
结合多层级解码器和动态融合机制的图像描述
2022-09-20 09:13姜文晖占锟程一波夏雪方玉明
中国图象图形学报 2022年9期
姜文晖,占锟,程一波,夏雪,方玉明
江西财经大学信息管理学院,南昌 330032
0 引 言
图像描述任务(image captioning)旨在对一幅输入图像自动生成完整的自然语言描述。图像描述任务可以应用于人机对话、盲人导航以及医疗影像报告生成等场景,具有巨大的应用前景和研究价值。为生成完整的句子描述,该任务需要全面建模图像中物体的类别、属性以及与场景的交互关系等丰富信息,并将这些内容通过组织语言的方式流畅地进行描述。图像描述任务是计算机视觉和自然语言处理交叉领域的挑战性问题。
早期研究首先分析图像视觉内容,即检测图像中的物体及其属性,分析物体间的相对关系,并将这些内容映射为单词或短语等描述信息(Farhadi等,2010)。然后通过自然语言技术,例如句子模板或语法规则,将这些基本描述单元转化为完整句子进行图像描述(Kuznetsova等,2014)。然而模板和语法规则较大地限制了图像描述的多样性和独特性,且对数据集和人工设计的依赖性较强。
得益于深度学习(deep learning)的发展,大量研究工作将深度学习应用于自动图像描述领域(Wan等,2022)。基于深度学习的主要框架是“编码器—解码器”模型。其中,编码器分析图像的语义内容,形成一组图像特征向量;解码器输入这些特征向量,通过语言生成模型输出完整的图像描述。相比于传统的方式,基于深度学习的模型脱离了具体的本文规则,能够生成变长、多样化的图像描述,并在描述准确性方面具有压倒性优势。因此,基于深度学习的方法是当前自动图像描述领域的主流模型。
注意力机制(attention mechanism)广泛融入编码器—解码器框架(Xu等,2015),其主要优势在于生成描述语句的每个字符时,可以动态地改变输入特征的权重以指导文本生成,极大提高了图像描述模型的准确性。然而,通过可视化分析和量化分析,发现注意力机制普遍存在不聚焦问题(Liu等,2017)。具体地,在生成描述单词时,注意力机制有时关注在物体不重要区域,例如人的身体,从而错误预测人的性别(Hendricks等,2018);有时关注物体背景,导致幻想出与目标相关但未实际出现的物体(Rohrbach等,2018);有时忽略图像中重要目标,导致描述中缺少重要信息。注意力机制的不聚焦问题严重影响了模型的可解释性。导致该问题的原因为:1)预测t时刻的单词时,注意力机制仅依赖t时刻之前生成的文本序列作为指导。因此,在未知待预测的目标单词条件下,显著性机制难以准确定位图像的正确区域。2)文本预测过程中,错误预测的单词将进一步误导注意力机制,从而对后续文本的生成产生误差累积。
为解决以上问题,本文提出一种结合多层级解码器和动态融合机制的图像描述模型。该模型是对标准的编码器—解码器结构的扩展,出发点是虽然通过t时刻之前预测的单词不足以指导t时刻文本生成,但是该预测结果能够提供更加有效的反馈信息,并进一步指导注意力机制定位到准确的图像区域。首先,设计解码器级联的结构实现注意力机制的渐进式精化。其中,第1级解码器采用标准的文本预测结构,以前时刻预测的单词为输入,输出粗略的图像描述。其次,后级解码器以前级解码器的预测单词为输入。由于该输入与预测的目标单词更相关,注意力机制能够更有效地聚焦到图像的关键区域,从而生成更准确的文本序列,并缓解误差累积。同时,本文提出一种解码器动态融合策略,根据每级解码器的输出,动态调整其对应权重,自适应地融合由粗到精的文本信息,最终生成细节信息丰富且准确多样的图像描述。动态融合结构使低层级解码器的输出直接参与最终的文本预测,为不同层级的解码器直接引入了监督信息,解决了传统级联结构容易产生的梯度消失现象,使模型训练更加稳定。
