
基于多特征融合卷积神经网络的年龄预测
2022-10-24 01:38廖黄炜
计算机技术与发展 2022年10期
廖黄炜,马 燕,黄 慧
(上海师范大学 信息与机电工程学院,上海 200234)
0 引 言
人脸图像中存在如性别、年龄、面部表情、种族等个体特征的重要信息,在人的交互交流中至关重要,其中人脸年龄作为一种生物及社会特征,在人类社交中起到了重要作用,而人脸年龄预测已经成为人机交互和计算机视觉的重点研究领域,其在市场分析、人机交互、安全监控等领域应用前景广阔。
年龄预测[1-2]的难点在于受个体差异和图像拍摄的光照、角度、遮挡等影响,图像与实际年龄差距较大。另外,年龄是一个缓慢变化的参数,很难从年龄角度描述年龄相仿图像之间的区别。而年龄标注的公开数据集数量少且人数规模小,深度学习方法依赖算力和数据,模型学习时长不足以及数据不足难以达到拟合。
针对以上问题,该文对年龄预测应用传统图像特征提取技术设计卷积核,结合缩减的卷积网络,提出综合传统图像特征处理技术的深度学习方法——多特征融合卷积神经网络的年龄预测方法。
1 相关工作
随着近年来深度学习的提出与发展,基于深度学习的人脸年龄预测方法得到了快速的发展。目前基于深度学习算法的年龄预测研究主要集中在拟合年龄分布提高精度和构建小模型支持小样本训练两个方面。
在拟合年龄分布提高精度方向上主要分为以下三类:
基于回归方法的年龄预测,将年龄类别视为线性渐进关系学习空间映射特征。Li等人[3]提出使用本地回归器划分年龄数据区域,门控网络模拟构建回归森林提供连续年龄权重,通过回归加权组合得到估计年龄。
基于多分类方法的年龄预测,将年龄视作独立的标签单位,转化为分类问题。Rothe等人[4]提出基于卷积网络的分类的期望值进行年龄预测,同时搭建了IMDB-WIKI人脸数据集作为预训练数据集;李大湘等人[5]针对样本数量不平衡及不同年龄间发生误分类时付出代价不同的问题,提出深度代价敏感网络,同时设计对应的CS-CE损失函数,有效优化年龄估计性能。
基于标签编码方法的年龄预测,把年龄转化为连续编码标签,利用多节点拟合标签。Chen等人[6]进一步将二分类器转化为卷积网络中的节点值,提出Ranking-CNN模型,实现端到端的序列化年龄预测模型;Zeng等人[7]提出soft-ranking编码方法,在保持序列化特性的同时可以有效区分临近年龄特征。
构建紧凑模型支持小样本训练上,Gao等人[8]提出深度标签分布学习(deep label distribution learning,DLDL),为利用年龄标签中不确定信息,将年龄转换为离散正态分布标签,并将深度标签分布与Ranking分布内在数学关系相关联;Yang等人[9]提出SSR-Net网络,采用由粗到细的策略逐阶段动态范围调节预测年龄;Zhang等人[10]采用多尺度特征拼接的方法,通过两级串行监督补偿小模型的拟合问题。
