
多媒体英语听力自动评价系统设计
2022-11-07 10:49王青云
计算机应用与软件 2022年10期
王 青 云
(郑州大学体育学院 河南 郑州 450044)
0 引 言
英语听力作为学习英语语言必须掌握的技能,在提高英语学习者对于口语的发音与应用能力方面具有十分重要的作用,被越来越多的英语语言学习者所重视[1]。传统的英语教学模式是教师通过录音设备来播放录好的英语磁带,这种方式随着教学体制的改革,逐渐被多媒体教学模式取代。多媒体语言教学支持课堂讲解和自主学习两种学习模式,这种教学方式更利于学生与教师之间的教学互动,深得学生的好评,且教学效果得到了显著提高[2]。目前,多媒体英语信号源发出的标准语音信号参数单一,音频信号分析仪测量结果缺乏多样性,采用常规评价方法难以全面评价英语听力信号的准确性,无法有效满足多媒体英语听力校准的实际需求,在此背景下,研究更有效的评价方法具有非常重要的现实意义。
音频质量评价可以分为两种,其中一种是文献[3]给出的音频质量评价方法,其属于主观评价方法,通过对测听者的平均意见分直接显现人对听力的感觉,但该方法可重复性较差;另一种是文献[4]给出的音频质量评价方法,其属于客观评价方法,通过测量音频信号特征参数来评价听力质量,使客观评价结果可以准确预测出音频质量的主观评价结果,但该方法无法实现实时评测语音质量。针对上述方法存在的问题,设计多媒体英语听力自动评价系统,可应用于多媒体英语听力音频质量实际评价中。
1 多媒体英语听力音频质量参数分析
1.1 音频信号预处理
MFCC参数能够反映人类听觉系统对听力的幅频感知特性,在噪声环境下具有鲁棒性。多媒体英语听力自动评价系统开发框架结构如图1所示。
在多媒体英语听力自动评价系统中,选取三角形滤波器对输入多媒体英语听力信号实施滤波处理后,对滤波处理后信号分析音频信号能量谱提取音频信号MFCC特征参数,以MFCC特征参数为理论依据,根据MBSD测度值、噪声帧与弱音帧占总音频信号帧的比率及拟合获得的估计结果,得到与MOS高度一致的音频质量评价值,通过平衡控制支持向量机模型的复杂度与逼近误差[5],以MOS值为评价测度分析与管理音频质量,选取少量准确的听力音频数据采用支持向量机与扩展因子训练,支持向量机模型输出结果即可实现多媒体英语听力质量的判断,实现多媒体英语听力自动评价。
设定经过预处理后的英语听力音频片段x(n)经过加窗分帧和FFT变换得到音频信号频谱Xk(f),采用Mel频谱尺度更符合人类听觉特性,以下给出Mel频率与实际英语听力音频信号频率的具体关系:
M(f)=2 595 lg(1+f/700)
(1)
式中:频率f的单位是Hz。
