
基金项目学部分部的交叉网络分析
——以美国NSF数据中AI领域为例
2022-10-18 06:05:52王曰芬陈必坤恢光平
情报学报 2022年9期
杨 洁 ,王曰芬 ,2,3,陈必坤 ,恢光平
(1. 南京理工大学经济管理学院,南京 210094;2. 天津师范大学管理学院,天津 300387;3. 天津师范大学大数据科学研究院,天津 300387;4. 苏州大学社会学院,苏州 215021)
1 引 言
研究问题的复杂化与单一学科理论、方法及工具的难以应对,迫使科学研究要打破原有的学科边界,促进不同学科间相互交流碰撞与交融创新。交叉研究是未来科学发展的必然趋势,交叉融合是加速科技创新的重要驱动力。
随着交叉研究在科学技术和经济社会发展进程中战略地位的提升,多学科交叉或跨学科研究逐渐从学术关注转变为各国政府科技政策的重点决策对象,受到了政府及各类组织各种形式的支持,使其更加兼具鲜明的学术先进性与高度的政策相关性。强化学科交叉和寻求新的科研范式是未来科学技术快速发展的必由之路,如何促进学科交叉融合研究,一直都是世界各国科学资助机构面临的一个共同难题和挑战[1]。在我国,从2000 年推出“国家自然科学基金重大研究计划”模式以支持学科交叉研究[2],到2020 年11 月29 日正式宣布国家自然科学基金委员会成立交叉科学部[1],体现出中国政府在不断积极引领与促进学科交叉融合的发展;在国外,如美国国家科学基金会(National Science Foundation,NSF)对交叉学科领域的基础研究设立专项资助,也体现出美国政府对学科交叉研究的重视并积极推进学科交叉研究工作。因此,基于基金资助项目数据对交叉研究进行相关探索,具有重要的学术价值与战略意义。
2 相关研究工作
交叉研究作为一种新的科学研究范式,是指研究的跨领域、跨学科、多学科的学科交叉关联与渗透融合,也被称为多学科交叉研究与跨学科研究。跨学科是由团队或个人进行的研究模式,这种模式整合了信息、数据、技术、工具、观点、概念,和/或来自两个或两个以上学科或专业知识体系的理论,以推动基本理解或解决超出单个学科或研究实践领域范围的问题[3]。
研究者大多数是从学科交叉角度探究交叉研究的,认为学科交叉是伴随社会和学科自身发展需求而出现的一种综合性科学活动,是形成交叉学科的途径和过程[4]。在交叉学科的实践层面上,国内外相关研究主要体现在学科交叉理论研究、测度研究、相关规律研究三个方面[5]。其中,构建学科交叉测度指标与模型以分析交叉学科的学科组成并确定组成学科间交叉程度的测度研究,被关注的程度比较高。学者们从提出研究视角、确定分类体系、构建学科交叉测度框架、选择指标计算方法等方面开展了大量研究。根据学科特性构建学科丰富度、学科平衡性、学科差异性、网络一致性等不同维度组合的学科交叉测度框架[6-7],提出学科专门度、信息熵指数、学科区分度指数、学科集成化指数、Rao-Stirling 指标、凝聚子群密度等的不同测量指标[8-9],并基于文献计量、引文分析、复杂网络、因子分析等方法构造指标算法[10-11]。同时,分层次与建立关联进行测度研究,例如,从引文内容角度出发在微观层面测量学科交叉度和高交叉度术语[12],利用随机引文网络通过前向引用与后向引用关系并与Rao-Stirling 指标结合测度新颖性与学科交叉度[3],以及利用三重底线(triple bottom line,TBL)框架促进基于环境、经济和社会可持续性度量的跨学科综合测度指标的研究[13]。
