
面向图像与视频的AI篡改技术综述
2022-10-11 02:09童世博
中国刑警学院学报 2022年4期
孙 鹏 童世博
(1 中国刑事警察学院公安信息技术与情报学院 辽宁 沈阳 110035;2 辽宁网络安全协同创新中心 辽宁 沈阳 110035;3 司法部司法鉴定重点实验室 上海 200063)
1 引言
近年来,由于计算机硬件算力的不断进步,基于深度学习的 AI技术得到了快速发展。可以对图像和视频进行编辑处理的AI篡改技术便是AI技术的一种重要衍生,并被广泛应用于影视拍摄、游戏制作和社交软件等领域。此项技术的快速发展给我们的日常娱乐和生活带来极大便利的同时,也同样威胁到我们的个人隐私和信息安全,给新闻媒体、金融服务及公安工作等领域带来很多风险与挑战。在公安工作中,案件的侦查需要对提取到的视听资料进行严格审查并判断其是否具有法律证明力,而经过AI篡改的图像视频因原始性、完整性、真实性在一定程度上发生改变,导致其法律证明力下降,甚至无法再作为证据使用。
AI篡改技术在编辑处理图像和视频时与传统篡改技术不同,传统篡改技术需要较强的技术与经验支持,而AI篡改技术虽然本身技术性强、复杂难懂,但是具有黑盒特性,使得AI篡改技术与传统篡改技术相比,对于使用者的技术要求较低且学习成本小,可以较轻松的制作出高质量且不易分辨的虚假图像和视频。其中Deepfakes作为AI篡改技术之一,使用深度学习网络基于数据集训练,对图像和视频中的目标进行重建、替换、编辑合成[1],从而完成对图像视频中目标的篡改。AI篡改效果如图1所示,其中a为原始图像,b为经过AI篡改后的图像。

图1 AI篡改效果图
Deepfakes可以将源人物的面部篡改到目标人物面部区域上[2],其名字来源于深度学习(Deep learning)和虚假(fake)两个词的组合。2017年一位名为“deepfakes”的用户使用Deepfakes工具将影视明星与色情视频演员的面部相互替换,基于此制作了一段虚假色情视频并将其发布在Reddit网站上。随后,该用户将该工具的代码在网络中进行开源,其他开发者基于开源代码进行不断改进,降低使用该工具的学习成本,最终使得有一定相关知识基础的人便可以熟练运用Deepfakes工具。
文中第二部分对面向图像视频的AI篡改技术基本原理进行介绍,第三部分对AI篡改技术所使用神经网络的分类及衡量指标进行介绍,第四部分对常用的AI篡改工具进行介绍,第五部分对训练深度学习网络的数据集分类及特点进行介绍,第六部分和第七部分对AI篡改技术存在的问题、带来的影响及应对措施进行讨论,从而为AI篡改与检测的相关工作提供参考并为未来的研究方向提供思路。
2 AI篡改实现基本原理
根据篡改媒体对象的不同,AI篡改可以分为对单帧图像的篡改、对多帧视频的篡改及对音频的篡改。其中对图像视频的篡改,按照篡改内容和方法上的不同具体可以分为5种:人物面部生成式篡改、人物面部替换式篡改、人物面部驱动式篡改、对于物品的篡改、对于图像视频整体画面风格的篡改。其中人物面部生成式篡改是生成现实生活中不存在的人物面部;人物面部替换式篡改是使目标图像视频与源图像视频中的人物面部相互替换,从而达到人物身份篡改的目的;人物面部驱动式篡改是使目标人物面部的表情或动作去驱动源人物面部的表情动作,从而达到改变源人物面部表情或动作的目的;对于物品的篡改是删除或增加图像视频中人物携带的物品或衣物等;对于图像视频的整体画面风格的篡改是改变画面的表现风格,如将普通的风景图像改变为油画、水彩画风格,或改变风景所处的季节等。
AI篡改技术最初使用自动编码器-解码器模型。此模型在训练阶段使两个自动编码器共享参数形成一个通用的编码器并分别对两个数据集进行编码,使得通用编码器获得两个数据集中人物面部的特征[3]。在测试和解码阶段交换解码器对两人物的面部特征进行解码从而完成对人物面部的篡改。例如使解码器B对通用编码器编码的面部A特征进行解码,即可完成对于人物A的面部篡改。其篡改流程图如图2所示。
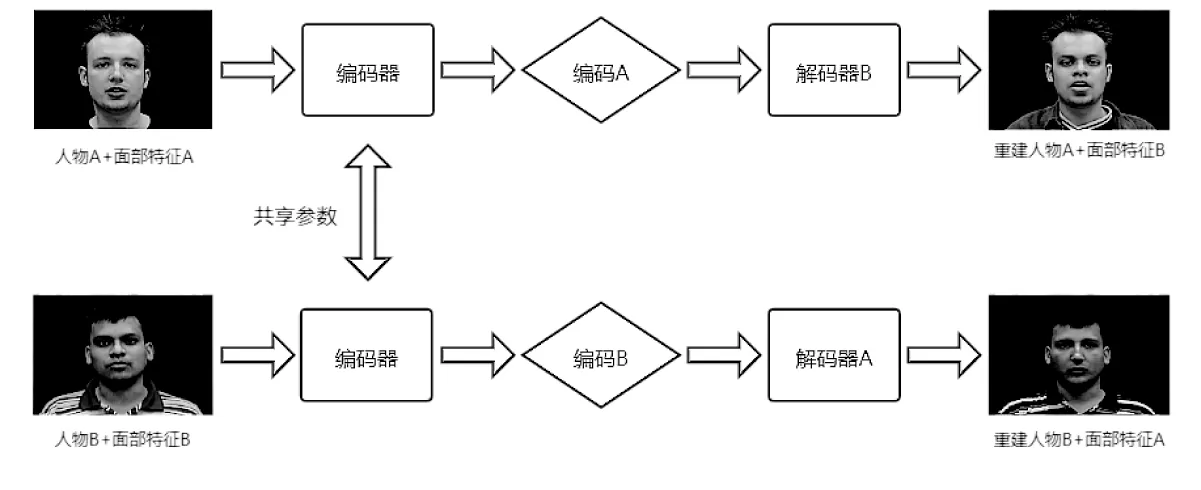
图2 AI篡改流程图
