
基于秘密共享的本地多节点联邦学习算法
2022-10-09 00:53:24王捍贫范耀榕
广州大学学报(自然科学版) 2022年3期
王捍贫, 范耀榕
(广州大学 计算机科学与网络工程学院, 广东 广州 510006)
目前,深度学习技术在各个领域发展迅速,这离不开数据和算力的爆发。深度学习模型的准确度依赖于数据量,由于隐私问题不断出现,人们逐渐重视数据的隐私安全,与此同时,政府也颁布隐私保护法律法规(如:GDPR[1]、《中华人民共和国网络安全法》[2]等)进一步保护用户数据安全,导致数据不断分散出现“数据孤岛”现象,从而无法聚集数据来训练高精度模型。
对此,Google 于2016年提出联邦学习(Federated Learning, FL)理论[3]。在FL系统中,参与者通过在自己的私有本地数据上执行本地训练算法,并仅与中心服务器共享模型参数,此中心服务器用作中央聚合器,以适当方式聚合本地参数更新后与每个参与者共享聚合的更新。然而参与者与中心服务器之间存在高频通信及长传输延迟,这导致FL不得不面对通信效率问题[4]。
根据应用场景的不同,联邦学习可分为跨设备联邦学习(Cross-device federated learning)和跨数据库联邦学习(Cross-silo federated learning)[5]。联邦学习的通信拓扑图一般为星形拓扑,对于跨设备联邦学习而言,参与训练的客户端为数量庞大的IoT设备或者移动设备,并且具有本地数据量少、通信不稳定和客户端间不互信的特性,这往往会对中心服务器的通信造成巨大的压力。对此,最近的研究提出了分层联邦学习框架(Hierarchical Federated Learning, HFL)[6-7],在客户端-中心服务器的结构中加入边缘服务器,形成客户端-边缘服务器-中心服务器结构,在训练过程中相邻的客户端将模型发送到近端边缘服务器进行聚合,然后由边缘服务器发送局部聚合模型到中心服务器进行最终聚合,从而减少中心服务器的通信压力。目前的HFL主要是利用物理层的中间设备充当边缘服务器,如Mehdi等[8]利用物理层面的小型蜂窝基站(Small-cell Base Station, SBS)来充当边缘服务器,大型基站(Macro-cell Base Station, MBS)作为中心服务器,构建分层联邦学习训练架构,移动用户将与最近的SBS进行通信形成局部交流结构,SBS聚合模型后再与MBS通信从而减少MBS的通信量。而在跨数据库联邦学习的场景中,其客户端数量通常在100个以内,每个客户端具有数据量大、通信可靠、计算资源丰富和客户端间不互信等特性,并且都参与每个轮次的训练。以往的HFL在该场景下反而可能会由于额外增加的边缘服务器聚合操作造成通信效率下降[6-8]。
本文关注在跨数据库联邦学习环境下客户端与服务器之间的通信效率问题。在该场景下,客户端内部通常拥有多个本地计算资源,如高性能计算机,且本地的内部通信相对于外部网络WAN而言具有速度更快、更可靠和可信任的优点。传统的联邦学习框架在该场景下,客户端上仅利用部分计算能力训练模型,并不能够充分地利用其计算资源训练模型。而HFL的结构则根据跨数据库联邦学习内部通信的特性与优点,可以很好地利用客户端本地的计算资源,通过客户端将本地的多个计算资源生成多个节点参与到全局联邦学习的训练中,形成本地节点-客户端-中心服务器的多级分层联邦学习结构,有效地利用跨数据库联邦学习的计算资源来加快训练速度,从而提高通信效率。
此外,虽然FL允许参与者将其原始数据保存在本地,为客户端的数据隐私提供了保护,但最近的工作表明,它不足以保护本地训练数据的隐私免受成员推理攻击[9]、属性推理攻击[10],训练过程中交换的模型参数与梯度更新仍然是重点攻击目标[10-11]。Gei等[11]通过余弦相似性和对抗攻击策略从梯度信息中恢复训练时输入一批图像,并证明从梯度中重建输入图像与模型的深度架构无关。
与传统架构一样,HFL架构中传输的模型参数或梯度仍面临着潜在的隐私泄露风险,不足以保护训练数据的隐私免受推理攻击及数据重构攻击。为保护FL系统免受这些隐私攻击,目前已有学者提出解决方案,如Abadi等[12]在神经网络模型训练过程中添加差分隐私噪声来消除训练数据的隐私,后续的工作在此基础上进行适应改造,将该方法移植到联邦学习系统中,如Truex等[13]提出LDP-Fed,用于实现客户端能自主定义本地差分隐私预算,在客户端上传模型时添加隐私噪声,实现相对于中心式差分隐私更为优秀的隐私保护功能。Lu等[14]提出了一种在HFL场景中应用差分隐私的隐私保护方案HFL-DP,在客户端上传模型时,添加满足局部差分隐私的噪声进行扰动,并且采用Abadi的时刻记账方式来跟踪累计的隐私损失。又如Moreau等[15]将Abadi的方法应用至跨数据库联邦学习中,并提出了一种混合策略,即客户端根据本地数据量选择固定或自适应的隐私预算策略。