采用三角形滤波器对音频信号进行滤波处理时,近邻频带之间存在频谱能量彼此泄露[6],难以反映出共振特性。听觉分析滤波器刚好可以弥补三角形滤波器这一不足,式(2)为听觉分析滤波器在时域对音频信号进行滤波处理的表达式:
gl(t)=tn-1e-2.038cos(2πflt+φl)u(t)
(2)
式中:n用于描述滤波器阶数;bl表示第l个滤波器的等效矩阵带宽;fl表示第l个滤波器的中心频率;φl表示第l个滤波器的初始相位;u(t)表示滤波器阶跃函数;L表示滤波器数量。
采用听觉分析滤波器组在频域对英语音频信号能量谱进行滤波处理,可获得各个听觉分析滤波器的输出能量:
(3)
MFCC参数将对数运算考虑为语音信号幅值转换过程,但对数运算从本质上来看是属于同态解卷积,其变换特性难以模拟英语听力的强度-响度感知特性。非线性压缩运算刚好能弥补此不足,采用非线性压缩运算替换对数运算[7],使MFCC参数更符合人类听觉生理模型。通过立方根函数来描述英语听力的强度-响度感知变换,即:
Sk(l)=[Pk(l)]1/3
(4)
对各个滤波器的输出能量求取对数,来模拟听力强度-响度变换,对数能量通过DCT变换到音频信号的倒谱域,获得MFCC参数。
对于英语听力音频信号中的频率常量采用RASTA滤波器进行滤波处理,即:
(5)
通过RASTA滤波和DCT变换后获得优化后的MFCC参数:
(6)
式中:i=0,1,…,p,p表示MFCC参数的阶数。
1.2 失真测度计算
失真测度能够较好地模拟人耳对英语听力原始语音和失真语音的对比过程。利用MBSD作为失真语音大小的度量,以计算获得的各帧音频信号的不同临界带的响度和噪声掩盖门限,结合MBSD测度的设定获得MBSD值。计算出信号失真帧与弱音帧之间的比率。为了计算出该值,需要计算各帧输入信号与编码信号的能量,再根据设置的能量门限值先判定该帧信号是失真帧还是弱音帧,再判断该帧信号为失真帧和弱音帧时占总音频信号帧总数的比例[8],由通过拟合获得的音频质量评价式获得与MOS值高度相关的英语听力质量评价值。
评价多媒体英语听力音频质量与人体感受声音响度有着十分密切的关系,设定MBSD时,应当以每帧原始音频信号和编码信号响度间差值的平均来考虑。在进行响度计算时需要将音频信号转换到响度中,来模拟人类的听觉感受特性[9]。
对于音频信号临界带,原始音频信号与编码信号之间的能量差值与噪声掩蔽门限值相比较小时,则在此临界带内信号失真将不会被感知;相反假设原始音频信号和编码语音之间的能量差值与噪声掩蔽门限值相比较大时,则此临界带内信号失真将被感知。噪声掩蔽门限经过临界带滤波、扩展函数作用与绝对门限联合得到。通过临界带滤波处理后可获得信号不同临界带的能量[10];扩展函数可用于描述不通过音频信号临界带之间噪声信号的相互作用。当通过扩展函数作用后获得噪声掩蔽门限值比其相应的临界带绝对门限值小时,MBSD测度值利用式(7)计算:
(7)
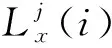
如果某帧音频信号在初始阶段能量较小,后期能量值明显增大,则该帧音频信号为噪声信号;如果某帧音频信号在编码阶段能量损失较为明显,则该帧信号为弱音帧。信号噪声帧以及弱音帧占整个听力音频帧的多少反映了该段音频信号的失真程度[11]。各帧音频信号的能量如下:
(8)
(9)
式中:X(i,j)和Y(i,j)分别用于表示与输入的英语听力音频信号第j帧相应的短时功谱序列中第i个样值点。
考虑到测试阶段英语听力的响度级在75 dB以上的占50%以上,门限值应当设定小于听力音频信号能量最大值的35 dB和45 dB,即:
(10)
(11)
当第j帧音频信号的能量小于xt2,而第j帧编码信号能量大于yt1时,说明该帧音频信号经过编码处理后能量被放大,则该帧为噪声信号帧;当第j帧音频信号的能量大于10 dB,而第j帧编码后的音频信号小于yt2时,说明该帧音频信号经过编码处理后能量损失较多,则该帧为弱音帧。信号噪声帧与弱音帧占总听力音频信号帧总数的比率为Vnm。
在IBSD中,音频信号质量评估值应当与主观质量评价值存在正相关关系,英语听力质量越好[12],相应的评估值越高。为了方便起见,将主观质量评估值区间设定为[0,1],为1时说明音频信号没有失真现象,为0时说明音频信号质量较差。
2 自动评价方法
2.1 支持向量机模型
支持向量机(SVM)是基于结构风险最小原理及VC维理论所建立的,可有效解决高维数、小样本以及容易陷入局部最小点等问题,是机器学习算法中解决非线性问题的重要方法[13],支持向量机模型具有较好的学习性能已广泛应用于各种评价问题中。
用xk∈Rn表示输入数据,用yk∈R表示输出数据,可得待评价样本集为B={(xk,yk)|k=1,2,…,N}。通过非线性特征映射将Rn映射至特征空间内用G表示,利用函数f(x)=ωTφx+b逼近未知函数g(x),函数f(x)属于训练集B内函数,ω与b分别表示特征空间G内权向量以及偏置,且b∈R。
支持向量机利用极小化结构风险获取目标函数如下:
(12)
(13)
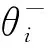
选取拉格朗日乘子建立拉格朗日泛函,获取二次规划问题的对偶公式如下:
(14)
(15)
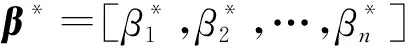
(16)
2.2 音频质量估计
