
基于鼠标事件的虚拟仿真实验中学习状态评价模型研究
2022-10-10 01:23刘志勇王淑贤
软件工程 2022年10期
刘志勇,王淑贤
(东北师范大学信息科学与技术学院,吉林 长春 130117)
1 引言(Introduction)
近年来,虚拟仿真实验为学习者带来一种崭新的实验方式,突破了传统实验中时间与空间的约束,并且解决了由于实验环境及设备的限制造成的实践性缺乏、实验培养效果不理想等问题。然而,虚拟仿真实验中时空分离的教与学的方式,使教学者对学习者实验时的学习状态知之甚少,仅可通过了解实验者的实验结果来进行评价,缺少了对实验的过程性评价,显然具有一定的片面性和局限性。即使有教师实时参与的实验的过程性评价,由于缺少数据支撑,教师的即时性诊断仍然偏于经验分析和定性分析。
很多学者致力于研究在线学习环境下的学习状态评价模型,它能够根据学习过程中的实验操作数据对学习状态做出评价。黄涛等指出,信息技术的发展,使得传统教育评价机制向数据驱动的精准化学习评价方向迈进,分析多模态的数据更加有利于发现教育中的问题。王蓓蓓等从大数据的视角,对大数据应用于学习过程评价进行了特征分析,探究了学习过程错题个性化推送,学生过程行为评价的应用模式等。可见,在线学习环境中,信息技术手段赋能学习分析,可以大大提高评价的全面性与科学性,也有助于教育者对后续课程安排的调整,有效提高教学质量。学习者学习状态评价最常用的方法有两种,一种是基于生理信号的方法,比如脑电图、心电图等,需要借助专用的传感设备;另一种是基于非生理信号的方法,比如面部表情、眼动、手势、身体动作等。郑茜元等提出了基于循环神经网络(Recurrent Neural Network,RNN)的眼动分析算法,判定学生注意力情况。还有一种较为流行的方案是利用Kinect体感数据对学习者学习过程中的姿态识别,进而判断学习者的状态,以实现学习过程的监测。基于生理信号采集数据的方式存在设备佩戴烦琐从而影响学习者等问题,基于非生理信号的方式又可能造成隐私泄漏,并且获取到的数据不够准确、客观,难以真实全面地反映学习状态。利用鼠标事件实现学习者学习状态评价是一个比较新颖的研究方向。美国杨百翰大学曾提出仅根据鼠标的运动方向来评估使用者的情绪状态,该研究发现,学习者的情绪状态影响鼠标运动的方式,而鼠标事件也能够反映出使用者的情绪状态。
本文以虚拟仿真环境下的初中物理电学实验为研究对象,以鼠标事件与学习状态的相关性作为理论基础,提出了一种基于鼠标事件分析的学习者学习状态评价模型。该模型分类能力较强,且扩展性较好,运行也非常稳定。
2 数据的获取(Data collection)
采集学习者实验过程中的鼠标事件,将其作为原始的数据样本。选定的志愿者群体为初中学生,共征集了943 名初中在读学生参与了数据的收集,每人完成七个物理实验,完成过程中初中物理老师对数据进行人工标记。
在对志愿者实验结果进行筛选后,剔除了没有进行实际实验操作的数据,最后得到897 名志愿者的有效数据,共计4,485 条。
以初中物理虚拟仿真实验软件“吃掉物理”中电学的七个实验为例,将实验界面进行分区,分为实验操作区与非实验操作区。实验操作区分为实验操作区域与实验器材区域,非实验操作区为除此之外的其他区域。从实验开始时启动对学习者的鼠标事件的收集工作。
鼠标事件数据要尽可能全面地反映实验者实验的全过程。所以从实验开始每隔1 s收集一次鼠标事件信息,收集的主要信息包括鼠标位置坐标、时间戳、鼠标所在区域、移动的距离、移动的角度、鼠标点击的次数、鼠标滚动的次数等。
数据的收集原理是将设计好的鼠标获取工具嵌入到虚拟仿真实验的操作界面。当学习者进行实验时,对学习者的鼠标事件数据进行收集,然后将收集到的数据上传处理,最后经过处理得到实验所需要的特征。
鼠标事件获取工具基于JavaScript设计与实现,主要利用了一些经典的鼠标驱动事件。在这些鼠标驱动事件中添加脚本,就可以获取鼠标的横纵坐标,再叠加鼠标当前滚动的横纵距离就可以得到鼠标当前所在的位置。获取到原始数据后,从原始数据中提取了16 个特征,人工处理后形成数据表。部分字段及数据如表1所示,数据集信息如表2所示。

