
基于CatBoost算法的长江中游冬季降水相态预报方法研究*
2022-10-12 04:39:22王珊珊雷彦森方鸿斌孟英杰章翠红刘文婷李康丽
气象 2022年9期
王珊珊 雷彦森 方鸿斌 孟英杰 章翠红 刘文婷 李康丽
1 武汉中心气象台,武汉 430074 2 湖北省荆门市气象台,荆门 448124
提 要: 利用2000—2014年地面观测资料和欧洲中期天气预报中心(ECMWF)ERA5再分析资料,选取表征四类降水相态(雨、雪、雨夹雪、冻雨)的温度、湿度、微物理特征的43个特征量,使用精细地形高度订正,利用CatBoost算法开展长江中游降水相态预报方法研究。结果显示:此方法对雨、雪、冻雨有较好的分类和预报效果。使用精细地形高度预处理后的特征量,能够提高降水相态判别的准确率和空间精细度。雨、雪、冻雨的预报准确率与ECMWF预报产品相比分别提高了9.9%、39.1%、11.1%,但对雨夹雪的改进不明显。
引 言
长江流域地处中纬度地带,冬季降水相态复杂多变,同样量级的降水,由于雨、雪、雨夹雪、冻雨等不同的降水相态,其对人类的生产和活动的影响也不同,如2008年初发生在中国南方的低温雨雪冰冻灾害,使得城乡交通、电力、通信等遭受重创,百姓生活受到严重影响,经济损失巨大。降水相态预报一直是长江流域冬季降水预报的难点,很多学者进行了大量研究。关于雨雪的判别,国内很多研究针对温度层结和特定气压层的厚度进行了大量统计和分析,徐辉和宗志平(2014)在2012年11月3—4日华北地区降水相态转换过程中温度垂直结构特征分析中指出,当850~1 000 hPa的厚度差<1 300 gpm,且700~850 hPa的厚度差<1 530 gpm时,地面的降水相态类型以雪或雨夹雪为主,反之,则以雨为主。张琳娜等(2013)通过对近10年北京地区雨雪转换过程分析,得到了850 hPa温度、925 hPa 温度、1 000 hPa温度、1 000~700 hPa厚度、1 000~850 hPa厚度和地面温湿条件(2 m温度、2 m相对湿度的结合量)与雨、雨夹雪、雪三种降水相态的关系。漆梁波和张瑛(2012)考虑温度和厚度因子提出了中国东部降水相态的识别判据。陈双和符娇兰(2021)、陈雷等(2012)、郑丽娜等(2016)、杨成芳等(2015a;2015b)、许爱华等(2006)基于个例分析,给出了温度和厚度的识别指标。
另外还有一些学者通过开展客观算法研究实现降水相态预报,Dai(2008)通过30年的地面观测建立了降雪频率与地面气温和气压的关系,Bourgouin(2000)认为降水相态的变化与垂直方向上高于和低于0℃的面积相关,因此利用环境融化参数研发了降水相态识别算法。陈双等(2019)通过对我国临界气温条件下降雪的时空分布特征分析,引入湿球温度,利用决策树方法对临界条件下雪和雨进行了判别分析。
近年来机器学习算法在气象领域广泛应用,朱文刚等(2020)发现利用DNN法对山东雨、雪、雨夹雪的预报较ECMWF预报有明显的提高。董全等(2013)对相同条件下线性回归法和人工神经网络的预报效果进行对比,指出人工神经网络法要优于线性回归,同时也指出南方的雨雪分界线没有北方的预报效果好。杨璐等(2021)分别基于XGBoost、SVM、DNN三种机器学习方法建立了降水相态的高分辨率客观分类模型,通过对比指出XGBoost和DNN都很好地实现降水相态的分类。黄骄文等(2021)应用深度学习网络技术构建雨、雪判识模型,雨雪分界线比ECMWF预报更接近实况。