从紧凑模型出发,该文提出基于融合特征提取的卷积神经网络的年龄预测模型,主要工作和创新包括:(一)模型利用传统图像处理中滤波技术的特征提取优势,构建多种小波卷积核,以这类卷积核构成的小型卷积网络作为浅层特征提取的网络,适用于训练样本较少的情况;(二)通过融合浅层特征和引入注意力机制,主干网络可缩减至1/4的卷积核数,模型整体缩小;(三)综合上文拟合年龄分布方法提出多组合的序列化年龄损失函数,使得模型对预测图像损失补偿更加精确。模型整体计算量少,体积小,适合小样本迁移。模型在有限的训练样本和相对较短的时间下,在MORPH和ChaLearn15数据集上取得了较高的准确率。
2 方法原理
2.1 特征提取设计
卷积神经网络(CNN)可以视为由多个卷积层和池化层组成的特征提取器,其核心在于卷积层的设计。卷积层中通常包含若干个特征平面,同一特征平面的神经元共享权值,即卷积核。卷积核可由随机小数矩阵形式初始化,并在网络训练过程中学习得到合理的权值。卷积层通过大量计算换来感受野的同时,也会随着卷积网络的层数增加失去图像低维度的特征同时成倍数地引入冗余特征。
另一方面,传统的特征提取技术如小波变换[11]可以快速提取到图像的边缘轮廓信息。在卷积神经网络中,每个卷积核可以看成一个滤波器,利用小波滤波技术构成特殊的滤波器代替原有的卷积核,以此达到减少训练参数,同时在数据量较小时仍能提取到图像鲁棒特征的目的。Sarwar等人[12]提出使用Gabor滤波器替换网络中的部分卷积核,减少网络的训练复杂度,同时在分类任务上达到与CNN网络类似的准确率。Liu等人[13]提出使用离散小波变换(DWT)作为卷积核的卷积层改造网络,在图像超分辨率重建和图像去噪上取得较好的效果。在此启发之下,该文使用Gabor小波和双树复小波作为卷积核设计改造特征提取网络。
2.1.1 Gabor滤波器
Gabor小波[14]与人类视觉系统中简单细胞的视觉刺激响应较为相似,在提取目标的局部空间和频域信息这两方面有较好的特性。该文提出使用单层Gabor滤波器改造卷积核的卷积网络(GCN)提取人脸图像的方向性和尺度性特征。Gabor小波对图像的边缘敏感,能够提供良好的方向选择性和尺度选择性,并且对光照变化不敏感。二维Gabor滤波公式如下:
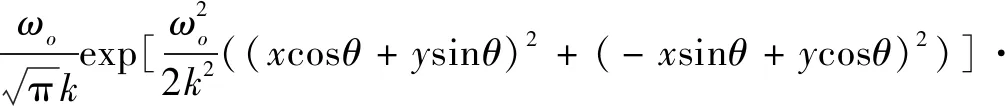
sinωo(xcosθ+ysinθ)
(1)
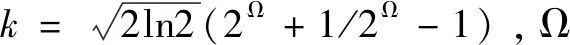
2.1.2 双树复小波滤波器
小波变换的卷积网络能够在提取图像高频信息的同时,保留低维度信息从而恢复图像细节。受文献[11,15]启发,以Mexico小波制作滤波器,其公式如下:
(2)
YLL,(YLH,YHL,YHH)=Mexico(Y)
(3)
其中,公式(2)为小波函数,公式(3)为输入尺寸为(h,w)的原始图像Y,输出得到下采样图像YLL,以及横向细节YLH、纵向细节YHL、斜向细节YHH,其尺寸为(h/2,w/2)。