然而差分隐私方案会带来噪声,随着噪声变大模型精度也逐渐降低,从而导致模型难以收敛[4]。另外一个方向为采用安全多方计算来进行隐私保护,Bonawitz等[16]提出了一种FL的安全聚合方法,通过使用伪随机数、Shamir的秘密共享[17]和对称加密来禁止服务器直接访问客户端模型。然而该方法需要可信服务器,并且需要较高的通信代价。更进一步,David等[18]基于Bonawitz等人的工作,将差分隐私与安全多方计算结合,用于联邦学习的安全训练过程,即客户端向训练好的模型参数添加差分隐私噪声以及基于加密原语生成的随机数,在中心服务器进行聚合操作时,对加密模型进行聚合,即可将随机数消除得到聚合模型。但是该方法依旧向模型添加了额外的差分隐私噪声。Duan等[19]提出了一种采用秘密共享策略的深度模型隐私保护方法,各个客户端将本地模型的梯度更新进行秘密共享,由中心服务器聚合秘密,从而得到梯度聚合结果。然而,该方案并未处理客户端掉线问题。目前的隐私保护方案中,采用安全多方计算的方案并不会在训练过程中额外添加噪声,相比于差分隐私方案其能够得到准确的模型,但是也存在相应的缺点,如需要较高的通信代价,需要依赖可信服务器与没有处理客户端掉线情况等。因此,设计一种高效且保护隐私的FL方案,以防止数据的隐私泄露至关重要。
在对模型精度要求更高的需求下,安全多方计算方案能更好地发挥数据的价值。秘密共享作为安全多方计算中应用场景较为广泛的方法,相比于其他安全多方计算方法而言算法实现更为简单,且在联邦学习系统中产生的代价相对较小[20],故而本文采用秘密共享方法进行保护跨数据库联邦学习中的数据隐私安全,通过优化加密过程来减少秘密共享所产生的通信代价。
因此,针对跨数据库联邦学习的通信效率问题,以及目前联邦学习隐私保护方案中存在的问题,本文提出了一种基于秘密共享的本地多节点联邦学习算法Mask-FL。本文假设用户数据分布在不同的客户端上,例如电商平台、银行或金融机构,它们拥有大量不同的用户数据。每个客户端将生成多个本地节点,然后将用户数据划分成多份分布在本地节点上,每个客户端进行本地训练时,由本地节点采用划分的数据训练模型。在训练过程中通过秘密共享方式解决模型上行传输的隐私泄露问题。实验结果表明,该算法在保护隐私的同时具有较高的通信效率。本文的主要工作如下:
(1)提出本地多节点跨数据库联邦学习框架。在客户端-服务器的结构上加入本地多节点结构,每个客户端根据自身的计算资源能力生成多个本地节点,并将本地数据进行切分后设置在各个本地节点上,每个本地节点并行参与到全局联邦训练。针对节点的数据量分配问题,设计了一种基于计算能力的数据切分算法,客户端根据各节点计算能力进行数据切分,以减小数据量不平衡带来的影响。
(2)提出基于秘密共享的自适应掩码加密协议。在本地多节点跨数据库联邦学习框架的基础中,通过秘密共享的方式得到可复用的安全自适应参数掩码,客户端通过对模型添加掩码以保护模型参数安全后,再发送至服务器进行聚合。在诚实且好奇的安全设置下,证明了本协议能够对抗来自客户端与服务器的威胁。
(3)将Mask-FL算法用于训练卷积神经网络模型过程,通过对Mask-FL的各个参数进行独立实验,以及对比3种不同联邦学习算法,证明了本文提出的Mask-FL在保护隐私的前提下能保持相对较高的准确率,并且减少了全局通信轮次,有效地提高了联邦学习模型训练速度。
1 背景知识
1.1 联邦学习
联邦学习提供了使用分布式数据训练机器学习模型的能力,参与实体之间无需共享原始数据。假设(D1,D2,…,Dn)是分布式数据集,分别分布在n个用户(O1,O2,…,On)上,在联邦学习中,每一个用户都独立拥有一个数据集,并且仅使用本地的数据独立训练一个ML模型,而不对外部公开本地数据。每个用户通过本地训练得到的模型参数被收集到服务器(一个中心实体/机构)中,该服务器聚合所有收集到的模型参数以生成全局模型。全局模型的精度Afed应非常接近在服务器上使用所有数据集训练得到的模型精度Actr,这种关系可用公式(1)表示,其中,δ是一个非负实数[20]。
|Afed-Actr|<δ
(1)
标准的FL训练算法在多轮训练中进行,典型的联邦学习步骤如下:
(1)服务器初始模型,下发到各个客户端;
(2)每个客户端根据各自的数据训练本地模型;
(3)每个客户端将其模型权重发送到受信服务器;
(4)服务器计算模型平均权重得到共享模型;
(5)服务器将共享模型返回给所有客户端;
(6)客户端从共享模型开始,重新训练本地模型。
在提供高度准确推断的同时,保护敏感用户信息非常重要。例如输入法提供商可以使用联邦学习来提高客户输入推荐词的精确度。各提供商不必采集客户设备上的隐私输入词来训练自己的推荐算法,而是结合其模型创建共享的高频词推荐机制,无需共享其个别客户的隐私输入词。然而,恶意方仍然有可能通过从训练模型的权重或参数中推断出训练数据集的细节来潜在地损害个人用户的隐私[9-11]。