综上所述,国内外很多判断降水相态的判据,不管是人工判断还是客观算法判断,主要是对温度和厚度的垂直分布的分析,因此降水相态的转换更加依赖对温度的分析,对于数值预报而言,看似很小的温度误差,也会导致错误的预测(Frick and Wernli,2012)。
除温度外,相对湿度由于能影响降水粒子融化蒸发等过程,也会影响到达地面的降水相态(Kain et al,2000;Stewart et al,2015)。也有研究表明造成降水相态不同的关键在于云中的成雪机制以及雪花下落过程中发生的变化(廖晓农等,2013),也就是云微物理机制。
因此,降水相态的预报需综合考虑温度、湿度和云物理等要素。目前在实际的预报业务中发现,长江中下游降水相态精细化预报主要有两个难点:一是地形复杂,降水相态精细化格点预报模型不好建立;二是温度的预报准确率对降水相态预报影响较大。本文采用5 km分辨率的地形对训练数据进行预处理,将降水相态分为四类(雨、雪、雨夹雪、冻雨)进行建模,使用订正后的地面温度逐小时预报产品,选用CatBoost(党存禄等,2020)算法进行预报,提供更加准确和精细的格点降水相态客观预报产品。
1 资料和方法
1.1 资 料
所用资料包括2000—2014年冬季(11月至次年2月)范围为27°~36°N、108°~118°E的地面观测站逐小时的2 m气温(T2 m)、降水相态、高空观测数据以及地面观测站所在高度;ECMWF ERA5再分析资料(以下简称ERA5),包括1 000、975、950、925、900、875、850、825、800、775、750、700、650、600、550、500、400、300、200 hPa温度(T1000、T975、T950、T925、T900、T875、T850、T825、T800、T775、T750、T700、T650、T600、T550、T500、T400、T300、T200)、比湿、云冰和云水混合比,并计算得到700 hPa以下大于0℃的层数(以下简称暖层层数)和小于0℃的层数(以下简称冷层层数)。ERA5的空间分辨率为0.25°×0.25°,时间分辨率为1 h。分析时利用反距离权重插值法将ERA5逐小时数据插值到上述范围内的自动气象站数据,与观测的降水相态进行时间匹配。
1.2 CatBoost算法
降水相态的判断是个复杂的过程,要综合考虑各层的温度、湿度的配置,单一的决策树方法往往难以判断不同温湿状态下的降水相态。因此本文采用集成学习算法,它使用一系列的学习器进行学习,并使用某种规则将各个学习器的学习结果进行整合,从而获得比单个学习器更好的学习效果。集成学习模型主要分为Bagging和Boosting。基于Bagging模型的方差较小,但偏差较大。Boosting可以降低模型偏差,它通过迭代训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关,对基分类器的准确性要求较低。基于Boosting模型的算法主要有AdaBoost,GBDT,XGBoost,LightGBM,CatBoost等算法。