
从RTL 到GDS 的功耗优化全流程
2022-09-24 06:47:42顾东华曾智勇余金金黄徐辉朱嘉骏何湘君陈泽发
电子技术应用 2022年8期
顾东华 ,曾智勇 ,余金金 ,黄徐辉 ,朱嘉骏 ,何湘君 ,陈泽发
(1.燧原科技上海有限公司,上海 200000;2.上海楷登电子科技有限公司,上海 200000)
0 引言
芯片设计一直在追求最好的PPA,在28 nm 之前的技术节点上,很多时候更多地优先考虑性能和面积。随着技术节点向7 nm 进化,标准单元的密度不断提升,随之而来的功耗密度也越来越大。因此作为PPA 之一的功耗在设计中变得尤为重要。设计芯片需要在流程的各个节点尽量对功耗进行精确评估并进行优化,否则最终芯片的性能很可能由于功耗过大而无法充分发挥。
1 芯片功耗
首先来看下从原理上芯片的功耗的计算方式。集成电路的功耗一般分为静态功耗和动态功耗。如图1 所示,静态功耗又称为泄露功耗(leakage power),是指电路处于等待或不激活状态时泄漏电流所产生的功耗。
图1 中箭头表明了在通电状态下PMOS 内主要的泄漏电流及其走向,意即:

图1 静态功耗示意图
泄漏电流(Leakage Current)=漏极->N-Well+Gate->N-Well+源极->漏极
泄漏电流存在的原因在于,MOS 管中的多种掺杂区形成导电区域,同时这些区域会组成多个PN 节,从而在通电后形成一系列微小的电流。
尽管在现今芯片的工作电压已经很低的前提下每个MOS 管的漏电流很小,但由于每颗芯片中集成的晶体管多至几亿甚至几百亿,积少成多,导致芯片的整体泄露功耗变得越来越恐怖。
在后端设计中,由于每个标准单元(standard cell)的leakage 都集成在其liberty 库文件(.lib)中,因此计算leakage power 只需在制定条件下将design 中所有的标准单元(包括各种Macro)的leakage 值相加即可。
目前所有的主流PR 工具对此都有支持。需要指出的是,由于一个标准单元的leakage power 和其面积成正比,因此在实际后端设计的各个阶段,尤其是low power设计中,一般会重点关注芯片中逻辑门的面积变化并以此快速推断design 的leakage 功耗变化。
另一部分称为动态功耗,是指芯片在工作过程中晶体管状态跳变所产生的功耗。当把反相器简化成一个简单的RC 电路时,就可以清晰地看出充放电时的电流走向。当芯片处于工作状态时,每一个工作中的标准单元都会随着时钟以及数据的翻转而不断重复上述过程,从而产生大量的动态功耗。
在实际后端设计时,动态功耗由于和芯片的功能息息相关,因此在计算的时候会引入翻转率(toggle rate)的概念。翻转率是指单位时间内标准单元上信号翻转的次数,翻转率的高低直接影响到标准单元上的动态功耗开销。