表1 部分实验数据Tab.1 Some experimental data
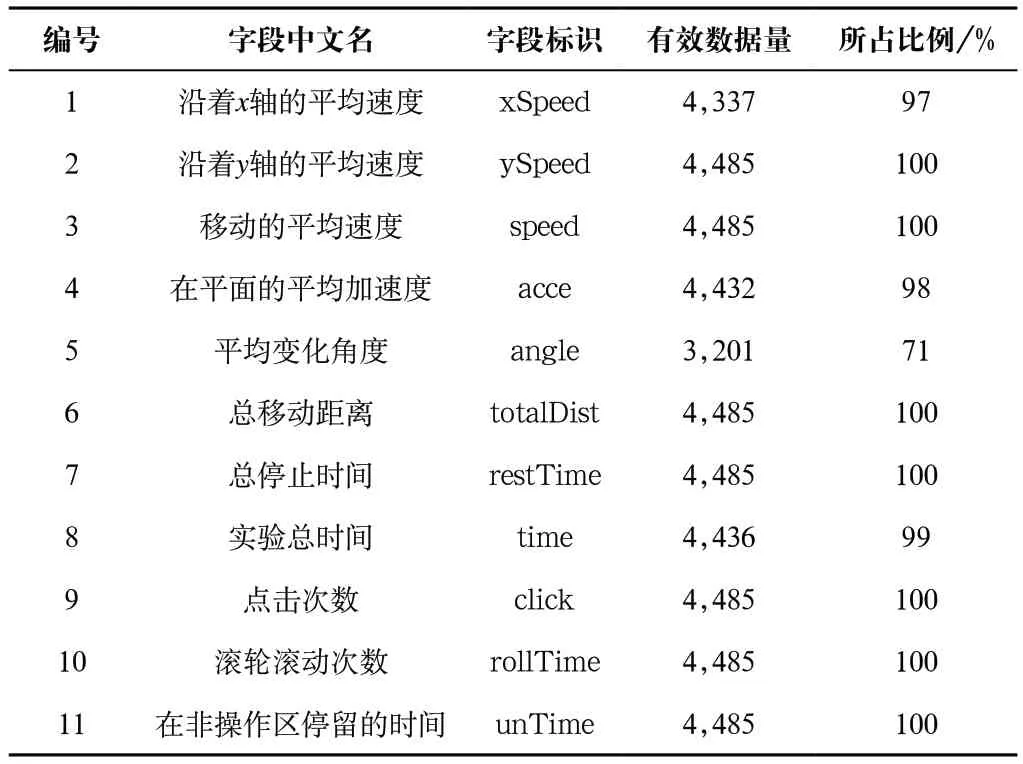
表2 数据集信息Tab.2 Dataset information
3 评价模型的构建(Evaluation model construction)
评价模型的构建过程中,首先分析了实验对象和内容——初中物理电学实验,并根据各个物理实验所涵盖的知识点的不同进行划分。其次通过不同的降维方法与回归方法分别进行实验,分析得出其共性与个性。在这些基础上,聚焦实验完成的过程以及实验中各知识点的细节,构建了基于HMM的融合时序因素的学习状态评价模型,并分析问题与不足,针对HMM模型分类能力较弱的特点,采用引入SVM的方式,构建了一种结构松散相对独立的混合模型。
3.1 实验内容的选择与分析
实验教学是培养创新思维的重要方式,初中时期是学生刚接触实验教学的时期,这个时期的实验教学对于学生的创新能力有很好的启蒙作用。其中电学实验覆盖面广,知识点丰富,因此选择初中物理电学实验作为研究对象。
根据《义务教育物理课程标准》中要求的“初中物理学生必做的20 个分组实验”,其中电学共有七个实验,分别如下所述。
(1)探究电流与电压、电阻的关系;
(2)探究通电螺线管外部磁场的方向;
(3)探究导体在磁场中运动时产生感应电流的条件;
(4)用电流表测量电流;
(5)用电压表测量电压;
(6)测量小灯泡电功率;
(7)连接简单的串联电路和并联电路。
通过分析七个实验涵盖的实验内容和各自的操作要点可以发现,物理实验1、6可以涵盖物理实验4、5、7的实验内容及操作,于是将物理实验1、6作为主体实验。根据物理教学要求,在主体实验中提炼出五个知识点:电流表、电压表、滑动变阻器、串联、并联。
在完成实验过程中采集的数据主要有鼠标运动的平均速度、加速度、角度及时间等,主要目的是对学习者完成实验时的整个过程建模,通过各知识点操作采集的时间序列性的数据也可以对实验进行知识点的评价。为了具体分析知识点操作情况,将各知识点的学习状态分为正常与非正常,如表3所示。

