
面向物联网设备的安全集群证明及修复协议①
2022-09-20 04:11林江南吴秋新
计算机系统应用 2022年9期
林江南, 吴秋新, 冯 伟
1(北京信息科技大学 理学院, 北京 100192)
2(中国科学院 软件研究所 可信计算与信息保障实验室, 北京 100190)
1 引言
在物联网发展迅速的今天, 物联网设备早已遍布人们日常生活的周围. 物联网设备通常使用低功耗的嵌入式智能设备, 用于执行一些特定的任务, 比如发送、传输以及处理一些在环境中所获得的数据[1], 从而构成了物联网系统, 以此提高整个网络的运行速度和服务质量.
由于嵌入式物联网设备的低成本, 大量的物联网设备应用于日常生活中, 但其内存、计算能力等方面都存在限制, 特别是缺乏安全机制[2]. 从而导致嵌入式设备系统容易成为网络攻击的目标, 如Mirai[3], 将僵尸程序传播至网络, 感染在线设备, 从而形成僵尸网络,导致很多网络服务功能瘫痪, 无法进行正常工作, 从而造成无法挽回的损失.
而远程证明能够证明设备完整性这一特性, 恰好可以用于解决嵌入物联网设备的安全问题. 利用远程证明基于证明者提供的可信度建立起一个安全的交互式协议[4]. 目前学术界已经提出了很多的远程证明协议, 大体可以分为3类: (1) 基于软件的证明, 无需硬件支持, 但往往基于实践中难以实现的假设, 如SAKE[5]、VIPER[6]; (2) 基于硬件的证明, 由于其昂贵且复杂的特性, 对于资源受限的嵌入式物联网设备不太实用, 如TrustVisor[7]、Flicker[8]; (3) 混合证明, 旨在提供最小化的硬件支持来弥补纯软件证明的安全性不足, 实现与基于硬件相似的安全保护, 如TrustLite[9]、TyTAN[10].
本文提出了一种基于信誉机制和Merkle树的安全集群证明及修复方案, 主要贡献如下:
(1) 本文方法使用信誉机制实现了多对一的证明协议, 能有效解决单点故障, 消除了固定的验证设备,可以从设备触发验证, 使得证明更加及时, 并且适用于半动态网络.
(2) 引入Merkle树进行度量, 能够快速精确地判断出被恶意软件感染的代码块, 再形成定制的补丁进行恢复, 不仅减少数据传输, 还能高效地修复受损设备.
(3) 本文还对提出的集群证明方法进行了安全性分析和性能评估, 结果表明, 本文集群证明在提高了安全性的同时所导致的性能开销是可以接受的.
本文结构如下: 第2节介绍集群证明的相关工作;第3节给出本文基于的系统模型与假设; 第4节详细给出本文提出的集群证明协议与修复机制; 第5节对本文提出的协议进行安全性分析; 第6节为性能评估,包括计算、通信、内存、运行时间以及能源开销方面的分析、本方案与ESDRA[11]及HEALED[12]的安全性对比以及仿真模拟的实验结果; 第7节对本文工作进行总结.
2 相关工作
集群证明. 纵观集群证明的发展历程, 随着第一个集群证明协议SEDA[13]提出至今, 不少集群证明的方案呈现在公众的视野中. 大多数都是以SEDA为基础的一对多证明协议. 这些证明协议以验证者为根构造生成树, 从根往下进行证明, 最后不断将证明结果汇聚至验证者, 这也就意味着这类协议只能应用于静态网络. 比如, SeED[14]在SEDA的基础上增加了抵抗DoS攻击, 从而形成了非交互式的拒绝服务攻击的认证方案. 在2019年, ESDRA提出了第一个多对一的集群证明协议, 通过设备端发起的证明, 从而可以适用于半动态的网络. POSTER[15], SALAD[16]都是基于设备的自身认证, 积累个体验证报告, 最后共享至整个网络, 从而实现适用于动态网络的认证协议.
安全修复. 目前大多数协议只提出了证明方案, 对于后续的修复没有详细的介绍.已有的修复协议方案,如HEALED, 利用集群相同软件配置的可信设备对其进行修复, 从而将受损设备回滚至可信状态.
