
基于知识蒸馏的轻量化残差网络在塑料颗粒高速检测中的运用*
2022-10-09 08:37:00梁家睿马鹏涛
机电工程技术 2022年9期
李 东,梁家睿,马鹏涛
(金发科技股份有限公司企业技术中心,广州 510663)
0 引言
改性塑料颗粒的品质对于注塑成型之后的制件性能、外观有很大影响,因此改性塑料颗粒生产过程中的品质检测环节是极其关键重要的环节。
改性塑料颗粒生产过程中的品质检测为出厂前的最后一环,也是保证质量的最后一关,因此在颗粒质量和外观以下方面做要求:塑料颗粒的粒比;塑料颗粒表面是否有黑点以及黑点的大小、个数;塑料颗粒的色差等。现目前行业内普遍的检测方式为人工检测,检测模式为人工巡检的模式:开机生产时做一次品质检测,生产过程中间隔1~2 h抽样500 g,做人工检测。但人工检测的模式有很多不足:首先,人眼检测主观成分很大,受到很多因素的制约对检测结果造成影响,甚至对同样品质的塑料颗粒会造成不同的判断,容易造成误检和漏检,对下游注塑客户的制件造成影响;其次,人工检测的时效性、效率低,每隔1~2 h 的检测频率无法覆盖完全的生产过程,当发现不合格品产生时,已经造成了相应的经济损失;另外人眼检测容易造成视觉疲劳,更加降低了检测质量;最后,人工检测的精度不能满足品质要求,人工检测一般对于黑点、色差、粒径比相对较大的缺陷能够识别出来,对于一些品质要求高的产品,时常发生漏检现象。
随着人工智能、图像检测等技术的不断发展,工业计算机、工业相机、传感器等硬件的成本不断降低,在改性塑料行业采用图像处理技术、在线检测系统去替代人工检测已经成为一种趋势[1]。Park 等[2]针对工件表面的毛刺、划痕、污痕等缺陷难以检测的问题,设计了一种简易的CNN 网络,该方法在实验测试集上准确率为98%。Kyeong 等[3]设计了一种卷积神经网络框架对半导体行业的晶圆仓图进行了分类。Liang等[4]为了解决塑料容器行业复杂背景下在线喷码检测识别的问题,提出了一种基于ShuffleNetV2 的神经网络。上述3 个场景,都是对图片直接分类来实现工件、样品缺陷的检测。大多数场景,用户只关心ROI(Region Of Interesting)区域是否有缺陷,Shang等[5]提出了一种先基于Canny 边缘检测算子分割目标区域,再对目标区域图片搭建卷积神经网络进行缺陷分类计算的模型,在减少模型的运算时间的同时,提高了分类精度,目前广泛用于工业的缺陷检测。
上述CNN 网络都能在一定程度上解决工业上产品表面缺陷检测的问题。目前面临的问题是,虽然成熟或者经过fine-tuning 的成熟网络模型经过训练之后能表现出优秀的性能、鲁棒性及泛化能力,如VGG[6]、Resnet[7]等,但是网络在线推理的时间必须和生产产品的节拍同步,才能满足在线检测的需求。因此模型大小和深度严重限制了工业场景的产业化落地使用。Hinton 等[8]提出知识蒸馏的架构,其核心思想是通过大模型教师网络对轻量化学生网络进行指导。通过保持或牺牲少有复杂模型准确率的基础上,优化了模型的参数以及推理运算耗时,实现了在线成功部署,大大降低了模型部署的成本,特别切合于改性塑料颗粒的在线生产。
本文提出Vgg-16、Vgg-19、Resnet-18 作为教师网络,来指导自主搭建的轻量化残差网络,在保证准确率的基础上减少模型参数,提高模型推理速度,以匹配改性塑料生产线在线高速检测的需求。与此同时,采用梯度加权映射(Grad-CAM)算法可视化学生网络对塑料颗粒样品特征提取的热力图,能对轻量化学生网络的性能做出直观的判断,更清晰地表征了知识蒸馏对学生网络优化带来的作用。
1 图像数据集的建立
本文所用的样品通过在塑料颗粒生产线在线抽样,再通过在实验室搭建图像采集系统获取,采集系统的配置如表1 所示,实物如图1所示。

