
基于随机权重分配策略的面目表情识别
2022-10-12 09:43:22张洋铭王艺凡
重庆大学学报 2022年9期
张洋铭,吴 凯,王艺凡,利 节
(1.复杂系统仿真总体重点实验室,北京 100020;2.重庆科技学院 智能技术与工程学院,重庆 400000)
面部表情是人际交往过程中表达情感和含意的重要手段之一[1]。近年来,面部表情识别在虚拟现实、智能教育系统、医疗卫生和数据驱动动画等领域都取得了较大进展[2-4]。面部表情识别主要是根据给定的人脸图像来识别人脸的情绪和情感态度(如中性、愤怒、厌恶、恐惧、开心、伤心和惊叹)[5]。一方面因在训练过程中表情标注主观性强,歧义较大,训练数据集标注难度大,导致可训练样少,甚至公开数据集均是缺乏多样性的小数据样本,导致训练困难和识别准确度不高。目前众多数据增强的预处理方法(比如随机裁剪,随机翻转等)可以解决数据样本缺失导致准确度不能提高的问题[6],但采用具体模型适用于面部表情数据集的,才可以最大程度上提高识别的准确率。
笔者主要研究通过随机数据增强策略并结合基于特征的方法以提高人脸面部表情识别准确度,通过VGG19网络提取面部表情特征并进行准确识别。其中数据增强是采用5种数据增强方式(图像旋转、图像平移、图像缩放、图像翻转、图像投射)随机权重结合,通过实验结果得出了哪种数据增强的分配策略更适用于面部表情识别,即在保证可训练的数据集具有多样性的同时,得到更加准确的识别模型并掌握其权重的分布情况。
1 用于面目表情特征提取的网络VGG19
VGG在2014年由牛津大学著名研究组VGG(visua geometry group)提出,斩获该年Imagenet竞赛中定位任务(localization task)的第一名和分类任务(classification task)的第二名[7-8]。VGG19的结构如下图1它是由16个stride为1,padding为1的3×3卷积核与5个size为2,stride为2的maxpool层加上3个全连接层最后添加一个soft-max层组成的。VGG 19连续使用多个3×3卷积堆叠以便于优化并取代大体积的卷积核。多层非线性层在增加网络深度时,可以保证更复杂的模型学习而且代价更小(以至于达到参数更少的目标)。简单地来说,在VGG中,用3个3×3卷积核代替7×7的卷核,用2个3×3卷积核代替5×5的卷积核。其主要目的在于是在同一感受野的条件下,提高卷积网络的深度,在一定程度上提高神经网络提取特征的效果[9]。

图1 VGG19结构图Fig. 1 The structure diagram of VGG19
2 随机权重分布的数据增强
将输入图像并行通过穷举法策略,进行随机分配权重的5种数据增强方式,再将其送入到面目表情检测识别网络中通过采用数据增强策略以达到可提高面目表情识别准确率的目的。整体结构框图如图2所示。将原始数据X通过随机分配权重W1~W5得到分配后的图像数据X1~X5,将其并行通过5种数据增强的图像变换并结合原始数据组成新的数据集Y。将新的数据集Y送入到图像特征提取VGG19网络模型中,进行后续的面目表情识别处理。
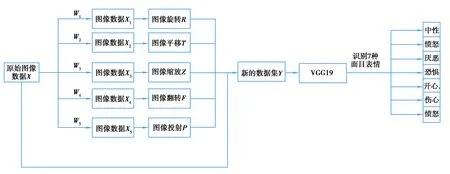
图2 随机权重分布的数据增强结构图Fig. 2 Data enhancement structure diagram of random weight distribution
2.1 图像旋转(R)
图像旋转是指将图像以其中某一个点为旋转中心旋转一定角度,对图像对齐起着极其重要作用。以矩阵变换来表示设点P0(x0,y0)逆时针旋转θ角后对应点为那么,旋转前后点P(x0,y0)的坐标分别为P(x,y)
(1)
(2)
2.2 图像平移(T)
图像的平移操作就是将图像所有的像素点坐标分别加上水平与垂直操作上的偏移量。对于平移变换假设水平偏移量为dx,垂直偏移量为dy,则平移变换的坐标映射为
(3)
其逆变换为
(4)
x1与y1的矩阵变换可表示为式(5)
(5)
2.3 图像缩放(Z)
图像缩放是指对图像的大小进行调整的过程,是一种非平凡的过程,需要高效率,平滑和清晰,缩小图像称为下采样,放大图像称为上采样。
(6)
2.4 图像翻转(F)
图像的翻转变换是从A(x,y)(二维坐标)到B(u,v)(二维坐标)的一种线性变换,其数学表达式为

(7)
式(7)分别为水平翻转,垂直翻转,对角线翻转。且通过图像的翻转变换,可以使图像达到180°的翻转效果这样就可以加大其样本的多样性。
2.5 图像投射(P)
将一张图像投影到一个新的平面为图像的透射变换,其使用的变换公式为
(8)

