
基于推荐算法的物资计划智能申报
2022-10-14 03:04詹佳悦陈国洪叶心舒
海峡科学 2022年8期
詹佳悦 陈国洪 叶心舒
(国网福建省电力有限公司物资分公司,福建 福州 350003)
1 研究背景
近年来,云计算、移动互联网、人工智能等技术快速发展,大数据时代正在改变电力企业的运营管理决策方式。项目物资申报作为电力行业的基础业务,是数字产业链的重要环节。物资申报难度大且复杂,涉及到ERP、ECP、国网商城等多个系统;需要十余道审批,操作流程时间长且复杂;涉及项目投资、目录、价格、时间、技术规范、工厂、采购组、采购方式、交货地点等数据属性,影响项目管理、供应链多个环节。以项目为例,物资需求量大,传统的需求计划方式更多依靠经验、人力,有限的效率对项目中的物资采购、库存等多个环节形成制约。随着物料信息与项目需求数据的互联互通,如何充分应用大数据与人工智能技术,运用推荐算法技术[1],开展项目需求精准预测、科学安排物资变得尤为重要。推荐算法技术已经在购物、书籍、音像、文章、网页、新闻等行业得到了广泛应用,抖音、淘宝、今日头条等应用都引入了推荐算法系统。
2 推荐算法
2.1 基于内容的推荐方法
基于内容的推荐算法[2]是基于资源描述和用户兴趣信息的匹配度对各个用户进行个性推荐,算法的设计思想简单,符合人们的思维习惯,也便于人们理解。
2.2 基于协同过滤的推荐算法
基于协同过滤的推荐算法[3]主要考虑项目与项目之间、用户与用户之间的关系,并基于此关联关系进行分析推荐。由于协同过滤推荐方法仅依赖评分对用户进行推荐算法,不需要深入的专业知识,甚至不需要知道推荐资源的内容,所以该方法适用于不同结构类型的资源。但也正是因为依赖评分,该算法存在数据稀疏和冷启动问题。
2.3 基于关联规则的推荐算法
关联规则[4]挖掘主要分为两个步骤,先从原始资料集合中找出频繁项集,再依据频繁项集找出关联规则。在两步完成的前提下,向用户提供推荐算法供客户参考和选择,基于关联规则推荐是对数据自身进行分析,不需要专业知识就能很好地进行推荐。但是随着数据规则的増加,算法的复杂度会大大增加。
3 基于聚类和关联规则的物资推荐算法
本文结合聚类方法、关联规则、短文本相似度形成组合推荐算法[5],通过聚类方法,对数据进行降维,能够解决由于数据量大导致关联规则算法复杂化和计算成本问题,同时考虑到输入数据的不完整性,采用基于关联规则文本相似度方法进行物资推荐算法。
3.1 数据获取及清洗
基于数据中台建设成果,溯源整合项目模块、物资模块相关表数据,开展数据分析及模型构建工作。数据来源主要是ERP系统,部分涉及ECP、规划计划系统、储备库系统回传数据等。采集2018—2021年全省25909个配网项目和8739个零购项目数据及101万条物料出入库数据,作为模型的基础数据。在数据预处理阶段,对基础数据进行缺失值、异常值清洗,剔除了投资金额为零等业务异常数据,最终配网、零购项目数分别为24317个、8725个。