多学科交叉或者跨学科的本质是学科之间知识的交流与转移,不仅包括学科之间进行交叉、融合以及相互渗透的规律,还包括学科领域概念、方法等的相互交换、转移、流动与扩散[14]。所以,将关键词或主题词结合进行学科交叉度测量及应用的研究也不断地受到学者们的重视。例如,Wagner 等[15]建议整合不同学科的专业知识构造一个自下而上的将论文与引用相结合的方法流程,以探讨解决与交叉学科内容有关的特定问题是在何种知识内容水平上进行聚合的;马瑞敏等[16]认为两个学科的共关键词越多,这两个学科在研究主题和内容上的交叉程度就越大,文献直引、文献耦合、共关键词综合可用于直接测度不同学科之间的交叉程度;许海云等[17]基于 TI(term interdisciplinary) 指标结合社会网络分析方法和时序分析方法来分析和研究情报学学科交叉主题;闵超等[18]采用聚类分析和战略坐标分析方法以图书情报与新闻传播学为例探索学科交叉研究热点领域的主题划分、结构特性和演化过程。
综上所述,已有研究不仅产生了大量的理论与方法,而且正在拓展实践应用的广度和深度,为正在兴起的学科交叉研究奠定了发展的基础。
美国NSF 设立7 个学部,每个学部下设立若干个分部。NSF 学部分部(以下简称分部)与研究所属的学科或者项目类别密切相关,对分部进行分析可以发现基金项目资助领域的学科交叉特征和演化趋势。那么,关于研究领域的学科交叉,在NSF 的资助政策下,不同分部的内部知识发展状况如何?NSF 各分部间的知识又是如何相互渗透和影响的?针对上述问题,本文拟以科学基金数据为研究对象,采用共词网络、复杂网络和词向量分析等方法构建分析框架与测度指标,以美国NSF 资助的领域数据为例,测算交叉研究领域内分部间的知识内聚性与知识交叉融合能力,分析交叉融合过程中分部内部、分部之间的知识关联与渗透演化,探索交叉研究的发展对基金分部发展的推动,以揭示科技投入对交叉研究的引导方向、影响特征及演化作用。
3 研究设计与方法
3.1 分析流程框架
对基金项目中包含的关键词开展相关研究,是从微观层面视角对基金分部的知识结构进行探索。共词网络是由论文关键词之间的共现关系构成的一种表达科学领域知识结构的知识网络[19],因此,本文借助论文共词网络构建思想,分别构建分部内关键词共词网络和分部间交叉网络,以探索分部内知识的发展与分部间知识交互关联的结构特征和演化规律。具体地:①通过项目关键词共现构建如图1所示的不同分部内部的共词网络,共词网络的边权重由关键词对领域重要程度和关键词的共现频次共同决定;②依照不同分部之间存在相同关键词而形成的交叉部分构建如图2 所示的分部交叉网络,其中任意两个分部之间关键词交叉度之和构成分部间的交叉强度。