编码器-解码器模型最初被应用于解决seq2seq问题,如机器翻译、问题匹配系统、智能对话系统等。Bahdanau D等人[4]发现该模型在处理问题时存在一定的局限性,即编码器在进行语义特征提取时会将所提取到的信息压缩到一个固定长度的向量中,而随着提取到的信息越多会对已提取到的信息进行覆盖。这会使编码器提取到信息因压缩或被覆盖而不完整,从而丢失有效信息,最终导致解码器对编码信息进行解码时的效果不理想,编码器-解码器模型在处理面对图像和视频的AI篡改问题时所遇到的相类似问题。为解决类似问题,并不断改进AI篡改效果,加强篡改的逼真程度,由卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和生成式对抗网络(Generative Adversarial Networks,GAN)混合而成的AI篡改模型相继出现。
3 实现AI篡改的神经网络
3.1 卷积神经网络
CNN是常用的深度学习神经网络之一,常被应用于目标检测、图像分类、图像分割[5]、图像重建[6]等任务中。一般由一个或多个卷积层、池化层、全连接层交替排列组成。卷积层包含多个卷积核,卷积核中的神经元与前一层中的神经元相连接,在前一层的特征图上滑动进行卷积运算,提取输入数据的特征。池化层的应用可以去除网络模型中的冗余信息,降低网络的复杂程度,有效减少参数量,从而提高计算速度同时防止过拟合的情况出现。上述可以通过多种池化操作实现,例如最大值池化、均值池化、随机池化、重叠池化、中值池化,组合池化、空金字塔池化等。其中最大值池化操作可以更好的保留图像的纹理信息,均值池化操作可以更好的保留图像的背景信息,而随机池化操作会使不同的随机设置得到不同的池化结果,无法人为预估池化对于图像的影响。在卷积层和池化层后会有一个或多个全连接层,全连接层的神经元与前一层的所有神经元进行全连接[7],对到达全连接层的特征信息进行分类整合。
3.2 循环神经网络
RNN的内部之间存在自连接,一般由输入层、隐藏层和输出层组成[8]。RNN经常被应用于语言建模、机器翻译、语音识别[9]和篡改视频检测[10]等领域当中。其与CNN相比CNN的信息输入与输出之间是相互独立的,是根据输入信息和大量数据集训练来进行信息的输出,而RNN是非独立的,每一个输出信息都受到输入及前一个输出信息的影响。
3.3 生成式对抗网络
GAN是无监督式的深度学习神经网络,在图像生成、图像修复[11]、提高图像分辨率[12]及图像风格迁移等领域中都有较为广泛的应用。GAN最初于2014年由Goodfellow J等人提出[13],其特点在于使用两种模型,分别为生成模型和鉴别模型通过对抗机制进行迭代和训练,从而摆脱人工监督。近年来因其具有对抗式的网络结构而流行于AI篡改领域中。GAN的对抗式网络框架由鉴别模型和生成模型两部分组成,首先对原始图像和随机噪声进行采样,并将采样数据作为训练数据输入鉴别模型中进行训练。而生成模型通过随机噪声生成图像样本,由鉴别模型对生成的图像样本是否来自于训练数据进行评估,并根据评估的可能性给出分数反馈于生成模型。生成模型再结合反馈数据与随机噪声,重新生成图像样本由鉴别模型评估,鉴别模型通过再次进行分数评估并反馈给生成模型。二者所组成的对抗式网络通过不断对抗与迭代,并最终达到收敛,使最终生成模型所生成的图像可以达到以假乱真的效果,从而达到AI篡改的目的。GAN流程图如图3所示。
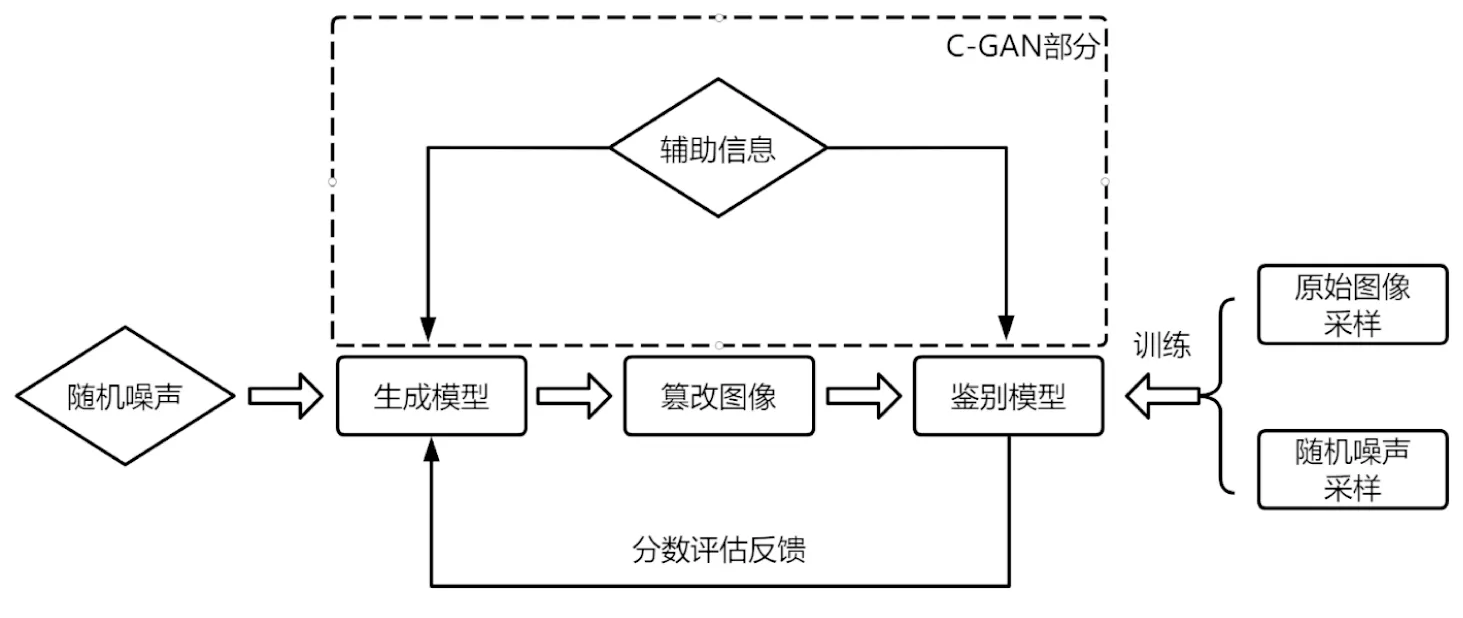
图3 GAN与C-GAN流程图
3.3.1 生成式对抗网络衡量指标
在GAN的训练过程中,需要对其表达能力进行衡量,从而更好的改进和优化GAN模型。不同的GAN模型具有不同的特性,同时衡量其表达能力也具有很强的主观性,所以采用不同的衡量指标可能得出不同的结果。因此,需要根据不同的衡量目的,采用适当的衡量指标对GAN模型的表达能力进行衡量。
(1)图像质量与类别衡量指标(InceptionScore, IS)。IS利用Inception网络将GAN生成图像的清晰程度与生成图像类别的多样化程度作为两个评价指标,并以此来比较不同GAN模型的表达能力[14]2232。在评价生成图像的清晰程度指标时,IS通过计算图像的熵值来衡量图像的清晰程度。首先将每一幅生成图像输入于Inception Net-V3分类网络中,分类网络会对每一个输入的图像相应的输出一个1000维的向量标签,向量标签每个维度对应的值代表此图像属于某一类图像的概率。如果一幅清晰的图像属于某一类图像的概率很大,则属于其他类图像的概率很小,那么此图片的熵值越小,相反则熵值越大。在评价生成图像类别的多样性程度指标时,IS通过计算图像类别的熵值来衡量生成图像的多样性程度。如果生成模型生成图像的多样性程度足够高,那么所生成的图像在所有图像类别中应趋近均匀分布。图像在所有图像类别中越趋近于均匀分布,则图像类别的熵值越大,生成图像类别的多样化程度也越高,反之则熵值越小,多样化程度也越低。在对表达能力较强的生成模型评估IS分数时,IS分数较高。其局限在于在评估的过程中不能判断出是否出现了过拟合问题,泛化性能差,并且评估的分数对于选取的训练数据集图像过于敏感,受其影响较大,不适合在图像差异较大的训练数据集中使用。其定义如公式(1)[14]2229所示:
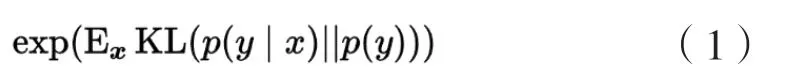
(2)图像类别分布概率衡量指标(Mode Score,MS)。MS是 IS经过改进后的衡量指标[15]6,除了将生成图像的清晰程度与生成图像类别的多样化程度作为衡量指标外,还将生成图像类别的概率分布与训练数据集图像类别的概率分布纳入衡量范围内,并以此来衡量GAN模型的表达能力。如果对表达能力较强的GAN模型进行MS分数评估,则MS的评估分数较高。生成图像类别较高即趋近于均匀分布的同时生成图像类别也要与训练数据集图像类别的概率分布足够接近。其定义如公式(2)[15]5所示:
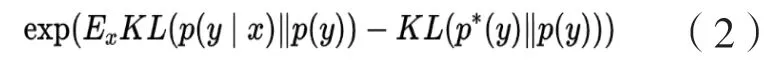
(3)弗雷歇距离衡量指标(Fréchet Inception Distance,FID)。FID通过计算生成图像与训练数据集图像之间在特征层面的距离,并以此距离作为指标来衡量GAN模型的表达能力。首先分别将生成图像与训练数据集图像输入InceptionV3分类网络中,分类网络会相应的输出2048维的向量,并分别对其估计高斯分布的均值和,并通过和分别得到协方差和,最后根据得出的数据计算Fréchet distance(弗雷歇距离)即FID的值[16]450-451。FID在衡量GAN表达能力时对于图像中的噪声有较强的抗干扰性,判断相较于IS评价指标来说较为准确。在对表达能力较强的GAN模型评估FID分数时,FID分数较低。其定义如公式(3)[16]451:
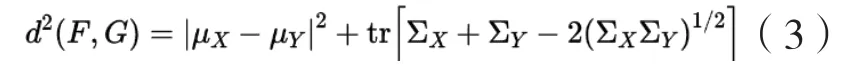
(4)最近邻域分类衡量指标(1-Nearest Neighbor Classifier,1-NN)。1-NN分类器通过比较训练数据集图像分布与生成图像分布,并计算1-NN分类器的LOO(leave-one-out)准确率,并以此作为指标衡量GAN模型的表达能力。如公式(4)所示,从训练数据集中采样得到,并将其标记为正样本,从生成图像中采集得到,并将其标记为负样本。并将1-NN分类器在两个样本图像数据集与进行训练。在对表达能力较强的GAN模型评估1-NN分数时,||=||且LOO准确率约为50%。特点在于,该方法可以检测出GAN模型的过拟合问题,当LOO准确率低于50%时,则说明模型存在过拟合问题。
(5)推土机距离衡量指标(Wasserstein Distance,WD)。WD通过引入两个概率分布之间距离的量,从而可以比较生成图像分布与训练数据集图像分布之间的相似程度,并以此作为指标衡量GAN模型的表达能力。WD又称earth-mover距离或推土机距离,与KL散度相比WD可以衡量任意两个概率分布之间的距离,从而判断两概率分布之间的相似程度[17]216。在对表达能力较强的GAN模型评估WD分数时,其分数较低。
(6)Kernel Maximum Mean Discrepancy(KMMD)。KMMD是在Reproducing Kernel Hilbert Space (希尔伯特空间)内,通过选择一个核函数,通过核函数将生成图像与训练数据图像映射到希尔伯特空间[18]514,以较小的计算代价比较图像间分布差异,并以此作为指标衡量GAN模型的表达能力。在对表达能力较强的GAN模型评估KMMD分数时,其分数较低。其定义如公式(5)[18]516:

3.3.2 生成式对抗网络的分类
GAN同样存在一些局限性,例如由于生成模型和鉴别模型对抗训练所使用的无监督模式和初始随机噪声的不可控制性,容易导致训练过程困难、鉴别模型鉴别能力过强等问题。基于此,GAN衍生出了许多分支和模型,以应对上述类似各种问题。针对于图像和视频的AI篡改GAN模型有以下几种:
(1)Condition-GAN(C-GAN)。为了使GAN生成的图像可控制,C-GAN在给生成模型输入随机噪声的同时,添加辅助信息,给数据集打标签或是添加其他人为干预等操作。同时辅助信息也会被输入鉴别模型中进行辅助训练使鉴别模型做出更精准的判断。C-GAN流程图如3虚线部分所示。
