
粉末床激光成形熔池辐射强度信号的机器学习
2022-10-12 11:44段玉聪王学德周鑫张佩宇郭西洋成星樊军伟
航空学报 2022年9期
段玉聪,王学德,周鑫,*,张佩宇,郭西洋,成星,,樊军伟
1. 空军工程大学 航空等离子体动力学重点实验室,西安 710038 2. 西安空天机电智能制造有限公司,西安 710100
航空装备的备件保障是世界各国空军面临的共性难题,金属增材制造由于其快速、灵活、小批量生产、个性化定制等诸多优点,在零部件的快速反应制造和现场修复中具有巨大优势。金属增材制造一般包括定向能量沉积成形(Directed Energy Deposition,DED)和粉末床熔融成形(Powder Bed Fusion,PBF)两类方法。激光粉末床熔融成形适合制备航空装备中的中小尺寸带内部结构的复杂零件,空军工程大学已将其应用在现场保障中,未来将向高性能、高批次稳定性、成形过程与后(热)处理复合等方向发展,并需解决过程回溯和质量追溯难题。控制成形过程、提高成形质量的关键是更好地理解原材料粉末参数、成形工艺参数及部件微观组织结构和机械性能之间的复杂关系。但激光粉末床熔融成形是典型的多物理、多尺度过程,包括微观尺度的激光-粉末相互作用、介观尺度的熔池动力学和柱状晶生长及宏观尺度的热力耦合等,工艺参数与最终质量之间的关系过于复杂而难以直接理解。
实施过程在线监控是保障成形质量的关键技术手段。在线监控可从多个传感器获取数据得到成形过程的最直接信息,对监测数据进行实时、准确分析,可实现对成形质量的闭环控制。但由于光斑(熔池)尺寸小、移动速度快、监测信息量大、信号理解不明晰等原因,建立熔池监测信号(辐射强度、形貌、温度场)与材料科学现象(凝固组织、缺陷、表面粗糙)的直接联系也较为困难。
对缺陷的在线监测和质量的在线分析,未来可能有两条主要的技术路线:一是采用较为先进的成像技术,在成形过程中直接观察熔池内气泡的演化、识别缺陷形成,这要求较高的空间分辨和时间分辨能力;二是采集熔池温度、辐射强度和光强信息,上述信息能反应熔池稳定性状态和缺陷产生倾向,但相互联系不直观,什么样的熔池信息特征变化代表缺陷一定会产生,目前还不十分清楚。熔池信息与成形质量(致密度、表面粗糙度、强度等)存在某种高维特征联系。近年来,机器学习算法(Machine Learning,ML)在计算机视觉、自然语言处理、自动驾驶等领域发展迅速,可识别数据之间潜在的复杂模式,表征数据之间非线性、高维度、高复杂度的关系,因此机器学习在挖掘激光增材制造过程参量与成形质量之间的复杂联系方面具有巨大潜力。
