
基于Hadoop和并行BP网络的打车需求量预测系统研究
2022-10-06 04:13孟哲,余粟
计算技术与自动化 2022年3期
孟 哲,余 粟
(上海工程技术大学 电子电气工程学院,上海 200000)
BP神经网络是目前使用最广泛的深度学习算法之一,其模型原理使它在理论上有逼近任何函数的能力,它结构灵活,易扩展,有强大的自学习能力,被广泛地用于预测行为,但是它在面对大数据集时会出现收敛速度过慢的情况,而Hadoop的出现及时地解决了这一问题。围绕着Hadoop搭建的集群可以使计算任务并行运行在集群内的每一个工作节点的计算框架上,针对Hadoop相关平台的各种研究开始层出不穷。
针对目前我国存在的出租车调度问题,围绕Hadoop搭建了一个打车需求量预测系统。并且针对上述提到的BP神经网络的缺点,提出了一种用MapReduce实现的并行BP神经网络将其用于系统的预测功能。通过实验可知并行BP神经网络比传统BP神经网络的收敛速度快得多并且训练效果也有提升。
1 相关理论和技术
接下来介绍本文作搭建的预测系统的核心技术Hadoop和核心算法BP神经网络。
1.1 Hadoop
Hadoop是一个由Apache基金会开发的分布式系统基础架构,它的出现解决了大数据时代下海量数据的存储和分析计算问题。且自Hadoop2.x版本推出以后,Hadoop的核心组件有三个,分别是: HDFS(Hadoop分布式存储文件系统)、MapReduce以及Yarn。
HDFS是Hadoop中的分布式文件系统,它位于Hadoop生态圈的最底层,负责Hadoop中的存储工作,其中NameNode负责管理整个HDFS,DataNode是具体的工作节点,进行存储工作并接收和执行来自NameNode的命令。
