
基于实验室指标的新型冠状病毒肺炎鉴别诊断模型
2022-10-18 06:38:30朱碧云王妮陈卉应晓飞康娜张淳
北京生物医学工程 2022年5期
朱碧云 王妮 陈卉 应晓飞 康娜 张淳
0 引言
2019年新型冠状病毒肺炎(corona virus disease 2019,COVID-19)在全球范围内广泛传播,截至2021年5月7日,全球确诊病例超过1.5亿例,其中死亡病例超过326万例[1]。目前,新型冠状病毒肺炎(以下简称新冠肺炎)在全世界范围内广泛传播,已经成为当前乃至未来几年最严峻的全球性公共卫生事件。冬春季节,也是流感病毒性肺炎爆发流行的时间,快速、准确地鉴别新冠肺炎与流感病毒性肺炎至关重要,有利于开展针对性的治疗,避免医疗资源浪费。
新冠肺炎与普通流感性肺炎在病原学、流行病学以及发病症状方面具有一定的相似性,均以发热为主要症状,且新冠肺炎临床症状不典型或者无临床症状,单纯依靠临床症状无法将其与普通流感性肺炎区分[2-3]。目前两者确诊的金标准均为核酸检测,但是核酸检测受控因素较多,容易出现假阴性。另一种鉴别手段是通过CT检查,但是早期症状相似、检测成本高、检测结果滞后及临床医生主观判断失误等均会为结果造成差异。
临床研究[4-5]及《新型冠状病毒肺炎诊疗方案》均指出,新冠肺炎患者外周白细胞总数、淋巴细胞计数、C反应蛋白等多项指标均会有所变化,为开展基于实验室指标的诊断和鉴别诊断模型研究提供了依据。近年来,机器学习已逐渐应用于医学领域,通过对样本集进行学习,发现其中隐含的规律,对疾病的早期诊断及预后具有重要的临床指导意义[6-8]。由于流感病毒性肺炎和新冠肺炎均可以通过呼吸道传播,临床症状与新冠肺炎相似,容易造成误诊与漏诊,为此,进行两者的鉴别诊断模型的研究具有重要意义。本研究回顾性收集新冠肺炎及流感病毒性肺炎患者的七大类84项实验室检测指标,采用决策树及其集成学习算法建立两类肺炎的鉴别诊断模型,并筛选影响诊断结果的重要实验室指标,为医生诊断提供参考依据。
1 材料与方法
1.1 数据来源及预处理
回顾性收集首都医科大学附属北京地坛医院2020年1月至6月收治的327名新冠肺炎患者入院后的首次实验室数据,由于其中152名患者在医院信息系统中记录的实验室项目过少,被直接剔除,最后剩余有效数据175例。以相同方式选取2019年同期收治的157名流感病毒性肺炎患者的实验室数据。提取全血细胞分析、电解质系列、降钙素原检测、尿液分析、急诊肝功、心肌酶谱、凝血组合七项,共计84个指标。尿液相关指标中,有17%左右数值缺失,其余指标的缺失值不足10%或更少,这部分缺失值利用所有样本的众数进行插补。另外,尿液检查的8个指标均有超过95%的患者结果为阴性,故将其剔除,最终剩余76个特征。