(2)pix2pix与pix2pixHD。pix2pix是基于C-GAN实现图像到图像的篡改网络。pix2pix网络可以将一幅输入图像作为辅助信息输入进生成模型中进行约束[19],从而使生成模型生成的图像可控制。生成模型基于输入图像与随机噪声生成输出图像,即图像到图像的篡改。为使鉴别模型能够对输入图像和输出图像之间的关联性与差异性进行鉴别,在鉴别阶段需要同时提供成对的输入图像与输出图像。最终生成模型和鉴别模型基于输入图像与输出图像进行对抗和迭代。
pix2pixHD采用多尺度的生成与鉴别模型并采用不同的损失函数[20],从而提高pix2pix生成图像的分辨率,优化图像的质量,同时支持了用户交互,进一步提高了pix2pix网络对于生成图像的可控制性。
(3)CycleGAN。CycleGAN与pix2pix相似,但CycleGAN可以实现不成对的图像到图像的篡改,该方法通过对抗损失函数(adversarial loss)得到输入图像与原始图像之间的映射,并与其逆映射相结合,同时引入一个循环一致性损失函数 (cycle consistency loss)[21],最终实现不成对图像到图像的篡改。
(4) StarGAN。StarGAN模型将图像中的人物特征定义为不同属性,例如头发颜色、性别或年龄等,各属性具有不同的属性值,例如黑色、黄色、棕色为头发颜色属性的属性值,男性和女性为性别属性的属性值。在模型的训练与篡改中将共享相同属性值的一组图像称之为同一领域的图像。该模型借鉴CycleGAN的构造[22],其生成模型使用了2个卷积层,6个残差层和2个反卷积层,在生成图像时需要向生成模型中输入目标领域的信息,使鉴别模型在鉴别图像是否真实的同时,还需鉴别该图像的内容属于何种领域。保证生成模型在生成图像时,随着图像的目标类型不同而映射到不同的图像领域。pix2pix模型实现了成对图像到图像的篡改,CycleGAN实现了不成对图像到图像的篡改。此类模型都仅适用于同一领域的图像篡改,模型的泛化性较差。当此类模型对不同领域图像进行篡改时,则需要训练多个生成模型。StarGAN则可以对多类型图像进行篡改,使用统一的框架加以实现,进一步提高对于图像的篡改效率。
(5) StyleGAN和StyleGAN2。StyleGAN可以对图像中人物面部的细节信息进行收集和提取,例如面部表情、肤色、皱纹、发型、面部朝向等信息。StyleGAN在处理图像中的人物面部信息时,可以分成两个网络,映射网络和合成网络。映射网络将输入的隐藏变量转换成中间隐藏变量。合成网络将中间隐藏变量进行仿射变换,并将这种仿射变换和随机噪声输入进合成网络的所有子网络中,从而实现对生成图像中面部细节信息的控制[23]。StyleGAN2是StyleGAN的改进版本,通过重新设计并训练StyleGAN模型,修复了StyleGAN在生成图像时产生的伪影现象[24]。
(6)Wasserstein GAN。在GAN的训练中,为使生成模型与鉴别模型进行对抗与迭代并最终达到收敛,二者的生成能力与鉴别能力不可以相差过大,鉴别能力过强或过弱都会导致生成模型的训练进度缓慢[25]。为解决此类问题,Arjovsky M等人将Earth-Mover距离应用到GAN中[17]218,对GAN算法进行优化,使得在使用Wasserstein GAN时能更好的平衡两个模型的生成能力与鉴别能力,有效的提高训练速度。
(7)ProGAN。ProGAN模型可以提高生成图像的质量并且解决生成模型和鉴别模型由于不良竞争机制所导致的网络层中参数过大的问题。Karras T等人从生成和鉴别低分辨率图像入手[26]2,例如由生成模型生成4×4的图像,再由相应层数的鉴别模型进行鉴别,而后对生成模型添加一层网络层基于4×4的图像生成8×8的图像,并以此类推循序渐进的训练生成模型与鉴别模型,其训练流程如图4所示。该模型通过逐步增加新的网络层来优化图像的细节信息,使该模型生成的高质量图像更加稳定和迅速。同时,Karras T等人在每一个卷积层后将像素的特征向量归一化为生成模型的单位长度,以避免生成模型和鉴别模型之间差异过大的问题。
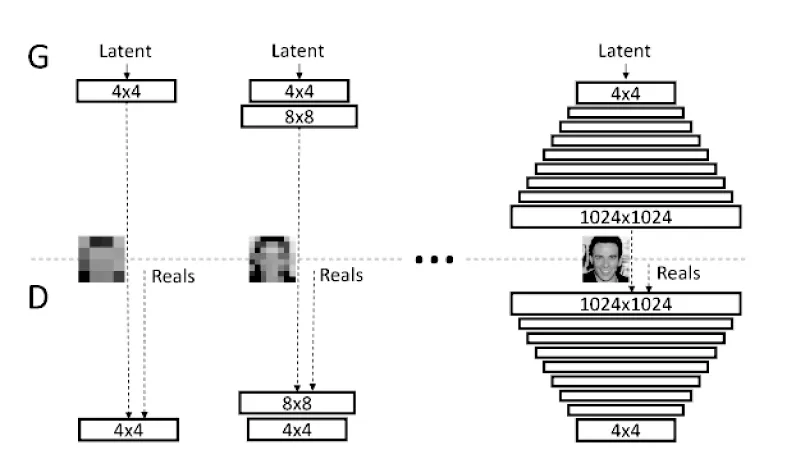
图4 ProGAN训练流程图[26]3