在诸多过程参量中,熔池辐射强度信号由激光作用于粉床时形成的熔池及其周围物质辐射而形成,蕴含了丰富的熔池动态特征信息,反映工艺过程的稳定性和最终成形质量,国内外诸多学者对其进行了研究。比利时鲁汶大学Clijsters等采用光电二极管采集到的熔池辐射强度信号和图像处理技术,在原理上实现了对熔池特征的在线监控,但采样率和系统稳定性较低,难以应用于实际生产。Montazeri等使用光电二极管采集到的激光粉末床成形过程数据,对过程中的粉床污染进行了监测,但不能根据数据对污染类型及污染的严重程度进行分类。Coeck等采用离轴监测方式,将熔池辐射强度信号与内部缺陷关联起来,但只适用于监测样件局部固定尺寸的缺陷,局限性较大。上述研究均对熔池辐射强度数据有一定的分析与利用,但由于采样频率较低、没有对数据进行适当的预处理及特征提取,造成信息采集不充分、数据处理效率低下和精确度不高等问题,难以在实际生产中进行工艺参数的实时调整及对样件总体质量进行分类识别。
针对上述问题,本文设置不同的工艺参数(部分偏离工艺窗口)开展粉末床激光成形实验,成形过程中采集熔池辐射强度信号。通过数据分割、特征提取和特征选择对信号数据进行预处理,构建用于机器学习的数据集。使用21种不同的机器学习算法,一是将熔池辐射强度数据按工艺参数(如激光功率、扫描速度高、中、低)进行准确分类,实现熔池辐射强度偏离最佳参数窗口时的异常识别;二是将熔池辐射强度数据按照最终成形块体的质量(密度、表面粗糙度)进行分类,以期实现根据熔池辐射强度数据识别样件质量。
1 实验设计与数据获取
1.1 样件制备
成形实验采用北京易加三维科技有限公司的EP-M250设备,设备由激光光学扫描系统(激光光学系统、扫描振镜)、工作舱、气体流通分析系统(气体循环系统、氧气分析报警系统)及控制系统(计算机、软件系统)组成;成形材料选择霍尔流速为18.8 s/50 g、松装密度为4.02 g/cm的316L不锈钢粉末,粉末粒径分布=20 μm,=32.7 μm,=53.4 μm,其中、、分别表示粒度分布数达10%、50%、90%时对应的粒径。
根据设备厂商提供的标准数据包,致密成形的参数窗口为功率250~280 W、速度950~1 000 mm/s、扫描间距0.1 mm、每层铺粉厚度40 μm。在较大范围内改变激光功率、激光扫描速度等参数设置。具体参数设置详见表1,扫描策略按标号顺序以长直线单向扫描,见图1。最终成形的每个样块尺寸为15 mm×15 mm×60 mm,最终成形样品见图2。根据参数不同分5组,样块3、8处于最佳参数窗口,其余样件的参数偏离最佳窗口。
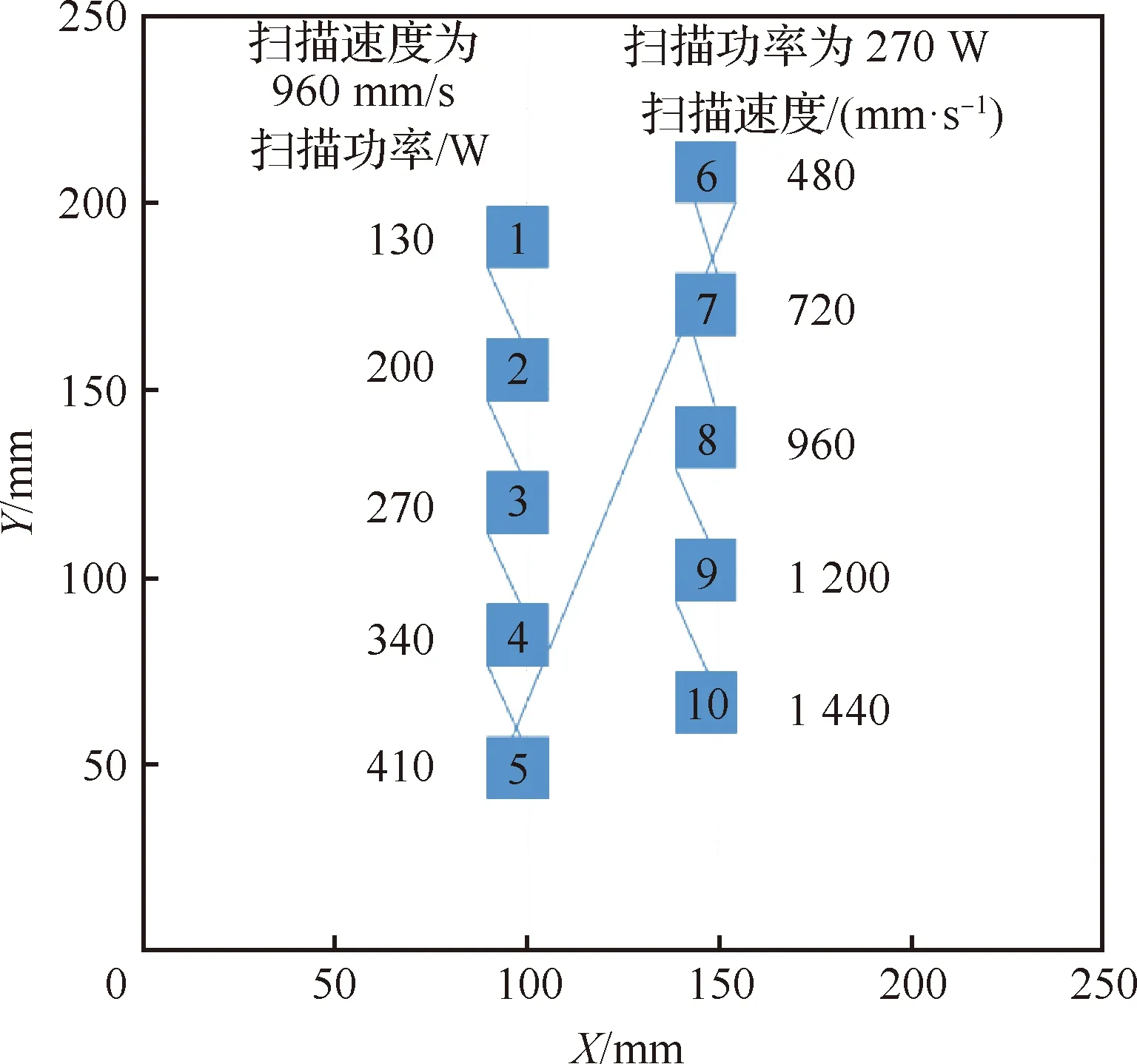
图1 激光扫描平面Fig.1 Laser scan plan

图2 成形样品Fig.2 Manufactured samples
1.2 样件测试
打印完成后,使用线切割将样件从基板上切下,使用OHAUS公司的AX223ZH电子天平,在25 ℃的测试水温下,每个样件采用排水法测试5次密度并记录,最终使用5次密度的均值表示每个样件的实际密度。用表面粗糙度测试仪检测表面粗糙度,当样件粗糙度在上表面分布差异较大时,采取不同位置多次采样取平均值作为最终值并记录,密度和表面粗糙度实验结果见表1。
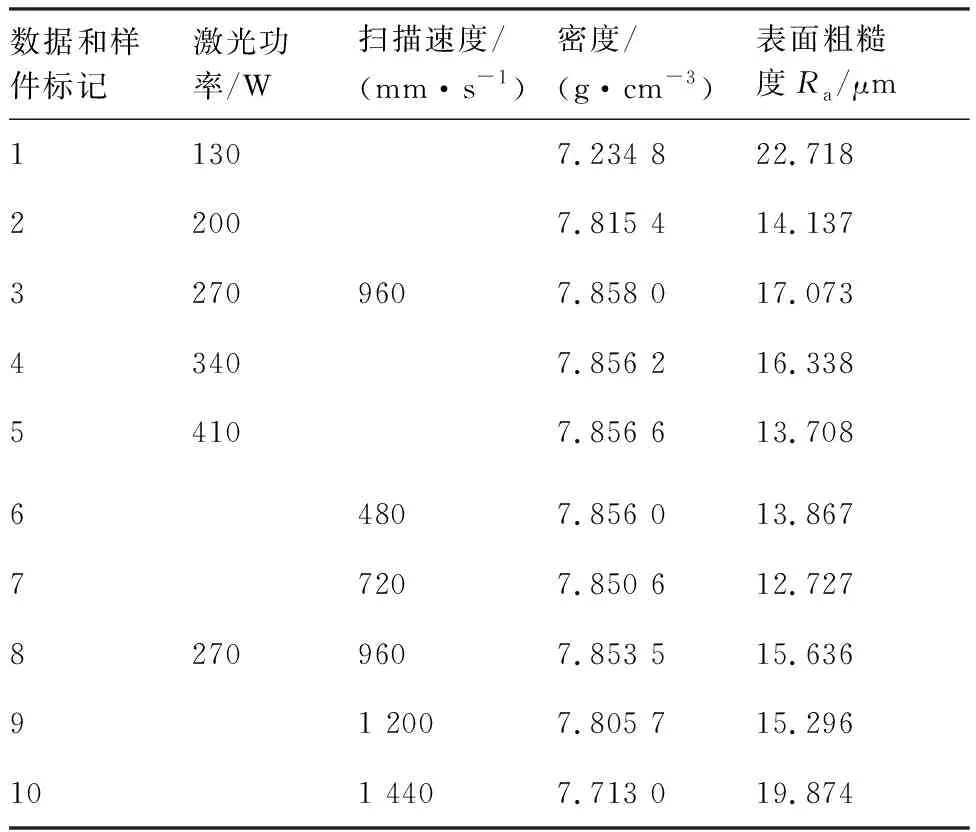
表1 打印样件参数取值范围分布和测量结果
