
基于YOLOv5深度学习的茶叶嫩芽估产方法
2022-11-04 09:57徐海东刘星星郑永军田志伟
中国农业大学学报 2022年12期
徐海东 马 伟 谭 彧 刘星星* 郑永军 田志伟
(1.中国农业大学 工学院,北京 100083;2.中国农业科学院 都市农业研究所,成都 610213)
我国是茶叶生产大国,2021年茶叶产量318万t,茶叶产量居世界第一[1]。茶叶估产能够在采收时间和采摘量之间寻求收益最大化时提供可靠的数据支持,直接关系到农户的经济收入。现有的茶叶估产主要依靠茶农的种植经验或直接采摘后称重估计产量,这种方法获取产量信息较为滞后,不能在茶叶生长时期提供相关的产量数据支持,不利于茶叶生长的前期管理。
目前,针对小麦、大豆、油菜等大规模种植的经济作物估产技术已经较为成熟。常用的估产方法有田间抽样调查法、农业气象模型估产法、基于光谱指数的作物估产法、基于图像的作物估产法[2]。田间抽样调查主要步骤为:在大田中按面积等距或者按组平均抽样法选取若干代表性小田块,水稻成熟后,收获小田块中水稻,并对其进行人工脱粒和后续的一系列考种步骤,提取产量相关四因素,进一步利用公式折算出该片田块的水稻产量数据[3]。现有利用农业气象模型估算产量的方法,大都是研究对作物产量贡献性较大的气象因子,分析气象因子之间相关性,进而利用回归建模预估最终作物的产量情况[4],陈冬梅等[5]使用自适应增强的BP模型,结合59个县市的地面气象数据,对浙江省的茶叶产量进行了预测。遥感估产主要利用多光谱相机来获取作物不同光谱波段下的反射指数信息,结合作物农艺学性状,综合构建产量预估模型[6]。王鹏新等[7]使用遥感技术,选取玉米植被温度系数和叶面积指数为特征变量,使用极限梯度提升算法和随机森林算法对玉米单产进行估测,估计了河北中部平原玉米单产。使用气象模型和光谱指数的估产方法主要应用于大规模作物估产,对于个体农户的小规模作物的估产手段还较为缺乏。