在实际计算动态功耗的时候,又会分成两个部分。一部分为标准单元内部的动态功耗,一般叫做短路功耗,又可以称为内部功耗(Internal Power),如图2 所示,这部分的计算是嵌入liberty 库文件内部,通过标准单元的input transition 和output load 来查表得到的。
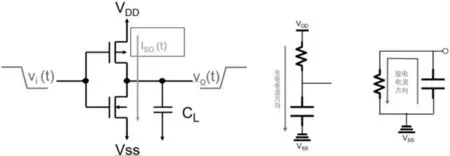
图2 内部功耗示意图
另一部分为互连线(net)上的动态功耗,也称为翻转功耗(Switching Power),这部分的计算通过将所有net上每个翻转周期的功耗乘以其翻转率并相加得到。
翻转率通过某种固定格式的文件传入EDA 工具,比较常用的格式有SAIF (Switching Activity Interchange Format)、VCD(Value Change Dump)以及FSDB(Fast Signal Database)文件。
目前主流的PR 工具均支持此类用法,但是签核signoff 时仍然需要比较专业的power 计算工具如Synopsys PrimeTime PX 或Cadence Palladium 等。
至此,我们基本了解了一颗芯片整体功耗的计算方法。而在现今十分重要的低功耗设计中,所有的手法都是从降低以上两个方面(Static,Dynamic)的功耗着手的:比如应用多个power domain 以便在芯片的某一部分功能不用的时候将其断电关闭;或者通过升级更先进的工艺来降低每个晶体管的尺寸从而降低整体面积;抑或通过改善时钟树综合手段来降低芯片中占比很大的时钟网络功耗。
传统的功耗优化方案一般会采用减少ULVT cell 的使用率来优化静态功耗,另外引入无向量模式(vector-less)设置一个大概的switching activity 如15%,然后进行动态功耗优化。但是这样的优化就要一定的随机性因此目标不明确,效果不明显。
在7 nm 的AI 类芯片中,动态功耗占据了主体,仅靠对于静态功耗的优化,无法满足功耗优化的目的。因此带入能表征芯片实际工作的工况波形,再进行精确的动态功耗优化更具有决定作用。
2 工况波形
一般模块设计者会对模块进行功能验证,某些工况下该模块的功耗会达到峰值。此时通过验证工具可以给出峰值功耗波形。该波形会记录该模块所有信号的翻转信息。这里的验证工具可以是Cadence 的Palladium(如图3 所示)。当然有些模块的峰值功耗可能有多个情况,并且会涉及不一样的逻辑空间,那么就需要一组波形来表征该模块的功耗行为。但是一般验证工具是基于RTL设计给出来的RTL 波形,它虽然可以直接用于网表的优化,但由于它只能一定程度地映射网表中的寄存器,而无法精确匹配寄存器中间的大量组合逻辑。因此仅仅依赖RTL 波型进行优化不能达到最优效果。