为验证模型的有效性,在MS COCO(Microsoft common objects in context)(Lin等,2014)和Flickr30K(Plummer等,2015)数据集上进行实验。结果表明,本文设计的模型效果显著,在BLEU(bilingual evaluation understudy)、METEOR(metric for evaluation of translation with explicit ordering)和CIDEr(consensus-based image description evaluation)等多项评价指标上优于其他对比方法。定性分析结果也验证了本文模型能够生成更加准确的图像描述。
1 相关工作
自动图像描述任务主要以编码器—解码器为主要架构。编码器提取输入图像的语义特征,解码器对编码器的输出结果进行处理,形成完整的文本描述。鉴于深度神经网络的灵活性和较强的建模能力,当前的主要工作是基于深度神经网络分别对编码器和解码器的结构进行建模(谭云兰 等,2021)。编码器广泛采用卷积神经网络(convolutional neural network,CNN),例如使用ResNet(residual network)和VGG(Visual Geometry Group network)等深层网络进行图像的特征表示(汤鹏杰 等,2017)。解码器广泛采用循环神经网络(recurrent neural network,RNN)和长短时记忆网络(long short-term memory,LSTM)对较长的文本序列进行关联建模(罗会兰和岳亮亮,2020)。基于深度神经网络的结构不依赖文本规则,生成的图像描述语法灵活。
1.1 注意力机制
随着注意力机制在机器翻译领域的广泛应用,越来越多的研究将其引入编码器—解码器结构。Xu等人(2015)将注意力机制引入自动图像描述任务,提出软注意力机制(soft attention),通过隐状态估算图像中不同空间特征的权重,使每一时刻的文本预测都能自适应地关注图像中的不同区域,从而提高下一时刻文本预测的准确性。然而,注意力机制学习的权重在模型中是隐变量,缺少显式的监督信息指导,导致注意力机制普遍存在离焦问题(Liu等,2017)。为解决该问题,Lu等人(2017)提出并不是每个本文都对应具体的图像区域,对于部分虚词和注意力机制不置信的情况,引入视觉信息将误导文本预测的结果。因此提出一种“哨兵”模型,当注意力机制的输出结果不足以对预测的单词提供有效的指导信息时,依赖语言模型进行文本预测。Huang等人(2019a)通过分析注意力机制预测的结果与输入单词的相关性,提取可靠信息对图像编码特征和输入词向量进行加权,以修正注意力机制的输出结果。除此之外,Zhou等人(2019)额外引入名词在图像中的位置信息,显式地监督注意力机制的学习。然而,收集描述中的名词在图像对应位置的标注信息引入了额外的标注成本。Zhou等人(2020)提出基于图像和文本的匹配模型进行知识蒸馏,以提高注意力机制的定位能力,降低了监督信息的标注成本。Ma等人(2020)提出对预测的单词重建作为对注意力机制的规则化,以避免注意力机制关注不相关的图像区域。Zhang等人(2021)通过视觉图模型和语言图模型的对齐操作提高注意力机制的准确性。这些方法都一定程度地改善了注意力机制,但准确性远低于预期效果。
1.2 语言生成模型
语言生成模型旨在预测句子中文本生成的概率。当前,图像描述任务中的语言模型可以分为两类,一类是基于LSTM的模型(Vinyals等,2015),主要结构基于单层LSTM或多层LSTM进行序列预测;另一类是基于Transformer的模型(Vaswani等,2017)。
