
基于改进YOLOv3的水电施工区安全佩戴检测方法
2022-10-11 10:04刘增辉和孙文张社荣王枭华
水力发电 2022年7期
刘增辉,和孙文,张社荣,王 超,王枭华
(1.天津大学水利工程仿真与安全国家重点实验室,天津 300350;2.中国电力建设集团(股份)有限公司,北京 100048)
0 引 言
根据水利部2018年发布的水电工程施工危险源清单,施工作业类危险源中明确指出高处作业、有限空间和检查作业时未正确使用防护用品可能导致的物体打击和人身伤害后果,而安全帽的佩戴和及时的险情(如火情)报警可以有效防止和降低外来伤害,从而更好地保障施工安全,此外,伴随新冠疫情的常态化,需要尤其重视施工区人员的口罩佩戴。然而,通过对多处水电施工现场进行统计发现,水电施工作业人员的安全帽佩戴意识较为薄弱,现场管理及险情处理滞后,防疫口罩佩戴参差不齐,这无疑增加了施工场区的作业风险。近年来,国内外众多专家学者对施工区域的安全佩戴和险情识别技术进行了深入研究。冯国臣等[1]提出判别人体像素面积的模型识别方法,并基于安全帽位置和颜色特征统计来完成佩戴检测;胡超超等[2]将改进型YOLOv2与卡尔曼滤波结合来检测追踪多目标;何超[3]提出了在YOLOv3主网络三层卷积之后增加特征尺寸更大的卷积层,一定程度上提升了小目标识别效果;徐守坤[4]等提出基于改进的Faster RCNN和多部件结合的安全帽佩戴检测方法用于提高安全帽检测准确率,但检测速率较低;张勇等[5]提出采用DenseNet方法处理低分辨率特征层,在一定程度上提高了YOLOv3时序约束效果。但是现有检测识别方法仍然存在检测效率低等问题,无法较好地满足实际工程应用的需要。为此,提出多目标检测识别算法YOLOv3-SG,以期对目标检测识别在复杂水电施工环境中的应用效率提升起到指导作用,满足水电工程施工场区智能识别场景下的人员安全佩戴管控目标。
1 水电施工区人员安全佩戴YOLOv3网络结构分析
深度学习网络相对于传统的图像特征提取方法有明显优势。当前目标检测算法主要有R-CNN、Fast R-CNN、SPP-Net、YOLO、SSD、Retina-Net等[6],并按照其产生候选区域和分类回归是否融合分为two-stage和one-stage两类,上述前3种算法就属于two-stage,其中R-CNN作为开山之作,是Girshick等[7]在2014年CVPR会议上提出的,后续提出的算法多是在其基础上进行优化改进的。one-stage的代表为2016年的YOLO算法,Redmon等[8]将其判识统一,极大地降低了因重叠导致的重复运算,提高了检测效率。
本文参照的YOLOv3目标检测网络结构是基于YOLOv2进行改进的,其特点是在检测精度提高的同时,检测速度相对前版本并无降低。不同于YOLOv2的Darknet-19网络结构[9]和softmax loss逻辑回归损失函数,YOLOv3采用darknet-53网络结构[10],在避免信息丢失方面做了2方面的调整:①融合ResNet跳跃连接层(同时避免梯度消失);②去除Pooling层,使用Conv做下采样,进一步减少特征损失。此外,相对于YOLOv2的5个锚框anchor,YOLOv3新增了4个anchor,对应在每层为3个anchor,使得预测框与锚框的交并比IOU得到了有效提高。
darknet-53一共是53层卷积(全连接层也是由卷积得到的),Convolutional不单单是一个卷积层,它是普通的卷积、BN归一化处理和LeakyReLU激活函数三者按照固定顺序组和而成的。每个方框对应一个Residual残差结构,具体残差结构构成如图1所示,它的主分支组成为1×1和3×3的卷积层,最后将接近主分支上的输出直接从输入上引过来,和主分支上的输出相加,得到最终的输出,并非在两个卷积层之后又接了一个残差结构,而是整个框对应的为一个残差结构。在模型结构部分,是在3个特征层上进行预测的,使用k-means聚类算法得到9组尺度进行均分,每个尺度在coco数据集上分别预测4个偏移参数+1个置信度+80个类别参数。同时YOLOv3采用特征金字塔网络,3个特征层的预测输出并不是独立的,第二层和第三层都通过前一层进行上采样处理,然后和本层网络结构之后的输出在深度上进行拼接融合,再通过Convolutional Set 处理后得到本层的最终输出,最后三层输出分别对应大中小目标的检测。
2 基于YOLOV3-SG的水电施工区安全佩戴识别模型构建
本文提出的YOLOv3-SG水电施工区人员安全佩戴识别模型主要针对原有算法的主干网络结构、损失函数、锚框聚类进行改进优化,从而使得新网络模型更加贴合水电工程施工区人员佩戴行为和险情数据集,提升施工现场的安全检测识别精度和速度,更快更高效地锁定施工风险源以提升管控效率和安全水平,减少事故发生。
2.1 安全佩戴网络结构优化
网络结构的优化改进主要是通过在每层的Convolutional Set和Up Sampling之间增加Space pyramid空间金字塔网络结构(参照于SPP-Net)以及加深层级。其中,SPP-Net中使用的Space pyramid结构一方面可实现特征规范化和降低裁缩损失,另一方面可通过多角度特征提取来提升模型精度。考虑到Darknet-53网络结构中存在局部特征在提取时未得到充分利用的弊端,本研究参照上述逻辑融入Space pyramid空间金字塔网络结构进行YOLOv3的改进,同时在池化层上采用5×5,9×9,13×13共3种不同尺寸最大值采样处理特征信息,设置池化步长为1,最后在路由层进行保存所有输入特征的融合(区别于残差层的叠加合并),具体流程如图2所示。

