
残差密集块的卷积神经网络图像去噪①
2022-11-07 09:07李小艳宋亚林
计算机系统应用 2022年10期
李小艳,宋亚林,乐 飞
(河南大学 软件学院,开封 475004)
图像在采集、存储、记录和传输过程中常常会受到众多不良因素的干扰影响,从而导致图像在一定程度上会退化失真,质量下降,导致获取的图像中有噪声的存在,从而影响图像的质量.图像去噪是在保持原始图像细节信息完整的同时,去除图像中的无用噪声信息,以便于后续对图像进行应用[1,2].图像去噪是计算机视觉研究中的一个经典问题,同时也是图像领域中一个具有挑战性的研究课题[3-5].
传统的图像去噪方法主要是高斯滤波降噪[6,7],这种方法属于局部平滑滤波,这种去噪方法针对图像的非平滑部分,不能进行有效的处理.非局部均值降噪[8]方法可以解决图像的非平滑这一问题,该方法利用了图像中存在的冗余信息进行去噪处理,能够较好地去除图像中存在的高斯噪声,该方法的最大缺陷就是计算复杂度太高,程序非常耗时,导致该算法不够实用.小波阈值降噪[9,10]主要是利用滤除高频信号这一原理,小波阈值降噪如果选择的阈值过大,会导致图像中的高频信息被无区别的抑制,从而导致图像边缘信息,纹理细节丢失.如果阈值过小,就不能对高频噪声进行有效的去除.Dabov 等人在2007年提出了一种基于融合变换算法的块匹配和三维滤波降噪方法[11],简称为BM3D (block matching and 3D filtering),该方法采用不同的去噪策略,通过与相邻图像块进行匹配搜索,在三维空间进行滤波,得到块评估值,最后通过加权求和将各个块复原得到最终去噪效果.BM3D 降噪方法虽然去噪效果显著,但时间复杂度比较高.采用传统图像去噪算法的复杂度较低,实时性比较强,处理速度快,但在去噪过程中边缘细节信息和纹理信息很容易丢失.
随着深度学习特别是卷积神经网络(CNN)[12,13]在计算机领域的逐渐发展,CNN 被众多研究学者应用在图像去噪问题上并取得了较好的研究成果.Holt[14]在研究神经网络去噪的过程中,其选用的研究方法是多层感知机(multi layer perceptron,MLP).在他看来多层感知机网络具有强大的拟合能力和非线性能力,通过学习带噪声的图像和无噪声图像来实现图像之间的映射关系,MLP 模型对各种类型的噪声影响不大,通过对含有此类噪声的图像进行分类,可以获得良好的效果.这种模型的缺点是由于不能很好地处理各种等级噪声,因此用不同等级噪声图像进行训练,则很难获得较好的去噪效果.Mao 等人[15]提出了一种深卷积编解码网络应用于图像去噪,该网络具有对称结构的编码(encoding)和解码(decoding),每一层编码卷积和解码卷积之间都有跳跃连接,可以获得更好的泛化能力.但是由于网络变深会导致图像细节的丢失.Zhang 等人[16]提出用较深层的CNN 网络实现图像去噪,称为DnCNN,该网络模型通过利用残差学习[17]和归一化[18]的共同作用,提高去噪性能,该算法使用端到端的神经网络模型来进行降噪,同时该算法具有较好的盲去高斯噪声的能力.