在IBSD中,音频质量评估结果受到MBSD和Vnm的影响,MBSD值越大,说明原始音频信号和重建后的音频信号之间谱失真情况较为严重[14],此时音频质量将随之下降。而随着Vnm数值的不断增大,音频信号中含有的噪声帧和弱音帧也不断增加,此时英语听力质量随之下降。通过上述分析可知,IBSD和Vnm之间为反比关系,即受到有界的约束,可利用式(17)计算音频信号的IBSD值:
(17)
2.3 多媒体英语听力的自动评价系统
由于听力信号受信号节点的中继位置的扩展因子影响,因此需结合该因子的分析对语音信号进行训练,以实现多媒体英语听力自动评价,其中听力语音信号的中继位置与扩展因子关联性关系如图2所示。
由图2可知,发送端的坐标点为(0,0),转发节点的坐标为(d,0)。将支持向量机中一组错误扩展因子作为萤火虫算法个体,采用萤火虫算法优化支持向量机模型参数扩展因子,采用少数准确的多媒体英语听力音频片段对SVM模型进行训练,以实现多媒体英语听力的自动评价。具体过程如下所述:
扩展因子可以控制SVM模型复杂度与逼近误差之间的平衡,将SVM中一组错误扩展因子作为萤火虫算法个体,对扩展因子C进行优化,具体步骤如下:
(1) 初始化种群中荧光素挥发函数ρ,增强因子γ,种群个体的感知范围rs,邻域变化率β,萤火虫移动步长s。
(2) 确定SVM模型中扩展因子的取值区间。
(3) 在扩展因子C的取值区间内,随机选取一个值,将其作为种群个体当前所在位置。采用英语听力音频数据,将音频信号实际MBSD测度值的误差作为种群适应度函数,误差较小,SVM模型性能越好,种群适应度越大。
(4) 计算种群中每一个个体的荧光素浓度,其近邻个体的荧光素浓度值确定个体的搜索方向[15]。
(5) 判断是否达到终止条件,如果此时已达到中止条件,则将此时搜索得到的最优解视为模型的参数,否则转至步骤(4)。
假设yi、yj分别表示ti、tj时刻两段英语听力音频片段数据,则这两个阶段听力音频数据间的分段函数为:
(18)
设定两次测试间分段函数可以偏离的能量损失为h,则ti、tj时刻英语听力音频数据的上限函数为:
(19)
在线测量数据的下限函数为:
(20)
假设两次离线测试间的多媒体英语听力音频数据若超过了上限或是下限,则认为在线测量的音频数据质量差。采用少数准确的英语听力音频数据对模型进行训练,通过训练好的SVM模型对英语听力音频信号质量进行自动评价。
3 实验结果与分析
为了验证所提出的多媒体英语听力自动评价系统设计的合理性,选取Intel Celeron Tulatin 1 GHz CPU和384 MB SD内存的硬件环境和MATLAB 6.1的软件环境进行测试。表1列出了评价系统运行环境及实验信息的基础参数。

表1 实验参数表