MapReduce是Hadoop中的分布式计算框架,负责处理Hadoop的所有计算任务。它分为map和reduce两个阶段,它将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,然后并发的运行在一个Hadoop集群上。
Yarn是一个资源调度框架,它像整个Hadoop集群的大脑一样负责集群内部所有的资源管理和调度,它的存在让Hadoop集群中的各个组件更加协调地工作。
1.2 BP神经网络
BP神经网络分为三部分:输入层、隐含层和输出层。输入层负责向整个网络输入数据,输出层负责输出网络的计算结果,隐含层负责网络中间的一系列计算。
BP神经网络的核心原理就是通过输入层传入隐含层,隐含层进行层层传递和计算,最后传入输出层输出结果。之后对结果和给定值进行误差分析,然后结合梯度下降法以及链式法则层层进行反向传播以更新网络内部的参数。不断循环上述过程最后得到一个理想的网络模型就是BP神经网络的核心思想。
2 并行BP神经网络的实现
BP神经网络虽然有着优秀的自学习能力并且理论上能逼近任何函数,但是在数据量大的情况仍然存在着收敛速度过慢的问题,为了缓解这一问题,本文提出了基于MapReduce的并行BP神经网络来对打车需求量进行预测,并用Hadoop搭建了一个打车需求量的预测系统。
MapReduce在进行神经网络的训练时有优势,也有劣势,优势在于MapReduce是一个基于Hadoop集群的并行计算框架,多个工作节点能同时进行计算来加快网络的训练过程。劣势在于MapReduce不擅长迭代计算,每一次任务结束都要进行落盘操作,这就会造成大量的I/O操作。
2.1 并行BP神经网络的实现流程
为了充分利用MapReduce的并行计算优势并降低其劣势的负面影响,本文提出的并行BP神经网络算法流程如图1所示。