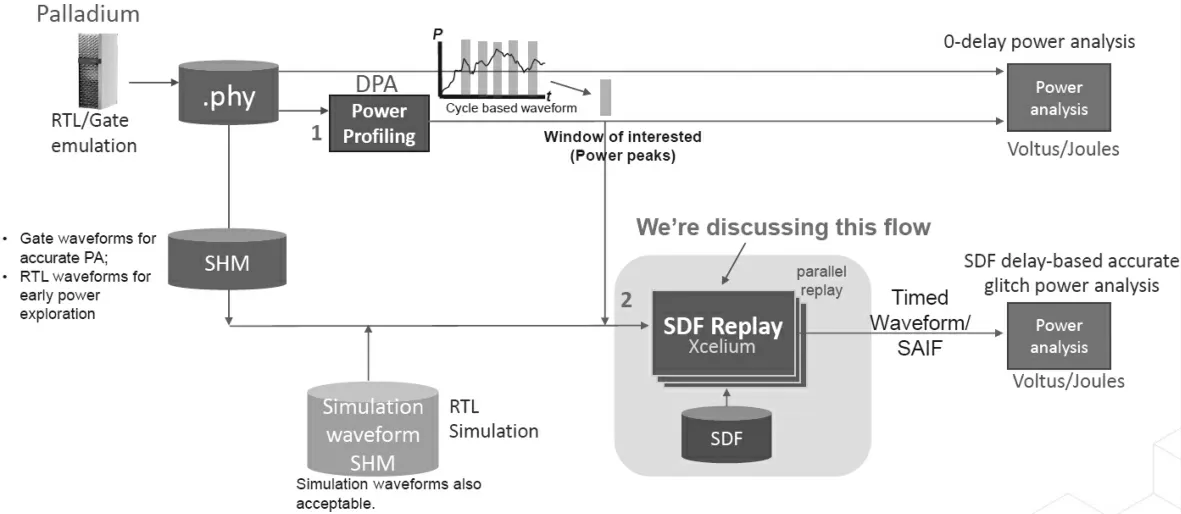
图3 Palladium 示意图
Cadence 在其功耗计算工具Joules 中集成了Joulesreplay,该功能可以将RTL 波形转换到与之相对应的门级网表(Gate Level Netlist)并且进行仿真,产生所有组合逻辑的详细波形。有了这一功能就可以在优化过程中使用更为精确的网表波形。
3 功耗优化全流程
3.1 综合流程
当拿到RTL 设计,并利用Genus 进行综合时,可以利用对应的RTL 波形开始进行功耗优化。Genus 综合可以分为3 个步骤:syn_gen、syn_map 和syn_opt。因此,可以形成如图4 所示Genus 结合FSDB 的综合流程图。
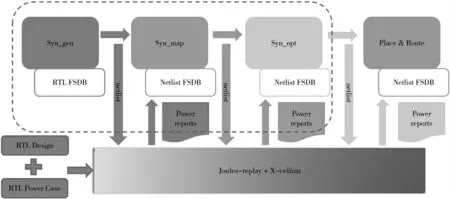
图4 Genus 结合FSDB 综合流程

3.2 PR 流程以及signoff 阶段
如图5 所示,在Innovus 中实现Place 和Routing 也分为3 个阶段:place_opt、cts_opt 和route_opt。同样每一步都加入Joules-replay 来实现优化所需的网表波形。同时可以通过设定weight 值来实现引入多个波形同时优化。
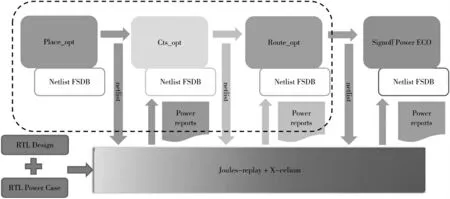
图5 PR 各阶段结合FSDB 功耗优化流程
·Innovus:

3.3 Signoff 流程
如图6 所示,在Signoff 阶段,通过IPA 工具进行power的signoff,可以了解到最终power 的静态功耗和动态功耗的大小。引入IPA 产生的FSDB 至IR 仿真中,得到vector 的IR 结果。
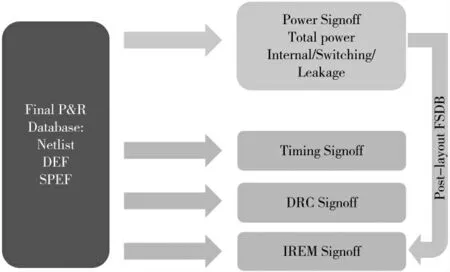
图6 sigoff 流程图
4 功耗优化实验和结果
选取了三个case 作为比较对象,如表1 所示,case 0为不引入FSDB 的base 情况,case 1 为由Genus 综合开始至Innovus PR 各阶段均引入FSDB 的全流程功耗优化,case 2 为在case 1 的基础上同时使用MBB cell。

表1 实验设定
4.1 Signoff QOR 结果分析
如表2 所示,对比case0、case1 和case2 的QOR 结果可以发现:(1)三个case 时序结果都比较一致,且在安全范围;(2)case1 和case 2 的DRC 数量有增多,但增加的DRC 主要集中在IO ports 附近,核心区域的DRC 没有明显变化;(3)case 1 和case 2 的IR 结果变好,这是引入FSDB 的case,平均功耗更优化。总的来看,引入FSDB 全流程功耗优化对PR 的QOR 影响不是很大,而且对IR还有提升。