正交的小波变换只对下采样图像YLL做进一步分解,而对高频部分即信号的细节部分不再继续分解,因此,小波变换能够较好地表征以低频信息为主要成分的信号,但不能很好地分解和表示包含大量细小边缘或纹理等细节信息的信号。为解决上述问题,该文提出使用双树复小波设计单层卷积网络(WCN)。双树复小波[16]具有近似的平移不变性,信号的平移不会导致各尺度上能量的分布变换。同时具有良好的方向选择性,能反映图像不同分辨率上多个方向的变化情形。同时数据冗余度较小,对于二维图像为4∶1冗余占比。
双树复小波通过离散小波变换实现,双树复小波对图像X(z1,z2)分解可表示为:
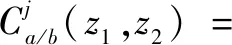
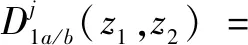
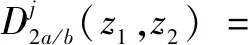
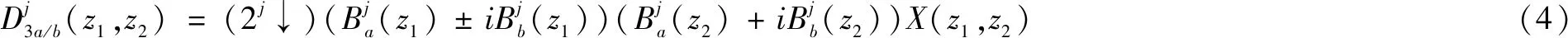
其中,(2j↓)表示以2j向下采样,下标a和b分别对应±中的+和-。即双树复小波变换在每一层一共有4个共轭复数滤波对,包括2个低频子带和6个高频子带,高频子带方向分别为±15°、±45°、±75°。利用WCN反映图像在不同分辨率上的方向属性可以更好地提取人脸图像上的纹理和边界的特征。
2.2 模型设计
2.2.1 多特征融合提取网络
该文提出的多特征融合的卷积网络模型框架如图1所示。该模型由多特征融合提取、注意力机制模块和损失函数设计三部分组成。首先输入人脸图像,由GCN、WCN和CNN多特征融合提取,接着引入注意力机制模块的深度神经网络(SE+1/4 ResNet-34)进一步提取年龄特征,最后根据真值年龄生成的序列化标签,经组合损失函数优化标签分布学习得到预测年龄。
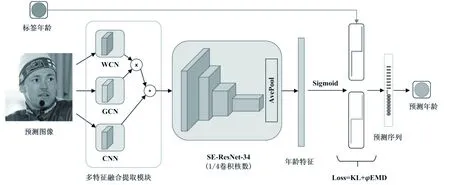
图1 多特征融合年龄预测模型框架
针对年龄预测问题,网络需要加强人脸图像的特征提取能力而忽略不重要的背景内容,即模型需具有人脸的关注能力。引入文献[17]提出的基于通道加权的关注度模块(SE Module),改造特征骨干网络为SE-ResNet-34,由于特征融合网络已经做了精准的特征提取,骨干网络可以减小卷积核数以减少冗余特征,该文采取1/4倍率缩小骨干网络的卷积核数量。
2.2.2 损失函数设计
损失函数是计算年龄特征向量的预测值与年龄标签之间差异的函数,用来描述预测值与标签值的拟合程度,损失函数的设计应当与标签相匹配。人脸年龄在主观认识下是连续的,比起年龄数值标签,连续化的标签更符合预测年龄的结果。参照文献[6]提出的序列化标签方法,把数据集的年龄范围[0,n]编码成n个二分类器,第i(i∈[1,n])个二分类器表示当前图像年龄是否大于i岁,得到n长度的年龄标签,把年龄预测问题简化为二分类问题,通过二分类器的累加计算预测年龄。
