
一种多源传感器数据层叠降维分类融合器设计*
2022-10-25 08:25叶成景郭海涛陈红玲杨叶芬
传感技术学报 2022年8期
叶成景,郭海涛,陈红玲,杨叶芬*
(1.广东科学技术职业学院机器人学院,广东 珠海 519090;2.华南理工大学土木交通学院,广东 广州 510640)
近几年,多源传感器技术进入了一个高速发展阶段,各项技术逐渐成熟,使得多源传感器的应用范围越来越广泛。 多源传感器的主要作用是对监测范围内的多样化信息进行采集,并经过重定位后传送至汇聚节点内进行统一处理[1]。 由于传感器种类众多,为提升传感器寿命,相关研究学者提出在传送数据之前,通过数据融合[2]对其进行整合、特征提取和融合处理,以此来减少传感器节点的通信错误率。 一些国内外学者针对多传感器的融合问题提出了一些比较好的方法。
文献[3]研究了一种复杂环境下的多传感器数据融合方法,根据信任度结果,引入证据迭代融合思想,从证据源层面对证据冲突进行修正。 融合修正后的证据数据,即实现多传感器数据的融合。 文献[4]提出基于流形学习的多源传感数据融合方法,采用T-SNE 算法将高维多源传感器数据进行降维处理,更新低维概率矩阵,使多源传感器数据距离较小点之间产生合理的排斥梯度,完成数据融合。 文献[5]提出基于数据相关性的多传感器数据融合方法,采用MDF 技术识别组别数据中的隐藏关联特征,通过融合关联特征完成多传感器数据的融合。文献[6]针对无人机的检测与跟踪提出一种多传感器数据融合方法,度量数据集的可信度,根据可信度结果,构建高斯过程模型,完成多传感器数据融合。但是,以上方法在融合过程中,都存在效率较低的问题。
为了提高多源传感器数据分类与融合的质量,此次研究从深度学习的角度出发,针对多源传感器提出了一种新的数据融合方法。
1 基于深度学习的层叠自动降维分类器(SAESM)设计
本文利用深度学习算法设计层叠自动降维分类器(SAESM),处理多源传感器中的低维数据,得到理想的特征提取结果。 具体实现过程如下详述。
数据降维,将数据从高维特征空间向低维特征空间映射的过程,可以避免杂乱、无效数据的干扰,提高运算质量与效率。 设计的自动降维分类器(SAESM)是一种单隐层结构,SAESM 结构图如图1 所示。

图1 SAESM 结构图
输入层,指输入到神经网络中的数据,输入数据必须是数值,也就是说非数值的内容需要转化为数值,通常情况下,数据处理过程是创建机器学习模型最耗时的部分。
隐含层,由神经网络中的大多数神经元组成,是处理数据以获得所需输出的核心部分。 数据将穿过隐含层,进行许多权重和偏差调节。
输出层,是在神经网络中处理数据的最终产物,可以表示不同的事物。 通常情况下,输出层由神经元组成,每个神经元代表一个对象。
SAESM 降维分类器的目标是寻找传感节点中的最优融合参数(W,b),融合参数决定了数据融合的性能,选取最优融合参数可以提高数据的融合能力。
寻找多源传感网络全局最优解对分类过程的初始权值和阈值进行优化[7],深度学习训练的过程本质是对权重进行更新,在对一个新的模型进行训练之前,需要每个参数有相应的初始权值,初始权值的选择对于局部极小点的放置和网络收敛速度的提高均有一定程度的影响;神经元是一个多输入单输出的非线性单元,输入之和需要超过一定数值时,输出才会有反应,这个数值一般称为阈值。
使输入的传感节点信息x在输出结果y的作用下实现降维,以此获得隐藏层的输出结果a(k,2),并将a(k,2)看作是输入项经过降维处理后得到的特征结果,用于分类。
在计算过程中,要确保a(k,2)的特征具有稀疏鲁棒性,就要通过三个约束函数来实现,如式(1)所示:

为了控制损失函数值最小,通过梯度下降算法对传感器网络中的参数进行训练,实现降维。 具体实现过程如下详述:
步骤1 对所有层数l,使单元偏置变量参数满足ΔW(k,l)=0、Δb(k,l)= 0;
步骤2 将i的取值范围设定在1 ~m之间,计算公式为:
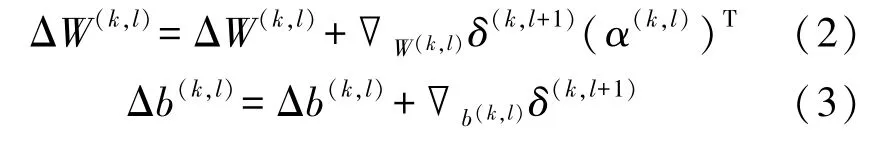
式中:α(k,l)表示l层单元n的损失参数,δ(k,l+1)表示l+1层中单元n的残差,T表示损失约束项。
步骤3 更新算法中的参数值:
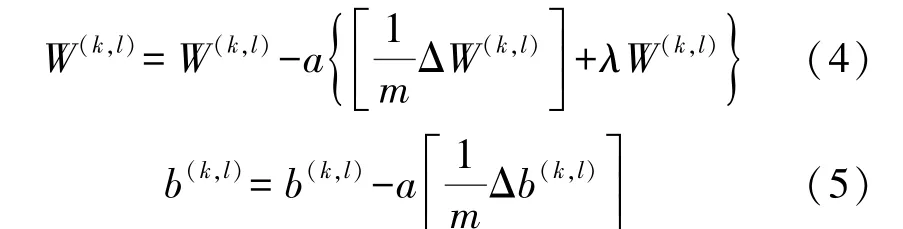
步骤4 返回步骤2,循环计算,直至满足预先设定的条件时输出(W(k,1),b(k,1),W(k,2),b(k,2))。
完成以上降维处理后,设计分类器。
层叠自动分类器SAESM 是由若干个降维处理器经过层层级联作用后得到的,SAESM 有一个明显的优点,输入项在经过多次降维处理后才会输出结果,剔除了大部分的冗余信息。 SAESM 中各个层的参数值都可以通过贪婪算法计算得出,即使用上一个层的输出结果作为下一个层的输入项,具体实现过程如下所示。
将SAESM 中的隐藏层层数设置为Nk层,输入数据x经过贪婪算法的处理后,得到参数和输出结果a(1,2),过程如图1(a)所示。 再将a(1,2)作为输入项,经过下一轮的贪婪算法[8]后得到输出结果a(2,2),过程如图1(b)所示。
重复训练过程,对含有Nk层AE 的SAESM 经过逐层贪婪训练后得到参数组为{(W(k,1),b(k,1))|k=1,…,Nk|},将(W(k,1),b(k,1))看作SAESM 各个层级之间的连接权重值。 多源传感器编码分类器如图2所示。

