
基于决策重要度的概念认知学习模型
2022-10-17 13:08:26王启君林艺东林梦雷
模式识别与人工智能 2022年9期
王启君 林艺东 林梦雷,2 寇 毅
“概念”一词来源于哲学,是外延与内涵的统一.概念学习理论作为粗糙集理论的高度补充,在规则提取、对象分类等领域具有广泛的应用价值[1-5].经典概念通过内涵和外延描述同类事物的本质特征,为概念学习提供数学基础[6-13].其中,对象(外延)和属性(内涵)的关系是分明的,即属性是否为对象所拥有.然而在实际应用中,对象与属性之间的关系通常是模糊的、不确定的,连续型数据只有通过离散化预处理才能进行经典概念学习,这期间往往会造成信息丢失[8-10].
作为经典概念的扩展,模糊概念能处理连续型数据,通过把属性值转换为对象的隶属度以刻画概念,不仅降低由于离散化产生的耗时,并且保留原始信息[2,5,14-15].目前,已有许多学者在信息描述、模式识别与概念聚类等方面进行相关研究[2,9,12,14].Cross等[14]对比单边阈值方法和模糊闭包算子方法分别产生的模糊概念格,发现前者概念的外延是后者外延的子集.Xu等[11]基于粒计算提出双向概念认知模型,能有效处理实际问题中的模糊知识.
随着科学技术的发展,尤其是数据科技和人工智能的兴起,概念认知学习理论(Concept-Cognitive Learning, CCL)逐渐成为认知科学、脑科学、计算机科学等领域的研究热点.CCL的主要思想是通过具体的认知模型从给定线索中进行概念学习,揭示人脑概念学习的系统性规律.然而,在自然条件下,概念学习容易受到认知环境和个体认知水平等因素的影响[2,16-19].李金海等[17]提出概念的渐进式认知理论与方法,处理不完全认知条件下的概念获取问题.在概念认知学习理论的发展过程中,李金海等[18]对概念认知的公理化、概念认知系统、概念认知过程等问题进行进一步思考与研究.徐伟华等[19]提出模糊三支算子,用于讨论模糊三支概念的概念认知学习方法.
为了克服认知环境的限制,一些学者研究基于进化计算的概念学习方法,并通过实验验证其有效性[2,3,16,20-28].Mukhopadhyay等[20]提出多目标进化算法,解决工程中的多目标问题.Dragoni[21]基于概念域,提出多域情感分析进化策略.为了提高概念学习的效率和灵活性,Li等[8]从认知计算的角度讨论基于粒计算的概念学习.Mi等[2]考虑个体认知水平和认知环境的限制,从概念聚类角度阐述模糊概念.
大型数据集的时限性、多样性、复杂性等因素使高效计算概念空间成为必要.为了降低概念认知学习过程的复杂度,Shi等[22]利用并行计算,提高概念认知学习效率.Zhang等[23]基于属性拓扑设计概念更新算法.Tsang等[3]提出多层次认知机制.Wang等[24]利用特征之间的相关性设计具有认知推理能力的分类模型.
概念的构建和概念空间的更新是概念认知学习中影响学习效率的两个重要因素.对于动态分类问题,Yan等[25]基于三支偏序结构图,提出增量概念认知学习方法.Mi等[26]从概念认知计算系统的视角出发,实现对数据的动态分类.Xu等[27]考虑注意力对概念认知的影响,提出多注意概念认知学习模型.为了去除一些不必要信息的影响,根据概念内涵之间的差异性,Yuan等[28]提出基于渐进模糊三支概念的增量学习机制,却忽略先验决策信息对概念认知的影响,导致部分有效信息的丢失.
受文献[28]的启发,本文利用先验决策信息,提出基于决策重要度的概念认知学习模型.首先,引入余弦相似度构造邻域粒,生成相应的模糊概念空间.考虑到个体认知的局限性和认知环境的不完全性,进一步构建渐进模糊概念空间.由于不同决策对对象的影响程度不同,通过渐进模糊概念的外延得到某一决策对该概念的决策重要度和置信度,以此讨论概念分类,并设计相似性度量指标.最后,通过实验验证本文模型的有效性.
1 相关知识
本节主要回顾模糊形式背景和模糊概念的定义[28].

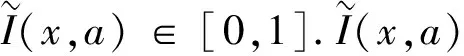

在形式概念分析中,将概念定义为由内涵和外延组成的二元组.符合概念的全体对象的集合称为概念的外延,此集合全体对象共有的属性称为概念的内涵.然而,经典形式背景下只能判断一个对象是否具有某个属性.若具有,为1;否则为0.但现实生活中很多问题不能通过绝对真1和绝对假0来刻画,而模糊形式背景可通过对象对属性的拥有程度处理模糊状态下的部分问题.