但是,由于所建立的神经网络模型是由单一大小的卷积核卷积运算完成,因此,图像的特征信息提取很少.Zhang 等人[19]采用扩张卷积来学习残差图像并提出了IRCNN 模型,该模型基于半二次方分裂(HQS)算法,利用卷积神经网络学习快速有效的去噪器,以此来处理不同的图像修复问题,但是该模型收敛速度慢,计算成本大,比较耗时.Zhang 等人将估计的噪声水平和图像下采样后的多张子图像作为输入,提出了快速灵活的图像去噪网络FFDNet[20],该模型能够在较大程度上改善降噪性能,同时能较好地处理真实场景下的图像去噪问题.该方法只有在噪声水平较大时,才能保持更好的视觉效果,当噪声较小时,去噪后的视觉效果不佳.Creswell 等人[21]介绍了GAN 用于图像合成、图像超分辨率和图像分类.Wang 等人提出了一种基于GAN 和CNN 相结合的图像去噪网络[22],该网络采用GAN 进行降噪处理,采用CNN 实现对图像细节的恢复.该方法存在网络训练不稳定,收敛速度慢,模型不可控等问题.席志红等人[23]提出了一种深层残差神经网络用于图像的超分辨率重建,通过实验验证该网络可以更好地还原图像中的细节信息,消除伪影.但该方法特征表达能力不足,难以去除密集的噪声.陈人和等人[24]采用对抗损失和重建损失的加权和,该网络虽然能够去除噪声并且针对图像的细节信息得到保留,然而该算法可能会导致图像的边缘模糊.秦毅等人[25]针对不同类型的图像,通过采用一个边缘感知损失函数去除图像噪声,同时恢复图像的边缘细节.该算法的浅层像素级信息利用率低,纹理细节容易丢失.朱斯琪等人[26]提出一种循环一致性生成对抗网络,实现了从低剂量CT 图像到标准剂量CT 图像的端到端映射,同时将密集型残差学习网络模型引入到该网络生成器中,利用残差网络的特征复用性来恢复图像细节,但是该方法在去除噪声后仍然会有伪影存在,且该方法目前只适用于腹部CT 图像.
上述图像去噪算法尽管在网络结构设计,目标损失函数以及数据集的选择上存在差异,但是这些算法都能够取得显著的成果.上述这些算法在进行网络训练时,图像特征不能被充分学习,导致图像细节丢失,降低去噪效果.因此为进一步改善图像去噪质量,本文在去除噪声的过程中,保存图像的边缘特征信息的基础上,提出一种密集连接残差块的卷积神经网络去噪算法.该网络模型由卷积层,Leaky ReLU 层,批量归一化,密集残差块组成,其中密集残差块通过多级残差网络和密集连接,用优化的残差映射代替原始的卷积层,相邻的卷积层之间通过短连接,以提高残差网络的学习能力.该网络结构以含噪声的图像作为输入,去噪后的图片作为输出,构成了由噪声图像到去噪后图像的非线性映射.本文算法在去除噪声的同时,能够保留更多的图像细节信息和图像边缘特征,去噪后的图像视觉效果更好,且具有更高的峰值信噪比值和结构相似性值.
1 相关技术原理
1.1 基于卷积神经网络的图像去噪算法
Zhang 等人[16]设计出一种经典的基于残差学习的卷积神经网络去噪模型称为DnCNN,相比于MLP 和BM3D 等传统的图像去噪算法,去噪性能有明显的提高.
DnCNN 网络共有17 层,其中第1 层由64 个大小为3×3×1的滤波器被用来生成64 个特征映射,然后经过ReLU 激活函数.第2 至第16 层由64 个大小为3×3×1的滤波器,而后经过BN 和ReLU 激活函数; 网络的最后一层采用1 个大小为3×3×64的滤波器对网络模型进行重构.DnCNN 网络的训练通过式(1)进行学习:

