
基于ON-LSTM的业务过程模型深度自动生成
2022-11-07 04:27吕昌龙何亚辉张存明陈晔婷
计算机集成制造系统 2022年10期
朱 锐,吕昌龙,李 彤,何亚辉,刘 航,张存明,陈晔婷
(1.云南大学 软件学院,云南 昆明 650091;2.云南省软件工程重点实验室,云南 昆明 650091;3.云南农业大学 大数据学院,云南 昆明 650201;4.云南师范大学 经济与管理学院,云南 昆明 650091)
1 问题的提出
业务过程管理(Business Process Management, BPM)能够显著节约成本,提高生产力[1],是提高客户对企业满意度的关键[2]。在BPM生命周期,业务过程模型在重设计和配置/实现阶段扮演了重要的角色[1]。目前大部分企业在组织管理、产品设计、生产装备、产品研发等方面都蕴含大量的业务过程[3],例如,中国北车集团在控制产品实施的过程模型库中存储了20多万个过程模型[4];澳洲Suncorp银行有6 000多个过程模型[4]。业务过程是企业的私有财产,面对海量数据,人为建立过程模型愈发困难。当前学者主要通过过程挖掘方法获取业务过程模型[5],过程挖掘方法虽然通过事件日志提取过程相关信息取得了巨大成功[6],但是仍然面临一些挑战,主要表现为对日志的严重依赖[6]。过程挖掘方法获取业务过程严重依赖PAIS(process-aware information systems)系统产生的日志,如果日志缺失,则无法实施过程挖掘方法。因此,日志缺失时如何发现业务过程模型受到越来越多的关注[7]。
研究发现,大约85%的信息采用非结构化或结构化程度很低的形式存储[7],尤其是作为文本文档存储,对于难以理解的诸如业务流程建模标注(Business Process Modeling Notation, BPMN)语言或Petri网之类的形式描述的过程通常有详细的文字描述,主要通过文本详细描述业务工程模型,帮助公司工作人员更好地理解过程。因此,有学者提出从业务过程描述文本中自动发现业务过程的方法,以帮助分析人员短时间内从大量文档中创建更好的模型[8-14]。
FRIEDRICH等[15]指出在BPM项目中获取初始流程模型需要花费总时间的60%;HAN等[16]指出从文本中自动发现业务过程可以减少40%的时间成本;FRIEDRICH等[16]、Ferreira等[17]、De Ar Goncalves等[18]指出,过程的自动生成可以最大限度地减少过程分析时间。发现文本描述中蕴含的业务过程,对于有效支持过程工程师理解过程模型并指导重新设计过程模型,以及发现实际的过程模型、辅助重新开发、支持模型驱动的过程模型自演化和软件再工程,具有重要的意义。
神经机器学习领域的最新发现表明,句子中不同单词之间的层次结构可以通过距离来捕获,而不同单词之间层次结构的距离可以通过建模捕获[9]。作为代表性的网络之一,有序神经长短期记忆网络(Ordered Neurons Long Short Term Memory, ON-LSTM)[9]已被证明在语言建模方面表现较好。除此之外,自然语言处理领域的研究表明,命名实体识别模型可以识别句子中的单词和单词序列信息[7]。