2 基于邻域粒的渐进模糊概念空间的构造
粒化是粒计算的基本问题.在模糊形式背景中,对象的相似度通常使用其属性之间的距离进行刻画.本文利用相似度描述对象之间的邻域关系,以此构造模糊概念空间.

为对象xi、xj之间的余弦相似性.显然,cos(xi,xj)∈[0,1],当对象的余弦相似性大于某值时,认为它们相似度较高,越趋近1,表示两个对象的方向越接近.在本文中,引入参数δ,由此得到每个对象的邻域粒.



模糊概念空间为C={C1,C2,…,Cl},每个Ci称为C的第i个子空间.同时,注意到δ值会影响邻域粒的大小,不同对象集的最小隶属度会不同,进而内涵会随外延变化而变化,因此模糊概念会受到δ值的影响.此外,本文提出的对象分类机制是基于模糊概念的,因此δ将进一步影响模型目标分类性能.在算法1中给出模糊概念空间的构造过程.
算法1构造模糊概念空间
输出模糊概念空间C
令Ci←Ø;
forx∈X

end
例1表1为包含10个对象和2个属性的模糊决策形式背景,对象被b1和b2描述.
在模糊决策形式背景下,令δ=0.95,根据定义5,得到相应邻域粒:
进而得到模糊概念子空间:
C1=({x1,x2,x4},(0.04,0.47)),
C2=({x1,x2,x4,x5},(0.04,0.47)),
C3=({x3,x5,x6},(0.28,0.47)),
C4=({x2,x3,x5,x6},(0.11,0.47)),
C5=({x7,x9},(0.68,0.11)),
C6=({x8,x9,x10},(0.75,0.32)),
C7=({x7,x8,x9,x10},(0.68,0.11)).
模糊概念空间C={C1,C2,…,C7}.
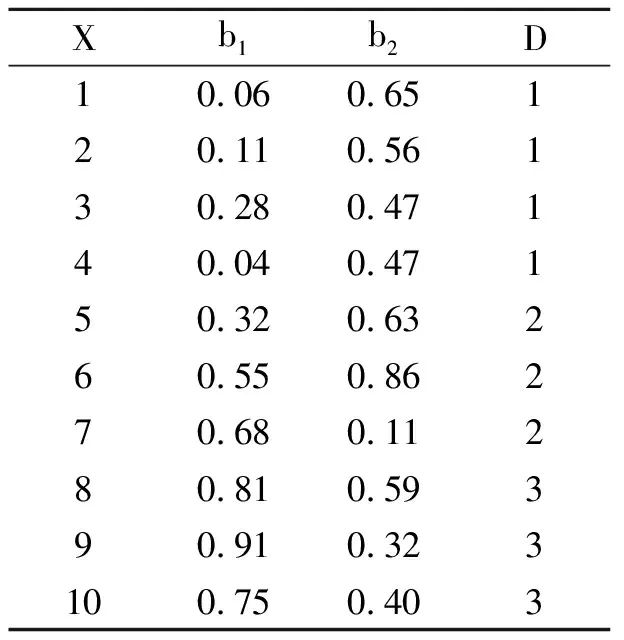
表1 模糊决策形式背景Table1 Fuzzy formal decision context
在模糊概念空间中,概念之间相互影响,甚至存在大量的重复信息.与此同时,由于个体认知的局限性和认知环境的不完全性,概念认知通常是渐进的.因此,为了提高认知的准确性,在原有模糊概念空间的基础上构建对应的渐进模糊概念空间.

称Pi=(Qi,Gi)为渐进模糊概念空间.
在渐进概念的学习过程中,不同子概念的内涵根据其相应外延大小被赋予不同的权重.子概念对新概念生成的影响随外延的增加而增大.同时,所有概念的权重之和为1,即总效应之和为1.因此,在算法2中给出选择上确界概念和获取渐进模糊概念空间的详细过程.
算法2构造渐进模糊概念空间
输入模糊概念空间C={C1,C2,…,Cl}
输出渐进模糊概念空间P={P1,P2,…,Pl}
投身脱贫攻坚的青春身影,把希望和信心带进大山深处;“脑洞”大开的创业团队,为放飞梦想努力打拼;风华正茂的年轻法官,甘当法治建设的“燃灯者”;激情满怀的青年人才,扛起航天报国的千钧重担;沙场练兵的勇毅战士,用方刚血气筑起保家卫国的钢铁长城……
for Ci∈C
Ci∈Ci-S;

else
end



end
end

计算渐进模糊概念(Qi,Gi);
Pi←(Qi,Gi);
end
end
例2(接例1) 根据定义7,由例1中模糊概念进一步得到渐进模糊概念:
P1=({x1,x2,x4,x5},(0.04,0.47)), P2=({x2,x3,x5,x6},(0.195,0.47)), P3=({x7,x8,x9,x10},(0.6975,0.1625)).
3 基于决策重要度的概念认知学习模型
面向动态环境,如何基于概念空间识别新增对象的类标签是一个值得探讨的问题.为了解决此问题,本文提出决策重要度和置信度,再充分融合二者信息,提出概念认知学习模型.
3.1 渐进概念的决策重要度和置信度
在动态环境中,原有决策信息会对新增对象的学习产生影响,然而这部分信息往往被人们忽略.因此,为了充分利用先验决策信息,在渐进概念的基础之上引入决策重要度和置信度,用于刻画分类指标.