(8)BigGAN。在BigGAN模型中,Brock A等人采用IS(Inception Score)指标来衡量此模型的表现能力,IS指标有两种评判标准分别个体样本层面的生成图像质量和生成图像的多样程度。通过使用多种手段提高模型的表现能力,在图像质量和图像多样程度之间选择恰当的折中点,从而达到较高的IS分数。该模型将batch size提高为原来的8倍,增加网络的通道数,从而大幅度提高模型的表现能力,使IS分数分别提升了46%和21%[27]。但是加大batch size会降低模型的稳定性,导致模型生成图像的多样性降低,即模型崩塌。在GAN中随机噪声仅仅输入生成模型的第一层中,而在BigGAN中使用了多层级潜在空间,将随机噪声输入进生成模型的多个层,并使用层共享嵌入的方法减少计算量和内存占用,使得该模型的训练速度和模型表现都有所提升。同时该模型使用一种“截断技巧”,使采样点在一个阈值范围以内,以降低生成图像多样性为代价,提升图像的质量,这种截断技巧就是在生成图像的多样性和质量之间找到恰当的折中点,从而提高IS分数。
(9)GauGAN。GauGAN模型可以通过一幅语义图生成一幅与该语义图相对应的图像[28]。GauGAN模型在训练阶段使用编码器从输入图像中获取与图像分布有关的均值、方差和高斯分布,再将其三者产生的向量进行反归一化操作,得到包含输入图像信息的随机向量。再将产生的随机向量输入进生成模型中,并在生成图像的过程中使用输入图像的语义图增强语义信息。最后生成模型与鉴别模型进行对抗、迭代、收敛。GauGAN模型的特点在于生成模型使用SPADE模块,能够有效地弥补语义信息的丢失,使得生成的图像更加逼真。
4 实现AI篡改的常用工具
4.1 Faceswap和Faceswap-GAN
Faceswap和Faceswap-GAN篡改工具目前在GitHub网站上开源,其中Faceswap篡改工具是基于自动编码器-解码器网络制作而成。使用两组编码器-解码器,并使两个编码器共享参数。Faceswap-GAN篡改工具应用不同的损失函数和预测注意力掩膜以提高模型的表现能力。其中对抗损失函数可以提高图像解码和重建阶段的图像质量。感知损失函数可以在训练阶段优化人物眼部细节,使目标人物眼睛的转动与源人物眼睛转动更吻合,达到目标人物面部更加逼真的效果。预测注意力掩膜可以辅助消除因面部遮挡和伪影所带来的影响,并使篡改后的目标人物肤色更加自然。
4.2 Deepfacelab
Deepfacelab是GitHub网站上关于AI篡改的一类开源工具,其工作过程可以分为提取、训练和转换。在提取部分首先对图像中人物面部进行定位,对面部定位的关键点进行检测和对齐,最后形成一个掩膜进行图像中面部的分割。在训练部分该工具使用了较新颖的LIAE结构网络,在LIAE网络中解码器可以更好的解码图像。在转换部分将解码器重新生成的面部与提取部分的掩膜进行对齐和融合。最后将篡改后的图像进行适当的锐化,以优化图像质量。
4.3 Transformable Bottleneck Networks(TBNs)
TBNs是是GitHub网站上关于AI篡改的一类开源工具,该篡改工具基于CNN[29]制作,其架构包含2D-3D编码器,重采样层和3D-2D解码器网络。该网络可以通过CNN对一幅或多幅图像中的3D内容进行编码,将其转换为包含坐标信息的图像并进行聚合,最后进行解码从而完成对3D模型可控制的3D精细化操作和3D模型重建。该网络不同于原有3D转换的网络,原有的3D转换网络需要人为将空间转换的向量参数输入与网络中,并利用解码器执行,而该网络则直接将图像中的3D变换应用于网络中,使该网络能够学习原图像和目标图像之间的3D变换,从而推断出图像中3D内容的空间结构,完成可控制的3D精细化操作。同时,该网络可以对具有多个视角的图像数据集训练,推断出图像内容的空间结构,从而实现更加灵活的NVS(novel view synthesis),即不同视角下的图像合成或变换。
4.4 Few-shot face translation
Few-shot face translation是一类基于GAN制作而成的AI篡改工具,其特点在于该工具使用了预训练模型,并且包含了SPADE和ADaIN[30]模块。该工具可以根据所提供源面部的注视方向、佩戴饰物,生成与其一致的人物面部图像,但该工具在篡改具有亚洲面部特征的图像时效果欠佳。
4.5 StyleRig
StyleRig是基于StyleGAN制作而成的AI篡改工具。StyleGAN可以生成许多逼真的篡改图像,但却无法很好的处理图像中3D语义信息,如场景的光照信息、面部表情信息、姿态信息等[31]。而3DMM(3D Morphable Models)可以控制3D语义信息,但是其渲染的人物面部3D建模缺乏细节信息,例如嘴巴内部、背景等,导致整体效果不真实[32]。StyleRig将3DMM与GAN结合起来,先使用StyleGAN生成逼真的人物面部图像,再使用3DMM对图像的3D语义参数进行控制,二者形成互补解决了StyleGAN处理3D信息困难的问题。
