优问题上被广泛应用。此方法可以利用之前已搜索的信息确定下一个搜索点,提高结果的质量以及搜索的速度,因此比网格搜索和随机搜索更为有效,具有迭代次数少、参数粒度小等优点。贝叶斯优化算法的核心由两部分构成:①先验函数(Prior function,PF):对目标函数进行建模,即计算每一点处的函数值均值μ(x)和方差δ(x),通常用高斯过程回归实现。 ②采集函数(Acquisition function,AC):通过采集函数确定下一个采样点[18],采样点的选择要综合考虑利用和探索,以保证最大限度地找到全局最优解。采集函数主要包括期望改善(Expected improvement,EI)、概率改善(Probability of improvement,PI)、置信区间上界(Upper confidence bound,UCB)等方法,本实验选取UCB函数作为采集函数,其数学表达式为
UCB(x)=μ(x)+εδ(x)
(1)
式中ε——权重
其中,参数ε用于平衡采样点的选择,有助于找到全局最优值。贝叶斯优化算法具体流程为:
选择n0个采样点,计算f(x)在采样点处的值
n=n0
whilen≤Ndo
根据当前采样数据D={(xi,f(x)),i=1,2,…,n}更新p(f(x)|D)的均值和方差
根据p(f(x)|D)均值和方差计算采集函数u(x)
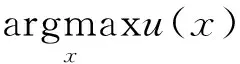
计算下一个采样点处的函数值:yn=f(xn+1)
n=n+1
end while
return:argmax(f(x1),f(x2),…,f(xN))以及对应的y