表3 知识点状态及编号说明Tab.3 Learning status and number of knowledge points
学习状态评价中使用全部七个物理实验,评价结果有优、中、差三级。通过研究覆盖面较广的主体实验可为实验者反馈需要重点关注的知识点,便于后续的学习。
3.2 数据降维及回归
数据特征的好坏与模型的效果直接相关,数据的降维对模型的构建及训练都至关重要。我们采用了较为经典的三种降维方法,即随机森林算法、主成分分析法、卡方检验法对特征进行降维。合适的评价方法可以提高评价的准确性,我们选择了评价方法中较为经典的BP(Back Propagation)神经网络、RBF(Radial Basis Function)神经网络、支持向量机与最小二乘向量机。结合这些方法,得出各个物理实验适用的数据维度及回归方法。
实验结果:物理实验1采用支持向量机与卡方检验法得出的实验结果最优;物理实验2采用反向传播神经网络与卡方检验法得出的实验结果最优;物理实验3采用反向传播神经网络与随机森林法得出的实验结果最优;物理实验4采用支持向量机与卡方检验法得出的实验结果最优;物理实验5采用支持向量机与卡方检验法得出的实验结果最优;物理实验6采用支持向量机与卡方检验法得出的实验结果最优;物理实验7采用支持向量机与卡方检验法得出的实验结果最优。
综合本次实验中七个物理实验的所有结果,可以得出,在本实验选取的众多降维方法中,卡方检验法的降维效果最好;支持向量机是本次实验采用的所有回归方法中效果最好的,最终均方根误差较小。
3.3 基于HMM的模型构建
鼠标事件与知识点状态存在着一定的关联,通过实验者实验时的鼠标事件可以了解实验者各知识点的学习状态。计算机可以直接观测到鼠标事件而无法直接观测实验者在知识点学习时的状态。所以就需要用统计的推理方法确定它们之间的关联。从观测序列推断出概率最大的隐含状态,也就是从实验的鼠标事件数据中推断出实验者的学习状态。该问题就是HMM中的预测问题,要构建基于HMM的知识点学习状态评价模型,首先要提取特征,特征的选取对模型构建及训练至关重要。其次将建立HMMs模型库并对模型库进行训练,最后是分类决策,分类决策将具体实现知识点学习状态的评价。
特征提取时需要考虑初中物理电学实验中知识点操作的要求及特性,从而构建合适的观测序列。在数据收集的过程中,教学者提出的基本要求如下:能够对于实验者整体操作时的情况得出需要重点关注的模块。
对于各个知识点,通过分析数据可以得出实验过程中特征值的变化情况,具体情况如图1所示。

图1 特征值的变化Fig.1 Variation chart of characteristic values
根据特征值的变化情况,可为各个知识点设置两个关键值。这两个关键值分别代表合格、不合格。各知识点关键值如表4所示。

表4 各知识点关键值Tab.4 Key values of all knowledge points
模型库中的模型对应的是对各个知识点的评价模型,每个模型都需要经过训练之后再并入HMMs模型库中,其基本训练流程如图2所示。