表1 硬件配置

图1 实验室图像采集系统
图像采集系统由1 个8k 45 kHz 线扫相机、2 个角度约为45°的高亮线扫光源、工作站以及传输装置组成,传送带均速传输保证了线扫相机良好的成像。本次实验采集的图像总数约为6 000 张,数量上基本满足卷积神经网络对样本集的要求,不需要做数据增强或者旋转变换等操作来制造更多样本。图片数据分为OK类和NG类两类,OK类表示合格的样品,NG类表示表面有黑点的样品,比例约为1∶1,样本比例比较均衡,如图2 所示。图像数据集由训练集,验证集与测试集组成,比例为7∶2∶1,70%的训练集保证了模型迭代训练的鲁棒性和泛化能力,20%的验证集用于反向传播过程中的模型参数调优,10%的测试集用于评估模型最终的性能,如表2 所示。
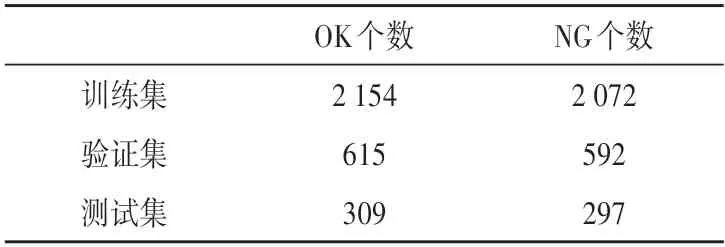
表2 图像数据集
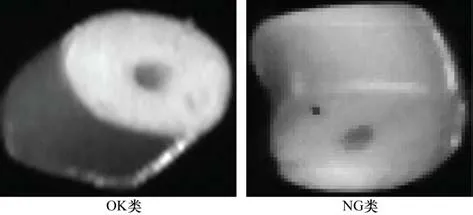
图2 样本分类
2 轻量化网络的搭建
2.1 轻量化网络的组成
本研究搭建的轻量化网络由1 个输入层、10 个卷积层、4个最大池化层、1 个全局均化层和2 个全连接层组成。大量采用残差块来增加模型的鲁棒性,保证了深度网络能更好的提取到样本的特征以及不发生退化以及梯度消失的现象。输入网路的输入图片大小为50×50×1的单通道图像,图像在传入网络之前先进行标准化处理,使得网络更容易收敛。在卷积层末端,通过全局均化层代替flatten 函数把多维特征张量转化为一维向量以减少模型的参数量。再经过全连接层映射为二分类输出,经过softmax 激活函数变化,输出值直接表征图像属于每个类别的概率。网络的详细结构如图3~4 所示。与此同时,轻量化网络从以下几个方面来优化网络,防止过拟合,提高模型的精度和泛化能力:(1)采用LeakyRelu 作为来替代常规的Relu 作为激活函数,能够避免输出值为负时,神经元“死亡”的问题;(2)采用Dropout层防止模型过拟合;(3)大量采用BN 层(Batch Normalization Layer),防止数据输入到激活函数时进入饱和区无法迭代;(4)学习速率的优化方法采用余弦退火的方式,使得网络快速收敛,逃离局部最优点。

图3 轻量化模型基本结构

图4 网络模型结构详细信息
2.2 残差层的作用
在深度学习中,深度卷积网络通过融合各个层次的特征图来加强语义信息。深度卷积网络深度的增加会提高网络的表征能力,从而提高模型的识别率,但是深度的增加,会带来梯度消失与网络退化的风险。通过Resnet网络里的残差模块,可以有效堆叠高中低维度特征,深度网络更加容易训练和拟合,同时加强网络的变现能力和模型的泛化性。
残差模块的原理图及表达式如图5 所示。残差模块有两种堆叠方式:第一种是通过两个3×3 的卷积层去提取网络层次的特征信息,再去堆叠不同层之间的特征图,第二种是通过1×1、3×3、1×1卷积层去实现特征的提取和堆叠。两种方式之间的区别是第二种通过1×1 的卷积层去改变特征图的通道数,再通过3×3的卷积层去提取高层次信息,最后通过1×1的卷积层去调整特征图的通道数,这样一来网络整体的参数会比用两个3×3 的卷积层的参数要少,加快网络的训练速度。