随着计算机技术的发展,已经有了很多成熟的深度学习算法用以检测目标的数量,主要可分为2类:一类是以YOLO[8-11]和SSD[12-14]为代表的一阶段快速检测算法,其优点是速度快,但检测精度相对较低;另外一类是以区域卷积神经网络R-CNN[15-17]为代表的二阶段检测算法,优点是准确度高,缺点是速度相比于一阶检测算法较慢。
综上,现有的田间估产主要方法是遥感估产,依赖于遥感数据与样本产量间的映射模型,常用于大规模农作物估产。对于小规模茶园估产,相关研究报道较少。本研究拟使用YOLOv5目标检测算法识别茶叶嫩芽并计算嫩芽数目,再使用田间抽样法,通过目标检测算法获取抽样点的嫩芽数目,并利用最小二乘法建立产量预估模型,最后按照估产模型估算出茶园嫩芽的产量,以期在茶叶生长时期为农户提供茶叶嫩芽产量相关的数据支撑,便于茶叶生产的前期管理。
1 材料与方法
1.1 数据集采集
试验地点位于四川省都江堰市的青城道茶观光园,试验茶叶品种为青城道茶,数据采集时间为分别为2021年4月、7月和9月。
图像采集设备为Intel RealSense D435i摄像头,分辨率为1 920像素×1 080像素。采集春茶、夏茶、秋茶图像共计1 000张,作为试验所用数据集。模型训练测环境为Intel Corei7-10750H CPU@2.60 GHz,NVIDIA GeForce RTX2060,16 G内存,软件环境为Python3.6,Pytorch深度学习框架,操作系统为Windows10。
1.2 图像预处理
使用在线工具makesense.ai对茶叶图像数据进行标注。标注对象为嫩芽的一叶一芽,标注完成后对标注文件进行了归一化处理,使得在训练的时候能够更快地读取数据。
