
风机叶片结冰故障预测模型研究
2022-11-01 02:46张吴飞李帅帅李嘉成
农业装备与车辆工程 2022年9期
张吴飞,李帅帅,李嘉成
(200082 上海市 上海理工大学 机械工程学院)
0 引言
风力发电中叶片结冰问题长期困扰各国。低温运行环境导致的风叶结冰,使风机出现材料性能和载荷能力变化等问题,对风机的发电性能和安全运行构成巨大威胁,在这种条件下工作,增加了叶片断裂和损坏的风险。目前最大的问题是,难以准确预测早期结冰的过程,从而提前启动除冰系统[1]。SCADA 系统每天产生大量的数据,但目前大多数系统仍局限于故障报警,这些故障往往在达到报警阶段时已经非常严重,需要关闭风机进行检修,造成发电和维护费用的巨大损失。SCADA 系统产生的数据可以通过挖掘和建模来进行一些严重的故障预测和诊断,因此过去强调的维护模式可以转化为积极的预测维护模式,可有效提高利用率,降低风力发电设备的运行和维护成本[2]。
国内外在故障预测与诊断方面的研究已经比较成熟。Shin[3]等在NASA 的结冰风洞对翼型做了很多结冰验证,研究了结冰条件下结冰形状及冰层传热、冰滴释放的潜热等;Frohboese[4]等研究了覆冰对风力发电机疲劳载荷的影响,估计出风机结冰量并对结果进行了讨论;Zhou[5]等采用支持向量机(Support Vector Machine,SVM)算法对风机叶片结冰进行检测;Peng[6]等通过动态主成分分析提取关键特征,并结合埃尔曼人工神经网络(Elman artificial neural network,EANN)对风机叶片结冰故障进行预测。
本文着重研究了风机结冰状况,提出了一种在采样平衡处理下对白天黑夜2 种模式自动判断并分别预测的算法,比较了该算法与传统算法的模型精度以及传统采样处理和平衡处理的精度差异,证明该采样处理和算法的优越性。本文还以另一风机数据(18 号风机)为测试数据集,进一步证明该算法的优越性和泛化能力。
1 数据分析与预处理
1.1 离群点剔除
本次数据集为采样的SCADA 数据集,采样时长2 个月,共采集样本30 万条数据,其中结冰数据2 万多条,正常数据35 万多条,无效数据2 万条左右。16 号风机数据为训练集,18 号风机数据为测试集相关特征,16 号风机样本总数为393 886 条,结冰数据为23 846 条,正常数据为350 255 条,无效数据为19 785 条;18 号风机样本总数为190 494 条,结冰数据为10 638 条,正常数据为168 930 条,无效数据10 926 条。