算法首先初始化n0个候选解,通常在整个可行域内均匀地选取一些点。然后开始循环,每次增加一个点,直至找到N个候选解。每次寻找下一个点时,用已经找到的n个候选解建立高斯回归模型,得到任意点处的函数值的后验概率。然后根据后验概率构造采集函数,寻找函数的极大值点作为下一个搜索点。接下来计算在下一个搜索点处的函数值。算法最后返回N个候选解的极大值作为最优解。
1.4.3基于LightGBM的番茄病害诊断模型
利用贝叶斯优化算法对LightGBM进行参数寻优时,以LightGBM的不同超参数组合作为自变量x,以5折交叉验证评估得到的准确率(Accuracy)作为贝叶斯框架的输出y。基于贝叶斯优化的LightGBM的番茄病害诊断模型具体步骤如图5所示。
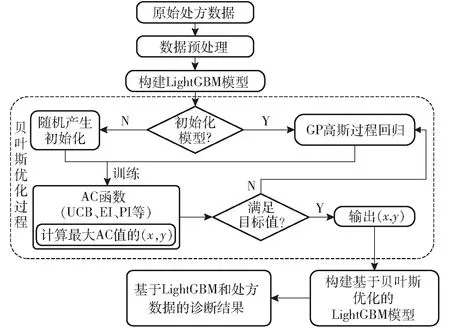
图5 基于LightGBM的番茄病害诊断模型原理图Fig.5 Principle of tomato disease diagnosis model based on LightGBM
1.5 评价指标
对于二分类问题,常见的评价指标是精确率、召回率、F1值和准确率[19]。
F1值可以同时兼顾分类模型的精确率和召回率,是分类问题常见的评价指标,F1值越高,表示分类器的综合性能越好。在本研究中对于番茄的某一种病害的诊断是二分类问题,对于番茄多种病害的诊断是多分类问题。对于多分类问题,其评价指标可扩展为宏平均和加权平均。宏平均是所有类别的评价指标(精确率、召回率和F1值)的算术平均值,但是此评价方法忽略了样本之间可能存在不平衡问题,因此加权平均在计算各个评价指标时先乘以该类在总样本中的占比再进一步求和。