CatBoost是基于梯度提升决策树(GBDT)(刘顺祥,2018)的机器学习方法,相对其他Boosting算法的优势是无需调参即可获得较高的模型质量。降水相态预报中需要寻找各个要素的联系,如温度和湿度,该算法使用了组合类别特征,可以利用特征之间的联系,极大丰富特征的维度。CatBoost通过添加先验分布项的方式减少了噪声和低频数据对于数据分布的影响,对于类别数较少的特征,先验项的添加有利于噪音数据的减少。传统的Boosting算法计算的是平均数,而CatBoost在这方面做了优化,采用oblivious 树(党存禄等,2020)作为基学习器,oblivious树中每个叶子节点的索引被编码为长度与树深度相等的二进制矢量,这种计算节点值的方式避免了直接计算过拟合的问题。
1.3 检验方法算法
本文将降水相态划分为四类:雨、雪、雨夹雪、冻雨,对某一类降水相态检验其准确率、漏报率和空报率。以雪为例,当观测为雪、预报也是雪时,判别为正确,记为NA;当观测为雪、预报为其他相态时,判别错误,记为NC;当预报为雪,观测为其他相态时,判别错误,记为NB。任意一类降水相态的检验公式如下:
式中:TS为某一类降水相态的准确率,PO为某一类降水相态的漏报率,FAR为某一类降水相态的空报率。
2 主要气象要素统计特征
选取地面观测中的T2 m和天气现象(将天气现象分为四类降水相态),ERA5的1 000~700 hPa温度、850 hPa以下的云冰混合比和云水混合比,及利用ERA5各层温度统计的冷暖层的层数作为降水相态判别的特征量,提取各个站点海拔高度以上的数值作统计,以确保数据真实性和可用性。
为了检验ERA5要素的可用性,首先将实况探空500、700、850、925 hPa的温度与ERA5相同层次对比,图1a~1d分别为2000—2014年长江中游探空站雨、雪、雨夹雪、冻雨相态对应的500、700、850、925 hPa的实况探空温度和ERA5相同层次温度。可以看出雨、雪、雨夹雪实况观测的数据与ERA5观测的数据分布基本一致,雨的850 hPa和925 hPa温度的第50%分位均高于0℃,雪的各层温度均低于0℃,但是冻雨实况观测的各层温度第50%分位比ERA5低1~2℃。对比发现,除了冻雨观测与ERA5略有偏差外,其他几种相态偏差很小,由于ERA5的垂直层次、水平分辨率以及时间分辨率更精细,因此可以使用ERA5的数据与国家站逐3 h的地面观测数据一一对应,建立降水相态数据集。
2.1 各层气温与降水相态的统计特征
图2a为2000—2014年不同降水相态T2 m的箱线图,粗柱分别代表第25%分位和第75%分位,可以看出,75%以上的降雨样本T2 m>4℃,降雪样本T2 m<0.6℃,冻雨样本T2 m<-0.2℃,雨夹雪样本T2 m<2℃,可见,四类降水相态的T2 m有一定的差异,但是也有交叉,特别是雪和冻雨在25%~75%样本的T2 m分布范围基本一致。图2b为各类相态的925 hPa温度箱线图,75%以上的降雨样本T925>0℃,而75%以上的雨夹雪、雪、冻雨样本的T925在-7~0℃,交叉范围大,无法确定阈值分类,但从分布看,冻雨的低层温度要比雨夹雪更低一些。图2c为775 hPa温度箱线图,75%以上的降雨和冻雨样本T775>0℃,而75%以上的降雪和雨夹雪样本T775<0℃。表1为1 000~700 hPa各类降水相态的第50%分位温度值,可以看出,低层温度很难区分雪和冻雨,但是从875 hPa开始,雪的温度依然维持在-5℃以下,而冻雨的温度快速升高,在775 hPa 达到最高,为1.7℃。雨夹雪不管是低层温度还是中层温度一直处于雪和冻雨之间。从以上的分析可以看出,为某一层温度设定一个阈值来判断降水相态是不合理的,在判断降水相态时,需要综合各层温度的配置,因此可选用各层温度作为机器学习输入的一个特征量。