图1 Darknet-53网络结构和Convolutional、Residual结构示意

图2 Space pyramid结构配置
根据实测水电施工现场图像中目标尺寸与整图尺寸的对比发现,实际检测过程中的目标分布占比大多数不超过0.2(小目标),本文研究对象采用的是416×416原始输入尺寸,考虑到小目标的尺寸小,分辨率低,需要经过多层卷积后才能有效进行特征提取,而单纯地进行更深层尺度的特征提取容易造成特征的丢失,因此,可以采用将深层次特征与残差结构输出后的特征图进行深度上的拼接,从而达到增强小目标特征提取的目的,这也符合利用多尺度特征融合来提高小目标检测精度的逻辑,因此本研究在原有特征融合的基础上依照上述逻辑采取向上扩充融合的方法,具体步骤为:在第三层52×52之后,首先,通过1个1×1的卷积层和SPP结构特征处理后进行上采样放大,高宽扩大两倍后,将之与2个残差结构之后输出的特征图进行深度上的拼接,最后循序前述特征层,得到预测特征层4。即调整为Space pyramid结构(负责每层的局部多池化尺度特征提取)和第四预测特征层(负责抽取更多小目标特征),两者的融合构成YOLOv3-S网络结构。经过在本文的水电施工安全佩戴和火灾险情数据集(VOC2012)测验对比,检测速度FPS从46.5变化到41.2,检测精度mAP提升了近7个百分点。具体结构形式如图3所示。
2.2 安全佩戴损失函数调整及聚类优化
YOLOv3损失函数是在YOLOv2的基础上将分类损失调换为二分交叉熵,通过剔除softmax改为logistic,在遮挡重叠情况下的检测效果得到了提升。其损失分为置信度误差、分类误差和定位误差,其中定位误差又可分为中心坐标和高宽坐标误差。具体损失函数公式如下
Loss=lxy+lwh+lconf+lcls
(1)
(2)
(3)

图3 改进后整体结构

通过对以上YOLOv3损失函数置信度损失的理论分析可以发现,交并比IoU是目标检测中的关键评判参数,即某候选框(anchor)与某目标对象的IoU最大时的预测框负责该对象。但是通过分析实际水电工程人员佩戴行为危险源识别模型训练和结果判定可以发现,存在IoU为0时的无梯度回传以及IoU相同但是重合度不同的问题,这直接影响了目标的检测精度。
因此,本研究根据前人经验提出基于GIOU[11]改进的YOLOv3损失函数用以提升anchor box与ground truth box的拟合效果,同时保留IoU的尺度不变性特征。IoU和GIoU的计算公式如下
(4)
(5)
LGIoU=1-GIoU
(6)
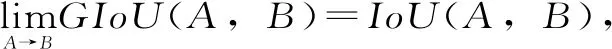