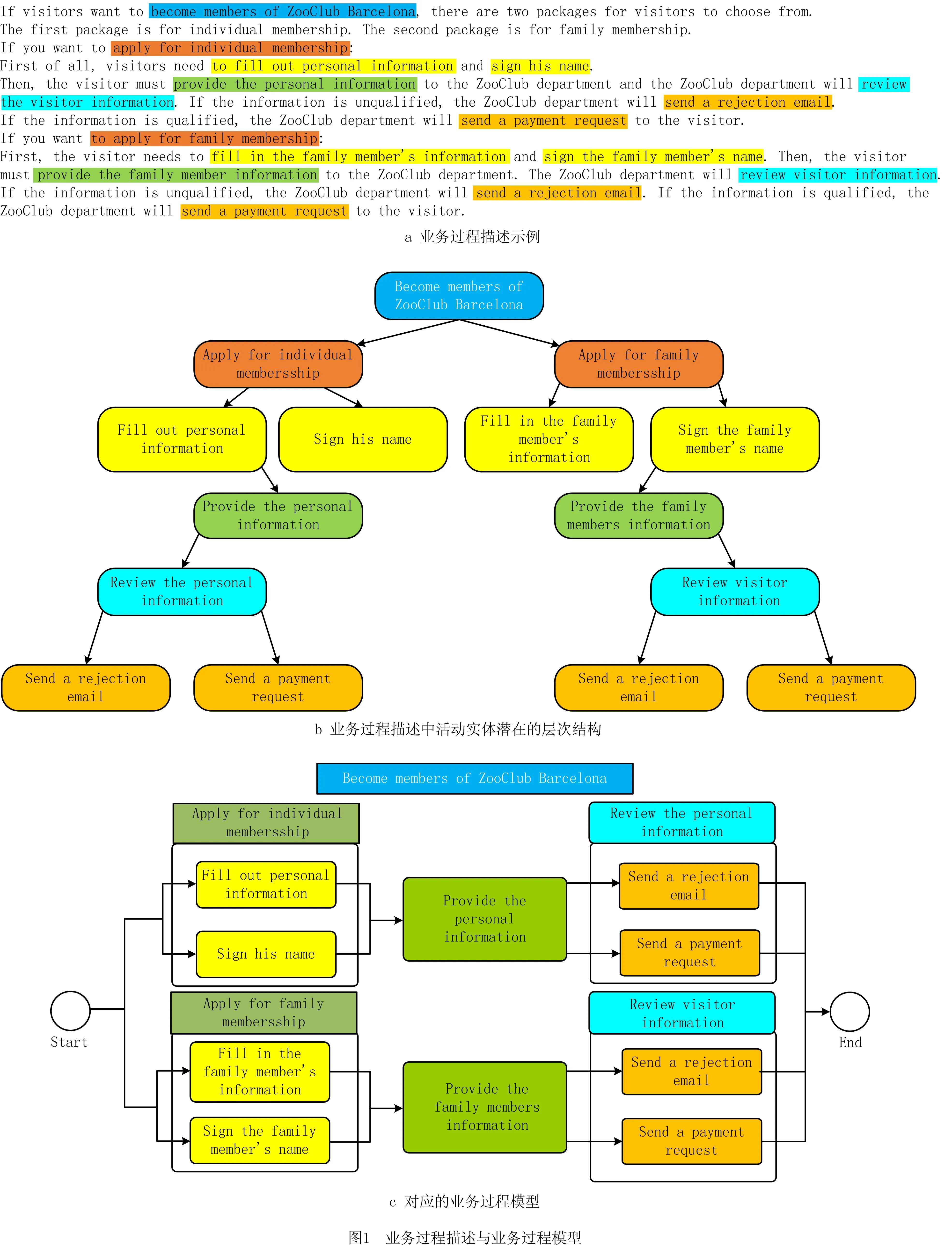
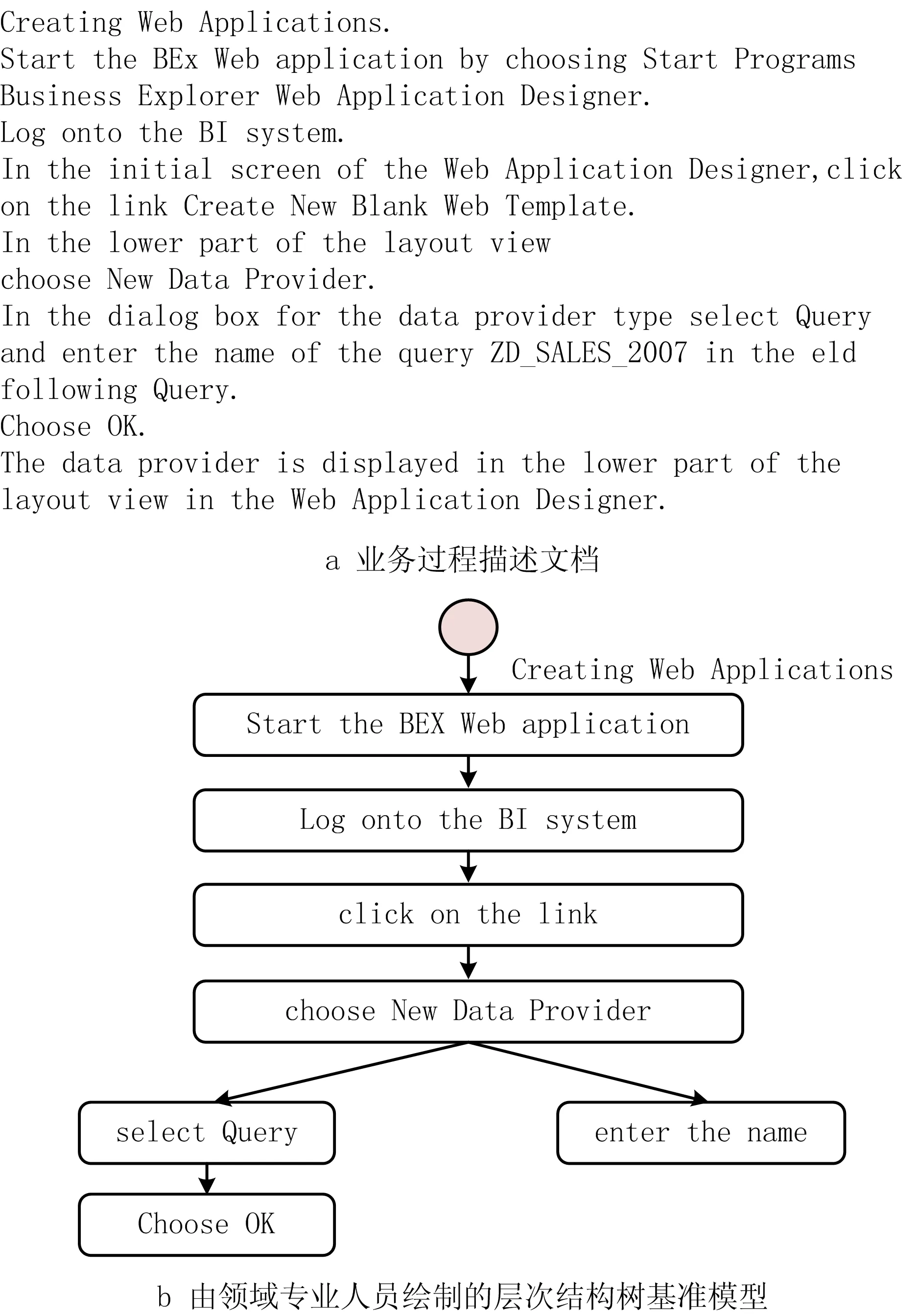
图1所示为业务过程描述和业务过程模型,可见活动实体在业务过程文本描述中存在潜在的层次结构,该层次结构定义了活动实体在业务过程模型中发生的先后顺序,以显示业务过程并反映复杂的逻辑关系。图1a是一个业务过程描述,其详细描述了业务过程模型的逻辑结构。图1b中每一个节点为一个活动实体,其中根节点为父进程,用于指导其他节点;子句是对父进程的详细描述。这种潜在的层次结构也反映在相应的业务过程模型中,如图1c所示。
本文首先对现有命名实体方法进行改进,以业务过程描述为输入,通过BERT(bidirectional encoder representation from transformers)、双向长短期记忆(Bi-directional Long Short Term Memory, BiLSTM)模型、条件随机场(Conditional Random Fields, CRF)构建命名实体识别模型,提出面向业务过程的活动实体识别方法,旨在识别如图1a所示的业务过程描述中的活动实体;其次将语言模型从句子级别扩展到文档级别,提出一种通过递归体系结构ON-LSTM无监督地发现过程描述文档中所蕴含活动实体间潜在的层次结构;最后通过活动实体的层次深度原则,将层次结构树转化为业务过程模型。通过识别解析150个SAP产品用户指南文本并与领域专业人员绘制的基准模型对比,本文方法可以正确识别业务过程描述中88.5%的活动实体,生成整个BPMN过程模型的准确率达到73.2%,为日志缺失时业务过程发现提供了一种新的思路。
本文的主要贡献概括如下:
(1)提出一个新颖的从业务过程文本描述中自动提取业务过程模型的深度学习框架,该框架针对开放、动态、不确定环境下的业务过程模型自动生成问题,构建了端到端的业务过程模型自动生成方法,该方法以业务过程文本描述为输入得到业务过程模型,为在日志缺失而无法使用过程挖掘方法时提供了一种新的思路。
(2)从业务过程描述中提取结构化过程的研究仍处于早期,目前网上尚无开源数据集。本文通过将人工采集与标注的150个真实SAP产品用户指南文本作为训练数据进行实验,将命名实体识别模型迁移到对活动实体的识别,弥补了当前领域由于缺乏此类数据集导致不能进行实验的空缺。
2 相关工作
针对业务过程发现中存在的问题,有研究人员提出自动发现业务过程模型的方法,以帮助分析人员在更短的时间内从大量文档中创建更好的模型[18]。虽然从文本自动提取过程的研究处于早期发展阶段[20],但是仍有很多学者针对这一问题提出不同方法从文本中提取流程[8,9,11,21-28],现有方法大致分为3类:
(1)依赖信号词列表和规则的方法[25,27]通过解析句子的结构和语法得到句子活动、任务、模式等信息,再通过定义的规则将信息映射到业务过程模型。比较具有代表性的为EPURE等[27]提出的TextProcessMiner方法,该方法以考古学过程描述作为输入,删除不必要的标点和短语,采用Stanford解析器以及Stanford和NLTK标记器的组合生成语法树,识别出句子中包含的动词,并默认相连的两个活动之间的关系为顺序关系。为了识别活动之间的关系,基于识别的活动和关键字模式,TextProcessMiner定义了一系列复杂的规则来确定动词和动词之间的关系,逐句分析文本,构建业务过程模型。该方法虽然在一定程度上识别活动间的关系,但是规则过于复杂且难度较大。
