
考虑移动目标不确定行为方式的轨迹预测方法
2022-09-23 06:18:18郭继峰白成超
宇航学报 2022年8期
颜 鹏,郭继峰,白成超
(哈尔滨工业大学航天学院,哈尔滨 150001)
0 引 言
飞行移动目标轨迹预测技术在智能空战、协同拦截以及目标跟踪监视等任务场景中具有重要的理论研究和实际应用价值。在移动目标跟踪与监视任务中,由于目标行为的不确性以及任务环境的复杂性,极易丢失跟踪的目标。特别是在一些复杂的任务场景中,由于任务环境中分布着大量的障碍物极易遮挡观测视线,很容易导致目标丢失。因此,对移动目标运动轨迹的预测可在目标丢失之后为目标的搜索过程提供指导,使得目标被快速搜索到,从而实现对目标的长期跟踪与监视。
针对目标轨迹预测的方法大致分为基于物理模型的预测方法、基于数据驱动的预测方法以及基于规划的预测方法三类。在基于物理模型的预测方法中,通常根据目标的运动模型以及观测到的目标状态,使用卡尔曼滤波(KF)、扩展卡尔曼滤波(EKF)以及无迹卡尔曼滤波(UKF)等滤波方法对目标的运动状态做出一步或多步的预测。然而以上滤波方法只能处理具有单一运动模式的预测问题,无法处理具有多种运动模式的目标轨迹预测问题。文献[14]根据临近空间短距滑翔飞行器的多模式机动特点设计了一种基于变结构交互式多模型(IMM)滤波的轨迹预测方法。在上述基于滤波的预测方法中假设目标的行为方式服从建立的运动模型,若缺乏目标的运动模型,则无法对目标的轨迹进行有效的预测。文献[15]在假定高超声速滑翔目标具有必定攻击某目标的行为基础上结合滑翔目标的运动模型利用贝叶斯理论迭代地对滑翔目标的运动轨迹进行了预测。然而,作者并没有考虑当滑翔目标具有不确定行为时的预测问题。综上所述,上述预测方法只适用于目标运动模型已知的问题,对于具有复杂不确定运动行为的目标,很难建立有效的运动模型,因而不能准确地预测出目标的轨迹。
在基于数据驱动的预测方法中,通常使用深度神经网络(DNN)、隐马尔可夫模型(HMM)以及高斯混合模型(GMM)建立移动目标的轨迹预测模型,之后通过收集的大量目标轨迹数据训练模型参数,挖掘出目标的行为特征,据此对目标的轨迹做出预测。文献[19]将行人轨迹的预测问题转换为一个位置序列生成问题,使用长短期记忆网络(LSTM)建立预测模型,通过编码观测到的行人轨迹生成行人未来的轨迹。文献[20]基于LSTM与卷积神经网络(CNN)建立了车辆轨迹预测模型。模型首先使用LSTM将待预测车辆固定范围内的各车辆的历史轨迹进行编码,然后按照车辆的空间位置对编码的轨迹进行排列,之后使用CNN进行池化处理,最后使用LSTM解码得到预测的车辆轨迹。文献[21]利用高斯混合回归技术预测移动对象的复杂多模式运动行为,建立的预测模型可以通过数据自身预测移动对象可能性最大的运动轨迹。以上基于数据驱动的预测方法虽然可以在目标运动模型未知的情况下依靠目标的移动数据对目标的轨迹做出预测,但预测对象具有较为确定的行为方式,易于通过监督学习的方式学习出目标的行为模式。然而对于具有不确定行为的目标,这种方法难以达到较好的预测精度。