1.3 熔池辐射强度信号采集
光电二极管可在激光粉末床成形过程中将熔池辐射的光信号转化为电信号。使用Thorlabs公司的PDA10A2光电二极管可收集来自熔池辐射200~1 100 nm波段的光信号。光电二极管的响应率可定义为在给定时刻产生的光电流与入射光功率的比值。熔池辐射强度采集系统工作原理如图3所示。
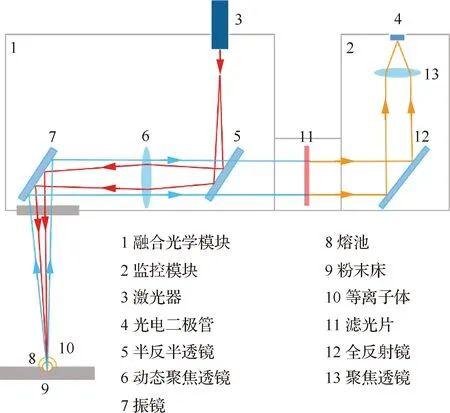
图3 熔池辐射强度监测系统Fig.3 Molten pool emission intensity monitoring system
在成形过程中,激光器发射出激光,经扫描振镜将激光照射到成形缸内与粉末发生相互作用,形成熔池及周围物质,发出光辐射,而后熔池辐射光经扫描振镜反射通过增透镜。由于熔池和周围材料的辐射光在各个波段分布且各个波段辐射强度不同,为避免引入太宽波段影响分析、排除反射激光(波长为(1 024±10) nm)及环境照明光的干扰,设置700~950 nm的带通滤光片,将处于辐射强度峰值附近的近红外波段光传输到光电二极管,光电二极管进一步将光信号转化为电信号进行存储,实现熔池辐射强度信号的监控。
上述监控系统数据采样率=50 kHz,打印过程中数据采集卡及自主研发的数据采集程序会实时获取打印机控制系统的层数同步信息,并在每层打印完成之后,自动将同一激光扫描层的熔池辐射强度数据储存为一个文件。
图4展示了一层熔池辐射强度数据的波形图,其中包含了一层中10个样件的熔池辐射强度信息。每层扫描时间约为27 s,采集到数据量约为40 MB,由于激光粉末床熔融过程通常耗时长、打印层数多,造成监控总数据量巨大。若直接使用原始数据进行计算,会耗费大量的计算资源及储存空间,实时分类十分困难,因此需对数据进行进一步的数据处理、特征提取和特征选择。
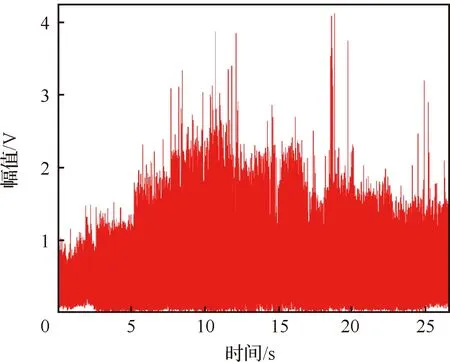
图4 一层熔池辐射强度数据Fig.4 Emission intensity data of a layer of molten pool
2 数据处理
将数据输入机器学习模型前需进行数据预处理,首先将采集到的每段数据与样件对应起来(数据分割);随后将每个熔化道对应熔池辐射强度数据的数据特征作为一个数据样本(特征提取和特征选择),用相应分类标签进行标定,构成用于机器学习的数据集(数据集的标定与划分)。与原始数据相比,特征提取和特征选择后形成数据集的数据量被压缩为原始数据量的3%以下。有效减少了监测数据冗余,提高了数据处理效率。
2.1 数据分割
首先将原始文件的一层数据分割为每个熔化道对应的数据,然后根据熔化道之间的时间先后顺序将每段数据与样件对应起来。
由于一层数据包含了10个不同工艺参数下样件的熔池辐射数据,因此首先需将一层数据的10段数据与打印的10个样品对应起来,对此提出了一种数据分割算法,解决熔池辐射数据与样件的对应问题。算法原理如图5所示。图5横坐标为时间轴,由于采样是在时间域上进行的,因此数据点的先后位置与时间点一一对应,相邻两个数据点之间的时间差即采样时间,为采样频率的倒数:
=1=002 ms
(1)

图5 数据分割原理Fig.5 Principles of data segmentation
图5中Δ定义为数据序列的第个数据脉冲(激光扫描线段也即一个熔化道对应熔池辐射强度)的下降沿对应位置d,与第个数据脉冲的上升沿对应位置u,的差值:
Δ=d,-u,
(2)
Δ={Δ,Δ,…,Δ,…}
(3)
则Δ即对应第个激光脉冲的扫描时间,截取Δ对应的数据,就得到了第个数据脉冲。由Δ序列组成的数集Δ对应所有数据脉冲扫描时间,如此一层的原始数据就被分割为以激光脉冲(单个熔化道)为单位的大量分段数据,按照扫描策略及先后顺序即可与样件一一对应起来,每个分段数据将作为一个数据样本,进行特征提取与特征选择。
2.2 特征提取
采用数据特征提取算法提取数据特征,相关特征量如图6所示。图中数据特征具体定义及其物理意义参照附录A。从每道激光脉冲数据中提取上述特征,这样即可用图6中的一组数据特征表征一道激光数据脉冲(每个熔化道),不同样件对应的脉冲数据特征按标定分类存储即可得到熔池辐射强度数据集。
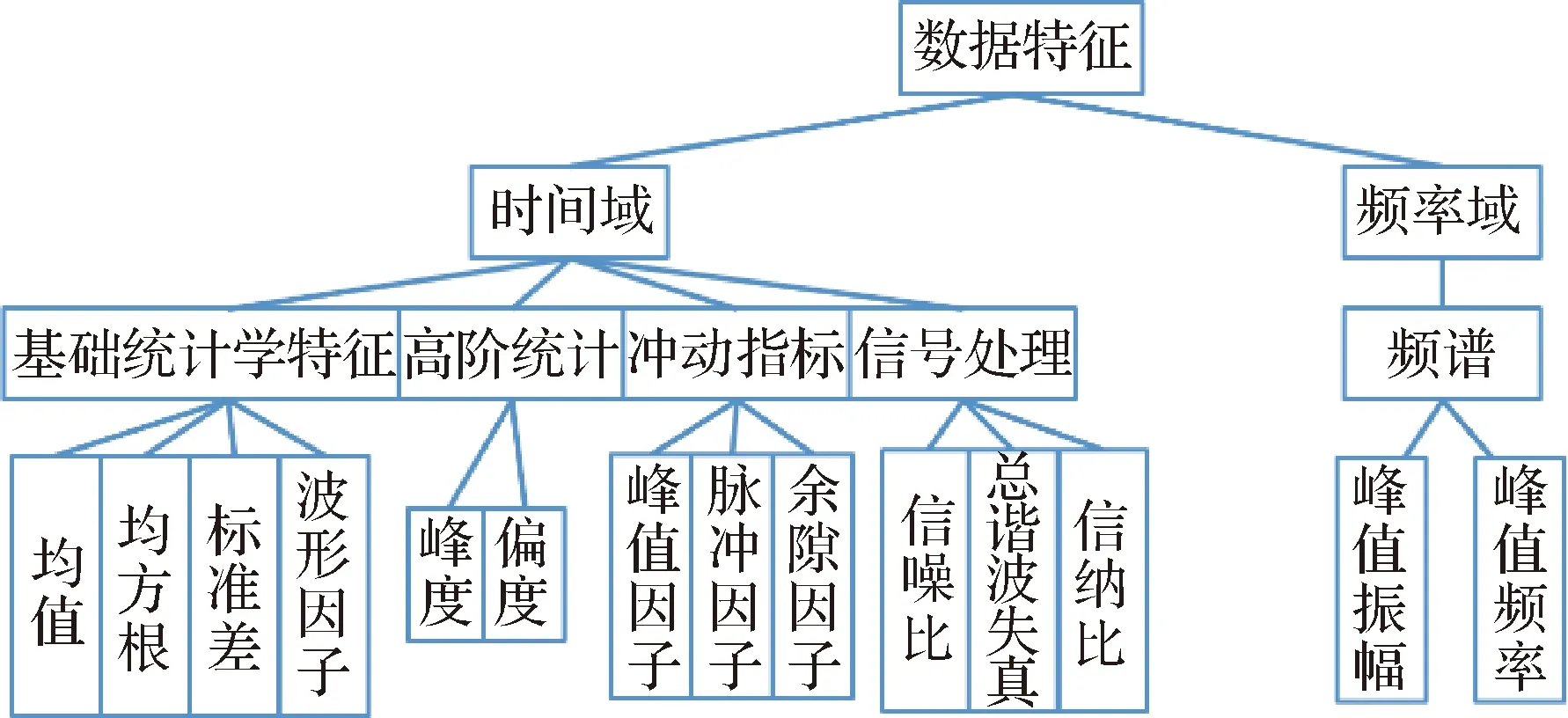
图6 数据特征Fig.6 Data features
2.3 特征选择
在特征提取过程中,难免会提取到一些与分类结果无关或相关性很小的特征,这些特征对于分类结果没有明显的影响,因此会造成特征的冗余及数据量的增加,删除这些特征有利于进一步清晰特征与分类结果之间的关系,去掉数据冗余。
使用MRMR(Max-Relevance and Min-Redundancy)算法选择特征,其原理为:在原始具有个特征的特征集合中找到一个特征子集,使子集中的特征与最终输出结果的相关性最大,但是特征彼此之间相关性最小。首先将最大相关性和最小冗余度结合起来,通过前向加法方案对特征进行排序,使用启发式算法量化特征的重要性,并返回每个特征所得分数,较大的分数表明相应的特征更加重要,然后给定特征数量找到一个最优集合。算法原理流程参考文献[23-24]中具体说明。
使用MRMR算法对提取的特征进行评分和排名,当以工艺参数为响应变量时,特征值重要性评分-排名柱状图如图7所示,不同响应变量对应的特征重要性评分如表2所示。
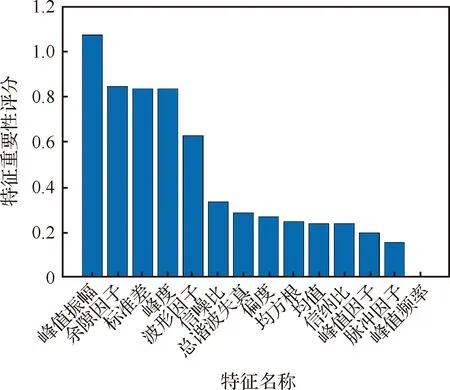
图7 工艺参数为响应时特征重要性评分及排名Fig.7 Feature importance score and ranking when response is a process parameter
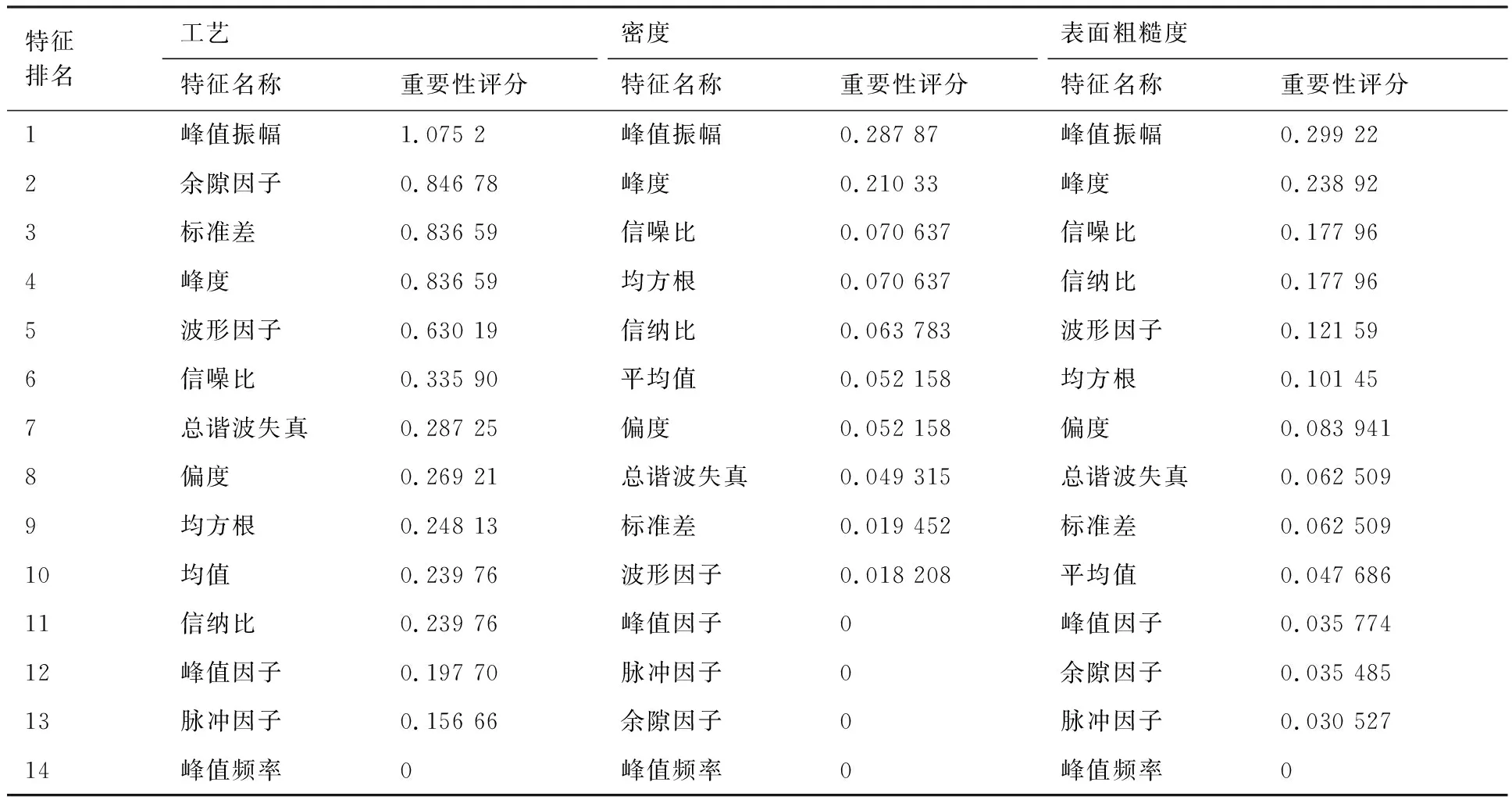
表2 不同响应的特征重要性评分及排名Table 2 Feature importance score and ranking for different responses