LSTM可以对时间序列进行关联建模,为生成复杂的文本序列奠定了基础。在该方案中,图像的特征编码作为LSTM的第1个词向量输入,其后每一时刻以前一时刻预测的文本作为词向量的输入,预测下一时刻的输出单词(Vinyals等,2015)。然而,该过程较大程度地依赖语言模型,忽视了图像的视觉信息。Gu等人(2018)设计了一种双层LSTM序列生成器,第1层LSTM生成粗略的图像描述,第2层LSTM以第1层LSTM的输出作为输入,生成更加准确的图像描述。Huang等人(2019b)进一步改进多层LSTM结构,针对LSTM预测不够准确的问题,提出基于每层输出结果的置信度,动态决定是否需要引入更深的LSTM修正预测结果。Guo等人(2020)提出先通过标准的LSTM模型输出完整的图像描述,随后结合完整描述的上下文对每个单词进行修正。然而,LSTM对较长的序列建模能力不足。同时,LSTM的训练过程是串行的,导致模型训练较为耗时。
Transformer的模型结构广泛用于自然语言处理领域(Vaswani等,2017),并逐渐应用于自动图像描述任务。标准的Transformer编码器采用多层的自注意力操作(self-attention)实现图像的上下文关联。解码器对生成的单词采用掩膜化的自注意力操作(masked self-attention),建模文本序列的上下文信息,同时采用跨模态注意力模块(cross attention)动态地更新图像的特征编码,以输出正确文本。同时,解码器通过自堆叠形成更加鲁棒的词汇预测。然而,堆叠增加了模型的深度,伴随而来的梯度消失使模型训练困难。
本文对Transformer的结构进行扩展,提出一种新颖的多层级解码器动态融合的图像描述模型。该模型通过解码器级联实现注意力机制的渐进式精化,并设计动态融合策略,自适应地融合由粗到精的文本信息,提高文本描述的准确性。同时,缓解了梯度消失现象,使模型训练更加稳定。
2 模型设计
本文模型的整体结构如图1所示。模型采取编码器—解码器架构。对于输入图像I,其对应的语言描述为y1:T,其中T为文本描述的最大长度。I经过卷积神经网络抽取图像的网格特征(grid features)。对于w×h的网格特征,每个特征向量都对应于原始图像特定区域的高层语义表示。将网格特征扁平化排列后(flatten),通过自注意力机制进一步增强,最终得到图像的视觉特征编码X={x1,x2,…,xN},其中,xi是dx维的特征向量,N=w×h是网格特征的总数。解码器则基于图像的编码特征预测描述图像内容的语句。不同于标准的解码器,本文提出的解码器采取级联结构,下一级解码器以上一级解码器预测的文本为指导,由粗到精地逐渐提高预测精度,从而生成更加准确的图像描述。同时,设计了一种自适应融合模型,结合多层次文本的输出实现对序列的综合预测,使图像描述更加准确。

图1 基于多层级解码器和自适应融合的图像描述模型的整体框架Fig.1 Overall framework of the proposed method
2.1 标准解码器结构
本文提出的解码器基本结构是标准Transformer解码器(Vaswani等,2017),包含1个跨模态注意力模块和1个文本生成模块。跨模态注意力模块通过基于点乘的注意力机制(dot-product attention)建模文本与图像之间的跨模态关联。具体地,该机制以查询矩阵Q∈RM×d、键矩阵K∈RN×d和值矩阵V∈RN×d为输入。查询矩阵由M个d维向量构成,键矩阵和值矩阵由N个d维向量构成。首先,通过计算查询矩阵与键矩阵之间的相似性预测在N个不同的值向量上的权重矩阵,计算为
(1)
式中,α=[a1,a2,…,aN] 描述了不同的值向量对应的注意力权重,A()为权重计算函数。较大的权重表示对应的值向量与查询的相关性更大。随后,结合权重矩阵和值矩阵,对不同的值向量加权融合,得到经过注意力机制聚合后的向量表示,具体为
Z=fAttention(Q,K,V)=A(Q,K)V
(2)
