
基于WPD-AGTO-DELM 模型的年径流时间序列预测
2022-10-24 04:22梁晓鑫崔东文
三峡大学学报(自然科学版) 2022年5期
梁晓鑫 崔东文
(1.云南省水文水资源局 文山分局,云南 文山 663000;2.云南省文山州水务局,云南 文山 663000)
径流时间序列预测是揭示径流自身演变规律性的一种有效而可靠的方法,有效提高径流时间序列预测精度对防洪抗旱规划、水资源管理保护、水库优化调度等具有重要意义.目前,径流预测模型大致分为回归模型[1-2]、机器学习模型(如人工神经网络[3-5]、支持向量回归机[6-7]、随机森林[8-9]、相关向量机[10-11]、自适应神经模糊推理系统[12]等)和组合模型[13]3类,均在径流预测研究中得到广泛应用.
由于径流时间序列影响因素众多,常表现出较强的非线性、非平稳性和多尺度等特征,因此,基于“分解-预测-重构”多种方法组合的预测模型被广泛应用于月径流时间序列预测,如包苑村等[14]基于变分模态分解(VMD)方法和卷积-长短期记忆神经网络(CNN-LSTM),构建VMD-CNN-LSTM 月径流组合模型;席东洁等[15]基于经验模态分解(EMD)与Elman神经网络建立EMD-Elman月径流组合预测模型;桑宇婷等[16]利用互补集合经验模态分解(CEEMD)方法和BP 神经网络建立组合预测模型;徐冬梅等[17]针对径流序列的非线性、非稳态化的特点导致直接预测精度低的问题,提出基于完整集成经验模态分解(CEEMDAN)和小波分解(WD)组合的CEEMDAN-WD-PSO-LSSVM 月径流预测模型;王丽丽等[18]融合奇异谱分析(SSA)方法、灰狼优化算法、回归支持向量机模型,提出SSA-GWO-SVR 月径流组合预测模型;杨琼波[19]等基于小波包分解(WPD)方法、SSA 分解方法、鼠群优化(RSO)算法和回声状态网络(ESN),提出WPD-RSO-ESN、SSARSO-ESN 月径流时间序列预测模型.可见,基于“分解-预测-重构”的组合模型在月径流时间序列预测研究中应用广泛,但鲜见于年径流时间序列预测研究.
为提高年径流时间序列预测精度,拓展“分解-预测-重构”组合模型在年径流时间序列预测中的应用范畴,本文研究提出小波包分解(Wavelet Packet Decomposition,WPD)-人工大猩猩群优化(artificial gorilla troops optimization,AGTO)-深度极限学习机(Deep Extreme Learning Machine,DELM)年径流时间序列融合预测模型.WPD 源于小波分解,其优势在于在分解信号低频子集的同时,能对高频子集继续分解[20-21].AGTO 算法是Abdollahzadeh.B 等人于2021年受自然界大猩猩群体社会智能行为启发而提出的一种新型元启式优化算法.该算法通过模拟大猩猩群体在探索和开发阶段不同的位置更新策略实现对待优化问题的优化求解,具有寻优能力强,收敛速度快等优点[22].深度极限学习机(DELM)也叫多层极限学习机,其采用多个基于极限学习机的自编码器(ELM-AE)进行无监督预训练,然后利用各ELM-AE的输出权重初始化整个DELM,从结构上看DELM相当于把多个ELM 连接到一起,与ELM 相比,具有随机参数少,网络复杂度低,激活函数类型多样化等优点[23-25].但在实际应用中,由于DELM 中各隐含层神经元数需要人为设置,这在很大程度上制约了DELM 网络的预测性能.目前,粒子群优化(PSO)算法[26]已成功应用于DELM 隐含层神经元数的优化,有效提高了DELM 的预测性能.本文以云南省龙潭站年径流时间序列预测为例,采用3层WPD 对实例径流时序数据进行分解,达到降低时序数据复杂性的目的;利用人工大猩猩群优化算法(AGTO)优化DELM 隐含层神经元数,建立AGTO-DELM 模型对各子序列分量进行预测,将预测结果加和重构后得到最终预测结果,并构建WPD-DELM、WPD-AGTO-BP、WPD-BP 及基于小波分解(WD)的 WD-AGTODELM、WD-DELM、WD-AGTO-BP、WD-BP 作对比分析模型.