3 系统模型与假设
在大规模的集群 S 中包含着软硬件配置不同的异构设备, 并且在通信过程中,能耗随距离增加而急剧增加. 面对着无处不在的各式攻击, 如果让管理者一一验证, 不仅存在验证不及时的风险, 并且验证者的性能将成为整体认证方案效率的瓶颈. 为了提高验证效率以及降低功耗, 我们将集群S 中的每个设备按照通信距离分成若干个簇, 每个簇都有一个簇头节点. 在簇内, 各个设备节点之间相互证明从而构建出集群的可信环境.此外, 检测到受损设备应当给予修复的机会, 若是修复不了, 即可判定修复成本大于他自身的价值, 可以进行移除操作. 当然, 为了识别集群中由于遭受物理攻击而探测不到的设备, 实施在线探测及时识别可能受到攻击的设备, 并进行隔离验证.
在本文集群证明系统中, 主要的参与者包含: 网络管理者 M, 负责初始化以及修复集群中受损的设备节点; 簇头节点Di, 负责管理簇内设备; 组内普通节点Dij,由簇头节点Di进行管理.
本文方法基于以下几点假设:
(1) 假设所有节点都满足安全远程证明的最低硬件要求, 即只读存储器和简单的内存保护单元, 可以通过SMART[17]等机制实现.
(2) 假设证明例程为原子程序运行, 并且证明代码无法被修改.
(3) 为了确保证明结果的可靠性, 假设每个节点应至少有3个邻居设备.
(4) 假设物理攻击会导致设备一段时间不可用, 从而攻击期间无法探测到设备.
(5) 由于DDoS攻击几乎不可能被完全抵抗, 与其他集群证明方案一样, 本文不考虑DDoS攻击.
4 系统方案
本方案提出一个多对一的集群证明及修复方案.如图1所示, 方案可分为两个阶段: 离线阶段和在线阶段. 在离线阶段完成设备的初始化以及设备之间的连接过程, 从而构建出整个集群的网络. 而在线阶段主要完成对设备的验证以及发现受损设备后进行的修复协议. 此外, 在线阶段还加入了缺失探测机制, 可以及时发现因物理攻击导致不可达的节点, 将其隔离出集群,再进行修复或者彻底移除操作. 表1定义了本文所用的符号及参数.

表1 符号和参数
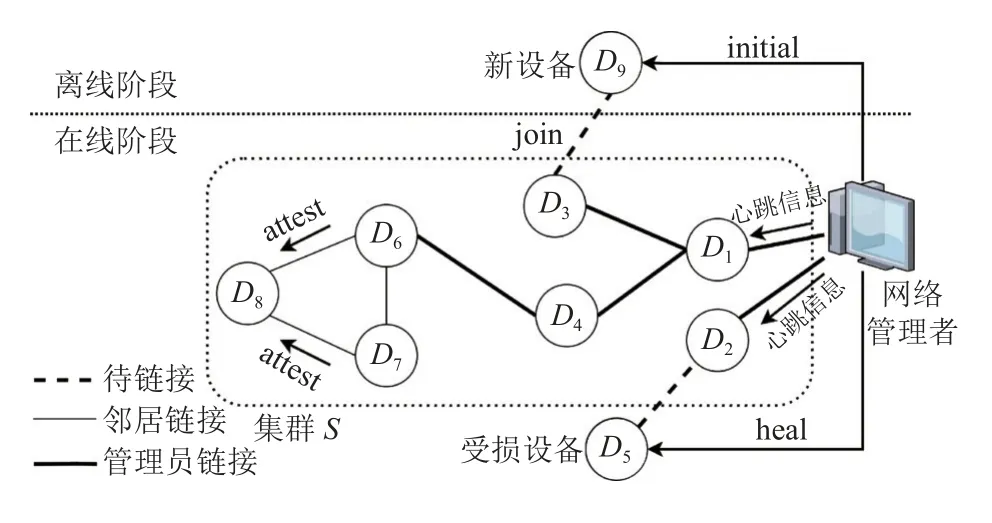
图1 协议网络图
4.1 离线阶段
离线阶段包括设备的初始化( i nitial协议)以及设备连接( j oin协议). 设备初始化过程中, 网络管理者对新增设备进行初始化工作; 设备连接过程是设备之间通过网络管理者提供的安全通道建立连接, 为后续证明及信息交流提供基础.
