
大数据在英语成绩可视化中的应用
2022-11-08 04:53廖志平
中国新技术新产品 2022年15期
廖志平
(湖南环境生物职业技术学院,湖南 衡阳 421005)
0 引言
大数据技术的发展使互联网的应用范围不断扩大,论文重查、物流配送、电商平台以及喜好推荐等许多传统行业都在利用大数据工具和技术开辟新市场。在大数据技术的帮助下,商家们可以更好地进行消费决策,同时也可以准确地预测出商品的销售量和销路,进而使整个行业的供求关系得到改善。
1 大数据开发需求分析
1.1 前后端框架
SpringBoot不能彻底取代Spring,而是将Spring的框架整合到一起,使它成为一个对开发者来说更方便的开发工具。该软件已经集成了很多第三方的资源库,在使用时只要简单地进行引入,无须经常进行其他的整合。
Ajax在Web服务器和Browser间进行异步的数据传送,而Web页面则需要从服务器方获取本地资料,这样可以让Web软件变得更小巧、更友好。Ajax也可以作为一个跨领域的链接,用于调整后端的前页。
MyBatis是一个基于Java的很好的持久的架构,它可以在以后的应用中存储和调用。MyBatis架构也可以在自定义数据库、存储等问题上做出出色的安排,基于MyBatis的实际应用和其本身的特性,通常将其分为3层:API接口层、数据处理层和底层支持层。
1.2 需求分析
该数据的采集过程包括数据爬取、数据清洗、数据分析和数据展示。数据挖掘技术是通过scrapy从一个特定的页面中得到一个完整的页面,再通过BS4的框架提取出该页面的主题和标记;数据清理就是对所采集到的数据进行初步加工、整理,剔除不合格的数据;数据处理是利用已有的Spark运算符对已洗数据进行求和、求平均等运算,将获得的最终结果存储在一个数据库中;数据显示部分使用SpringBoot架构,通过控制层、服务层和数据层对数据进行数据访问,并对数据进行可视性回馈。该体系的数据流图如图1所示。

图1 数据流图
2 系统总体设计
2.1 系统架构设计
系统架构设计如图2所示,该体系结构由控制层、服务层和数据层构成。
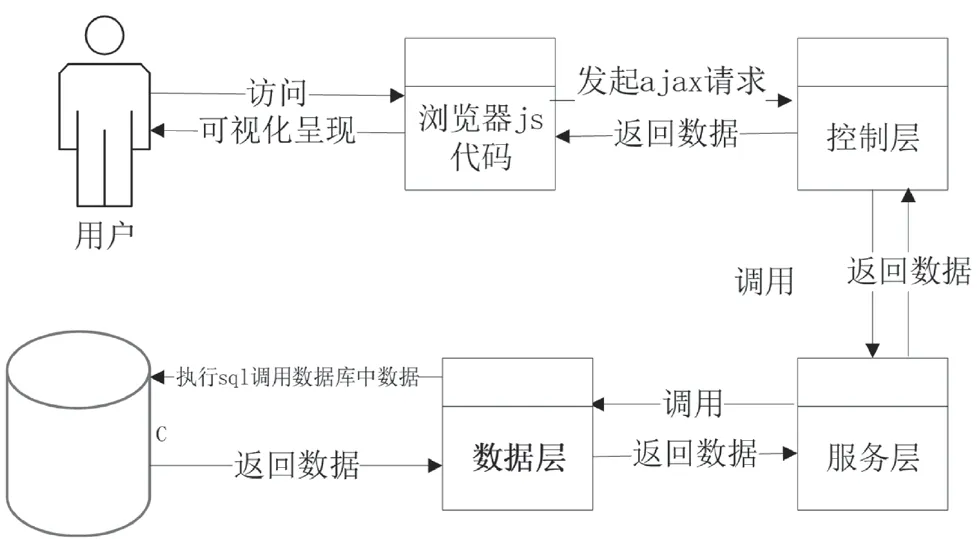
图2 系统架构设计图
这3个层次的区分使整个体系的体系设计更清晰。服务级可以利用SQL语句来抽取数据库中的数据,将这些数据保存在可视化的Data领域,然后将这些数据传输到VIP层,再将其反馈到VIP级,可以帮助系统的发展。在整个体系结构的框架下,可以进行完善的大学级的体系结构。整个体系结构的完善程度直接关系到整个体系结构的可变性和可扩展性。
2.2 数据爬虫
该平台采用Python爬虫,在“'./data/2020年9月大学英语六级成绩.xls'”“'./data/2021年6月份英语六级成绩数据.xls'”等搜索英语成绩信息,因此该系统的主要目的是为了获得更多的信息。但是经过检测,由于页面本身存在防扒的特性,如果频繁地进行大规模的爬行,很容易造成IP被封锁,因此在进行数据攀爬时,不能一次或多次地进行海量的数据访问。
3 大数据在英语中的应用
3.1 随机森林算法在英语中的应用
随机森林构建思想解决了原先单决策树存在的过拟合和非全局最优解的缺陷,体现随机性,该算法利用训练集和特征变量的随机性进行英语成绩分析,N棵树就有N个分类效果。每课决策树之间不相关联,这样在对英语成绩处理时可根据成绩特征区间进行分布。
随机森林算法由(),(),…,h()构成。
边际函数定义,如公式(1)所示。
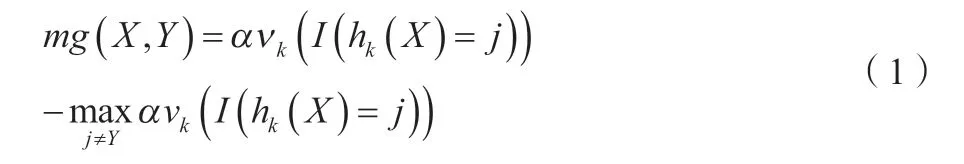
边际函数的概念是指如果分类结果的准确率高于不正确的分类结果,则获得的数量更多,则表明该方法有效性更高。
泛化误差定义,如公式(2)所示。