1.2 安全多方计算
安全多方计算理论是姚期智先生为解决一组互不信任的参与方在保护隐私信息,以及没有可信第三方的前提下,协同计算问题而提出的理论框架。目前,主要通过3种不同的框架来实现:不经意传输、秘密共享和阈值同态加密。不经意传输协议和阈值同态加密方法都使用了秘密共享的思想[20]。
秘密共享(Secret Share, SS)是指通过将秘密值分割为随机多份,并将其分发到不同方来隐藏秘密值的一种概念。每一方只能拥有一个通过共享得到的值,即秘密值的一小部分。根据不同场景,需要所有或者一定数量共享值才能重新构造原始的秘密值[17]。图1给出了如何使用秘密共享的简单示例。

图1 秘密共享的简单示例
由图1所知,2个数据源分别拥有数字X和Y,服务器想要知道X+Y之和,但对X和Y一无所知。该过程可以描述如下:首先,将原始数据分解为2个子部分,一个子部分在双方之间交换,然后计算剩余子部分与另一方部分的和。最后,对计算结果进行汇总,得到原问题的解。在这个过程中,原始数据不会被公开,因此,可以在保护数据隐私的前提下完成求和运算。
2 基于秘密共享的本地多节点联邦学习算法
本章介绍本文提出的联邦学习算法Mask-FL,主要分为3个部分,第一部分为本地多节点跨数据库联邦学习训练框架,第二部分为基于秘密共享的自适应掩码加密协议,第三部分为联邦学习算法Mask-FL,将掩码加密协议嵌入本地多节点跨数据库联邦学习训练框架,并进行更为详细全面的设计。
2.1 本地多节点跨数据库联邦学习训练框架
跨数据库FL自然适合企业对企业(B2B)场景,其中每个数据库可以是公司或组织,而跨设备FL对应于企业对客户(B2C)模式。跨设备FL通常涉及大量用户,故通信成本可能是一个瓶颈,而跨数据库FL只有几个参与方(通常少于10个),因此,对于通信要求相对不大。本文基于跨数据库设置FL,在这种情况下应该考虑计算成本,因为作为企业的每一方都拥有比个人设备更为庞大的数据,并且计算能力也比单一设备要强,然而当前的联邦学习框架在数据库节点上仅仅训练单一的模型,并不能够充分地利用计算资源。虽然有分布式机器学习方法的辅助,但是在联邦学习中仍存在缺陷,即不能够直接进行快速的训练,因此,本节主要为了解决在FL中充分利用客户端的计算能力问题,设计了新型的训练结构框架LocalNodes-FL,以将数据和算力利用起来,加快联邦学习模型的训练,进而减少训练过程中的通信开销。
考虑在FedAvg联邦学习的框架上,通过改变其结构来有效提高资源利用效率和通信效率。框架如图2所示,结构采用本地节点-客户端-中心服务器的方式。通信过程存在于客户端内部、客户端与客户端、中心服务器与客户端。本地节点由于是处于同一个数据库客户端环境下,网络传输的延迟影响较小,其中的通信开销可忽略不计。而主要的通信开销产生于中心服务器与各个客户端之间。
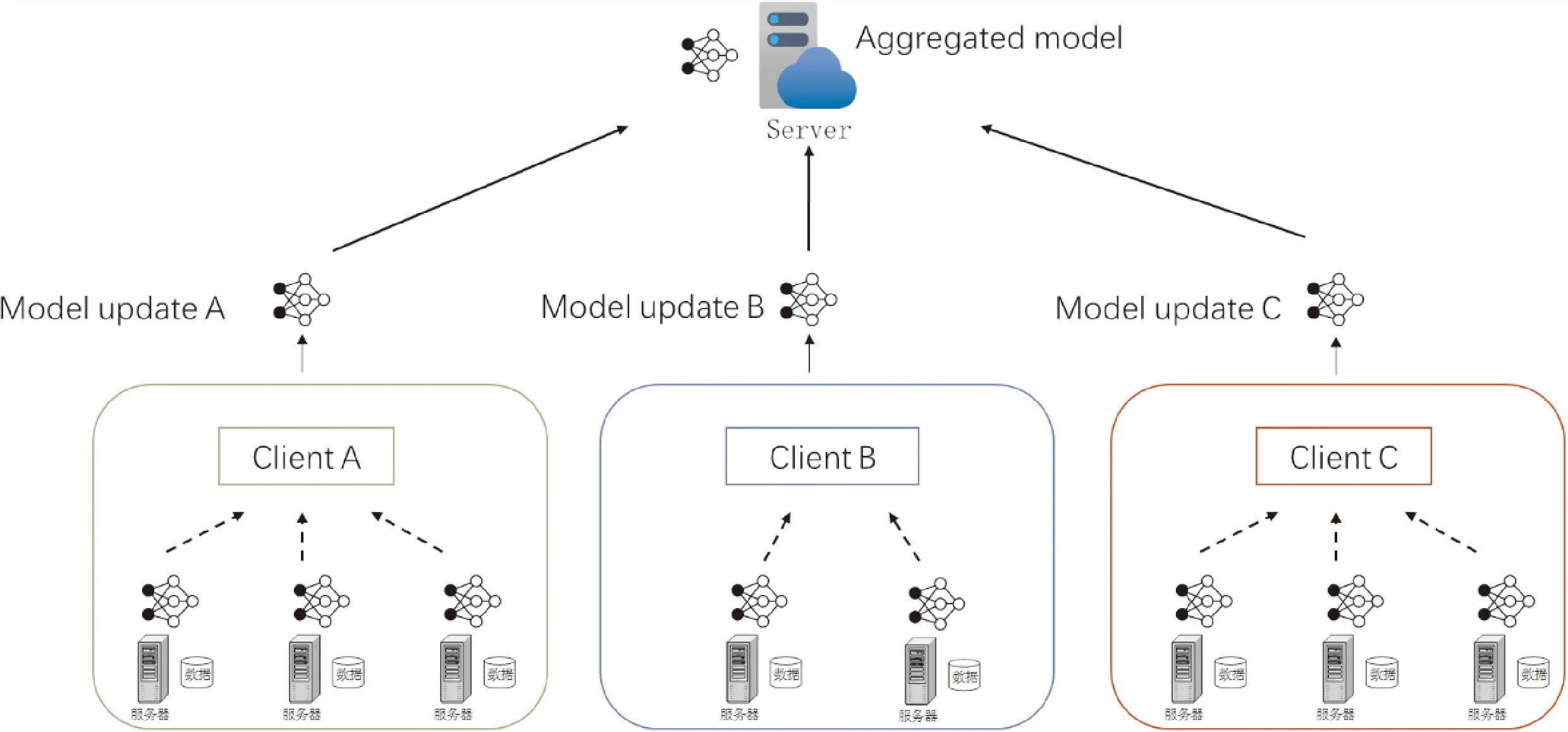
图2 本地多节点跨数据库联邦学习示例
考虑n个客户端参与训练的联邦学习,本地数据集设为(D1,D2, …,Dn),各客户端根据本地的m个计算资源能力生成m个本地节点,将本地数据划分成m份并放置在本地节点上,有
(2)
在本地节点训练模型过程中,各个对等节点的训练是同步进行的,那么在客户端等待收集各个节点训练完成时,最长等待时间为本地节点中训练时间最长的节点。而模型训练时间跟数据集大小成正比关系,跟节点计算能力成反比关系,因此,在数据划分时,为了能够减少客户端等待时间,本文设计了数据集切分算法——DataSplit,以让本地各个节点训练时间相近,从而能够提高整体的训练速度。伪代码如算法1。
首先,客户端确认本地拥有的计算资源节点数量m,从中心服务器获取初始化模型后,从本地数据集中采样m个batch大小为B的样本数据分配到各个节点上,每个节点采用该batch进行训练,记录节点训练所需时间tj。所有节点训练完成后,得到各个节点训练所耗时间序列。计算节点计算能力系数
(3)
客户端根据每个节点的计算能力系数进行划分数据集
|Dj|=cj|D|
(4)
在进行数据集划分时,各个节点所分配的数量为|Dj|,但是划分的数据是从客户端数据集中随机采样的,并且每个节点内的样本都不重复。

算法1 基于计算能力的数据切分算法———DataSplit输入: 客户端数据集D,计算资源节点集M,服务器下发模型w0输出:节点数据集|Dj|1:Client executes:2: sample m batches from the dataset and dis-tribute them to each node3: for each node j∈M in parallel do4: w1←ClientUpdate(j,w0)5: Statistic time tj ∥统计训练时间6: End for7: calculate dataset rate of nodes:8: cj←t1tj*∑mk=1t1tk9: for each node j∈M do:10: |Dj|=cj|D|11: End for