基于规划的预测方法将目标轨迹的预测过程转换为模拟目标轨迹规划的过程。文献[22]将人群以及障碍物对行人轨迹的影响等建模为能量,在该地图上使用快速步进法规划行人的轨迹,从而达到预测行人轨迹的目的。文献[23]将人行道、建筑物以及行驶的车辆等视为影响行人行为的势场,构建了势场代价地图,之后利用A算法在此地图上规划行人的轨迹,以此作为预测结果。以上预测方法都假设行人按照最优的轨迹运动,然而在现实世界中,移动目标的行为方式很有可能不是最优的,因此无法基于最优规划的准则预测目标的行为。为此,可以从目标的行为轨迹数据中学习出目标的行为方式,在此基础上预测目标的轨迹。解决这一问题的一大类方法为基于逆强化学习的轨迹预测方法。文献[26]在马尔科夫决策过程(MDP)框架下利用最大熵逆强化学习(MaxEnt)方法学习出行人的行为概率模型,以此预测行人的轨迹。在此基础之上,文献[28]使用多尺度的CNN拟合复杂城市环境中的导航代价地图,然后基于此地图规划行驶路径。这种直接使用深度神经网络处理环境信息得到代价地图的方法避免了人为手动设计的过程。此外,文献[29]使用最大化边际规划方法(MMP)学习机器人在复杂环境中的导航策略。其中,利用深度神经网络建立机器人的导航策略,输入为感知的环境状态特征,输出为选择下一步动作的概率。
虽然以上基于逆强化学习的方法可通过模拟目标轨迹规划的过程实现对目标行为轨迹的预测,然而对于在复杂环境中运动的、具有不确定行为的目标,其预测精度较低,难以学习到目标的不确定行为特征。为了解决这一问题,本文在一种最大熵逆强化学习方法——引导式成本学习(GCL)的基础上引入针对飞行移动目标不确定行为特征的改进措施,构建飞行移动目标轨迹预测模型。首先考虑到目标的行为方式受到局部环境信息以及全局导航信息的影响,基于CNN建立目标行为偏好模型与目标行为决策模型,通过融合局部环境信息以及全局导航信息将环境对目标行为的影响编码到建立的网络模型中。其中,目标行为偏好模型用于捕捉目标的行为特征,指导目标行为决策模型的训练,目标行为决策模型用于模拟目标的行为方式,生成预测的目标轨迹。然后在GCL框架下利用目标示例轨迹对建立的神经网络模型进行训练。为了有效地从目标示例轨迹信息中学习出目标的不确定行为特征,提高模型的训练效率,本文提出的改进措施包括使用目标示例轨迹概率分布模型指导目标行为偏好模型的训练以及初始化目标行为决策模型,同时通过对目标行为偏好模型进行预训练的方式提高模型训练的质量。
1 问题定义
1.1 飞行移动目标轨迹预测问题
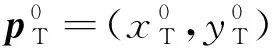
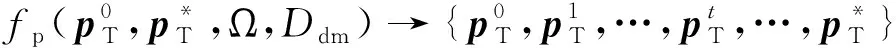
(1)