其中,x为去除噪声后的图像,y为噪声图像,F(x)为网络预测的噪声.对于DnCNN 图像去噪,实际上F(x)不可能包含全部的噪声信息,因此x会丢失掉部分的细节信息,因此DnCNN 的去噪效果仍有待提高.
1.2 残差学习
为了提高卷积神经网络的精确度,通常情况下都是通过简单的堆叠网络增加网络的深度,与此同时网络的加深致使网络梯度发生爆炸或者衰减到很小,误差值乘上权重后向后传播,使得权重越来越小,神经网络的训练精度先上升然后达到饱和,因此提出残差学习用来解决网络性能退化的问题.He 等人[17]提出了残差学习的方法,其框架结构如图1 所示.
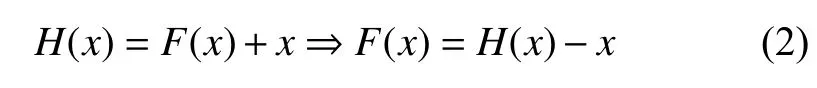
x为残差模块的输入,F(x)+x是残差模块的输出.只要F(x)=0就构成了一个恒等映射H(x)=x,残差为F(x),残差学习结构通过前向神经网络和shortcut 连接的方式实现,shortcut 连接执行了一个恒等映射,这种方式不会产生额外的参数,同时也不会增加网络的计算复杂度.采用残差学习策略使得深度卷积神经网络容易被训练并且能更好地提升精确度.
1.3 Leaky ReLU 函数
带泄露修正线性单元函数(Leaky ReLU)[27]是基于ReLU 激活函数的改进,带泄露修正线性单元函数在保留ReLU 函数的优点的同时,还可以做到修正数据分布.激活函数如图2 所示,通过在ReLU 函数的负半区间引入一个泄露值,解决部分神经元因为失活不能参与参数的更新.
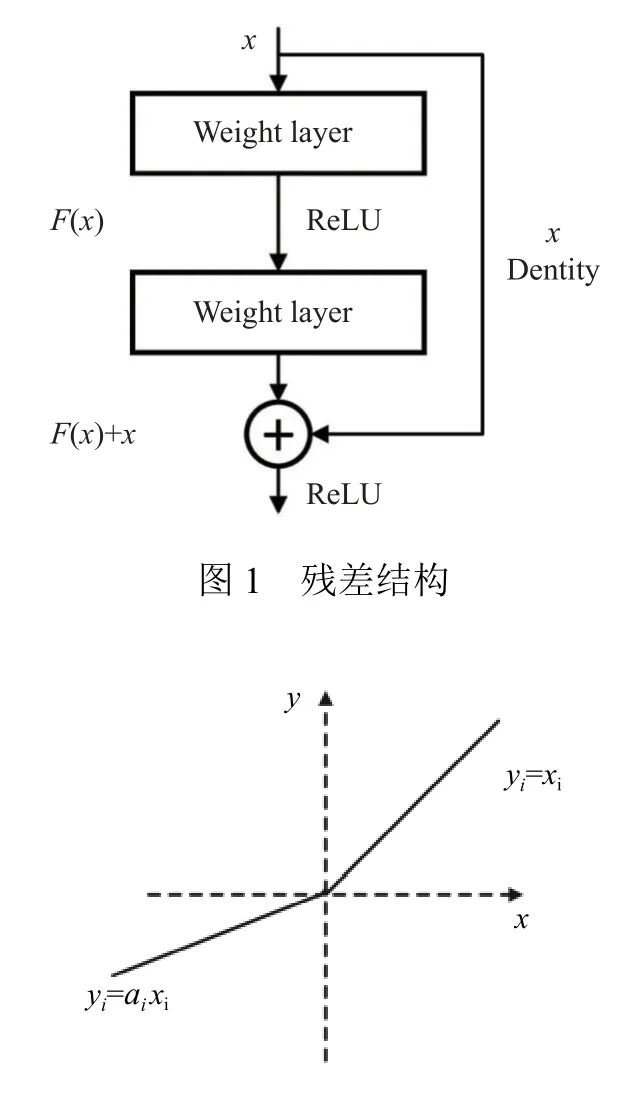
图2 Leaky ReLU 激活函数
在反向传播过程中,经过激活函数负区间的神经元在参与网络训练过程时,由于泄露值的存在,神经元对应的权重和偏置参数也得到了更新,计算得到的梯度不会恒为0,网络的拟合能力得到提高.由于图像在噪声环境下的有效特征信息相对来说较为有限,因此在网络训练中对于图像中的特性信息需要充分挖掘.Leaky ReLU 函数替换掉原始网络中的ReLU 激活函数,该激活函数可以实现网络梯度更快的更新,同时拥有比原始网络更好的图像去噪效果.
2 结合残差密集块的卷积神经网络去噪算法
2.1 密集连接残差块(RRDB)结构
卷积神经网络的输入都是上一层的输出,不同卷积层所提取到的特征各不相同,所以通过单一层的卷积不能尽可能多地获取到图像的特征信息,仅依靠残差块的叠加同样会限制网络的性能,所以为了优化残差网络的性能,Huang 等人[28]提出了一种新的密集连接残差模块,用于缓解梯度消失问题,加强特征传播与特征复用,极大地减少了参数量.本文提出了一个密集连接残差(RRDB)的卷积神经网络结构.RRDB 模块如图3 所示.