二分类器通常通过交叉熵学习节点权重,每个二分类器都有权重系数,得到每个分类器在数据集上的权重分布。为了在训练中得到拟合的结果,该文提出对比标签序列和预测序列的相对熵方法来设计损失函数。相对熵(relative entropy)又称为KL散度(Kullback-Leibler divergence),用来描述两个概率分布之间的差异,计算公式如下:
(5)
其中,p表示年龄标签分布,q表示年龄预测分布,则LKL(p‖q)表示用分布q拟合标签分布p时产生的信息损耗。相对熵使得每个分类器训练得到数据集的权重分布,同时可以更好表现两个序列之间的差异性从而获得更准确的损失值。
为减少冗余,使用单个节点和Sigmoid激活函数完成二分类器激活工作。假设预测年龄N∈[0,100],公式如下:
(6)
(7)
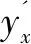
由于训练图像样本的不足以及样本年龄分布的不均,个别二分类器会出现未拟合的情况,如图2所示,可能出现如下两种坏情况。为保持二分类器与年龄序列的一致性,保证分类器始终处于依次激活状态,应避免情况B的出现。

图2 二分类器序列坏情况A和B
为解决以上问题,该文借鉴文献[18]提出的EMD方法,损失函数LEMD公式如下:
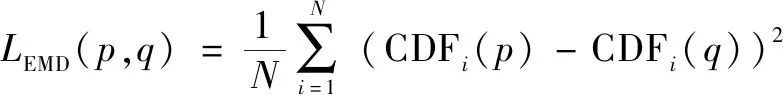
(8)
其中,N为数据集样本数量,p和q分别为网络预测和标签,CDFi为序列化标签[0,i]的累积分布函数。利用损失函数LEMD约束连续序列化,通过累积分布函数差使序列化的损失值始终控制在序列递增水平,从而使得二分类器顺序激活。
综合以上损失函数方法,该文提出使用相对熵约束年龄序列分类器的准确性,而用EMD保证年龄序列分类器的连续性特性,设计的损失函数L(p,q)公式如下:
L(p,q)=LKL(p‖q)+φLEMD(p,q)
(9)
其中,p和q分别为网络预测和标签,φ为超参数,控制EMD对模型的介入程度,实验表明,当φ=0.2时可以得到最佳的预测结果。
3 实验设置与评价指标
3.1 实验设置
在MORPH数据集[19]、IMDB-WIKI数据集[4]和ChaLearn15数据集[20]上进行实验。MORPH数据集拥有来自超过13 000人共有55 134张彩色人脸图像,年龄分布在16~77岁。通常使用5折交叉验证划分训练集和测试集。IMDB-WIKI数据集是目前公开的最大的人脸真实年龄数据集,数据均来自IMDB和Wikipedia,图片质量不高,其中,IMDB包含460 723张人脸图片,WIKI包含62 328张,年龄分布在0~100岁。ChaLearn15是首个包含真实年龄和表象年龄的数据集,共4 699张人脸图像,其中训练集2 476张,验证集1 136张,测试集1 087张。所有图像的表象年龄由至少10人标注并取均值得到。