图4 GIoU代码实现
本文在进行损失函数改进后,引入k-means++聚类优化算法,主要优化为初始随机点的生成[12]。针对初始聚类中心的随机选择缺陷问题,通过计算所有样本与已有聚类中心最短距离D(x),按照D(x)大小进行排列,使用轮盘法选出下一个聚类中心(值越大的被选中的概率越大),直至得到K个聚类中心为止。具体的实现步骤如图5所示。

图5 优化聚类中心实现流程
(7)
式中,x为数据集X中的一个样本点;D(x)2为样本点x到聚类中心的最短距离的平方。
轮盘法即获得距离最远的样本点作为聚类中心点,其中enumerate()用于将数据对象合成索引,并得出数据及下标。在经过上述步骤的循环后,得到相对于k-means算法更为合理的K个聚类中心。本研究在三层9个锚框的基础上增加了用于提升小目标的第四层,因此选取K值为12进行聚类,在经过迭代后将得到的聚类数据作为网络锚框参数写入配置。
3 应用分析
3.1 硬件配置
本文模型训练和测验软硬件配置如表1所示。

表1 软硬件配置
3.2 试验分析过程
本研究数据集为7 500张安全佩戴和3 000张火情图像,采集以水电施工现场拍照和视频截帧的方式,摄像头布设在施工场区沿线,为了避免完全遮挡,采取对立面交叉的方式布设。采集到的图像数据采用VOC2012格式处理,标注工具采用Labelimg,标注后生成对应的xml脚本(见图6),分为:person、head、helmet、mask、nomask、fire共6个类别。训练和测试样本比例为6∶1,编写程序生成对应的标签txt并建立标签文件.names,此外,在训练前将train数据和val转成TF格式,便可利用其中的数据加载和转化等API进行高效地训练和评估模型。

图6 数据集制作及部分训练程序
训练输入图像尺寸为416×416,batch_size为32,epoch设置为200(为防止过拟合使训练模型效果变差,在损失值收敛后自动停止训练),权重衰减值为0.000 5,动量配置为0.9[13],学习率的变化随着训练过程从0.001至0.000 1并趋于稳定。训练结束时的损失值收敛到0.3,相对于原YOLOv3的2.2有了较大的提升,训练过程平均损失对比如图7所示。试验检测对比如表2所示。按照环境干扰、多人遮挡、密集小目标的分类随机选取的图片进行的YOLOv3和YOLOv3-SG试验,效果图举例展示如图8所示。

图7 改进前后训练过程平均损失对比

表2 YOLOv3-SG网络检测对比
通过对比分析,图8a中由于背景颜色干扰,改进前未能识别到人员佩戴黄色安全帽,图8d中改进后除了识别所有漏检目标外,识别准确率也有了较大提升;图8b到图8e在多人遮挡上,图8c到图8f在密集人员佩戴安全帽和人员本身识别上,YOLOv3存在多处漏检,而改进YOLOv3-SG全部正确识别;图8g和图8h为改进后的施工区域火情识别,在模糊背景和小目标上都保证了精准度和检测效率,对各种环境适应性较好;图8i和图8j为对人员口罩佩戴行为的检测识别展示,其在单目标和多目标情况下都较好地完成了检测识别。
4 结 语
本文通过对网络结构、损失函数、聚类方法进行改进优化提出了YOLOv3-SG水电施工区多目标检测识别算法,通过引入Space pyramid空间金字塔网络结构实现特征规范化及裁缩损失的降低;通过增加特征层提升小目标识别精度,解决部分遮挡时小目标漏检问题;同时使用GIOU替代IOU交并比方法用以提升anchor box与ground truth box的拟合效果,并保留IoU的尺度不变性特征,较好地解决了水电工程复杂施工环境下施工工人、安全帽佩戴、防疫口罩佩戴和火情的识别速度与精度的矛盾问题,其泛化抗干扰能力强,具备较好的实用价值。
试验表明,本文提出的融合空间金字塔和小目标特征层的网络结构优化方案,提升了在水电施工场区部分遮挡、小目标和环境影响下的检测识别效率。
猜你喜欢
建材发展导向(2022年10期)2022-07-28
建材发展导向(2021年22期)2022-01-18
课外生活·趣知识(2019年4期)2019-09-10
今古传奇·故事版(2017年5期)2017-04-08
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
能源研究与信息(2016年1期)2016-06-01
软科学(2014年8期)2015-01-20
安全与健康(2008年11期)2008-12-27
安全与健康(2006年2期)2006-04-21