1 研究方法
1.1 小波包分解(WPD)
小波包分解(WPD)是目前信号特征提取技术中较为常用的方法,它通过低通滤波器H 和高通滤波器G 将信号数据分解为低频信号和高频信号序列各一组,然后将各层的频带进一步分解为其下一层的2个子频带,依此类推实现多层分解.利用WPD 对原始信号进行分解,公式[27-29]为:
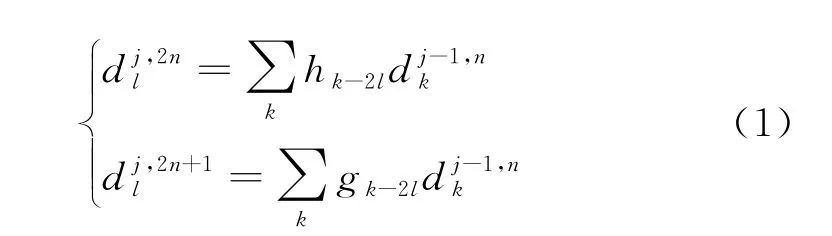

1.2 人工大猩猩群优化(AGTO)算法
AGTO 算法是受自然界大猩猩群体社会智能行为启发而提出的一种新型元启式优化算法,该算法通过模拟大猩猩群体在探索和开发阶段不同的位置更新策略实现对待优化问题的优化求解.在优化求解过程中,AGTO 算法遵循以下规则:①银背大猩猩领导和控制群体行动,负责群体安全和福祉,引导大猩猩群觅食.在迭代过程中,银背大猩猩即为每次迭代中找到的最优解;②大猩猩种群中有且只有一只银背大猩猩,所有大猩猩均受银背大猩猩的领导;③早期阶段,银背大猩猩因缺乏经验而无法做出正确的决策来获得食物或控制群体;④银背大猩猩会衰弱变老,最终死亡.群体中黑背大猩猩可能成为群体新领导,或者其他雄性大猩猩通过挑战银背大猩猩获得统治权[22].
参考文献[22],AGTO 算法数学描述如下:
(1)探索阶段.AGTO 算法中,大猩猩通过迁移到未知位置、迁移到已知位置和迁移到其他大猩猩位置3种机制来进行位置更新.3种位置更新机制数学描述如下:

式中:G X(t+1)表示大猩猩第t+1 次迭代位置向量;X(t)表示当前大猩猩位置向量;r1、r2、r3表示[0,1]之间的随机数;p表示给定参数,该参数决定选择迁移到未知位置的概率;UB、LB表示搜索空间上、下限;Xr(t)表示种群中随机选择的大猩猩位置向量;G Xr(t)表示当前阶段随机选择的大猩猩位置向量;C、F、L、H表示探索机制参数,C=F×(1-t/T),F=cos(2×r4)+1,L=C×l,H=Z×X(t),t、T分别表示当前迭代次数和最大迭代次数;r4表示[0,1]之间的随机数;l表示[-1,1]之间的随机数,Z∈[-C,C]中的随机值.
(2)开发阶段.大猩猩采用跟随银背大猩猩和竞争成年雌性大猩猩两种行为进行位置更新.
①跟随银背大猩猩.AGTO 算法中,群体成员跟随银背大猩猩进行觅食,其位置更新数学描述如下:
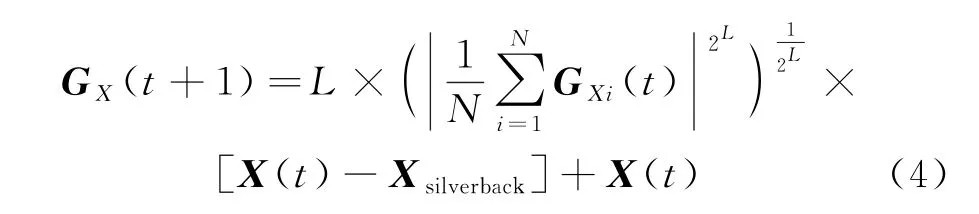
式中:Xsilverback表示银背大猩猩位置向量,即全局最优解;G Xi(t)表示每只候选大猩猩第t次迭代位置向量;N表示大猩猩种群规模;其他参数意义同上.
②竞争成年雌性大猩猩.当雄性大猩猩进入成熟期后,它们会与其他雄性大猩猩在选择成年雌性大猩猩上展开争斗,这种竞争往往是激烈的.式(4)用于模拟和描述这种行为:
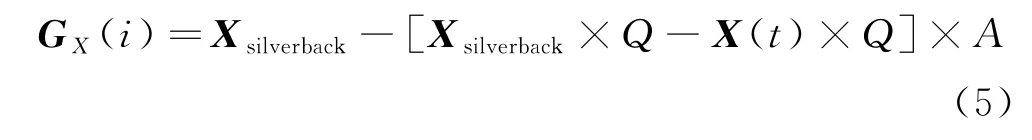
式中:G X(i)表示第i只雄性大猩猩;Q表示撞击力因子,Q=2×r5-1,r5表示[0,1]之间的随机数;A表示暴力冲突程度系数,A=β×E,β表示优化前设置的固定参数,E用于模拟暴力冲突对维度的影响;其他参数意义同上.