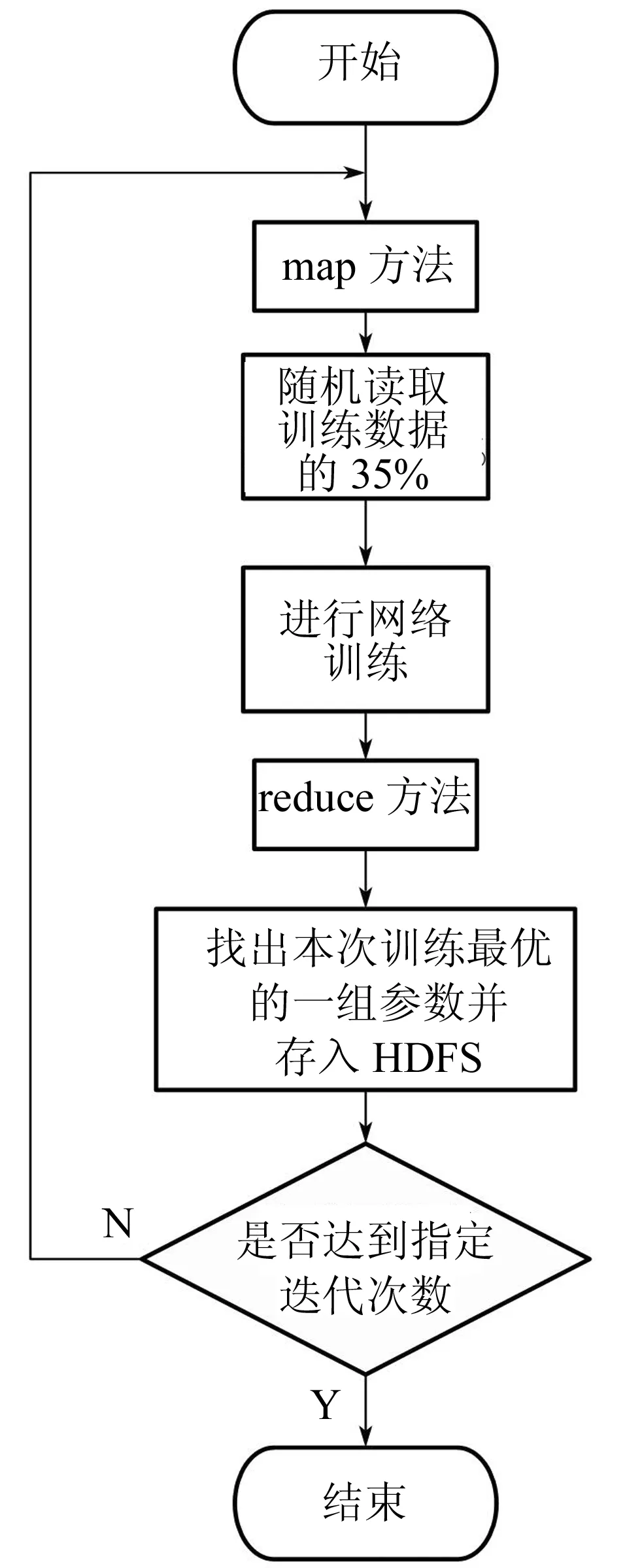
图1 并行BP神经网络流程图
(1)首先将待训练数据集进行随机划分,每个工作节点都读取训练数据集随机划分的35%的数据,并将其传入map端。
(2)节点在map端对这35%的训练数据进行网络的迭代训练,每个节点都在HDFS中有一个唯一的路径文件,用于存储本节点训练过程中的网络参数的变化,节点在训练过程中会不断地对其进行覆盖更新,在训练完成之后将节点自身唯一的编号封装为key,把训练之后以String形式存储的网络内部参数以及对应的误差封装为value,然后将
(3)在reduce端相同的key会传入同一个reduce方法中,在此方法中找出误差最小的一组参数即为一个节点此次训练效果最好的一次,同理找出所有节点下训练效果最好的一组,并将它们之间再进行比较找出所有节点之间训练效果最好的一组并将其保存到HDFS中,上述过程即为一次MapReduce对BP神经网络训练的过程。
(4)再次训练时,在map端将HDFS中上次训练得到的网络参数读入网络内部并继续训练即可。
上述即为本文提出的BP神经网络在MapReduce实现并行的原理和流程。
3 系统搭建和实验
为了证明提出的并行BP神经网络的有效性,搭建了Hadoop集群并进行了一系列实验
3.1 打车需求量预测系统搭建
基于Hadoop搭建了一个打车需求量预测系统,其中整体框架为包含4个节点的Hadoop集群,核心的预测模型为本文提出的并行BP神经网络。
集群4个节点的操作系统皆为Centos7.5,并安装了Hadoop3.2.0以及JDK1.8,它们各自的硬件配置如下:
节点一:Intel(R) Core(TM) i7-10510U CPU 1.80 GHz 2.30 GHz,8 GB RAM, 8-core 处理器