图2 多源传感器特征分类模型
特征提取的结果对后续数据融合的准确率起到决定作用,是数据能否顺利完成融合的关键所在。所以,通过级联作用,将SAESM 和Softmax 分类器结合在一起,实现了特征分类。 实现过程如下:
步骤1 通过训练样本无监督训练无线传感网络节点数据,以此获得参数{(W(k,1),b(k,1)) |k=1,…,Nk};
步骤2 经过训练后,得到传感节点数据特征,经过有监督训练和Softmax 分类器的作用,输出参数(Wc,θc);
步骤3 将步骤1、步骤2 所得的参数看作原始数据。 在SAESM 模型中,通过有监督训练算法对原始数据进行调整,然后将调整后的传感器网络和Softmax 分类器[9]作为特征提取模型中的提取模块和分类模块,完成多源传感数据的特征提取与分类。
2 多源传感器的数据融合方法设计
根据上文构建的特征提取分类模型,完成多源传感器数据的特征提取与分类,以此为基础进行多源传感器的数据融合研究。
在本文的研究过程中,为了使结果更倾向于理想结果,选取的多源传感器具备以下三点性质:
①传感器中各个节点都具备一个单独的ID 号码,确定位置后不再进行移动。 各个节点之间的初始能量是相同的,不可互相补充;
②将汇聚节点的位置设定在感知区域以外,固定且不可移动,电源补给充足,对于传输到此的数据具有超强的计算和存储能力;
③汇聚节点处的功率较其他节点来说较大,所以可直接向其他节点传输数据。 各个节点都可自主感知到其所在的位置。
多源传感器数据融合方法的实现过程为:
①根据传感器下达的指令,汇聚节点首先转换数据类型,并从数据存储库中选取与之对应的包含标签信息的样本数据作为输入数据,根据上文提到的训练方法对多源传感器数据的分类特征进行训练;
②簇内节点在接收到训练完成的数据后,根据多源传感器数据特征,然后将特征数据传送至簇首节点;
③根据分簇协议要求[10-11],将多源传感器内部网络进行分簇,并选取一个合适的簇首节点,该节点的主要作用是整合所有节点信息表,然后统一传输给汇聚节点,汇聚节点对这些信息表融合处理;

④簇首节点通过Softmax 分类器的作用,按照类别的划分用式(6)的方法进行同类特征融合:式中:Nc表示特征数据划分的类别数量,c表示特征数据的类别号,nc表示特征数据的个数,α(Nk,nl)(i,c)表示经过SAESM 的训练后,最终得到的样本数据特征[12],本文将其确定为c类特征。
通过上述过程,在已知多源传感数据特征分类结果的基础上,结合多源传感器的分簇性质,在Softmax 分类器的作用下,实现多源传感器数据的融合。
3 实验验证
3.1 多源传感器参数
由于此次需要验证多源传感器数据融合的效果,因此需要对多源传感器进行选择。 为了提高实验结果的真实性,选择的传感器有SHT30 温湿度传感器与MPU9250 磁场姿态角度传感器。 两种传感器可以采集多种数据类型,包括温湿度数据、磁场数据、姿态数据以及角速度数据,可以满足多源传感器数据融合的实验要求。
SHT30 温湿度传感器与MPU9250 磁场姿态角度传感器参数分别如表1 与表2 所示。

表1 SHT30 温湿度传感器参数

表2 MPU9250 磁场姿态角度传感器参数
3.2 实验数据
两种传感器的运行时间均设定为6 h,采集两种传感器在6 h 内的运行数据。 由于两种传感器的精度较高,因此并不需要对所采集的数据进行滤波处理,可以直接用于实验研究。
SHT30 温湿度传感器与MPU9250 磁场姿态角度传感器所采集的数据分别如图3 与图4 所示。

图3 SHT30 温湿度传感器数据

图4 MPU9250 磁场姿态角度传感器数据
将上述数据用于数据融合的实验研究,以充分证明所提出方法的融合性能。
3.3 实验环境
为了验证所提方法在多源传感器数据融合方面是否合理有效,与基于流形学习的融合方法[4]、基于数据相关性的融合方法[5]进行对比仿真分析验证。仿真分析在MATLAB 平台上实现,通过C++进行仿真编程。 为了使仿真分析公平合理,所提出方法、基于流形学习方法、基于数据相关性方法均选择未优化的LEACH 协议和第一类传感器通信能耗模型:

式中:d表示多源传感器内部各个节点之间的坐标距离;Eelec表示多源传感器发送/接收节点所消耗的能耗,通常情况下Eelec=50 J;εamp表示多源传感器在传输数据过程中所消耗的能耗,εamp=100 J;Efuse表示数据融合过程中产生的能耗,Efuse=0.5 J。
3.4 实验结果分析
3.4.1 特征提取分类性能
对所提出方法、基于流形学习方法、基于数据相关性方法在特征分类方面的性能进行对比仿真分析,对比仿真分析结果如表3 所示。 其中,l表示网络层数。
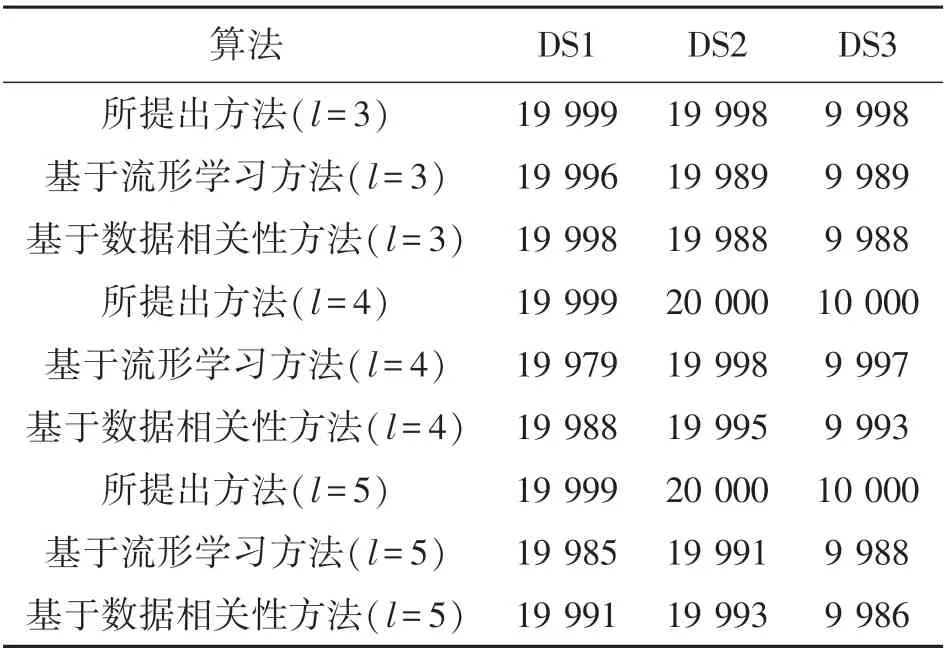
表3 特征提取结果
从表3 中可以看出,对于三种类型的多源传感器数据,不管网络层数怎样变化,所提出方法特征提取分类正确的样本数量明显高于基于流形学习方法与基于数据相关性方法。 这是由于所提出方法在构建SAESM 模型时,通过不断增加隐藏层的个数使得模型具有更加优秀的特征提取分类效果,同时避免了算法陷入局部极值,所以,所提出方法具有较强的特征提取分类效果。
3.4.2 数据融合能耗性能
通过上述分析可知,实验数据集中的样本类别共计100 种,对不同数据融合方法的能耗性能展开对比仿真分析。 所提出方法、基于流形学习方法、基于数据相关性方法的数据融合能耗对比结果如图5所示。
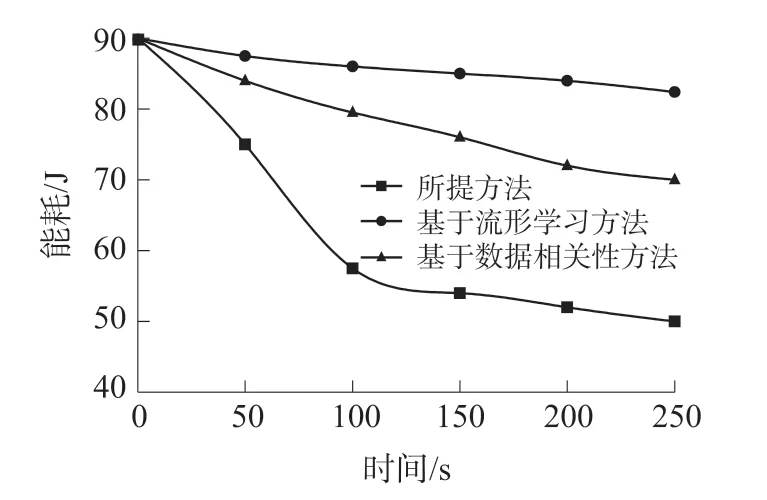
图5 能耗对比结果
从图5 中可以看出,所提出方法、基于流形学习方法、基于数据相关性方法在处理数据融合时都具有一定的节能优势,而基于流形学习方法与基于数据相关性方法的能耗均高于所提出方法,其中,基于流形学习方法的能耗最高,基于数据相关性方法的能耗次之,所提出方法的能耗最少。 这是由于所提出方法特征提取分类步骤在簇首节点已经完成,传输至融合阶段的数据已经经过分类处理,因此,降低了数据融合能耗。
3.4.3 融合后数据噪声对比