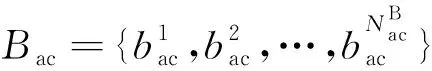
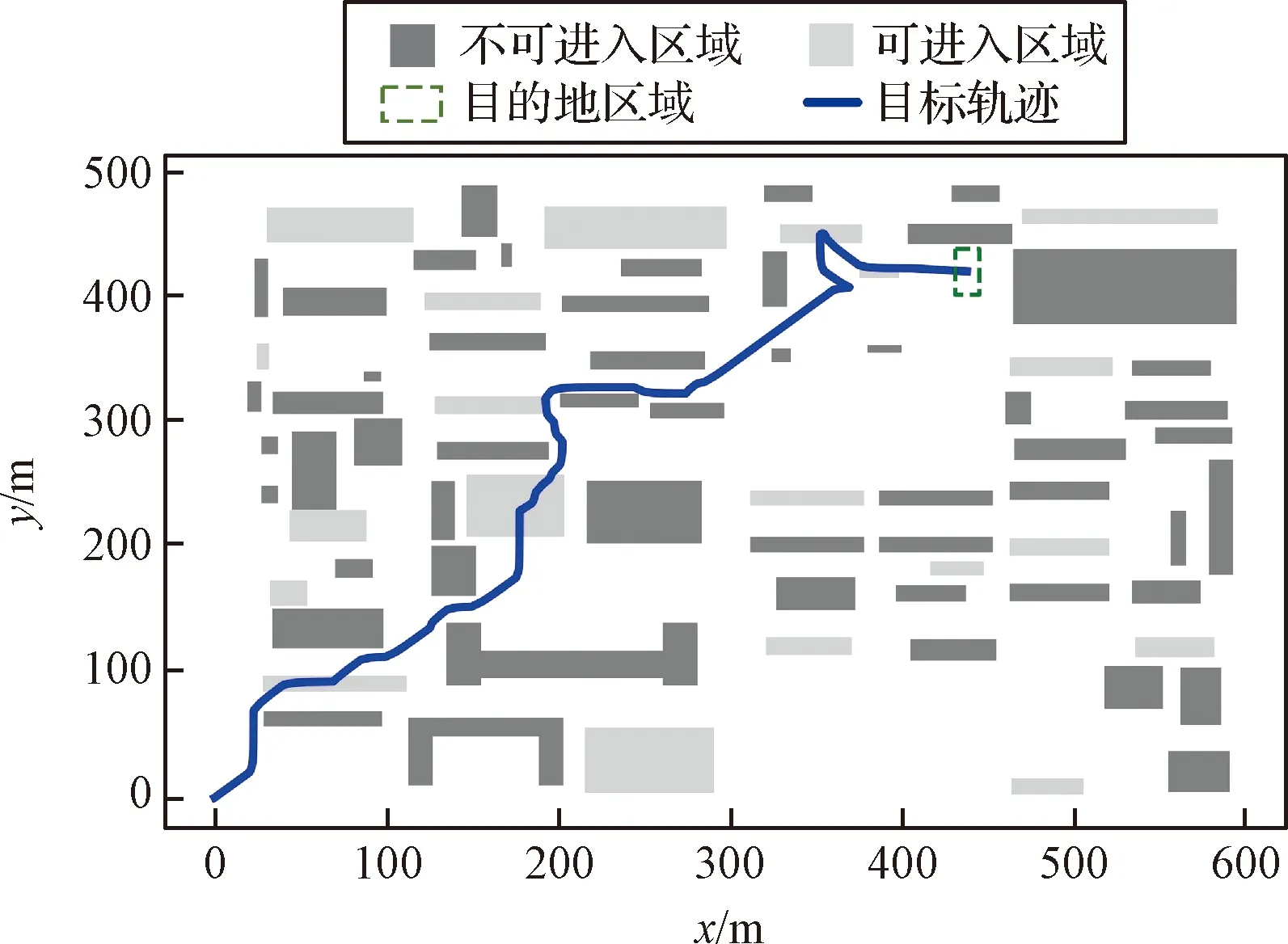
图1 飞行环境模型Fig.1 Flying environment model
1.2 目标不确定行为模型
由于现实中收集的目标轨迹数据难以调整其不确定性程度,无法对目标轨迹预测方法进行全面分析和验证。因此,本文手动设计目标的行为模型,使其可以灵活地调整目标行为的不确定性程度。
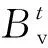

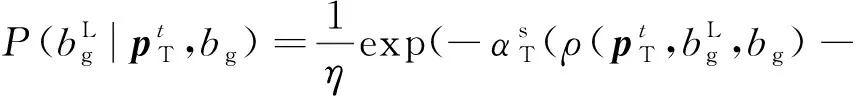
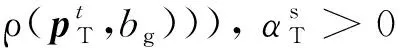
(2)
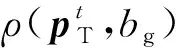
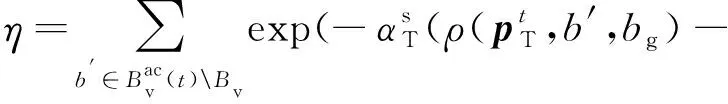
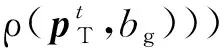
(3)
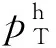
2 基于GCL的目标轨迹预测方法
本节在GCL方法的基础上实现对目标轨迹的预测。首先介绍GCL方法的基础理论,其次基于深度神经网络建立目标行为决策模型与行为偏好模型,之后由目标示例轨迹数据学习出目标的示例轨迹概率分布模型,用于改进目标行为决策模型与行为偏好模型的训练过程,然后使用目标示例轨迹数据对目标行为偏好模型进行预训练,进一步提高目标行为偏好模型的训练效率。最后给出模型的训练流程。
2.1 GCL算法
GCL方法是一种最大熵逆强化学习方法。逆强化学习方法解决的任务一般由马尔科夫框架定义,表示为M=〈S, A,,〉,式中S表示任务的状态空间,A表示动作空间,T(T(′|,),,′∈S,∈A)表示状态转移模型,(0≤≤1)为折扣因子,为奖励函数。在强化学习任务中,通过人为手动设计的奖励函数求解最优的策略π(|)使得智能体在执行该策略时所获得的累积奖励最大。对于一些复杂的任务,人为很难设计合理的奖励函数,因此逆强化学习解决从示例轨迹数据集中学习对应的奖励函数的问题。
在逆强化学习框架下预测目标的轨迹时认为目标的行为过程由一个马尔科夫框架定义,目标的行为方式是其潜在的真实奖励函数(,)对应的最优的行为方式π(|),逆强化学习的目标则是通过目标示例轨迹学习出目标的奖励函数(,)与行为方式π(|)。
在最大熵逆强化学习框架下,示例轨迹的概率分布表示为如下的形式:
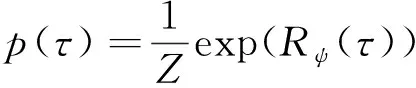
(4)
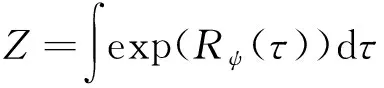
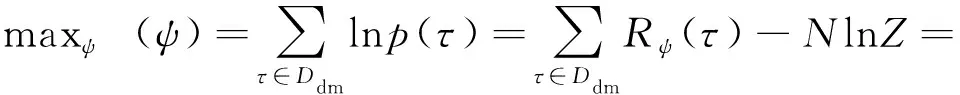
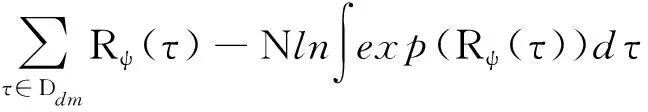