1.2 基于Logistic回归的特征选择
由于特征较多,特征之间可能具有一定的相关性及存在噪声特征,影响诊断分类的效果。因此,在建立诊断模型之前,利用单因素Logistic回归分析进行特征筛选,保留P<0.05的特征用于下一步建模。
1.3 构建诊断模型及识别重要指标
本研究采用CART决策树以及基于决策树的集成算法建立分类(诊断)模型。相对其他算法,决策树算法相对简单,计算复杂度不高,模型输出结果直观,易于理解和实现。
但是决策树的构建主要依赖于训练集,其预测结果的准确率往往不高,可扩展性也不是很好[9],因此,本研究除了构建单棵决策树模型外,还采用了两种以单棵决策树为弱分类器的集成模型,即随机森林分类器和极端梯度提升(eXtreme gradient boosting,XGBoost)分类器。在本研究中,这两个集成模型均分别包含200棵决策树。此外,在构建决策树模型时通常使用基尼系数或信息增益选择树的分支节点,因此本文利用CART决策树和随机森林提供的特征基尼系数以及XGBoost提供的特征平均增益来评价特征的重要性[10-11]。
1.4 分类诊断算法的性能评价
考虑到样本例数较少以及运算耗时,采用5折交叉验证法计算准确率、精确率、召回率、F1分数。利用接受者操作特征(receiver operating characteristic,ROC)曲线下面积(area under curve,AUC)综合评价预测模型的性能,并对各折返回的特征重要性求均值,筛选出影响分类结果的重要因素。
2 结果
2.1 特征选择
将76个特征逐一进行单因素Logistic回归分析,保留46个P值小于0.05的特征,涵盖14个全血细胞分析指标、7个电解质系列指标、降钙素原检测、9个尿液分析指标、6个急诊肝功指标、4个心肌酶谱指标、6个凝血相关指标。具体结果见表1。其中,优势比(odds ratio,OR)值大于1的指标,表示其为确诊新冠的危险因素,需引起注意。

表1 经单因素Logistic回归分析后部分特征初筛结果
2.2 模型预测结果
