
基于GF-2影像的南疆阿拉尔垦区绿洲作物种植区高精度提取研究
2022-09-28 06:14:30王玉珍高琪白建铎彭杰
塔里木大学学报 2022年3期
王玉珍,高琪 ,白建铎 ,彭杰*
(1塔里木大学农学院,新疆 阿拉尔 843300)
(2昌吉州地质环境监测站,新疆 昌吉 831100)
我国是世界人口第一大国,粮食需求量大,农业快速发展对我国粮食安全和社会稳定具有重要意义,因此及时准确地了解农田地块的范围和位置对农业监测、粮食产量评估具有重要作用[1]。传统的人工调查不仅耗费大量的人力物力,而且资金投入高,随着遥感技术的快速发展,利用遥感手段进行农田信息提取克服了传统调查方法的不足,且逐渐成为研究热点[2]。
已有研究多利用中低分辨率遥感影像提取农田信息,尽管提取速度快,但提取精度低,无法获得精确的农田地块信息,仅适用于大范围农田耕地信息监测[3]。高分辨率遥感影像的出现,使得高效、精确和低成本农田测绘成为可能[4]。高分辨率影像能够清晰、准确表达地物的边界、形状、表面纹理、内部结构和空间关系,可以充分利用高分辨率遥感影像进行农田地块信息提取,且提取结果从数量和空间分布上也更为可信[5]。近年来,利用高分辨率遥感数据提取地物的研究日益增多。丁相元等[6]基于高分一号卫星时间序列数据研究土地分类识别技术,提出了利用高分辨率单时相原始遥感影像和时间序列NDVI数据结合进行沙化土地遥感分类的新思路;陆昳丽[7]从植被光谱特征和边缘特征两个方向,详细探究了面向对象的高空间分辨率遥感影像农田目标的识别和提取方法。这些研究所用数据源均为高分辨率影像,有效避免了部分像元混分的问题。因此本研究选择国产高分二号影像为数据源,探究其高精度提取农田信息的潜力。
尽管利用高分辨率遥感影像提取地物信息十分方便,但是基于像素的分类方法仅考虑影像的单一像素光谱特征因素,该方法已较少用于含有丰富信息特征的高分辨率影像信息提取。而面向对象的分类方法更注重对象特征的空间相关性,因此采用面向对象的分类提取方法成为目前国内外学者研究的焦点问题[8]。目前面向对象影像分析已经逐渐成为高空间分辨率遥感信息提取的主流技术[9],对于高分辨率遥感影像数据,面向对象分类可以充分利用其丰富的光谱、形状、纹理、大小等特征更好地区分地物。WATKINS B等[10]通过改进基于目标的图像分析方法,实现了分时段Sentinel-2图像中5种不同农业景观的农田自动识别与轮廓检测,总体精度高达83.6%。面向对象分类方法极大提高了地物分类提取精度,故本研究选择两种较为典型的分类器算法对农田地块展开研究。此外,近年来深度卷积神经网络(CNN)在遥感图像处理领域受到了很大的关注,因为其能够从训练集中以分层的方式自动学习具有代表性和区别性的特征[11]。郭文等[12]采用一种注意力增强的卷积神经网络,实现了从卫星遥感影像中自动提取建筑物。WALDNER F等[13]使用 ResUNet神经网络模型解决多任务语义分割问题,从卫星图像中提取农田边界。因此本研究又尝试采用加入注意力模块的卷积神经网络模型提取农田信息。