图5 残差模块的两种堆叠方式
低纬度特征图通常只能表征图像的点、线、面、边缘信息,更加丰富的语义信息通常在高纬度的特征图里。本文中通过3 次使用残差块来堆叠图像的特征图,提取到颗粒的语义信息的同时减少了网络训练的困难度,加快了模型的收敛速度。
2.3 余弦退火的学习速率优化方法
训练过程中,学习速率作为十分重要的超参数,变化的趋势为初始时为比较大的设定值,然后通过指数衰减的方式下降。这样一来会造成网络训练初期由于模型不稳定,Loss的波动会比较大,在模型逐步趋向稳定之后,这时的学习速率已经衰减到比较小的值,会有陷入局部最小值的风险。在本文研究的过程中,通过余弦退火[9]的方式去优化学习速率。起初学习速率的变化是一个Warmup 线性增加的过程,这时可以减少由于模型不稳定Loss 波动过大带来的影响。当学习速率达到LRbase点时,再通过余弦函数的关系式去逐步减小学习速率,去匹配模型Loss 减小进入最小点的可能,避免跳过全局最小点。当学习速率达到最小值时,再次采用warmup 热重启的方式去增加学习速率,以跳过网络迭代过程中遇到的局部最优点。余弦退火算法在实际运用中,热重启阶段及下降阶段的变化函数表达式如下:

式中:LRbase为预先设置的学习速率,当warmup 阶段学习速率达到LRbase点时,学习速率开始下降;LRwarmup为热重启阶段设置的初始学习速率;stepwarmup为热重启阶段设置的步长;stepglobal为网络训练的过程中的全局步长;steptotal为网络训练总共的预设步长;LRlinear为热重启阶段的学习速率;LRcosine_delay为余弦下降阶段的学习速率。
本文中优化器使用ADAM反向传播去迭代模型,初始学习速率设置为10-4,分别用plateau 和cos 退火曲线去控制学习速率的变化曲线,Batchsize 样本量设置为64,拟合100 个epoch,分别得到Loss 曲线、验证集val_loss、val_acc 曲线以及学习速率曲线,如图6 所示。由图可知:(1)loss 曲线在经过一定epoch 陷入局部最优值时,通过余弦退火的优化方式,大约在epoch 为60 时,这时学习速率通过warm_up 阶段达到最大值,会产生一种陡峭的大斜率跃阶突变来跳过局部最优;(2)采用余弦退火的优化方式在拟合的最初几个epoch 内,loss 值相比常规通过plateau 去优化方式较低,这样可以在一定的程度上避免模型过拟合;(3)通过val_loss、val_acc 曲线去观测模型的可靠性,可以得出,经过100epoch的迭代,采用余弦退火的优化方式相比常规通过plateau 的优化方式,可以得到更低的val_loss 值以及更高的val_acc 值,由此可以证明,模型采用余弦退火的方式去优化学习速率,可以提高模型的鲁棒性和推理能力。
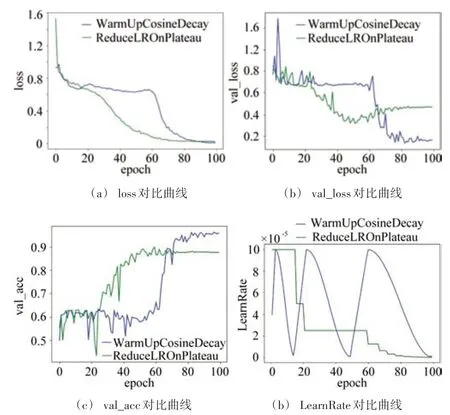
图6 对比曲线
3 多教师模型融合的知识蒸馏颗粒缺陷识别模型构建
3.1 知识蒸馏中的温度参数T
在搭建的轻量化残差网络中,末端softmax 层会把全连接层的logit 输出向量转化为一个概率向量P,用来表示当前样本属于每一个类的概率,每一类概率Pi的计算公式为:

式中:j为分类的总类别个数;Zj为总类别全连接层的logit 值;Zi为当前类全连接层的logit值。
而知识蒸馏引入了一个温度系数T,在计算概率向量qi的时候使得softmax层的输出更加平缓,计算式如下:

温度参数T的值越大,概率函数的分布图就越平缓,模型的软化程度就越大。当温度参数T=1的时候,输出是没有经过软化的概率分布。知识蒸馏通过引入参数T,使得教师网络更多的“暗知识”被蒸馏出来传入学生网络,从而提升了学生网络的性能[10]。
3.2 知识蒸馏网络的搭建
现有研究表明[11],通过多个复杂的教师网络通过知识蒸馏的方式,把“暗知识”传递给学生网络和单一教师网络相比,会明显提升学生网络的模型的性能和泛化能力。此外,教师网络的结构如何和学生网络相比,如果相似度较高也能提高学生模型的性能[12]。本文采用Vgg-16、Vgg-19、Resnet-18 三个复杂网络作为教师网络,对教师网络的训练通过在末端全连接层logit 输出值添加温度参数T的软化,形成3 个软化标签,取软化标签的平均值作为教师网络的输出标签n1。对学生网络的训练分为两部分,第一部分的末端全连接层logit输出进行知识蒸馏系数T软化,形成学生网络软化预测结果m1,第二部分直接得到的概率向量P作为硬预测结果m2。知识蒸馏的流程如图7所示。

图7 知识蒸馏流程
知识蒸馏网络的混合损失函数由两部分组成,第一部分是由n1与m1组成相对熵损失函数,相对熵损失函数(Kullback-Leibler Divergence)定了两个事件的不同程度,当两个概率分布相似时,其相对熵损失函数的值趋近于0。第二部分由m2与真实标签Label 组成传统的交叉熵函数,交叉熵损失函数(Cross Entropy)的作用是表示预测样本标签和真实样本标签之间的差值。混合损失函数的表达式如下:

式中:T为温度参数;Lambda为比例系数,当Lambda=0 时,混合损失函数相当于没有使用知识蒸馏,常规的交叉熵损失函数构成了知识蒸馏网络的损失函数。
4 实验验证
4.1 教师网络与学生网络实验结果对比分析
为了验证知识蒸馏对学生网络带来的影响,选取Vgg-16、Vgg-19、Resnet-18 三个复杂网络作为教师网络,分别训练教师网络、未使用和使用知识蒸馏技术的轻量化残差网络。训练完成后,以精确度、召回率、模型参数、模型浮点运算次数以及单次检测耗时来评估模型的性能,对比结果如表3 所示。实验结果表明,训练完成后,未经过知识蒸馏的学生网络,模型的精确度、召回率分别为88.8%、96.7%,而经过知识蒸馏的学生网络(后面简称KD学生网络),模型的精确度、召回率分别为90.6%、98.9%,相较于未经过蒸馏的网络,2个指标均有较大幅度的提高,精确度和召回率分别提高了1.8%和2.2%,精确度从88.8%提升到90.6%,召回率从96.7%提升到98.9%。实验结果说明了轻量化残差网络经过知识蒸馏过程,教师网络能够传递大量“暗知识”给到学生网络,显著地提高学生网路的性能。

