
空间信息感知语义分割模型的高分辨率遥感影像道路提取
2022-10-15 06:24吴强强王帅王彪吴艳兰
遥感学报 2022年9期
吴强强,王帅,王彪,吴艳兰,3
1.安徽大学 资源与环境工程学院,合肥230601;
2.武汉大学 资源与环境科学学院,武汉430079;
3.安徽省地理信息智能技术工程研究中心,合肥230601
1 引言
高分辨率遥感影像的道路提取在地理信息更新、城市规划、路线导航和救灾应急等应用中发挥着极其重要的作用。近年来针对道路提取的研究越来越多,但是由于道路的背景环境复杂、阴影遮挡以及高分辨率遥感影像中地物信息丰富导致的“同谱异物”和“同物异谱”现象(文贡坚和王润生,2000)等问题的存在,高效的道路提取方法的提出仍然存在许多困难。
道路提取方法大致可分为基于道路形状、纹理、灰度阈值和深度学习这4类方法。基于道路形状的提取方法主要利用道路的形状特征结合其他方法提取遥感影像中的道路,比如,在基于道路形状特征方面,有混合像素对象(Song和Civco,2004)、多特征匹配(付仲良 等,2016)和结合同质特征(许锐,2014)等的道路提取方法。该类方法在噪声较多的情况下提取道路具有优势,但是一般需要人为设置参数,自动化程度不高,因此研究人员着眼于道路纹理特征的提取。纹理特征是道路的内在属性,描述了像元灰度的分布情况,依据道路的纹理特征能够有效的提取道路信息,比如,基于道路纹理的提取方法有FMH模型(Hong等,2019)、基于角度纹理特征的城市道路全自动提取(Haverkamp,2002)和结合角度纹理特征与Ziplock Snake算法的道路提取(陈卓等,2013)等。基于道路纹理的提取方法有利于提取城市道路,但是对于复杂情况适应性差,例如阴影遮挡的情况。为了更好地提取道路信息,研究人员利用灰度阈值方法来分割道路地物特征(张永宏等,2018),主要包括双阈值法(周家香等,2013)、Otsu阈值法(Mu等,2016)和基于霍夫检测的道路检测与提取(李建和张其栋,2017)的方法。这些阈值分割方法对规则形状提取效果好,但方法对于复杂形状的适应性差、提取效率低。总体而言,上述道路提取方法在针对特定任务时表现较好,但方法主要依赖设定的阈值参数,由于这些参数可能在不同的图像中有所差异(Mnih和Hinton,2010),从而导致泛化能力弱。除此之外,这些方法难以满足道路提取任务的精度和时间要求。随着深度学习技术飞速发展,其在场景识别、物体检测、语义分割等计算机视觉任务上取得了优异成绩,它能够自动学习大数据中的有效特征,并对同一类问题具有普适性。所以,大量的研究人员开始利用深度学习方法处理卫星遥感数据(Sherrah,2016;Nogueira等,2017)。
近几年来,许多研究已将深度学习方法应用于道路提取任务,基于深度学习道路提取的方法可以分为基于卷积神经网络(CNN)和全卷积神经网络(FCN)的道路提取方法。基于CNN道路提取方法,包括,带有RBM(Restricted Boltzmann Machine)(Mnih,2013)、基于补丁(Alshehhi等,2017)和利用Wavelet Packet Method(Jiang,2019)等卷积神经网络。此类方法结合卷积神经网络和其他方法进行道路提取,其优势是不需要设计特征,但输入影像的尺寸是受限的,而且基于补丁的提取方法比较耗时。基于FCN道路提取方法,同样借助卷积来提取道路特征,区别是FCN用卷积层替换全连接层,并且输入影像的尺寸不受限制,通过上采样操作可以得到与输入影像相同尺寸的分割图,例如,Deep Residual U-Net神经网络(Zhang等,2018)、SegNet网络(Panboonyuen等,2017;Badrinarayanan等,2017)和D-LinkNet网络(Zhou等,2018)等道路提取方法。