式中,fAttention()为注意力机制的计算函数。在图像描述任务中,以文本序列编码矩阵Y和视觉特征编码X为输入。跨模态注意力模块首先将X和Y通过线性映射形成查询矩阵、键矩阵和值矩阵,并通过多头注意力机制预测对下一时刻输出单词具有区分性的视觉特征,并通过前馈神经网络(feed forward network)输出最终的特征向量F。即
Z=fAttention(WqY,WkX,WvX)
F=FFN(Z)
(3)

(4)
式中,SAmask()为经过掩膜化的自注意力函数。
最后,基于生成的加权图像特征编码,预测输出单词的概率分布,以预测该时刻的目标单词。具体为

(5)
式中,We是可学习的投影矩阵,将F映射为输出单词的概率分布。

2.2 级联解码器结构

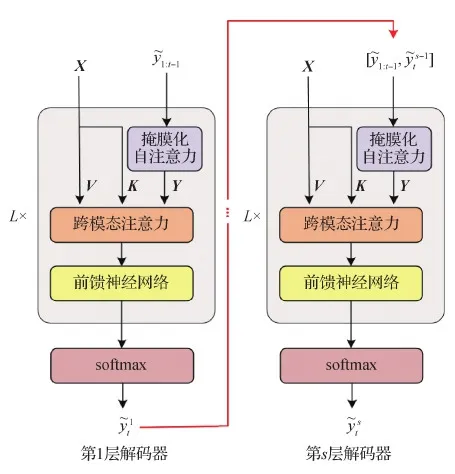
图2 级联解码器结构示意图Fig.2 Architecture of the hierarchical decoders
(6)
式中,[·,·]是拼接操作。对于第s级解码器,跨模态注意力模块以图像的视觉特征编码X和文本序列的编码矩阵Ys为输入,对t时刻的预测单词进行更新。具体为

(7)
2.3 多层级解码器自适应融合
解码器级联结构包含了文本由粗到精的预测结果,蕴含了描述图像内容的丰富细节。为进一步提高模型预测的准确性,本文提出一种自适应融合结构,以最大化利用不同层级解码器的输出结果。具体地,基于门机制(gating mechanism),动态地预测权重β,以控制不同解码器的输出信息流。如图3所示,第s层解码器的权重βs由注意力机制的输出Fs和输入文本序列的编码Ys共同决定。即
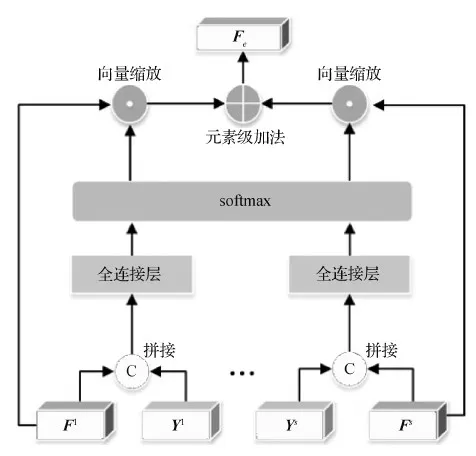
图3 自适应融合结构示意图Fig.3 Architecture of the dynamic fusion module
cs=Ws[Ys,Fs]
β=fsoftmax([c1,c2,…,cS])
(8)
式中,[·,·]是拼接操作,Ws∈R1×2d是可学习权重矩阵,β=[β1,β2,…,βS]代表不同解码器的权重。不同于传统的门机制仅依赖单路信息流预测其对应的权重(Cornia等,2020),本文提出的门机制同时输入多路信息流,引入具有互斥功能的softmax函数感知不同层解码器的上下文信息,融合全局信息流,以指导权重的自适应调整。
随后,自适应融合模块基于已学习的权重对不同层的注意力特征进行集成。即
(9)
最后,基于集成后的特征预测最终的输出单词。具体为
(10)
动态融合结构能为多层级解码器更好地引入监督信息并缓解梯度消失。以最容易形成梯度消失现象的第1级解码器为例,设模型学习的损失函数为L,第1级解码器的参数为θ1。由式(8)—式(10)可知,θ1的梯度计算为
(11)


图4 不同解码结构的对比示意图Fig.4 The architectures of different decoders ((a) vanilla decoder architecture; (b) stacked multi-layer decoder; (c) concatenated multi-layer decoder; (d) hierarchical decoders)
2.4 学习策略
本文采用图像自动描述的标准训练方法(Rennie等,2017),将训练过程分为两个阶段。第1阶段对每个时刻生成的单词采用交叉熵损失函数(cross-entropy loss)进行训练,第2阶段采用强化学习对描述生成的模型进行调优。
在以交叉熵损失函数为目标的训练阶段,通过输入真实文本y1:t-1,预测与之对应的下一单词。记模型的参数为θ,损失值为LXE。采用最大似然估计,以最大化真实单词yt的预测概率,具体为
(12)
式中,T为句子的长度。交叉熵损失函数预测过程简单,但是每个单词独立优化,导致生成的句子完整性和流畅性不足。
