
高速公路典型要素语义分割深度学习模型适用性分析
2022-11-04 05:50李升甫周城宇许濒支
北京测绘 2022年10期
贾 洋 李升甫 周城宇 南 轲 许濒支
(1. 四川省公路规划勘察设计研究院有限公司, 四川 成都 610041;2. 西南交通大学 地球科学与环境工程学院, 四川 成都 611756)
0 引言
激光点云语义分割是一种根据点云数据的视觉内容将其中的每一个点归类为其所属对象的语义类别的技术。随着越来越多应用需求的出现,点云语义分割已成为三维场景理解和分析的关键步骤,也是场景单体信息化的重要基础。在智慧交通行业应用中,高速公路路面实体要素信息的综合利用是公路工程建管养多阶段数字化综合业务应用的重要体现。多平台激光扫描设备可以快速完整地获取高速公路路域范围的三维激光点云数据,如何高效利用点云数据快速、精准识别路面及其他典型公路要素成为研究热点[1-7]。
现有的点云语义分割方法大多是采集点云的强度信息、辐射信息和回波信息,以及几何属性分布,通过先验经验设置各项阈值,建立分类器,构建判别模型,采用支持向量机、随机森林、马尔可夫随机场和条件随机场等方法进行点云分类。此类传统方法需要经验知识,固定的阈值不适用于多个场景,且原始点云杂乱无序,噪声会对结果有随机性的干扰[8]。深度学习语义分割起源于二维图形,随着深度学习的发展,更多学者尝试用深度学习方法对点云语义分割。当前基于深度学习的点云分割方法主要分为基于多视图、基于体素和基于点云的方法[9-10],其中,基于多视图的语义分割方法将点云数据转化为若干个二维图像的过程通常较为复杂,存在着关键的三维空间信息丢失、语义分割结果易受所选投影角度影响的问题[11];基于体素的语义分割方法较好地解决了点云非结构化的问题,但由于该类算法计算量较大,且存在信息丢失的问题,导致其针对大场景点云语义识别的实用性较,仍有巨大的发展空间[12];基于多视图和体素的方法都存在着一定的局限性,为了更好地对点云数据的特性加以利用,很多研究者开始对基于点云的语义分割方法进行研究,这类方法直接对点云数据进行处理,逐点输出标签,这类方法可以处理任意的非结构化的点云,且识别精度及计算效率综合表现较好。目前,基于点云的方法以其较好的分割效果吸引着越来越多的学者对其进行研究,以深度学习点云语义分割算法PointNet[13]、PointNet++[14]及RandLA-Net[15]等网络模型为代表。文章将对具有代表性的激光点云深度学习神经网络模型在计算效率、识别精度等方面进行对比分析,优选一种适用于高速公路典型要素激光点云语义分割的模型方法。
1 研究方法
本文主要针对高速公路路面、护栏、绿化带植被、车辆、车道标线、杆状交安设施及面状交安设施等典型要素语义识别问题,分别使用PointNet、PointNet++及RandLA-Net三个激光点云深度学习模型进行1 km路段的信息识别性能测试,通过优选后的模型,进行差异性路段更长距离公路要素识别的鲁棒性实验。具体过程为:①构建样本集;②1 km路段模型比选测试;③长距离路线鲁棒性实验,如图1所示。
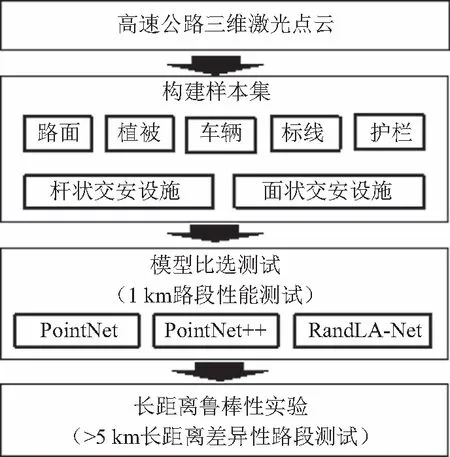
图1 技术流程
2 构建样本集
高速公路场景激光点云数据包含三维空间坐标(XYZ)信息及相应的附加信息如强度、全球导航卫星系统(global navigation satellite system,GNSS)授时、回波数、影像光谱(red green blue,RGB)信息等。使用激光数据处理软件TerraSolid对整段高速公路点云数据进行分段,然后对每段数据单独进行滤波去噪。文章选择使用半径滤波器进行滤波操作,具体操作如下:对于任意一个点,设定半径r为0.05 m,若在该点半径r内的邻近点数小于10,则认为该点为噪声点。由于选定的高速公路基础要素集中于路面范围以内,为便于进行深度学习网络的训练和验证,滤波后还需利用行车轨迹去除路面以外的点云。图2为高速公路点云数据预处理前后对比。