本数据集共包括时间戳、风速、发电机转速、对风角、偏航位置、偏航速度等28 个变量,包含运行参数、所处环境参数等多个维度特征。在剔除无效数据后,发电机转速(generator-speed)、偏航速度(yaw-speed)、ng5_2温度(pitch2_ng5_tmp)、ng5_3温度(pitch3_ng5_tmp)存在离群点,设置合适的阈值对离群数据进行剔除,如图1 所示。
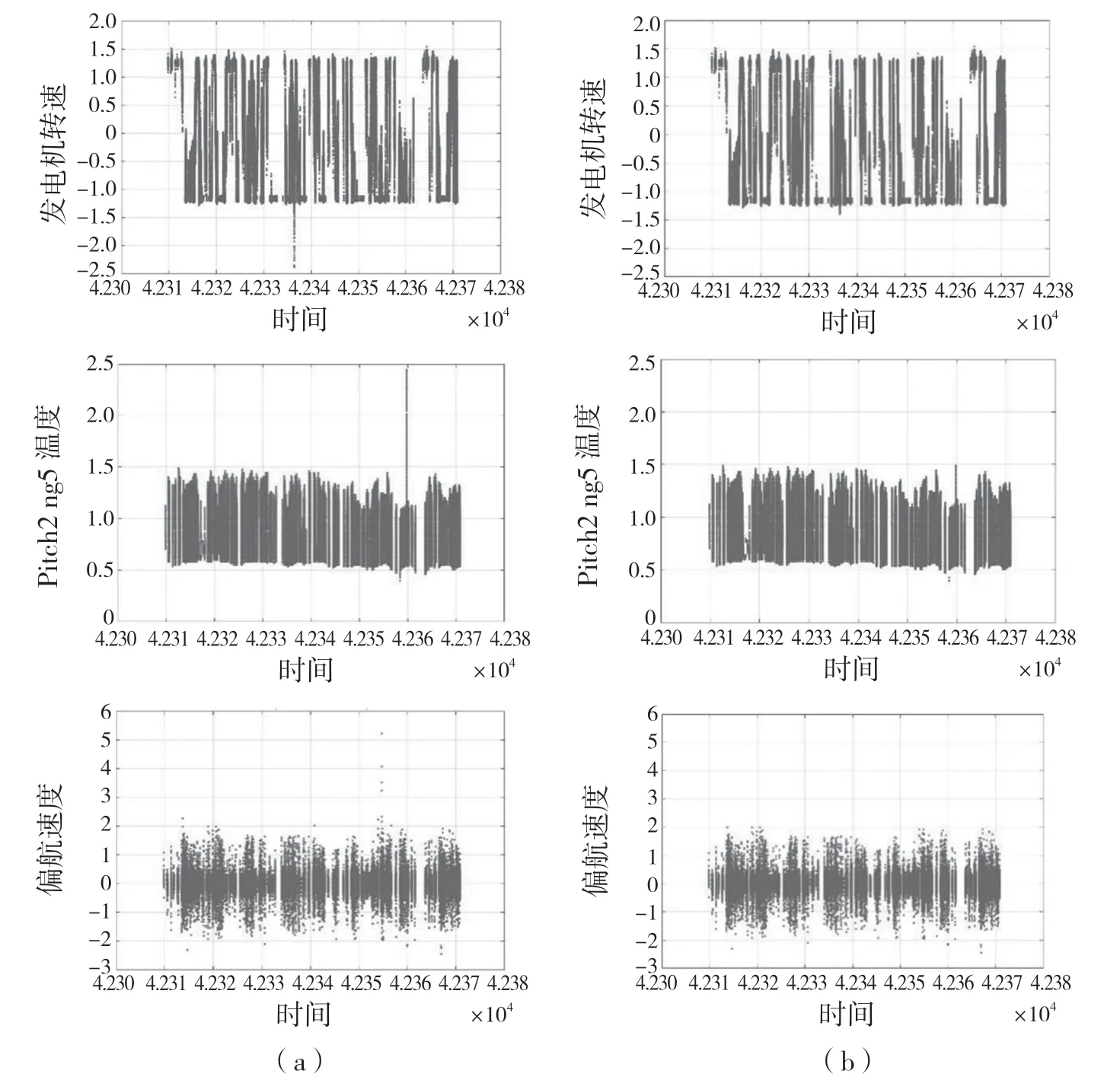
图1 离群样本筛查与坏点剔除前后的数据-时间分布对比Fig.1 Data-time distribution comparison before and after outlier sample screening and bad spots elimination
1.2 不平衡数据均衡化
训练数据16 号风机的样本总数393 886 条,其中结冰数据23 846 条,正常数据350 255条,无效数据19 785条。测试数据18 号风机的样本总数190 494 条,其中结冰数据10 638条,正常数据168 930 条,无效数据10 926 条。存在严重的类不平衡。为消除类不平衡,一般采用数据均衡化处理,常用方法有减少采样、增加采样等。权衡考虑到降采样带来的原始数据丢失,以及过采样引入的估计(非原始)数据,本文采取降采样与过采样相结合的方法,尽可能规避单纯采用过采样或降采样带来的弊端。其中过采样采用了SMOTE 结合ENN 的方式,降采样采用随机抽样(Random Under Sample)的删除方式。
SMOTE 算法基本思想是,通过在少数类样本之间进行插值,从而获得额外的样本[7]。具体地,对一个少数类样本Xi使用K近邻法,求取距离Xi距离最近的K个少数类样本。本次求解中,采用样本之间n维特征空间的欧氏距离作为临近判据,从K个近邻点中随机选取一个,使用式(1)生成新样本。

式中:——选出的K近邻点;δ——一个随机数,δ∈ [0,1]。
ENN算法基本思想是剔除离群的多数类样本。本文采用SMOTE+ENN 结合的方法清除更多重叠样本,使得过采样的样本能够更好地贴近原始数据。
为了分析降采样和过采样对于分类预测模型的影响,本文对原始数据集(记为数据集1)、仅使用过采样得到的数据集(记为数据集2)和使用过采样+降采样得到的数据集(记为数据集3)分别进行比较,其中原始数据共374 146 条,结冰数据和正常数据分别为23 892 和19 739,过采样共699 881 条,正常数据和结冰数据分别对半,过采样+欠采样混合共37 379 条数据,正常数据和结冰数据各占一半;其次,为了分析类间均衡化对于数据集变量间耦合关系的影响,给出3 个数据集的相关关系热力图,如图2 所示。

图2 原始数据集与均衡化数据集变量间相关关系热力图Fig.2 Heat diagram of correlation between variables of original dataset and equalized dataset