将5种数据增强方法进行基于随机权重分配策略结合其结果Y可表示为
Y=W1XR+W2XT+W3XZ+W4XF+W5XP,
(9)
式中W1~W5分别表示5种数据增强方式的随机权重分布。W1~W5X分别表示进行并行处理图像数据。RX1为进行随机旋转的图像样本;TX2为随机图像平移的图像样本;ZX3为随机图像缩放的样本;FX4为随机图像仿射变换的图像样本;PX5代表随机透射变换的图像样本。
3 实验结果分析
3.1 实验数据集
Fer2013人脸面部表情数据集是人脸面目表情研究中最常用的数据集之一并且在研究当中占据了很高的地位,Fer2013数据集已经为使用者划分好了训练集,验证集和测试集。Fer2013数据集包含35 887张人脸图片,其中训练集28 709张,验证集3 589张,测试集3 589张。并该数据集中的图像均是灰度图像并且大小为48x48.样本被划分为0=anger(生气)、1=disgust(厌恶)、2=fear(恐惧)、3=happy(开心)、4=sad(伤心)、5=surprised(惊讶)、6=normal(中性)7类。
在Cohn-Kanade基础上扩充数据集产生了CK+数据集,并在2010年发布。该数据集有20%的图像数据当作测试集并用于测试模型,80%的图像数据用于训练模型。图3,4分别展示了Fer2013和CK+人脸表情数据集对应的7种表情。

图3 Fer2013数据集的7种表情图像Fig. 3 Seven facial expressions of Fer2013 dataset

图4 CK+数据集的7种表情图像Fig. 4 Seven facial expressions of ck+ dataset
3.2 训练数据并验证识别精准度
训练与测试数据集按8∶2划分此整体数据集,并将训练集图像基于遗传算法的随机分配策进行权重的划分,并每次均采用相同的训练方式和识别网络架构进行实验。为验证其结果的通用性,实验中将使用的模型为VGG19,Resnet,Googlenet,为了提高模型的整体识别能力,通过微调将模型调整到最佳结构。训练的初始权重参数设置为Epoch=30时,batchsize=128,学习率为0.001,优化算法采用随机梯度下降(SGD),并在每训练1个Epoch后便用此权重测试一次测试集,并记录每次实验的精准度。
通过随机算法生成不同的数据预处理子策略权重配比,比较实验结果准确度得出哪种比例数据预处理子策略配比方式更适用于面目表情识别网络并可以提升识别准确度。通过大量的等同条件重复实验,选取识别准确率最高的6种子策略权重配比方式,结果如表1所示。通过对比实验可看出图像旋转和图像平移2种数据增强子策略的权重比例增加,可一定程度上提高其模型的面目表情识别的准确率。
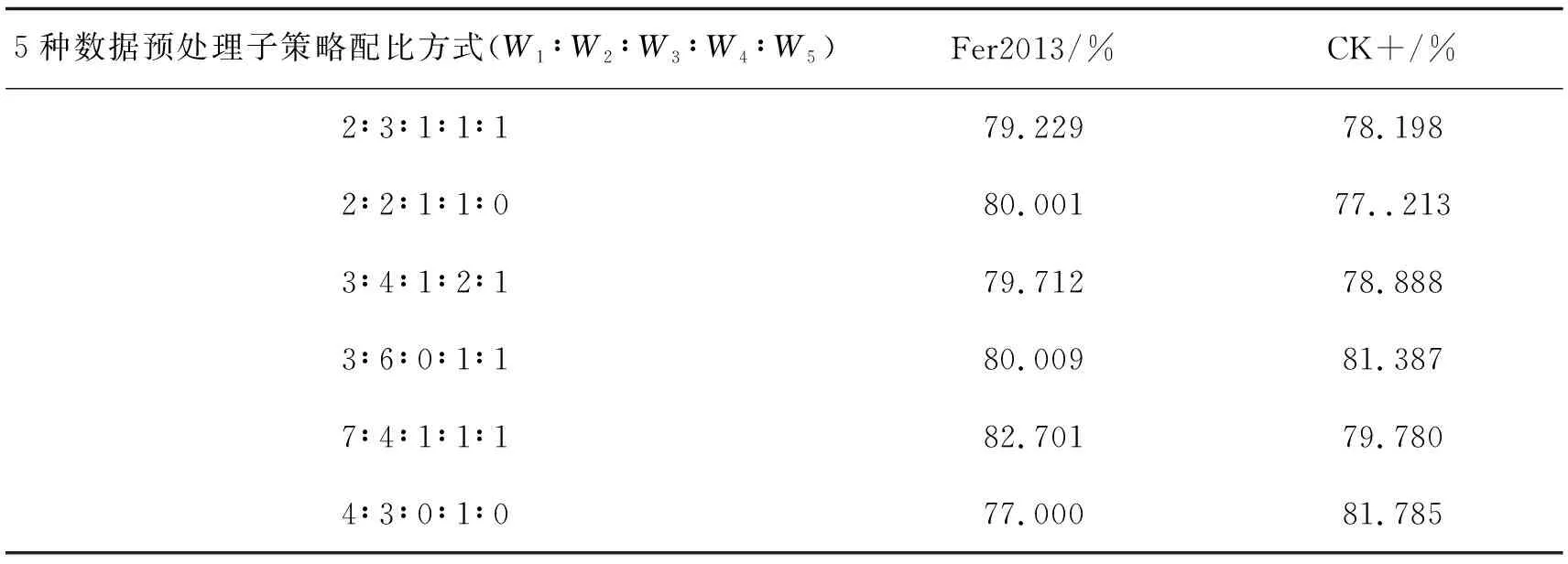
表1 在Fer2013和CK+ 数据集上数据预处理子策略配比最优权重
为了验证实验的正确性,手动将数据预处理子策略配比方式调成1∶ 1∶ 1∶ 1∶ 1的形式,通过将数据预处理子策略的任意一种子策略手动调成2,实验结果如表2所示。

