
基于前向注意力机制的长句子语音合成方法
2022-09-28 14:50田泽佳卓奕炜
电子设计工程 2022年18期
田泽佳,门 豪,卓奕炜,刘 宇
(1.武汉邮电科学研究院,湖北武汉 430074;2.南京烽火天地通信科技有限公司,江苏 南京 210019)
语音合成在人工智能领域有着十分广泛的应用场景。随着对神经网络技术的深入研究,基于深度学习的语音合成极大程度上改进了传统语音合成技术,降低了行业门槛。文献[1-2]最早使用基于常规注意力机制的序列到序列方法进行语音合成的探索。文献[3]提出全新的语音合成模型Tacotron,其基于常规注意力机制实现了首个端到端的语音合成模型。针对语音合成长句子存在的漏读、重读问题,有很多改进的方法,如文献[4]引入一个卷积窗的约束,对注意力机制本身进行改进,将全局注意力机制转换为带卷积窗的注意力。文献[5]模型使用了自注意力的方法,能够在更少参数的情况下快速对齐语音帧。
该文针对长句子语音合成中存在的漏读、重读等问题,提出前向注意力机制,该机制能够充分考虑文本序列中前后时刻的关系,利用前一时刻语音帧的注意力得分平滑当前时刻的注意力得分,消除注意力计算过程中的异常点,提高长句子合成的质量,比基线模型具有更快的收敛速度,提高了语音合成的效率。
1 前向注意力机制
该文提出的前向注意力机制主要对常规注意力[6]中注意力得分的计算过程进行改进,其核心思想是利用前一时刻生成的正常得分来平滑当前时刻的注意力得分。
通常,注意力机制的基本结构为编解码器[7],其结构由递归神经网络组成[8],在计算流程上,将输入的文本序列x=(x1,x2,···,xt,···,xT)转化为语音序列y=(y1,y2,···,yt)输出,这里xt为第t帧特征向量;yt为当前t时刻解码器输出;每个yt可能对应一个或者多个xt。具体过程:首先通过编码器将输入的文本特征序列x生成相对应的更适合注意力机制处理的特征序列H=(h1,h2,···,ht):

其中,Encoder(·)是编码器的操作,它通常由一个双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)[9]组成。H∈RD×t为特征序列向量,D为网络神经元个数,即特征序列向量的维度,ht为第t帧特征序列。
其次是注意力部分,利用编码器的输出、前一时刻解码器的输出以及注意力部分的信息,计算当前时刻的注意力得分αj:
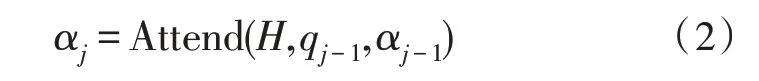
其中,Attend(·)为注意力的计算,qj-1为前一时刻解码器的输出,αj-1为前一时刻注意力的得分。
通过对上述注意力机制的计算过程进行分析发现,在注意力得分的计算中没有施加约束,而是只计算了单个语音帧的分数,但是实际上每个音素往往包含几十个语音帧,这就会导致同一音素内不同帧之间的注意力得分异常,导致相关语音帧存在较大偏差,从而造成语音重读问题。因此,该文对上述注意力得分进行了改进,将新的注意力得分记为,在计算得分时,对当前时刻的注意力得分用前一时刻l帧的注意力得分之和加以约束。同时,为了简化计算,只考虑前一时刻关注的语音帧与其相邻帧之间的关系,以提升平滑效率,公式如下:

最后,再利用式(4)对式(3)得到的结果进行归一化处理,得到前向注意力得分。再利用得到的结合隐含状态向量便得到上下文向量:

上述方法利用了前一时刻得到的前向注意力得分来平滑当前的异常分值,达到消除异常点的目的,同时保证不同语音帧注意力得分之间的连续性,确保合成语音的单调性,提高模型训练效率。在实际训练和后续测试中,长句子合成质量有明显的提升,未出现重读和漏读问题。
2 带约束的前向注意力
前文提出的前向注意力机制能够有效解决长句重读、漏读问题,但在分析其基本方法的过程中,发现式(3)中的在前l个语音帧中发挥影响的程度不一致,并且前一时刻关注的语音帧在当前时刻不能保持完全相同,因此需要对前一时刻的前l语音帧添加新的约束,并动态调整注意力得分的重要度,以自适应的方式解决异常点问题,提高平滑效果,确保合成语音的自然度。因此,在前一方法的基础上,提出了带约束的前向注意力机制。具体的做法为采用具有一个隐藏层和sigmoid 激活单元的深度神经网络(Deep Neural Networks,DNN)作为过渡代理,产生约束因子uj,用来动态地控制对齐过程中向前移动或停留的动作,如式(6)所示:

其中,uj∈Rl为当前时刻DNN 利用前一时刻qj-1、cj-1、oj-1产生的约束因子,qj-1为解码器状态,cj-1为DNN目标向量,oj-1为上一语音帧的输出序列。
利用式(6)产生的约束因子能够对前一时刻的注意力得分加以约束,可以减少注意力得分之间的差值,注意力得分较高的语音帧重要度可能会下降,注意力得分较低的语音帧重要度可能会上升。通过引入该动态调节机制可以使得分值更加平滑。于是对式(3)进行改进,便得到如下新的计算公式:

其中,uk,j代表当前j时刻k个语音帧的约束因子,乘上该因子可以达到约束的目的。故通过式(4)对式(7)得到的结果进行归一化处理,可得到新的注意力得分
前文中提出的带约束的前向注意力机制也可以从专家产品模型[10](Product of Experts,PoE)的角度来思考。PoE 模型的核心思想是通过将各自独立的模块组合到一起,然后将模块各自的输出进行归一化,每个模块相当于一个软约束。在该文提出的带约束的前向注意力机制中,式(6)相当于为单调对齐的任务添加一个约束,任务中的另一个约束为αi,j,即原注意力概率,带约束的注意力得分便是基于这两个约束的乘积。因此,不满足单调对齐条件的路径的注意力得分较低,以此达到单调对齐的目的。
常规的序列到序列声学模型难以做到控制合成语音速度,而该文提出的带有约束的注意力机制可以实现该功能。在语音合成的过程中,对DNN 网络[11]中的sigmoid 输出单元添加正偏置或者负偏置,会使带约束的注意力得分增加或者减少,进而影响参与注意力计算的音素移动的快慢,从而可以达到控制合成语音合成速度的目的。
3 实验与分析
3.1 实验条件
该文中实验的操作系统为Ubuntu18.04,显卡使用的是NVIDIA GeForce GTX 2070S,处理器为Intel i5-5200U,内存为16 GB,主频为3.2 GHz,程序基于Tensorflow 1.3.0 深度学习框架。
实验中使用了公开的标贝女声数据集。该数据集为一位女性专业人士录制的普通话语音数据集,整个数据集音频有效时长约为12 小时,采样格式为无压缩PAM WAV 格式,采样率为48 kHz。录音语料涵盖各类新闻、小说、科技、娱乐、对话等领域。数据集由10 000 个话语以及相对应的文本拼音标注组成,划分为训练子集、验证子集和测试子集,分别包括8 000、1 200、800 条语句。
3.2 实验过程
该实验针对基线模型Tacotron2 语音合成模型[12]中存在的重读、合成效率低等问题,采用控制变量的方法,使用该文提出的前向注意力机制替换原模型中的带卷积窗的注意力,完整的网络结构如图1 所示。完整的语音合成是基于序列到序列架构的模型,模型分为两部分,第一部分是频谱预测网络,负责从文本和音频中提取出特征序列向量,并通过注意力机制获取两个特征序列向量的映射,最终输出预测的梅尔频谱图;第二部分为WaveNet 神经声码器[13],用于将梅尔频谱图[14]转化为声音波形输出。语音合成模型的核心为注意力机制,由编码器和解码器两部分结构组成。编码器部分由3 个卷积层和一个BiLSTM 组成,卷积层的作用与N-gram 相似[15],具备感知上下文的能力,解码器由预处理网络和两个LSTM 层组成。文本序列首先由卷积层提取上下文信息,然后传递到BiLSTM,用以生成编码器隐状态,之后通过注意力机制生成编码向量,再由解码器将该向量和LSTM 的输出连接后,送入到解码器端的LSTM,计算出新的编码向量,该向量再与LSTM 的输出拼接后,进入后处理网络,用以预测频谱。整个实验中,采用的基线模型为带卷积窗的注意力机制的Tacotron2 语音合成模型,其基本的编解码器网络结构与该文所采用的网络结构相同,唯一不同的是注意力得分的计算部分。