由图2 可知,重采样之后变量相关关系基本无变化,因而采样操作并未使得采样后数据偏离原数据,所以采样后的结果是可信的。
2 特征工程
2.1 降维
原始数据集各特征间存在耦合关系,在进行特征提取与特征重构之前,需要对数据预处理之后的数据集进行变量之间的相关关系分析,从而达到降低维度减少运算量的目的。基于此目的,绘制26个变量的相关关系热力图,如图3 所示。
由图3 可知,在26 个变量中,其中的3 组变量具有比较强的相关关系,分别为风机角度(1、2、3)、风机速度(1、2、3)、变桨电机温度(1、2、3),因而可以用均值分别代替这9 个原变量,作为新的特征供后续模型学习预测。
2.2 特征提取与构造
由于风机结冰问题的分析和求解依靠高性能算法实现,具有很大的局限性,因此需要结合变量间的实际物理意义,对其中某些变量进行线性、非线性组合运算,得到新的特征变量,用于大数据预测分类模型的构建。
(1)温差Tmpdiff:表征环境温度与机舱温度的差值,温差绝对值越大,机舱结冰可能性越高,公式为:
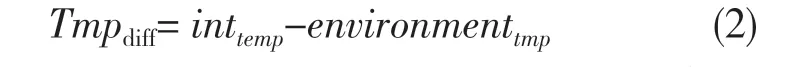
式 中:Tmpdiff——温 差;inttemp——机舱温度;environmenttmp——环境温度
(2)扭矩Torque:表征风机转动所需克服的阻力,所需克服的阻力越大,扭矩越大,机舱结冰可能性越高,公式为:
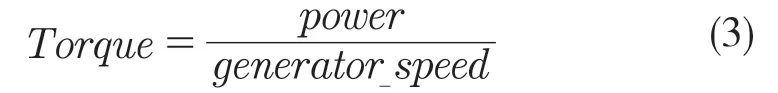
式中:power——功率;generator_speed——发电机转速
(3)功率系数Cp:表征风机发电功率与风速大小的相对关系,功率系数越低,机舱结冰可能性越高,公式为:

式中:power——功率;wind_speed——风速均值。
(4)推力系数Ct:表征风力推动风机转动的阻尼程度,阻尼程度越高,推力系数越高,机舱结冰可能性越高,公式为:
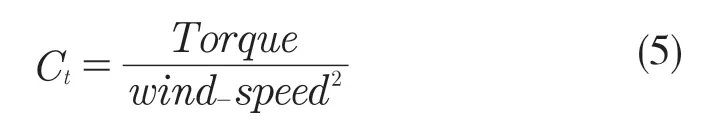
式中:Torque——扭矩;wind_speed——风速均值
(5)速率比Lambda:表征风机转速与风速的相对大小关系,速率比越低,机舱结冰可能性越高,公式为:

式 中:generator_speed——电机转速;wind_speed——风速均值。
3 实验模型建立
3.1 随机森林
决策树(Decision Tree)是在已知各种情况发生概率的情况下,直观地利用概率分析,形成决策树,得到净现值的期望值大于0 的概率的一种图形化方法[8]。随机森林是随机建立一个森林,许多决策树都参与其中形成这个森林,每棵决策树彼此之间没有相关性。每次有新的样本时,森林中的每棵决策树都会对其类别进行判断,并通过投票选出票数最高的类别作为最终的分类结果,将风机特征参数传入随机森林模型得到的分类结果如图4 所示。