4.1.1 设备初始化
如图2所示, 当新设备 D7要加入网络时, 网络管理者 M 就会对D7执 行i nitial协议, 生成设备对应的配置信息, 其中包括: 私钥 s k7, 公钥 pk7, 身份证书c ert(pk7), 代码证书c ert(c7), 网路管理员公钥 pkM, 初始信誉值w7, 最后验证时间 ta7以及唯一设备标识符d7, M保存软件配置代码c7, 便于后续修复(h eal)协议的使用. 对新设备的初始化可以表述为:
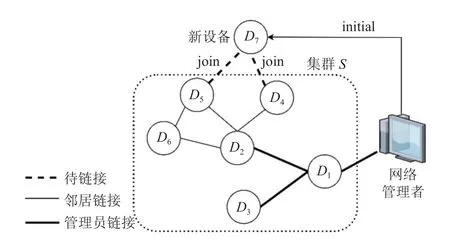
图2 离线阶段
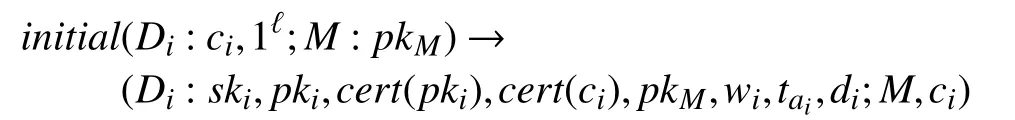
每个设备的公私钥对都是基于SM2 ECC密钥体制[18]生成. 代码证书c ert(ci)包含设备的可信散列代码ci以及证书的公共信息. tai和te主要是在证明阶段提供可靠的标准, 当前时刻为 tai+te时, 就会对该设备执行设备证明( a ttest协议). 由于触发验证条件在于设备本身, 集群内就可以并发执行a ttest协议. 此外, 每个设备的信誉值取决于它参与的每次证明例程. 在证明例程中, 任何一个节点没有权限为其他节点报告信誉值. 一旦发现某个节点是不可信的, 其信用值将被设置为-wmax. 在我们的方案中, 信誉值更高节点在邻居节点的最终证明结果生成中拥有更大的权重.
4.1.2 设备连接
当设备 Di初始化或者更新后, 通过网络管理者M提供的安全通道, 与邻居设备进行配置信息的交换.如图2所示, D7初 始化后, 与邻居设备D4和D5进行连接. 在连接过程中, 它们双方交换自身的公钥 pki、身份证书 c ert(pki) 、代码证书c ert(ci) 、当前信誉值wi、最后验证时间tai以及唯一设备标识符di. 设备的配置信息存储在受硬件保护的内存之中, 这就意味着设备节点无法虚报配置信息. 通过已认证的密钥协商协议生成基于双方私钥的会话密钥k, 在本文中使用非相邻形式椭圆曲线Diffie-Hellman密钥交换协议[19]. 在后面的证明和修复过程中, k是双方进行数据交流的保证. 设备连接过程可描述为:
网络管理者 M会周期性地根据簇头选择算法来选取簇头, 使得簇头的分布能覆盖整个集群, 本文采用基于最佳簇半径的无线传感器网络分簇路由算法[20]. 簇头节点通过信息的传输形成了以 M为根节点的树形结构, 其他普通设备节点以传输距离为参照连接到对应的簇, 从而形成集群. 普通设备保存簇头的公钥 pkM, 便于后期提交证明报告. 对于网络管理者 M , 存储集群中所有设备当前的信誉值, 在每次证明例程后会更新对应设备的信誉值. 当簇头发现不可信的设备节点时, 其信誉值将被设为- wmax, 将wi以 及di发 送给 M , 然后 M 对其进行隔离, 再执行h eal协议或者移除网络等操作.
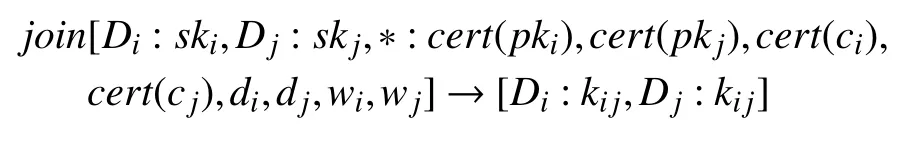
4.2 在线阶段
在线阶段包括对设备进行验证(a ttest)、对设备的修复( heal)以及缺失探测3个子协议. 一旦有设备Di触 发验证条件, 邻居设备就会对其执行a ttest协议, 每个邻居生成临时的证明结果上传至簇头, 由簇头生成最终的验证结果, 最后将 Di的最新信誉值上报网络管理者 M. M 接收到Di的最新信誉值, 若等于信誉值最大值- wmax, M 就会对Di执 行h eal 协议, Di将最终修复结果反馈 M. 在缺失探测中采用心跳协议来进行, M广播心跳请求, 由簇头节点负责收集反馈, 找出不可达节点,从而对其进行修复或移除等操作.