数据集经人脸识别模块过滤非人脸图像后,根据得到的人脸关键点对齐人脸眼睛并统一裁剪填充为256×256尺寸,再缩放为128×128尺寸,在训练集上,随机裁剪为120×120尺寸。为了扩充训练集,随机使用水平翻转、旋转15度、对比度增强,在验证集和测试集上根据中心裁剪为120×120尺寸。
实验使用卷积神经网络基于Pytorch 1.7框架实现,在一台GeForce GTX1660 6G显卡配置电脑上训练。提出的模型均直接在年龄数据集上做训练。所有网络使用Adam优化器,设置优化器参数为β1=0.90、β2=0.99和ε=10-8。在IMDB-WIKI数据集上以每批次64张图片,训练200轮次,初始学习率为0.001,在100轮次和150轮次减小学习率为目前的10%,在MORPH和ChaLearn15数据集上修改初始学习率为0.000 1。
3.2 评价指标
在年龄预测的研究中主要采用的是平均绝对误差(mean absolute error,MAE)[1],平均绝对误差是指预测年龄与真实年龄差值的绝对值,公式为:
(10)
累积分数(cumulative score,CS)[1]是另一个常用的研究指标,反映不同误差阈值下的年龄预测的准确率,计算公式如下:
(11)
其中,e为真实年龄与预测年龄差的绝对值,j为累积分数可接受的差值阈值,Ne≤j是测试样本中真实年龄与预测年龄差的绝对值小于j的样本数量即可容忍的年龄误差,N是测试样本总数。
ε-error[20]是描述模型在ChaLearn15表象数据集上预测性能的指标,数据集上包含表象年龄的均值和方差,ε-error定义为:
(12)
其中,x为年龄预测值,σ和μ为表象年龄的均值和标准差,ε越小则年龄预测越准确。
4 实验结果与分析
对比提出的不同模块和损失函数组合的网络在MORPH数据集上的性能表现,如表1所示。所有的模型都经过IMDB-WIKI数据集预训练后,在MORPH训练集上进行训练,在测试集上测试MAE指标。
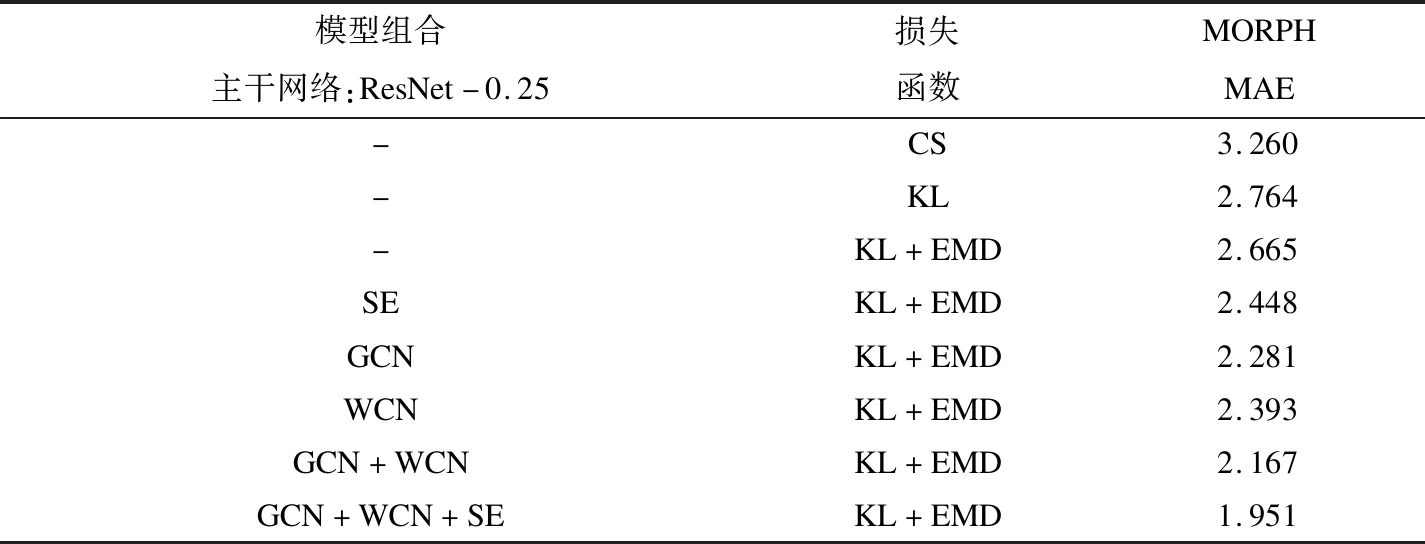
表1 模块和损失函数组合模型在MORPH上的性能
损失函数中相对熵和平均绝对误差的组合要优于相对熵和交叉熵的拟合表现。SE模块增强了模型对图像中人脸的关注度,增加SE模块的网络相比直接使用卷积网络大幅提升了模型性能表现。利用GCN和WCN提取图像特征对比CNN来提取特征在MORPH数据集上表现更好。通过以上对比实验可知,由GCN和WCN组合提取特征,SE模块组合的网络在相对熵和平均绝对误差组合的损失函数下得到最佳的性能表现。