2.2 基于秘密共享的自适应掩码加密协议
在联邦学习训练过程中,按照参与训练的主体划分,存在着来自非诚实服务器以及其他参与训练方的威胁,所以为了解决来自这些主体的威胁,本节在LocalNodes-FL框架上设计基于秘密共享的自适应掩码加密协议,加入了联邦加权平均算法的思想。该协议用于一组固定的客户端(P1,P2, …,Pn),还有一台服务器S的深度神经网络交互训练。
安全假设:①假设所有客户端与服务器都采用安全的通道进行通信,如TLS/SSL;②所有客户端和中心服务器都是诚实且好奇的[21],诚实且好奇的定义如下:诚实且好奇的客户端和中心服务器会根据协议执行相应步骤,但是,它们也会尝试推断出其他客户端的隐私数据;③每个客户端至少生成m(m≥2) 个节点参与联邦学习过程。
为了向服务器隐藏每个客户端的模型权重,协议采用安全多方计算技术中的秘密共享技术,在该协议中,客户端协同工作,以加密的方式向服务器发送各自的模型参数或者模型更新梯度。在模型从中心服务器下发到客户端后,每个客户端生成一个与模型参数形状相等的掩码Mask,例如对于一个具有10 M个参数的模型,那么也相应生成一个10 M个参数的掩码,即
shape(Mask)=shape(w)
(5)
由于模型参数与掩码值可能相差过大,进而会出现一种危机:服务端接收到本地掩码模型后,通过比对原始模型,判断掩码模型参数是否出现异常值,那么将异常值去掉突出部分得到原始模型参数,某种程度上也会反映出本地真实模型,因此,本文提出自适应的掩码生成方案,将生成的掩码值界限设置为[min(w), max(w)],使得模型值与掩码值在同一范围区间内,进而消除掩码与模型参数之间的差距,从而更好地防止服务器从客户模型中推断私人数据。模型掩码采用伪随机数发生器进行生成:
Mask=PRG(a)z
(6)
其中,z代表PRG(·)的输出维度(在本协议中,其维度等于模型的参数数量),PRG(·)是伪随机数生成器,输出空间限定为[min(w), max(w)],a为模型参数值。
协议如图3所示,该图为3个客户端参与的掩码交换过程。
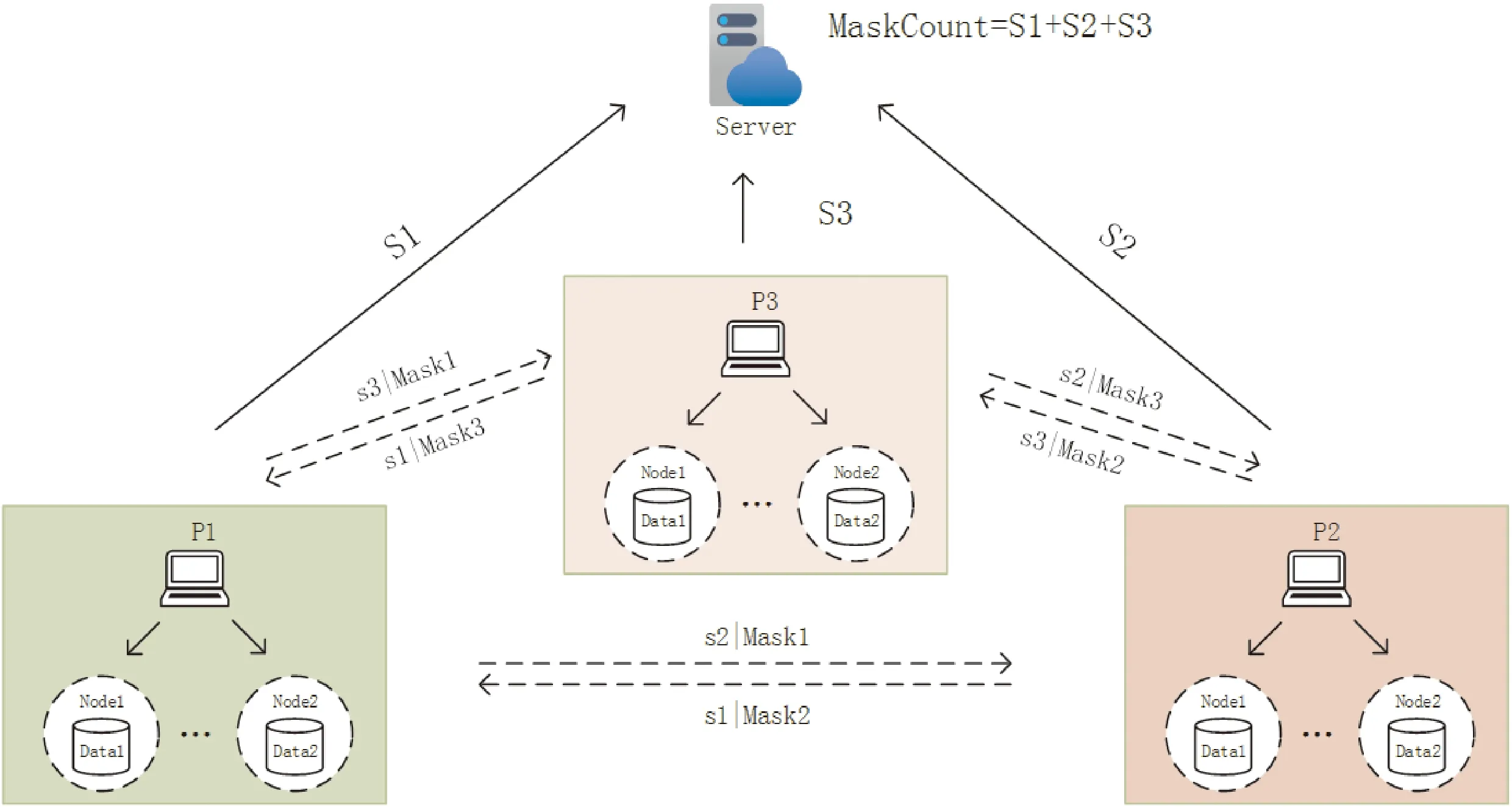
图3 三方参与掩码加密协议过程
协议具体流程如下:
(1)节点生成掩码
自适应掩码加密的目标是保护单个客户端的模型参数,每个参与训练的节点按照式(6)生成本地掩码。
(2)进行秘密共享求和
每个客户端的各个本地节点都生成本地掩码后,进行求和,即
(7)
得到客户端掩码和,每个客户端对掩码和执行秘密共享协议,将Maski分别拆成n份Maski= {si,1,si,2, …,si,n},分发给n个客户端。客户端收到各个客户端发来的部分秘密后,对部分秘密进行求和,即
(8)
得到部分秘密和,接着将其发送到中心服务器。
(3)服务器计算掩码和
中心服务器接收来自各个客户端发送的部分秘密和之后,计算掩码和
(9)
(4)模型添加掩码
节点在本地训练完模型后,向模型添加权值|Di,j|,其代表客户端划分到本地节点的数据集大小,再向模型w添加自适应掩码。即对模型参数w做如下处理:
(10)
然后客户端将本地掩码模型聚合:
(11)
将本地掩码模型发送至中心服务器,|Di,j|为局部节点划分到的数据集大小,并且客户端发送|Di|至中心服务器。通过对模型参数添加自适应掩码,从而保护客户端的训练模型参数在交互过程中不被泄露。
(5)模型解码
中心服务器收到每个客户端发来的掩码模型和数据集值,然后执行模型解码:
(12)
(13)
(14)
(15)
(16)
得到聚合模型。
本文协议能够让客户端在每次模型迭代中重用掩码,因此,客户端在协议开始时只需要与服务器和其他客户端进行一次通信。在随后的迭代中,每个客户端只需与服务器通信,当然,随着训练的轮次增大,模型参数的最值区间改变,那么相应的,掩码值也应更新,并且掩码值定期更新能为系统带来更高的安全性。
协议安全性分析:
本节证明了在诚实且好奇的客户端和中心服务器参与攻击下,本协议是安全的。
定理1(抵御服务器攻击) 服务器不能推断出节点的模型参数。
证明在上述联邦学习训练过程中,服务器可以获得客户端上传的加权聚合掩码模型。假设服务器可以推断出wi,j,那么服务器需要推断出节点的参数掩码和权值。首先,推断出基于a的伪随机数生成的掩码Maski,j,a是节点的参数,服务器需要与节点进行相互串谋才能获取a,这与该攻击方式相矛盾。故而服务器无法推断出节点的模型掩码Maski,j;其次,服务器破解权值|Di,j|,由于假设③,|Di,j|≠|Di|,则需要推断出客户端给该节点分配的数据量,而客户端在本地内进行切分的方法是根据节点的计算能力进行分配的,服务器需要与客户端进行合谋才能破解,节点是属于客户端的,这与该攻击方式相矛盾,因此,服务器无法推断出节点的权值|Di,j|。