共标注图像1 000张,其中800张用于目标检测算法的训练,200张用于算法的测试。由于训练算法模型需要大量的图像数据,因此对数据集进行数据增强操作。数据增强的方式包括添加噪声、旋转、镜像等步骤(图1),可提高目标检测算法的泛化能力。本试验中,选择添加高斯噪声到原始图像中,这是由于在实际环境中,噪声通常不是由单一来源引起的,而是来自许多不同来源的噪声的复合体。假设实噪声是具有不同概率分布的非常多随机变量的加法和,并且每个随机变量都是独立的,则随着噪声源数量的增加,它们的归一化和将收敛为高斯分布,因此在算法模型中添加高斯噪声可以更好地适应实际场景的应用,提高算法模型的鲁棒性。使用数据增强的方式将原有800张训练集扩充至8 000张。

图1 茶叶图像数据增强Fig.1 Tea image data enhancement
1.3 YOLOv5算法模型
YOLO是一种基于回归的目标检测算法。经过不断的发展,算法迭代到目前最新的YOLOv5系列。与R-CNN系列的目标检测算法相比,YOLO算法在保证精度的前提下显著的提高了模型的运行速度。YOLOv5目标检测算法是基于YOLOv3的改进算法,采用多尺度预测方法,可以同时检测不同大小的图像特征的目标。因此,YOLOv5目标检测算法在算法精度和运行时间方面相较之前版本都有了较大提升,适合用于茶园场景中的茶叶嫩芽检测。YOLOv5目标检测算法的网络结构主要分为Input、Backbone、Neck、Prediction这4个部分(图2)。
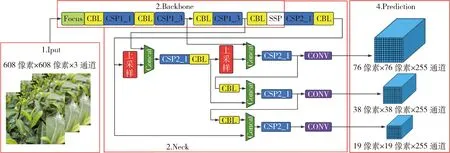
图2 YOLOv5网络模型Fig.2 YOLOv5 network model
YOLOv5目标检测算法的基本原理是:将输入图像分成7×7的网格,每个网格负责预测以该网格单元为中心的目标边界框及其相应的置信度值;生成预测框后,按非极大抑制筛选最后结果(图3)。
1.4 估产模型建立