2 实验结果与分析
2.1 特征选择结果分析与讨论
图6为通过RFECV结合GDBT得到的特征选择个数与模型交叉验证准确率的关系,本研究将原始数据的50个特征变量输入GDBT模型,前期交叉验证准确率基本一直保持上升趋势,说明特征越多,模型的准确率越高,模型准确率随着特征的增加先增加后趋于平稳,经实验得到选择的最佳特征个数为32个,包括所属区域、发育阶段、发生面积、发生比重、受害部位(整株植物、果实/谷粒、根等5个特征)、主要症状(丛枝、干枯、叶斑等19个特征)、田间分布症状(仅个别植株、分散分布等4个特征),作为番茄病害诊断模型的输入。
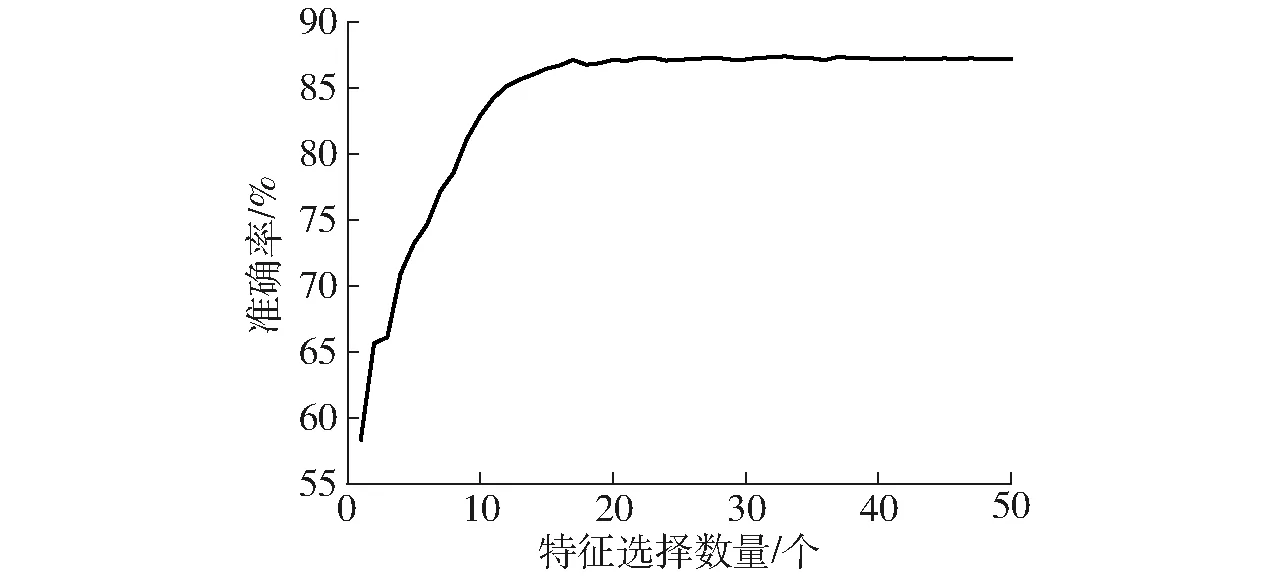
图6 基于RFECV和GDBT的特征选择结果Fig.6 Feature selection results based on RFECV and GDBT
2.2 模型结果与分析
2.2.1基于LightGBM的番茄病害诊断模型参数优化
通过构建LightGBM模型对3种番茄病害进行诊断,并同时基于KNN、决策树、SVM、GDBT、随机森林、AdaBoost和XGBoost进行建模以对比分析不同模型的分类性能,进一步验证本文提出的基于LightGBM的模型诊断能力。利用贝叶斯优化方法对本研究建立的LightGBM模型的10个重要参数进行优化,经过5折交叉验证获得最优超参数,其他参数均为默认值。待优化参数、选择范围及最终结果如表2所示。训练集和测试集的比例设置为7∶3。