4.6 Auto-painter
Auto-painter是一个基于Condition-GAN所制作的AI篡改工具[33]。该工具通过数据集训练后,可以对黑白卡通图像进行着色操作。即该工具可以根据一幅黑白草图,输出一幅相同分辨率的彩色图像。Auto-painter在训练生成模型时使用了多种损失函数,例如使用total variance loss通过像素点与邻域像素点灰度值之差的平方来衡量图像的平滑性;使用特征损失函数(Feature loss)或是感知特征函数(Perceptual Losses),通过获取输出特征图,来提取比较图像中的特征或差异;使用Pixel Loss来计算和预测目标图像的像素间损失。
4.7 FaceShifter
FaceShifter由两部分结构组成[34],第一部分通过AEINet(Adaptive Embedding Integration Network)提取原图像中人物面部身份特征和面部表情等属性特征,并利用AAD(Adaptive Attentional Denormalization Generator)将提取到的身份特征与属性特征进行融合,从而实现原图像中人物与目标图像中人物面部的高精度替换。第二部分主要解决了图像中人物面部的遮挡问题,通过原图像与目标图像的差值区别作为线索,对人物面部遮挡进行感知,并利HEARNet(Heuristic Error Acknowledging Refinement Network)丰富生成图像的细节,该方法在可以对图像中由于人物面部遮挡所产生的异常现象进行修复。
5 数据集
由于AI篡改根据篡改的对象和方法可以分为5种,针对于5种AI篡改种类所使用的算法模型,其训练所需的数据集可能各不相同。各数据集所包含的数据量、数据类型、获取方式等特点也都有所不同。
5.1 Flickr-Faces-HQ
FFHQ数据集是一个高质量的人物面部图像数据集,该数据集中包含的人物面部图像多样化程度高,曾被应用于StyleGAN模型的训练中,由英伟达公司开发并于2019年开源。其中包含了70000张分辨率为1024×1024的PNG格式面部图像[35]。
5.2 UADFV
UADFV[36]数据集建立的时间较早,包含49个来自YouTube的真实视频,使用Fakeapp将视频中的人物面部与著名演员尼古拉斯凯奇的面部进行替换,形成49个AI篡改视频。每个视频时长大约11秒,所有视频共32752帧。
5.3 Deepfake-TIMIT
Deepfake-TIMIT数据集共有640个经过AI篡改的视频,其中有320个低质量视频和320个高质量视频。该数据集是由Korshunov P等人开发,研究人员使用VidTIMIT数据集并基于其中的16个对象,对每个对象10个视频共160个视频分别使用两种不同的GAN模型对其进行AI篡改,并保留了低质量图像和高质量图像两种。其中低质量图像分辨率为64×64,高质量图像分辨率为128×128。
5.4 FaceForensics
FaceForensics数据集由Rossler A等人开发,数据来自于YouTube网站,其中包含了两个小数据集,每个小数据集包含1004个视频。其中第一个数据集使用Face2Face方法在两个随机选中的视频进行人物面部驱动式篡改。第二个数据集则进行人物面部生成式篡改。每个小数据集都使用了704个视频进行训练,150个视频进行验证,150个视频进行测试。
5.5 FaceForensics++
FaceForensics++作为FaceForensics的改进版本数据集,是当前最流行的数据集之一,FaceForensics++以509914张图片和1000个真实视频作为原始数据,并分别使用Face2Face、FaceSwap、Deepfake、NeuralTextures对数据集进行AI篡改[37]。在视频输出时为了模拟社交网络对视频进行的处理,输出视频使用H.264进行视频编码,并分别压缩成高质量视频和低质量视频。其中高质量视频的量化参数为23,低质量视频量化参数为40。
5.6 CelebA
CelebA(CelebFaces Attribute)是人物面部属性数据集的缩写,由香港中文大学开发,并于2016年开源。该数据集包含10177名人物的202599张人物面部图像,分为118165张女性面部图像和138704张男性面部图像,且每张图像都具有特征标识(人物面部标注框、人物面部特征点坐标、人物面部属性标识)。