综上所述,在中心服务器攻击中,服务器无法推断出节点的模型参数。
定理2(抵御节点攻击) 恶意客户端不能推断出节点的模型参数。
证明假设恶意客户端在每次训练迭代过程中,根据聚合模型结果推断出其他客户端的本地节点模型参数,但是在协议中,模型聚合结果是由每个客户端本地节点的模型加权聚合平均得到的,那么恶意客户端需要推断其他客户端生成的本地节点个数mi及划分到本地节点的权值|Di,j|。首先,推断所有其他客户端生成的本地节点个数mi,m是每个客户端根据本身计算资源生成的节点,其他客户端并不知晓,恶意客户端需要与所有客户端相互勾结才能获取mi,这与该类攻击方式不相符,故恶意客户端无法推断出其他客户端生成的本地节点个数mi;其次,恶意客户端推断本地节点的权值|Di,j|,|Di,j|是每个客户端的隐私数据集大小,只有其本身知晓,恶意客户端需要所有客户端相互勾结才能获取,与该类攻击方式不符,因此,恶意客户端无法推断出其他客户端的本地节点权值|Di,j|。综上所述,无法从聚合结果推断出其他客户端本地节点的模型参数。
定理3(抵御h≤n-1个客户端和服务器的共谋攻击) 服务器和客户端不能推断出其他客户端本地节点的模型参数。
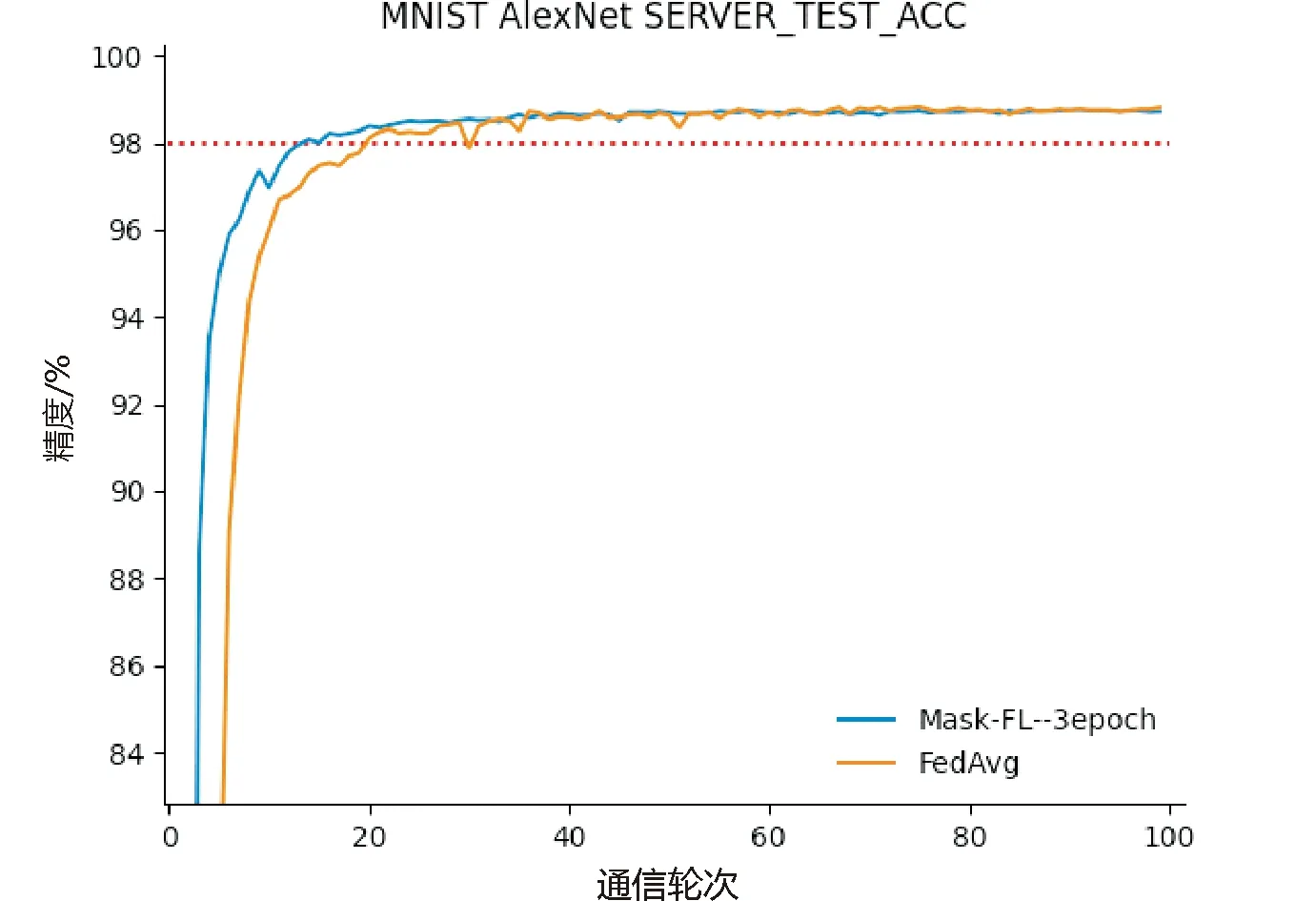
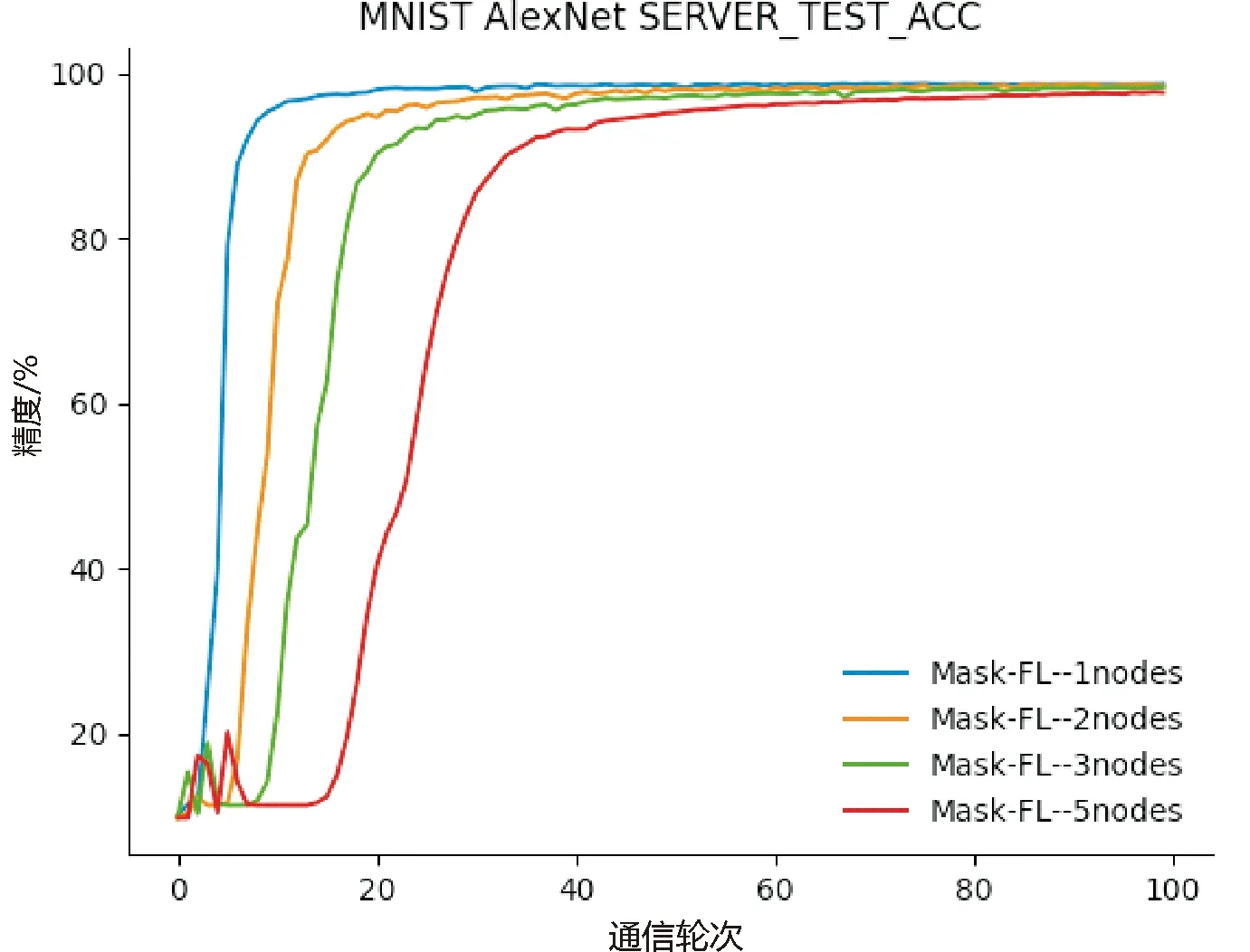
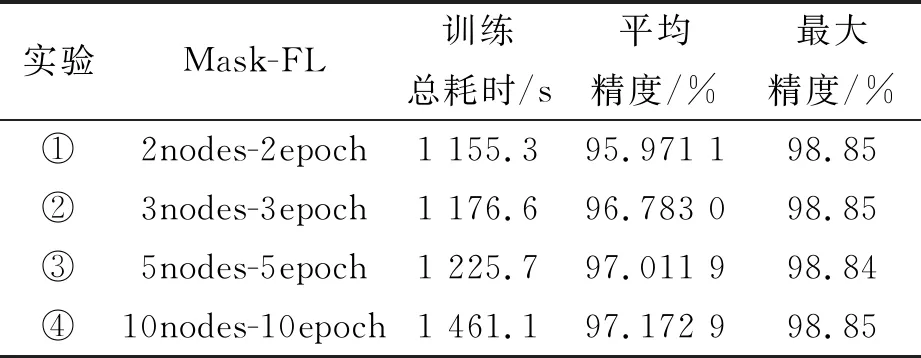
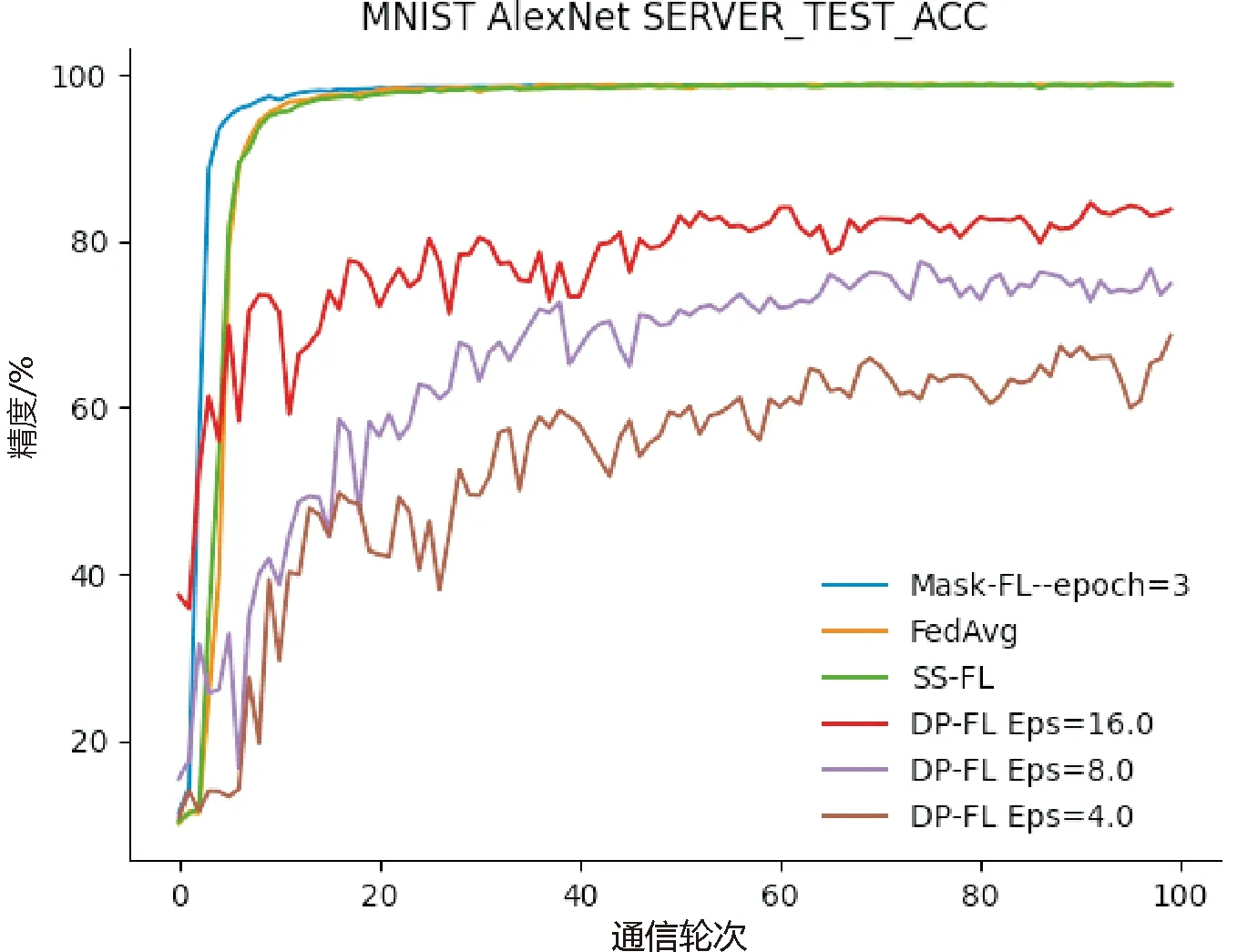
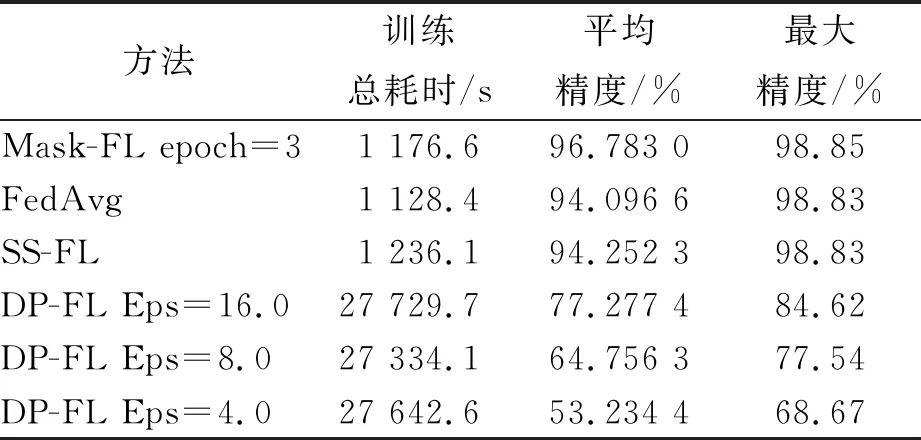
证明首先从服务器角度证明。假设中心服务器可以推断出其他客户端本地节点的模型参数wi,j。服务器收到来自客户端发送的加权聚合掩码模型,服务器需要推断出本地节点添加的掩码Maski,j和权值|Di,j|,服务器要求与之勾结的h个客户端上传各个节点的掩码值,服务器拥有MaskCount,当h=n-1时,则仅能推断出客户端内所有本地节点的模型掩码和,无法获得本地节点的单一模型掩码。通过消除加权聚合掩码模型的掩码,得到客户端的加权聚合模型,而服务器要破解本地节点的权值|Di,j|,需要与客户端进行合谋,与攻击方式不符。当h 其次,从客户端角度证明。①客户端可以从聚合结果进行推断。假设h个客户端相互合谋,从聚合结果推断出其他节点的模型参数。h个客户端需要推断其他客户端生成的本地节点个数mi以及划分到本地节点的权值|Di,j|。与服务器合谋获知其他客户端发送的客户端总权值|Di|,然而h个客户端仍需与所有客户端进行勾结才能获取|Di|和mi,与该攻击不符,故客户端不能从聚合结果中推断出节点的模型参数。②客户端可以从加权聚合掩码模型中进行推断。与上述服务器角度证明相同,故客户端不能推断出其他客户端本地节点的模型参数。综上所述,诚实且好奇的客户端无论从聚合结果进行推断还是从客户端上传的结果进行推断,都不能推断出其他客户端的节点模型参数。 总之,服务器和客户端不能推断出其他客户端本地节点的模型参数。以上3个定理证明了基于秘密共享的自适应掩码加密协议能够有效地抵御服务器攻击、客户端攻击以及服务器与客户端相互合谋的共谋攻击。因此,本文提出的结合自适应掩码加密的本地多节点联邦学习隐私保护方案是安全的。该方案能够保证诚实且好奇的服务器和客户端都不能获取其他诚实客户端的隐私数据。 集成本地多节点训练框架和自适应掩码加密协议,考虑客户端掉线问题与全联邦学习训练流程,在本节给出完整的Mask-FL联邦学习算法。训练分为2个阶段,第一阶段为初始化阶段,第二阶段为联邦学习训练阶段。具体如算法2所示。 算法2 Mask-FL输入:客户端{P1,…,Pn},服务器S,初始模型参数w0,全局训练轮次R,掩码更新阈值T,本地训练迭代次数E,客户端数据集{D1,D2,…,Dn},客户端本地节点集{m1,m2,…,mn} 输出:结果模型w1:S initialization model w0 and deliver the model to each client.2:Mask-FL.Setup:3: for each client i∈Pn do:4: {Di,j},{wi,j}←DataSplit(Di,w0) ∥详见算法15: Maski,j←PRG(wi,j) ∥采用伪随机数生成器生成与模型相同的模型掩码6: Maski←∑mj=1Maski,j7: Split {si,1,si,2,…,si,n}←Maski8: Send share si,n to Pn9: receive share and merge them:10: Si←∑nj=1sj,i11: Send Si, Di to server12: End for13: Server