图2 HMMs模型库基本训练流程Fig.2 Basic training process of HMMs library
HMMs模型库建立之后就可以解决概率计算问题。计算观测序列与模型库中各个模型的匹配程度。
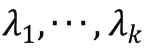
实验采集了300 组实验过程的数据,其中每个知识点的状态各50 次。将300 组数据平均分为两组,一组用来训练,另一组用来识别。
实验结果如表5所示,表中状态所在行代表实际的状态,所在列代表实验的结果,数值代表对应识别的次数,最终实验结果由准确率进行衡量。

表5 HMM模型的实验结果Tab.5 Experimental results of HMM
从表中的识别结果来看,准确率最高的为S1与S4。评价的平均准确率为79.7%。
3.4 混合模型的构建
由HMM模型实验结果来看,对于大部分状态的识别还是较为准确的,因此使用HMM模型是可以对各知识点学习状态进行有效评价的。但是对某些状态的识别准确率欠佳,这就代表当观测序列较为相似时,HMM模型并不足以完全识别。而SVM虽然不考虑时间因素,但它提升了对比分类的效果,并且更加适用于小样本的数据。因此SVM可以很好地弥补HMM存在的不足。
混合模型的基本架构分为上层和下层,HMM模型位于上层,负责处理具有时序特征的观测序列,通过计算观测序列与模型库中各个模型的似然率来缩小结果的范围。SVM位于下层,由于其分类能力较强,将上层HMM模型缩小范围后的数据输入到SVM模型中,对结果进一步处理。这种独立的混合模型可以减轻工作负担,提升工作效率,通过联合评价的方式提高评价准确率。基本架构如图3所示。

图3 混合模型的基本架构Fig.3 Basic architecture of hybrid model
由于混合模型是外部引入的双层架构,因此HMM模型与SVM模型要先单独训练,这两个模型的训练相互独立。HMM模型的训练方法与上一节中类似,SVM模型的训练要遵循“一对一”策略,使用序列最小优化(Sequential Minimal Optimization,SMO)算法对分类器进行训练。
混合模型的训练与识别具体步骤如下所述。
(1)首先将观测序列输入HMMs模型库计算与各个模型的似然率,计算似然率采用了前向-后向算法;
(2)其次将似然率较小的结果排除后,选择较高的2—3 个状态,将其观测序列传递给下层的SVM;
(3)再调用对应的SVM的分类器对这些特征向量进行投票;
(4)最后将得票率最高的结果输出。
这种由外部引入的混合模型,不仅保留了隐马尔可夫模型对于实验中实验状态时序变化的描述能力,还通过支持向量机提高了评价的准确性。而且这种松散的结构有助于后续对知识点的添加与删除,具有很强的可拓展性。
基于HMM/SVM模型的实验结果如表6所示,评价标准为实验状态识别的准确率。

表6 基于HMM/SVM模型的实验结果Tab.6 Experimental results of HMM/SVM model
可以发现,HMM/SVM模型的采用可以显著改变HMM模型的性能。各个状态的准确率均有一定的提升,在HMM模型中被识别为同类问题的串联模块与并联模块,在混合模型中的准确率上升也非常显著,可以解决HMM分类能力不足的问题。
基于HMM/SVM的学习状态评价系统将HMM模型与外部引入的SVM模型进行结合。不仅可以处理时间序列的数据,反映实验完成的过程性,还提高了评价的准确度。同时,文中提出的基于HMM/SVM的知识点学习状态评价模型,可拓展性强,对于后续需要添加或删除知识点的情况非常友好,实际应用性很强。
4 结论(Conclusion)
提出的学习状态评价模型不仅可以做出过程性的评价,弥补实验评价的片面性与局限性,还可以充分挖掘学习者在实验中知识点的学习状态信息,对需要重点关注的知识点做出反馈。有利于学习者与教学者及时发现问题、解决问题,一定程度上降低了学生产生厌学情绪的可能性,增强了学习评价的科学性与全面性,同时也为虚拟仿真实验评价问题提供了一种新的思路。
猜你喜欢
Engineering(2020年3期)2020-09-14
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
海外华文教育(2016年4期)2017-01-20
湘潭大学学报(哲学社会科学版)(2015年5期)2015-11-25
会计之友(2014年28期)2014-10-13
继续教育研究(2014年1期)2014-02-27
测绘工程(2013年6期)2013-12-06
少年科学(2009年1期)2009-01-20
IM家庭电子(2008年11期)2008-12-05