3.2 项目初步聚类分析
K-Means方法是最常用的聚类算法,但计算时间过长、成本大。Mini Batch K-Means聚类模型在尽量保持聚类准确性前提下大幅降低计算时间。针对电力物资数据量较大的情况,本文选用Mini Batch K-Means聚类算法来提高聚类效果。Mini Batch K-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次训练使用的数据集是在训练算法的时候随机抽取的数据子集),减少计算时间,同时试图优化目标函数。利用Mini Batch K-Means聚类算法,对项目的物料使用数量进行聚类,得到物料使用情况较为相似的24个项目群,对前20个项目群进行项目分析,剔除异常项目群,提高分析的准确性。
3.3 项目群关键字提取
聚类之后,获得了不同物料使用情况的项目群。针对同一个项目群,对所有项目的项目名称进行关键词分析,获取最有业务代表性的项目类型属性。
选取项目数目较大的项目群,对分词结果进行关键词提取。采用TF-IDF(词频—逆向文件频率),词频最高的词语将作为该簇的关键字。在一份给定的文件里,词频 (term frequency,TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母,区别于IDF),以防止它偏向长的文件。逆向文件频率 (inverse document frequency,IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。如配网项目基于关键字的类别,可分成3类关键字,一是柱上开关、环网柜、电缆管沟、分界开关、真空开关、箱式变、架空线、防雷装置、漏保等37个;二是延伸、联络、绝缘化、应急、业扩配套、跨年、抢修等27个;三是线路改造、支线改造、配变新建、配变改造、送出配套、杆改造、改造、新建等28个。零购项目可分成2类关键字,一是便捷式、智能化、钳形、激光、彩色、多功能等201个;二是打印机、笔记本、一体机、避雷器测试仪、消谐器测试仪、抽水车等859个。每一个项目可能拥有多个关键字属性作为其项目标签。
3.4 项目关联规则
通过经典的 Apriori 算法,对上述聚类后的项目集群、物料小类进行挖掘,得到频繁项集,并结合最小支持度和最小置信度获取有价值的关联规则。通过设定最小支持度,以迭代的方式挖掘频繁项集。
构建关联规则的输入,要对项目的基本属性、关键字属性进行不同的数据预处理,将离散型变量,如地市转为福州、龙岩等规范地市名称;将电压等级转为110kV、10kV等大小写一致;对关键字进行一些近似词的整理;将连续性变量,如项目周期、投资金额根据数据分布情况进行离散化,分为五等分。