1.3 深度极限学习机(DELM)
深度极限学习机(DELM)从结构上看相当于把多个极限学习机(Extreme Learning Machine,ELM)连接到一起,能更全面地捕捉到数据之间的映射关系,有效提高处理高维度、非线性数据的能力.
设DELM 有Q组训练数据{(x i,y i)|i=1,2,…,Q}和M个隐含层,将输入训练数据样本根据自编码器极限学习机(ELM-AE)理论得到第一个权值矩阵β1,接着得到隐含层特征向量H1,…,以此类推,能够得到M层的输入层权重矩阵βM和隐含层特征向量H M.DELM 数学模型表述式为[17-20]
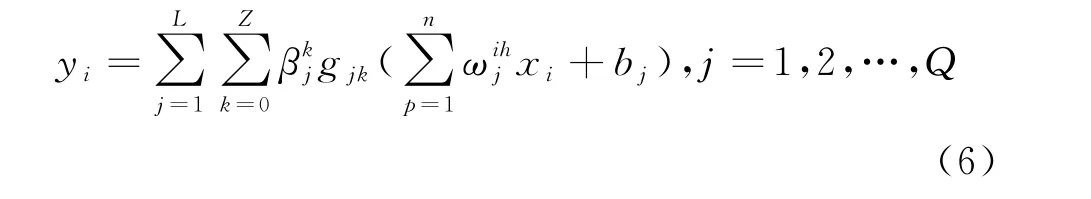
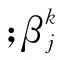
由于DELM 网络前期是进行多层无监督学习,不需要人为设置输入的权重和阈值,只要设置各隐含层的神经元数,所以DELM 网络具有学习速度快、泛化能力强等特点.为合理设置DELM 网络各隐层神经元数,本文采用AGTO 算法对各隐含层神经元数进行优选,其优势在于:①减少对各隐含层神经元数的反复调试.②优化时间短,且能有效提高预测精度.③优化后的模型具有更好的泛化能力.
1.4 WPD-AGTO-DELM 建模流程
步骤1:采用WPD 将实例年径流时间序列进行3层分解,采用自相关函数法(AFM)确定各子序列分量的输入向量,划分训练样本和预测样本.
步骤2:确定DELM 网络结构(本文采用4隐层DELM 网络).针对每一个子序列分量,构建训练样本均方误差作为AGTO 优化DELM 各隐含层神经元数的目标函数:
步骤3:设置大猩猩种群规模N,最大迭代次数T,其他采用算法默认值.随机初始化大猩猩位置X i(i=1,2,…,N).流程如图1所示.
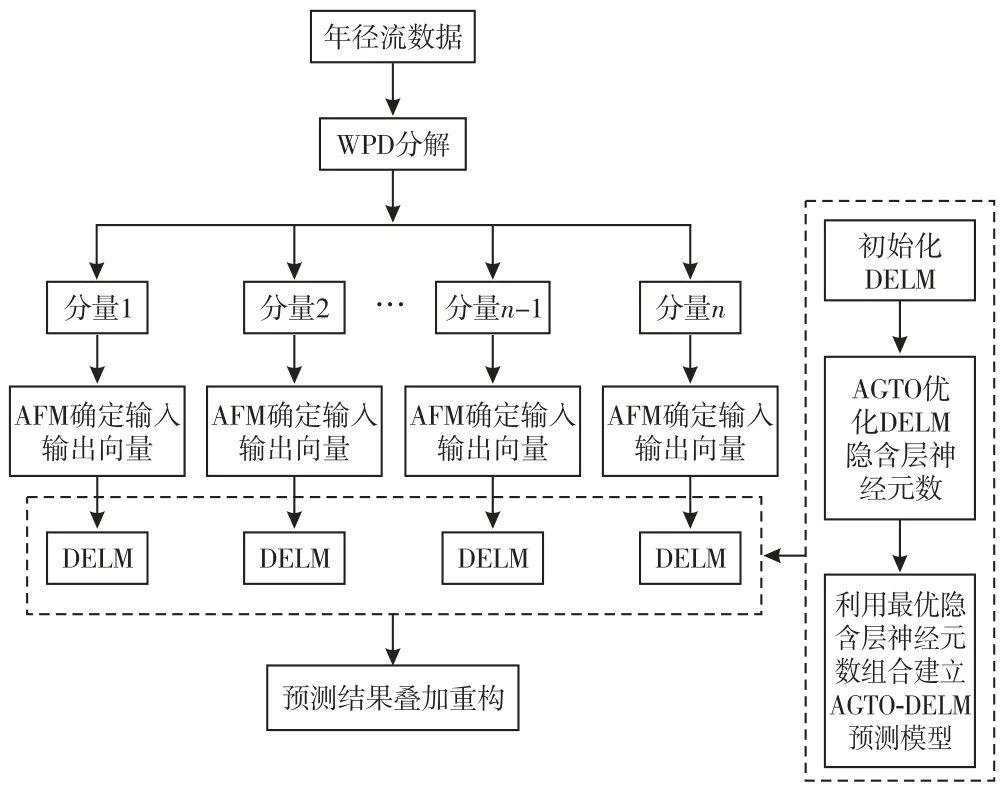
图1 实例年径流预测流程图
步骤4:计算大猩猩适应度值,找到并保存银背大猩猩位置Xsilverback.令迭代次数t=1.