图1 基于前向注意力机制的语音合成模型示意图
3.3 实验结果及分析
该文讨论了在不同注意力机制下的序列到序列模型在语音合成中的效果,以评估不同注意力机制下声学特征生成的稳定性。从测试集中随机选择120 条文本进行语音合成,其中最长的语句大致有100 个字,采用MOS 评分法[16-17]对合成的语句进行主观评估。该文共建立了4 种基于序列到序列的声学模型,分别为基于常规注意力机制(记为Att_None)、带卷积窗的注意力(记为Att_Win)、前向注意力(记为Att_For)、带约束的前向注意力(记为Att_ForTA)。几种注意力机制下的MOS 得分情况如表1 所示。

表1 不同方法的MOS得分
由表1 可以看出,在使用前向注意力机制方法后,合成的语音质量相对于常规注意力机制和带卷积窗的注意力机制都有了一定程度的提升,其中相比于基线模型Tacotron2,合成语音的MOS 得分提升了2.5%,原因在于该方法在不影响合成语音质量的前提下,解决了长句子合成中存在的重读、漏音等问题,提升了语音合成的自然度。
同时,该文还使用前向注意力机制的声学模型和基线模型合成同样长度的句子,对这两种方法的特征预测网络对齐情况和预测的梅尔声谱图进行了对比,如图2 所示。
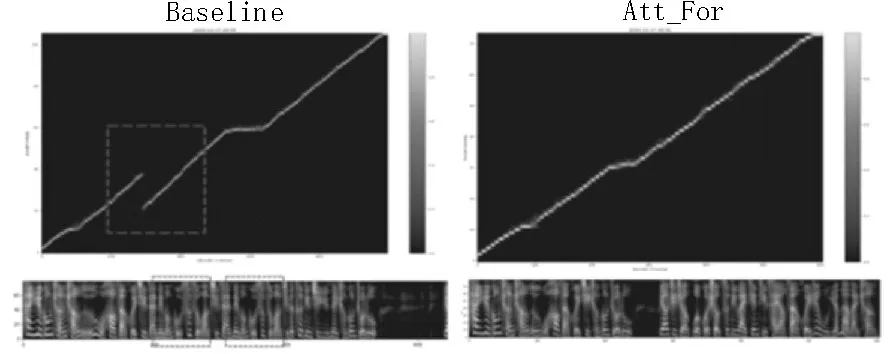
图2 特征预测网络对齐情况和梅尔声谱图对比
在合成相同长句子时,左图代表基线模型Tacotron2 的对齐情况和梅尔频谱图,右图显示的是前向注意力机制下的对齐情况和梅尔频谱图。由图中可以看出,在合成相同长度句子的情况下,基线模型在特征预测网络对齐图上出现了重叠现象,生成的梅尔频谱图出现了频率谱的重复,并且合成长句子的时间较长,也就是合成效率较低;而使用了前向注意力机制模型的相同句子在特征对齐图上未出现重叠现象,对应的梅尔频谱也未出现频谱的重复,同时整个句子的合成耗时较短,说明了该文方法有效地解决了长句子合成中的问题,提高了语音合成的质量,并且提高了合成效率。
在对带约束的前向注意力的方法测试中,该文对DNN 网络中sigmoid 输出单元添加正偏置或者负偏置,会使带约束的注意力得分增加或者减少,进而影响参与注意力计算的音素移动的快慢,从而达到控制合成语音合成速度的目的。该文验证了该方法的有效性,具体做法是使用前一实验中合成的20 个话语进行对比,从0 开始以步长0.2 增加或减少偏置值,分别合成20 个话语,计算合成话语长度和偏置为0 的话语长度的平均比值,如图3 所示,从图中可看出,每次调整不同的偏置,能够有效地实现对合成语句速度的控制。

图3 偏置值对合成语音速度的影响
4 结束语
该文提出的前向注意力机制能够有效平滑注意力计算中出现的异常得分,消除异常点,解决长句子语音合成中出现的漏读、重读问题,提高语音合成质量。更进一步地,该文又提出了改进的带约束的前向注意力机制,通过对前一时刻的注意力得分引入约束因子来自适应平滑当前时刻的注意力得分,提高了长句子语音合成的稳定性且能够自主控制合成语音速度。实验结果表明,相对于基线模型Tacotron2,前向注意力机制的长句子语音合成方法在MOS 得分上提升了2.5%,且带约束的前向注意力能够有效地控制合成语音的速度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
甘肃教育(2020年22期)2020-04-13
小学阅读指南·低年级版(2017年1期)2017-03-13
第二课堂(课外活动版)(2016年2期)2016-10-21
人生十六七(2015年6期)2015-02-28
小学阅读指南·高年级版(2014年2期)2014-05-27
计算机辅助工程(2012年5期)2012-11-21