(5)
式中:=||表示示例轨迹的个数。在式(5)的求解过程中,对于高维连续的任务环境,配分函数的计算非常困难。因此,在GCL方法中使用采样的手段估计配分函数,如下所示:
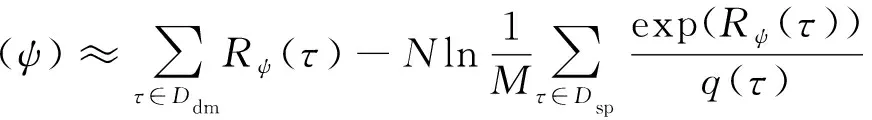
(6)
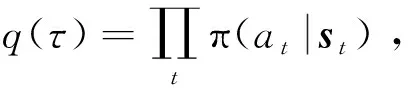
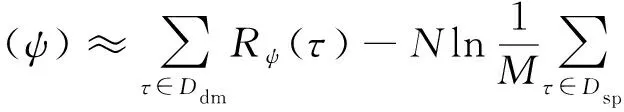
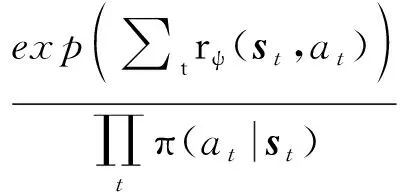
(7)
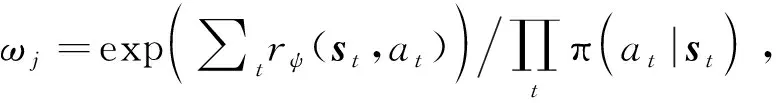
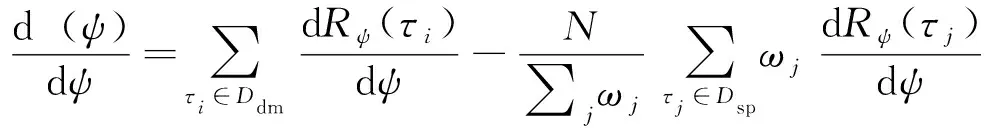
(8)
因此,在GCL框架可根据目标示例轨迹数据集利用式(8)对奖励函数(,)进行训练,而(,)又通过相关强化学习算法指导采样策略π(|)的训练过程,使其采样的轨迹更加接近在奖励函数(,)下的最优策略采样的轨迹。通过对(,)与π(|)的交替训练,最终可使得奖励函数(,)逼近目标的真实奖励函数(,),采样策略π(|)逼近真实的目标行为决策策略π(|)。两个模型的训练过程互相影响,互相促进。因此,对(,)与π(|)的建模非常关键,需要充分考虑影响目标行为的各种因素,建立具有较强数据处理能力与拟合能力的奖励函数模型与采样策略模型。
对于飞行移动目标轨迹预测问题而言,奖励函数(,)对应目标的行为偏好模型,影响目标的行为方式;采样策略π(|)对应目标的行为决策模型,用于模拟目标轨迹产生的过程。
2.2 目标行为决策与行为偏好模型
通常,目标的行为决策过程以及行为偏好受到目的地位置以及目标周围环境的影响,因此,本文将目标周围环境信息以及目的地位置信息作为目标行为决策与行为偏好模型的输入信息。
首先,将飞行环境Ω进行离散化处理,得到大小为×的栅格地图(∈×),具体定义如下:
=[()]×,

(9)

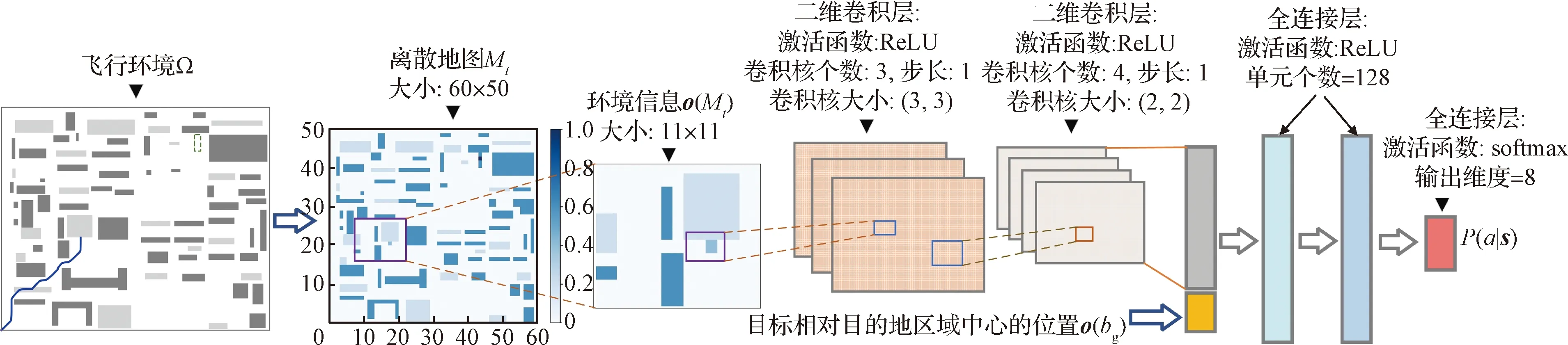
图2 目标行为决策模型网络结构Fig.2 Network structure of the target behavior decision model
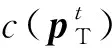
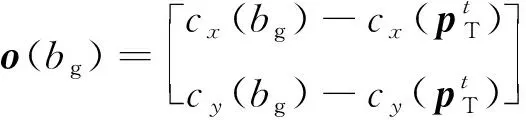
(10)
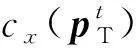
在建立的目标行为决策模型π(|)中,首先使用两层CNN编码目标周围环境信息(),然后将编码之后的信息与观测信息()进行拼接,之后通过两层全连接网络融合处理得到全局目的地信息与局部环境信息的混合编码,最后经过激活函数为softmax的全连接层处理,得到选择下一步行为动作的概率值(|)。