本研究提出的茶叶嫩芽估产方法分为2部分:1)采集茶叶嫩芽图像数据训练目标检测算法,用以快速地检测出茶叶嫩芽的数目;2)拟合茶叶嫩芽数目与产量间的关系,获得茶叶嫩芽产量。
在标准化种植的茶园中(图4),茶垄的宽度约为100 cm,两条茶垄的间距约为60 cm,茶垄之间分布较为均匀,茶垄的顶部可近似一个平面,茶叶嫩芽竖直生长在茶垄的表面。因此可通过抽样调查法,在茶园中抽取若干抽样点,通过目标检测算法计算抽样点的茶叶数目,并结合抽样面积计算茶叶嫩芽生长密度,进而利用数学模型估算茶园嫩芽产量,本研究用嫩芽的质量表示产量。
根据抽样点茶叶嫩芽数量建立估产模型步骤如下。
1)计算出抽样区域面积S,根据识别的茶叶嫩芽数Ne,估算幼苗种植密度Re:
(1)
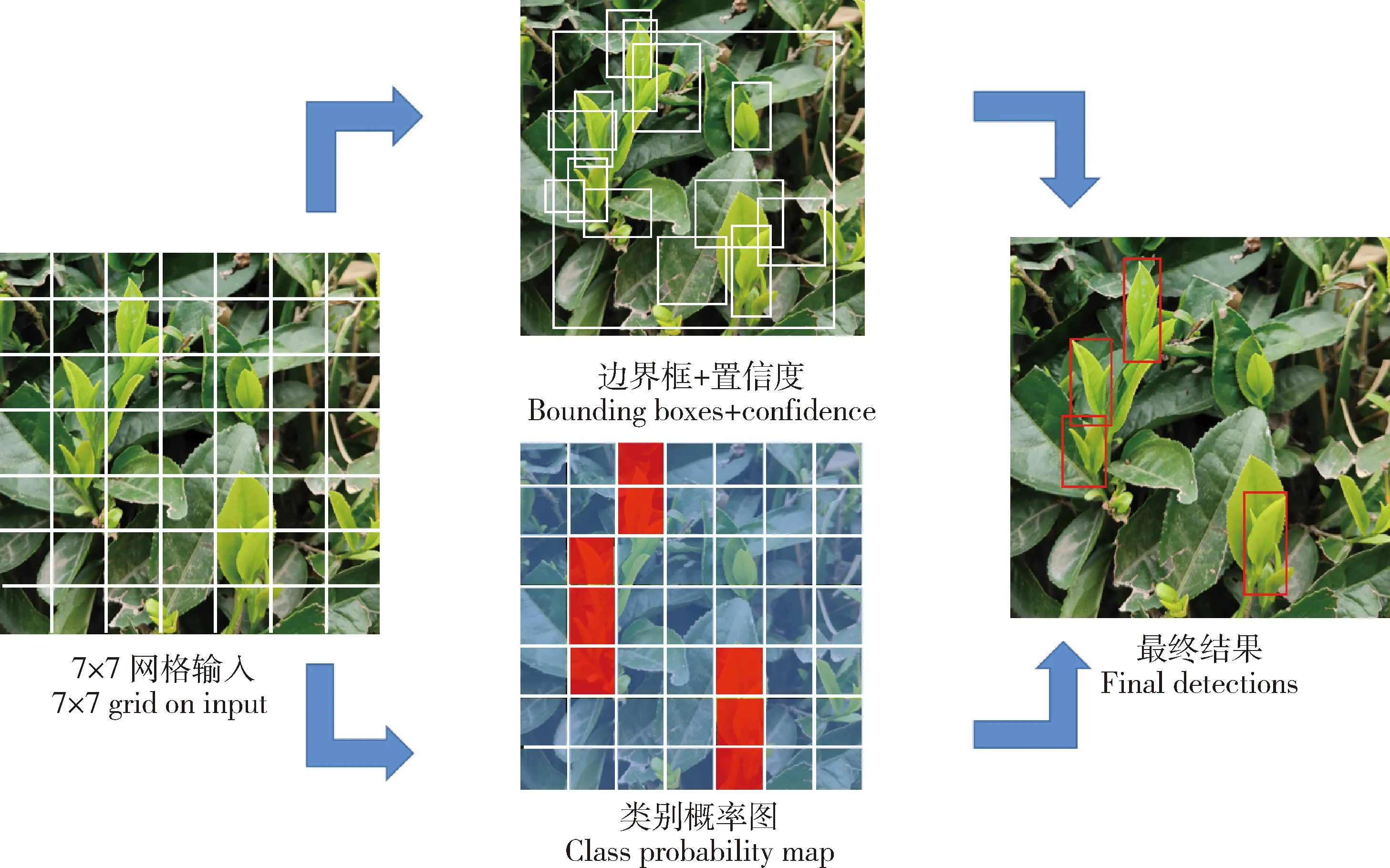
图3 YOLOv5检测原理Fig.3 YOLOv5 detection principle

图4 标准化种植茶园整体图Fig.4 Overall view of the standardize tea plantation
2)根据茶场总面积ST估算茶叶嫩芽总数P:
P=ReST
(2)
3)根据嫩芽数量与产量之间的关系确定茶园总产量M:
M=k·P+b
(3)
式中:k为线性关系的比例系数;b为偏差。
4)联合式(1)、(2)和(3)可得出茶叶产量M的计算方法:
(4)
2 结果与分析
2.1 茶叶嫩芽数目与产量的关系
在茶园中采收约500 g茶叶嫩芽,茶叶嫩芽的外形特征见图5。嫩芽高度约为18 mm,宽度约8 mm,大小分布较为均匀,因此可初步做出假设,茶叶嫩芽的数目与质量之间有较好的线性关系。

图5 茶叶嫩芽外形特征Fig.5 Tea shoot shape characteristics