例3(接例2) 根据定义1,
则
由于决策重要度有时会产生相等的情况,导致无法确定对象的决策,因此本文引进决策置信度对其进行进一步处理.
由于渐进模糊概念的初始邻域粒可能由多个子邻域组成,多个邻域粒之间相互影响,故需计算每个子邻域的决策置信度,融合后得到最终决策置信度.具体融合方式如下.
若存在
则

算法3构造基于渐进概念决策重要度
渐进模糊概念空间P={P1,P2,…,Pl}
输出决策重要度sig(Gi,dj)
for Gi∈P
forxi∈X


end
end
end
例4(接例3) 根据定义8,
其渐进模糊概念初始邻域粒为
则
3.2 基于决策重要度的增量学习机制
本文结合分类机制与动态更新机制,构建基于决策重要度渐进模糊概念的学习机制.首先对比新增对象与原渐进概念的信息,寻找相似性最大的渐进概念,再选取其决策重要度最大的决策更新新增对象的信息,具体过程如算法4所示.
算法4基于决策重要度的分类机制
输入渐进模糊概念空间P={P1,P2,…,Pl},
新增对象xa
输出xa的类别
for Pi∈P
计算cos(Pi,xa);
得到si=index(maxcos(Pi,xa));
forsi∈Pi
xa的类别为max(sig(si,di));
end
end
当添加新对象xa时,X′=X∪{xa},构造渐进模糊概念空间的时间成本很高.为了减少耗时,本文设计决策重要度的动态更新机制(Incremental Lear-
ning Mechanism for Fuzzy Concept Based on Decision Significance, FCDS).在此过程中,只需计算xa和Ci∈C的相似度以更新模糊概念空间,进而更新决策重要度,而不需要计算与每个样本的相似度.决策重要度的动态更新过程如算法5所示.
算法5决策重要度的动态更新机制

添加的对象xa,参数δ

for Ci∈C
计算cos(xa,Ci);
xi=index(maxcos(xa,Ci));
end

由于|Ci|为原始概念空间的个数,算法总的时间复杂度为
即为动态更新决策重要度的时间复杂度.
4 实验及结果分析
4.1 实验环境
为了验证本文提出的决策重要度的动态更新机制(FCDS)的分类性能,选择如下对比算法:ILMPFTC(Incremental Learning Mechanism Based on Progressive Fuzzy Three Way Concept)[28]、KNN(k-Nearest Neighbor)、CART(Classification and Re-gression Trees)、NB(Naive Bayes)、DT(Decision Tree).
根据定义9的分析可知,参数δ是影响分类精度的一个重要参数.在实验中,FCDS和ILMPFTC根据添加对象的分类精度选择最佳δ,选择范围为[0,1],步长为0.001.其它4种对比算法都具有相同的邻域参数k,本文中k=3.
实验选择UCI机器学习库上的11个实验数据集,详细信息如表2所示.

表2 数据集详情Table 2 Dataset description
在预处理阶段,对数据集进行归一化,得到区间[0,1]内的隶属度.本文使用文献[29]对这些数据集进行归一化:
(1)
其中,f(xi,aj)表示属性aj中xi的值,max(f(aj))和min(f(aj))表示属性aj中所有对象的最大值和最小值.在模糊决策形式背景中,R(xi,aj)反映(xi,aj)对aj的隶属度.通常,模糊集可理解为对象对属性的拥有程度.f(xi,aj)的值越大,x拥有属性a的程度越大.式(1)作为一种模糊化方法,可将原始数值转换为模糊决策形式背景.
在每个数据集上,70%的数据用于训练模型,剩余数据均分为10份,逐次添加至测试集上,由此验证FCDS的分类性能和有效性.
所有算法均在Matlab 2021b上实现,并在配置为Intel(R)Core(TM)i7-7700 CPU@3.60 GHz和8 GB内存的个人计算机上执行.
4.2 各算法分类性能的对比
各算法在11个数据集上添加对象时的分类精度对比如表3所示,表中,t1~t10表示逐次添加测试数据的时间,黑体数字表示最优值,-表示该算法在两周之内未输出结果.由表可见,除了Breast数据集,FCDS的分类精度都大于或等于对比算法,同时,FCDS在8个数据集上的平均分类精度最高,这表明利用决策重要度可提高样本的分类性能,由此验证FCDS的有效性.利用先验决策信息也可提高分类器性能,使分类更准确.