为解决该问题,本文以交叉熵损失函数训练得到的θ作为初始值,以SCST(self-critical sequence training)强化学习(Rennie等,2017)为模型训练的第2阶段,进一步优化文本描述的评价指标。具体地,解码器的输出作为“实体”与外部环境进行交互。“行为”则是对下一个单词预测。在预测完整的文本序列后,“实体”收到一个奖励(reward)。本文定义奖励为预测的图像描述与真实描述之间的相似性,用语言评价指标CIDEr描述。强化学习的目标是最小化负的期望奖励,具体为
(13)

(14)
式中,b代表基础模型生成的图像描述对应的奖励分数。本文采用贪婪算法(greedy decoding)作为基础模型。
在序列的预测过程中,本文采用集束搜索策略(beam search),即每个时刻从解码器的概率分布中采样概率最大的前k个单词,并在解码过程中始终保留置信度最高的前k个文本序列。最后,将置信度最高的序列作为预测的文本描述。
3 实验结果与分析
3.1 数据集和评估指标
实验在MS COCO(Lin等,2014)和Flickr30K(Plummer等,2015)公开数据集上进行,对图像描述模型进行评价。MS COCO数据集包含123 287幅图像,Flickr30K数据集包含31 783幅图像。两组数据集均涵盖广泛的自然场景,每幅图像均提供5条参考描述。实验采用Karpathy和Li(2015)提出的训练集和测试集划分方法对模型进行训练和评估。对MS COCO数据集,分别取82 783、5 000和5 000幅图像及其描述作为训练集、验证集和测试集。对Flickr30K数据集,分别取29 000、1 000和1 000幅图像及其描述作为训练集、验证集和测试集。
为评估模型生成图像描述的质量,采用BLEU-1、BLEU-4(Papineni等,2002)、METEOR(Banerjee和Lavie,2005)和CIDEr(Vedantam等,2015)等标准的图像描述评估标准验证模型的效果。以上指标分别记为B-1、B-4、M和C。B-1和B-4评价预测语句与参考语句之间1元组和4元组共同出现的程度,衡量预测语句的准确性;METEOR描述句子中连续且顺序相同的文本数量,反映语句的流畅度;CIDEr使用语法匹配测量生成句子与参考语句之间的语义相似性,与人类的主观评价一致。
3.2 实施细节
本文基于深度学习框架Pytorch实现所述模型,模型的训练和测试均使用2080TI GPU。在图像的编码器部分,采用Jiang等人(2020)的方法抽取图像的网格特征,其中网格大小为7 × 7,每个特征表示为2 048维的向量。文本的编码采用标准的词嵌入模型(Cornia等,2020)。模型的实现细节中,本文参照Transformer的一般设置,将维度d设为512,FFN的隐藏层特征维度设为2 048,dropout的概率为0.1。对于每层解码器,L设为1。采用ADAM(adaptive momentum estimation)优化器进行模型训练,批处理大小(batch size)设为50。在交叉熵学习阶段,初始学习率设为0.000 5,学习率变化过程参照模型训练的一般设置(Cornia等,2020)。如果训练过程中,验证集的CIDEr连续下降5个训练周期(epoch),则进入强化学习阶段。在强化学习阶段,学习率固定为5×10-6。当验证集的CIDEr连续下降5个训练周期后,模型训练结束。在测试过程中,集束搜索中k值设为5。
3.3 消融实验与分析
为验证多层级解码器动态融合的有效性,设计4种不同结构与本文提出的模型进行对比。第1种结构(图4(b))为级联结构中每层解码器独立地设计损失函数,预测过程依靠最终解码器输出的结果,该结构记为堆叠;第2种结构(图4(c))对不同解码器的输出拼接后预测文本序列,该结构记为拼接;第3种结构将式(8)采用的softmax门函数替换为sigmoid门函数,以独立计算不同解码器的权重;第4种结构将式(8)中的Ws设为d×2d的权重矩阵,βs此时为与解码器输出特征维度相同的矢量,对不同维度的特征赋予不同的融合权重。不同的解码器结构性能对比结果如表1所示。