在此基础上,在训练模型时根据响应变量选择对应重要性较高的特征子集,删除不必要的特征可更高效地求解问题。
2.4 数据集的标定与划分
在构建数据集时,删除由于设备原因采集到损坏的无效数据,再从无损的数据中进行抽样,使每个样件对应数据样本数尽量一致。得到7 575 组数据样本;再根据2.3节结果,选择每组重要性评分前10的特征构建对应数据集。因研究熔池辐射强度分类和样件质量预测分类两个问题,所以建立两个数据集。
熔池辐射强度分类数据集
将最佳工艺参数下的数据样本标记为“参数正常”(样件3、8)。将扫描功率小于和大于最佳值参数的数据样本分别标记为“功率过小”(样件1、2)和“功率过大”(样件4、5);将扫描速度小于和大于最佳速度参数下的数据样本分别标记为“速度过小”(样件6、7)和“速度过大”(样件9、10),得到用于工艺参数异常识别的训练数据集。
质量预测分类数据集
将测得样件的密度与表面粗糙度按数值大小进行分类,描述打印样件的质量。316L不锈钢的密度为7.980 g/cm,将致密度大于95%(密度大于7.581 g/cm)样件的密度标记为“正常”,反之标记为“缺陷”;样件的标记为“正常”“偏大”“过大”。相应分类标准如表3和表4所示,以此标记对应样件的数据样本构成用于质量预测的数据集。

表3 密度取值范围及其对应标签Table 3 Density value range and its corresponding labels

表4 表面粗糙度Ra取值范围及其对应标签
在数据集1、2中随机抽取900组数据作为测试集,不参与模型训练过程,只用于模型训练完成后测试模型性能,其余6 675组数据作为训练集对机器学习模型进行训练。
3 熔池辐射强度异常识别与样件质量识别
3.1 机器学习与算法模型
常用的有监督机器学习分类模型有以下5类:决策树模型、判别分析模型、朴素贝叶斯分类器(Naive Bayesian Classifier)、支持向量机(Support Vector Machine,SVM)分类、最邻近(-Nearest Neighbor,KNN)分类,每一类又可根据算法复杂度不同分为具体的算法模型。采用的相关21种具体机器学习算法模型及其特点见附录B。
由于各种分类器的特点不同,模型复杂度不同,因此对不同数据的适用性也不同,采用21种机器学习模型逐一对构建的两个数据集进行分类和预测,比较不同分类器的分类准确度和算法模型性能,分别得出异常识别和性能预测的最佳模型。
3.2 熔池辐射强度异常识别
首先对工艺异常种类进行识别可有针对性地实时调控,确保加工稳定性和成形质量。将数据集1中的训练集逐一输入不同模型进行训练,对工艺参数的异常类型进行识别和分类,为减少数据过拟合、提高模型的泛化能力,在训练过程中采用五折交叉验证方法进行模型训练,步骤如下:
1) 不重复抽样,将6 675组数据随机分为5份。
2) 每次挑选其中1份作为验证集,其余4份作为训练集训练模型。
3) 第2)步重复5次,使每个子集都有一次作为验证集,其余作为训练集。