设计试验从人工采收的嫩芽中称取10,20,…,80 g共8份茶叶嫩芽,每个质量独立称取3次(称完一次质量后需将嫩芽放回,重新从采收到的嫩芽中称取该质量的嫩芽),记录每个质量下的茶叶嫩芽数目,计算3次嫩芽数目的平均值,最后利用最小二乘法拟合出茶叶嫩芽数目与质量间的关系(图6)。
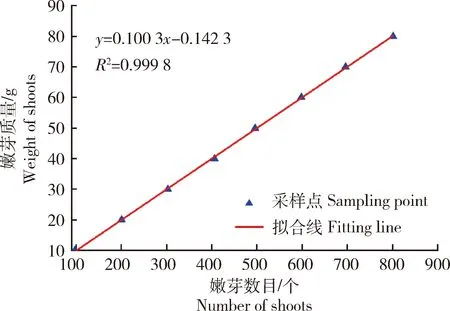
图6 茶叶嫩芽数目与质量的线性关系Fig.6 Linear relationship between number of tea shoots and quality
最小二乘法确定茶叶嫩芽与质量之间的线性关系为:
M=0.100 3P-0.142 3
(5)
线性拟合关系中,决定系数R2=0.999 8,表明茶叶嫩芽的数目和质量之间有高度线性关系,因此使用茶叶数目估计茶叶产量是可行的。
2.2 YOLOv5训练结果及不同算法对比分析
2.2.1评价指标
为评价图像识别算法的性能,本研究选取精度(P)和平均准确率(Mean average precision,MAP)作为算法的主要评价指标。计算公式分别如下:
(6)
(7)
式中:TP(True positive)表示正样本预测正确的数量;FN(False negative)为负样本预测错误的数量;FP(False positive)为正样本预测错误的数量;TN(True negative)为负样本预测正确的数量;p(r)为不同查准率r下对应的查全率;Api为第i类的检测准确率,N为类别数量。
2.2.2YOLOv5训练结果分析
茶叶嫩芽检测模型共训练3 000次,结果见图7。可见,训练达到约300次时模型精度提升最快,在500次左右时模型精度趋于稳定,最终模型的精度为99.02%。在训练到500次左右模型平均准确率提升较快,在2 500次左右趋于稳定,最终平均准确率为90.14%,基本满足茶叶嫩芽检测需求。
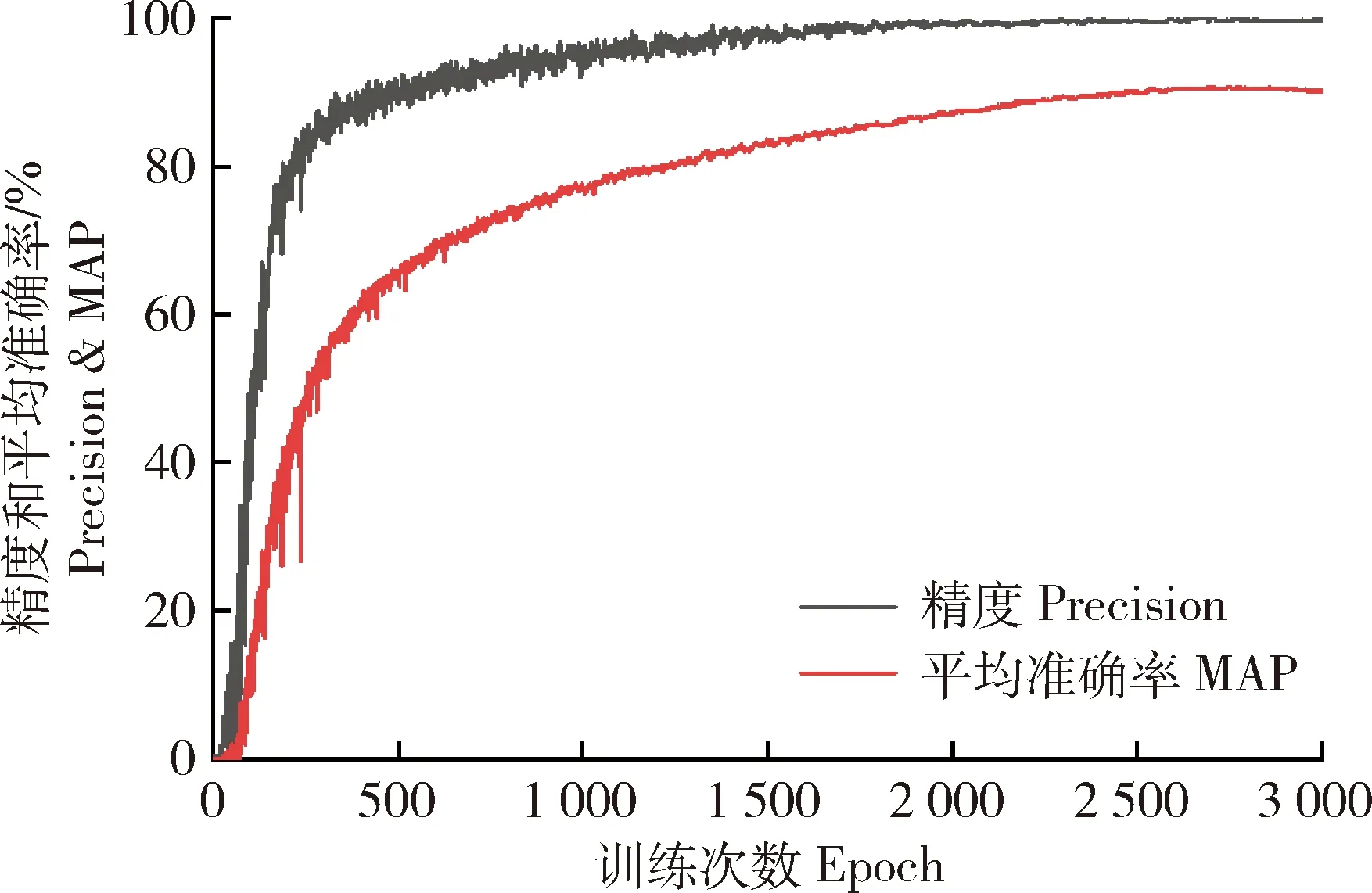