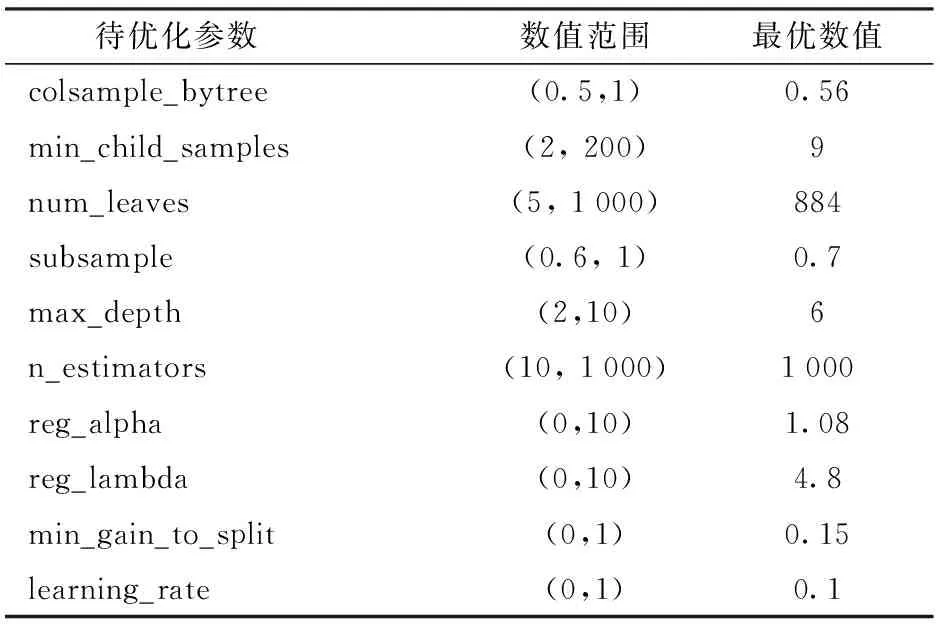
表2 参数优化结果Tab.2 Parameter optimization results
2.2.2基于LightGBM的番茄病害诊断模型结果分析
根据表3可知,基于LightGBM的番茄病害诊断模型在番茄病毒病、番茄晚疫病和番茄灰霉病3个类别数据上均达到较好的分类效果。其中,在番茄病毒病上的分类效果最佳,精确率和召回率分别达到97.27%和94.68%,同时综合评价指标F1值可达到95.95%。相比于番茄病毒病、番茄晚疫病和番茄灰霉病的分类效果稍显逊色,其原因在于两种病害均是实际田间环境中常见而难以区分的病害。两者在发病初期在果实上以灰白色霉层出现,发病后期在叶片上以深棕色斑点出现。特别是番茄晚疫病,此病害蔓延迅猛,短期内可造成毁灭性伤害,因此利用基于LightGBM的病害诊断模型的优势,对番茄病害及时防治具有重要现实意义。
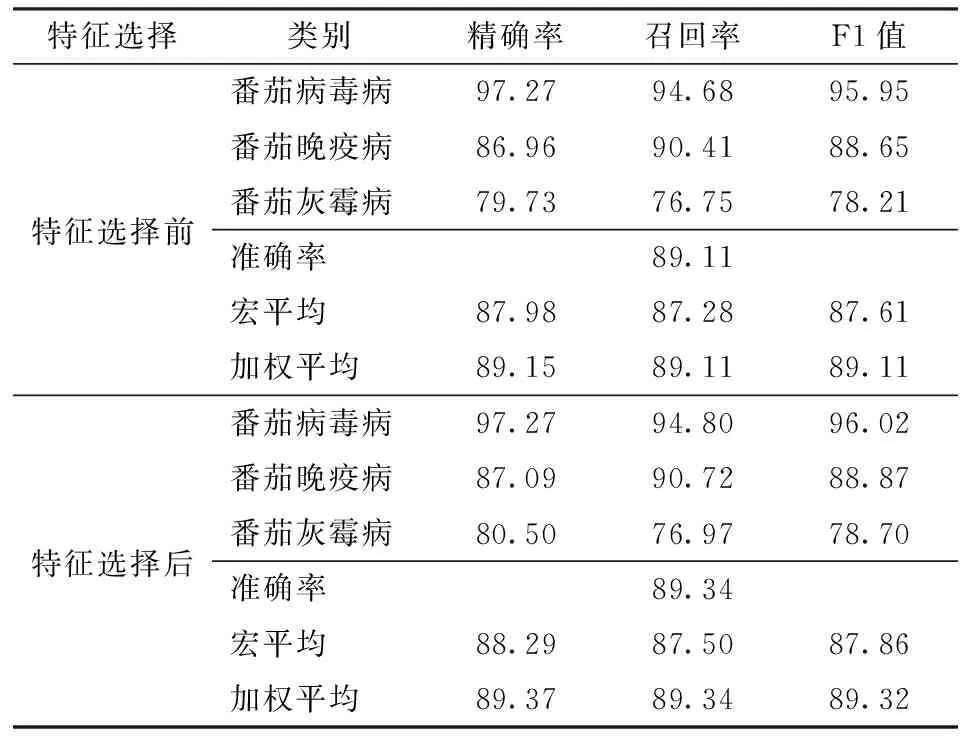
表3 基于LightGBM的番茄病害诊断模型实验结果Tab.3 Experimental results of tomato disease diagnosis model based on LightGBM %
2.2.3对比实验结果分析
基于LightGBM的番茄病害诊断模型结果较优。根据表4中准确率、宏平均和加权平均 3个评价指标的结果可知,LightGBM模型整体的分类性能较好。