目标行为偏好模型的网络结构与目标行为决策模型的网络结构基本相同,相比于目标行为决策模型,其最后一层只有一个输出值,且激活函数为tanh,目的是将输出奖励值(,)限制在(-1,1)之间。需要注意的是目标行为偏好模型的输入为在状态处执行动作之后的下一步状态′,即(,)→(′)。
2.3 目标示例轨迹概率分布模型
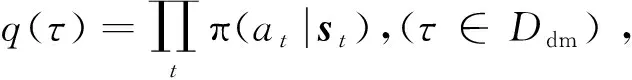
具体地,目标示例轨迹概率分布模型的网络结构以及输入输出同目标行为决策模型一致,其模型参数的训练通过最小化以下损失函数实现:
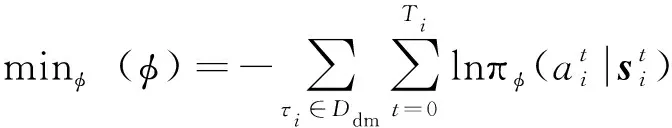
(11)
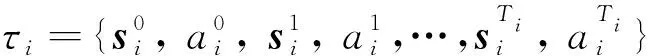
2.4 目标行为偏好模型预训练策略
在目标行为偏好模型的训练过程中,可通过对模型参数进行预先训练的方式提高模型训练的速度与质量。为此,本节提出基于目标示例轨迹的目标行为偏好模型预训练策略。
对于收集的目标示例轨迹数据集={,,…,},统计其经过栅格地图中每个栅格单元的频次,则经过栅格单元的频率可表示为:

(12)
式中:min(·)函数的使用是为了将()限制在[0,1]之间。则目标行为偏好模型的预训练通过最小化以下损失函数进行:
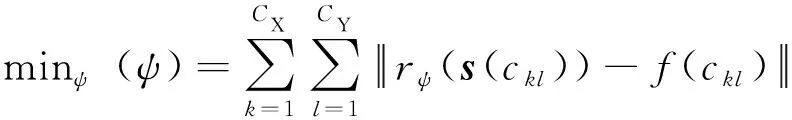
(13)
式中:()表示目标所在栅格单元为时观测到的输入状态;(())表示在状态()下目标行为偏好模型的输出值。目标行为偏好模型经过以上预训练之后,可在GCL框架下进一步训练。
2.5 模型参数训练流程
基于GCL算法的目标行为决策模型与目标行为偏好模型参数训练流程如图3所示。
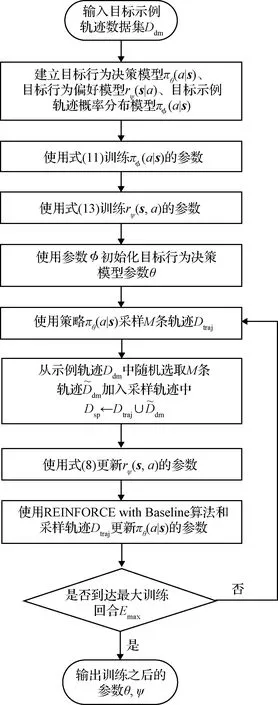
图3 目标行为决策模型与目标行为偏好模型参数训练流程Fig.3 Parameter training flow of the target behavior decision model and behavior preference model
在基于GCL的模型参数训练流程中,目标行为决策模型π(|)使用具有基线的蒙特卡洛策略梯度方法(REINFORCE with Baseline)训练,其中基线函数使用值函数网络()表示,其网络结构与决策模型π(|)的网络结构基本一致,不同的是值函数网络()的最后一层只具有一个线性输出单元。
3 仿真校验
3.1 仿真场景设置
3.2 模型训练结果