同时,由于每个分部中都包含大量的关键词,且每个关键词在不同分部中的重要程度是有差异的,进而影响着交叉网络的构成;所以,本文将导入基金项目关键词重要性计算,并与交叉度、平均路径长度和影响力等指标结合构建并测度交叉网络。由此,设计如图3 所示的分析流程框架。首先,从项目的题名和摘要中抽取关键词数据并进行清洗,计算基金项目所属不同分部中每个关键词的重要性;其次,根据分部内的基金项目中关键词共现关系构建共现网络并计算分部平均路径长度,其中关键词共现边的权重依据关键词在分部的重要性及关键词对的共现频次进行分配;最后,根据不同分部间的相同关键词集进行分部间交叉度的计算,构建分部交叉网络,并计算各分部在分部交叉网络中的影响力。
3.2 测度指标与方法
1)不同基金分部的关键词重要性计算
TF-IDF (term frequency-inverse document frequency)作为信息检索常用的加权技术,可被用于衡量主题词对特定文档集合的重要程度。因此,本文采用TF-IDF 来计算关键词对特定分部的重要程度。在基金分部i中,关键词km的重要程度wim为
其中,nkm,i表示关键词km在分部i中的词频;Ni表示分部i的关键词总数;|D|表示基金分部总数;|{n:km∈dn}|表示包含关键词km的分部数。则分部i和分部j的词向量di、dj分别表示为
2)基金分部的共词网络与基金学分部间交叉网络构建
基金分部内部关键词的关联程度通过共词网络来衡量。与传统的共词网络不同,为更好地区别基金分部内不同关键词对不同分部的重要性,基金分部的共词网络边权重由关键词共现频次和关键词重要性共同决定,具体计算公式为
其中,Cmn为关键词km和关键词kn的共现频次。
根据分部间相同的关键词集建立分部交叉网络,如果两个基金分部之间存在相同的关键词,那么这两个分部之间存在交叉关系。采用余弦相似度表示分部交叉度,分部间交叉度计算公式为
若Sim(di,dj) >0,则分部i和分部j之间存在交叉;若Sim(di,dj) = 0,则分部i和分部j之间不存在交叉。
3)基金分部平均路径长度
平均路径长度是衡量网络的凝聚程度的重要指标。本文基于网络平均路径长度来衡量基金分部内部知识间关联程度,基金分部平均路径长度(division average path length,DAPL)越短,分部内知识关联越密切,具体计算公式为
其中,dmn为关键词km和关键词kn之间的加权最短路径长度;Ni为分部i的关键词总数;为分部i中最多可以形成的边数量的倒数。
4)基金分部影响力
基金分部影响力(division influence,DIn) 衡量基金分部在交叉网络中的重要程度。考虑到节点度与中介中心性、特征向量中心性等常用网络计量指标的相关性[20],主要采用节点度来衡量基金分部的重要程度。一个基金分部由这个分部与其他分部交叉的数目和强度共同决定,计算公式为
为了统一各类指标的量纲,共现频次、关键词重要程度在后续研究中均进行归一化处理。
4 实证分析
基于上述分析流程框架与测度指标及方法,选取美国NSF 数据中人工智能(artificial intelligence,AI)这个新兴交叉学科领域为数据来源与实证案例。
4.1 数据来源与处理