do:14: MaskCount←∑ni=1Si15:Mask-FL.Train:16: While r≤R do:17: for each client i∈Pn in parallel do:18: for each node j∈mi in parallel do:19: wjr+1←ClientUpdate(j,wr), do it for E time20: wjr+1 ←|Di,j|*wjr+1+Maski,j21: End for22: wir+1 =∑mj=1wjr+1 and send to server23: End for24: Server do:25: wr+1 ←∑ni=1wir+1 26: wr+1←1∑ni=1|Di|(wr+1 -MaskCount)27: Send wr+1 to all clients28: r++29: if r % T == 0 or client dropout: 30: Run Mask-FL.Setup (wr+1)31: End while32:ClientUpdate(k, w): ∥ Executed on client k33: for each local epoch i from 1 to E do:34: batches←(data D split into batches of size B) 一个完整的训练周期如下: (1)初始化模型参数。中心服务器初始化模型,并且生成模型初始化参数,分别为客户端本地节点的训练迭代次数、全局通信轮次以及学习率,并且将模型和这些参数发送至所有参与训练的客户端,客户端根据本地计算资源能力将本地数据集进行随机划分,每一个计算资源生成一个节点并拥有一个划分后的数据集。 (2)节点采用一个batch的隐私数据集进行单次训练,每个节点根据模型参数生成模型掩码,采用秘密共享机制与其他节点分享模型掩码秘密,各节点再将获得的掩码秘密求和后发送到服务器,服务器结合各部分掩码秘密和获得总掩码。 (3)节点采用隐私数据集进行本地训练,获得模型参数后加权,并且添加本地掩码得到掩码模型,发送至客户端,客户端聚合后再上传至中心服务器并且发送客户端本地参与训练的数据集数量。 (4)中心服务器检测是否有离线客户端,①没有离线客户端,直接将所有客户端上传的掩码模型相加并采用总掩码和解密后进行平均得到全局模型;②存在离线客户端,则其他客户端重启步骤2~步骤5,然后计算全局模型,下发全局模型至各个客户端。当全局迭代次数达到掩码更新阈值时,各个客户端按照步骤2更新掩码。 如果训练过程中,有客户端中途退出,则采用步骤2重新生成新的掩码并将其保存下来,若在下一次迭代掉线客户端重新上线,则可启用上一次掩码值而不用重新运行步骤2。反复迭代,直到模型收敛或达到最大训练轮数。 在本章中对Mask-FL进行实验以评估其性能指标,同时设置对照实验组:联邦平均算法(FedAvg)[3]、结合差分隐私的联邦学习(DP-FL)[12]、结合秘密共享方案的联邦学习(SS-FL)[19]。为了进行相同背景的对比,3个对照实验组的超参数、模型及数据集都设置成与Mask-FL一致。 本文在分布式数据集上使用深度神经网络AletNet进行训练来模拟,模型参数数量为3.87 M。实验数据集采用MNIST手写图像数据集,该数据集由28*28像素的60 000张训练图片和10 000张测试图片组成,一共10个数字类,其中,每类各有6 000张训练集和1 000张测试集。实验运行环境为一台配有Tesla P100 PCIe 16GB GPU的PC,内存为32 GB。各节点训练模型使用SGD作优化器。 在实验中默认训练数据集batch为64,测试集batch为1 000,学习率为0.01,全局训练轮次round为100。对于Mask-FL中客户端的本地节点进行本地迭代训练次数epoch设置为1,其他框架的客户端本地训练次数epoch为1。在本文DP-FL对照实验中,设置隐私预算松弛度δ=1e-5,训练抽样集比例q=0.01,clip=8,由于抽样集比例为0.01,为能与其他算法在同等情况下进行比较,控制其模型训练的样本数与其他算法相等,因此,设置DP-FL的本地训练轮次epoch=100。 Mask-FL、FedAvg、SS-FL和DP-FL均采用1个中心服务器、3个客户端的结构进行训练。对60 000张图片的MNIST训练集进行打乱后随机采样切分成3个训练集[20 000,20 000,20 000],每个客户端拥有一个训练集参与联邦学习训练。测试集只放置在中心服务器,在一个轮次训练结束后,中心服务器使用测试集进行测试以观察聚合模型的效果。 本文分别从协议通信成本、训练时间、模型训练精度等角度对Mask-FL进行评估与分析。 通过实验来评估协议,可以构建一个精确的过程,以确定在实际场景中运行协议需要多长时间。