图3 RRDB 残差块
RRDB 模块包括3 个dense block 块,每一个dense block 里面又包含4 组卷积层与Leaky ReLU 激活函数,卷积核的大小为3×3,每组由32 个卷积核组成,每组都通过密集连接,最后通过一个3×3的卷积层.每一个dense block 的输出进行残差缩放[29,30],乘以一个0 到1 之间的数,以用于防止网络模型的不稳定.
通过多级残差网络和密集连接,用优化的残差映射代替原始的卷积层,相邻的卷积层之间通过短连接,以提高残差网络的学习能力.RRDB 模块中的卷积与卷积之间以跳跃连接的方式,让模块中每一层卷积层的特征可以做到被充分利.RRDB 模块提高了网络的整体训练的速度,加深了网络的深度,通过每一层特征的融合,输出的特征图可以更好地包含原图像的特征信息.
2.2 网络模型结构
图像去噪是通过对含噪图像进行处理,通过非线性映射到噪声图像,从而得到去噪后图像的过程.
为了对网络进行特征提取,同时为了降低网络训练的复杂度,通过结合密集连接残差块,设计了一种基于密集连接残差的卷积神经网络模型(DRCNN).图4展示了本文算法网络整体架构示意图,该模型结构分为3 个部分: 特征提取模块,密集连接残差模块(RRDB)和重建模块.
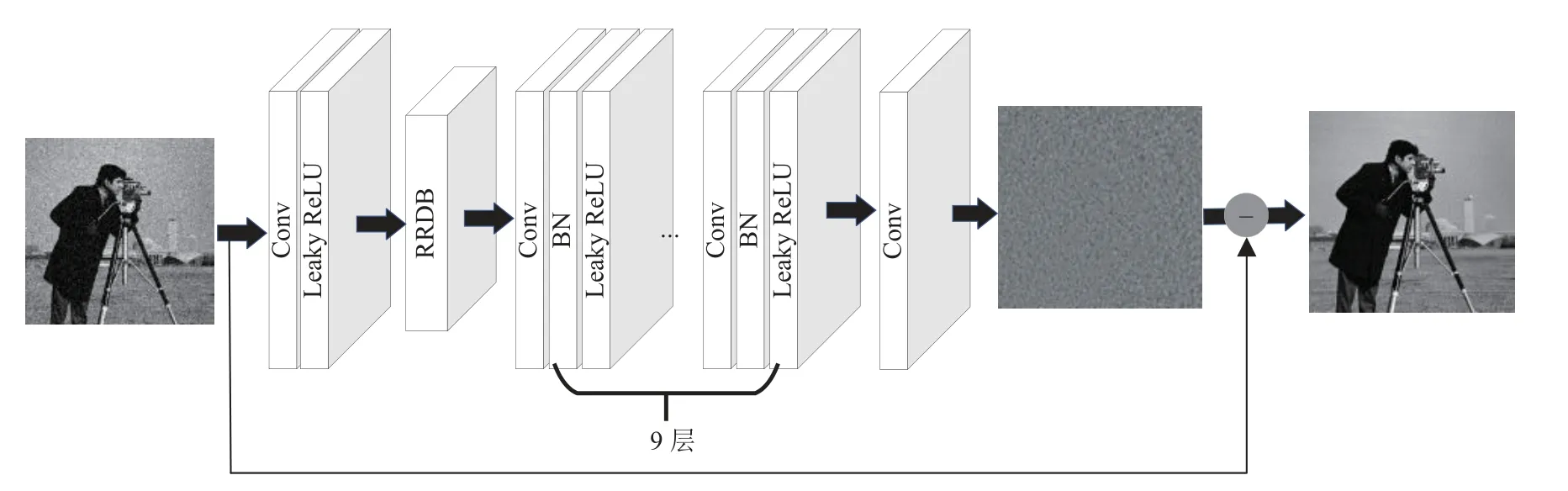
图4 网络模型结构
本文提出的去噪网络,共有12 层,网络架构由3 部分组成: 卷积层(Conv),激活函数(ReLU),批规范化操作处理(BN),具体如下:
网络模型第1 层: Conv + Leaky ReLU,由64 个卷积核大小为3×3×c的滤波器用来生成64 个特征映射,并使用Leaky ReLU 激活函数对特征实现非线性变换形成非线性特征映射,步长为1×1,c表示图像的通道数,该网络模型使用灰度图像,故c=1.
网络模型第2 层: dense block + dense block +dense block,结构如图3 所示,每一个dense block 里面又包含4 组卷积层与Leaky ReLU 激活函数,卷积层由32 个卷积核大小为3×3的滤波器用来生成32 个特征映射,每组都通过密集连接,最后通过64 个卷积核大小为3×3的卷积层生成64 个特征映射.
网络模型第3-11 层: Conv + BN + Leaky ReLU,由64 个卷积核大小为3×3×c的滤波器用来生成64 个特征映射,并使用Leaky ReLU 激活函数对特征实现非线性变换形成非线性特征映射,步长为1×1,c表示图像的通道数,该网络模型使用灰度图像,故c=1.
网络模型第12 层: Conv,采用c个大小为3×3×64的滤波器进行网络重构,步长为1×1,通过式(1)的残差学习策略进行训练,最终输出去噪后的图片.
在网络结构中,采用0 填充的方法保持每层卷积特征图的大小保持不变,用来防止产生边界伪影.
2.3 损失函数
通过从预测的噪声图片中恢复无噪声图片,训练数据是带有噪声的图像y=x+v,去噪模块采用残差学习获取到残差映射R(y)≈v,然后得到x=y-R(y).本文所设置网络训练的目标损失函数为:

其中,N为训练样本数,xi代表原始图像,yi表示带噪声的图片.实际噪声为(yi-xi)(噪声图像值减去无噪声图像值),θ为当前网络的训练参数数值,估计的噪声残差R(yi;θ)与图片中实际噪声的平方误差是损失函数的期望值.为了计算函数L(θ)的最小值,本文采用Adam 优化器进行迭代和参数更新.定义如下:

其中,mt表示一阶动量项,vt表示二阶动量项,β1值为0.9,β2值为0.999,为偏移修正值,θt表示迭代t次模型的参数,利用式(7)的参数更新过程,能够通过训练得到网络模型.
3 实验分析
3.1 数据集
本文使用来自伯克利分割数据集(BSD)的400 幅大小为180×180的灰度图像来训练高斯合成去噪模型.深度学习模型在训练上往往需要大量的训练图像,但是训练集的图片数量一般都有限,所以为了防止出现过拟合的情况,需要对样本图像进行数据增强.本文所设计的算法中,首先对每一张图像进行1、0.9、0.8、0.7 倍的缩放,然后采用40×40的裁剪框,滑动步长设置为10,随后将每一个子图像块都进行随机旋转,原图像进行水平、垂直、顺时针翻转90°、180°、270°进行数据增广操作,将400 张图像裁剪成238 336 个 子图像块,充足的训练图像块有助于促进特征的鲁棒性并提高训练去噪模型的效率.通过上述数据增强操作后的不含噪声的原始图像,随后将高斯白噪声添加到原始图像中生成含噪图像.为了测试不同噪声强度对网络性能的影响,将σ=5,σ=10,σ=25,σ=50的高斯白噪声分别添加到原始图像中用以生成不同的训练集.测试数据集采用BSD68 和Set12 组成,Set12 数据集如图5 所示,包含5 张人像,3 张动物以及房子轮船飞机场景.BSD68 数据集包含建筑,人物,动物,植物,飞机等场景,共68 张图片.两个测试集均为灰度图像.