本文使用Pytorch深度学习框架建立神经网络模型,并使用Adam优化器对所建立的网络模型进行训练。在建立的网络模型中,输入环境信息()的大小为11×11,即==11。其中,目标示例轨迹概率分布模型的训练过程与目标行为偏好模型的预训练过程共经过1000个训练回合,梯度更新使用的批大小为32,学习率为0.0001,训练过程中的损失值变化如图4所示(为了方便显示,图中将损失值归一化到[0,1]之间)。在基于GCL的目标行为决策模型与目标行为偏好模型的训练过程中,训练最大回合数=125,每回合采样轨迹条数=20,批大小为32,学习率分别设置为0.00002, 0.0002。在具有基线的蒙特卡洛策略梯度方法中,折扣因子=095,值函数的学习率设为0.001。训练结果如图5所示(为了方便显示,图中将损失值归一化到[-1,0]之间)。
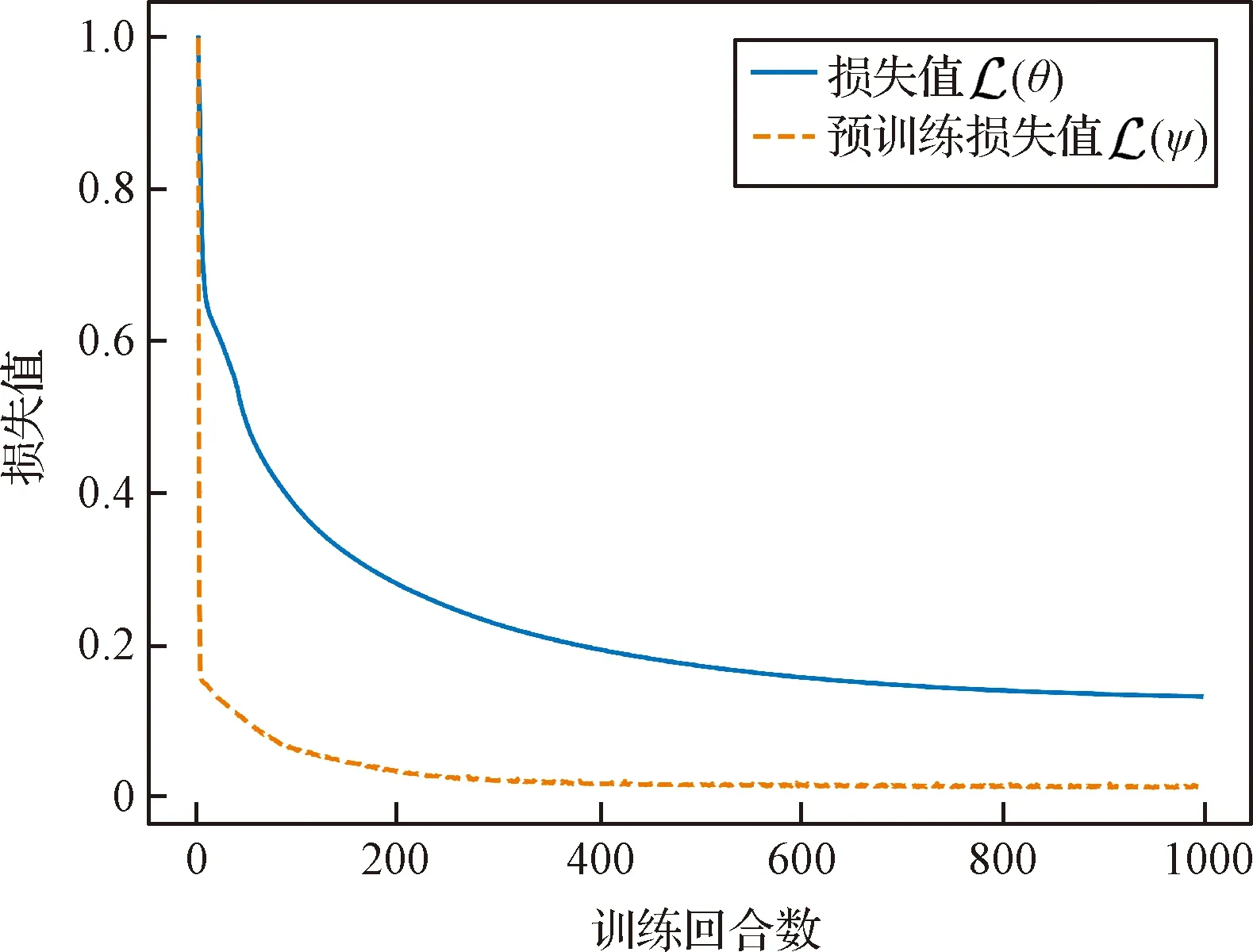
图4 监督学习过程损失值变化曲线Fig.4 Curves of the loss values during supervised learning
如图4所示,随着训练回合的增加,目标示例轨迹概率分布模型与目标行为偏好模型的损失值下降变缓,在训练后期损失值基本保持不变,表明模型训练完成。从图5中可以看出,随着训练回合的增加,目标行为偏好模型的损失值的绝对值逐渐减小,表明从目标示例轨迹中学习到的目标行为偏好模型逐步接近目标真实的行为偏好,以及以目标行为偏好模型为奖励函数的目标行为决策模型逐步向目标真实的行为决策方式逼近。在训练后期,损失值逐渐接近0,表明学习过程基本完成。
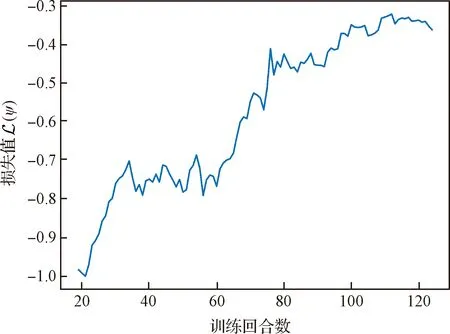
图5 目标行为偏好模型的损失值变化曲线Fig.5 Curve of the loss value of the target behavior preference model
3.3 预测性能对比结果
对比方法
本节将所提的飞行移动目标轨迹预测方法与其他类型的考虑目标行为方式的轨迹预测方法进行对比,对比方法包括:
(1)基于随机A的预测方法。在A算法的基础上加入了随机性,使得其规划的轨迹具有不确定性,从而可以对不确定行为轨迹进行预测。目标在每次选择行为动作时以概率选择A算法规划的行为动作,以概率1-从其邻居节点中随机选择下一步的行为动作。在以下的对比实验中设置=07(取值的确定过程为以0.1为步长,从0.0开始增加的值到1.0,当=07时具有最好的预测性能)。基于随机A的预测方法作为一种最基本的基于规划的预测方法,此处作为对比的基准。


(14)
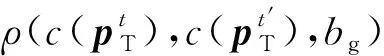
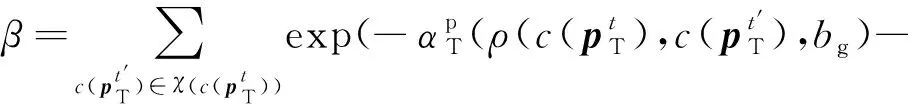
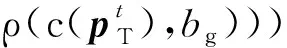
(15)
在基于概率模型的预测方法中,目标按照式(14)选择下一步的行为动作,直到到达目的地,目标经过的轨迹即为预测的轨迹。以上建立的基于概率模型的预测方法与1.2节中建立的目标真实行为模型类似,故理论上具有较好的预测性能。