步骤5:利用式(3)中3种探索策略更新大猩猩位置向量,计算大猩猩适应度值,比较并保存银背大猩猩位置Xsilverback.
步骤6:利用式(4)~(5)两种开发策略更新大猩猩位置向量,计算大猩猩适应度值,比较并保存银背大猩猩位置Xsilverback.
步骤7:令t=t+1.若满足判断终止条件,则输出Xsilverback,否则返回步骤5.
步骤8:输出银背大猩猩位置Xsilverback,即DELM各隐含层神经元数.利用AGTO-DELM 模型对分量[3,0]-[3,7]进行预测,将各分量预测结果加和重构.
步骤9:采用平均相对误差(EMAPE)、平均绝对误差(EMAE)、均方根误差(ERMSE)对各模型进行评估,见式(8).其中,EMAPE、EMAE、ERMSE越小,说明预测效果越好,模型可信度越高.
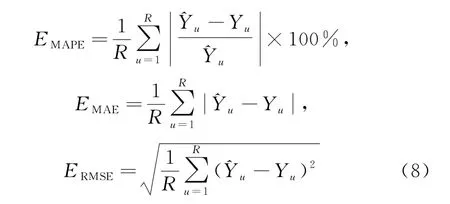
2 应用实例
本文以云南省龙潭寨水文站1952—2018 a年径流时间序列为研究对象.龙潭站始建于1952年,位于盘龙河干流,控制径流面积3 128 km2.盘龙河发源于红河州蒙自县鸣鹫乡,流域面积6 497 km2,主要支流有德厚河、畴阳河等.
本文利用1952—2008 a年径流量数据为训练样本,2009—2018 a为预测样本,年径流变化曲线如图2所示.从图2可以看出,龙潭寨水文站年最大径流量50.6 m3·s-1,最小径流量6.8 m3·s-1,年均径流量23.4 m3·s-1,年径流时序数据呈现出典型的多尺度、非线性特征,起伏变化激烈.
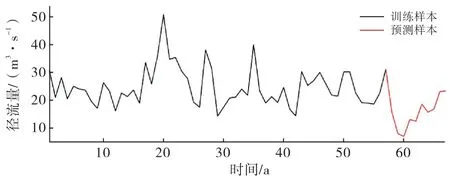
图2 实例年径流时间序列变化图
2.1 WPD 分解
WPD 优势在于对时间序列的低频和高频信号同时进行分解.本文基于dmey小波包基将龙潭站67 a径流时序数据进行3层小波包分解(采样频率设置为20 MHz),得到8个分解空间的子序列分量数据,如图3所示.