为了实现这一点,本文统计了Mask-FL各个节点及服务器交流过程中协议各个步骤的计时结果,包括节点上的掩码初始化平均时间、掩码交换时间、加密平均时间、训练平均时间,服务器上的模型聚合平均用时、解码平均用时、模型下发平均用时,并且统计了FedAvg算法各个训练过程的平均耗时。虽然实验是单线程的,但它确实跟踪每个节点每个动作的独立时间,并确保实验不允许在同一时间内执行多个活动。因此,可以断言这些时间应该是对协议完整、分布式实现的合理估计。 实验采集了100个通讯轮次FedAvg和Mask-FL的各阶段平均用时,如图4所示。对于Mask-FL算法,基于秘密共享的自适应掩码协议的掩码初始化过程耗时为11.027 9 ms,在训练过程中,模型在本地训练的耗时为1 056.182 6 ms,相比之下,本协议对模型的加解密过程所耗费的时间仅为2.771 4 ms,说明本协议加密过程所产生的耗时并未对FL系统产生明显的时间开销。并且通过2.2节中对协议进行的安全性证明分析,说明基于秘密共享的自适应掩码协议消耗的时间不仅极小,而且能够有效地保护客户端数据隐私安全。除此之外,从图中可以看出,Mask-FL客户端的模型训练时间大大缩小,证明本文提出的本地多节点结构设计能够有效地减小客户端模型训练的时间。 图4 Mask-FL和FedAvg训练中各阶段耗时 由于本次实验是在单机上运行的,所以并未对客户端-客户端、客户端-服务器的上下行传输时间进行模拟,并且在实际应用中,各种设备的通信带宽、数据传输效率和网络状态各不相同,所以在联邦学习上下行过程中,考虑的评价指标为通信数据量。本文对各种联邦学习安全协议的训练过程进行了数据传输量的比较。 表1比较了4种联邦学习协议全局训练过程中的通信成本,|w|为传输的模型大小,n为参与训练的客户端,k为服务器聚合模型次数。相比于其他协议,Mask-FL协议需要在训练开始进行初始化设置,在该过程中所有客户端间需传输固定数据量(n-1)*n*|w|,客户端与服务器需传输3|w|数据量。在整个训练流程中,初始化产生的时间损耗仅发生一次,而在训练中掩码的更新频率T小于全局训练次数k,其数据量相对于整个训练过程的数据量仅占少部分,考虑协议安全性与时间损耗,Mask-FL仍具有很大的优势。 表1 不同联邦学习算法之间的通信成本比较 构造1个中心服务器、3个客户端及每个客户端3个节点的结构,每个客户端拥有20 000张数据,由于在相同的机器上训练,因此,按照Datasplit数据切分算法划分,得到每个客户端节点中的数据为[6 666,6 666,6 666]。按照以上采用默认参数设置,每个节点本地迭代训练1epoch,全局通信轮次为100,进行Mask-FL训练,训练结果如图5所示。 图5 Mask-FL的模型训练精度 由于采用的是平均聚合方式,所以在模型下发各个节点后,再次进行本地训练导致训练精度突然改变,从而出现了图5(a)中的毛刺,9个参与训练的节点的训练效果各有差异,但是在联邦学习的平均聚合效果下,最终都能达到整体的最优精度,在图5(b)中,随着全局迭代的不断增加,模型逐渐收敛,最大准确率达98.69%,即Mask-FL充分地利用各个节点数据达到训练目标。 由于Mask-FL客户端的训练速度提高,那么在相同的通信轮次内,本地节点可进行更多本地迭代训练的次数,根据上述实验,Mask-FL客户端训练时间约为FedAvg客户端训练时间的1/3,因此,设置节点本地迭代次数为FedAvg的3倍以进行相同条件的对比。训练结果如图6所示。 图6中,在相同的训练时间条件下,Mask-FL训练模型的收敛速度比FedAvg显著提高。达到相同的98%准确度条件下,Mask-FL需要进行14次通信,FedAvg需要进行20次通信,相比之下本方案所需的通信轮次更低,提高训练效率比为30%。Mask-FL最大收敛准确率为98.85%,FedAvg为98.83%,2种方案训练的模型均收敛。 图6 Mask-FL本地节点训练3 epoch与FedAvg训练模型精度比较 在默认参数设置下,针对Mask-FL不同的本地迭代训练次数进行实验,将epoch设为1、3、5、10分别进行训练,研究节点本地迭代训练次数对训练结果的影响,见图7。 图7 Mask-FL中不同epoch对训练的影响 图7为训练模型达到98%精度,Mask-FL在本地迭代1epoch方式需要进行通信47 round,3 epoch方式需要进行通信14 round, 5 epoch方式需要进行通信12 round,10 epoch方式需要进行通信8 round。1 epoch方式达到最大精度为98.69%,3 epoch方式最大精度为98.85%,5 epoch方式最大精度为98.85%,10 epoch方式最大精度为98.86%。随着本地节点迭代次数的增加,模型能更快地收敛,从而联邦学习训练收敛时所需的通信轮次更少。 