与表4的常用机器学习方法相比较,无论是单一的机器学习模型(KNN、DT和SVM),还是基于bagging集成框架的RF算法和基于Boosting集成框架的其它算法(AdaBoost、GDBT和XGBoost),LightGBM模型的表现最佳,准确率平均高于其它模型3.65个百分点。图7为LightGBM与其他7种机器学习方法的比较。
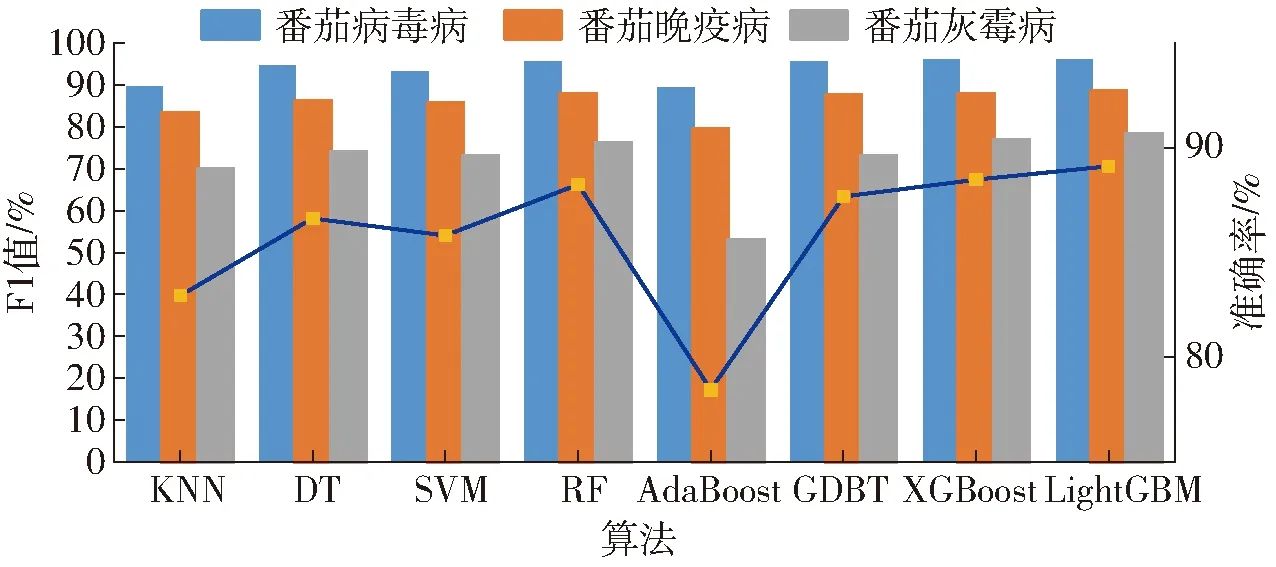
图7 各算法在3种病害上的F1值和模型准确率Fig.7 F1-score of each algorithm on three kinds of diseases and model accuracy
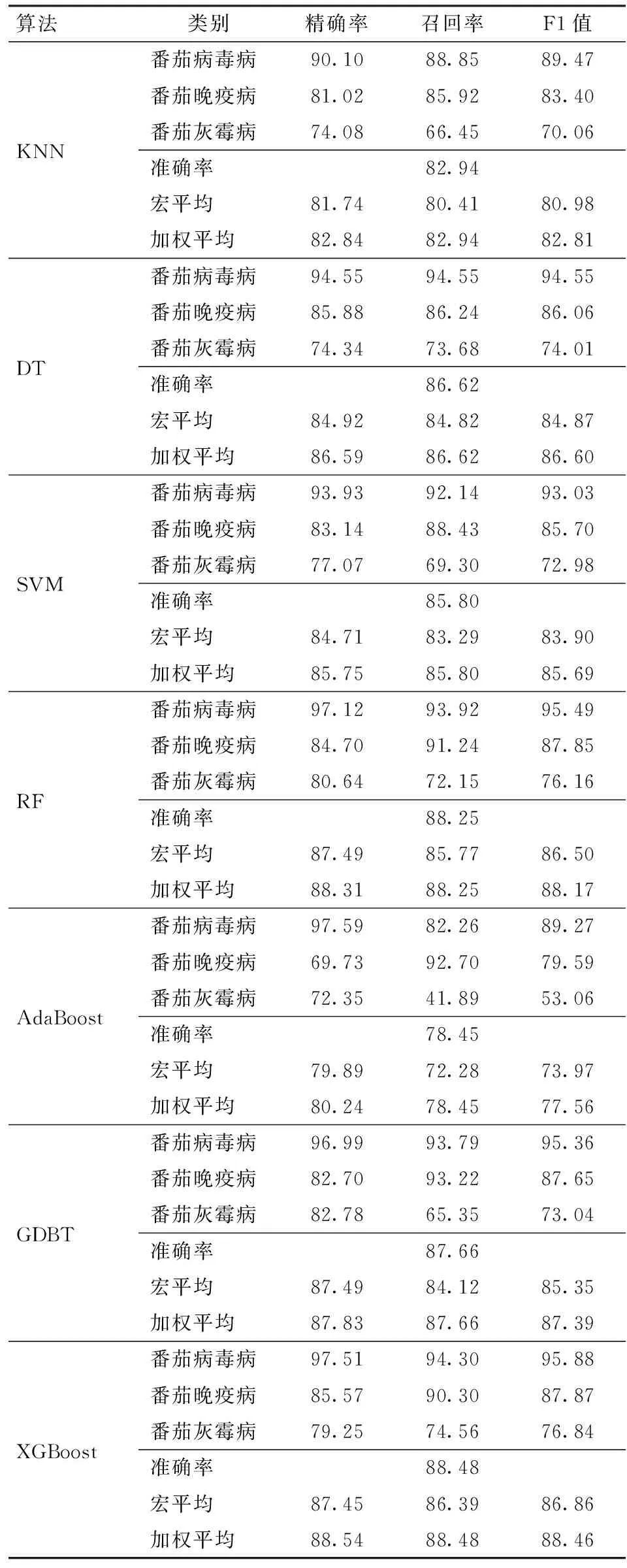
表4 特征选择前算法实验结果对比Tab.4 Comparison of algorithm experimental results before feature selection %
2.2.4特征选择结果分析
特征选择后的LightGBM模型在保证模型准确率的基础上降低了前期数据收集难度。本研究利用RFECV和GDBT结合的特征选择方法,进一步减轻前期数据采集的困难,提高模型运行效率。由图8可以看出,本文提出的特征选择算法的可靠性和稳定性。由图8可知,所有机器学习模型均可在一定程度上减少运行时间,实验结果表明特征选择前后每个模型运行时间平均降低20.37%,LightGBM模型的效果最为显著,时间消耗减少了47.73%,模型准确率提升至89.34%。
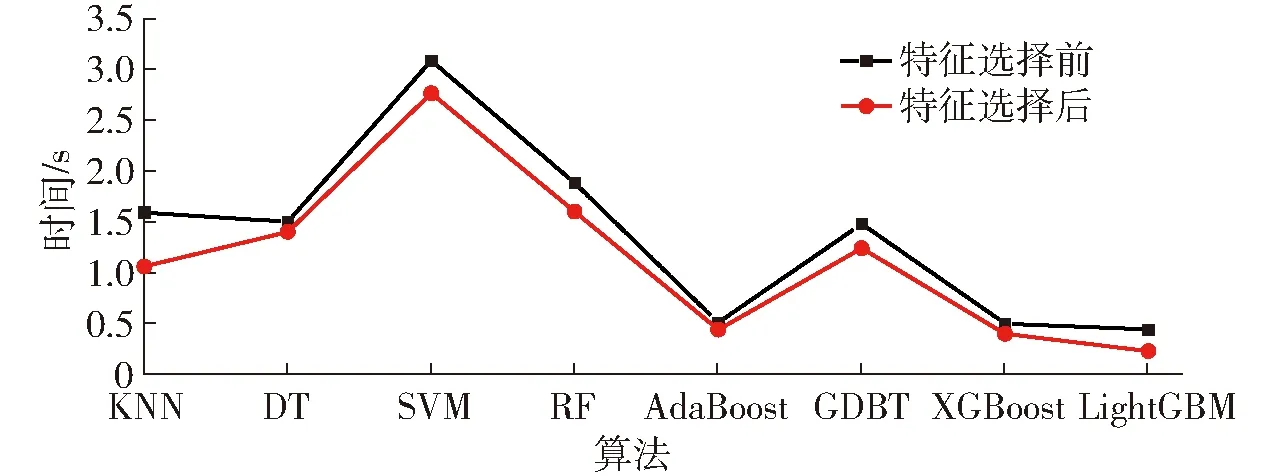