表2 在Fer2013和CK+ 数据集上不同权重分配策略,准确度测试比较
继续采用相同的数据预处理子策略权重配比方式,运用不同的网络结构在Fer2013训练集上训练表情识别模型,其性能在测试集上的结果比较如表3,验证了其随机权重分配策略的通用性。但是,表情识别领域可能存在更好的权重分配策略,在今后的工作中将进一步深入探究。
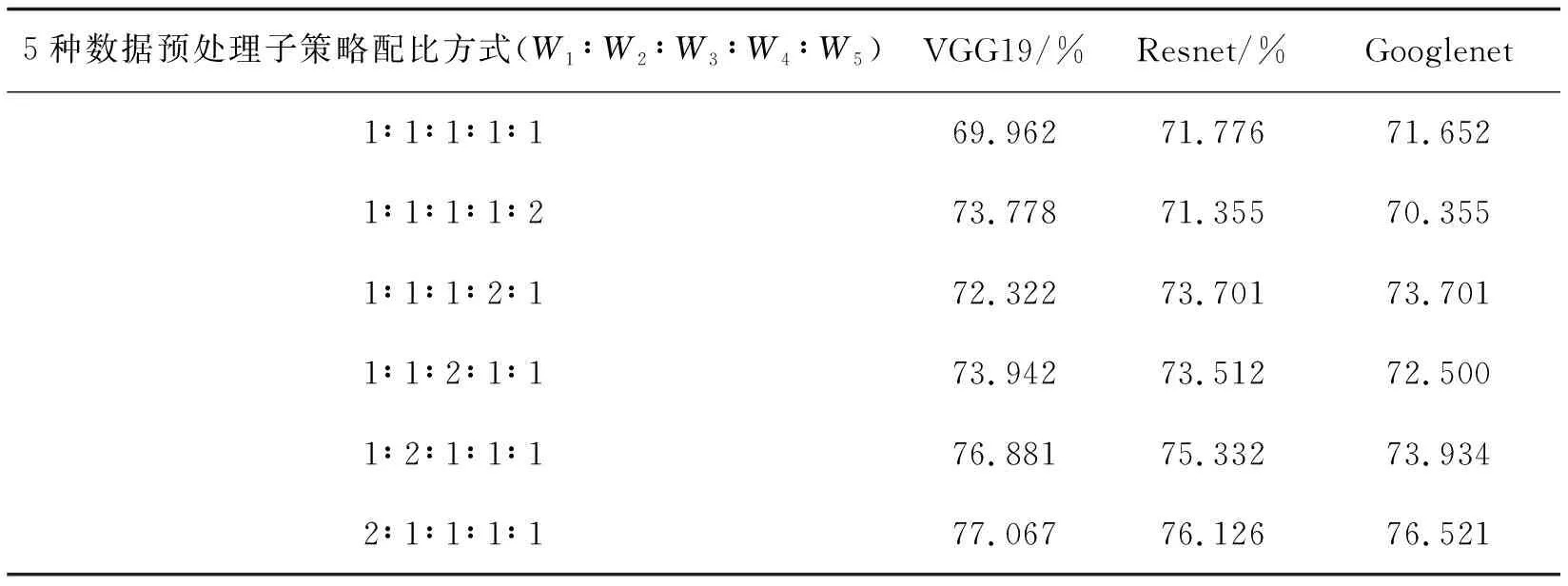
表3 采用不同网络结构与相同权重分配策略,平均准确度测试比较
4 结束语
笔者提出了一种在现有的表情识别算法训练和识别的网络架构基础上增加了一种随机权重分配进行数据增强的预处理方式,解决了由于在训练过程中表情标注主观性强,歧义较大,导致可训练样本缺少,识别准确度不高等问题。实验结果表明,文中提出的方法可提高图像的数据库质量,提高分类器的性能和面目表情识别的准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
建筑科技(2018年6期)2018-08-30 03:40:54
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
制导与引信(2017年3期)2017-11-02 05:16:56
中国交通信息化(2016年5期)2016-06-06 03:51:43
工业设计(2016年11期)2016-04-16 02:50:19
环境科技(2015年6期)2015-11-08 11:14:26
电网与清洁能源(2015年2期)2015-02-28 16:03:07
电视技术(2014年19期)2014-03-11 15:38:20