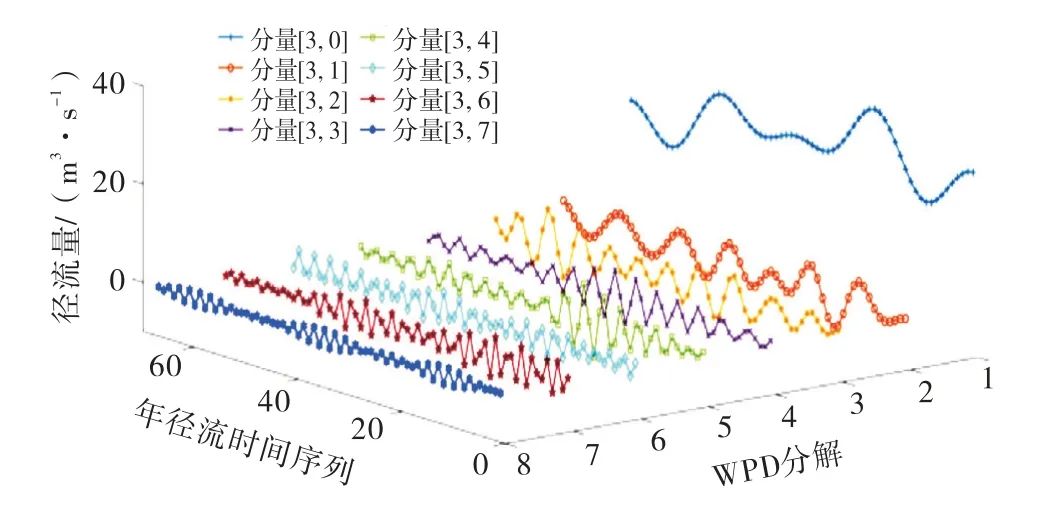
图3 年径流时间序列WPD 分解3D 效果图
从图3可以看出,[3,0]、[3,1]、[3,2]、[3,3]为低频空间数据波形,振幅较大、波长较短,大致反映年径流时间序列的变化趋势;[3,4]、[3,5]、[3,6]、[3,7]为高频空间数据波形,从[3,4]分量到[3,7]分量,其振幅逐渐减小、波长逐渐变长,大致反映年径流时间序列的波动情况.
2.2 WD分解
WD 不足之处在于仅对时间序列低频信号再次分解,而忽视了高频信号.为在公平条件下进行比较,利用db7小波将实例1952—2018 a年径流数据进行7层分解(采样频率设置为20 MHz),即分解为1个低频率分 量r A7 和7 个 高 频 率 分 量r D1、r D2、r D3、r D4、rD5、r D6、r D7,如图4所示.
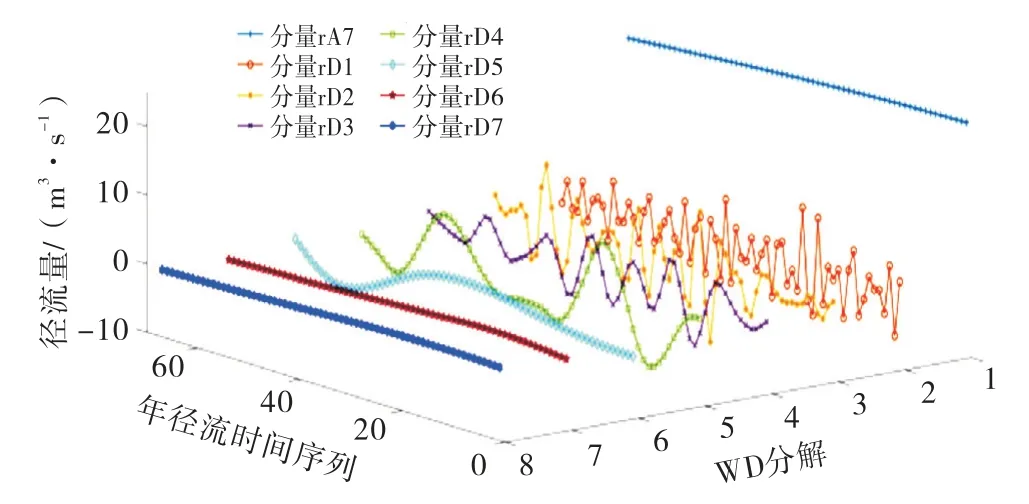
图4 年径流时间序列WD 分解3D 效果图
从图4可以看出,高频分量反映原始数据的变化特征;低频分量反映原始数据的变化趋势.
2.3 时间序列建模
本文采用自相关函数法(Autocorrelation Function Method,AFM)确定各分量的输入、输出向量.确定原则:通过SPSS软件计算各子序列分量的自相关系数,在滞后数H≥4的情况下,将自相关系数最大时所对应的滞后数H作为各子序列分量最优嵌入维数,即将预测年的前H个年径流数据作为输入向量,预测年年径流作为输出向量,见表1.