鉴于已有研究运用面向对象方法以及深度学习在影像分类提取中所表现出的优势,本研究以阿拉尔垦区部分区域为研究区域,该垦区为典型的灌溉农业区,农业机械化作业程度高,土壤盐渍化问题突出。因此,农田周边分布有农机通行的机耕道,用于灌溉的灌渠和排除盐碱水的排碱渠。利用中低分辨率影像进行农田信息提取时,由于混合像元问题,该部分面积通常被计算在农田中,导致农田统计面积往往大于实际种植面积。针对这一问题,本研究以高分二号(GF-2)遥感影像为数据源,采用面向对象分类法中的两种分类器以及深度学习方法提取农田种植区并比较分类精度,最后将提取农田地块面积与实际农田种植面积对比,计算农田识别精度,为高精度提取耕地信息提供新的方法和技术。
1 材料与方法
1.1 研究区概况
研究区位于新疆维吾尔自治区南部的阿拉尔垦区部分区域内(80°30′~81°58′E,40°22′~40°57′N)如图1所示,该垦区地处阿克苏地区境内,北起天山南麓山地,南至塔克拉玛干沙漠北缘,东西相距281 km,南北相距180 km,总面积约为4 197.58km2。阿拉尔垦区气候类型为暖温带大陆性干旱荒漠气候,年均降水量少,地表蒸发强烈,地势由西北向东南倾斜。垦区内光热资源丰富,适宜耐旱作物棉花的生长,棉花是垦区内种植面积最大的作物,垦区棉田周围田埂极其宽阔,用于通行大型农机,如大马力拖拉机和采棉机。由于土壤盐渍化严重,盐碱地广布,故在盐碱地中或周围开挖用来排碱的渠,用这些排碱渠改良土壤,减缓盐碱程度。为验证本研究所采取方法的有效性,本研究选取垦区内地物类别相对丰富并靠近垦区中心的地区作为研究区域,其中研究训练区作为研究区的一部分用于制作深度学习样本数据集。
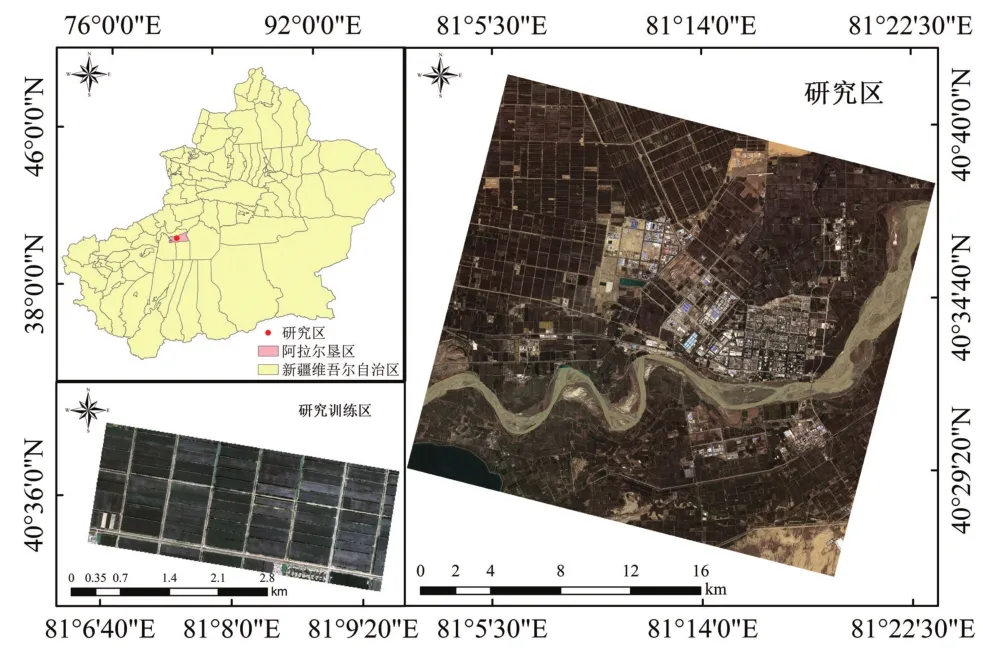
图1 研究区位置
1.2 遥感数据源及其预处理
高分二号影像是我国目前分辨率最高的民用陆地观测卫星,搭载有两台高分辨率相机,分别是0.8 m全色、3.2 m多光谱相机[14]。高分二号卫星参数如表1所示。为精确识别农田周围田埂级别地物,本研究使用的高分二号影像成像时间为2020年9月16日。该时相影像农田植被较为旺盛,与其他地物光谱差异显著,区分度较好。影像数据包括红、绿、蓝、近红外四个波段,将获取的影像通过ENVI 5.3软件进行大气校正、正射校正、裁剪融合等预处理过程保存为图片格式,为制作数据集做准备。

表1 GF-2影像参数
1.3 面向对象机器算法分类提取
1.3.1 影像多尺度分割
eCognition中影像分割是分类的第一步,选取合适的分割参数进行分割,为后续分类奠定基础,否则将会直接影响后期的分类效果。由于本研究目标是提取农田地块,所以只建立一个分割层保证农田地块的分割效果。本研究采用多尺度分割算法,该算法主要由影像对象的光谱(color)和形状(shape)的异质性决定影像的异质性[15]。影像异质性按照下列公式计算:

式(1)中,wc为光谱信息的权重值;ws为形状信息的权重值,且wc+ws=1;hc为光谱信息异质性的值:hc=Σwb·sb,wb为各波段权重;sb为各波段的标准差值;hs为形状异质性的值,包括光滑度(smooth)和紧凑度(compactness)2个指标,根据公式(2)计算为:

式中,ht为紧凑度;hc为光滑度;wt和 wc分别代表ht和 hc的权重,即 wt+wc=1
基于上述过程,参考eCognition 9.0软件中的ESP(Estimation of Scale Parameter)插件,在尺度参数分析工具(Scale Parameter Analysis)中进行多次参数设置,利用局部方差(local variance,LV)的变化率值(rates of change,ROC)结合目视解译确定最优尺度,当LV的变化率值最大即出现峰值时,该点对应的分割尺度即为最佳尺度[16]。图2所示为设置不同尺度参数和形状因子的分割效果对比图。本研究最终将分割参数设置如下:尺度参数为1.5;形状因子权重为0.000 5;紧致度因子权重为0.5。在最优分割尺度设置下,影像被分割为142 550个像元,后续基于该分割尺度的分割像元进行分类。

图2 不同分割尺度下的分割效果
1.3.2 CART分类器分类
决策分类回归树(classification and regression tree,CART)是Breiman提出的一种二分递归分割技术,它将包含测试变量与目标变量构成的训练数据集进行循环迭代分为两个子样本集,使生成的每个非叶子节点均有两个分支,进一步形成二叉树形式的决策树结构图[17]。该算法是挖掘数据常用的一种方法,可将复杂的决策形式过程抽象成易于理解和表达的规则和判断[18]。这种分类方法可将复杂的分类问题简单化,按照一定的规则将遥感数据集逐级向下细分最终得到不同属性的各个子集,其基本思路是不局限于使用一种算法,一个决策规则就将所有类别一次性分开。
1.3.3 随机森林分类
随机森林(random forest,RF)是将多棵树集成为一种的算法,它的基本单元是决策树。该算法每棵树的训练样本均由初始选择的样本“随机”产生[19],所有的树都以相同的特征但是以不同的训练样本进行训练,分类过程中根据每棵树所对应的样本的投票数决定该样本所属的类别,RF分类法提取速度较快[20],常用于面向对象分类领域。
本研究根据第三次全国《土地利用现状分类》[19]、阿拉尔垦区土地利用现状图和本研究选用影像的季相特点,将研究区主要分为农田、林草地、园地、水体、建设用地、其他六大类[21]。其中,其他地类包括沙地、裸地、盐碱地等。本研究在CART和RF分类实施过程中,先结合原始影像与野外实地调查经验选取训练样本,各训练样本的分布遵循均匀、全方位覆盖的原则选取建筑用地(包括道路)、农田、林草地、园地、水体以及其他地类(包括盐碱地、裸地、沙地等)共1 749个训练样本。其中建筑用地230个、农田251个、林草地77个、园地230个、水体461个、其他500个,基于这些样本进行分类。首先将分割后的矢量转化为样本,然后运用不同分类器训练样本,最后将训练的样本应用到影像中得到分类结果。