图7 茶叶嫩芽检测模型训练结果Fig.7 Tea shoot detection model training results
2.2.3不同检测算法对比分析
表1示出YOLOv5、SSD和Faster R-CNN算法对相同数据集的训练结果。在平均检测时间上,YOLOv5对单张图片的处理时间为9 ms,略优于SSD,明显优于Faster R-CNN。这是由于使用了一阶检测算法的YOLOv5和SSD在对图像进行处理的时候无需先生成特征框,使得其识别速度快,要优于使用二阶检测算法的Faster R-CNN。
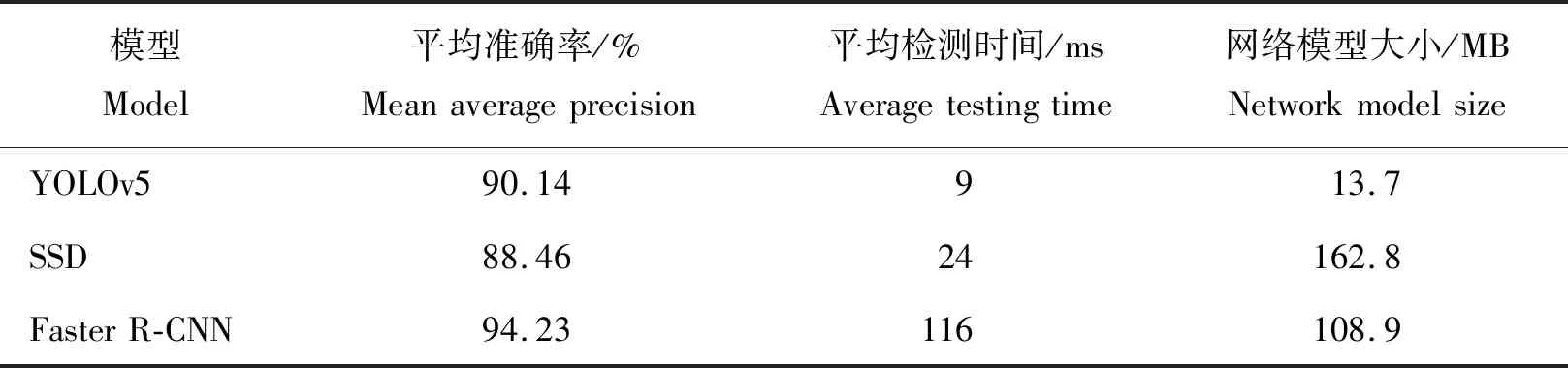
表1 YOLOv5、SSD和Faster R-CNN算法对相同数据集的训练结果Table 1 Training results of YOLOv5,SSD and Faster R-CNN algorithms on the same dataset
在图像识别的准确率上,使用二阶检测算法的Faster R-CNN的平均准确率达到94.34%高于YOLOv5和SSD,但差距不太明显。在网络模型的大小上,YOLOv5的优点体现的较为明显,仅需13.7 MB,这使得YOLOv5适合在移动设备上使用。
综合考虑平均准确率、检测时间和网络模型大小后选择使用YOLOv5作为茶叶嫩芽的目标检测算法。
2.3 田间估产试验与分析
2.3.1评价指标
本研究使用相对误差δ作为估产方法精度的评价指标,具体公式为:
(8)
式中:x表示估计产量;μ表示实际产量。
2.3.2估产试验
估产试验用到的茶叶图像采集装置见图8,该装置由摄像头、图像采集架和电脑组成,采集架的底部长和宽都为50 cm,抽样区域面积为0.25 m2。摄像头将采集到的图像送入目标检测算法中处理,先利用算法识别出抽样区域内的茶叶嫩芽数量,再结合抽样面积和茶园茶叶种植面积估算出茶园嫩芽总体数量,最后将嫩芽数量带入式(5)估算出茶园茶叶产量。估产试验在3条茶垄中随机抽取了9个抽样点,每条茶垄宽约1 m,长约50 m,试验茶垄总面积为150 m2,茶园茶叶种植面积约为20 000 m2。