表2 实验QOR 结果对比
4.2 各阶段功耗优化效果
Joules-replay 可以具体表征每个阶段功耗的数值,为此总结了引入FSDB 后各阶段功耗优化的比例,如图7所示,在综合阶段有7%的优化效果,当到达signoff 时有10.5%的优化,此外,当FSDB 结合MBFF cell 使用时,功耗优化效果会进一步提升,在签核阶段达到19.8%的比例。
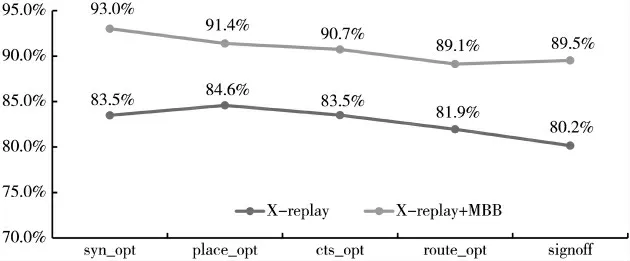
图7 各阶段功耗优化的比例
表3 列举了签核signoff 阶段,这三个case 的具体功耗组成,结果显示,case1 和case 2 的功耗优化主要是由于内部功耗和开关功耗大幅度降低。
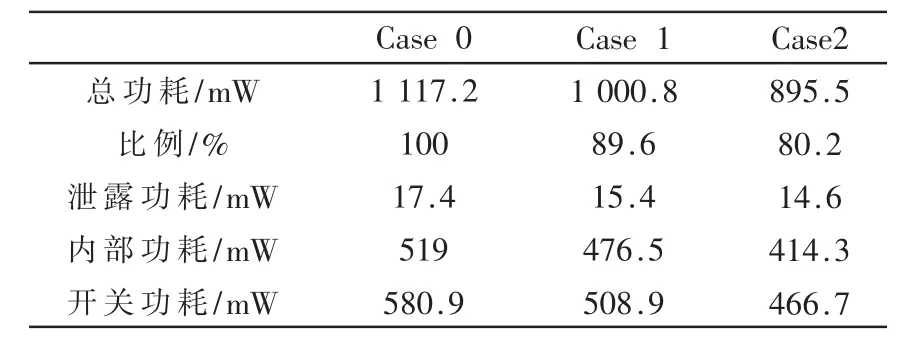
表3 各case 功耗组成占比
4.3 签核流程中功耗优化
为进一步优化功耗,在Tempus timing signoff 的流程中进行PowerECO,如图8 所示,PowerECO 能够进一步优化1.8%的功耗,最终全流程功耗优化能够达到21%的优化效果。
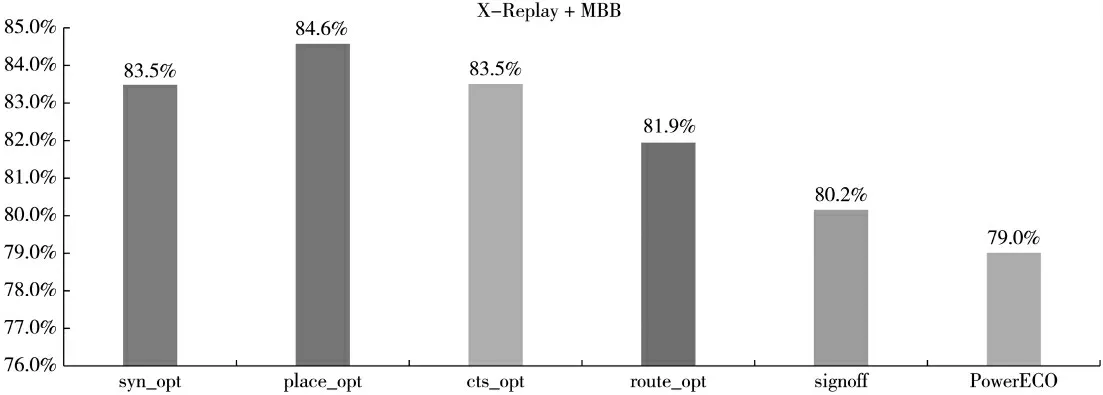
图8 Joules-replay+MBB 各阶段功耗优化的比例
5 结论
综上所述,本文使用了带FSDB Genus 综合流程,带FSDB Innovus PR 实现流程,以及Tempus Power ECO 签核优化流程,并在整个实现与优化流程中结合MBFF 技术,可以实现从RTL 到GDS 的21%的功耗优化,这为大芯片的功耗优化带来全新的选择,为芯片的PPA 的提升提供了一种全新的方法。
猜你喜欢
中国特种设备安全(2021年9期)2021-03-02 05:40:46
测控技术(2018年2期)2018-12-09 09:00:46
个人电脑(2016年12期)2017-02-13 15:24:40
发明与创新(2016年23期)2016-10-13 02:16:14
电子制作(2016年19期)2016-08-24 07:49:54
通信电源技术(2016年3期)2016-03-26 07:13:14
湖北工业大学学报(2016年5期)2016-02-27 13:14:51
电子世界(2015年22期)2015-12-29 02:49:44
防灾减灾学报(2015年3期)2015-12-16 16:15:40
电源技术(2015年11期)2015-08-22 08:51:02