文中算法在ChaLearn15和MORPH数据集上的预测性能表现如图 3所示,其中L为标签年龄,P为预测年龄。由于MORPH数据集拍摄背景较为单一, 拍摄角度相对固定,因此,得到较好的预测效果。ChaLearn15数据集采集自网络,大部分图像有复杂的背景,预测效果仍能保持在2岁误差左右,其中,第六、七幅由于图像模糊和老年数据样本过少而表现不佳。

图3 文中算法在ChaLearn15和MORPH上的预测性能表现
为进一步验证文中算法的有效性,选择近年算法进行对比实验。具体对比算法如下:大模型算法有DEX[4]、Ranking[6]、BridgeNet[3]、Soft-ranking[7]、CS-CE CNN[5],紧凑模型算法有SSR-Net[9]、DLDL-v2[8]、C3AE[10]。
各算法在MORPH和ChaLearn15数据集下的性能表现如表2所示。部分模型未知其模型内存,根据主干模型内存大小估计及VGGNet约为500 MB,ResNet约为180 MB。其中大模型有现有的经ImageNet图像分类数据集预训练的主干模型,在原有模型基础上增加对年龄的拟合处理和训练。紧凑模型对主干模型有较大改动,因此需要自行进行对ImageNet的预训练或无需预训练。模型除标注有对比模型外均在IMDB-WIKI人脸年龄数据集上预训练,测试阶段分别使用MORPH和ChaLearn15数据集进行测试,使用平均绝对误差对实验结果进行评价,ChaLearn15数据集额外使用ε-error作为评价标准。文中算法在紧凑模型算法下保证最少的预训练下得到了最好的预测性能,对比大模型算法保持了较好的预测性能且模型内存占用远低于该序列下的模型。
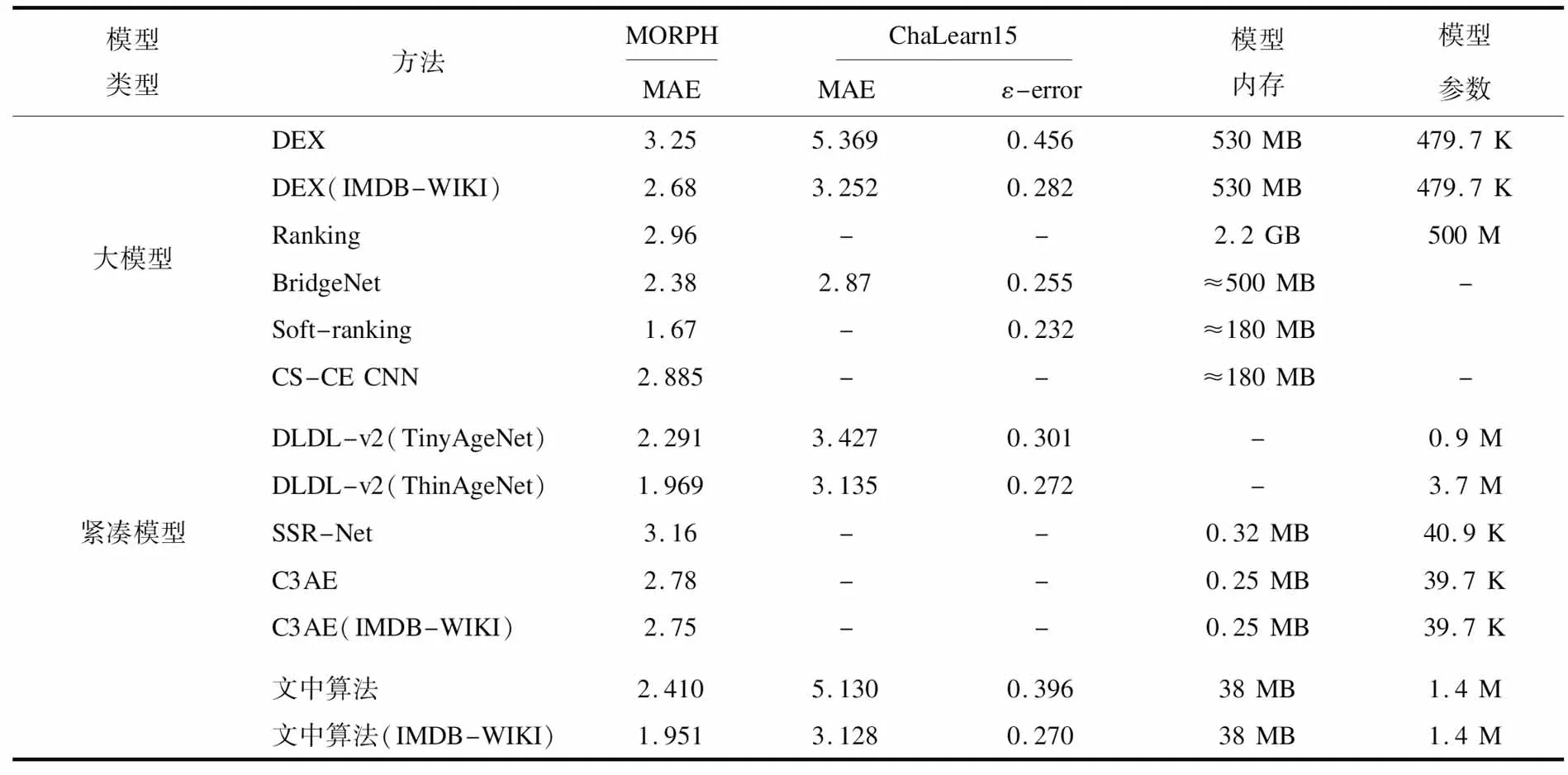
表2 MORPH和ChaLearn15数据集下不同算法的性能对比
文中算法有效构建了支持小样本数据集的紧凑模型,同时保证了预测精度。对比近年一些代表性大模型算法,模型迁移和学习成本低,大大降低了该算法模型的硬件需求。对比紧凑模型,文中算法对比上述算法有精确度的优势,且重新设计的紧凑网络不依赖大型分类数据集如ImageNet等的预训练,只需在人脸数据集上进行训练即可得到较高的精度,从而降低了模型训练时间。此外,序列化的标签设计更适用于年龄预测任务。
5 结束语
针对提升网络特征提取能力和增强小样本数据的拟合能力,提出基于滤波技术的卷积网络GCN和WCN,在此基础之上提出多特征融合提取网络,并设计适合年龄预测的标签和损失函数。实验结果表明,提出的网络可有效提升年龄预测精度,且仅需要人脸数据集上训练,迁移和学习成本低。下一步可对该网络进一步轻量化去冗余处理,以提高年龄预测速度。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
计算机系统应用(2021年9期)2021-10-11
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机测量与控制(2019年4期)2019-05-08