(a)预处理前点云数据 (b)预处理后点云数据
点云样本数据集的构建是以人工标注为主。使用TerraSolid的框选工具和剖面选择工具对预处理后的高速公路点云数据手动标注每个点的类别,共分为7类,分别是路面、护栏、植被、车辆、杆状物、车道线、面状物。
3 模型比选测试
本节利用标注好的高速公路场景车载激光点云数据集训练PointNet、PointNet++及RandLA-Net,并在测试数据集上对上述深度学习网络的语义分割效果进行了对比测试,经调参实验后最高精度的网络模型实验设置如下。
3.1 PointNet网络模型的实验设置
PointNet使用每个点的XYZ及归一化后的xyz和归一化后的强度信息组成9维的特征作为网络输入。PointNet采用块状的点云输入(本节实验中设定块边长为3 m×3 m,若该块内总点数小于1 000则舍去,点数位于1 000~8 192,则随机复制部分点至总点数到8 192,若大于8 192,则随机选择8 192个点),先将整个场景划分为规则平面体,再通过固定长宽的矩形框进行搜索。而公路场景呈长条形,会划分为较多的块状,搜索效率极低,多段数据累计处理时间较长。输入点云数为8 192,训练轮数设置为50,指数衰减初始学习率为0.001,每批数据量(batchsize)为24,使用自适应矩估计(adaptive moment estimation,Adam)优化器。
3.2 PointNet++网络模型的实验设置
PointNet++在PointNet上做出改进,采用最远点采样方法逐级下采样,增加邻域信息的利用,有效地使用了上下文语义信息,再通过最邻近算法(K-nearest neighbor,KNN)内插将传递至原输入点云上。PointNet++同样需要块状点云输入(与PointNet的数据预处理方式相同),为了公平比较,使用和PointNet同样的输入点云。输入点云数为8192,训练轮数设置为50,指数衰减初始学习率为0.001,batchsize为24,使用Adam优化器。
3.3 RandLA-Net网络模型的实验设置
RandLA-Net使用随机采样替代最远点采样,可一次性输入65 536个点,极大地提高了效率,配合局部空间编码模块和自注意力机制取得了良好的分割效果。数据预处理中,体素尺寸设置为0.06 m,输入点云数为65 536,训练轮数为50,初始学习率为0.01,每轮减少5%,batchsize为5,使用Adam优化器。
模型比选测试评价指标:本文采用交并比(intersection over union,IoU)评估神经网络,如式(1)所示。
(1)
式中,IoU表示交并比,可以更好地评估语义分割结果。tp、fp和fn函数分别为语义标注正确的目标个数、错误标注的目标个数和错误识别的正样本目标个数。
测试数据集在PointNet、PointNet++、RandLA-Net上的语义分割实验结果如表1所示。

表1 模型测试结果
通过对实验结果进行分析可以发现,PointNet使用两个张量网络(tensor network,T-net)结构使得网络具备旋转不变性,并结合了全局特征和单点特征,但是PointNet没有考虑点云的邻域信息,造成语义信息缺失,同时基于块状的输入方式会造成数据准备大量耗时的问题,导致效率极低。PointNet++虽然通过半径搜索的方式利用了每个点的邻域点特征,但最远点采样会随着点云数量的增加而变得效率低下,并不适合用于高速公路大场景点云语义分割。RandLA-Net中采用的随机采样方法的时间复杂度不会随着点云数量的增加而变化,是高速公路大场景点云语义分割的首选网络。因此,优选RandLA-Net进入高速公路点云语义分割鲁棒性实验。
4 研究方法
4.1 实验环境与参数设置
长距离路线鲁棒性实验路段为雅西高速中长约6 km的一段高速公路,通过车载激光扫描设备获取激光点云数据,最终得到了1,1 102,3 233个点的原始点云,大小为3.51 GB,如图3所示。将原始点云分为12块通过Terrsoild工具进行人工标注(图4),分为7类,分别是路面、护栏、植被、车辆、杆状物、车道线、面状物。