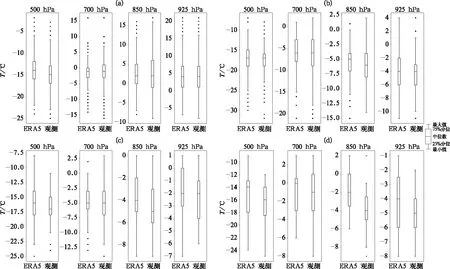
图1 2000—2014年不同降水相态(a)雨,(b)雪,(c)雨夹雪,(d)冻雨高空观测与ERA5数据的500、700、850、925 hPa温度箱线图Fig.1 Boxplots of temperature at 500, 700, 850, 925 hPa between observation and ERA5 data for (a) rain, (b) snow, (c) sleet, (d) freezing rain during 2000-2014
2.2 冷、暖层厚度和强度与相态的统计特征和差异分析
为了描述温度在垂直方向的分布对降水相态的影响,统计700 hPa以下暖层(≥0℃)和冷层(<0℃)的层数,以反映垂直方向上大气的冷暖结构。图3a、3b分别为2000—2014年ERA5资料冬季(11月至次年2月)不同降水相态对应的冷层、暖层层数箱线图,可以看出在雨和雪的判断上,冷层层数和暖层层数上基本无交叉,降雪冷层大于10层,降雨有25%样本冷层大于4层。雨夹雪和冻雨有交叉,冻雨的暖层层数要比雨夹雪多,第50%分位为5层,而雨夹雪为2层,同时暖层最高温度也高于雨夹雪(图3c)。总体上看,暖层层数和冷层层数对降水相态有较好的指示意义,由于机器学习算法寻找的是特征量与结果的数学关系,而气象预报关注的是物理意义,因此该带有物理意义的特征量可以作为机器学习算法的输入量。
2.3 云中冰水混合比与降水相态的统计特征
由于每次过程云冰和云水含量差别比较大,单独分析某层云冰或云水的含量,数值变化范围很大,并不容易总结出阈值。因此分析四种相态各层水或冰所占云中水物质的比值,以925 hPa(图4a)和800 hPa(图4b)为例,可以看到雨和雪仍然是比较容易区分的,但是雪和雨夹雪、冻雨和雨则存在很多交叉。越到低层,雪和雨夹雪的含冰量占比分布范围比较宽,为25%~100%,而雨的含冰量基本为0%,冻雨的含冰量占比主要在0%~25%,而随着高度的增加,雨夹雪的含冰量占比降到50%以下,而冻雨的含冰量占比降到0%。根据逐层分析(图略),可以看出,850 hPa以下的云冰和云水占比对降水相态有一定的指示意义,特别是利用从低到高云冰和云水占比的变化,可以对四类相态做区分。

图2 2000—2014年不同降水相态(a)T2 m,(b)ERA5 T925,(c)ERA5 T775的箱线图Fig.2 Boxplots of (a) T2 m, (b) ERA5 T925, (c) ERA5 T775for different precipitation types during 2000-2014