图8 特征选择前后算法时间对比Fig.8 Comparison of algorithm time before and after feature selection
2.2.5LightGBM诊断模型泛化能力测试结果分析
基于LightGBM的番茄病害诊断模型具有一定实用性且泛化能力强。为验证本研究提出模型的泛化能力和实用性,数据集增加番茄叶霉病和番茄早疫病2种番茄病害种类,数据量分别为390条和947条。由表5可以看出,本研究提出的多分类模型在番茄病害四分类和五分类的实验效果都较佳,其中番茄病毒病、晚疫病、灰霉病和叶霉病4种病害分类的准确率达到88.37%。
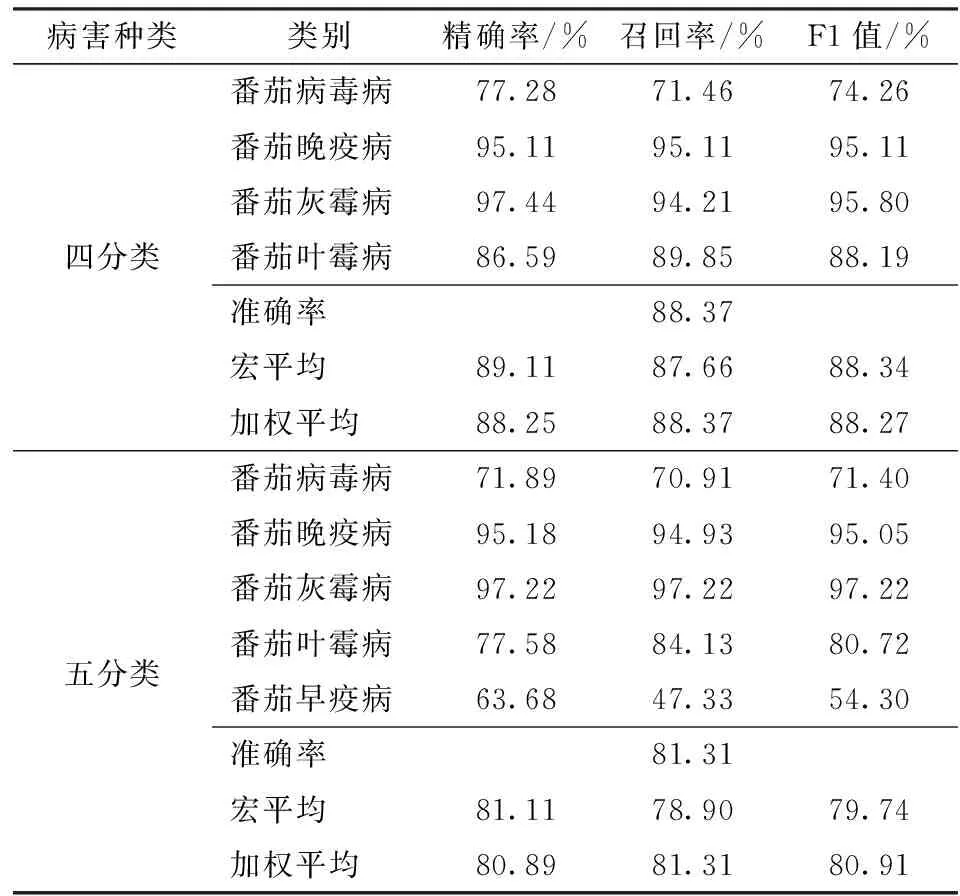
表5 四分类和五分类的实验结果Tab.5 Experimental results of four-class classification and five-class classification
3 Android客户端构建与应用
3.1 设计目标
为研究和掌握作物多种病害发生的规律和特点,根据处方大数据分析总结的经验,及时准确为生产者和决策者提供病害预警提示、对症防治、科学用药和辅助决策,结合LightGBM模型,设计适用于普通农户行为习惯、简明方便的“植物健康”APP界面模式。
3.2 结构与功能
针对植物医生-农户诊断服务流程,基于Android系统应用程序开发技术[20],选用Android Studio平台,采用Android MVC设计模式,此模型具有耦合性低的特点,使得View(视图)层和Model(模型)层可以很好地分离,达到解耦的目的,减少模块代码间的相互影响,利于开发人员维护。同时使用轻量级SQLite数据库,实现无服务器、零配置、事务性的SQL数据库引擎,可以按应用程序需求进行静态或动态连接。