1.4 深度学习方法提取
1.4.1 卷积神经网络模型结构
卷积神经网络(convolutional neural network,CNN)是一组使用卷积运算的深度神经网络,由于可以利用图像从局部到全局的特征,因此在图像分析中得到广泛的应用[22]。本研究根据高分二号影像的特点采用基于注意力机制的U-Net模型对研究区农田进行提取,该神经网络模型是基于PyTorch深度学习框架搭建的,包括上采样和下采样部分,上采样和下采样左右对称,形成“U”型结构。如图3所示,下采样部分用来捕捉图像详细特征,通过卷积部分形成特征图,由编码器完成。上采样部分将特征图进行反卷积,由解码器完成并与编码器部分提取的特征联系起来,使网络最大程度保留基本的原始特征信息[23]。如图4所示,本研究将注意力机制加入到编码器和解码器中形成的特征图拼接之前,从通道注意力模块和空间注意力模块两个维度对特征图进行推断,以达到优化图像特征的目的。

图3 U-Net模型结构图

图4 U-Net注意力模块图
1.4.2 模型训练
通过U-Net模型并加入注意力模块对影像进行分割,实验数据采用研究区部分高分二号影像,通过ArcGIS Pro软件人工标记农田与非农田并导出为深度学习数据集[24],其中不同波段三通道组合样本各348个以及相同数量对应的标签影像。为提高模型的训练速度和精度,将数据集中的影像通过滑动窗口裁剪为256×256像素大小,并对数据通过旋转、翻转等手段进行扩增[25]。按照深度学习数据集3:1的比例划分为训练集和测试集。最后在实验室提供的硬件GTX1080Ti 11GB显卡下进行模型训练并测试。模型中涉及的部分参数见表2。

表2 U-Net模型参数设置
2 结果与分析
2.1 面向对象分类结果
影像分割结束后,结合同时期影像对象的光谱、形状特征及纹理信息等,采用CART、RF分类方法对阿拉尔垦区一景高分影像进行分类,最后利用eCognition的部分修改功能进行分类后处理,将分类时错分和误分的对象判别到正确的类别当中,结果如图5所示。图5显示了两种面向对象分类方法的最终结果以及部分相同区域的细节,从分类结果图中可以得出,两种分类器算法在阿拉尔垦区土地利用分类中取得了不同的分类视觉效果。从局部放大细节处可得出在分类过程中CART和RF分类法都存在错分、漏分现象;比如细节处所显示的农田、林草地和园地这三种地物类型混分严重,影响最终的农田提取,这主要是三种地物类型在分类时的光谱特征相似所导致,即“异物同谱”现象导致的问题。