(2)采用具有中间表示方法的两步转换方法[21,28]该方法第1步将过程元素标识在文本中并存储在文本框中进行结构化表示,第2步从结构化表示生成相应的过程模型。FERREIRA等[21]提出一种半自动方法来识别自然语言文本中的过程元素,该方法首先从句子中提取参与者进行句法分析,得到一个主语—谓语—宾语结构用于生成中间过程模型,在得到主语—谓语—宾语结构基础上,从文本中搜索是否包含条件、并发、先后等顺序,并将结果表示为基于电子表格的过程描述,每行表示一个阶段,最后将其转化成BPMN过程。由于这种方法缺乏衡量各种错误的指标,无法同时为每种类型的错误分配不同的权重,将其用于判断所提议系统质量的指标存在局限性。
(3)通过神经网络建立过程描述与其形式表示之间的直接映射方法[16]比较具有代表性的为HAN等[16]提出的一种基于树的模式查询语言提取描述关键过程元素的注释模型A-BPS(automatic business process service),其不需要任何人工标记即可通过神经网络检索到过程文档中潜在的层次结构。HAN等以文档为输入,在句法树的基础上将编码器扩展到文档级别,得到句子的向量表示,然后采用过程级语言模型目标的神经网络ON-LSTM检索出句子在文本中的层次结构,并用树状图表示,结构树中的每个节点代表一个句子。实验表明,A-BPS模型生成BPMN的准确率达到32%,该模型以检索句子在文档中的层次结构为目标,并默认一个句子中只含有一个活动,而实际上,业务过程文本描述的一个句子很可能包含多个活动。
除此之外,还有学者提出一些假设,由于未通过实验验证[11,20],无法进行实际分析。
综上所述,自动获取业务过程模型受到广大学者的普遍关注,然而相关研究仍处于起步阶段。相比前两类方法,第3类方法不用任何人工标记即可通过神经网络检索到过程句子在文档中潜在的层次结构,也无需人为制定语法规则。本文所提方法与第3类方法类似,均基于ON-LSTM检索文档潜在的层次结构,但是在具体实现上不同。本文将自然语言处理的实体识别技术与深度有序神经网络有机融合,将业务过程描述作为输入,提出面向业务过程的活动实体识别方法来识别业务过程描述中的活动实体,有效避免了业务过程描述中冗余、无用、重复信息对业务过程模型的影响;在此基础上,将语言模型扩展到文档级,通过ON-LSTM无监督地发现过程描述文档中所蕴含活动实体间潜在的层次结构;最后通过活动实体的层次深度原则,将层次结构树转化为业务过程模型。特别地,本文方法不需要复杂的过程编码器,具有模型时间和空间复杂度更低、速度更快的特点。
3 总体框架
本文所提基于有序深度神经网络的业务过程自动生成模型总体架构如图2所示,模型包括面向业务过程模型的活动实体识别和过程层次结构解析两部分。
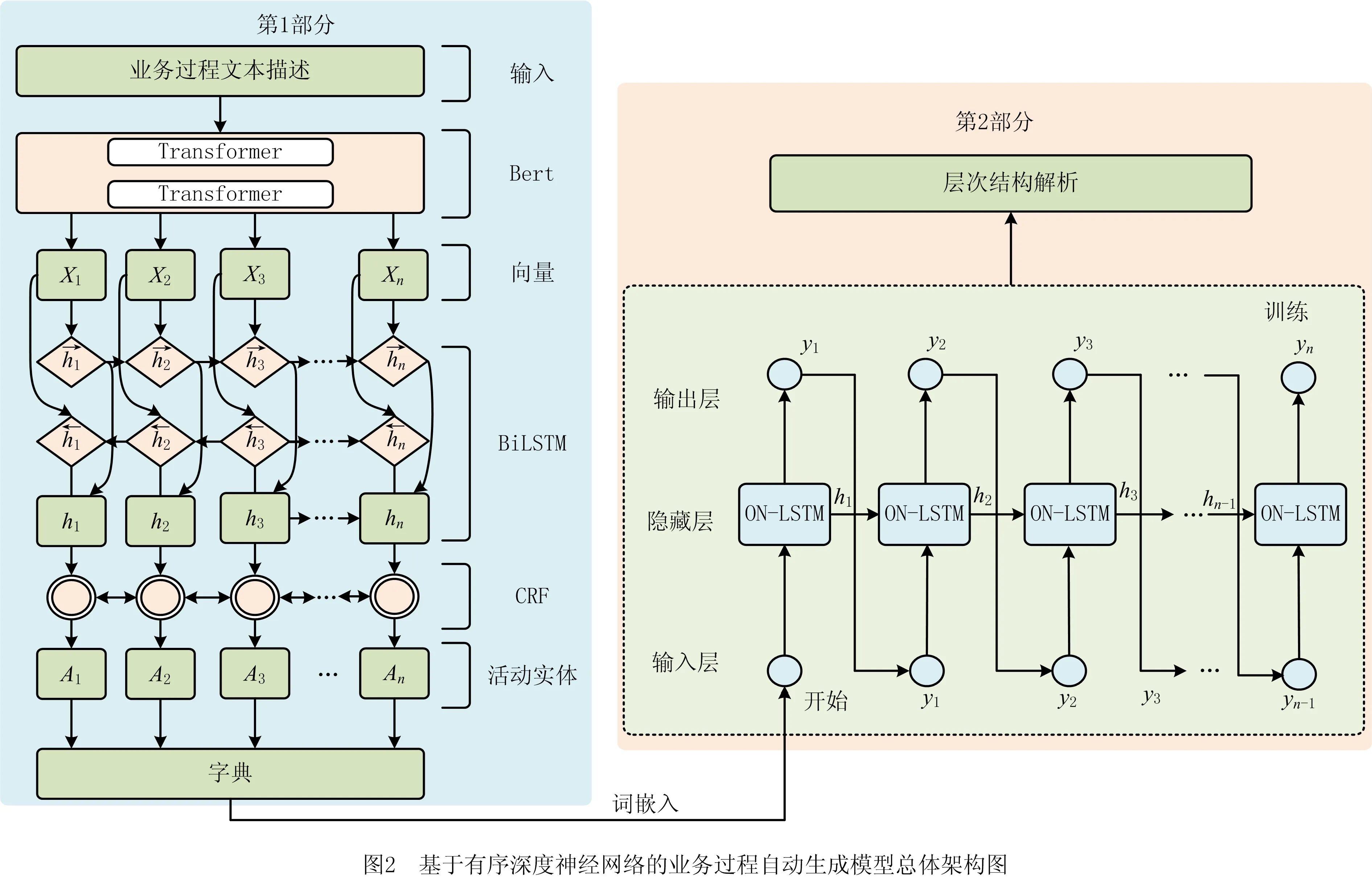