根据设计目标,本系统设计了2个主要功能模块,分别是用户功能模块和管理员功能模块(图9)。
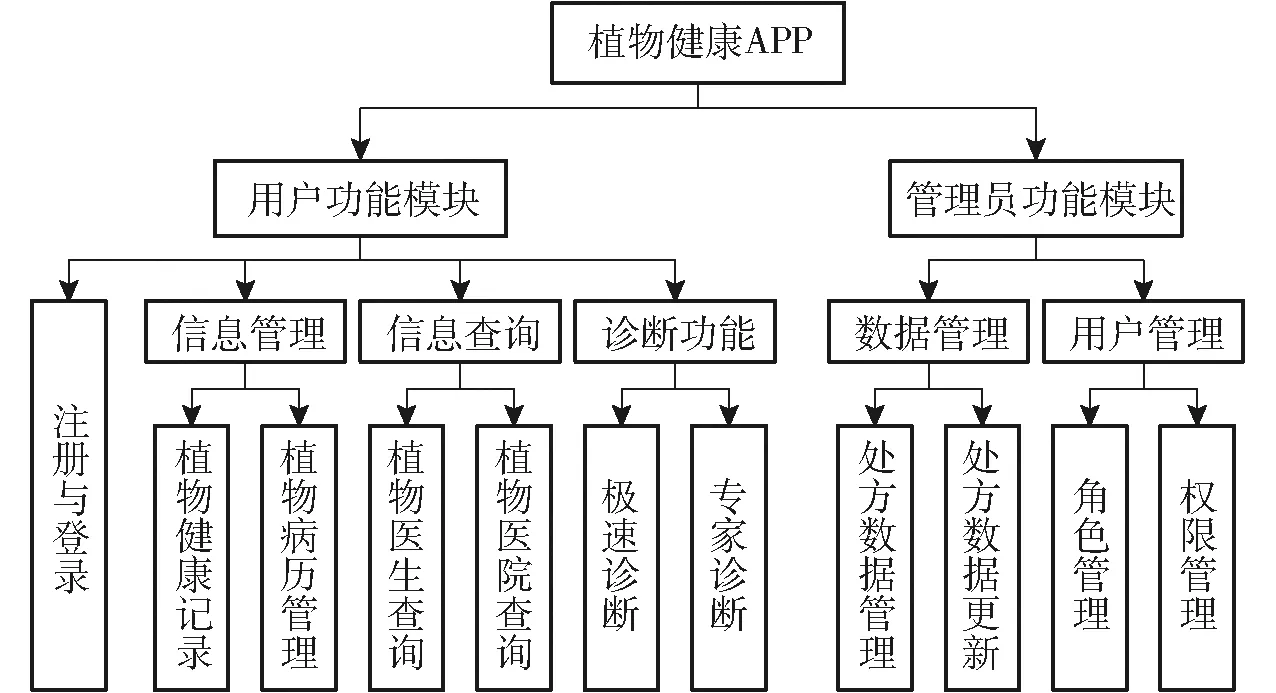
图9 植物病害诊断系统结构与功能图Fig.9 Functional and structure diagram of plant disease diagnosis system
3.2.1用户功能模块
用户功能模块主要包括注册与登录、信息管理(植物健康记录和植物病历管理)、信息查询(植物医生查询和植物医院查询)、诊断功能(极速诊断和专家诊断),图10分别是“植物健康”APP的首页、极速诊断农户填写信息界面和极速诊断结果界面。农户可登录APP首页选择诊断方式,本研究主要应用于极速诊断,对于缺乏病害知识和经验的农户,通过简单填写病害相关信息,可以及时获得基于LightGBM和处方数据的病害诊断模型提供准确的诊断结果。对于处方数据库中不存在的特殊疾病特征,此APP还提供在线专家解答,农户与专家的问答结果和处方过程中产生的数据也将作为快速诊断新的处方数据库。
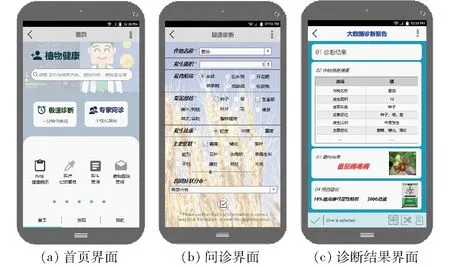
图10 “植物健康”APP手机端系统相关功能界面Fig.10 Related function interfaces of “Plant Health” APP mobile terminal system
3.2.2管理员功能模块