经过数据融合后,多源传感器中的数据量明显减少,但融合后的数据中含有一定的干扰噪声数据,而一旦噪声过大,则会降低融合后多源传感器数据的质量。 因此,有必要对所提出方法、基于流形学习方法、基于数据相关性方法融合后的噪声数据含量进行对比验证。 融合后的噪声数据含量对比结果如图6 所示。
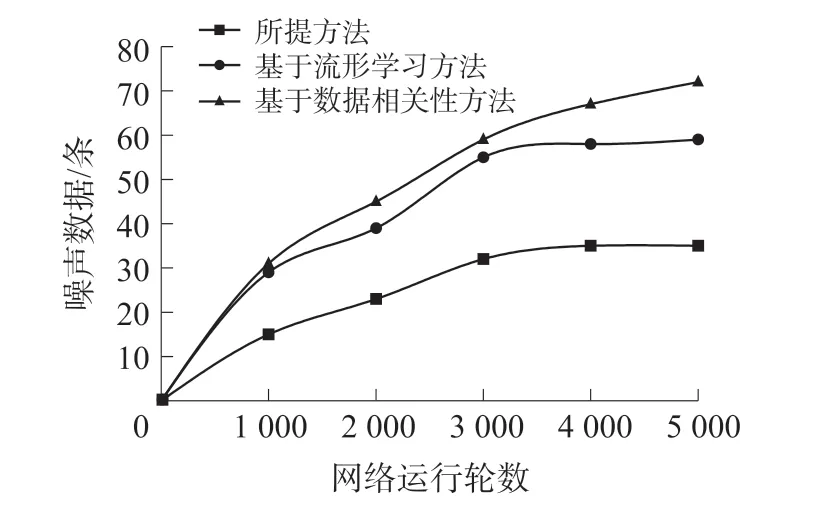
图6 融合后噪声数据量对比
从图6 中可以看出,所提出方法与基于流形学习方法的在3 000 轮左右,噪声数据量逐渐趋于平稳,而基于数据相关性方法的噪声数据量持续增加,并且所提出方法融合后的噪声数据量远远低于基于流形学习方法与基于数据相关性方法。 这是由于所提出方法运用了SAESM 模型进行特征提取与分类,可以对不同类别的数据进行更好的融合,降低了数据之间误差,使得融合后的噪声数据量明显降低。
4 结论
基于多源传感器采集数据量大、复杂程度高的特点,为了满足实际需求,运用深度学习自编码器理论,对多源传感器数据融合方法进行了深入研究。从理论与实验两方面对融合方法的性能进行研究,该方法在进行多源传感器数据融合时,能够准确地进行数据的特征提取分类,降低了数据融合能耗,并且融合后噪声数据量明显降低,大大提高了多源传感器数据融合的质量。 因此,所提出方法具有十分明显的优势,能够为多源传感器数据融合技术的发展提供一种新的参考思路。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
车主之友(2022年4期)2022-08-27
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
汽车实用技术(2022年4期)2022-03-07
计算机系统应用(2021年2期)2021-02-23
海峡姐妹(2019年12期)2020-01-14
电机与控制学报(2018年9期)2018-05-14
软件导刊(2017年4期)2017-06-20
计算机应用(2016年10期)2017-05-12