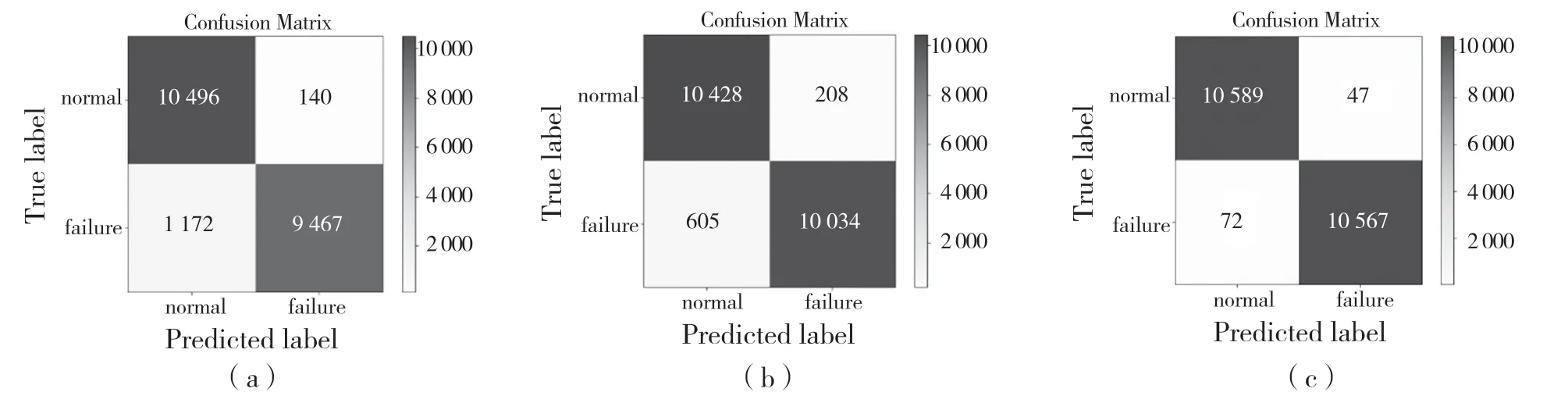
图4 随机森林模型类间结果对比Fig.4 Comparison of results between classes of random forest model
3.2 卷积神经网络
卷积神经网络本质上是输入到输出的映射网络,该方法避免精确的数学解析表达式。通过学习大量输入输出之间的映射关系,利用已知的模式训练卷积神经网络,使神经网络具有输入输出之间的映射能力。卷积神经网络由卷积层、池化层和全连接层组成。卷积层的权重取决于特征的提取和共享,特定数据点与局部数据点周围的关系紧密。与全局像素之间的关系距离较远,卷积层通过卷积将相邻区域内的数据点过滤在一起进行卷积,使其能更好地提取局部特征。通过各层的卷积,可以进一步扩大卷积的范围,使特征具有全局意义。
由于风机结冰不是一蹴而就的,具有较强的连续时间趋势关系,因此需要综合考虑多维变量和时间信息对分类结果的影响。基于上述考虑,对于卷积神经网络的输入数据进行滑窗选取的操作,过大的窗宽虽然包含了更多的时间维度信息,但会不可避免地造成数据处理量的增加,不利于算法效率的提高;而过小的窗宽会造成时间维度信息不足的缺陷,不能够很好地体现连续时间信息对于风机结冰情况预测的重要作用。本实验中选取了步长为1、窗宽为64 的方案,将某一条数据及其之前的63 条数据作为CNN 的输入,CNN 的输出选为该数据所对应的“正常/结冰”标签,进行卷积神经网络模型训练,最终训练结果如图5 所示。

图5 卷积神经网络模型类间结果对比Fig.5 Comparison of results between classes of convolutional neural network model
3.3 基于CNN 的白天黑夜模型
基于卷积神经网络的时序分类算法,其预测正确率很大程度上依赖于训练数据量的大小。如果希望减小训练数据量,一方面可通过对原始数据集进行数据预处理完成,另一方面可通过优化模型结构达到较少训练数据量的目标。本问题求解中,考虑到白天与黑夜不同时间段风机结冰情况的差异,采用预测融合的方法,以达到能够更具针对性地处理数据的目的。共构建了3 个子卷积神经网络,第1 个卷积神经网络依据数据特征,对所处时间段是白天或黑夜进行判断;第2 个和第3 个卷积神经网络分别为基于白天数据与基于黑夜数据训练的卷积神经网络模型。数据首先通过第1 个卷积神经网络进行白天黑夜判断,依据判断结果,再将数据分别对应送入白天或黑夜的子预测模型中,以更具针对性地对数据结果进行预测。由于是二分类问题,本文对白天黑夜判别模型采用交叉熵损失函数,如公式(7)。预测结果如图6 所示。