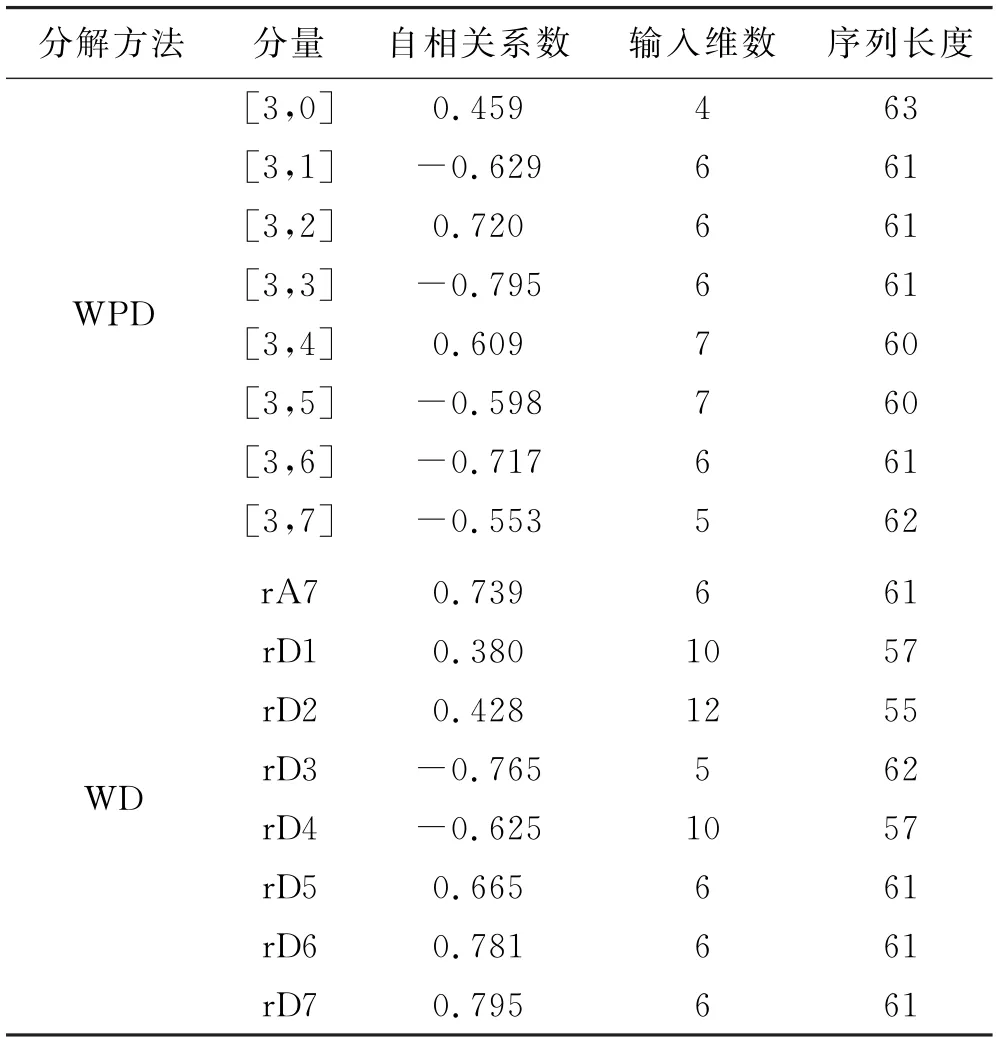
表1 各分量自相关系数、嵌入维数及序列长度
2.4 参数设置及预测分析
2.4.1 参数设置
1)WPD-AGTO-DELM、WD-AGTO-DELM 模型:设置大猩猩种群规模N=50,最大迭代次数T=50,DELM 网络隐含层神经元搜索空间[2,10],其他采用算法默认值;选择4隐层DELM 网络,激活函数选择sigmoid函数,数据采用[-1,1]进行归一化处理.
2)WPD-AGTO-BP、WD-AGTO-BP、WPD-BP、WD-BP模型:设置WPD-BP、WD-BP 模型各分量隐含层数为输入维数的2倍-1,隐含层传递函数、输出层传递函数、训练函数分别采用tansig、purelin、traingdx,设定期望误差为0.000 1,最大训练轮回设置为1 000次,数据采用[-1,1]进行归一化处理.为在公平条件下对比验证WPD-AGTO-BP、WD-AGTO-BP模型,AGTO 算法参数设置同WPD-AGTODELM、WD-AGTO-DELM 模型,BP 参数设置同WPD-BP、WD-BP模型.
3)WPD-DELM、WD-DELM 模型:选择4 隐层DELM 网络,激活函数选择sigmoid函数,数据采用[-1,1]进行归一化处理;设置DELM 各隐含层神经元数均为10,在不满足精度要求时进行适应调整.
2.4.2 预测结果分析
利用表1 构建各分量的输入、输出向量,基于1.4节中“WPD-AGTO-DELM 建模流程”建立的WPD-AGTO-DELM 等8 种模型对各分量进行预测,将预测结果进行叠加得到年径流最终预测结果.各模型采用上述EMAPE(%)、EMAE(m3/s)、ERMSE(m3/s)评估,结果见表2;预测效果如图5~6所示.