将项目的基本属性(地市、变电站电压等级、线路电压等级、项目周期、投资金额)和基于聚类后得到的关键字属性进行合并,获得关联规则前项。关联规则后项则为物料小类编码。设置最小支持度为0.5,最小置信度为0.5,获得关联规则组合。合并5个项目基本属性及三类关键字项目属性后,配网项目、零购项目分别获得7484个、3648个关联规则。例如,[南平,35kV,10kV,开关,改造,103,203] 项目信息是关联规则前项,交流三相隔离开关、线路柱式瓷绝缘子等物料小类是关联规则后项,即[南平,35kV,10kV,开关,改造,103,203] 项目最有可能使用的物料小类为交流三相隔离开关、线路柱式瓷绝缘子等14个物料小类。
关联规则对应的物料数据,采用基于统计的方法,获取每个关联规则下的物料编码和物料数量。根据关联规则前项、关联规则后项进行项目数量的聚合汇总,获取每个关联规则下,每个物料小类中出现在最多项目中的物料编码,获得物料编码所在项目数量的比例及该物料编码的平均数量,见表1。
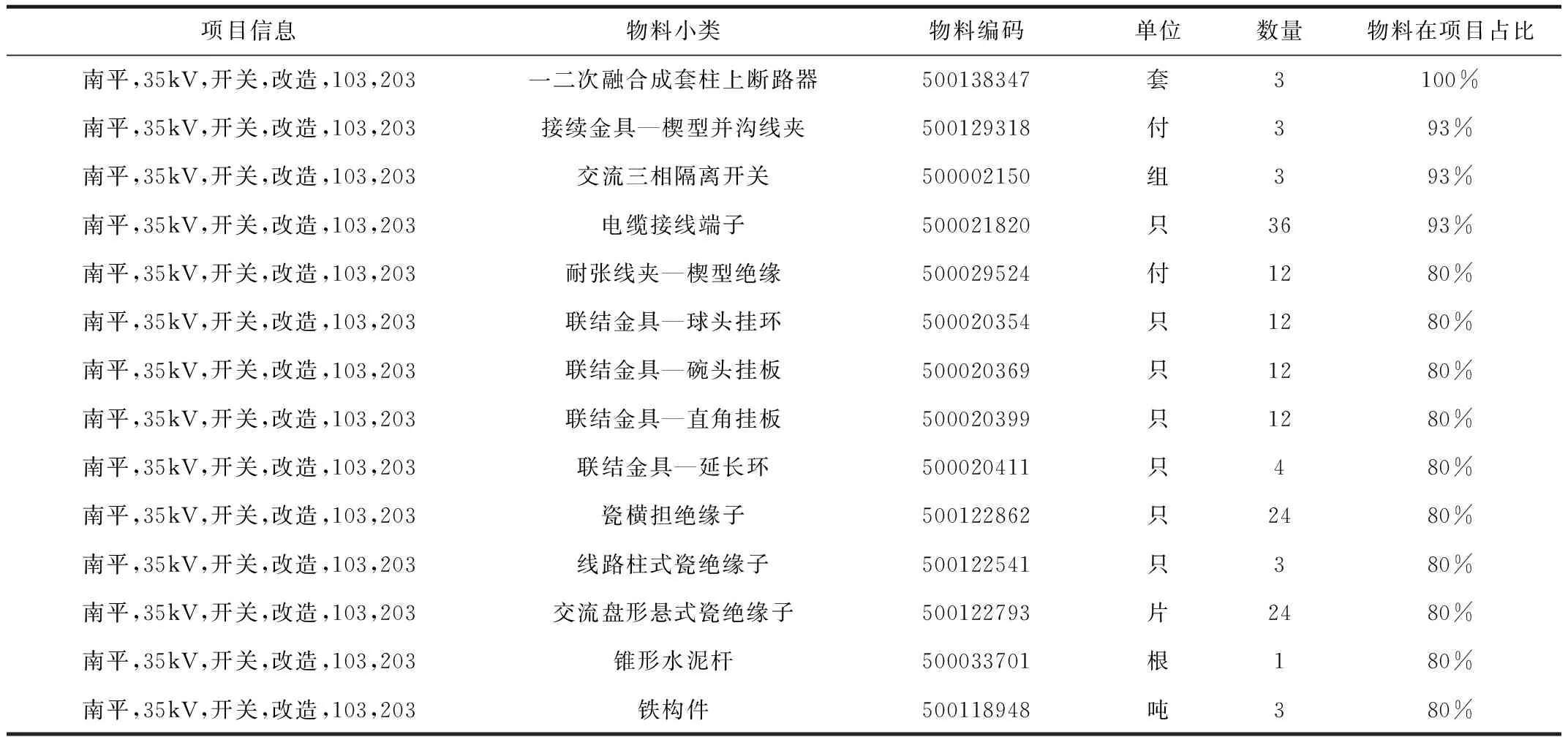
表1 某项目类基于关联规则的推荐清单
4 推荐算法的验证
随机选取200个配网、235个零购项目进行算法验证。首先,通过数据中台获得项目的一些基本信息,其中,项目名称、项目类型(配网、零购项目)为必填项,而电压等级、投资金额、时间为选填项。其次,对项目名称进行关键字提取,如地市、变电站电压等级、线路电压等级、关键字(福州、110kV、10kV、配套、送出等)、周期、投资金额等。再次,根据相似短文本,在配网项目关联规则库中进行关联。设置原始最小支持度和最小置信度为0.5,其查准率(预测准确的物料数量占预测物料总数比例)100%,但查全率(预测准确的物料数量/实际物料编码数量)低于50%。最后,通过优化参数,调整最小支持度、最小执行度至0.4,发现各项目类型查准率超过90%,查全率超过75%,可见整体推荐情况较准、较全,满足实际应用要求。
5 研究展望
推荐算法成功地推荐了合理的物料、数量等,提升了项目需求单位的便利程度。同时,实际系统中通过提高标准物料、优选物料的推荐系数进一步提升了推进的准确性、针对性。下一步,将推荐算法应用范围从项目拓展到电网基建、营销项目、生产技改等16类项目,从仅物资物料推荐拓展到物资、服务同时推荐,进一步提升项目物资的服务水平。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
华人时刊(2022年1期)2022-04-26
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
动漫界·幼教365(大班)(2019年10期)2019-10-28
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
棋艺(2014年7期)2014-09-09