管理员功能模块包括数据管理(处方数据管理和处方数据更新)和用户管理(角色管理和权限管理)等基本功能。
4 结论
(1)以RFECV和GDBT结合的方法对番茄病害的关键特征进行选择,最终原始的50个特征简化为32个特征,作为番茄病害诊断模型的输入。实验结果表明特征选择前后每个模型运行时间平均降低20.37%,其中基于贝叶斯优化的LightGBM模型在保证准确率的基础上运行时间降低了47.73%。
(2)相比于KNN、DT、SVM、RF、GDBT、AdaBoost、XGBoost 7种常见机器学习方法,构建的基于LightGBM的番茄病害诊断模型分类性能最佳,平均高于其它模型3.65个百分点,综合准确率达到89.34%,对于番茄病毒病诊断效果最佳,精确率和召回率分别达到97.27%和94.80%,同时F1值可达到96.02%。最后通过番茄叶霉病和番茄早疫病2种番茄病害验证了该模型的实用性和泛化能力。本研究提出的模型可以满足农户对于番茄病害诊断的实际需求。
(3)结合基于LightGBM的番茄病害诊断模型,本研究构建了“植物健康”APP手机端系统,可视化展现了作物病害处方数据挖掘及诊断的实际应用场景,为实现基于处方数据的高效番茄病害诊断提供了新方法。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
恋爱婚姻家庭·养生版(2018年10期)2018-10-26
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
祝您健康(2000年4期)2000-12-30