以上网络模型均采用高效的编码—解码结构并取得了显著的效果,但是这些方法仍具有FCN网络结构的弊端,即下采样过程中卷积和池化操作会造成空间特征的丢失,导致细小道路和细节信息的提取效果差。Zhou等(2018)提出D-LinkNet结构,利用空洞卷积替换下采样中的池化操作,扩大感受野的同时有效地减小了空间特征的损失。但是连续的空洞卷积操作导致空间特征的不连续,产生“棋盘效应”,造成特征信息的损失。
针对以上问题,本文以改进的残差模型(Residual Network,简称ResNet)(He等,2016)为基础,利用U-net(Ronneberger等,2015)结构,并且引入坐标卷积(CoordConv)和全局信息增强模块提高空间信息感知,设计了一种改进的网络模型。为了充分利用道路细节信息,本文模型采用改进的ResNet作为主体网络,提取不同尺度和不同级别的目标特征;此外,针对池化操作造成的空间特征丢失问题,本文在编码结构前引入坐标卷积,抽取空间坐标信息,用于增强空间信息变化的感知、减轻空间信息丢失;同时,针对空洞卷积的“棋盘效应”导致的上下文信息缺失情况,在编码结构后加入全局信息增强模块,加强全局空间信息的感知,获取全局语义信息,提高道路分类的一致性。
2 模型网络结构
2.1 网络框架
本文以ResNet与U-net网络为主体框架,网络顶部利用坐标卷积机制,编码部分使用全局信息增强模块,提出一个改进的全卷积网络模型。网络入口放置坐标卷积层,它将坐标信息存储在附加通道中并与原先通道合并成一个整体作为输入,目的在于获取输入坐标信息,精确特征图中的像素位置。编码器部分,采用4个改进的Residual block(He等,2016)来抽取不同级别的抽象特征,Residual block由若干残差单元堆叠而成。在解码器部分,通过反卷积恢复由编码器中池化操作生成的特征图的分辨率,再与编码部分中分辨率相同的低级特征进行跳跃连接。网络输出会得到与输入影像同样大小的分割图。网络的最后一层为带有ReLU(Rectified Linear Unit)激活函数的1×1卷积层。为了详细展示我们设计的网络,模型的具体参数如图1所示,在结构图中标注了每一层网络的输入输出大小。由于道路提取是二分类任务,所以网络输出形状为512×512×2。
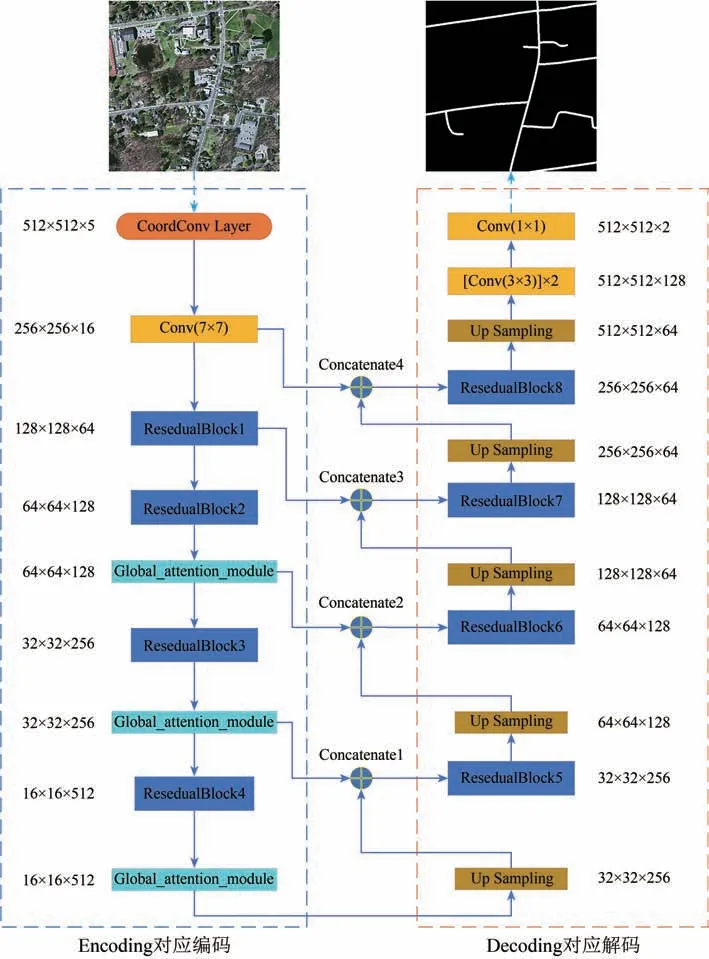
图1 本文的模型结构Fig.1 The model structure of this paper
一般全卷积神经网络的层数越深,表现效果越好,但是存在着性能退化等问题。为了克服这类问题,本文模型采用残差单元(He等,2016)代替普通卷积层。残差单元主要包含快捷连接(shortcut connection)层、批处理归一化BN(Batch Normalization)层、非线性激活函数(ReLU)和卷积层(Conv Layer),其中快捷连接层能够增强上下层信息流,提高特征的复用率,减少参数数量,有效的提高了网络的性能。因为BN对batch size有严格的要求,因此当batch size较小时,归一化误差将迅速增加,从而削弱了模型的性能。由于计算机内存限制,在训练过程中batch size通常无法满足BN要求。与BN相比,组归一化GN(Group Normalization)(Wu和He,2018)的计算与batch size无关。当batch size小时,精度稳定。本文根据实际情况对残差单元进行了改进,将批处理归一化换成组归一化。残差单元的公式定义如下:

式中,xl和xl+1是第l个残差单元的输入和输出,F(xl,wl)是残差函数,f(yl)是激活函数,h(xl)是恒等映射函数。
2.2 坐标卷积
针对常规卷积神经网络无法有效顾及特征空间位置信息的问题,Liu等(2018)提出了坐标卷积。坐标卷积是标准卷积层的扩展,主要在标准卷积层中引入坐标信息。坐标卷积提取特征中的空间信息作为额外的通道与原始特征拼接,添加的通道一般称为i坐标和j坐标。这两个坐标均经过相关的线性变换,并归一化到[-1,1]范围内。i坐标和j坐标能够有效的存储特征中的空间位置信息,即特征边缘的水平和垂直信息。坐标卷积机制能够突出细节信息、减少特征损失和加强边界信息,有利于像素分割任务。标准卷积和坐标卷积对比如图2所示,h、w和c分别代表输入特征的高、宽和通道数;h1、w1和c1分别代表卷积之后的高、宽和通道数。

图2 标准卷积层和坐标卷积层的对比Fig.2 The comparison of structure between the standard convolutional layer and coordconv layer
2.3 基于全局池化的全局信息增强模块
全局池化具有提高全局上下文感知的能力(Yu等,2018)。本文设计了基于全局池化的全局信息增强模块,结构如图3所示。该模块主要由平均池 化、1×1卷 积、ReLU激 活 函 数、1×1卷 积 和Sigmoid激活函数串联组成,生成的通道权重与输入特征相乘,接着与输入特征进行相加。全局信息增强模块改变了输入特征权重,用于优化类别内预测一致性,增强了语义信息,提高了道路的分割精度。