为发现自然语言文本中实体间的层次结构,需要识别业务过程文本描述中所蕴含的活动实体。本文对现有命名实体识别方法进行改进,提出面向业务过程的活动实体识别方法,将命名实体识别对象迁移到活动实体。面向业务过程模型的活动实体识别模型由BERT,BiLSTM,CRF 3个模块组成,其以业务过程文本描述文档为输入,以经领域专业人员标注的活动实体为输出。首先采用BERT预训练模型获得业务过程文本描述的词向量表示,然后将得到的词向量作为BiLSTM的输入进行进一步处理。最后用CRF对BiLSTM的输出进行解码得到一个预测序列,根据预测序列建立实体级别的词典。
以第1部分面向业务过程模型的活动实体识别模型的输出构建词典,并在构建的词典基础上采用过程层次结构解析方法。过程层次结构解析方法包括一个3层ON-LSTM网络和一个结构检索组件,旨在检索业务过程描述文档中活动实体的层次结构。首先,基于实体级别的字典获得活动实体的向量表示训练过程级语言模型,将相邻的两个活动实体视为一个活动实体对,最大化两个相邻活动实体之间的联系;其次,保存训练好的模型,以同一个文档中的活动实体为输入,通过训练好的模型检索不同活动实体之间的距离;最后,采用贪心算法自顶向下解析活动实体之间蕴含的层次结构。
4 业务过程模型深度自动生成方法
4.1 面向业务过程的活动实体识别
命名实体识别[30]主要用于识别文本中人名、机构名、地名、时间、日期、货币和百分比等。面向业务过程的活动实体识别方法将业务过程描述中的谓语和宾语定义为活动实体(如图3)。专业标注人员用{{activity:}}标注业务过程文本描述中的活动实体,建立识别的中间状态,并将标注过的数据转化为BIO(begin,inside,outside)标注模式(B表示活动实体的第一个词,I表示活动实体的其他词,O表示文档中除活动实体外的所有词),以每一个单词为一行,用BIO中的一个字母标注;然后用BERT,BiLSTM,CRF构建命名实体识别模型;最后BERT预训练模型将获得的数据词向量表示输入BiLSTM[31]进行进一步处理,再用CRF对BiLSTM的输出进行解码,得到一个预测序列,完成实体抽取流程。

经过标注的数据用BERT编码,该编码器通过句子中词与词之间的关联程度获取词的表征,即
(1)
式中:Q,K,V为字向量矩阵;dk为词嵌入的维度,本文均采用BERT[32]中的默认值。采用BERT提取词向量,然后通过BiLSTM[31]深度学习上下文特征信息,得到输出
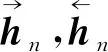
(2)
最后通过CRF解码,得到最大分数的输出序列
(3)
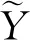
4.2 过程层次结构解析
自然语言是分层的[19],即较小的单元(如短语)嵌套在较大的单元(如从句)中,较大的单元对较小的单元具有指导意义。ON-LSTM对神经元进行排序,通过位置的前后关系表示信息层级的高低。在更新神经元时,先分别预测历史的层级和输入的层级,用这两个层级分区间更新神经元。在更新过程中,高层级的信息尽可能地保留长距离,低层级的信息可能会被随时更新。因此,高层级信息跨度大,低层级信息跨度小,通过不同信息的跨度即可得到不同输入在神经网络中保留的距离。本文以活动实体为输入,通过活动实体之间的距离检索不同活动实体之间的层次结构。