相态p/hPa7007507758008258508759009259509751 000雪-5.7-5.5-5.7-5.8-5.9-5.7-5.4-4.9-4.2-3.3-2.0-0.5雨夹雪-3.4-2.8-2.9-3.2-3.4-3.6-3.5-3.0-2.3-1.4-0.31.0冻雨0.21.61.7-1.30.4-0.9-2.5-3.6-3.8-3.1-1.8-0.4雨0.12.43.23.63.73.73.63.74.04.75.87.1
3 算法设计
3.1 基于地形高度的特征量预处理
首先需要提取每个站点相对地面以上的特征量,主要原因在于:(1)对于海拔高度高的站点,边界层(如925 hPa)的特征量在地面以下,该层数据对降水相态没有指示意义,不能作为训练数据;(2)由于预报的分辨率是5 km×5 km,地形起伏比较大,长江中下游部分地区海拔高度可达3 km以上,而用于训练的国家站均在3 km高度以下,建立的模型用于更高海拔高度台站的降水相态预报误差会比较大。基于以上两点原因,首先把特征量在垂直方向上进行插值,然后选取每个站点地面以上固定层数的特征量,形成训练数据集。
3.2 训练模型
通过上文降水相态与温度、湿度及微物理特征量的分析,利用不同特征量组合测试,找到最优的输入特征量。选取表征四类降水相态(雨、雪、雨夹雪、冻雨)的温度、湿度、微物理特征的43个特征量,包括地面以上0~3.6 km每300 m间隔高度上的温度、云冰混合比、云水混合比,600~400 hPa的比湿,0~3 km冷层和暖层的层数。其中之所以采用600~400 hPa的比湿是由于在预报个例总结中,高层的比湿反映了水汽伸展的高度,体现了高层冰晶的含量,对降水相态的判断也有一定的辅助作用。利用CatBoost算法,建立降水相态预报模型。
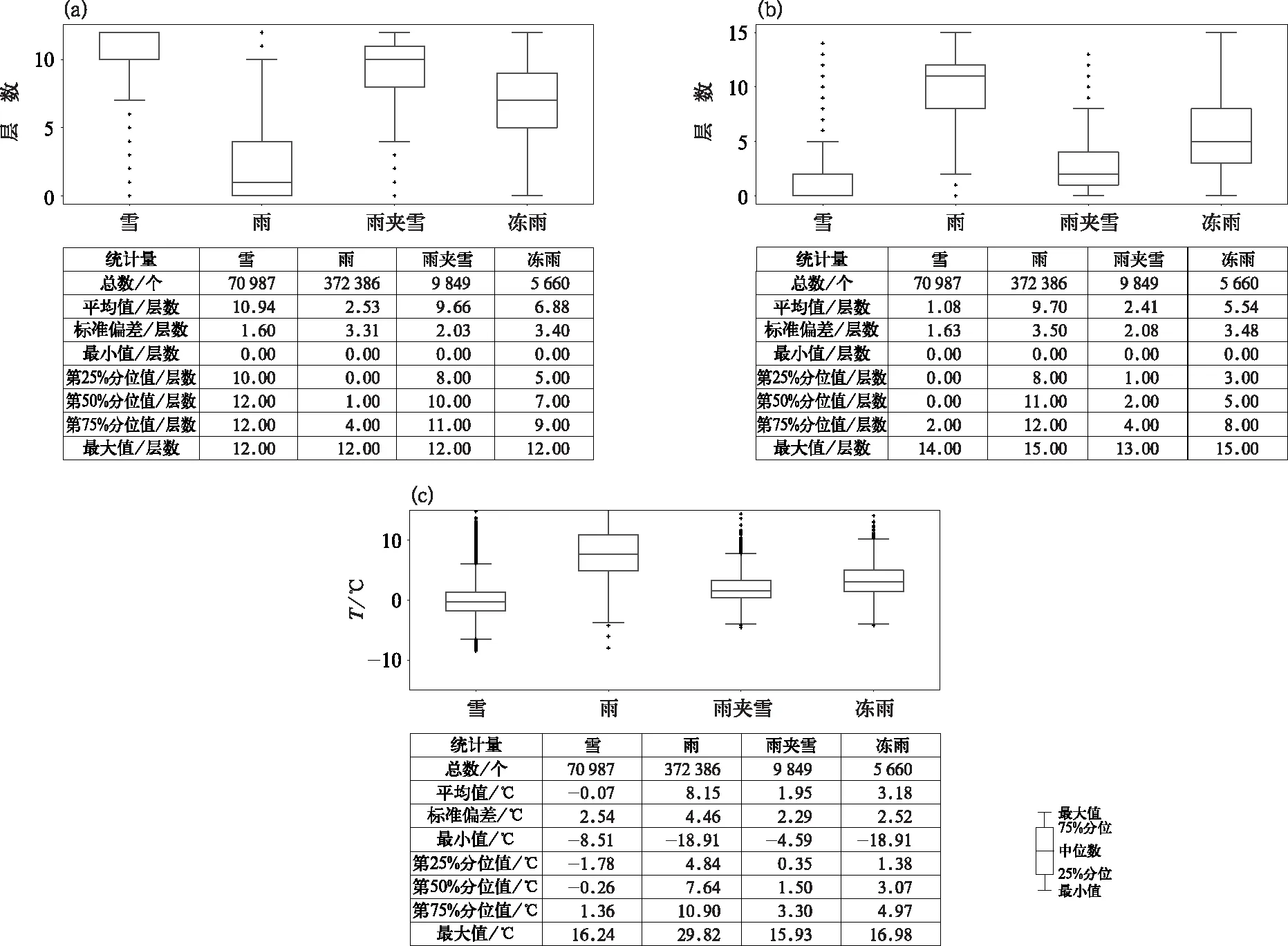
图3 2000—2014年不同降水相态700 hPa以下(a)冷层层数,(b)暖层层数,(c)暖层最高温度箱线图Fig.3 Boxplots of (a) cold layer thickness, (b) warm layer thickness, (c) maximum temperature of warm layer for different precipitation types during 2000-2014

图4 2000—2014年不同降水相态(a)925 hPa,(b)800 hPa云冰混合比箱线图Fig.4 Boxplots of specific cloud ice mixing ratio of (a) 925 hPa and (b) 800 hPa for different precipitation types during 2000-2014
以2000—2014年的数据训练模型,经统计,2000—2014年区域内雨、雪、雨夹雪、冻雨分别有372 386、70 987、9 849、5 660个站次。通过分析也发现,雨、雪、雨夹雪、冻雨样本比例为66∶13∶2∶1,存在明显的数据不平衡现象,因此在训练前首先进行数据不平衡处理。常见的处理不平衡数据多采用SMOTE(synthetic minority oversampling technique)(郝晓红,2019),该算法的缺点是生成的少数类样本容易与周围的多数类样本产生重叠导致难以分类,本文采用SMOTE+ENN(郝晓红,2019)方法,该算法是SMOTE和k近邻算法(刘顺祥,2018)的结合。先用SMOTE方法生成新的少数类样本,获得新的数据集对其中每一个样本使用k近邻预测,若预测结果和实际类别标签不同则剔除该样本,对于属于多数类的一个样本,如果其k个近邻点有超过一半都不属于多数类,则这个样本会被剔除,以达到数据类别均匀的目的。