在此, 我们引入Merkle树对设备当前的软件状态进行度量. 由于Merkle树能够自下而上计算度量值,从而汇聚到根节点. 因此, 在证明阶段, 邻居设备仅需验证根节点的度量值即可形成临时验证报告. 在修复阶段, 如图3所示, 证明设备 Di将待证明的代码分成ω段等长的部分: c1,c2,···,cω, 并对应计算哈希值:hi[ω+1],hi[ω+2],···,hi[2ω], 然后以这些哈希值为叶子节点,c′i为根, 构造Merkle哈希树, 其中, 2 ω表示Merkle hash tree (MHT)中除根节点之外的节点数. 受恶意软件感染的代码段会导致沿着根路径生成错误的哈希值. 通过这种方式, 可以确认受恶意软件感染的代码段.
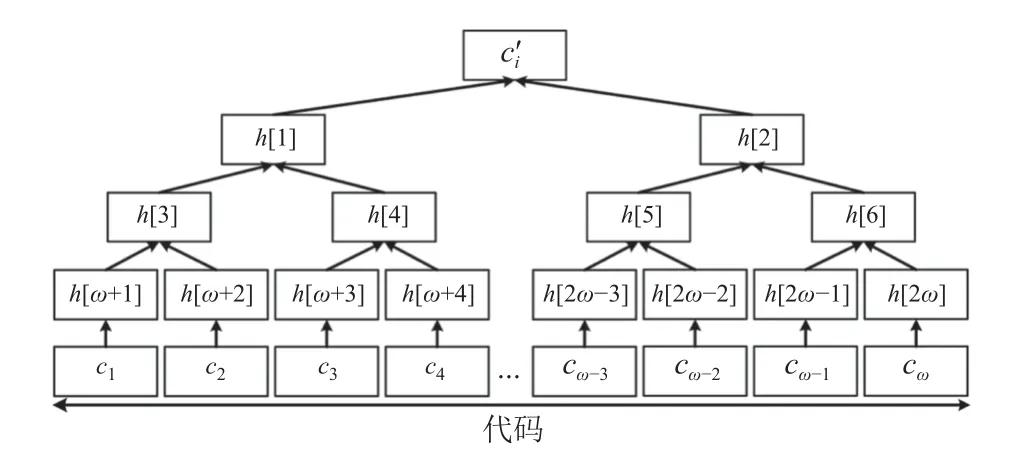
图3 Merkle哈希树
4.2.1 设备证明
每当设备 Di的 信誉值wi<wmin或者到达验证时刻,邻居设备 Dj就会对Di发出挑战, 并记录发送时间, 挑战包含随机数 Nij. Di结合挑战和自身当前状态以及会话密钥kij生成消息验证码µij来报告其软件状态, 在此采取基于MHT进行度量, 最终度量为以为根节点的树. Dj接 收到结果后, 通过连接阶段保存的cij以及密钥kij验证 µij的正确性, 若 µij验证成功, 则Dj生成临时验证结果 bij=1, 反之则推断 Di受 到攻击, 即bij=-1, 而当Di无 响应, 即为超时, 则bij=0. 形式化为:
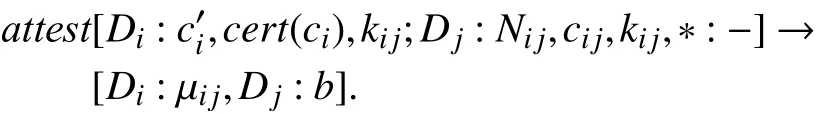
簇头接收所有邻居节点的临时证明结果后, 通过信誉机制进行最终验证结果, 每个邻居设备的信誉值代表着其参与生成最终验证结果的权重. 最后广播Di的唯一设备标识di以 及当前的信誉值wi. 对于邻居设备Dj, 簇头会将最终验证结果 f与各邻居节点的临时证明作对比, 做出相对应的奖惩措施. 最终验证结果及新信誉值计算公式如下:
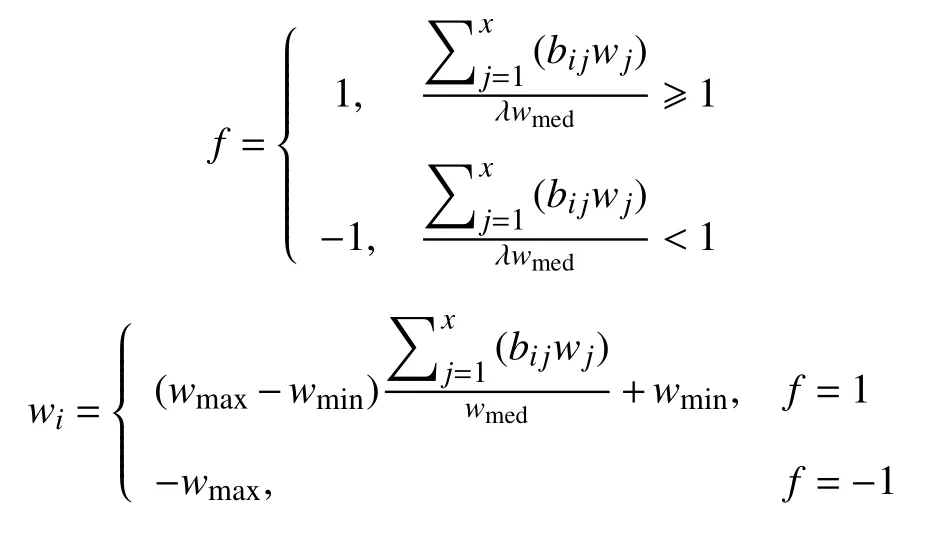
其中, x 为 Di邻居数量, wmed为邻居节点信誉值中位数,它能够对于高信誉值的设备起到制衡作用, λ为调和参数, 且λ ∈(0,1], 随λ 增加验证的条件越是严格. a ttest协议流程如算法1所示.