式中:、为概率定义空间。
随机森林边缘函数,如公式(3)、公式(4)所示。
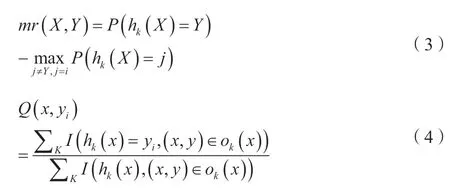
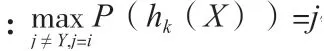
由此可对随机森林强度和相关性进行分析。
随机森林强度定义,如公式(5)所示。

将公式(4)代入公式(5)可得公式(6)。

随机森林相关度定义,如公式(7)所示。

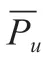


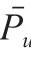

随机森林的特性主要表现为收敛程度、强度以及相关程度。它的收敛性是由于所有的概率分布都是收敛的,并且都是有极限的,因此就意味着它对未知的东西有很强的适应能力,而且不会产生太大的错误。
数据预处理,在数据预处理方面,采用“pandas+Matplot lib+seaborn+sklearn”等工具,该文采用了python的pandas库与numpy库进行协同的过滤操作。从多个角度对大学本科院校四、六级的数据进行了多个维度的统计和分析,揭示了目前大学英语的发展状况,为英语教学的改革做了细致的剖析。其操作如下。
df_202009_six = pd.read_excel('./data/2020年9月大学英语六级成绩.xls')
df_202009_four = pd.read_excel('./data/2020年9月大学英语四级成绩.xls')
df_202012_six = pd.read_excel('./data/2020年12月份六级成绩.xls')
df_202012_four = pd.read_excel('./data/2020年12月 份四级成绩.xls')
df_202106_six = pd.read_excel(w1'./data/2021年6月份英语六级成绩数据.xls')
df_202106_four = pd.read_excel('./data/2021年6月份英语四级成绩数据.xls')
3.2 英语数据可视化探索分析
在前端,需要处理数据进行查询和可视显示,尽可能使显示的接口更加直观和漂亮。选择SpringBoot进行前端架构的构建,其总体架构与SpringMVC相似,通过网页启动Ajax,通过逐层的访问控制层、服务层和数据层来实现数据的可视性。可视化的演示模式来源于Echarts的正式的说明,它拥有更多的互动和互动。
而后端则负责处理数据的攀爬与存贮,是整个分析体系的关键所在。使用scrapy和bs4中的BeautifulSoup架构进行了爬行。这2种结构都很方便,也很好地理解了常规规则和Xpath。然后编写Spark算符,将Spark的RDD转换为DataFrame,以便在SQL基础上进行数据格式的解析和运算。将数据写入MySQL数据库,并将其存储在数据表格中。作为一个数据解析的平台,为了确保数据的准确性,管理者必须定期对站点的结构和信息进行更新。
数据抓取:目前该文所使用的是一种爬行算法,其具体的算法是以Beautiful Soup为基础。HTML/XML是一种用Python语言写成的HTML/XML,它能处理不规则的标签,产生解析树。并通过随机森林算法进行成绩分类,可以方便地浏览、搜索和修改配置目录。该方法无须编写规则运算即可轻松抽取网络中的数据,快速给使用者提供各种分析方法。
寻找数据:确定好了数据区域是中间的部分,进行数据爬取。
抓取数据:抓取数据用到了urllib.request库,解析html用到了BeautifulSoup库。
应用随机森林算法对英语成绩样本进行分析,并可以选择对象的不同的特征将其划分为多个子集合,这样就可以对新的对象进行属性划分。
从分析中可以看出外国语学院通过率高,这主要源于学习内容与习惯,英语学习越多通过率越高,另外体育学院最低,主要原因在于平时学习较少,大多是体育训练,导致英语学习比重降低。
界面代码设置如下。


可根据所获取数据创建英语四级中阅读、听力、写作与总分之间的线性回归分析,大数据分析应用在英语中可使使用者尽快了解成绩以及学生详情,能够更好地帮助英语学习。在Hist表格上,系统会输出相应的数据让使用者看到。在Python上运行时,系统将会通过随机森林算法进行成绩分类,并由系统处理生产线性回归分析图,由该图可知,无论是总分、听力、阅读还是写作,分数集中位置都在中间,这与学生能力相关。
界面代码设置如下。

4 结语
该文主要从数据爬取、数据预处理、数据分析和可视化4个部分来研究“大数据在英语教学中的应用”的设计和实施。该数据解析体系由SpringBoot框架与数据库、爬虫和Spark结合在一起实现。重点阐述了决策树和随机森林在英语成绩分析中的应用及其算法,并对它的特性和优点进行了详细的论述。在系统的开发初期对系统的要求与可行性进行了细致的研究,并根据实际情况分析了随机森林算法在英语中的应用、大数据处理以及数据分析的具体实现,可为英语学习提供有效帮助。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
汽车工程(2021年12期)2021-03-08
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
电信科学(2017年6期)2017-07-01
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
海军航空大学学报(2015年1期)2015-11-11