为了能够得到比较理想的结果,需要不断尝试不同的组合参数值,Python提供了网格搜索法(刘顺祥,2018),可以快速进行各参数组合试错,最终得到最佳参数组合值,本文通过该方法选取最优参数组合为:iterations=1 000, depth=10, learning rate=0.3, loss function=‘multiclass’。
4 应用效果评估
4.1 独立样本检验
为了更加真实地反映模型的性能,不使用随机抽取样本方式检验,而是采用独立样本方式检验,本文使用2015—2019年的样本,并将检验数据范围扩大为25°~36°N、105°~118°E,包括湖南和贵州的大部站点,以获取更多的降水相态数据进行检验。共有降雨样本204 151个站次,降雪样本28 627个站次,雨夹雪样本5 045个站次,冻雨样本2 238个站次。表2为2015—2019年利用上述方法训练出的模型对降水相态判别的结果,可以看出雨、雪的准确率比较高,分别为95.1%和75.8%,冻雨准确率为34.1%,最低的雨夹雪仅为12.3 %。总体来看雨一般以空报为主,雪、雨夹雪、冻雨均是以漏报为主。
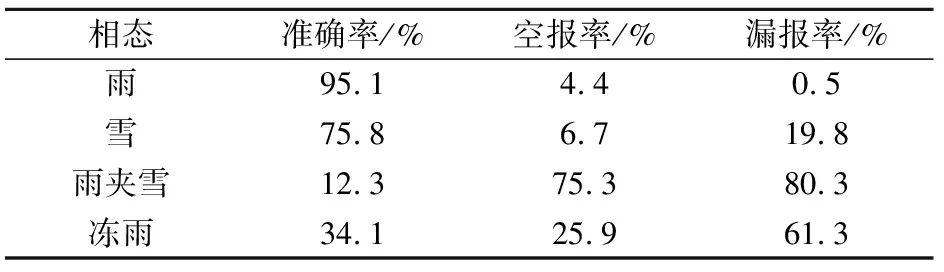
表2 2015—2019年CatBoost算法识别降水相态检验结果Table 2 The verification results of precipitation type identified by CatBoost algorithm during 2015-2019
4.2 个例检验
将以上模型投入实时业务运行,需要使用数值模式要素作为特征量输入模型。由于不同模式预报偏差不同,会影响降水相态的判别,因此在输入模型前,首先对各个模式的要素预报效果进行检验。通过对几种业务运行的数值模式检验,ECMWF细网格模式要素预报要优于其他几个业务模式,因此,使用ECMWF细网格模式要素预报来驱动降水相态预报模型。另外,地面2 m气温使用武汉中心气象台自主研发融合影响因子及模式偏差订正的机器学习格点气温预报产品,该产品在湖北省特别是西部山区的绝对误差低于ECMWF细网格的预报,因此用该产品代替模型中ECMWF细网格模式的地面2 m 气温。
2020年1月6—10日湖北出现一次大范围雨、雪、雨夹雪和冻雨天气过程。表3为2020年1月5日20时至1月9日20时起报的未来12~36 h逐3 h的ECMWF细网格模式与本方法的降水相态预报准确率对比,可见,与ECMWF细网格模式预报的降水相态对比,雨准确率提高了9.9%,雪提高了39.1%,冻雨提高了11.1%,雨夹雪的准确率相当。图5为CatBoost算法和ECMWF 2020年1月8日08时起报18 h和24 h降水相态和实况观测对比图,可见,1月9日02时(18 h)湖北中部一线已经转为纯雪,CatBoost算法对降雪与降雨的分界线预报的比较准确,特别是孝感和襄阳,而ECMWF对襄阳和孝感的降雪出现了漏报,1月9日08时(24 h),孝感至宜昌一线均转为纯雪,ECMWF的纯雪有明显的漏报,而CatBoost算法预报襄阳、孝感、宜昌和荆门的转雪时间基本与实况一致。通过对比,可以看出CatBoost算法对相态的预报能力要明显优于ECMWF的预报。