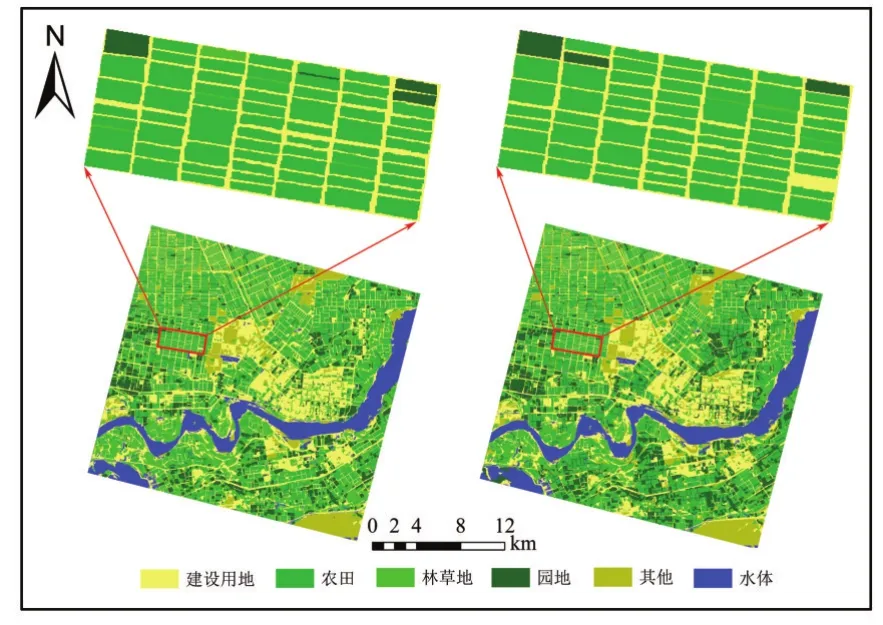
图5 CART和RF分类结果图
2.2 CNN模型识别结果
本研究使用加入注意力模块的U-Net卷积神经网络模型进行训练,并利用训练好的模型对测试数据进行农田提取,训练过程和测试精度如图6。

图6 CNN训练过程及测试精度
由图6A中分析可知,模型训练损失率在3 k次以后逐渐趋于稳定,模型训练过程中将最优模型参数自动保存。采用保存的最优模型对影像进行语义分割。分割的图像即训练过程中不包括的测试集图像[16]。测试结果如图6B所示,测试精度在120次趋于稳定,最终精度为90.46%。最终测试影像结果如图7所示。分析可知,大部分清晰的农田边界可以被提取出,但是仍存在农田与非农田的混分现象,出现未被识别的农田边界。虽然利用CNN模型仍存在误分现象,但是农田边界的提取效果更接近人工标注真实标签,提取效果较好。

图7 测试提取效果
2.3 面向对象与深度学习方法精度对比及验证
为了直观比较两种方法对农田的提取效果,需要对比两种分类方法的精度。将提取结果图进行局部放大并结合天地图影像进行实地调查,将分类后的错分像元剔除并对边缘进行细化,以提升分类精度。验证时根据两种方法的分类效果建立混淆矩阵,混淆矩阵包括用户精度(User Precision,UA)、制图精度(Producer Precision,PA)、OA值和 Kappa系数等。由于CNN模型为二分类,因此在精度评价与验证时将面向对象方法中的除农田外的其他类别都用非农田来计算。由表3中可以直观比较出,RF分类所得的OA值为78.79%,Kappa系数为0.57,在分类方法中最低;CART分类法OA值为80.29%,Kappa系数为0.61,相比RF分类法结果有所提升;CNN提取效果最佳,OA值为95.24%,Kappa系数为0.84。
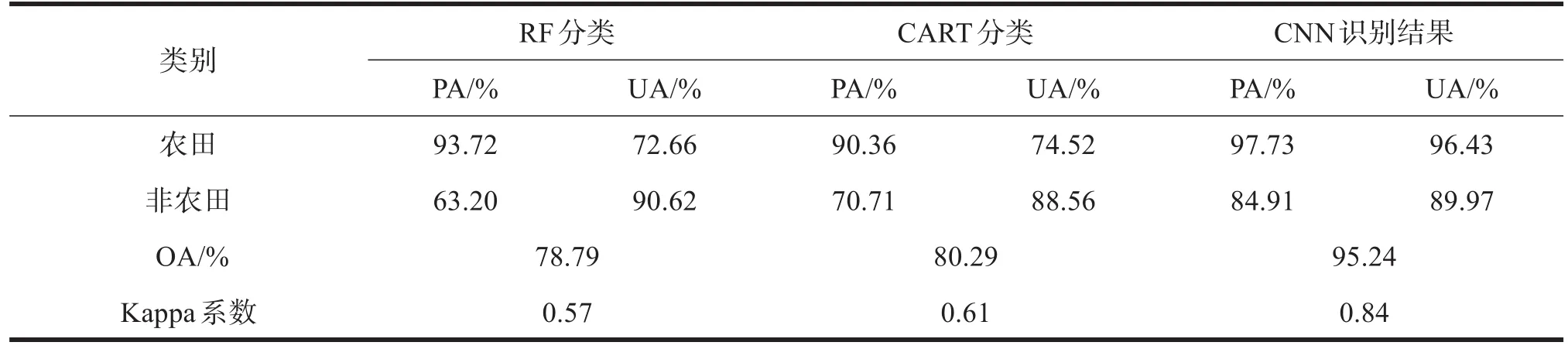
表3 CART、RF、CNN识别农田精度对比
2.4 农田种植区提取精度对比
本研究最终目的是提取农田种植面积信息,为了筛选一种最优的农田种植区提取方法,以一块经过实地量测的农田区域为验证区域,对比面向对象与深度学习提取方法的实际精度,统计不同方法的识别精度,农田识别精度为分类农田种植面积与实际农田种植面积的百分比。统计结果如表4所示。分析可知,面向对象与深度学习方法的农田种植区提取面积与实地调查所得面积相比差异不大,这主要是因为高分二号影像具有很高的空间分辨率,能有效识别出机耕道、灌排渠和防护林等非农田种植区,显著减少了像元混分现象。基于分类精度最高的CNN方法提取的农田种植面积与实际农田种植面积最接近,且提取面积识别精度高达93.05%;而基于CART分类法提取的农田种植面积与实际种植面积相差47.45 hm2,提取面积识别精度为92.40%;识别精度最低的RF分类法提取的农田种植面积与实际种植面积相差最大,提取面积识别精度最低,为90.15%。