式中:yt——某个样本点的真实标签;yp——该样本点取yt=1 的概率。
构建模型超参数设置如表1 所示。

表1 多融合模型参数设置Tab.1 Parameter setting of multi-fusion model
考虑到深度学习模型中的过度拟合问题,采用了 dropout 技术。在训练 CNN“白天黑夜”模型时,需要设置学习率控制参数的更新速度,表1 给出了CNN“白天黑夜”模型的超参数设置,预测结果如图6 所示。

图6 混合模型不同类间结果对比Fig.6 Results comparison among different classes of the mixed model
4 实验结果对比
基于不同运行数据集运行上述4 种模型,记录不同数据集、不同模型下的模型准确率及运行时间,结果如表2 所示。
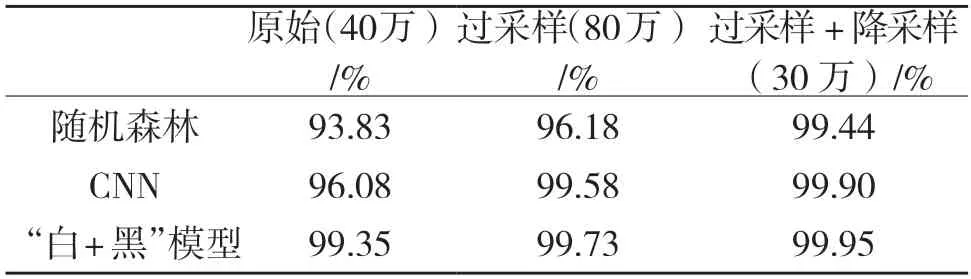
表2 多模型预测结果评估Tab.2 Evaluation of multi-model prediction results
为证明CNN“白天黑夜”模型以及均衡数据的有效性和优越性以及均衡数据,本文将此模型与典型分类器模型对比。纵向比较表格,以评估不同算法在预测问题中的表现。可以明显看出,采用以随机森林、CNN 为代表的非线性分类器在该预测问题中表现优异。随着过程中对模型的进一步改善,可以看到本文提出的基于CNN 的白天黑夜模型表现最为优异,这样的结果也是符合预期的;横向比较表格,以评估数据均衡化对预测问题准确性的影响。通过平衡数据集,能够有效地预防预测模型过拟合的情况,从而提升模型的泛化能力与准确性。可以明显看出,通过对模型进行过采样、降采样操作,以改善类间数据的不平衡性,对于模型的预测结果有较好的改善效果,结果同样符合预期。
5 结语
本文提出了通过均衡化处理与基于CNN 的“白天黑夜”模型相结合,可以有效提高风机叶片结冰的预测精度,对于风机故障诊断有一定参考价值。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
作文周刊·小学一年级版(2022年24期)2022-06-18
机电信息(2022年9期)2022-05-07
中国水运(2022年4期)2022-04-27
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小天使·一年级语数英综合(2019年2期)2019-01-10
中国化工贸易·中旬刊(2018年6期)2018-10-21
小学生导刊(低年级)(2017年1期)2017-06-12
城市建设理论研究(2014年37期)2014-12-25