1.摄像头;2.图像采集架;3.图像采集区域;4.电脑1.Camera;2.Image acquisition bracket;3.Image acquisition area;4.Computer图8 茶叶图像采集装置Fig.8 Tea image acquisition device
田间试验中抽样点的茶叶嫩芽识别结果见表2。可见,嫩芽个数分布较为均匀,9个抽样点嫩芽平均个数为12.11个,结合抽样区域面积可计算嫩芽平均生长密度为48.44个/m2,可以此密度估算茶园茶叶嫩芽产量。抽样点嫩芽的识别效果见图9,可以看出本研究算法可以准确的识别出抽样区域的茶叶嫩芽。
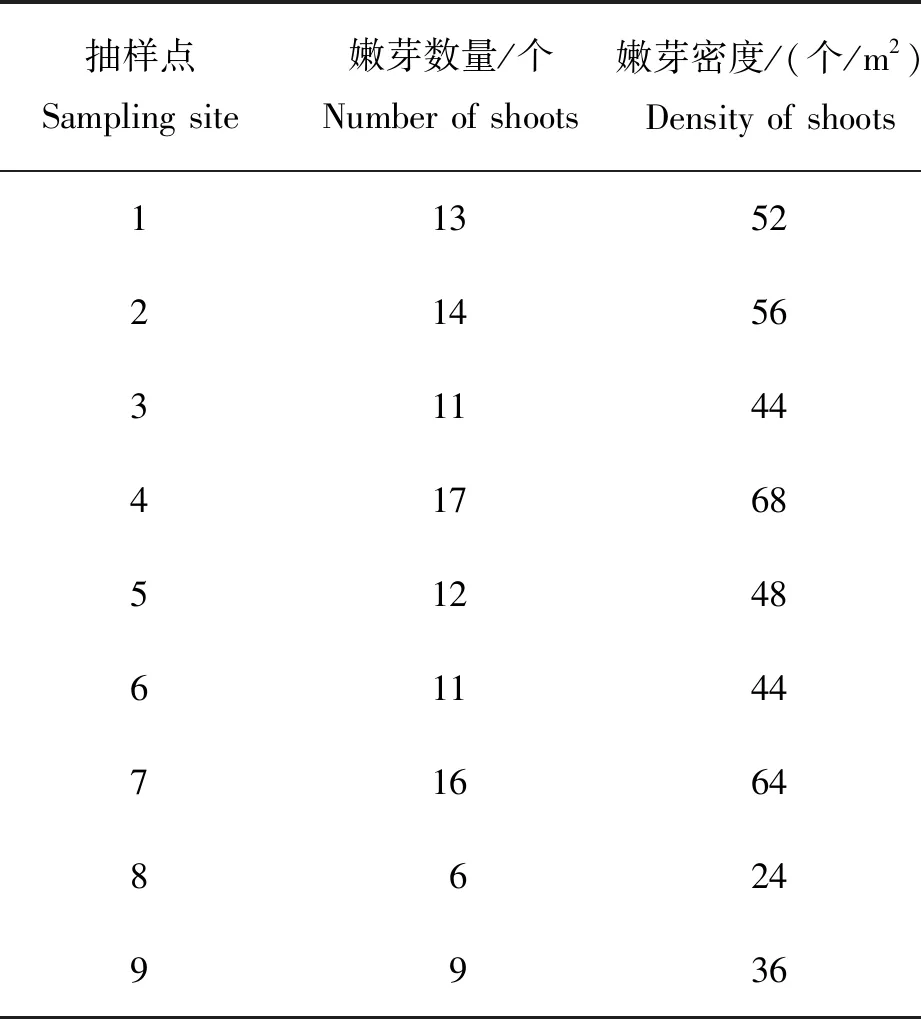
表2 抽样点茶叶嫩芽识别结果Table 2 Identification results of tea buds at sampling points
由抽样点茶叶嫩芽数量和嫩芽密度(表2)结合茶园面积可估算出茶园茶叶嫩芽产量,结果见表3。对于茶叶种植面积为150 m2的试验茶地,估计产量为0.73 kg,实际采收产量为0.58 kg,相对误差为25.86%。对于茶叶种植面积为20 000 m2的茶园,估计产量为97.17 kg,实际采收产量约为75 kg,相对误差为29.56%。综上,利用图像数据识别的方法估计茶园嫩芽产量基本可行。

1.识别到的茶叶嫩芽;2.图像采集架1.Identified tea buds;2.Image acquisition bracket图9 抽样点茶叶嫩芽识别效果Fig.9 Identification effect of tea buds at sampling points