5.7 Celeb-DF V1
Celeb-DF V1数据集由Li Y等人开发,该数据集拥有高质量的篡改视频,以便更好的评估AI篡改的检测方法,并支持AI篡改检测方法的开发。该数据集包含了408个收集于YouTube网站的真实视频和795个使用deepfake进行AI篡改的视频。每个视频有13秒的时常和30帧率。
5.8 Celeb-DF V2
Celeb-DF V2数据集是V1数据集的改进版本,V2数据集在视频数量上有了大幅度增加,其中包含收集与YouTube网站的真实视频590个,以及5639个经过篡改的虚假视频[38]。
5.9 DFDC
DFDC数据集是由一线互联网公司与研究机构为举办DeepFake Detection Chanllenge(DFDC)假脸识别挑战赛而开发,其中包含3426名对象,48190个原始真实视频。该数据集与其他数据集不同的地方在于其他数据集的视频收集多来自于网络,而该数据集是由摄像机实际拍摄而成。该训练集使用多种主流的AI篡改方法对于原始真实视频进行篡改,最后生成119154个时长为10秒的视频用于训练,4000个时长为10秒的视频用于验证,10000个时长为10秒的视频用于测试。该数据集真假样本的比例大约为1:5,并且5%~10%的视频会同时出现两个人物,参与拍摄制作该数据集的演员性别、种族、年龄都接近均匀分布。
5.10 CIFAR-10
CIFAR-10是一个小型数据集,该数据集分为10个类别,每个类别中包含6000张图像共计60000张图片,训练集分为5个训练组和1个测试组,每组包含10000张图像。每一幅图像都是完整的3通道的彩色RGB图像,图像尺寸为32×32。
5.11 FakeAVCeleb
FakeAVCeleb是由Khalid H等人开发的数据集,该数据集中包含4个不同种类的音视频数据样本,分别是原始视频和原始音频相匹配样本、篡改视频与原始音频相匹配样本、原始视频与篡改音频相匹配样本、篡改视频与篡改音频想匹配样本,其中第一种类包含500个样本,第二种类包含9000个样本,第三个种类包含500个样本,第四个种类包含10000个样本。
6 AI篡改技术的问题与展望
6.1 AI篡改技术的影响
在网络技术完善的今天,自媒体行业的快速发展,使信息传播速度快,范围广。随着AI篡改技术的学习成本逐渐降低,技术实现更加容易。有危害性的AI篡改图像视频的产生与传播速度也会加快,不仅会使公民的个人隐私和权利受到侵害,也会对社会知名人士和政治领袖产生舆论的负面影响,从而对社会治理和国家安全造成影响。在国家的司法领域中,由于先进的AI篡改模型篡改的图像和视频使用传统鉴别技术很难区分真假,提高了公安机关在执法办案的过程中证据收集与处理案件的难度,也导致了视听资料证据对于案件的法律证明力下降甚至不再具备法律证明力。在我国的金融领域,部分ATM机取款,购物支付和手机转账,使用面部识别认证系统,而AI篡改技术可以通过对面部的篡改进行身份顶替,从而给应用面部识别认证系统的金融服务领带来挑战。
6.2 存在问题
AI篡改模型中的神经网络进行深度学习需要大量数据进行训练验证和测试,这些数据集包含真实的和经过AI篡改的图像视频,目前大部分数据集内容繁杂且标准不一,也存在个人肖像权及隐私侵犯问题。神经网络的训练与测试需要较高的硬件规格,虽然在一定程度上提高了实现AI篡改的门槛,但随着相关算法的不断优化与改进,会逐渐降低对于计算机硬件算力的要求,同时个人计算终端算力的不断提升,云计算服务的提出,都在使AI篡改技术不断走向便捷化、大众化。
6.3 政策层面的应对措施
为应对AI篡改相关技术对个人,社会和国家产生的不良影响,在全球范围视角下,例如美国、英国及欧盟纷纷推动关于AI篡改相关的立法工作。仅仅2018年至2019年一年时间,美国便颁布数条法案,其中《2018年恶意伪造禁令法案》,其中将“deep fake”定义为“以某种方式使合理的观察者错误地将其视为个人真实言语或行为的真实记录的方式创建或更改的视听记录”。除此之外,还包括制定使用AI篡改技术规范,在法律层面明确“数字内容伪造”的定义,对利用AI篡改技术进行不法行为进行量刑,并且鼓励开展对于AI篡改技术检测与鉴别的相关活动,举办相关技术竞赛,努力使此项技术走向商业化等。在国内的视角下,我国也在努力推进立法和保障工作,从而限制AI篡改技术所带来的不良影响。2017年6月,我国首部有关网络安全的法律《网络安全法》正式实施。2019年,在民法典中对“AI换脸”等科研活动和试验及个人信息保护等问题做出了规范。