各模型预测结果见表2及图1。结果显示,单棵CART决策树模型的整体表现最差;随机森林模型的召回率优于其他模型;XGBoost的准确率、精确率、F1分数和AUC值最高,整体表现最好。
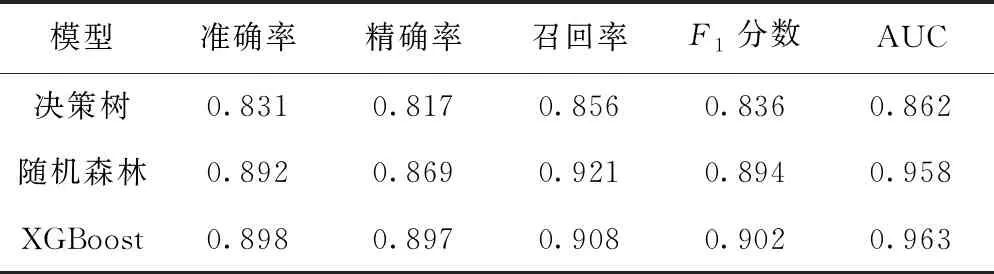
表2 决策树、随机森林以及XGBoost模型预测结果
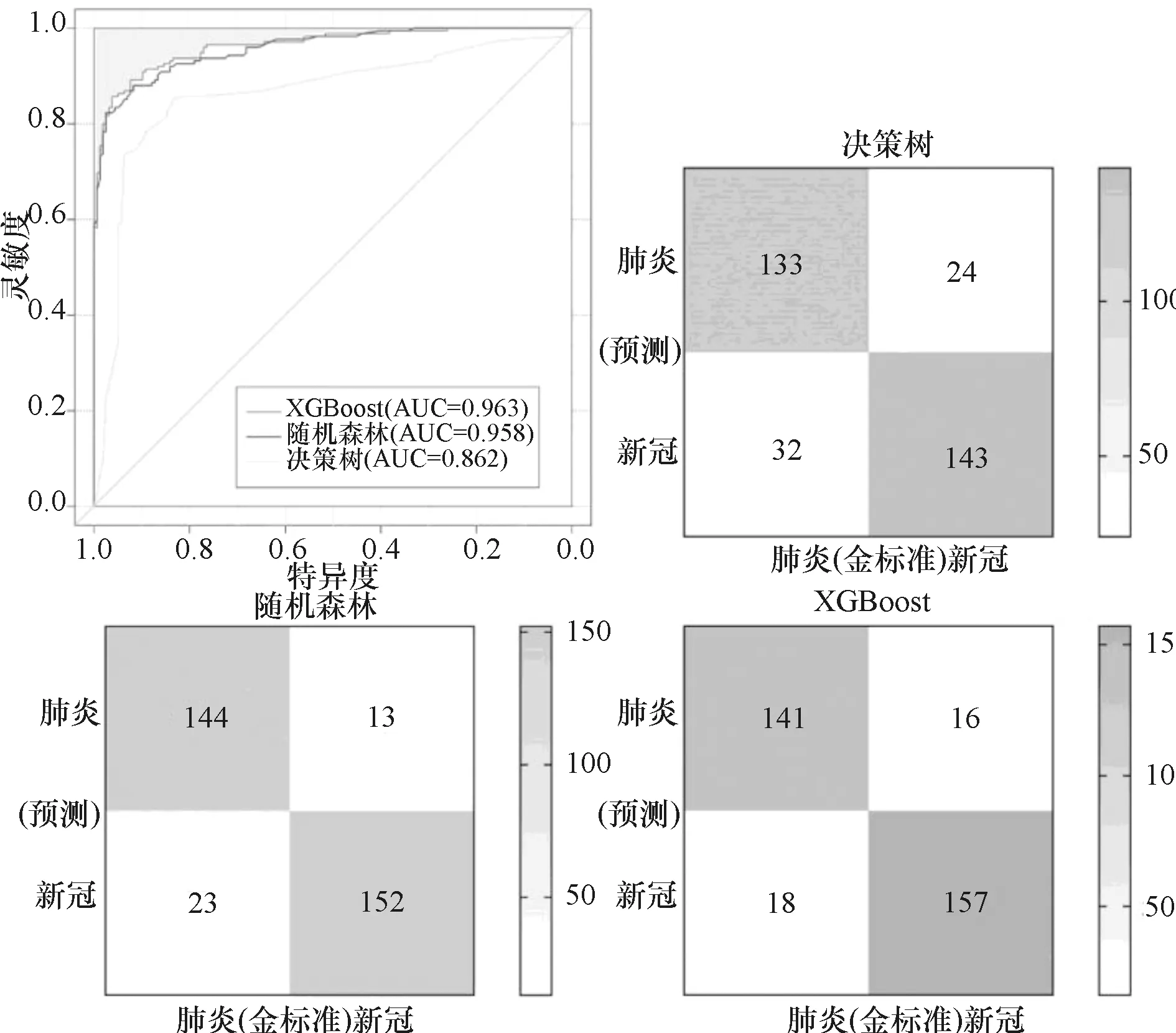
图1 决策树、随机森林以及XGBoost模型分类性能(ROC曲线及混淆矩阵)
2.3 重要因素识别
对决策树、随机森林和XGBoost各折返回的特征重要性求均值,排名前10的指标及其平均重要性如表3所示。三种模型中,降钙素原重要性均排在第一位,说明此指标在三种模型预测新冠肺炎中具有重要作用。排名靠前的10个指标中,淋巴细胞计数、淋巴细胞百分比,白蛋白、总蛋白,C反应蛋白和纤维蛋白原定量测定6个指标均涵盖在其中,提示这些指标或有临床意义。
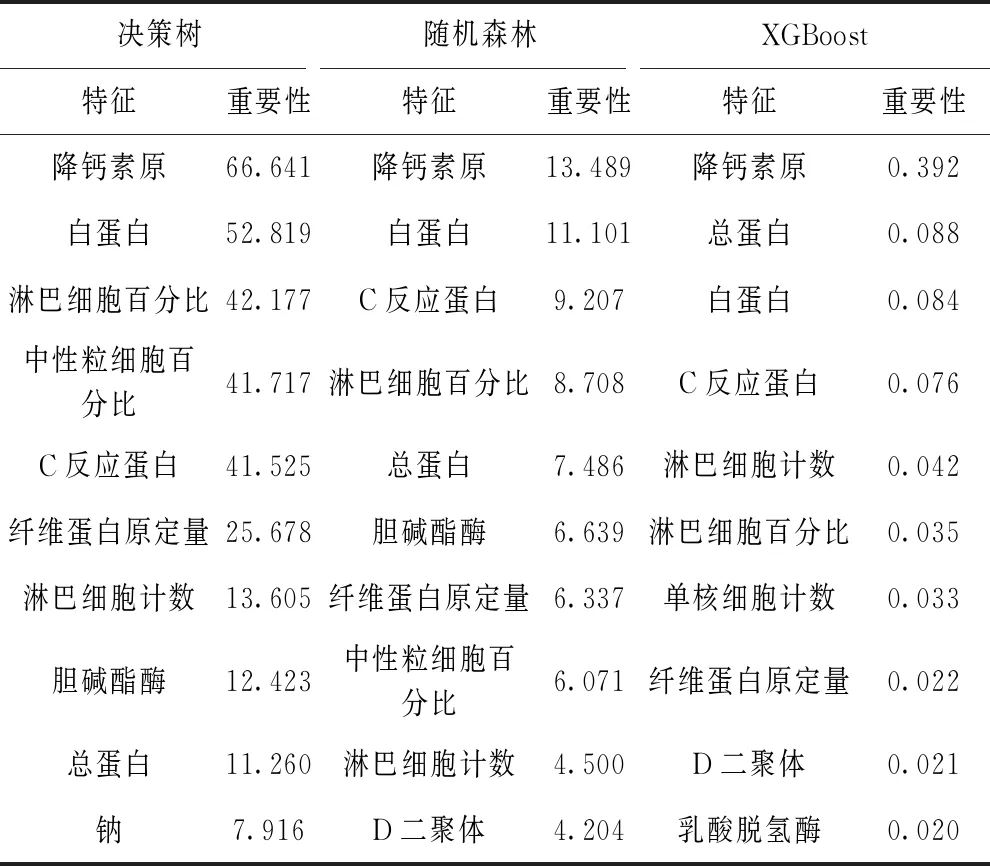
表3 不同预测模型提供的特征重要性
3 讨论
新冠肺炎的临床症状主要是发热、干咳、乏力,这与流感病毒性肺炎很相似。另外新型冠状病毒感染后临床症状多样性及不典型性给诊断带来很大的困难[12-13]。目前两种疾病确诊均依靠病毒核酸检测,但是核酸检测受控因素较多,特别是COVID-19流行高峰期时,其敏感度仅为59%[14]。本研究对患者的实验室检测指标进行清理、挖掘,利用机器学习模型对两种病毒性肺炎进行鉴别预测,并从中找出对两种疾病诊断影响较大的因素,以期为两种病毒性肺炎的鉴别诊断提供参考意见。
目前,随着海量医疗健康大数据的产生,传统的统计学方法已经无法满足数据分析需求,越来越多的研究学者开始尝试利用机器学习方法,如决策树及其集成学习算法,建立诊断模型。曾雪元等[6]利用决策树算法构建缺血性卒中复发的预测模型,模型精确度为81%。杨青等[7]采用决策树算法构建肿瘤患者难免性压疮风险预测模型, ROC曲线下面积为0.84。随机森林和XGBoost是基于决策树的集成学习算法,有研究表明,其性能通常要优于单棵决策树。于大海等[8]将Logistic回归方法筛选出的与并发上消化道出血有关联的变量作为输入变量,建立随机森林和决策树模型,决策树的准确率(75.1%)和ROC曲线下面积(0.72)均低于随机森林(88.9%和0.909)。