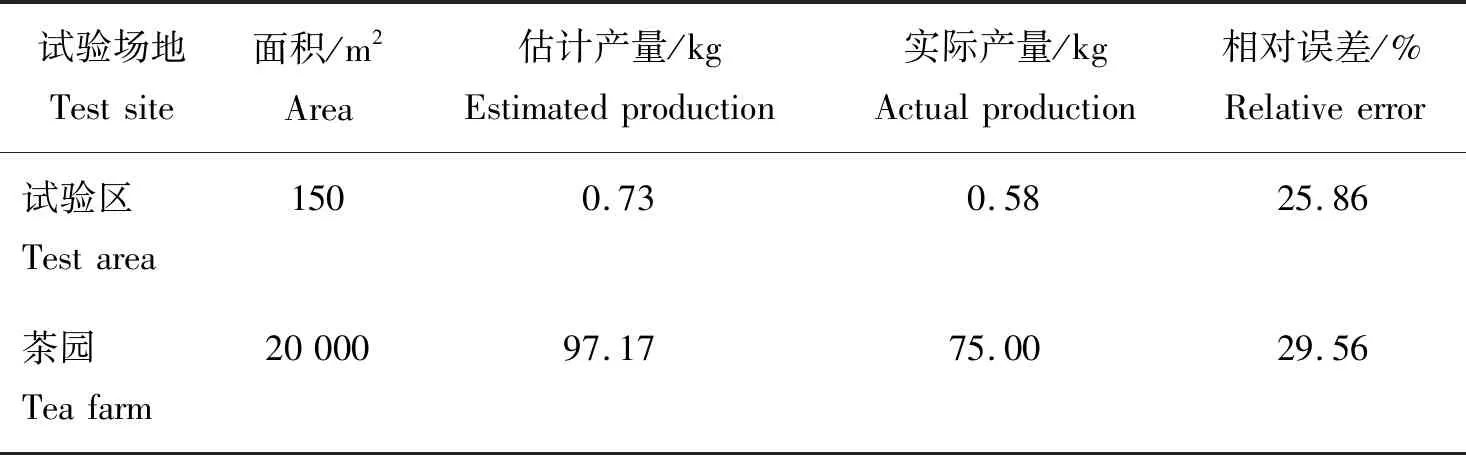
表3 茶园茶叶嫩芽估产结果Table 3 Yield estimation results of tea buds in tea farm
3 结 论
本研究提出了一种基于YOLOv5的茶叶嫩芽估产方法,并在田间展开相关试验工作验证此方法的可靠性。主要结论如下:
1)YOLOv5算法可以用于茶叶嫩芽检测。本研究算法对于茶叶嫩芽识别精度为99.02%,平均准确率为90.14%。
2)本研究算法可快速的估计出茶叶嫩芽产量。嫩芽估计产量与实际采收产量相对误差为29.56%,证明本研究算法具有一定的可行性。如增加抽样点样本数量、提高茶场有效种植面积统计精度,可以进一步提茶叶嫩芽估产的准确性。
对于小规模的茶叶产量估计,本研究在传统的田间抽样调查法的基础上做出改进,用图像识别的方式替代了人工识别嫩芽,以抽样点的茶叶生长情况为依据估算出茶园嫩芽的产量,为小规模茶园农户提供茶叶嫩芽产量相关的数据支持,便于茶叶生产的前期管理。下一步可将本估产方法移植到手机中,农户可通过手机摄像头拍摄茶叶照片,快速的估计出茶园嫩芽产量。
猜你喜欢
儿童时代·幸福宝宝(2022年10期)2022-11-23
茶叶通讯(2022年2期)2022-11-15
红蜻蜓·低年级(2021年2期)2021-07-20
小学生学习指导(高年级)(2021年6期)2021-06-19
心声歌刊(2021年6期)2021-02-16
创造(2020年5期)2020-09-10
湘潮(上半月)(2019年3期)2019-05-22
小学生必读(低年级版)(2019年6期)2019-01-14
乡村地理(2018年1期)2018-07-06
百科知识(2018年7期)2018-04-17