图3 基于全局池化的全局信息增强模块Fig.3 Structure of the Global information enhancement module based on global pooling
3 数据与实验
3.1 数据集
3.1.1 Massachusetts roads数据集
Massachusetts roads(Mnih和Hinton,2010)是世界上公开的道路数据集中规模最大的。该数据集共有1171张图像,包括1108张训练图像,14张验证图像和49张测试图像以及对应的标签图。每张图像的大小为1500×1500像素,分辨率为1.2 m/像素。该数据集包含各种地物,如道路、草地、森林和建筑物等。
由于数据集中影像数量太少,不利于模型的充分训练,本文对数据集进行切分。训练集中1108张1500×1500像素的遥感影像及相对应的标签图切分成512×512像素尺度的影像样本(首先按顺序切割整幅图,然后在图上随机切分)。根据数据集划分的规则,将所有切分后的样本数据按4∶1的比例随机分为新的训练集和测试集。最终,训练集包含14366张512×512像素尺度的图像,验证集包含3592张512×512像素尺度的图像。本文利用制作的数据集训练提出的网络模型,并在Massachusetts roads数据集中的测试集和验证集上测试模型性能。
3.1.2 高分二号道路数据集
本文使用28幅位于安徽合肥地区和天津地区的分辨率为1 m的高分二号影像制作道路数据集,其中该数据集包括16幅大小为4909×4672和12幅大小为4578×4442的影像。所有影像通过人工标注的方式制作遥感道路地面真值。本文将这28幅影像分为训练数据集(20张影像)、验证数据集(2张影像)和测试数据集(6张影像)。为了充分训练模型,本文对训练集和验证集进行切分增加样本数量,样本分割的大小为512×512。最终用于训练数据为5892张,验证的数据为1480张;此外,4幅大小为4578×4442的安徽合肥地区和2幅大小为4909×4672的天津地区的遥感影像被用于验证评估。
3.2 软硬件环境
在本文中,提出的模型使用TensorFlow作为深度学习框架,开发平台使用JetBrains PyCharm 2017,开发语言是Python,所有模型均在配置为Intel Core(TM)i9-7980XE CPU和NVIDIA GeForce GTX 1080 Ti显卡的计算机上训练和测试。
3.3 模型训练细节
本文模型使用交叉验证的训练方式,即训练集和验证集同时输入模型,每训练一次便在验证集上随机选取一个batch size数据来计算损失和精度,优化模型的训练。
由于模型训练对计算机的GPU内存要求很高,本文方法将大小为512×512的图像作为网络的输入。Adam(Kingma和Ba,2015)是一种具有高计算效率和低内存要求的自适应学习率优化器,因此本文利用Adam优化器进行优化网络并更新参数;此外,本文提出的网络使用BCE(Binary Cross Entropy)+dice coefficient loss(Zhou等,2018)作为损失函数,batch size设为4,轮数为50轮,每轮的迭代次数为4000,初始学习率设为1E-4。为了更好地训练模型,学习率会随着训练轮数的增加而自动调整即每20轮学习率减小10倍,结合优化器可以加速网络的收敛。
3.4 评价指标
为了量化评估道路提取的效果,本文利用语义分割领域中最常见的精度评价指标:召回率(Recall)、综合评价指标(F1 Score)和交并比(IoU)。本文将道路提取视作二分类问题,预测结果分为两类:道路和非道路。对于二分类问题,可将样本数据根据其真实类别与预测类别的组合划分为真正例TP(True Positive)、假正例FP(False Positive)、真反例TN(True Negative)和假反 例FN(False Negative)这4种 情 形。精 度(Precision)是正例预测正确的像素占预测为正例像素的比例;召回率(Recall)是正例预测正确的像素占真实正例像素的比例;F1 Score是基于精度与召回率的调和平均;IoU是不同类别中真实值和预测值的交集与并集的比值。评价指标公式如下:

4 结果与分析
4.1 实验结果
本文利用Massachusetts roads数据集中的测试集和验证集数据(共63幅)进行测试,测试结果的精度见表1。由表1可知,实验结果中整体精度IoU、Recall和F1 score分别为62.18%、71.02%和76.35%,其中,精度最高的和最低的测试结果,如图4所示,测试集编号为20728960_15的提取结果精度最高,而编号为23729020_15的精度最低。编号23729020_15影像的预测图取得的精度最低,但与真实道路标签图进行对比,大致提取出道路的整体轮廓,并且没有出现道路错误提取的情况。而在编号20728960_15影像的实验结果中,道路结构提取更加完整且与真实道路标签图近乎吻合。综上所述,证明了本文方法的良好性能。