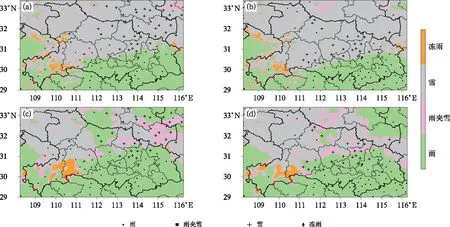
图5 (a,b)CatBoost算法和(c,d)ECMWF在2020年1月8日08时起报(a,c)18 h和(b,d)24 h降水相态预报(填色)与实况观测(符号)Fig.5 The forecast precipitation types with (a, c) 18 h and (b, d) 24 h leadtimes starting from 08:00 BT 8 January 2020 by (a, b) CatBoost algorithm, (c, d) ECMWF and the observation(colored: forecast, symbol: observation)

表3 2020年1月6—10日CatBoost算法与ECMWF细网格模式降水相态准确率Table 3 Precipitation types identified by CatBoost algorithm and ECMWF during 6-10 January 2020
5 结 论
(1)通过对2000—2014年冬季不同降水相态的温度、湿度和微物理特征的统计分析,得到降水相态机器学习算法输入的43个特征量,利用CatBoost算法,建立湖北省降水相态格点预报模型,可以提供时间和空间更精细的降水相态预报。
(2)利用5 km分辨率的地形高度数据,将要素订正到相对地形高度以上等高度的层次上,与使用固定层次的特征量训练的模型相比,对降水相态的判别和预报准确率均有提高,同时能反映湖北省西部高山和平原相态的区别。
(3)由于地面2 m温度受地形影响偏差较大,利用本地2 m温度客观产品代替ECMWF的地面2 m 温度预报产品,能够更好地反映地形的 2 m温度的变化,从而提高降水相态的预报准确率,特别是雨雪分界线也较ECMWF有更好的订正。
(4)利用建立的模型对2020年1月6—10日大范围雨雪过程做订正预报,并与ECMWF的降水相态预报产品对比,对雨、雪、冻雨的准确率有明显的提高,雨夹雪准确率仍比较低。
猜你喜欢
黑龙江气象(2021年2期)2021-11-05 07:07:00
家教世界(2018年16期)2018-06-20 02:22:00
东坡赤壁诗词(2018年1期)2018-03-31 09:10:10
材料科学与工程学报(2016年4期)2017-01-15 13:35:51
成都信息工程大学学报(2016年6期)2016-06-01 12:10:06
高原山地气象研究(2016年3期)2016-02-28 13:53:20
大气科学(2015年5期)2015-12-04 03:04:44
中国塑料(2015年4期)2015-10-14 01:09:21
Acta Mathematica Scientia(English Series)(2015年6期)2015-02-10 08:37:17
石油化工应用(2014年11期)2014-03-11 17:40:44