4) 保存5次训练的验证结果,计算5组验证结果的平均值作为最终精度,以此作为五折交叉验证下模型的性能指标。
训练完成后比较每个模型的分类准确度,结论如表5所示。可看出几种SVM模型对熔池辐射强度的分类准确度最高。表5中识别准确度最高的二次SVM、三次SVM通过核方法(Kernel Method)对数据集进行非线性分类。使用非线性函数将非线性可分问题从原始的特征空间映射至更高维的希尔伯特空间(Hilbert Space),即特征空间存在超曲面(Hyper Surface)将各个类别分开。由此可说明熔池辐射强度数据与其工艺异常类别之间存在高维度的联系,只有使用SVM模型对数据样本的最大边距超平面决策边界进行求解才能获得最高准确度。

表5 加工参数异常识别准确度
相比于支持向量机模型,准确度最低的一类分类器属于最邻近法,其算法结构较为简单,无法准确表征数据内部的复杂结构,因此准确度相对较低。
3.2.1 模型优化
使用随机梯度下降法对二次SVM的分类问题进行优化,图8展示了一次优化过程的准确度曲线,优化过程可理解为在空间中寻找一个最优化的超平面,使训练集上不同类别间离其最近的点到此超平面的距离最大化,这些点被称为支持向量。具体步骤为:先使用数据集1中的训练集训练模型,将训练集全部输入模型得到一个输出,将此输出标签与真实标签对比,计算准确度;再根据输出结果与真实值之间的差异,使用随机梯度下降方法修正模型参数,接着进行下一轮迭代。如此进行20万次训练,每1 000次记录一次准确度得到图8,可知在随机梯度下降的过程中,准确度曲线先随训练次数增加而上升,直至约13万次之后逐渐收敛,最终达到了93%以上并趋于平缓。
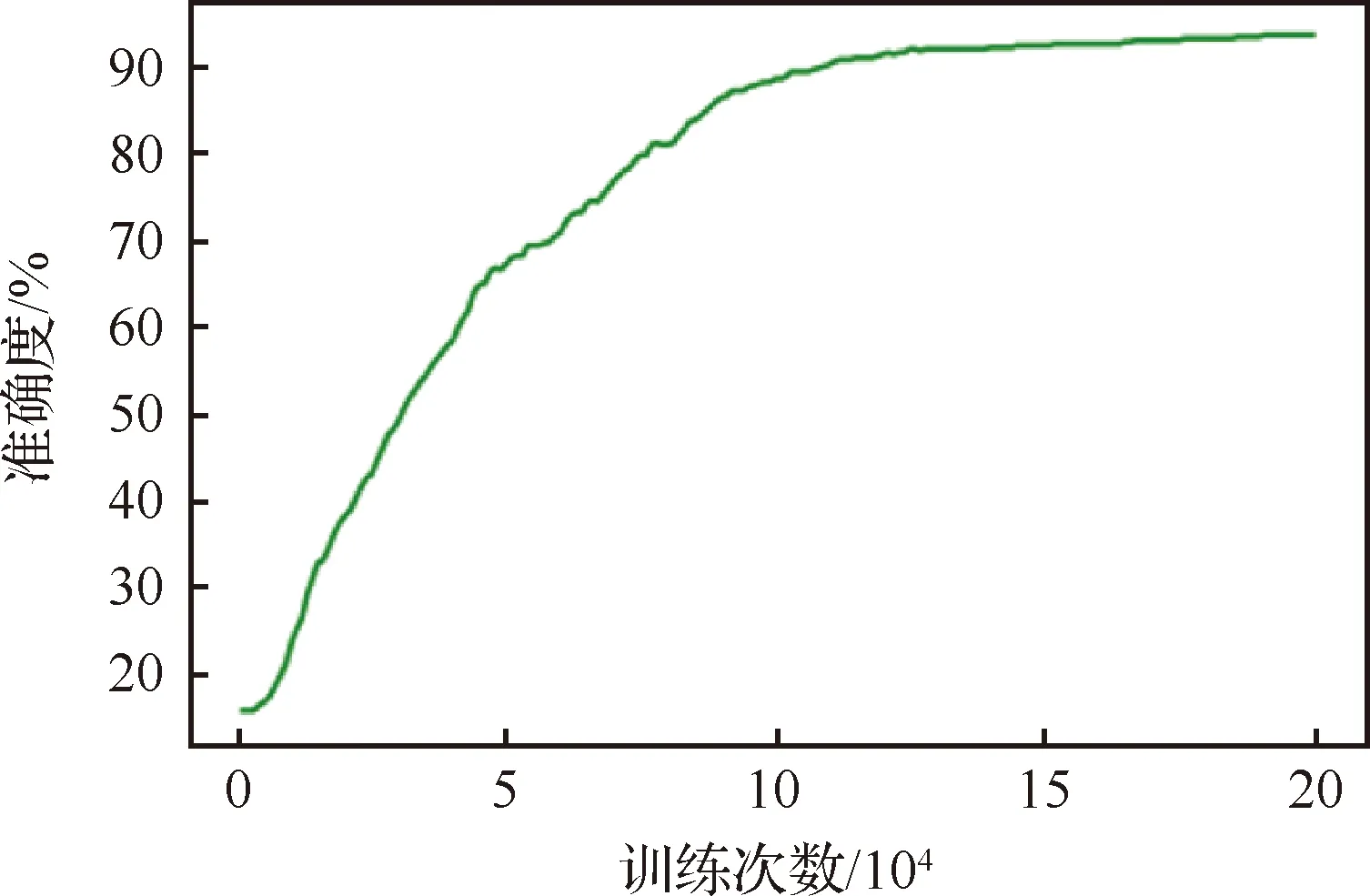
图8 随机梯度下降法下二次SVM模型的准确度曲线Fig.8 Accuracy curve of quadratic SVM model with stochastic gradient descent method
3.2.2 结果分析
在高维空间中,每个特征维度都对应一个坐标轴,数据点在每个坐标轴上的投影即为数据点相应特征值。高维空间难以展示,所以用其中两个特征为轴将这些数据点投影到二维平面以便于观察。对比发现以平均值和波形因子分别作为横、纵坐标时,同类数据点聚集性及不同类数据的区分度最佳,因此选择平均值和波形因子为轴画出散点图。
图9为将留出的900组测试集数据输入训练后的二次SVM分类模型得出的熔池辐射强度分类散点图。图9中一个点即代表对应横纵坐标数值下的一个样本,不同颜色代表不同样本的原始类别。由图9可看出激光功率过小类别的样本点均值特征明显较小,此类样本呈现明显的聚集性。这表明激光功率的异常变化最直接地影响了熔池辐射强度数据特征变化,使数据特征在数值上出现了明显差异。对于图9中其余异常强度下的样本,相同种类的样本也呈现出一定的聚集性,但不同种类样本点之间的重叠性较大,说明这些数据样本具有在原始特征空间观察不到的高维空间聚集性。