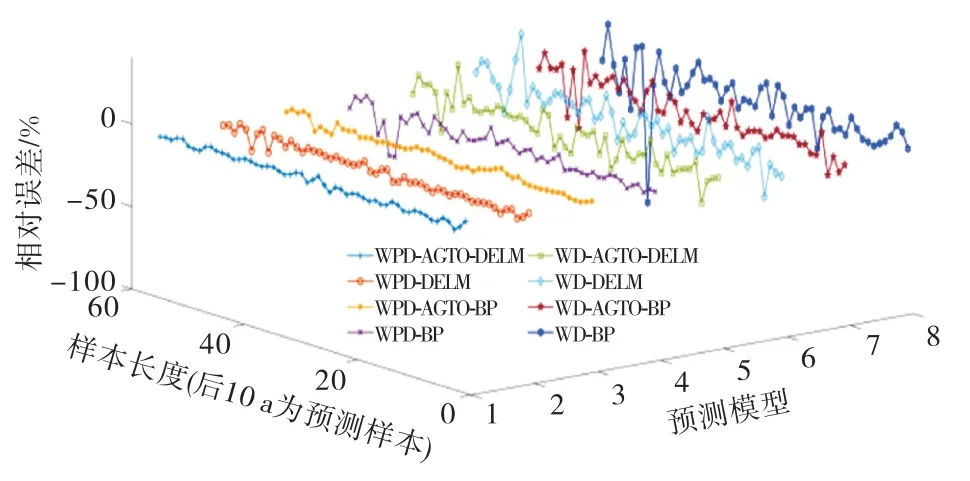
图5 实例拟合-预测相对误差3D 图
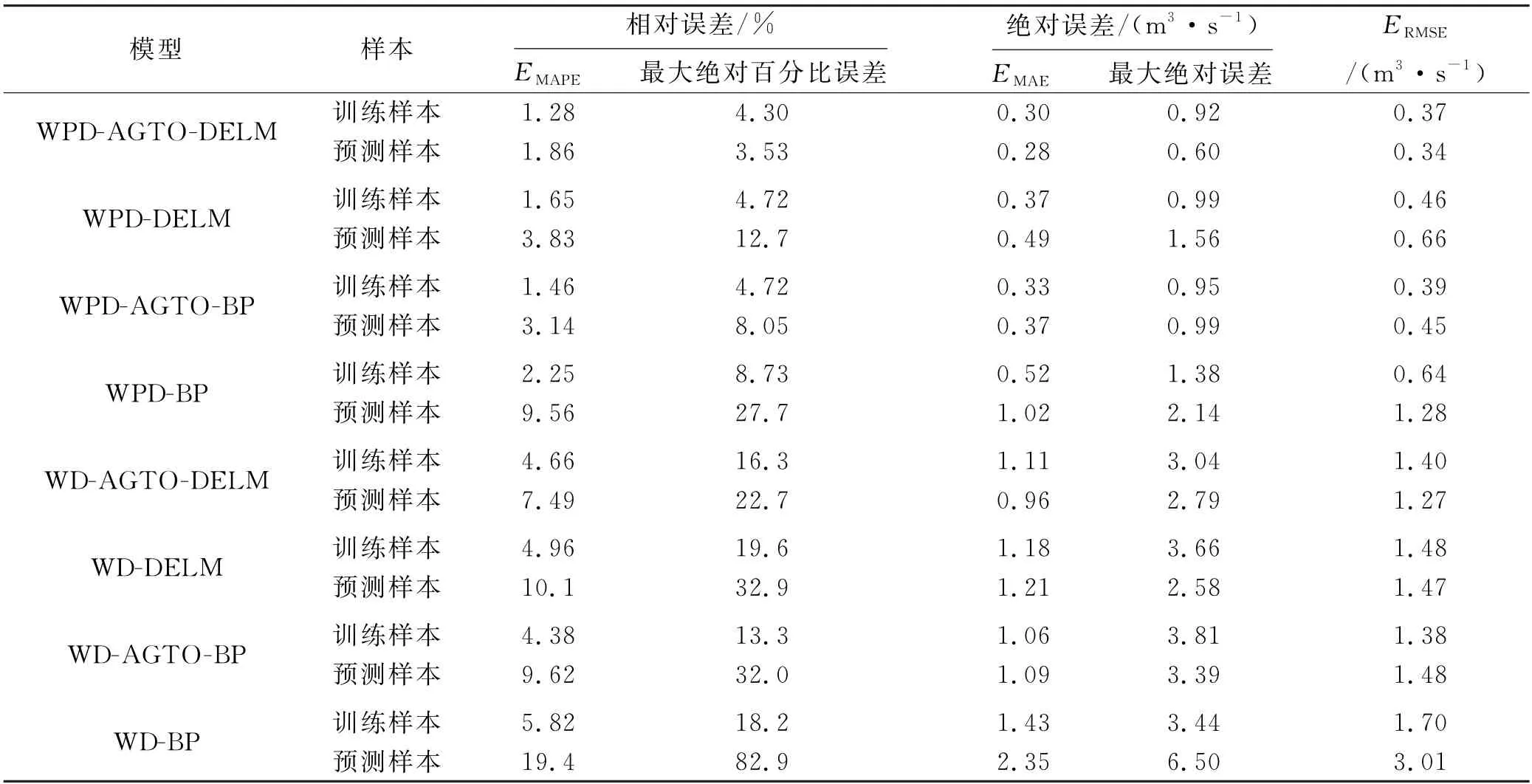
表2 年径流时间序列预测结果对比
依据表2及图5~6可以得出以下结论:
1)WPD-AGTO-DELM 模型预测的EMAPE、EMAE、ERMSE分别为1.86%、0.28 m3·s-1、0.34 m3·s-1,较WPD-DELM、WPD-AGTO-BP、WPD-BP、WD-AGTO-DELM、WD-DELM、WD-AGTO-BP、WD-BP模型在EMAPE上分别降低51.4%、40.8%、80.5%、75.2%、81.6%、80.7%、90.4%,在EMAE上分别降低42.9%、24.3%、72.5%、70.8%、76.9%、74.3%、88.1%,在ERMSE上分别降低48.5%、24.4%、73.4%、73.2%、76.9%、77.0%、88.7%,对训练样本拟合效果同样优于其他模型.可见WPD-AGTO-DELM 模型具有更高的预测精度,将其用于年径流时间序列预测是可行的.
2)从表2 及图5~6 来看,基于WPD 分解 的WPD-AGTO-DELM、WPD-DELM、WPD-AGTOBP、WPD-BP模型的预测精度优于对应WD-AGTODELM、WD-DELM、WD-AGTO-BP、WD-BP 模型的预测精度,说明WPD 在分解低频信号的同时,对高频信号继续分解,有效弱化了复杂环境对径流时间序列的影响,降低预测复杂度,提高预测精度,其分解效果优于WD 方法.
3)基于AGTO 优化的WPD-AGTO-DELM、WD-AGTO-DELM 模型的预测精度远高于对应未经优化的WPD-DELM、WD-DELM 模型,说明AGTO能有效优化DELM 隐含层神经元数,提高DELM 网络预测精度和智能优水平.