(3)基于模仿学习的预测方法。基于模仿学习的预测方法使用训练的目标示例轨迹概率分布模型π(|)直接模拟目标行为的决策过程,以此预测目标的轨迹。基于模仿学习的预测方法作为一种基于数据驱动的预测方法,在很多任务中具有较好的预测性能。
性能指标
由于目标的行为具有不确定性,因此难以凭借预测的轨迹直接对比预测性能。为了对各轨迹预测方法的预测性能进行合理的对比,本文通过定义目标行为轨迹奖励值评价预测的行为轨迹。
目标行为轨迹奖励值定义为目标在执行轨迹={,,,,…,,}的过程中获得的累计奖励之和,计算如下:
()=∑(,)
(16)
式中:()表示轨迹对应的目标行为轨迹奖励值;(,)表示目标在状态下执行动作所获得的奖励值。
本文在计算目标行为轨迹奖励值时,(,)设计如下:
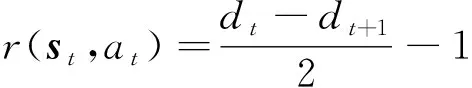
(17)
式中:表示目标在状态处距离目的地区域的距离;+1表示目标在状态处执行动作之后距离目的地区域的距离。
对比结果
图6所示为各预测方法预测性能的对比结果。从图中可以看出,本文所提的目标轨迹预测算法具有最小的KL散度,即其预测的目标轨迹最接近目标真实的行为方式。由于随机A算法在大部分情况下按照A算法规划的行为进行预测(其他情况下按照随机行为进行预测),因此其无法对目标的不确定行为轨迹进行有效的预测。相比之下,基于概率模型的预测方法具有较好的预测性能,因为其选择路径的方式与真实目标的行为方式比较相似。此外,由于模仿学习方法只是对目标轨迹的概率分布进行了模拟,即只学习到了“平均目标行为”,但没有学习到目标特有的行为方式,因而也不能对目标的轨迹进行有效的预测。
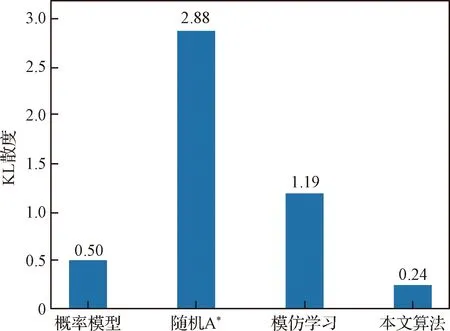
图6 预测性能结果对比Fig.6 Comparison of the prediction performance results
图7所示为各预测方法预测的目标轨迹。从中可以看出只有本文提出的算法预测到了目标进入可进入区域隐藏自身行踪的行为方式,而在其他算法预测出的轨迹中没有与目标行为方式相似的行为特征。以上结果表明,通过对目标示例轨迹的学习,本文提出的算法可以学习到目标的行为特征,从而对目标行为轨迹的预测更加准确。
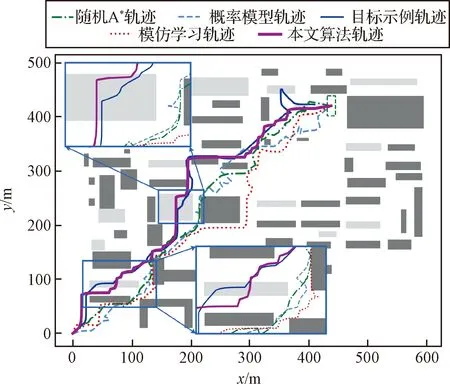
图7 各轨迹预测方法预测的目标轨迹Fig.7 Target trajectories predicted by each prediction method
3.4 泛化性能测试
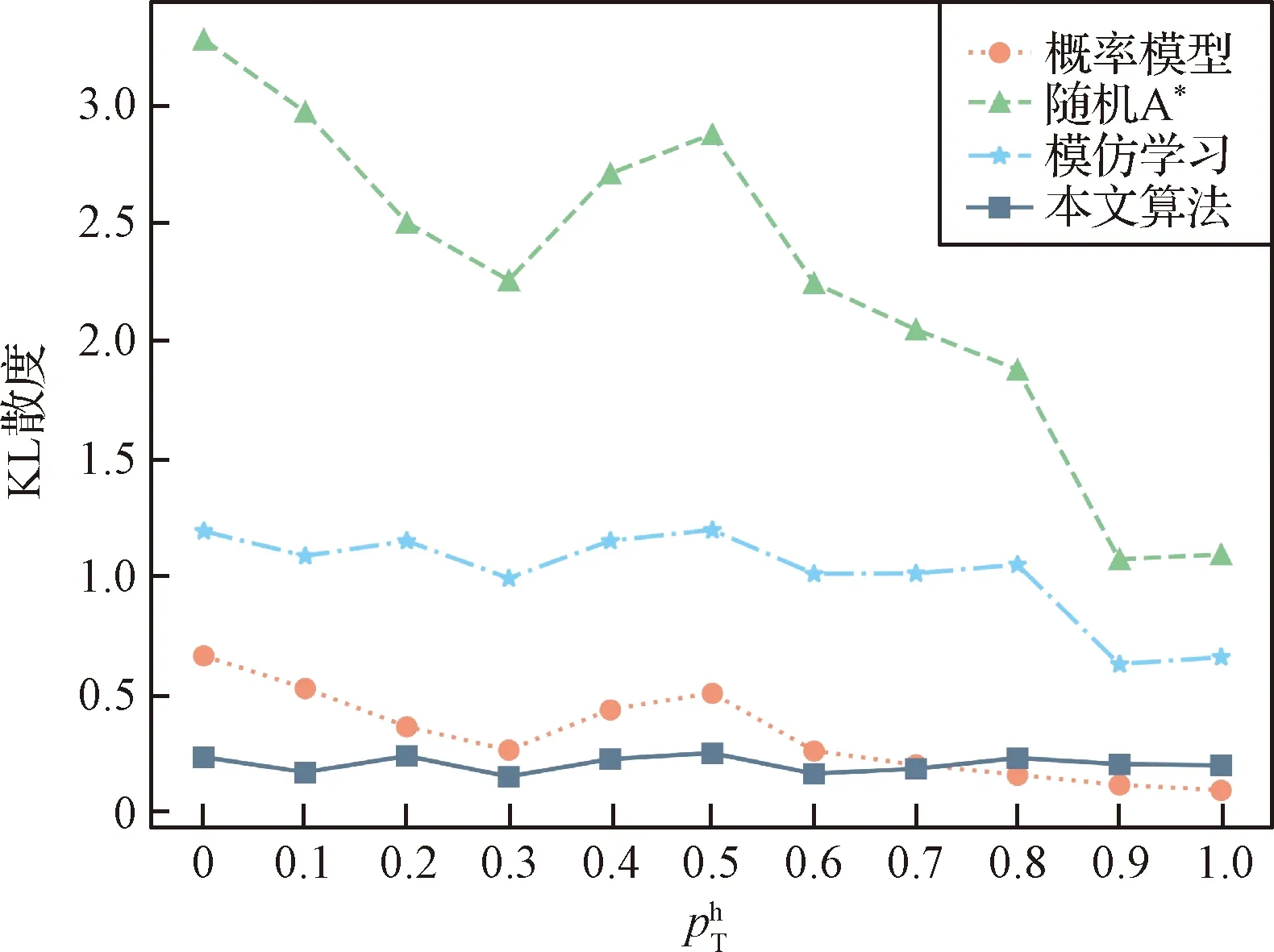
图8 参数的变化对目标轨迹预测性能的影响Fig.8 Influence of the variation of on the target trajectory prediction performance

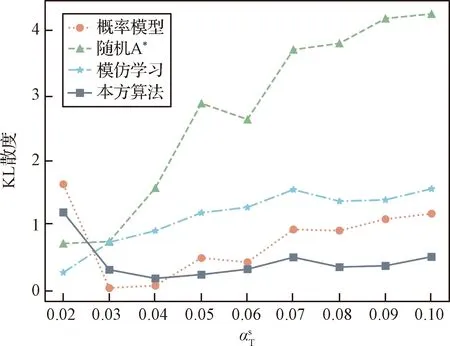