表3 模型实验结果对比
与此同时,学生网络和教师网络相比,准确度和召回率在没有明显降低甚至超过部分教师网络的情况下,模型参数和浮点运算次数以及单次检测耗时大大降低。轻量化残差模型参数为0.643×107,模型浮点运算次数1.288×107,单次检测耗时为0.005 s。3 个教师模型的平均参数量为1.576×107,模型浮点运算次数为3.151×107,单次检测耗时为0.01 s。模型的浮点运算次数和参数量决定了模型的复杂程度。模型越复杂,模型对硬件的要求就越高,相应的部署成本和部署难度就越大。从数据可知,和教师网络相比,模型的参数量、浮点运算次数、单次检测耗时分别降低了59.2%、59.124%、50%。尤其是单次检测耗时的降低为模型在轻量化的边缘侧、移动端、嵌入式部署提供了更大的灵活性以及拓展性。
图8 所示为学生网络以及KD 学生网络验证集准确率函数的过程曲线。模型的训练过程可以表征出模型的可靠性和泛化能力。从学生网络以及KD 学生网络损失曲线的过程相比较,可以看出最开始两者的准确率的值都以比较快的速度上升,两者在epoch 为40 左右时网络逐渐拟合,val_acc 趋近全局最大值。最终学生网路的准确值稳定在0.92 左右,KD 学生网络的准确值稳定在0.96左右,说明通过知识蒸馏网络“暗知识”的传递,训练过程中学生网络在验证集上的表现能力显著上升,模型的性能和泛化能力显著增强。
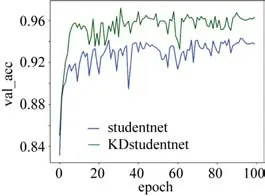
图8 学生网络经过知识蒸馏val_acc前后对比曲线
4.2 类激活热力图可视化分析
类激活热力图是根据输入图像类在当前层的梯度或卷积核权重进行叠加,生成热力图,表达的是图像每个位置对该类的重要程度。从类激活热力图的映射的结果,可以得到网络模型对图像每个位置的判断结果以及对当前类的决策能力,从而指导后续的网络调整以及优化。根据类激活热力图当前类的可视化结果,可以评估当前模型的决策能力以及鲁棒性。
本文通过softmax 层输出值类权重对不同的卷积层反向求导,导数求平均值作为权重加权到每个卷积层输出结果上,根据生成的梯度类激活热力图来评估经过知识蒸馏学生网络模型的可靠性和推理能力。模型部分卷积层的梯度类激活热力结果如图9所示,很直观地表征了模型的推测性能。
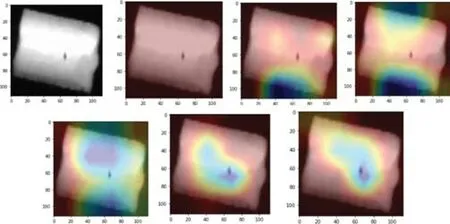
图9 模型卷积层梯度类激活热力图
5 结束语
本文在Intel(R)Xeon(R)Silver 4210 CPU 处理器搭载NVIDIA GeForce RTX 2080 显卡的硬件环境下,采用cudnn7.0 GPU 加速计算包,基于Python 平台,用Tensorflow-keras 算法包实现了模型的搭建、训练、评估验证以及优化器、损失函数、学习速率等超参数的设置。从知识蒸馏前后模型的对比实验结果以及网络类激活热力图可视化分析结果可以得出以下结论。
(1)经过知识蒸馏的学生网络,相较于未经过蒸馏的网络,精确度和召回率显著的提高,说明了本文的方法是可行的。轻量化残差网络经过知识蒸馏过程,能够显著提高模型的性能和泛化能力,通过“暗知识“的传递,达到甚至超过教师网络的性能。
(2)由于轻量化的网络可以大幅度降低模型的推理时间,本文的方法可作为一种通用方法应用于基于深度学习高速检测中以及轻量化部署的边缘侧、嵌入式部署的解决方案。
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
橡塑技术与装备(2023年10期)2023-10-06 13:39:48
现代苏州(2023年12期)2023-07-21 04:33:35
环球时报(2022-12-05)2022-12-05 17:24:48
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
精密成形工程(2022年2期)2022-02-22 05:44:14
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
智富时代(2019年2期)2019-04-18 07:44:42
专用汽车(2016年1期)2016-03-01 04:13:19