节点二:Intel(R) Core(TM) i7-10510U CPU 1.80 GHz 2.30 GHz,6 GB RAM, 6-core 处理器
节点三:Intel(R) Core(TM) i7-10510U CPU 1.80 GHz 2.30 GHz,4 GB RAM, 4-core 处理器
节点四:Intel(R) Core(TM) i7-10510U CPU 1.80 GHz 2.30 GHz,4 GB RAM, 4-core 处理器
针对4个节点各自的硬件配置,为它们分配的集群角色以及工作如表1所示。
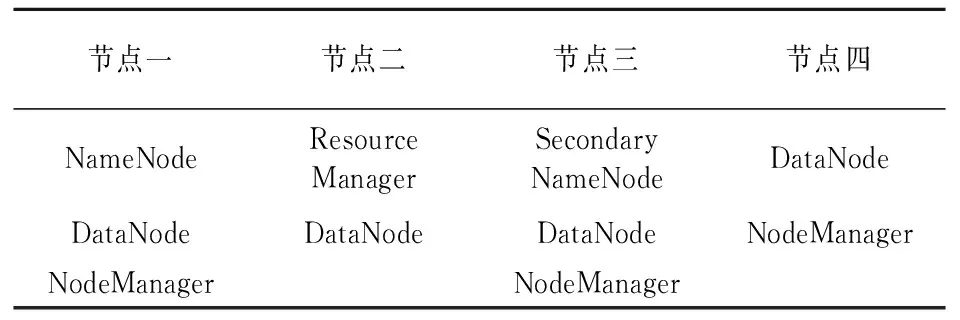
表1 4个节点在集群中扮演的角色
3.1.1 数据预处理
打车需求量预测系统所用数据来源于纽约TLC机构,其官网公开了其机构下的三种出租车每年载客的详细数据,包括载客时间、载客地点、卸客地点等,数据形式是以月为单位存储的csv文件,每个文件都包含了上述提到的总共17个字段。
选用黄色种类出租车2017年和2018年两年的数据作为系统预测模型的训练数据,用黄色种类出租车2019年的数据作为验证数据对训练过后的模型进行预测并对比检验。
而由于原始数据包含了很多系统用不到的无用字段并且缺少一些影响打车需求量的关键因素,所以需要对原始数据进行预处理。
通过分析,推测影响打车需求量的因素包括天气、温度、风力大小、以及节假日等。通过查找资料以及历史数据的方式,将相应的字段以数字的表示方式并且以日期为单位单独写入一组文件中并存入HDFS。之后将原始数据也存入HDFS中,然后通过MapReduce以日期为单位将剔除无用数据后的原始数据和对应日期的上述数据合并得到预处理后的数据文件。此时预处理后的数据即可用于系统模型的训练即预测。
3.1.2 系统架构
搭建的打车需求量系统整体架构如图2所示。