表3 各算法添加新对象时的分类精度

表3 各算法添加新对象时的分类精度(续)
分类精度虽然常用,但不能满足所有任务需求.本节通过其它性能度量,说明FCDS的有效性与优越性.
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(True Positive)、假正例(False Positive)、真反例(True Negative)、假反例(False Negative)4种情形,令TP、FP、TN、FN分别表示其对应的样例数,显然有
TP+FP+TN+FN=样例总数.
查准率P与查全率R分别定义为
为了更好地刻画学习器的分类效果,F1度量定义如下:
对于多个二分类混淆矩阵,如执行多分类任务,每两两类别的组合都对应一个混淆矩阵.本文先在各混淆矩阵上分别计算查准率和查全率,再计算平均值,得到宏查准率(macro-P)、宏查全率(macro-R)、相应的宏F1(macro-F1):
各算法在11个数据集上的查准率和查全率对比如表4所示,表中黑体数字表示最优值,-表示真正例和假反例或假正例和真反例的个数都为0.由表可知,FCDS在6个数据集上的查准率和查全率都大于或等于对比算法,在Colonstd数据集上取得最大查准率.ILMPFTC只在Zoo数据集上取得最大查全率和查准率;CART在Breast、Gearbox数据集上取得最大查全率和查准率,在Colonstd数据集上取得最大查全率,在Rice数据集上取得最大查准率;DT在Congressional Voting Records数据集上取得最大查全率和查准率,在Rice数据集上取得最大查准率;NB在Gearbox数据集上取得最大查准率和查全率.由此说明FCDS在分类效果上具有一定的优越性.

表4 各算法的查准率和查全率对比
各算法在11个数据集上的F1度量如表5所示,表中黑体数字表示最优值.由表可看出,FCDS在11个数据集中获得8次最大值,说明FCDS在分类方面的优越性.

表5 各算法的F1度量对比
4.3 统计检验
为了进一步验证分类算法是否性能相同,本节选择常用的Friedman检验[30],验证算法是否存在显著差异.设N为数据集数,k为算法数目,Ri为所有数据集上第i个算法平均排名.F遵循自由度为k-1和(k-1)(N-1)的Fisher分布.Friedman检验定义如下:
由于在NB中有部分数据未得出结果,因此在本次检验中只考虑FCDS与其它四种算法的差异性.对5种算法的分类精度进行排序,详细的排序结果如表6所示.
根据定义,计算F=10.28,大于临界值F=2.090,因此可知这5种算法有一定差异.下面使用Bonfer-
roni-Dunn检验测试5种分类算法之间的统计差异[32].当
k=5,N=11,α=0.1
时,q0.1=2.459,得到临界距离

表6 算法的分类精度排名Table 6 Classification accuracy rank of 5 algorithms
对于任意两种算法,如果它们的距离超过CDα,说明这两种算法的性能具有显著不同.本文使用Bonferroni-Dunn测试图[31]直观显示5种算法之间的统计学差异,具体如图1所示.图中使用灰色线段绘制临界差CDα=1.11,然后连接距离小于1.11的分类算法,越靠近1说明算法性能越优.由图可看出,FCDS与其它4种算法的平均排名的差值都大于临界差1.11,说明FCDS的分类性能与其它算法具有显著差异.

图1 各算法Bonferroni-Dunn测试图对比Fig.1 Bonferroni-Dunn test graph of different algorithms
5 结 束 语
本文提出基于决策重要度的概念认知学习模型,结合决策信息与渐进模糊概念,获得更优的分类性能.随着更新后的概念被进一步学习,概念空间包含新增对象的新信息,因此通过先验决策信息和新信息的结合可提高分类精度.同时,在11个公共数据集上的实验验证上述结论.在现实生活中,只要能从概念思维上描述对象,FCDS就可用于解决其相应的分类问题,如模式识别和人脸识别.同时,增量学习的思想也可应用于动态增加的数据,如时间序列数据.但是,本文算法对数据集决策分布依赖较大,当决策分布不均匀时,分类效果无明显优势.因此,今后将着重探讨决策分布不均匀时的分类方法.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
现代电子技术(2018年20期)2018-10-24 04:39:04
现代情报(2018年11期)2018-01-07 09:41:14
现代电子技术(2017年23期)2017-12-20 13:23:31
数学物理学报(2017年5期)2017-11-23 07:51:31
计算机应用(2016年10期)2017-05-12 11:02:20
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
新课程学习·中(2013年3期)2013-06-14 05:55:20
中国管理信息化(2009年10期)2009-06-19 08:24:28