图4 实验结果展示Fig.4 Demonstration of experimental results
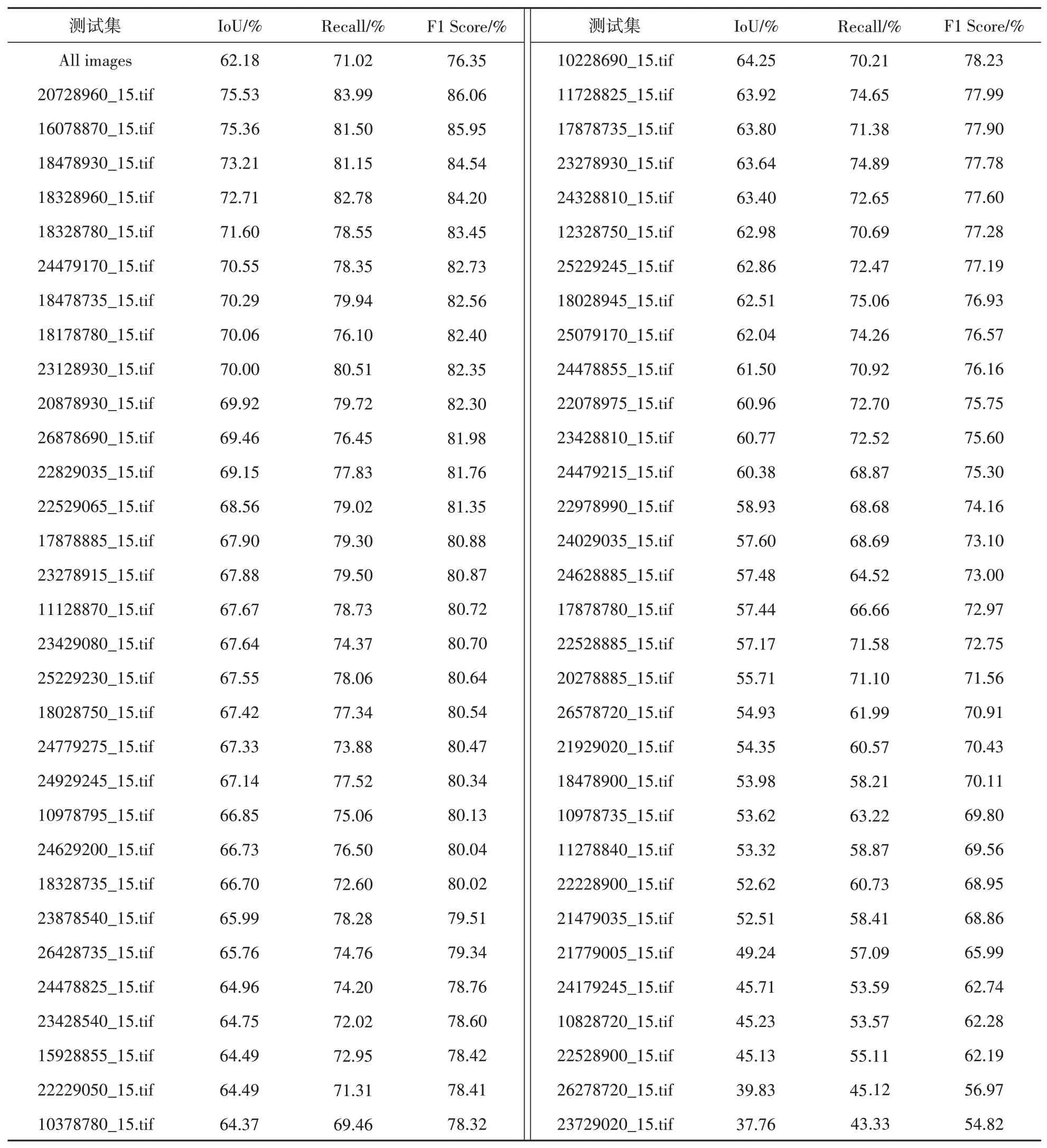
表1 本文方法对于Massachusetts roads数据集的测试结果Table 1 Test results of the Massachusetts roads data set are presented in this paper
4.2 方法对比与分析
本文提出一种改进的语义分割模型,实现了高分辨率遥感影像道路自动提取。在相同的环境下,与U-net、Segnet、DeeplabV3+(Chen等,2018)和D-LinkNet这4种具有代表性的深度学习网络模型进行对比。其中U-net网络模型主要应用于医学图像分割,它可以用深层特征定位和浅层特征精确分割,所以对道路细长特征的提取具有较好的性能;Segnet是基于VGG-16改进的FCN(The Fully Convolutional Network)网络模型,是更加先进的分割网络模型;DeeplabV3+是学者近期提出的新型全卷积网络模型,该模型进一步提升了在语义分割任务上的性能;而D-LinkNet获得了CVPR 2018中的全球卫星图像道路提取比赛(CVPR 2018:DeepGlobe Road Extraction Challenge)的冠军。
4.2.1 Massachusetts roads数据集的结果和分析
图5为5组实验结果的对比,黄色框展示本文方法整体提取能力,红色框展示本文方法细节提取能力。本文方法的提取结果非常完整,极大地保证道路的连通性,没有出现误提现象。本文针对道路目标的特征,对网络模型进行相应的优化,使得模型能够有效地提高道路提取的精度,其中引入坐标卷积和全局信息增强模块,不仅能减轻空间分辨率丢失、保留局部细节信息,而且能够通过抽取上下文信息来保证道路的连续性。本文方法实验结果的完整性和连通性明显优于其他4种方法,U-net、D-LinkNet和DeeplabV3+的结果都存在破碎情况,如图5中黄色框所示。Segnet提取结果中破碎情况更加严重,尤其是图5中第一幅遥感影像的道路信息基本没有得到提取;由于Segnet的网络结构非常简单并且仅下采样16倍,对道路特征感知不足以及道路在遥感影像上表现为细长的条带状,导致Segnet很难提取到道路特征信息;而相较于Segnet网络,U-net和D-LinkNet在提取道路特征信息上有很大的提升,已经能够提取出较完整的道路轮廓,但是局部道路提取结果连续性差,误提的现象严重。经过分析得出,U-net网络的跳跃连接联系低级和高级特征,对道路特征感受较好,但是与Segnet存在的问题相似,卷积操作不多导致道路特征提取不充分;D-LinkNet中的空洞卷积带来的“棋盘效应”,会导致上下文信息的丢失,所以提取结果中漏提现象严重。