造成面积误差的主要来源是农田种植区域和田埂交界处为混合像元,易错分、漏分,导致提取农田的种植面积与实际农田种植面积存在误差。综合比较三种方法的分类精度、农田种植面积识别精度发现,CNN方法不仅农田分类精度高而且面积提取精度也高,RF和CART分类器算法虽然面积识别精度高,但是分类精度较低,因此基于注意力模块的CNN深度学习方法不仅可以高精度识别农田,还可更准确提取农田种植面积信息,因而深度学习方法可为未来垦区耕地种植面积监测以及粮食产量评估提供一定的理论参考意义。

表4 三种方法提取农田面积验证精度对比
3 结论与讨论
本研究基于高分二号数据,采用面向对象和深度学习方法提取农田种植区域。其中面向对象方法以影像中四个波段的光谱特征指数为基础并结合影像形状指数特征和纹理特征,选取CART和RF两种分类器提取农田;深度学习方法引入一种加入注意力模块的U-Net网络识别农田信息,结果表明:基于加入注意力模块的U-Net模型识别农田精度最高,效果最好,总体精度可达95.24%,但深度学习对硬件要求高,模型在一般设备上耗时较久,经记录有5.5 h;CART分类效果次之,OA值和Kappa系数居中,RF分类效果最差,其OA值和Kappa系数分别为78.79%和0.57,但面向对象分类方法分类器运行时间均较少约2~3 h,综合比较,深度学习方法更能为高精度提取耕地信息提供新的方法和技术。此外,基于分类精度最高的深度学习方法,其提取的农田面积与实际种植面积相比误差较小,识别农田面积精度高达93.05%,这一结果与张宏鸣等[26]基于改进U-Net识别葡萄种植区所得精度相似;相比基于面向对象的分类方法和基于像元的分类方法,本研究中的深度学习方法在提取农田的面积和精度方面都有较好的优势,再次说明该方法对垦区耕地种植面积精准监测、粮食产量评估具有一定的参考意义。但本研究仅讨论了该方法在有限范围内的空间可转移性,在未来的研究中,整个垦区甚至整个国家的空间转移仍有待探索[27]。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-28 01:37:47
电子测试(2018年15期)2018-09-26 06:01:34
电测与仪表(2017年24期)2017-12-19 05:15:24
发明与创新(2017年3期)2017-01-18 05:14:04
新疆农垦科技(2016年2期)2016-08-21 13:50:18
农家科技中旬版(2016年12期)2016-04-16 03:41:29
现代计算机(2016年12期)2016-02-28 18:35:25
卫星与网络(2016年12期)2016-02-05 09:23:26
新疆农垦科技(2014年9期)2014-02-28 19:20:53
新疆农垦科技(2014年5期)2014-02-28 19:20:02