Dj Di attest算法1. 邻居设备对的算法Nijc′icijkij输入: ; ; ;b输出:Dj 1: // 运行程序reqij=mac(kij;Nij)Nij Di 2: 发送 , 给 ;startTimer()3: ;Timerout()=1 bij=0 4: if then ;Vermac(kij;Nij||cij,µij)=1 bij=1 5: else if then ;bij=-1 6: else ;7: end if bij 8: 将 发送至簇头Di 9: // 运行程序Vermac(kij;|reqij)=1 10: if thenµij=mac(kij;Nij||c′i)11:12: end if
4.2.2 设备修复
网络管理者 M接收簇头上报证明结果, 包括证明设备 Di的更新信誉值wi以 及唯一设备标识符di. 当wi=-wmax, M 对Di执行heal协议. 具体流程如下.
由于每个设备都有 M的公钥, 因此 M 可以在集群中与任意设备进行通信, M 向Di发送一个请求信息reqi. Di接收后将其软件配置和一个新的随机数Ni利用MHT算法度量后用 M 的公钥加密后发送给 M . M将自己保存的软件配置 ci以同样方式度量进行MHT的遍历, 直到到达叶子节点. 最后, M为每个异常的叶子节点添加一个代码段l, 用自身私钥 s kM对l进行签名生成补丁Γ, 并将其发送回Di. 一个代码段l ={s,e,p}包含其起始地址s、结束地址e , 其代码p. Di进行补丁修复,修复成功输出 r =1. 否则, 输出r =0. h eal过程可以通过如下公式表述为:
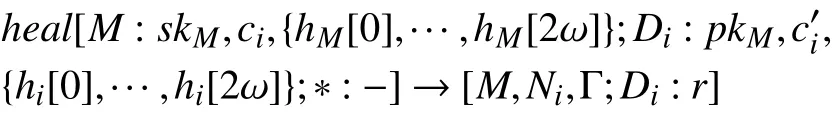
Di可以谎报修复结果来躲避补丁修复, 因此, 当heal 结束后, 将Di的信誉值设置为0, 这样Di就会触发attest 协议, 对Di进行再次证明, 若证明可信, 则说明Di已经恢复正常的软件配置. 反之, Di的信誉值将被设置为- wmax, 从而需要进行再次修复, 直到其配置正常. 此外, 为了避免同一设备a ttest 与h eal反 复执行, M记录设备执行 heal 的时间, 如果出现连续3次执行h eal失败, 将直接移除该设备. h eal协议的算法流程如算法2所示.