采用关键词组合检索的策略,根据前期综合研究确定的有关AI 领域的418 个关键词[21],构造检索式“"semantic analysis" or "neural network" or "support vector machine" or "machine learning"…”, 在NSF 官网上检索相关基金项目,限定基金资助时段为2008.01.01—2018.12.31 (检索时间为 2020 年2月)。去重处理后,共获取42126 条基金项目数据,结合本文的研究需要对数据进行人工筛选与研判后,最终得到人工智能领域基金项目数据20524 条。
本文抽取项目数据中的“StartDate(项目开始日期)”“Title(项目名称)”“Abstract(摘要)”“NSFDirectorate(NSF 学部)”“NSFDivision(NSF分部)”字段进行分析。由于基金项目数据缺少关键词字段,且人工智能领域目前没有领域术语词典,无法基于词典进行关键词抽取,所以,本文基于快速自动关键字提取算法(rapid automatic keyword extraction,RAKE)[22]开展研究,这是因为该算法计算速度更快,同时具有更高的准确率和召回率。由此,采用RAKE 算法对基金项目数据中的“Title(项目名称)”和“Abstract(摘要)”字段进行关键词抽取,并根据本文需要对抽取出的关键词进行如下处理:①删除无意义或者意义较为宽泛的关键词,如“algorithm”“model”等;②词形还原;③合并同义词、近义词。
由于个别分部不具有学科类别属性,为保障研究的需要,对这些NSF 分部项目数据做删除处理,主要包括MMA(数学与物理科学学部下的“多学科活动”)分部、EFMA(工程科学学部下的“新兴前沿和多学科活动”)分部、SMA(社会行为与经济科学学部下的“跨学科活动”)分部和NCSES(国家科学工程统计中心)分部以及EF(生物科学学部下的“新兴前沿”)分部。最终对29 个分部下的19853 条项目数据进行分析研究。
经过上述处理,每个分部的项目数量和关键词数量分布详情如表1 所示。其中,IIS(信息智能与系统)受到资助的项目数和关键词数最多,其次为CNS(计算机和网络系统)、DMS(数学)、GMMI(土木、机械与制造)等分部。

表1 NSF各分部项目和关键词数量分布
4.2 NSF分部内部知识关联
共词网络是一种能够表达关键词结构和关联性的一种方法,通过建立NSF 分部的共词网络并计算其平均路径长度(DAPL),来判断NSF 分部内部知识的关联程度,计算结果如表2 所示。整体来看,NSF 各分部平均路径长度分布范围较广,说明在AI领域范围内,各分部内部发展不均衡。从表2 可以看出,IIP(工业创新与合作)、EEC(工程教育中心)、AST(天文科学)等分部内的知识关联比较密切。

表2 NSF分部平均路径长度(DAPL)排序(升序)
4.3 NSF分部间的交叉及演化
1)NSF 分部间的交叉网络
NSF 分部间的交叉网络体现知识在不同分部间的交流、渗透、融合的关系。基于2008—2018 年的所有数据,采用Gephi 对AI 领域基金各分部的交叉网络进行可视化,结果如图4 所示。其中节点代表NSF 分部,节点大小由度决定,即与该分部存在交叉的分部数量越多,节点越大;节点之间的边代表分部间的交叉关系,边的粗细与NSF 分部之间交叉程度呈正相关。表3 为NSF 分部交叉网络不同区间边权重的数量分布及占比。