图5 数据集Set12 示例图片
3.2 评价指标
为了评估去噪后的图像质量,通常从峰值信噪比(PSNR)和结构相似性(SSIM)两方面进行定量的评估分析,其中PSNR是一种基于对应像素点之间误差的指标,PSNR和SSIM的值越大,就代表失真越少,图像去噪效果更好.计算公式如下:
(1)峰值信噪比(PSNR)
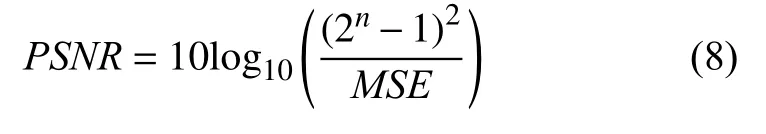
n为每像素的比特数,一般取8,即像素灰阶数为256,单位为dB.
(2)均方误差(MSE)
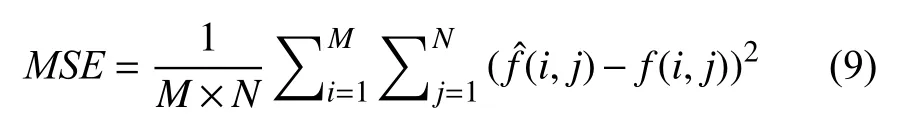
MSE表示当前图像fˆ(i,j)和参考图像f(i,j)的均方误差; 其中M,N为图像的高度和宽度.
(3)结构相似性(SSIM)
结构相似性分别从样本图像的亮度(luminance,l)、对比度(contrast,c)和结构(structure,s)这3 个方面来度量图像的质量.其中亮度l、对比度c和结构s的计算公式如下:

其中,c3=c2/2,ux代表图像x的像素的均值,uy代表图像y的像素的均值,σ2x代表图像x的像素的方差,σ2y代表图像y的像素的方差,σxy代表图像x和图像y的协方差,SSIM的计算公式为:

3.3 实验环境
为了验证本文所提出的网络结构的去噪性能,将本文所提出的算法与BM3D,DnCNN,FFDNet,IRCNN 几种常见的卷积神经网络去噪模型进行了实验对比,为了验证图像在不同等级噪声下网络去噪性能的影响,分别对训练集添加噪声等级为5,10,15,25,50 的高斯噪声.
为了对本文所设计的算法进行验证,实验的硬件配置为GPU 为Tesla P4,内存为8 GB,软件配置为CUDA 10.1,Python 3.7,神经网络的搭建采用深度学习框架PyTorch 0.4.采用Adam 优化器进行训练,学习率设置为1×10-3,训练轮数为50.为了提高网络训练效率,对网络的输入数据采用批量输入,batchsize 为128.
3.4 实验分析
为了考察不同的dense block 模块对网络去噪模型的影响,将分别对含有1,2,3 个Conv+Leaky ReLU层的dense block 模块进行图像去噪性能比较,实验结果如表1、表2 所示.表1 表示在噪声等级为25 时,不同数量的dense block 在测试集Set12 上的PSNR和SSIM值.表2 表示在噪声等级为25 时,不同数量的dense block 在测试集BSD68 上的PSNR和SSIM值.