从表1可以看出,相比于堆叠和拼接,自适应加权融合方法在MS COCO和Flickr30K数据集都具有明显优势。具体地,堆叠结构的CIDEr在MS COCO数据集上下降了1.4,在Flickr30K数据集上下降显著,比本文方法低4.3。拼接结构结果相似。在门函数设计方面,采用sigmoid门函数预测不同层解码器的权重使CIDEr在MS COCO数据集上下降了1.3,在Flickr30K数据集上下降了0.06。这意味着通过softmax操作引入不同层解码器的上下文关联对于解码器的权重控制十分重要。最后,对比基于矢量权重的融合方法,标量权重能够显著提高图像描述的准确性。特别地,基于矢量权重的融合方法在Flickr30K数据集上的CIDEr仅为62.0,显著低于基于标量权重的融合方法。原因是矢量权重增加了模型参数量,使预测结果对噪声干扰更加敏感,因此在较小的Flickr30K数据集上性能下降更加明显。

表1 不同的解码器结构对图像描述性能的影响Table 1 Ablation study on different decoder architectures
为进一步分析级联结构的有效性,实验对S的变化对图像描述性能的影响进行分析,结果如图5和图6所示。可以看出,当S取3时,模型在MS COCO和Flickr30K测试集上性能均达到最佳,这与标准的Transformer堆叠的数量一致。因此,在后续实验中,本文将S设置为3。

图5 参数S对MS COCO测试集性能的影响Fig.5 The impact of S on MS COCO test set

图6 参数S对Flickr30K测试集性能的影响Fig.6 The impact of S on Flickr30K test set
3.4 对比实验与分析
实验挑选12种代表性方法与本文提出的模型开展定量比较。包括Up-Down(Anderson等,2018)、Transformer(Vaswani等,2017)、M2(meshed-memory Transformer)(Cornia等,2020)、POS-SCAN(part-of-speech enhanced stacked cross attention)(Zhou等,2020)、GVD(grounded video description)(Zhou等,2019)、Stack-Cap(Gu等,2018)、AAT(adaptive attention time)(Huang等,2019b)、RD(ruminant decoding)(Guo等,2020)、CGRL(consensus graph representation learning)(Zhang等,2021)、Cyclical(Ma等,2020)、SOCPK(scene and object category prior knowledge)(汤鹏杰 等,2017)和CMFF/CD(cross-layer multi-model feature fusion and causal convolutional decoding)(罗会兰和岳亮亮,2020)。其中,Up-Down和Transformer是基准模型;M2是目前性能最好的图像描述模型;SCAN、CGRL和GVD通过修正注意力机制提高图像描述的准确性;Stack-Cap、RD和Cyclical通过引入解码器级联结构提高图像描述的性能;SOCPK和CMFF/CD通过改善图像的特征表示提高图像描述的准确性。
表2展示了不同方法在MS COCO和Flickr30K数据集上的对比结果。