图4a 中,所有NSF 分部的节点大小相同,即所有NSF 分部间均存在交叉关系,这种现象的产生主要是由于每个基金分部的关键词中均存在部分通用术语,这些通用术语贯通了整个分部的知识交叉网络。根据不同的阈值过滤NSF 分部交叉网络的边,得到图4b~图4d,结合表3 中的占比数值可以看出,大多数边的权重低于0.2,这说明绝大部分NSF 分部间知识交叉融合程度不高。在交叉度大于0.3 的如图4d 所示网络里,CCF(计算与通信基础)和IIS(信息与智能系统)的知识交叉程度最高,其次是IOS(综合有机体系统)和MCB(分子和细胞生物科学),以及CCF (计算与通信基础) 和CNS(计算机和网络系统)等。
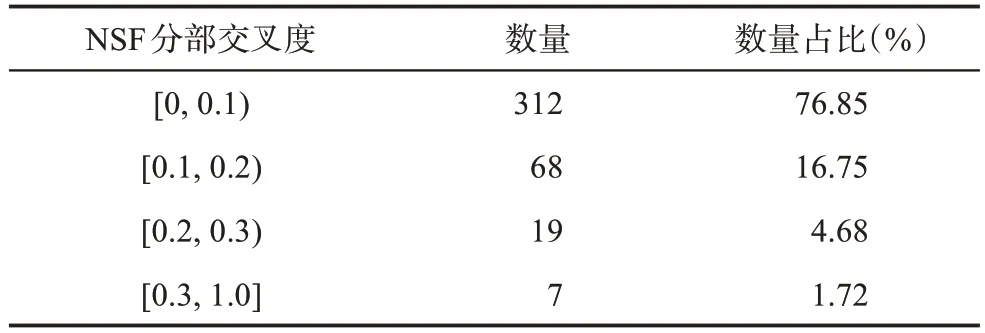
表3 NSF分部交叉网络不同边权重的数量及占比
2)分部间交叉度的演化分布
为了探究NSF 基金分部之间交叉度的变化,绘制如图5 所示的不同阶段交叉度的核密度分布图。根据项目对数据进行筛选后,没有2009 年的项目数据,因此将2008—2018 年划分为2008—2013 年、2014—2018 年两个阶段,每个阶段均包含5 年的项目数据。从图5 可以看出,2014—2018 年的核密度函数明显向右偏移,且分布范围扩大,这表明人工智能领域NSF 各分部间知识的交叉融合程度增加,同时各分部之间知识交叉融合程度出现分化。
表4 所示是在两个阶段中NSF 分部交叉关系变化程度排名Top 10 的结果。交叉程度变化最大的是CCF(计算与通信基础)和CNS(计算机和网络系统),其次是CCF(计算与通信基础)和IIS(信息与智能系统)。在交叉关系中,CCF(计算与通信基础)、CNS(计算机和网络系统)在表中出现次数最多。
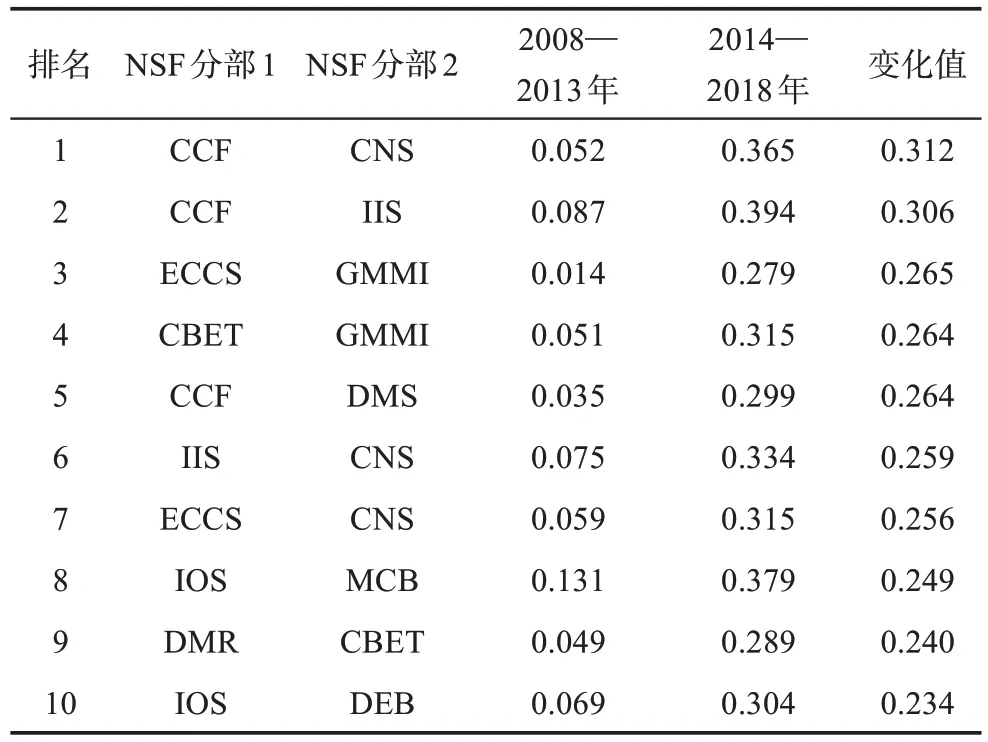
表4 领域内两个阶段NSF分部交叉关系变化程度排名Top 10
3)学部内交叉和跨学部交叉的差异
将分部之间的交叉划分为学部内交叉和跨学部交叉。学部内交叉指的是在同一学部内,各分部之间的知识的交叉融合,跨学部交叉指的是分部之间的知识交叉跨越相同或相似的理论方法及研究背景范围。图6 为学部内交叉度和跨学部交叉度分部的箱型图,表5 则采用均值、方差、标准差和中位数来衡量以上两种交叉方式之间的差异。可以看到,学部内交叉的均值和中位数均高于跨学部交叉,表明实现知识的近距离交叉融合更容易;学部内交叉的方差和标准差均高于跨学部交叉,表明学部内交叉出现分化状态,发展不均衡。
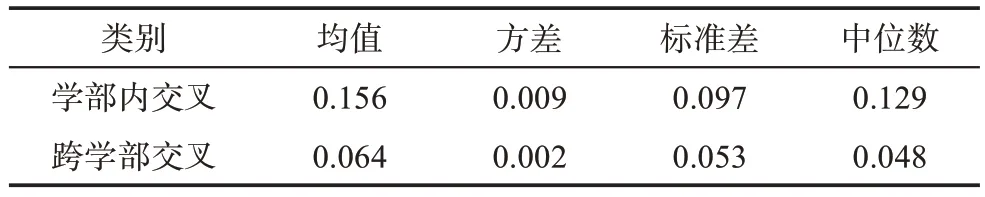
表5 NSF学部内交叉和跨学部交叉的差异
4.4 NSF分部影响力及演化
计算每个NSF 分部在交叉网络中的影响力,结果如表6 所示。其中CBET(化学、生物工程、能源与运输系统)在各分部中的影响力最高,其次是IIS(信息与智能系统)。CBET 支持化学工程、生物技术、生物工程和环境工程领域的创新研究和教育,该分部涉及多学科的领域知识;且结合表4 可知,在2014—2018 年,CBET 在NSF 分部交叉网络中,与GMMI(土木、机械与制造)、DMR(材料研究)的交叉度迅速增加。
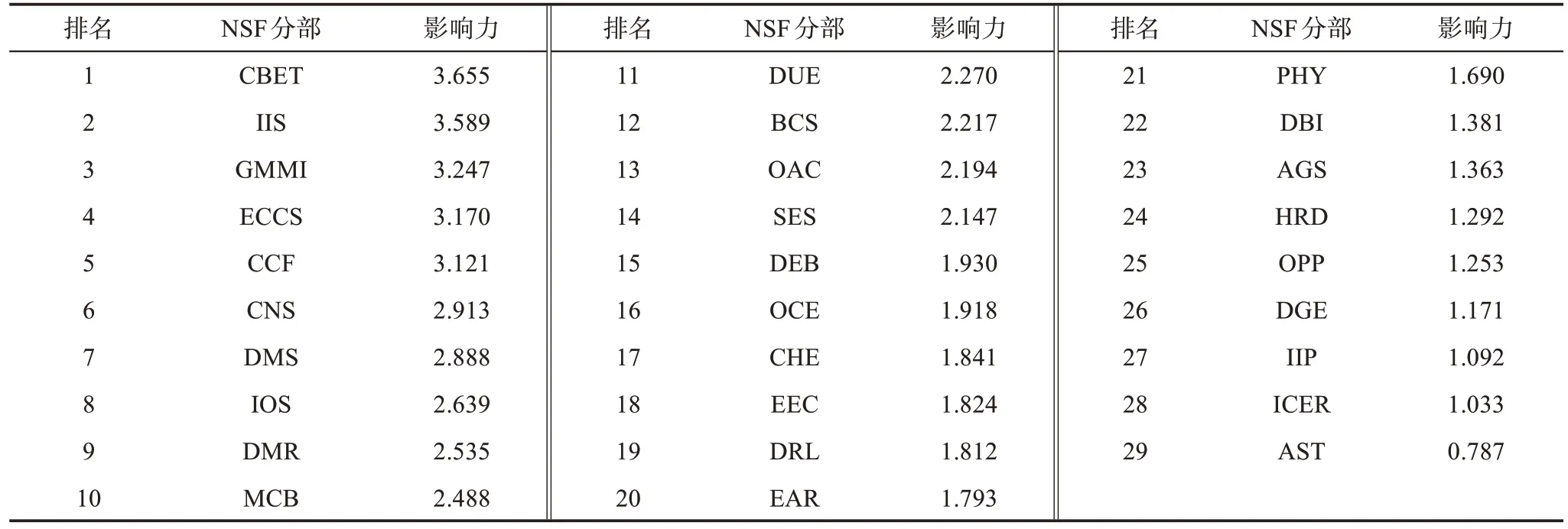