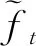
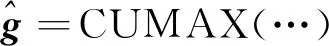
=CUMAX(softmax(…)),
(4)
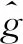
(5)
(6)
本文将编码器扩展到实体级别,根据命名实体识别模型从文档中识别的实体创建一个实体级别的字典,从而获得实体的向量表示。采用文献[32]的方法,将相邻实体视为一个实体对,用于学习标准实体对,旨在最大化相连两个活动实体对之间的联系。活动实体之间的距离检索函数定义为
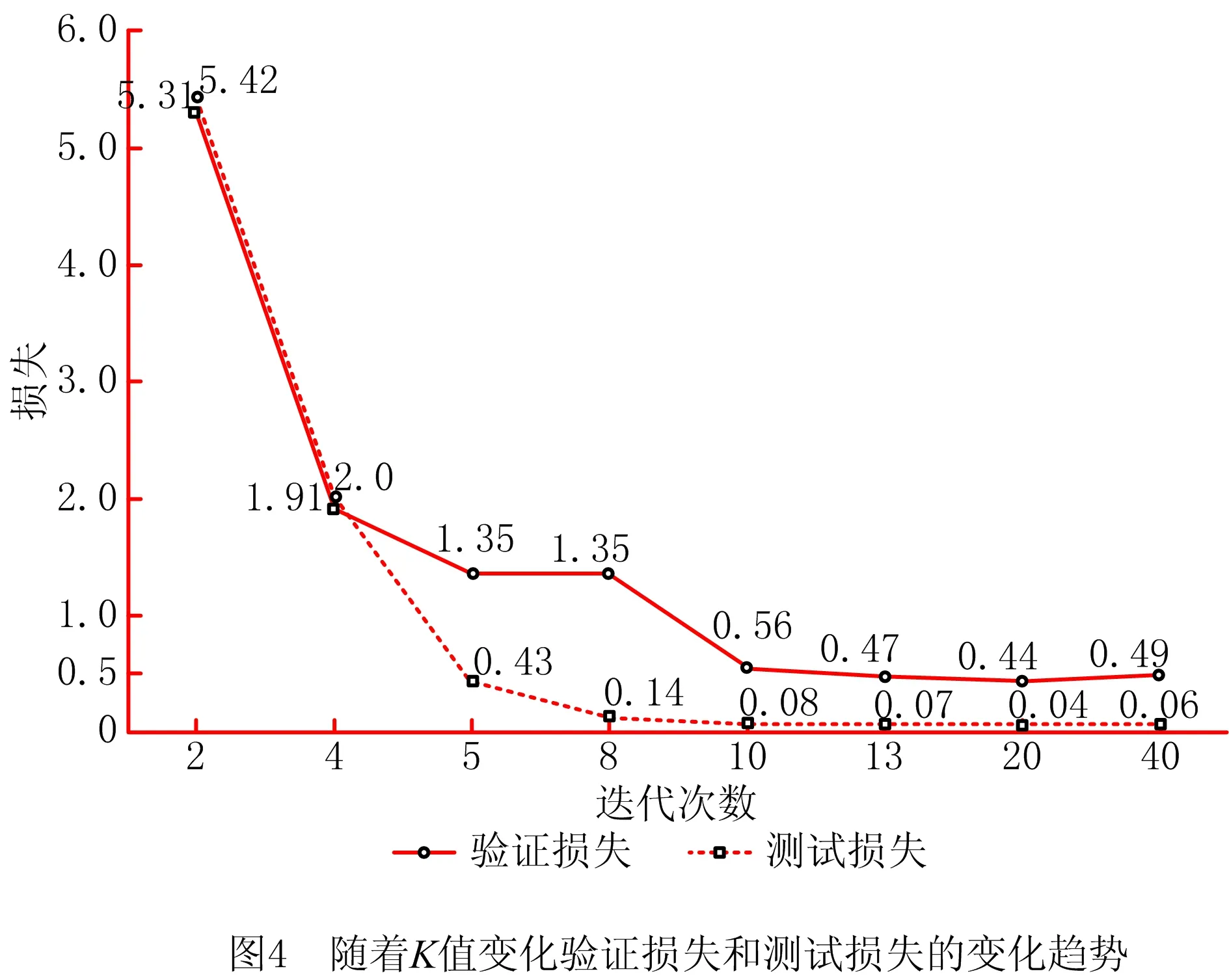
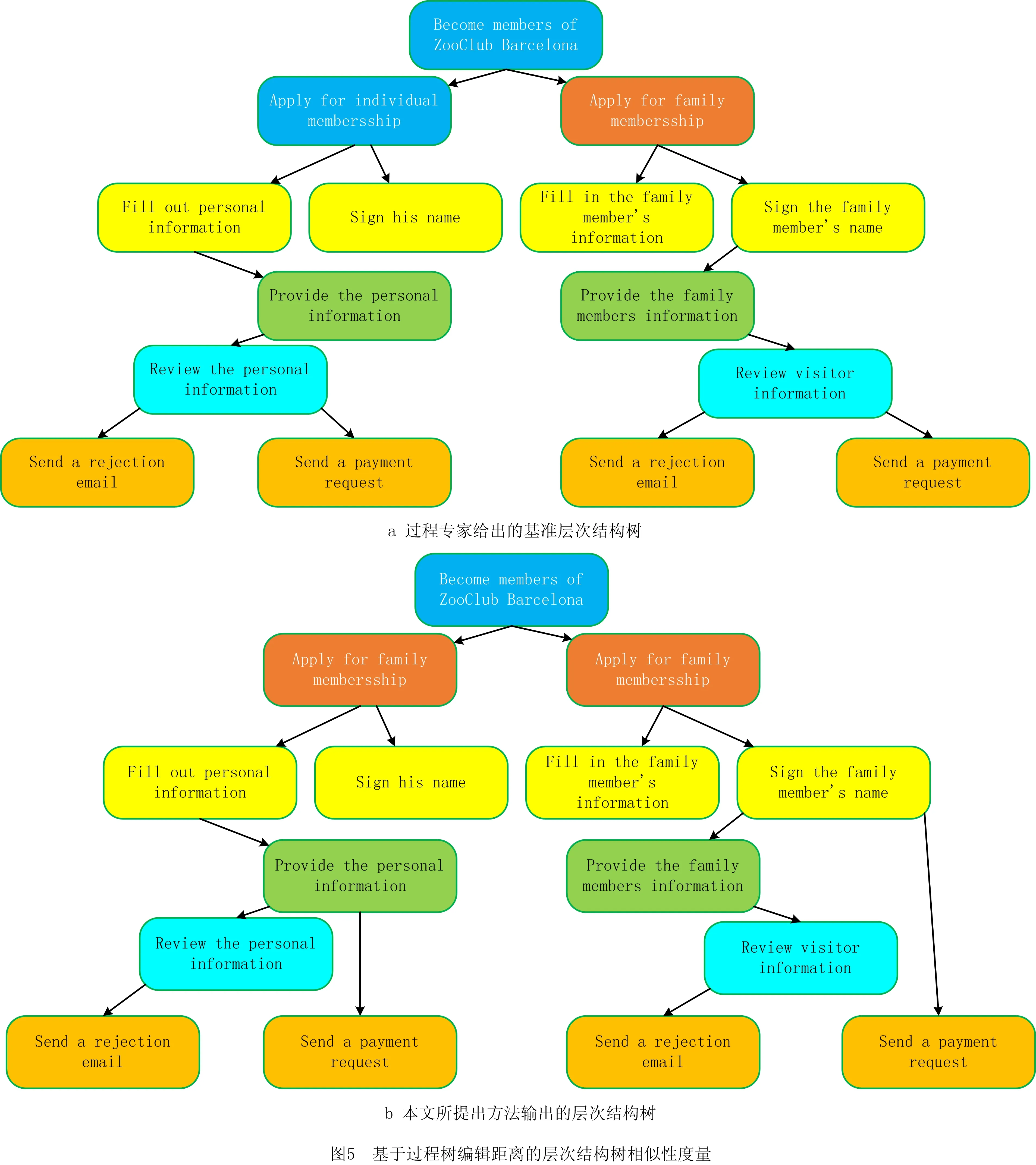
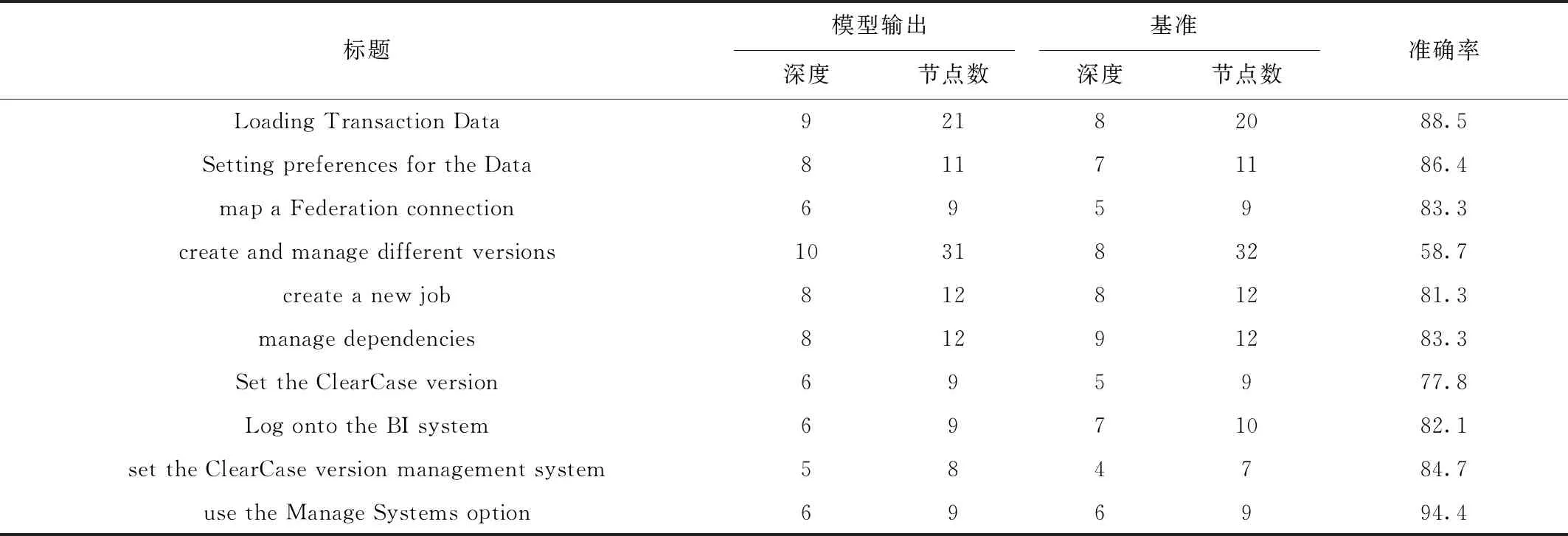
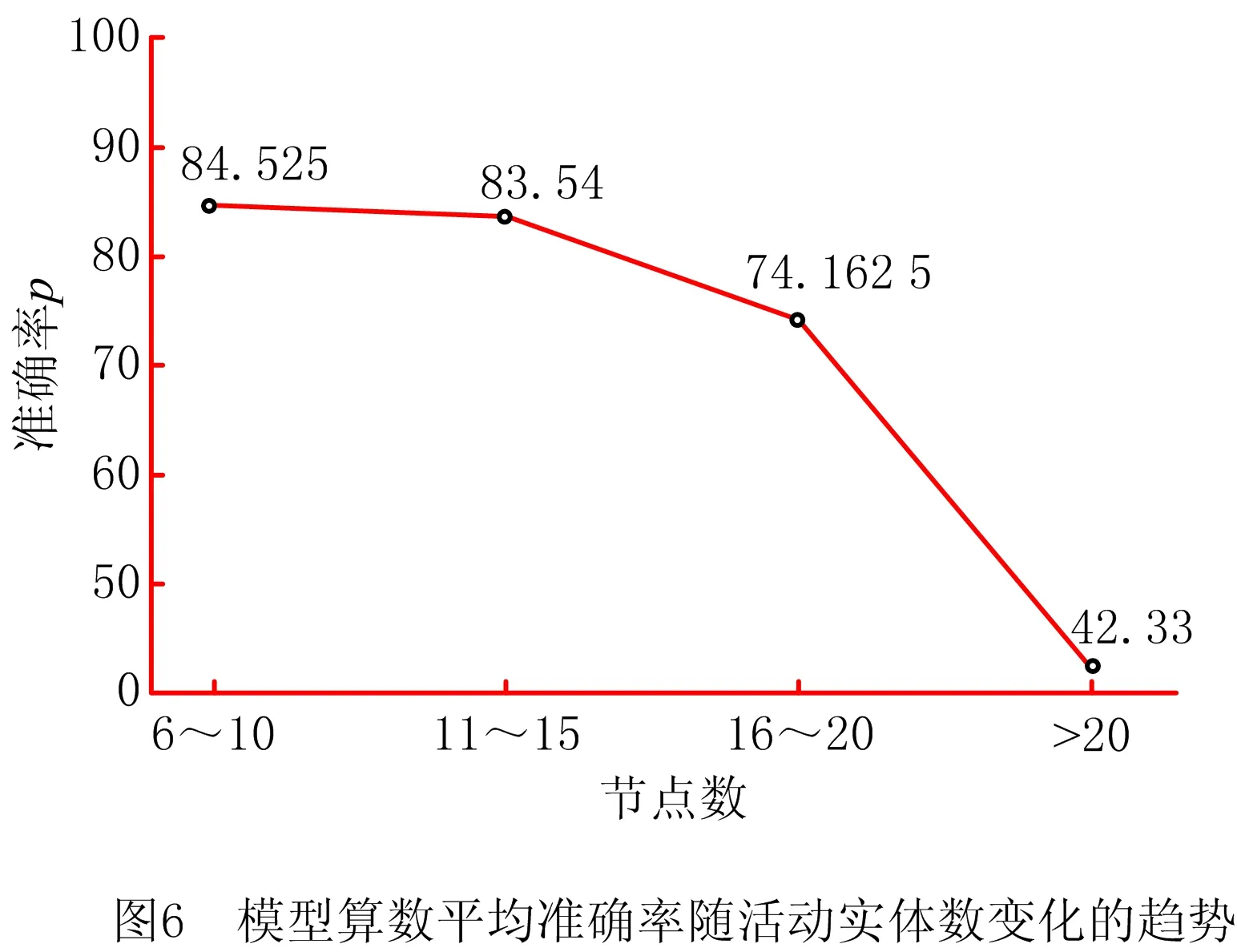
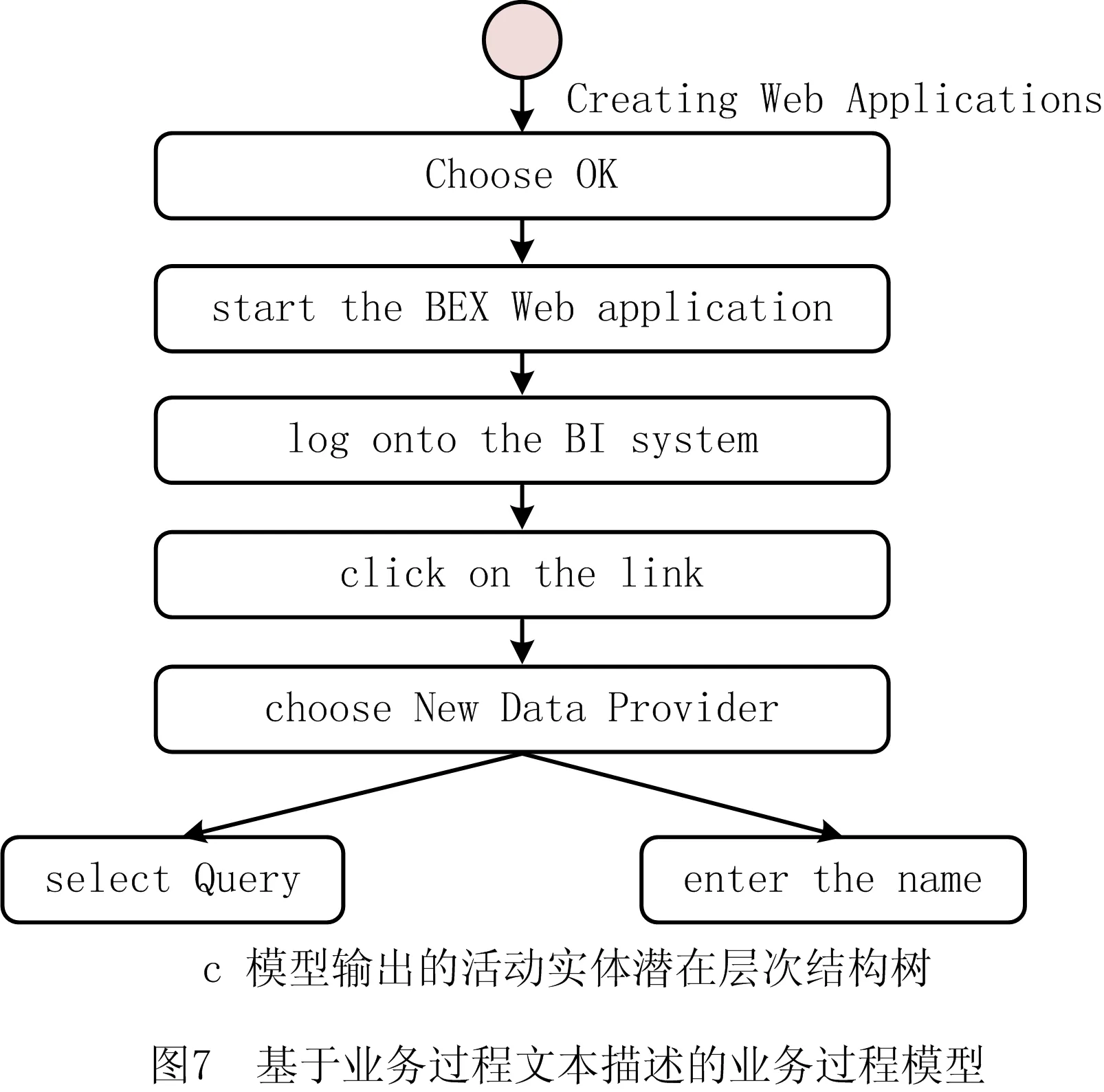
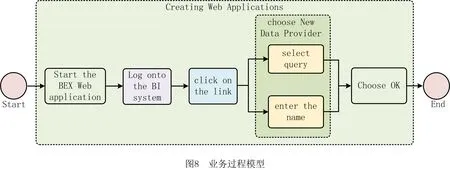
L=∑LlogP(WLi|WL, (7) 表1所示为过程层次结构解析中重要符号的解释,其中AL-1为活动实体集中第L-1个实体,WLi为活动实体AL中第i个单词,WL, (8) 将通过贪婪算法解析出的不同实体之间的层次结构转化为层次结构树(如图1b),设a1,a2,a3,…,an(n>1)为n个在层次结构树中深度相同的活动实体,则a在业务过程模型中的优先级相同,发生顺序不分先后。设a1,a2,a3,…,an(n>1)在层次结构树中同时为ai节点的孩子,则a1,a2,a3,…,an被视为ai的嵌套。例如图1b和图1c中的活动实体Fill out personal information和Sign his name被称为活动实体Apply for individual membersship的嵌套。 表1 重要符号 目前网络上尚无开源的业务过程描述数据,因此本文所需数据均由人工手动获取。本文的实验数据来源于SAP,该公司是全球最大的企业管理和协同化商务解决方案供应商、世界第三大独立软件供应商、全球第二大云公司,SAP官方网站提供了大量描述软件使用方法的业务过程文本描述,其数据能够支持对模型发现算法、融合算法的研究;SAP官方网站提供的大量开源数据能够用于解决深度优化算法中需要大量训练数据的问题。因此,所拥有的实验数据集已经覆盖本文研究,并具有较强说服力。 本文从SAP网站手动获取了150个SAP创建、定义和操作软件产品的过程模型文档,其中包括对过程模型的详细描述。然而,由于包含大量非相关信息,需要对部分数据进行采集和清洗。前期工作包括对数据进行识别、过滤、抽取等,清洗后的数据删除了大量非相关信息(如方程式、特殊字符等),领域专业人员将数据中的活动实体标注为3个版本,本文择优选择其中一个,数据设置如表2所示。 表2 数据设置 句子平均数=实体数/文档数; (9) 句子平均长度=单词数目/句子数。 (10) 表2表明,本文整理的150个业务过程描述文档包括2 362个活动实体,平均每个文档包括15个句子,句子平均长度为12。其中句子平均数与句子平均长度通过式(9)和式(10)计算。相比深度学习领域所需的数据,150个文档不算很多,然而作为首次从SAP文本中自动生成过程模型方法的探索性工作,本文花费了大量时间采集和标注业务过程文本描述数据。另外,为应对样本量稍显不足的问题,本文采用K折交叉验证的方法极大减弱了数据量少对实验结果的影响。实验结果表明本文方法是可行的,数据量欠缺是影响实验结果的主要原因,如果数据量充足,则模型准确率将有更大提升。 本文所有实验代码均基于PyTorch实现,在模型优化阶段,本文的损失函数采用交叉熵,并选择自适应学习率的Adam作为优化算法。具体参数设定如表3所示,其余参数均采用模型默认参数。 表3 参数设置 自然语言有层次结构[19],较小的单元被嵌套在较大的单元中。SHEN等[19]证明ON-LSTM在语言建模方面具有较高的准确率。业务过程详细描述了活动实体在业务过程模型中的逻辑结构,本文在此基础上将语言模型从句子级别扩展到文档级别,提出一种通过ON-LSTM无监督地检索业务过程文本描述中的不同活动实体层次结构来生成业务过程模型的方法。 本文按4.2节定义的规则标注数据并训练模型。表4所示为本部分内容的重要符号及相关释义。为验证模型的准确性,本文采用经专业人员标注的SAP产品用户指南文本进行实验,将经过领域专业人员标注的数据作为训练集,以业务过程描述作为输入,活动实体作为目标输出。加载训练好的模型,给定一个包含过程描述的文本PD=(S1,S2,S3,S4,…,Sl)作为输入,得到一个包含活动实体的序列集合PA=(A1,A2,A3,A4,…,Al)。以表1中的SAP数据作为训练语料库,利用如前所述的规则标注业务过程文本描述文档并转换为BIO格式进行训练,训练数据和测试数据按8∶2划分,经过30轮训练,得到一个面向业务过程的活动实体识别模型。 表4 重要的符号 本文通过计算精确率Accuracy、召回率Recall和F1值衡量面向业务过程的活动实体识别模型表现,具体如下: (11) (12) (13) 由式(11)~式(13)计算得,面向业务过程的活动实体识别模型的精确率、召回率、F1值分别为80.23%,87.34%,83.64%,实验结果验证了本文标注数据的可信性。在得到命名实体识别输出的活动实体集后,建立一个实体级别的字典,将每个实体视为一个单词进行词嵌入,作为有序神经网络的输入,从而将有序深度神经网络的语言模型扩展到实体级别,作为有序深度神经网络的输入。 由于自动化生成业务过程模型仍处于起步阶段,网络上尚未有公开的数据集,为减小数据量小对实验结果的影响,本文在ON-LSTM的基础上采用K折交叉验证的方法,充分利用所有样本,将数据集随机分为N个子数据集,每次将其中一个作为测试集,其余的N-1个子数据集作为训练集。每次迭代重复N次,使每个子集都有一次机会作为测试集。本文定义N=2,4,6,8,10,13,20,40,分别迭代1 000次,实验结果如图4所示,可见测试损失随着K值的增加不断下降。当N>10时,测试损失和验证损失均在一个稳定的区间内浮动;当N=20时,测试损失达到最小值0.04。