图9 基于二次SVM分类模型的工艺参数异常识别散点图Fig.9 Scatter plot of abnormality identification of process parameters based on quadratic SVM classification model
图10为混淆矩阵,展示的是二次SVM分类模型性能指标,矩阵中的数据为将第类样本判别为第类的样本点百分比,所以对角线上越大表示分类模型的准确度越高。图10中TPR(True Positive Rate)为召回率,定义为

(4)
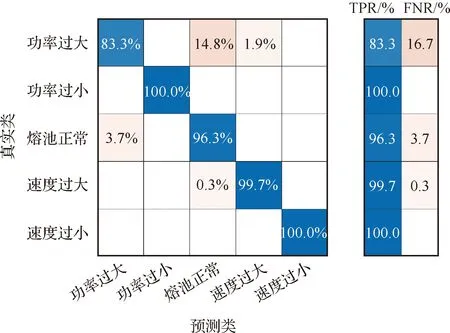
图10 基于二次SVM分类模型的工艺参数识别混淆矩阵Fig.10 Confusion matrix for process parameter identification based on quadratic SVM classification model
式中:TP为真正例数(True Positive);FN为假负例数(False Negative)。
TPR可以理解为所有正类中预测正确的比例,即真正例数与假负例数之和中真正例数的比例。FNR(False Negative Rate)为正类中预测错误的比例,定义为

(5)
从混淆矩阵中可看到功率过小和速度过小时识别准确度达100.0%,分类器的准确度非常高。在功率过大时TPR为83.3%,是几个类别中最低的,说明在激光功率过大时容易出现错误分类。分析原因认为功率过大时熔池辐射强度容易超出采用的光电二极管量程,从而使传感器采集到更多的错误数据,进而影响识别准确度。
3.3 样件质量识别
经过大量不同数据集的测试证明在使用熔池辐射强度数据进行预测和分类时,通常二次SVM模型准确度最高,因此选用二次SVM模型分别对样件密度和表面粗糙度进行识别。
3.3.1 对密度的识别
由于10个样件中标记为“缺陷”的样件只有1个,使分类问题中不同类别数据样本不均衡,易造成训练模型对大样本类别过拟合而对小样本类别欠拟合,为解决此问题,在构建数据集时对小样本类别进行过采样(over-sampling),即增加部分样本,对大样本类别进行欠采样(under-sampling),即删除部分样本,以此达到数据集的均衡。使用以密度作为分类标签经过特征选择、均衡处理之后的数据集(2 000组数据)输入二次SVM模型,以数据特征作为预测变量,以密度分类标签作为响应训练模型,以五折交叉验证法训练模型,训练完成后将900组测试集的数据输入,得到测试集数据样本的密度预测结果,准确度达99.6%,其识别结果散点图如图11所示。
图11中被分类为缺陷的数据点明显分布在均值较低的区域,集中度很高,且在纵坐标波形因子分布上相对较高。而密度正常的样本点集中程度较低,整体分布区域跨度较大,说明在形成致密样件时存在一定的参数窗口,熔池辐射只要在此参数窗口下,样件致密度均可处于较高水平。比较密度正常样本与缺陷样本可发现密度正常样本通常聚集在均值较大区域,说明熔池辐射强度均值较小时更易出现致密度较低的情况,原因是此时不能充分熔化粉末。