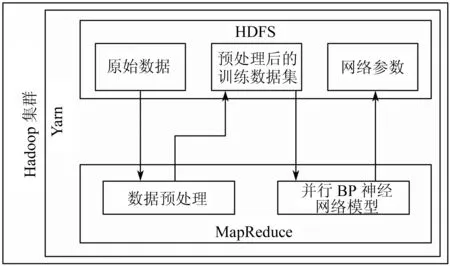
图2 打车需求量系统架构图
(1)所有原始数据会先存入HDFS中。
(2)使用MapReduce对原始数据进行预处理,并将处理后的结果再次存入HDFS中。
(3)经过预处理的数据即为样本数据集,运行系统的并行BP神经网络模型对数据进行训练。
(4)训练完成之后进行预测验证,输出结果。
3.2 模型实验
提出的并行BP神经网络模型的打车需求量的预测实验基于3.1节搭建的系统环境,同时将原始BP神经网络用相同的数据集进行对比实验。
图3展示了两种模型的迭代训练次数以及相应的预测精确度,可以很清楚地看出并行BP神经网络最后收敛时预测的精度为76.2%要高于传统模型的66.2%,并且其收敛速度要快于传统模型。而且图4清晰地展现出并行BP神经网络的迭代计算速度要远快于传统BP神经网络,在完成40000次的迭代计算时,传统BP神经网络耗时25.3 h,而本文提出的并行BP神经网络仅花费16.9 h,大大提高了训练速度。
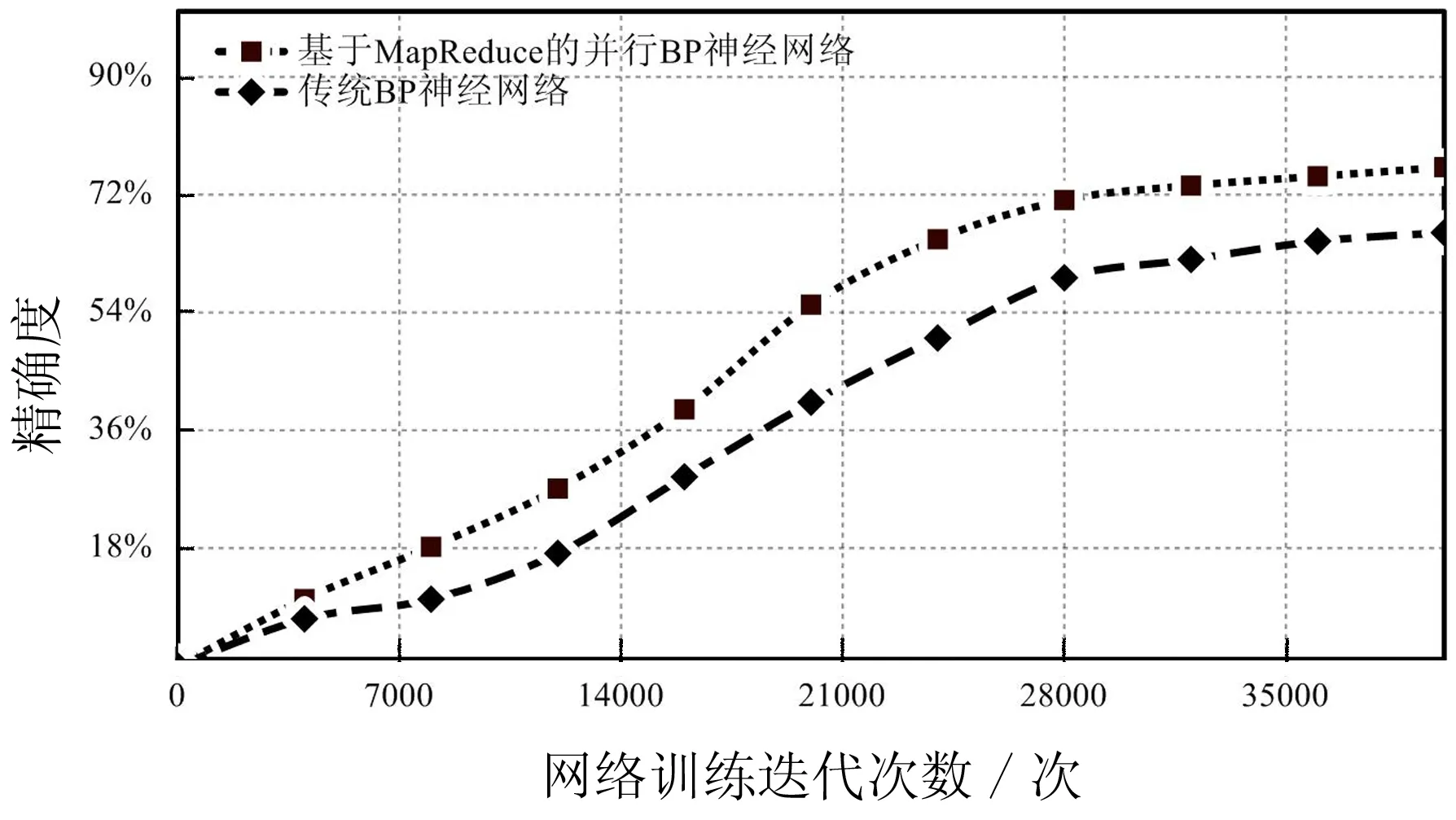
图3 并行BP神经网络与传统BP神经网络的训练效果
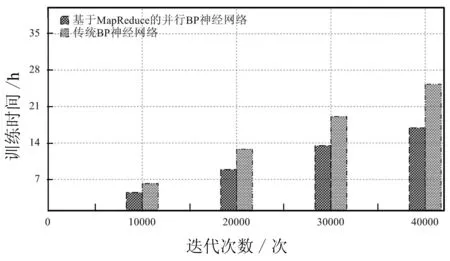
图4 并行BP神经网络与传统BP神经网络的训练速度
为了进一步验证并行BP神经网络的有效性,将验证数据随机分为10组并分别用并行BP神经网络和传统BP神经网络进行预测,并将两种模型得到结果的平均绝对误差和平均绝对百分比误差进行比较。如图5所示,并行BP神经网络在对10组数据进行单日某区域的出租车需求量预测时的平均绝对误差都在180以内,并且稳定性较好。而传统BP神经网络的平均绝对误差大都超过了270,并且波动较大。图6为两种模型的平均绝对百分比误差对比,可以明显看出传统BP神经网络的平均绝对百分比误差比并行BP神经网络高很多,在29.8%~40.2%之间并且波动较大,而后者的平均绝对百分比误差在20.3%~26.7%之间。