4)从图5 来看,WPD-AGTO-DELM 模型对 实例年径流拟合-预测的相对误差在-4.30%~3.48%之间,绝大多数样本相对误差在0值附近波动;从图6来看,WPD-AGTO-DELM 模型对实例年径流拟合-预测的绝对误差在-0.60~0.92 m3/s之间,大多数样本绝对误差在0值附近波动,具有更好预测效果.

图6 实例拟合-预测绝对误差3D 图
3 结论
针对径流时间序列呈现的多尺度、非平稳性特征,提出基于WPD-AGTO-DELM 的年径流时间序列预测模型,并构建WPD-DELM、WPD-AGTO-BP、WPD-BP、WD-AGTO-DELM、WD-DELM、WD-AGTO-BP、WD-BP 7种对比模型,利用云南省龙潭站年径流时间序列预测实例对各模型进行检验,得到如下结论:
1)采用WPD 对年径流时间序列进行分解,可以有效弱化复杂环境对径流时间序列的影响,降低预测复杂度,提高预测精度.WPD 在分解低频信号的同时,对高频信号继续分解,分解效果优于WD 方法.
2)WPD-AGTO-DELM 模型对实例年径流的拟合、预测效果优于WPD-DELM 等7种模型,具有更好的预测精度和泛化能力.模型及方法可为径流时间序列预测提供一种新的有效途径.
3)与WPD-DELM、WD-DELM 模型对比发现,WPD-AGTO-DELM、WD-AGTO-DELM 模型预测精度更高,说明采用AGTO 优化DELM 隐含层神经元数,有利于提高DELM 预测精度和智能化水平,具有较好的实用价值.
猜你喜欢
水利水电快报(2022年8期)2022-11-23
水力发电(2022年8期)2022-10-12
小哥白尼(野生动物)(2022年3期)2022-06-16
黑龙江大学自然科学学报(2022年1期)2022-03-29
雪豆月读·中年级(2021年10期)2021-10-26
小学生必读(低年级版)(2021年5期)2021-08-14
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
英美文学研究论丛(2018年1期)2018-08-16