M Di heal算法2. 网络管理者对的算法Nic′i{hi[0],···,hi[2ω]}pkM ci{hM[0],···,hM[2ω]}输入: ; ; ; ; ;r输出:M 1: //运行程序reqi=Sign(skM;Ni) Di 2: 发送 给 ;wait()3: //等待接收反馈decrypt(skM;d′i)=1 4: if then k<2ω 5: while ( ) then hi[k]!=hM[k]6: if ( ) then k=2k+1 7: ;8: else k++9: ;10: end if 11: end if l={s,e,p}12: ;Γ=Sign(skM;l) Di 13: 将 发送至wait() Di 14: //等待 回复后r=0 15: if then attest()16: ;17: end if Di 18: // 运行程序VerSign(pkM;Ni||reqi)=1 19: if then di=MHT(c′i)20: ;d′i=encrypt(pkM;di) M 21: 将 发送至22: end if wait()23: //等待接收补丁VerSign(pkM;Γ)=1 24: if then DoPatch(Γ)25: ;

r=1 26: ;27: else r=0 28: ;29: end if r M 30: 将 加密后发往
4.2.3 在线探测
在线探测阶段负责对整个集群设备进行定期的探测, 监测设备的运行状态. 本文采用基于多级心跳协议[21],由网络管理者定期给簇头节点发出心跳信息, 簇头节点在组内广播心跳信息, 并收集组内普通节点的心跳信息, 形成一个alive-node消息, 发给网络管理者. 若在规定的时间未接收到节点设备的心跳信息, 利用多级心跳协议增加和删除节点的便利性, 将其从集群的拓扑网络中删除, 经过验证为可信后, 再重新连接进入集群中.
5 安全性分析
我们将这个过程形式化为一个安全实验EXPADV敌手 A DV可以与其相连的设备进行通信, 至少修改一个设备 Di的软件配置, A DV可以篡改、窃听或删除所有通过 Di传输的信息. 经过一个多项式步骤后, Di被验证簇头最终验证为1, 即为证明成功. 也就是敌手成功攻破Di.
定义1. 安全集群证明. F是一个关于ℓN,ℓsign,ℓhmac的多项式函数. 受损设备通过证明的概率为Pr[f=1|EXPADV(1ℓ)=b] 在ℓ=F(ℓN,ℓsign,ℓhmac)中被认为是可以忽略的, 则证明和修复方案是安全的.
定理1. 如果底层签名、加密和MHTMAC方案是选择性防伪的, 则本方案是一个安全的集群证明方案.
证明: ADV 可以通过欺骗邻居节点返回b =1或欺骗网络管理者返回 r=1来破坏本方案的安全. 下面通过两种情况来分析:
(1) ADV 攻击a ttest: A DV 想要使得b =1来通过邻居节点的验证可以使用以下策略: 1) 使用基于原始代码的先前的HMAC µold; 2) 计算出基于新挑战的HMAC µ′; 3) 入侵多个邻居节点, 影响最终的证明结果.
对于策略1), 每次的挑战 N 都是新的随机值, 当且仅当 N =Nold时 , 验证可以通过. 然而N =Nold的概率为2-ℓN. 所以通过验证的概率可以忽略. 对于策略2), 一旦软件配置发生改变生成的HMAC无法通过邻居节点的验证, 因此µ′通过验证的概率也可以忽略. 对于策略3), 对于单个节点而言, P r[f=1|EXPADV(1ℓ)=b]是可以忽略的, 而同时攻破 k个节点概率为(Pr[f=1|EXPADV(1ℓ)=b])k, 也是可以忽略的.
(2) ADV 攻击h eal: h eal 协议由网络管理者 M 对受损设备 Di进行修复, A DV 可以以下策略来逃避h eal协议: 1) 伪造r =1返 回给 M ; 2) 在Di安装补丁前篡改补丁.
对于策略1), 虽然可以逃避补丁Γ 安装, 但是在之后的证明例程依旧被检测出来, 超过3次将被移出集群. 对于策略2), 与a ttest 类似, A DV 试图提取Γ 中提取补丁代码再进行修改的概率是可以忽略的.
因此, ADV 通过攻击a ttest 协议h eal协议来攻破良性设备的概率在 ℓN,ℓsign,ℓhmac上可以忽略不计, 再加上在线探测阶段对物理攻击进行检测, 由此可证明本方案是一个安全的集群证明方案.
6 性能评估
本节将从计算开销、通信开销、内存开销、运行时间以及能源开销这几个方面对本协议进行分析, 此外我们还对本文集群证明协议进行了仿真, 并与其他几个类似方法进行了对比.
(1) 计算开销. 对于普通设备而言, 主要计算开销在于一些密码操作. 在证明阶段, 证明设备需要计算mi个m ac() 并验证mi个V ermac() , 其中mi表示Di邻居设备的数量. 邻居设备验证一个 V ermac() 并 计算一个 S ign().对于簇头设备, 需要验证 mi个V erSign()并计算2个Sign(), 一个发往网络管理者 M, 一个广播到组内各个节点. 在修复阶段, 修复设备需计算2个e ncrypt()验证2个d ecrypt() , 而 M 需要验证2个V erSign()并计算2个Sign().