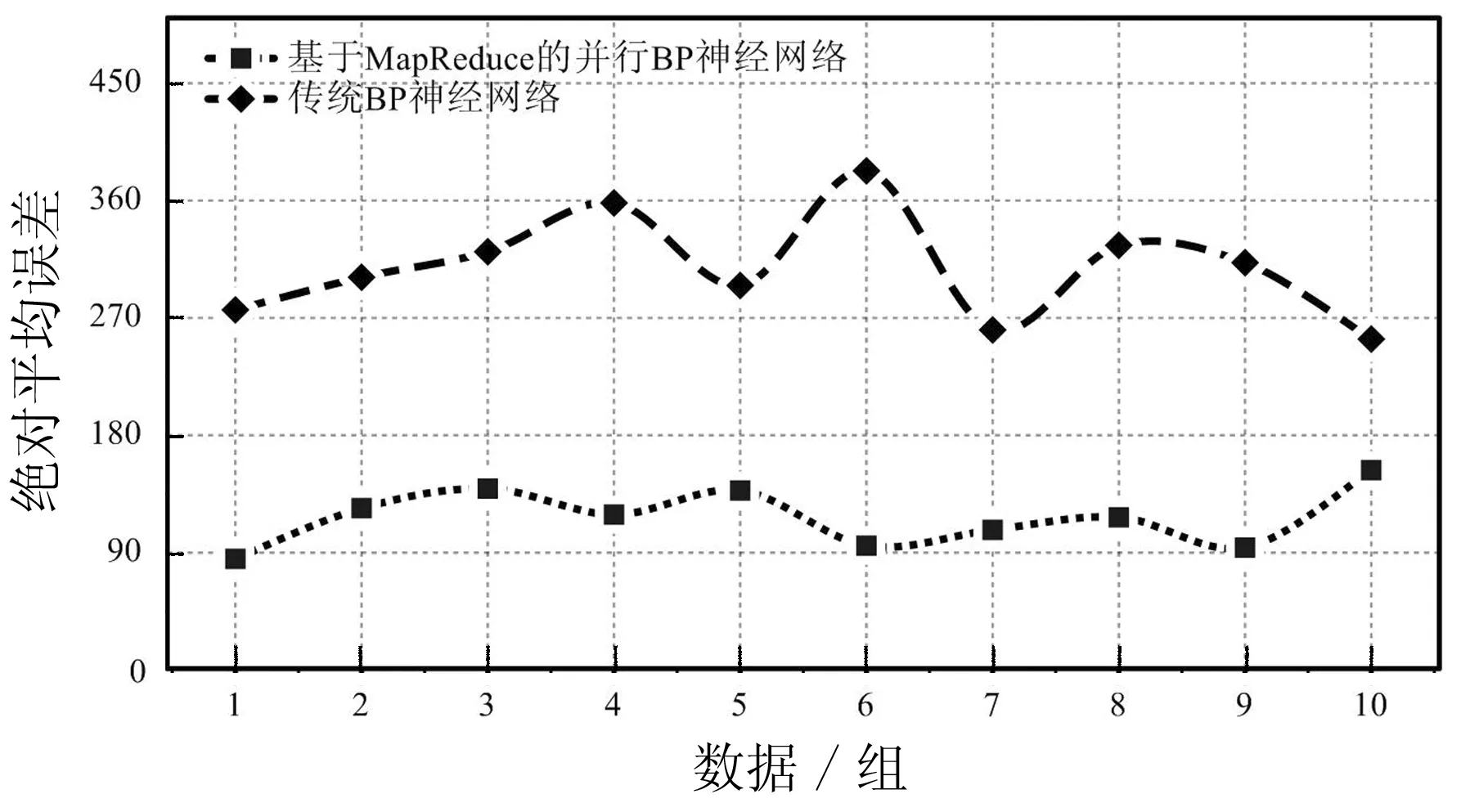
图5 并行BP神经网络与传统BP神经网络的平均绝对误差对比
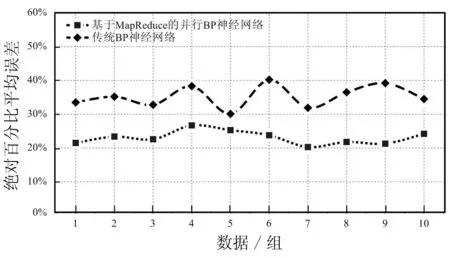
图6 并行BP神经网络与传统BP神经网络的平均绝对百分比误差对比
上述两组实验可以充分证明本文提出的并行BP神经网络的有效性,其比传统BP神经网络有更快的收敛速度,并且训练效果更好,拥有更高的预测精度和更小的误差,能较好地完成出租车需求量预测的任务。
4 结 论
提出了基于MapReduce的并行BP神经网络,与传统BP网络相比,其收敛速度加快并且训练效果更好,同时训练速度大大提高。并且针对我国目前存在的出租车调度问题,搭建了一个打车需求量预测系统,以并行BP神经网络作为本系统的预测模型。通过对TLC的公开数据进行训练和预测验证可知系统能较好地完成打车需求量预测的任务,给交通系统和出租车公司对出租车调度提供帮助和参考。
未来的工作主要有以下两个方面:一方面,优化并行BP神经网络的细节,找到更优的用MapReduce实现并行BP神经网络的方法。另一方面,优化Hadoop系统的搭建,包括数据的传输、预测结果的展示等。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
数学大王·中高年级(2021年6期)2021-09-27
软件(2017年6期)2017-09-23
知识就是力量(2017年2期)2017-01-21
建筑工程技术与设计(2015年21期)2015-10-21