采用默认参数设置,针对Mask-FL每个客户端生成的节点数分别为1、2、3、5进行实验,分析客户端节点数对模型训练的影响,结果见图8及表2。 如图8所示,在这次实验中Mask-FL节点数为1时,等价于FedAvg方法,但是不符合Mask-FL的安全性假设。随着客户端节点数的增加,模型收敛时所需的通信轮次增多,训练时间如表2所示,训练耗时大大降低,并且能够达到收敛精度。考虑上述实验图6的结果,可在提高客户端节点数的同时,提高节点本地迭代次数,以此来提高训练效果。 图8 Mask-FL客户端生成不同节点数对训练的影响 表2 Mask-FL客户端多节点训练100 round耗时和精度 采用默认参数设置,根据前面实验的结论节点数与训练耗时成反比,考虑在相同的时间内比较Mask-FL的训练效果,即客户端生成2节点的实验进行本地迭代2 epoch,客户端生成3节点的实验进行本地迭代3 epoch,客户端生成5节点的实验进行本地迭代5 epoch。实验结果如图9及表3。 图9 Mask-FL多节点多epoch对训练的影响 表3 Mask-FL多节点多epoch训练100 round耗时和精度 如图9所示,实验①达到98%精度时,所需通信轮次为17,实验②达到98%精度时,所需通信轮次为14,实验③达到98%精度时,所需通信轮次为9,实验④达到98%精度时,所需通信轮次为10。各个实验的模型通过100轮次的训练最终达到收敛。根据表3所示,得出实验结论:在近似的时间内,投入的计算资源越多,则模型训练速度越快,但是计算资源投入越多所获得的收益呈下降趋势。 采用默认设置,Mask-FL的每个客户端生成3个节点,节点本地迭代训练3 epoch,与其他3个框架进行100个通信轮次对比实验,比较模型准确度,结果见图10及表4。 图10 多种框架训练模型100 round的准确度 表4 各个框架训练100 round耗时和精度 如图10所示,在Mask-FL、SS-FL及FedAvg训练中,模型均获得较高精度,在DP-FL中,其结果模型准确度随着差分隐私预算减小而减小,即添加的扰动过大,导致模型精度下降,模型效果变差,并且表4显示,由于在训练过程中需要进行小批次采样训练和梯度切割而导致训练时间极大增加。Mask-FL训练所需耗时与SS-FL及FedAvg相近,但实验平均精度均比其他框架高,说明Mask-FL所训练的模型收敛更快。实验证明了Mask-FL训练过程中,在保证多方安全计算的前提下没有引入新的噪声,因此,得出Mask-FL能够在深度神经网络训练过程中不会造成精度的损失,并且能够更快地收敛模型的结论。 针对联邦学习目前面临着成员推理、重构攻击等隐私推断攻击,以及跨数据库联邦学习各节点训练时间长的问题,本文将分层联邦学习和基于安全多方计算的隐私保护机制相结合,提出了一种新型联邦学习训练算法Mask-FL,通过安全性分析证明,客户端的模型参数能不被服务器和其他客户端所获取。实验结果证明,相比于结合秘密共享的联邦学习,Mask-FL的通信成本较少;相比于添加差分隐私噪声的联邦学习训练方式,Mask-FL的训练准确度更高;相比于FedAvg算法,Mask-FL更安全且训练速度更快。本算法在保证数据隐私安全的前提下,拥有较高的模型准确度,以及具备优秀的模型训练速度。2.3 Mask-FL

3 实 验
3.1 协议时间消耗分析

3.2 通信成本评估

3.3 模型准确性分析




4 总 结
猜你喜欢
家庭影院技术(2020年10期)2020-12-14 07:54:16
家庭影院技术(2019年7期)2019-08-27 02:42:06
通信学报(2019年5期)2019-06-11 03:05:56
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
通信技术(2018年3期)2018-03-21 00:56:37
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
电子设计工程(2015年20期)2015-01-29 02:58:24
俄罗斯问题研究(2013年1期)2013-03-11 15:43:59

- 广州大学学报(自然科学版)的其它文章
- 广州大学《大学体育》课程“课内外一体化”教学模式的设计与实施研究
- Modified spin wave theory applied to the low-temperature properties of ferromagnetic long-range interacting spin chain with the antiferromagnetic nearest-neighbor interaction
- 布尔环及其谱的一些性质
- The cyclotomic numbers of order k=2m-1
- 基于分离逻辑的云存储系统并发正确性验证
- 广东省2035年土地利用空间分布的模拟预测