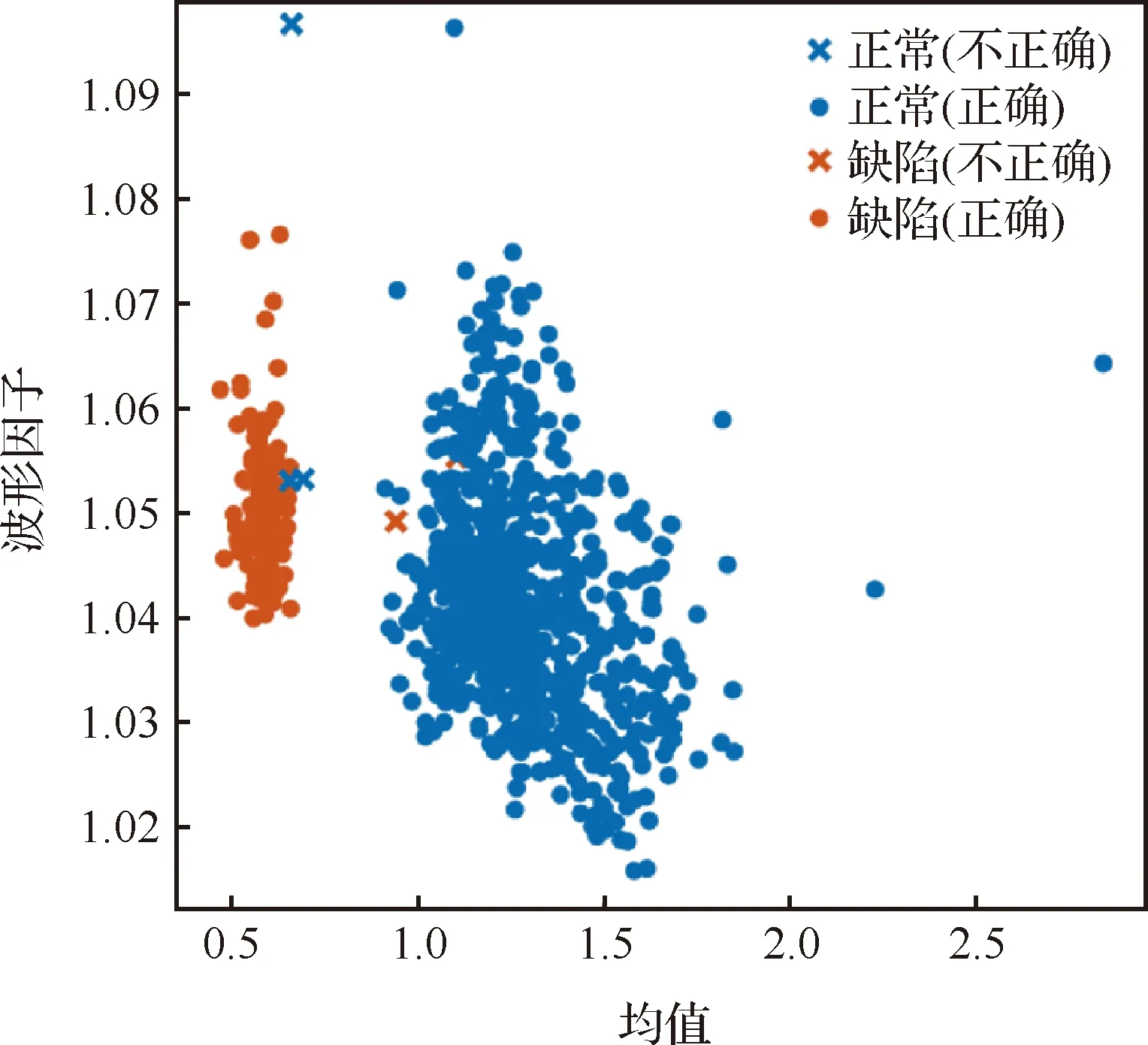
图11 基于二次SVM分类模型的密度预测散点图Fig.11 Scatter plot of density prediction based on quadratic SVM classification model
3.3.2 对表面粗糙度的识别
同样使用二次SVM模型,以表面粗糙度作为标签的训练数据集输入模型进行训练,使用测试集对训练结果进行测试,得出对表面粗糙度的预测准确度为97.0%,分类结果散点图如图12所示。可看出同一表面粗糙度类型之间在一定程度上聚集在不同区域,其分散程度也有所不同,如过大时的数据点聚集在两个不同的区域,正常的数据点有一部分较为集中,另一部分较为分散。分析其原因认为与成形密度不同,在熔池辐射强度过大和过小时都会出现较大的表面形貌缺陷;而在输入激光的功率和速度分别变化时,不同的参数可产生相同的表面粗糙度,情况较为复杂,导致表面粗糙度相同类型的数据点呈现不同的分散程度。

图12 二次SVM分类模型预测Ra散点图Fig.12 Scatter plot of Ra predicted by quadratic SVM classification model
4 结 论
首先设计实验,使用熔池辐射强度数据采集系统对粉末床激光成形中的强度数据进行了采集;然后对其进行数据分割、特征提取和特征选择,使用工艺参数的异常类型及相应密度、表面粗糙度进行数据标定;最后构建了用于机器学习分类模型的数据集,并对模型进行了训练。
1) 提出的熔池辐射强度数据特征提取方法可大幅减少过程监控的数据量,提高数据计算和存储效率。
2) 解决了监测数据有效利用问题,对采集到的大量数据进行了有效分析,建立了工艺参数-监测数据-样件质量之间的关联。机器学习分类模型对于制造过程中工艺参数的异常识别准确度很高,可实现实时监测熔池辐射强度数据,进行工艺参数异常识别,为实时反馈调整参数提供依据,进而达到提高产品质量的目的。
3) 使用机器学习模型预测产品质量,建立了监测数据与最终质量的联系,对密度、表面粗糙度预测准确度很高。基于熔池辐射强度监测手段可一定程度上替代传统人工复杂的质量检测方法,节省仪器和时间成本,从而实现实时预测质量,对样件进行智能分类。
猜你喜欢
中国应急管理科学(2022年1期)2022-04-18
科学与财富(2019年9期)2019-06-11
滇池(2017年5期)2017-05-19
中国科技纵横(2017年5期)2017-05-12
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
哈尔滨理工大学学报(2016年2期)2016-09-12
少年科学(2015年3期)2015-04-08
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