图3 雅西高速激光点云扫描

图4 分块处理点云数据
文章采用深度学习框架TensorFlow 1.13.1实现具体RandLA-Net模型的训练和语义分割实验。实验软硬件环境见表2、表3。

表2 实验硬件配置

表3 实验软件配置
数据集共包含12段数据。数据包括训练集、验证集、测试集。其中训练集为第1、2、4、7、9段,验证集为第3、8、11段,测试集为第5、6、10、12。段训练批次为5,迭代100轮,初始学习率为0.01,每轮下降95%。网络模型通过Adam优化器对网络的权重和偏置进行更新。每轮训练完成后进行验证,选取在验证集的平均交并比(mean intersection over union,MIoU)值最高的模型作为最终测试的网络模型。
4.2 实验结果
实验结果见表4。从表中可以看出,七类要素的整体精度达到90.53%,其中,路面的分割结果精度最高,车道线的分割结果精度最低,为79.14%,这是由于车道线长期受车辆碾压,存在污损、缺失等现象。总体来看,RandLA-Net模型可以较好地实现高速公路场景的激光点云语义分割。
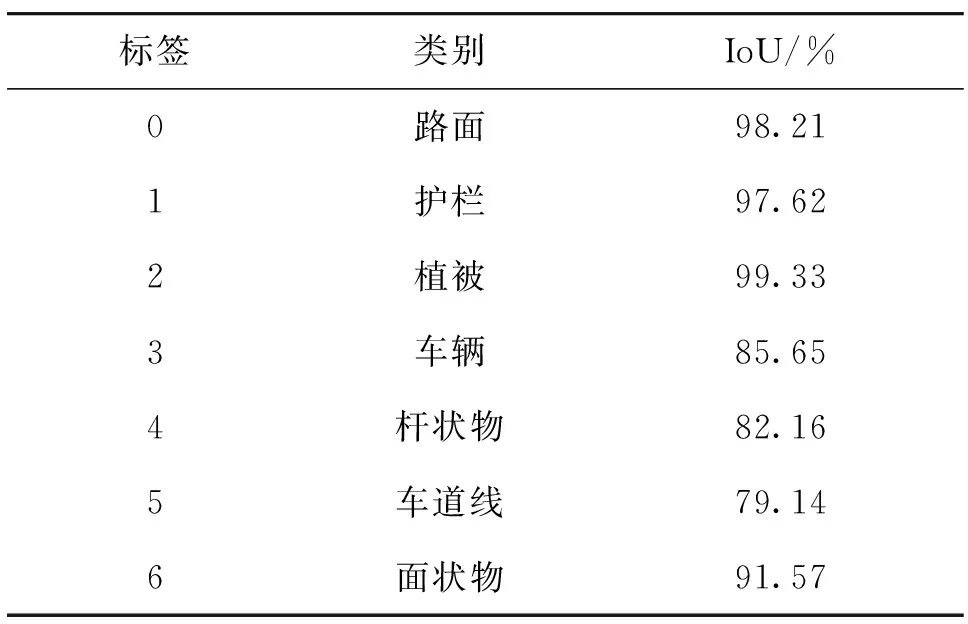
表4 实验结果
5 结束语
针对高速公路路面、护栏、绿化带植被、车辆、车道标线、杆状交安设施及面状交安设施等典型要素语义识别问题,文章对比评估了PointNet、PointNet++及RandLA-Net三大主流深度学习点云语义分割网络模型在高速公路场景下的语义分割性能和效果,最后选择性能最优的RandLA-Net网络模型进行长距离(>5 km)高速公路基础要素的语义分割实验,结果表明,RandLA-Net网络模型可以较好地实现高速公路场景的激光点云语义分割,总体精度达90.53%,能够满足高速公路场景数字化应用的信息识别精度要求。
虽然本文通过实验研究得到RandLA-Net在同类点云语义分割算法中更适用于高速公路线性带状场景的目标识别计算,但当前主流的几种基于深度学习的点云语义分割算法均需要大量人工标记样本数据进行训练学习,这无疑将增加大量前期工作。提高样本标记效率、提出弱样本依赖的语义分割方法等是未来高速公路线性带状场景目标要素自动识别的研究方向。
猜你喜欢
昆明医科大学学报(2021年6期)2021-07-31
科学(2020年5期)2020-11-26
开放教育研究(2020年2期)2020-03-31
小哥白尼(趣味科学)(2019年2期)2019-04-17
小学阅读指南·低年级版(2017年11期)2017-12-06
中国社会历史评论(2016年2期)2016-06-27
儿童故事画报·发现号趣味百科(2016年3期)2016-06-24
中国交通信息化(2016年9期)2016-06-06
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