验证损失在N<5时也呈下降趋势,在N=5,8时测试损失保持不变,当N>8时测试损失随K值的增大呈下降趋势,在N=20时达到最小值0.44。当N=20时,有序神经网络表现最为优异,因此本文选取N=20时的有序神经网络作为活动实体的层次结构解析模型。训练结束后进入活动实体层次结构解析阶段,为避免不同工业过程文本文档中的活动实体互相影响,每次的输入为从一个工业过程文本文档中抽取的活动实体。首先读取N=20时保存的层次结构解析模型,以工业过程文本文档中抽取的活动实体集为输入,通过模型检索不同活动实体间的距离来无监督解析层次结构。模型按4.2节定义的方法自动检索实体活动之间的层次结构并转化为层次结构树。 如图5所示为基于过程树编辑距离的层次结构树相似性度量方法,本文层次结构树表示活动实体的潜在层次结构。为了准确评估模型的准确性,本文采用文献[34]提出的基于过程树编辑距离的过程模型相似性度量算法度量树的相似度,通过树的相似度衡量模型准确性。图5a为过程专家通过阅读业务过程文本描述绘制的业务过程描述中活动实体潜在的层次结构树,图5b为模型输出的层次结构树,其中将每一个活动实体映射为树中的一个节点。假设业务过程经过程专家绘制的树和模型输出的树分别为T1,T2,则T1,T2之间的过程树编辑距离相似度 (12) 式中:δ(T1,T2)为T1转变为T2的最低开销;|T1|和|T2|为节点数。本文随机选取10个业务过程描述作为输入,分别计算专业人员和模型生成的层次结构树的编辑距离相似度,这里定义增加一个节点的开销为p,删除一个节点的开销为q,p=0.3,q=0.7,结果如表5所示。 表5 编辑距离相似度计算示例 表5中,本文随机选取的10个业务过程文本描述通过模型绘制的层次结构树准确率大部分在80%左右,最高准确率为94.4%,最低准确率为58.7%,平均准确率达到82.04%。除此之外,为观察模型准确率是否与业务过程文本描述中的活动实体数存在关系,本文随机选取40个业务过程文本描述文档,以观察文档中活动实体数与模型准确率之间的关系,其中文档中活动实体数的统计结果如表6所示。 表6 文档活动实体数 本文将实验重复5次,计算5次实验准确率的加权平均值,如图6所示。总体而言,以本文随机选取的40个活动实体为样本,模型总体平均准确率为73.20%。含有6~10个活动实体时,模型准确率可以达到84.53%;含有10~15个活动实体时,模型准确率比含有6~10个活动实体的文档略有下降,准确率为83.54%;在含有16~20个活动实体的文档中,模型准确率达到74.16%,与总体平均准确率相当;当工业过程文本文档中含有的活动实体数超过20个时,准确率下降较为明显,为42.33%。 基于业务过程文本描述的业务过程模型如图7所示。 以名为Creating Web Applications的业务过程描述为输入,业务过程文本描述包括Start the BEx Web application,Log onto the BI system,click on the link,choose New Data Provider,select Query,enter the name,Choose OK 7个活动实体,所有活动实体是对Creating Web Applications的详细描述,被视为Creating Web Applications的子进程。