本研究的结果也显示,随机森林和XGBoost模型的综合预测性能要优于单一决策树模型,ROC曲线下面积高达0.958和0.963,证实了基于决策树的集成模型在进行新冠肺炎鉴别诊断时具有优越的性能。高瞻等[15]以患者生化检验数据为特征,借助XGBoost模型建立新冠肺炎智能检测系统,虽然可以达到94.3%的准确率,但敏感度低于本研究的结果(83.3%与90.8%),容易造成新冠肺炎患者漏诊,说明仅使用生化指标进行诊断预测仍有一定的局限性。
利用决策树及其集成算法建立预测模型得到的另一个有意义的结果是筛选出了影响预测结果的重要因素。白欢等[4]分析新冠肺炎患者早期外周血实验室检查结果,发现白细胞、淋巴细胞、血小板、血清钙显著降低,C反应蛋白显著升高。刘子砚等[5]对347例新冠肺炎患者的实验室检查结果进行分析,显示白细胞计数、淋巴细胞计数等指标有明显异常。基于数据挖掘方法,本研究也发现,淋巴细胞计数、淋巴细胞百分比、白蛋白、总蛋白、C反应蛋白和纤维蛋白原定量测定均是鉴别诊断新冠肺炎的重要因素,提示除核酸检测和影像学检查外,血常规、生化指标及凝血机制结果可辅助临床医生进行诊疗。
4 结论
在医疗资源紧张和核酸检测准确率有待改进的情况下,本研究基于决策树的集成算法在利用实验室指标进行流感病毒性肺炎与新冠肺炎的鉴别诊断时具有一定的参考意义。本研究也存在一定的局限性。本研究仅限于普通流感病毒性肺炎与新冠肺炎的鉴别诊断,尚不适用于一般的新冠肺炎诊断。此外,由于疾病的特殊性,本研究的病例样本量较少,一些患者还可能同时伴有其他疾病,这些都可能对研究结果产生影响。今后将在进一步扩大样本量的基础上增加鉴别诊断疾病的种类,为新冠肺炎的临床诊断提供更多参考依据。
猜你喜欢
今日农业(2021年2期)2021-11-27 19:19:53
今日农业(2021年1期)2021-03-19 08:35:38
疯狂英语·初中天地(2020年5期)2020-06-22 08:47:54
恋爱婚姻家庭·养生版(2020年3期)2020-04-13 10:01:57
医学新知(2019年4期)2020-01-02 11:04:00
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中国卫生标准管理(2015年3期)2016-01-15 02:49:19
医学研究杂志(2015年3期)2015-06-10 06:41:52