图5 5组影像在不同方法下的道路提取结果Fig.5 Road extraction results for different methods of five sets of images

为了进一步量化模型的效果,5种模型提取道路的平均精度列于表2。由表2知,本文方法提取结果的整体精度高于其他模型,Recall、F1 Score和IoU分别达到71.02%、76.35%和62.18%;在F1 Score和IoU指标上比U-net和D-LinkNet提高了约1%,同时远远超过DeeplabV3+和Segnet,仅在Recall指标上低于D-LinkNet。结果分析表明,本文方法在道路提取任务上比其他网络模型有明显的优势。

表2 不同方法的道路提取结果的精度评价Table 2 Quantitative comparison of road extraction results in different methods
4.2.2 高分2号的结果和分析
图6展示了4种方法在高分数据集上的测试结果。从整体来看,本文方法提取的结果非常完整且与真实道路十分吻合,相比较其他的3种模型有显著的优势。从图6的黄色标记框中可以看出,由于缺乏坐标卷积和全局信息增强模块的作用,无法顾及空间特征和全局上下文信息,DeeplabV3+和D-Linknet两种方法均出现了破裂问题,在图6第3行D-Linknet方法的提取结果甚至出现了细小道路漏提的现象。其中,U-net模型的提取结果中道路的破碎化严重、漏提较多。表3是4种模型在高分2号数据集上测试的精度统计表。由表3可知,本文方法的提取精度在Recall、F1 Score和IoU这3种评价指标上分别达到了91.19%、91.49%和84.35%;所提方法相较于对比方法中表现最好的的DeeplabV3+方法,在Recall、F1 Score和IoU分别提高了7.48%、3.11%和5.11%。
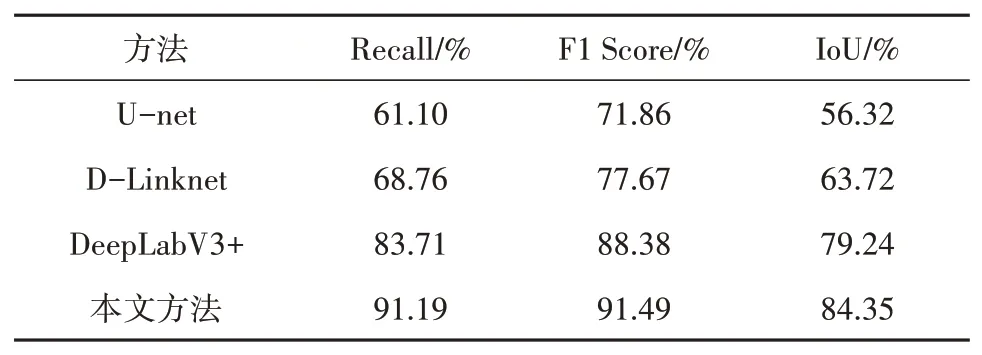
表3 不同方法的高分道路数据提取结果的精度评价Table 3 Accuracy evaluation of Gaofen road dataextraction results by different methods