表1 不同dense block (DB)模块在Set12 数据集上的PSNR/SSIM 值

表2 不同dense block (DB)模块在BSD68 数据集上的PSNR/SSIM 值
从表1 和表2 中可以看出,将3 个dense block 模块进行串联拼接,可以融合更多的图像特征信息,在网络输出时可以对输入图像进行更细节的恢复,平均峰值信噪比和结构相似性均具有较好的效果.此实验说明dense block 模块的特征融合对图像去噪是有效的.
对Set12 和BSD68 两种数据集分别添加不同等级σ=5,σ=10,σ=15,σ=25,σ=50的高斯噪声,由于图像自身结构的差异性,不同的图像在不同的去噪算法上的结果存在差异,导致PSNR和SSIM的值不相同.表3 显示在不同噪声等级下,Set12 数据集的每一张图片的去噪结果的PSNR值,本文提出的算法在σ=5,σ=10,σ=15,σ=25,σ=50时,图像去噪效果优于其他去噪算法,在高噪声σ=50场景下,本文的图像去噪效果一般,PSNR提升较小.表4 显示在不同噪声等级下,Set12 数据集在不同图像去噪算法下的平均SSIM值,本文提出算法的图像去噪上取得了良好的效果.从表3 和表4 可以看出,本文所提出的算法在5 种噪声等级下的PSNR与经典的BM3D 图像去噪算法相比平均超出了2.7 dB,SSIM平均超出了0.2776.与深度神经网络图像去噪方法中的DnCNN 方法比较,在噪声等级为5,10,15,25,50 时,本文提出的去噪算法平均PSNR分别提高了0.09 dB,0.11 dB,0.1dB,0.12 dB,0.18 dB,平均SSIM分别提高了0.000 3,0.000 7,0.000 6,0.002 1,0.0049.表5 展示了在5 种不同噪声等级下,本文算法在数据集BSD68 下,PSNR取得最好的平均值,表6 使用了SSIM作为评价指标,在不同噪声等级下,不同算法在数据集BSD68 下的平均SSIM值,表明本文算法在不同强度的噪声环境下,去噪性能整体效果最优.

表3 不同算法在Set12 数据集上的PSNR 值(dB)

表4 不同算法在Set12 数据集上的SSIM 值

表5 不同算法在BSD68 数据集上的PSNR 值(dB)

表6 不同算法在BSD68 数据集上的SSIM 值
图6 选取了Set12 数据集中的5 幅图像,在5 种不同噪声等级下,通过不同的算法对含噪声图像进行去噪,每一张去噪后的图片给出了局部放大效果,图片中的白框区域为放大区域,图片右下角为局部细节放大图,由图可见,本文提出的方法在去噪时很好地保留了图像的纹理细节,有效地较少边界伪影和边缘细节损失.

图6 不同算法不同噪声等级下数据集Set12 的部分去噪图片
4 结论与展望
本文针对图像去噪存在不能充分提取图像特征导致图像细节丢失且收敛时间过长的问题,提出了一种基于残差密集块的卷积神经网络图像去噪方法,该模型通过引入密集连接残差块并添加Leaky ReLU 激活函数操作进一步提高网络性能,能够有效去除不同等级强度的噪声,同时利用PSNR和SSIM值进行网络性能评估.与经典图像去噪算法相比较,实验结果显示,本文提出算法的PSNR和SSIM均有明显的提升,本文算法提高了图像去噪的性能,提升图像的纹理细节信息,随着残差结构的加入,网络训练的过程也随之加快,与此同时减少了边界伪影,但本文所提出的算法针对高噪声环境下的图像进行去噪时,依然存在图像细节丢失问题,针对该问题,后续将针对该网络模型作进一步的研究.此外,结合真实场景,例如医学成像、遥感图像产生的真实噪声问题,需要继续研究.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
电脑报(2022年24期)2022-07-01
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
舰船科学技术(2021年12期)2021-03-29
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
饮食科学(2016年7期)2016-07-27
科技与创新(2015年19期)2015-10-14