图9 参数的变化对目标轨迹预测性能的影响Fig.9 Influence of the variation of on the target trajectory prediction performance
3.5 消融实验
本文在GCL算法的基础上提出了3点改进措施,即①使用目标示例轨迹概率分布模型将目标示例轨迹通过重要性采样方法加入到采样轨迹中提高采样轨迹的质量,②使用目标示例轨迹概率分布模型初始化目标行为决策模型,以及③对目标行为偏好模型进行预训练。以下测试每种改进方法相对于原始GCL算法的影响。
图10所示为在以上改进措施的不同组合下对目标轨迹的预测性能,从中可以看出,以上3种改进措施可以逐步提高对目标轨迹的预测性能。在原始GCL算法下,只能学习到目标前往目的地的行为方式,无法学习到目标其他的行为方式。当在原始GCL算法中引入目标示例轨迹概率分布模型之后,学习到的行为偏好模型在目标示例轨迹附近具有较高的奖励,因而可以较好地模拟目标的行为方式。在此基础之上对目标行为决策模型的初始化以及对目标行为偏好模型的预训练提高了采样轨迹的质量以及模型训练的质量,因而可以更加全面地学习出目标的行为偏好。以上结果表明,本文在GCL算法的基础上提出的改进措施对目标不确定行为轨迹的预测具有明显的提升作用,可以有效提高对目标不确定行为轨迹的预测性能。
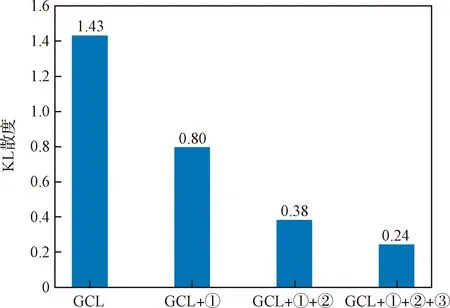
图10 各改进措施对目标轨迹预测性能的影响Fig.10 Influence of the improvement measures on the target trajectory prediction performance
4 结 论
针对具有不确定行为方式的飞行移动目标,本文提出了基于逆强化学习方法的目标轨迹预测方法,对目标轨迹的预测转换为对目标行为决策过程的模拟。由仿真结果可知,相对于其他轨迹预测方法,本文提出的算法可通过对目标行为方式的模拟实现对目标轨迹的准确预测。同时,其产生的预测轨迹可由目标行为偏好模型进行解释,相比于传统的基于神经网络的轨迹预测方法具有更好的可解释性。此外,学习到的目标行为偏好模型记录了目标的行为特征,因此具有较好的可迁移性,可用于不同的环境中预测目标的行为。未来的工作将对目标行为偏好模型的可迁移性进行深入研究,探索其在不同环境中的迁移效果。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
纺织科学研究(2021年9期)2021-10-14 08:52:10
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
山东冶金(2019年5期)2019-11-16 09:09:22
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