表6 NSF分部影响力及排名
图 7 为不同 NSF 分部在 2008—2013 年、2014—2018 年两个阶段影响力排名的变化。图7 中,两点间的连线代表排名变化的幅度。第二阶段节点出现在第一阶段节点上方,代表第二阶段的影响力排名均为下跌趋势;出现在第一阶段节点下方,则代表影响力排名出现上升。可以发现,HRD(人力资源开发)、DBI(生物基础设施)、AGS(大气与地球空间科学)、EAR(地球科学)的影响力排名下跌幅度较大,而ECCS(电气、通信与网络系统)、GMMI(土木、机械与制造)影响力排名上升较快。这表明随着人工智能领域资助计划的项目的变化,HRD 等分部与其他分部知识的交互性减弱,ECCS、GMMI 等工程学领域知识与其他分部的知识的融合增加。
4.5 NSF分部平均路径长度和影响力的关联性
计算不同NSF 分部的平均路径长度(DAPL)和影响力(DIn)并进行归一化处理,以平均路径长度和影响力的中位数作为原点进行可视化展示。按照是否高于NSF 分部的平均路径长度的中位数和影响力中位数将NSF 分部划归为不同组合的四个组,具体分布情况如图8 所示。
从整体来讲,NSF 分部平均路径长度和影响力的分布比较聚集,这是由于所研究的分部属于同一个学科领域,因此,分部的路径长度特征和影响力特征均比较相似。
高路径长度-高影响力(high DAPL- high DIn):相对于其他分部,分部内部的知识关联程度低,但是与其他分部的知识有较好交叉融合。代表分部有IIS (信息与智能系统)、CNS (计算机和网络系统)、GMMI(土木、机械与制造)、CBET(化学、生物工程、能源与运输系统)等。
高路径长度-低影响力(high DAP - low DIn):内部知识关联较少,且研究内容与其他分部的研究重合度低。代表分部有PHY(物理学)、DBI(生物基础设施)、EAR(地球科学)等。
低路径长度-高影响力(low DAPL - high DIn):内部知识联系密切,研究主题较为集中,且与其他分部的知识有较好交叉融合。代表分部有ECCS(电气、通信与网络系统)、IOS (综合有机体系统)、MCB(分子和细胞生物科学)等。
低路径长度-低影响力(low DAPL - low DIn):内部知识关联密切,但与其他学部之间的知识交叉融合程度不高。代表分部有ICER(综合与协作教育研究)、CHE(化学)、OCE(海洋科学)等。
基于Spearman 相关性对项目数量、分部平均路径长度、分部影响力三个指标的相关性进行检验,结果如表7 所示。可以发现:①分部的平均路径长度与分部影响力均与受资助项目数量正相关,即受资助项目数量越多,关键词的多样性越明显,分部的平均路径长度越大,使得内部的知识凝聚性减弱。同时,随着项目数增加,分部影响力增强,使得分部间的知识交叉融合程度加深。因此,随着项目数量的增多,分部内的知识凝聚性降低,而分部间的知识交叉融合程度增加。②分部影响力和分部的平均路径长度两个指标没有显著的强相关性,因此可以作为不同视角的测量指标。
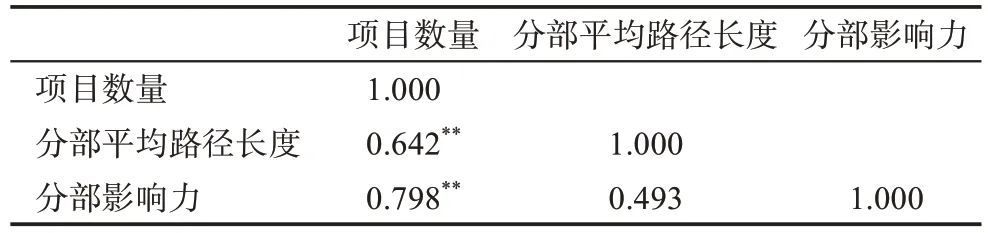
表7 Spearman相关性检验
5 结论与讨论