图6 U-net、D-Linknet、Deeplabv3+和本文方法对6组高分数据集测试图像的预测结果Fig.6 U-net,D-Linknet,Deeplabv3+and the method of this paper on the prediction results of six Gaofen dataset test images

4.2.3 算法运行效率比较分析
为了定量评估算法效率,本文使用了浮点数计算量(Flops)、参数量(Params)、空间占用以及运行时间等指标。浮点数计算量衡量的是模型的运算次数,参数量代表模型的总参数量,空间占用代表生成模型文件占用物理存储空间大小,运行时间是Massachusetts roads数据集中63幅图像的测试时间。实验结果如表4所示,所提方法在各运行效率方面没有取得最佳成绩,但是本文旨在解决空间特征损失和上下文信息丢失的问题,提高道路分割的效果和缓解阴影遮挡影响。因此,论文方法在分割精度方面取得了最好的效果,并且在树木或建筑物遮挡道路的情况下表现最佳。

表4 算法效率分析Table 4 Analysis of algorithm efficiency
4.3 遮挡适应性比较分析
本文方法在道路提取结果的完整性和评价指标上表现优异,但是仍然受到树木、建筑物阴影遮挡干扰,这也是道路提取任务中的难点。D-LinkNet、DeeplabV3+、U-net以及本文方法关于受这两个因素影响的道路提取结果如图7和图8所示。从整体来看,本文方法的提取结果准确完整。U-net、DeeplabV3+和D-LinkNet网络结构易受树木、建筑物阴影遮挡干扰,无法完整地提取出道路信息。而本文方法使用了全局信息增强模块,其具有提高全局上下文感知的能力,抽取空间语义信息,提高道路分类的一致性,能够在一定程度上减小了树木、阴影等对道路提取的影响,可以有效地提取被遮挡的道路,如图7黄色框和图8红色框所示。另外,通过图8第2行和第3行可以看出,本文方法对多尺度道路提取具备优势。因为论文方法引入坐标卷积,它具有强大的边界信息感知能力,可以准确地感受到不同环境的道路边缘特征,进而提取出复杂情况下的道路。表5和表6统计了4种模型在图7、图8上测试结果的平均精度。由表5可知,本文方法在树木遮挡影响下的提取精度在Recall、F1 Score和IoU这3种评价指标上分别达到了73.64%、77.96%和64.22%,相较于对比方法中表现最好的的U-net方法,在Recall、F1 Score和IoU分别提高了16.85%、13.41%和15.34%,更是远超其他两种方法。此外,本文方法在建筑物阴影遮挡影响下,Recall为78.66%,F1 Score为85.21%,IoU为74.58%,远远超过对比方法,如表6所示。综上所述,在提取道路过程中,对比方法均受到树木、建筑物阴影遮挡影响,而本文方法受到干扰最小,提取效果比其他方法更优异,说明论文方法具备良好的遮挡适应性能。

表5 树木遮挡适应性定量分析Table 5 Quantitative analysis of tree occlusion adaptability

表6 建筑物阴影遮挡适应性定量分析Table 6 Quantitative analysis of adaptability of building shadow occlusion