同年,《网络音视频信息服务管理规定》对网络音视频服务相关的从业者和消费者做出规范,即利用基于深度学习、虚拟现实等技术与应用进行制作传播非真实的音视频信息时,应开展安全评估并进行标识。随着我国相关法律法规的出台,实现了从法律层面维护网络安全的从无到有,对保护国家网络安全奠定了重要基础,也为公民隐私及相关权利提供有力的保障。将可能被用于制作AI篡改相关内容的公民图像或视频等个人数据置于法律保护之下,并通过法律法规,对互联网软件公司发布的换脸软件产品以及各类社交媒体平台的传播所可能引发的个人隐私泄露问题加以遏制。但是,我们对于完善法律法规的工作仍应不断完善和改进,对数字内容的伪造行为在法律层面做出定义,并根据所导致的后果严重程度制定相应的惩罚机制。通过举办AI篡改检测技术相关技术竞赛与交流会议,鼓励AI篡改检测技术相关的应用与研究健康发展。同时对相关的社交平台或搜索平台进行治理,加大针以深度伪造为代表的AI篡改音视频文件的管控力度,对于有危害社会可能的AI篡改图像和视频进行严厉打击。但是,我们也应该注意,AI篡改技术是人工智能和神经网络深度学习的附属产品,也是未来影视游戏制作,助力文化传播的关键性技术,我们在谨慎对待防止其危害出现的同时,仍应鼓励其健康发展。
6.4 技术层面的应对措施
为了遏制AI篡改所带来的消极影响,众多先进的篡改防御方法基于深度学习的AI技术。其主要分为被动式防御和主动式防御,被动式防御聚焦于图像视频在篡改过程中形成的代表性特点,例如Li Y等人[39]提出由于部分算法生成的人物面部分辨率与原始视频分辨率不相同,以及在面部匹配过程中进行的仿射变换所导致的伪影现象,该方法通过捕捉并检测视频中伪影的存在来判断视频是否经过AI篡改。Li L等人[40]提出一幅完整的原始图像特征是平均且相同的,不同图像具有不同的特征,而篡改的过程必定会破坏原始图像的特征从而形成边界,通过捕捉和检测图像中的边界来判断图像是否经过AI篡改。主动式防御聚焦于图像视频的数据溯源,以及通过对原始图像视频加入扰动的方法来增加AI篡改的阻碍。例如Wang R等人提出通过编码-解码器模型DeepTag在图像中嵌入UID信息,通过UID信息的完整性对图像进行溯源,从而判断图像是否经过AI篡改。Huang Q等人[41]提出在保持视觉效果一致的情况下通过对原始图像中人物面部进行毒化处理,使得AI篡改的输出图像受到污染,从而在视觉层面上形成明显的区别,从而达到AI篡改的预防目的。
7 结语
AI篡改技术与篡改防御技术之间的竞争不是平衡的,AI篡改技术从诞生发展至今,由于影视拍摄和游戏制作等娱乐项目的快速发展,对于深度学习网络和相关图像视频处理技术有着更高的要求,也必然使基于深度学习网络的AI篡改技术发展迅速。而AI篡改防御技术因需求较低,导致AI篡改防御技术始终落后于篡改技术。篡改防御技术大多是因一种或一类篡改技术而形成的,易导致泛化性不足等问题,因此针对先进的篡改模型仍然未有完全准确且稳定的识别方案。在公安工作中,应同时注重AI篡改的主动式防御与被动式防御,形成能够在篡改前预防,篡改后溯源并且稳定检测其真伪性的工作形式。但仍需注意的是,虽然AI篡改防御技术的训练发展依赖于大量的图像和视频数据,而面对网络中爆炸式增长的数据量,其收集和整理的方法、各类数据之间的关联程度、是否具有时效性[42]等因素也同样重要,稍有纰漏便可能引起巨大的偏差,造成公安机关对于案情产生错误判断的严重后果。日益发展的AI篡改技术,将越来越难以识别和检测,这必然会在个人和社会层面导致不同程度的问题,如何应对并解决由于AI篡改技术所导致的问题,维护合法权益,是当代各领域学者需要应对的挑战。因此在未来一段时间里,我们将继续对于AI篡改防御技术的研究现状进行挖掘和总结并形成文章,为后续研究人员推动和发展AI篡改防御技术提供参考。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
小天使·三年级语数英综合(2022年4期)2022-04-28
汽车工程师(2021年12期)2022-01-18
现代仪器与医疗(2021年4期)2021-11-05
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
汽车导报(2017年5期)2017-08-03
高中生学习·高三版(2017年4期)2017-04-14
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