本文针对科学基金数据的属性特征,将共词网络分析与学科交叉研究等方法相结合,设计学科交叉研究的分析流程与测度指标,以美国NSF 数据为来源,选取AI 领域为实证案例,利用共词网络研究NSF 中AI 领域各分部内知识的关联性,进而通过所构建的交叉网络探究NSF 各分部间的知识的相互渗透和影响,使用平均路径长度和点度中心度两个指标分别对基金分部内部知识的发展和学部间知识的交叉程度进行测量,分析科技导向和投入对于交叉研究的影响及交叉研究态势变化的特征。最后,对分部内部知识的发展与分部间交叉程度的相关性进行阐释,得到以下结论。
(1)在分部内部知识聚集程度上,NSF 各分部平均路径长度分布范围较广,说明在人工智能领域内,NSF 各分部资助力度的不同导致各分部内部知识不均衡的发展态势。
(2)在分部交叉网络分布及演化上,大多数分部间交叉融合程度不高,但随着NSF 资助力度的增加,分部间知识交叉融合能力增强,同时各分部之间知识交叉融合的程度出现分化,美国人工智能领域研究的分部交叉具有显著的学科属性并渐成有区隔的核心研究方向。
(3)NSF 的知识交叉集中在有相同或相似的理论方法的学科框架之下,表明知识实现近距离交叉融合更容易。而如何通过政策导向和投入提升知识的远距离交叉,实现重大甚至尖端的科学问题是值得进一步探讨的内容。
(4)分部内的知识凝聚程度和分部间的交叉程度与受资助项目数量存在相关关系。受资助项目增多,受资助主题的多样性增加,分部内的知识凝聚程度降低而分部间的交叉度增强。
综上所述,在科技政策引导下,美国人工智能领域交叉研究得到了有力的推动。一方面,促使该领域形成了稳定的主导分部及其核心知识体系,并对其他分部产生较大的影响,如IIS(信息与智能系统);另一方面,在该领域基金分部以其自身属性特征参与知识交融,并促进交叉演化态势的不断变化,而不同分部内部和分部间的知识关联与渗透演化及其影响的发展是不均衡的。
本文的研究工作还存在一些局限性。例如,采用共词网络对分部内知识体系进行构建难以从语义关系和认知维度体现知识间的内在关联,后续可考虑引入词向量等方式增加关键词的语义信息。同时,本文只讨论了受资助项目数量对于分部内部和分部间知识关联的影响,在后续研究中应考虑采用定性、定量分析相结合的方法,对其他相关因素进行探究,为政策制定提供更加有力的参考借鉴。
猜你喜欢
科技进步与对策(2023年18期)2023-10-09 02:22:14
浙江大学学报(理学版)(2023年3期)2023-06-07 11:16:38
现代特殊教育(2022年2期)2022-07-02 09:19:14
科技进步与对策(2022年1期)2022-01-24 02:13:10
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
浙江大学学报(理学版)(2017年3期)2017-05-18 02:10:07
考试周刊(2016年86期)2016-11-11 07:46:31
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
计算机工程(2015年8期)2015-07-03 12:19:54
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