图7 树木遮挡适应性比较Fig.7 Comparison of tree occlusion adaptability

图8 建筑物阴影遮挡适应性比较Fig.8 Adaptability of building shadow occlusion

4.4 模块机制的有效性分析
为了突出坐标卷积和全局信息增强模块对模型性能的重要性,本文在相同的训练条件下,进行了只加坐标卷积(Coordconv-net)、只加全局信息增强模块(GIE-net)、不加任何机制(Baseline)和所提方法的4种网络模型的对比实验。表7统计了实验的结果,Coordconv-net和GIE-net的整体精度均比Baseline高,说明坐标卷积和全局信息增强模块对提升模型性能有一定的帮助。本文方法尝试将两种机制相结合,结果表明精度均高于Coordconv-net和GIE-net。因此两者结合,可以更好地提高模型性能与道路提取精度。论文方法的提取精度优于其他3种方法,是因为所提模型中坐标卷积和全局信息增强模块对道路提取的有效性:一方面能高效的减少了道路空间特征的丢失,增强空间信息变化的感知;另一方面兼顾了道路的全局空间语义信息,缓解上下文信息丢失,保留了道路的连通性,在整体上提高了道路提取的精度。
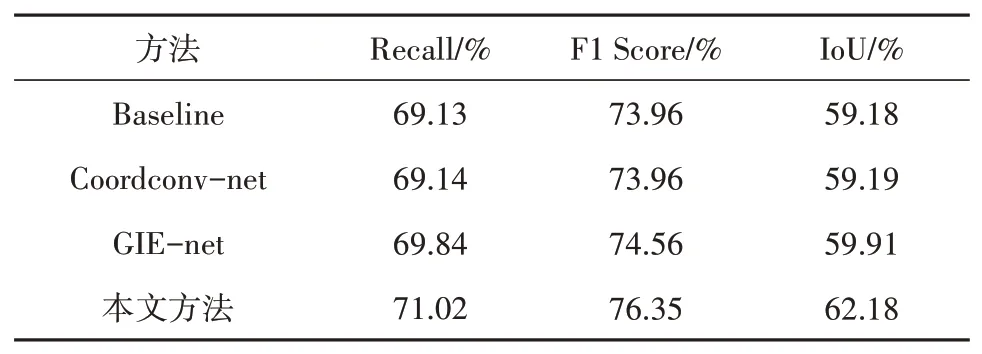
表7 4种道路提取方法的评价指标对比Table 7 Comparison of evaluation indicators of four road extraction methods
4.5 问题分析
本文方法在对比实验中取得突出效果,但是在提取过程中仍存在少量的道路漏提情况,这也是目前深度卷积神经网络模型在道路提取上的难点。如图5红色框所示,道路网周围存在的城市建筑、树木等众多地物,造成了复杂的背景,因此在道路信息提取过程中会对网络模型感知目标特征产生干扰;同时由于道路网本身的多尺度特征,要求网络模型具有高效的多尺度特征感受能力。在复杂背景和多尺度道路共存的情况下,本文方法相比其他方法提升了道路提取的精度,并在一定程度上提高道路网提取的完整性,但是也存在着局部道路不连续现象。
5 结论
本文针对深度卷积神经网络道路提取方法中存在空间特征损失和上下文信息丢失的问题,利用ResNet的残差单元和U-net的结构,引入坐标卷积和全局信息增强模块,提出了高分辨率遥感影像道路自动化提取方法,主要结论如下:
(1)在Massachusetts Roads数据集和高分数据集上的实验结果表明,本文方法在Recall、F1 Score和IoU提取指标上都表现优异,整体精度高于其他模型,分别达到71.02%、76.35%和62.18%。道路提取结果取得了更高的精度和更好的完整性,而且没有出现错误提取道路的情况,这表明所提方法可以有效地从遥感影像中提取道路;
(2)本文方法相较于基于道路特征的提取方法,不需要人工干预和参数调节,经过训练的模型,其在不同的遥感影像提取任务中具有一定的泛化性,因此应用前景更加广阔;
(3)本文利用坐标卷积引入空间坐标信息和全局信息增强模块抽取全局上下文特征来提取道路,缓解了树木、建筑物阴影等其他地物遮挡的影响,并且对多尺度道路提取具备优势。由于保留了丰富的细节特征,因此道路的提取结果更加准确完整。
本文方法在对比实验中表现优异,但是仍然存在由于地物遮挡而漏提道路的现象。本研究未来的工作计划为:针对影像中复杂的道路特征如遮挡问题,优化网络结构的同时考虑道路的空间几何特征,加强模型抽取细节特征和多级特征的能力进一步提升性能。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
金桥(2018年4期)2018-09-26
华人时刊(2016年16期)2016-04-05