(2) 通信开销. 我们使用SM3实现MHTMAC, 密钥协商算法和签名方案都是采用基于SM2的算法. 以len(x)=1 表 示 x 的长度为1 B. 因此,len(MHTMAC)=32ω-16, 其中ω 为 验证代码分割的段数, l en(Sign)=64,len(N)=16, l en(µ)=16, l en(w)=4, l en(t)=4, l en(d)=4,len(b)=4, l en(r)=4. 证书的大小取决于密钥和签名,所以 l en(cert)=48. 因此, 在证明阶段, 证明设备而言,需发送( 32ω-16)miB以及接收1 6miB; 邻居设备而言,需发送20 B以及接收 ( 32ω-16) B; 簇头节点需发送(128+8ni) B接收4 miB; 网络管理者 M 接收64 B. 在修复阶段, 修复设备需接收36 B以及发送( 32ω-12) B,M发送36 B以及接收( 32ω-12) B.
(3) 内存开销. 每个普通设备需要存储: 1)自己的密钥对 ( ski,pki)和 设备标识符di; 2)邻居设备的设备标识符dj及 其信用值wj、 最近证明时间taj、 代码证书cert(hj)和会话密钥kij; 3) 簇头的公钥. 簇头设备还需要存储簇内所有节点的设备标识、相应的信用值和公钥. 因此,普通节点需要 ( 52+80mi) B的存储空间, 簇头节点需要(52+80mi+24ni)B的存储空间.
(4) 运行时间. 我们使用th、 tp、 tca、 ttr、 ts、 tv来表示计算或验证 MHTMAC、生成随机数、一跳访问信道并传输一个字节、签名或验证签名的时间. H是群的生成树的高度. 因此, 总证明时间tattest为:
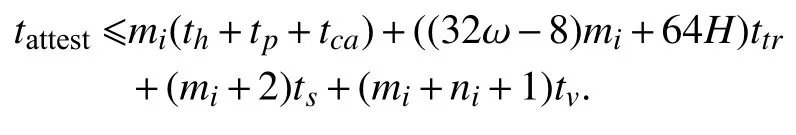
总修复时间theal为 :
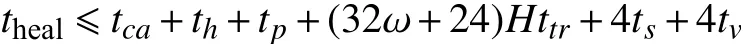
(5) 能源开销. 我们分别使用 Es、 Er、 Ep、 Eh、 Esg、Ev表示发送 1 B、接收 1 B、生成随机数、计算或验证 MHTMAC 以及签名和验证或签名的能源开销. 在一个证明过程中, 簇头节点的最大能耗为:
E≤(128+8(ni+1)Es)+4miEr+2Esg+tvmiEv
证明设备的最大能耗为:
Ei≤(32ω-16)miEs+16miEr+miEh+Ev
邻居设备的最大能耗为:
Ej≤20Es+(32ω-16)Er+Ep+Esg+Ev
在一个修复过程中, 修复设备的最大能耗为:
Ei≤(32ω+24)Es+(32ω+24)Er+Ep+Eh+4Esg+4Ev
本方案还与ESDRA、SEDA、SALAD在运行时间、平均能耗等方面进行比较, 具体数据展示如表2所示.

表2 不同方案对比
(6) 安全性对比. 我们将本方案与ESDRA、HEALED进行安全性对比. 如表3所示, 在我们的方案中, 增加了在线探测技术, 可以针对物理攻击造成探测不到的设备进行识别, 从而预防物理攻击. 在ESDRA中, 簇头与所有簇内设备公用一个会话密码, 存在会话密钥泄露的风险, 本方案改用簇头的公钥进行加密, 仅有簇头本身能够解密, 解决了会话密钥窃取的风险. 此外, 在ESDRA中, 证明设备的新信誉值计算存在高信誉值影响整个结果的风险, 一旦攻击者入侵高信誉值设备, 足以影响整个集群的安全性, 本方案引入中位数, 计算每个证明设备的邻居设备信誉值的中位数, 以此作为基准, 从而规避高信誉值设备“一票否定”的情况, 而在HEALED中, 利用传递性, 也同样存在高信任度的设备, 再加上证明节点的任意性, 很难快速找到受损设备.

表3 安全性比较
(7) 仿真结果. 我们使用OMNet++[22]对本文集群证明协议进行了仿真模拟, 并与ESDRA、SEDA、SALAD几个代表性工作进行了比较. 在仿真过程中, 我们使用嵌入式开发板上测得的密码算法性能数据[23]进行仿真, 相关密码算法在嵌入式开发板上的数据如表4所示.