本文所设计多媒体英语听力自动评价系统界面图如图3所示。
可以看出,所设计多媒体英语听力自动评价系统可有效评价英语听力的韵律、情感及重音情况,有效验证了系统评价的有效性。
多媒体英语听力样本为语音数据库中已知MOS值的听力文件,对听力文件进行数据转化,得到语音信号幅值情况,结果如图4所示。
可以看出,系统可有效将听力文件数据转化至语音信号幅值情况,所获取语音信号幅值有助于提升多媒体英语听力精准性。
选取专家评价法评价采用本文系统评价8段多媒体英语音频片段韵律、情感及重音情况的评分准确性,满分为10分,专家评分结果如表2所示。
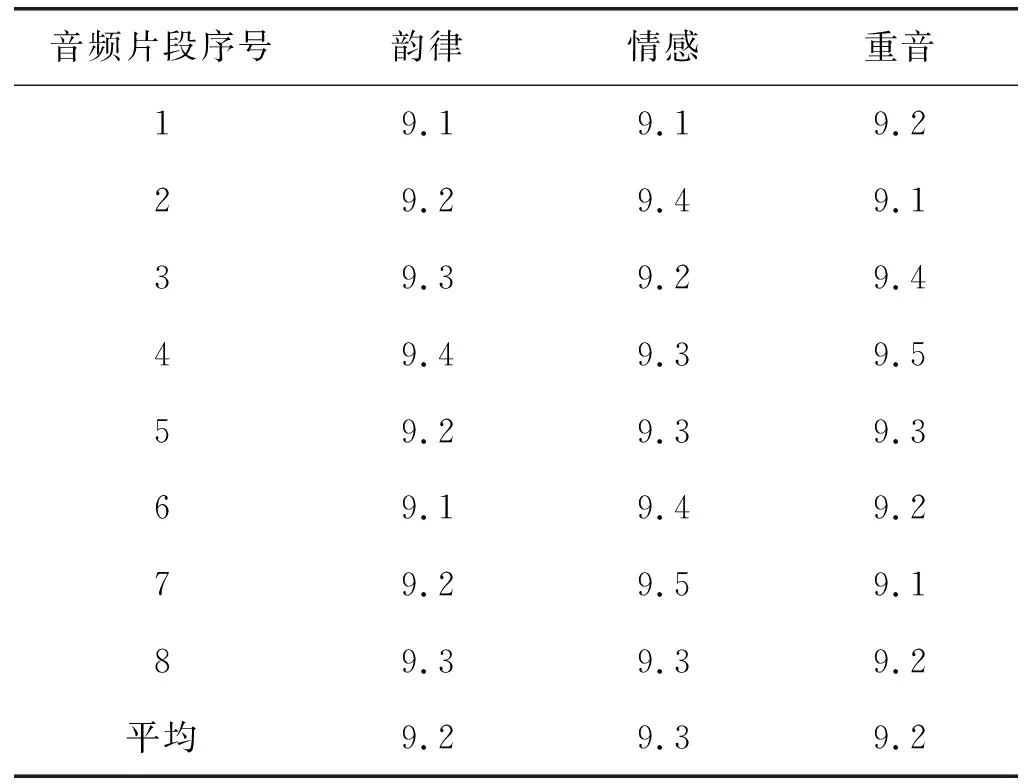
表2 专家评分结果
可以看出,本文系统对于多媒体英语听力8个音频片段评价韵律、情感以及重音情况准确性的评分结果分别为9.2分、9.3分、9.2分,专家评分结果说明采用本文系统可准确评价多媒体英语音频片段,具有较高的实用性。
本文系统对随机音频片段运行100 s内的幅值信号统计结果如图5所示。
可以看出,所设计系统可直观体现不同音频片段的信号情况,依据所展示幅值可准确评估不同多媒体英语音频片段的信号质量,有效验证所设计系统评价多媒体英语听力音频信号质量有效性。
统计采用所设计系统评价8段多媒体英语音频片段的评价时间,并选取基于层次分析法的评价系统及基于神经网络的评价系统作为对比系统,对比结果如表3所示。
表3 不同系统评价时间对比
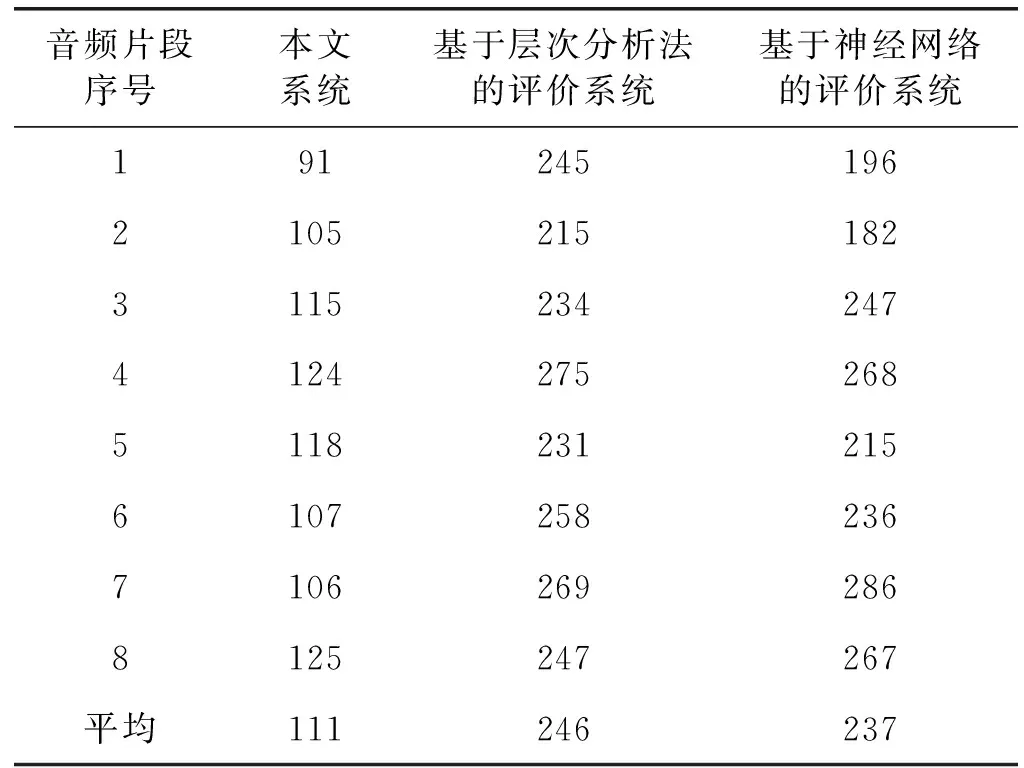
单位:ms
可以看出,采用本文系统评价8个多媒体英语听力音频片段平均评价时间仅为111 ms,对比结果说明所设计系统评价多媒体英语听力具有较高的实时性。
4 结 语
本文提出一种多媒体英语听力自动评价系统设计。该系统结合了人耳的听觉生理模型、MBSD测度,并考虑了噪声帧和弱音帧比率对多媒体英语听力音频质量的影响,将其应用于多媒体英语听力的校准。实验证明所设计系统可准确评价多媒体英语听力音频文件,相比其他系统具有较高的实时性。
猜你喜欢
疯狂英语·初中天地(2022年2期)2022-07-07
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
疯狂英语·初中版(2022年2期)2022-05-04
疯狂英语·初中版(2022年4期)2022-04-11
疯狂英语·初中版(2022年1期)2022-01-26
家庭影院技术(2021年1期)2021-03-19
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2017年10期)2017-04-20