根据4.2节定义,所有活动实体与Creating Web Applications为嵌套关系。除此之外,根据上下文语义,难以识别除活动实体select Query和enter the name外5个活动实体之间的直接关系,因此默认5个活动实体为顺序关系。因为活动实体select Query和enter the name均与Query有关,而且根据语义发现处于同一对话框,所以定义select Query和enter the name层级相同,不分先后关系。基于以上描述绘制的层次结构树如图7b所示,基于图7b生成的业务过程模型如图8所示。 本文提出一种基于命名实体识别模型和有序深度神经网络自动生成业务过程模型的方法,并通过识别解析150个SAP产品用户指南文本,说明本文模型可以正确识别业务过程描述中88.5%的活动实体,生成业务过程模型的准确率达到73.2%,为在日志缺失而无法使用过程挖掘方法时提供了一种新颖且可行的解决方案,具体如下: (1)科学理论角度 本文研究业务过程自动生成的理论和方法,是传统业务过程研究在人工智能时代的自然延伸和融合,可以确保高效、准确地通过业务过程文本描述建立过程模型。最后通过正确性验证保证了过程模型的正确性和可信性。 (2)应用角度 目前生活中的描述通常是一大段文字,这些文字往往复杂且难理解。从应用角度而言,本文提出的面向智能制造的工业过程模型深度生成方法可以对过程工程师重复的工作起到辅助作用,更容易了解工业过程模型并对决策进行修改,显然对企业的管理、决策等具有较大意义。 虽然本文通过实验验证了所提方法的有效性和优越性,但是仍有一些问题和工作需要完善,未来的研究重点如下: (1)数据方面 本文虽然证明了所提方法的有效性和可行性,但是数据量不充足。未来将通过建立数据的采集标注机制来扩展数据量,而且不仅扩展本实验所用的SAP数据,还要通过多个领域数据验证所提方法的健壮性。 (2)方法层面 作为探索性的文章,本文提出一种自动检索文本中活动实体层次结构的方法,然而业务过程模型是一个很复杂的模型结构,不仅有实体,还有人物、时间、地点等主体信息,同时包含并发、判断、选择等逻辑信息。未来将在解析活动实体层次结构的基础上,将主体扩展到人物、时间、地点等,并考虑活动实体之间的并发、选择、判断等逻辑关系。

5 实验
5.1 实验数据

5.2 实验参数设置
5.3 实验过程
5.4 层次结构树准确率的计算与分析

5.5 案例讨论
6 结束语
猜你喜欢
客联(2022年3期)2022-05-31中国新闻周刊(2021年26期)2021-07-27健康之家(2021年19期)2021-05-23医学食疗与健康(2021年27期)2021-05-13农业科技与信息(2021年2期)2021-03-27健康体检与管理(2021年10期)2021-01-03电脑爱好者(2017年7期)2017-05-06科技创新与应用(2017年3期)2017-02-18电脑知识与技术(2016年25期)2016-11-16无线互联科技(2015年11期)2016-03-04