表4 采用的密码操作耗时
对于本方案, 我们设置初始信誉值为3, 最大信誉值wmax为5, 最小信誉值wmin为 1, 调和参数λ 为0.8, 奖励信誉值为1, 惩罚信誉值为2. 通过仿真模拟, 以上4个方案得出数据如图4、图5所示.
图4展现了本方案与ESDRA、SEDA以及SALAD关于证明设备不同邻居数量的验证时间. 相较于ESDRA,由于本方案在上报临时验证结果是采用簇头的公钥进行加密, 并且后期广播证明设备的验证结果采用簇头签名, 因此运行时间有所增加, 但在总体看来, 为了提高协议的安全性, 这些性能牺牲还是在可以接收的范围内, 并且分布式证明的优势依旧可以体现. 图5描绘了本方案与ESDRA、SEDA以及SALAD关于不同的集群设备数量所进行的证明时间, 本方案对于集群数量的增大, 受影响的幅度较小.
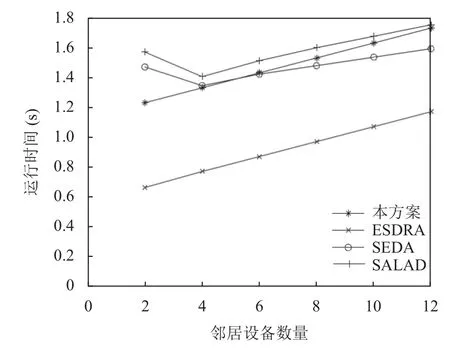
图4 邻居节点数量与运行时间关系图
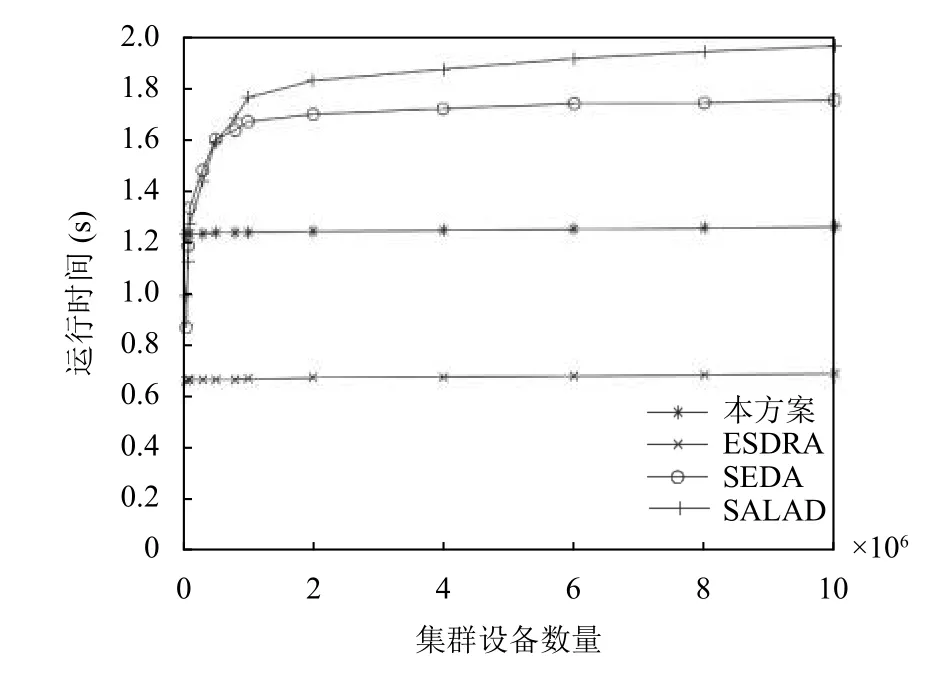
图5 集群设备数量与运行时间关系图
7 总结
本文提出了一种基于信誉机制和Merkle树的安全集群证明及修复方案. 利用信誉机制实现了多对一的证明协议, 不仅能有效解决单点故障, 可以从设备触发验证, 并且适用于半动态网络. 引入Merkle树进行度量, 能够快速精确地识别被恶意软件感染的代码块,并进行高效地恢复到可信状态. 通过对方案的安全性分析和性能评估, 结果表明, 本文集群证明在提高了安全性的同时导致的性能开销是可以接受的.
猜你喜欢
农业工程学报(2022年11期)2022-08-22
计算机应用文摘·触控(2022年8期)2022-05-25
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
文萃报·周五版(2021年15期)2021-05-08
计算机与网络(2018年2期)2018-09-10
知识就是力量(2017年2期)2017-01-21
中国质量万里行(2014年7期)2014-08-09
西安交通大学学报(2009年12期)2009-02-08