表2 不同方法在MS COCO和Flickr30K测试集的性能比较Table 2 Comparison of performance among different methods on the MS COCO and Flickr30K test set
在MS COCO数据集的实验结果表明,本文方法显著改善了基于Transformer的基准模型,同时高于其他对比方法。具体地,对于描述短语重叠率的评估指标,B-1指标比M2提高了0.5,说明本文提出的模型能精确地输出描述图像的单词;对于描述句子流畅程度的指标,M指标相比对比方法中的最好结果也略有改善。对于描述语义相似性的指标,CIDEr提升更显著,相比当前最好的模型M2提高1.0,说明模型能更好地输出与人类主观描述一致的文本序列。对比Transformer、M2、Stack-Cap、AAT和RD在各项指标上的性能,本文方法性能均高于对比方法。值得注意的是,在Transformer和M2结构中,堆叠的参数L设置为3,与本文的层级S取值一致,表明本文模型复杂度与Transformer和M2等对比方法接近,也间接证明了本文提出的级联结构设计的有效性。
在Flickr30K数据集上的实验结果表明,本文模型在较小数据集上能够保持良好描述效果。具体地,相比M2模型,本文方法在CIDEr上提高了2.2。B-1、B-4和M指标也均高于M2。相比引入额外监督信息的SCAN和GVD方法,本文提出的模型在CIDEr指标上分别高出0.6和7.6。以上结果表明,本文提出模型同时关注了图像描述的准确性、流畅性和语义的正确性。
3.5 可视化分析
图7展示了本文模型与Transformer基准模型在MS COCO测试集上对部分图像的描述对比。整体来看,本文方法能够输出更加准确和丰富的图像描述。例如,图7第1行,本文模型能够准确预测出猫旁边小物体是a box of donuts,而不是toy;图7第2行,本文模型能够在同类物体密集出现条件下正确预测量词。为了进一步验证多层次解码器的有效性,本文对跨模态注意力机制进行可视化分析。由图7(b)可见,Transformer基准模型关注的视觉区域更分散,受背景干扰较大。例如,图7第1行,注意力机制部分关注于“猫”后方的背景区域,从而对描述“猫”周围环境时造成干扰。对比图7(c)可见,本文提出的级联解码结构能够准确定位至图像的相关区域,从而生成更加准确的文字描述。以上可视化分析结果从另一角度验证了本文方法的有效性。
4 结 论
本文提出了一种结合多层级解码器和动态融合机制的图像描述模型。通过设计解码器级联结构实现注意力机制的渐进式精化。其中,高层级的解码器以低层级解码器的预测结果为输入。由于该输入与预测的目标单词更相关,注意力机制能够更有效地聚焦到图像的关键区域,从而生成更准确的文本序列。此外,设计了一种解码器动态融合策略,根据每级解码器的输出动态地调整输出权重,自适应地融合由粗到精的文本信息,提高图像描述的鲁棒性。同时,动态融合为不同层次解码器引入监督信息,进一步解决了级联结构容易产生的梯度消失现象,使模型训练更加稳定。但是自动图像描述的准确率还有进一步提升空间。下一步工作将尝试改进图像的特征表达以提高图像描述的丰富性,优化图像的视觉特征和语言模型的关联以提高自动图像描述模型的鲁棒性。
猜你喜欢
心理学报(2022年5期)2022-05-16
小雪花·成长指南(2022年1期)2022-04-09
当代陕西(2020年17期)2020-10-28
现代信息科技(2019年18期)2019-09-10
证券市场红周刊(2018年3期)2018-05-14
科技创新与应用(2017年26期)2017-09-12
第二课堂(课外活动版)(2016年2期)2016-10-21
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
网络传播(2014年12期)2015-03-16
