
基于超前钻探及优化集成算法的隧道围岩双层质量评价
2022-09-19 11:40:32解威威宋冠先朱孟龙张亚飞
隧道建设(中英文) 2022年8期
梁 铭, 彭 浩, 解威威, 宋冠先, 朱孟龙, 张亚飞
(广西路桥工程集团有限公司, 广西 南宁 530000)
0 引言
据数据统计,截至2020年底,全国共有特长隧道1 175处,累计512.75万m[1]。伴随巨大的建设规模,我国隧道整体向大埋深、长洞线的方向转变,选址远、高应力、强岩溶、高水压、构造复杂等特点也逐步凸显[2]。为应对上述情况,保障隧道施工安全,如何进一步提高超前地质预报的合理性与准确性成为隧道领域的研究重点。
就隧道超前地质预报而言,常规的物探方法如地质雷达、TSP、红外探水等在预报距离、预报效果及操作难度等方面均存在不同程度的局限性,而钻探法通过对掌子面前方岩体进行物理钻进,能直观地反映未开挖岩体的真实地质信息[3-4]。但目前钻探数据解译工作主要依赖技术人员结合现场实际钻探情况进行,虽然钻机搭载的随钻测量系统可实时记录各项钻探参数,但通常只是作为解译参考,并未被充分利用[5]。总体而言,该种解译方式未跳脱经验判断的范畴,较为粗糙,是一种“伪定量”解译。
随着大数据、人工智能等信息化技术的发展,机器学习的理念已逐步渗入各个领域,为数据分析提供了新的思路[6]。近些年开始有研究者将机器学习的方法引入到隧道超前地质预报的数据定量解译中,并已分别在TSP[7-8]、隧道掌子面图片[9]、地质雷达[10-11]等领域取得了一定的成果。在超前钻探方面,由于在钻进的同时可提供大量与钻进深度相对应的定量指标,如推进速度、推进力、转矩、旋转速度等,这为机器学习在超前钻探地质预报中的应用提供了重要的数据基础。因此,基于钻探参数的超前钻探围岩质量评价受到越来越多学者的重视。国内如房昱纬等[12]针对复杂地层隧道施工,提出了一种基于神经网络的钻探测试数据智能分析和地层识别方法,对不同地层的识别准确率达到90%以上;邱道宏等[13]与Wang等[14]基于数字推进技术,分别利用量子遗传(QGA)-径向基函数(RBF)神经网络与支持向量机(SVM)对Ⅲ~Ⅴ级围岩超前分类进行研究,实际工程应用显示分类效果良好。国外如Galende-Hernández等[15]将三臂台车的推进速度、旋转速度等8项钻探参数与RMR法相结合,用于确定围岩级别,预测错误率仅为3%左右;Ghosh等[16]从23台钻机共186个钻孔中收集了推进速度、推进压力等4项钻探参数,利用机器学习对隧道掌子面前方岩体的空洞、塌方及破碎带的预测展开了研究。此外,在工程实用性方面,基于超前钻探参数的围岩智能质量评价方法在郑万铁路的多条隧道得到了成功应用[17]。可以预见,基于钻探数据定量解译的钻孔精细超前探测技术是未来隧道钻探预报领域的重要发展趋势[18]。
但以上研究普遍存在2个问题: 1)大多以单一围岩级别或地层属性作为预测结果,对于隧道施工的指导意义有限; 2)通常以某单一断面的预测结果对该断面所在一定区间范围内的围岩进行质量评价,未能充分考虑该区间整体的岩体质量,致使评价结果具备一定的偶然性与随机性,且以断面为单位极易受数据噪点的影响,从而进一步使得评价结果的真实性不足。
针对上述问题,本文提出以围岩完整程度及围岩级别组成隧道围岩质量评价双标签,在对超前钻探原始采样数据进行有针对性收集的基础上,构建适用于超前钻探数据的预处理流程及机器学习模型,最终形成基于超前钻探数据的隧道围岩双层质量评价模型,以期为隧道岩体开挖工法与支护措施的动态调整提供可靠岩体质量信息参考。
1 数据来源及分析
1.1 工程概况
柳州经合山至南宁三南高速公路凤凰山隧道位于南宁市上林县,隧道区属岩溶峰丛洼地地貌。隧道设计长度约为1 500 m,最大埋深约240 m。隧址区工程地质条件复杂,主要穿越较破碎—破碎的中风化灰岩地层,且岩溶较为发育,极易发生涌水突泥等不良地质灾害。为保障隧道施工安全,现场使用Casagrande厂家生产的C6-2型多功能履带式钻机进行超前钻探作业,并基于钻探数据及现场情况进行超前地质预报。凤凰山隧道超前钻探作业如图1所示。
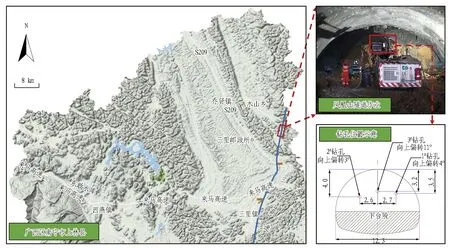
图1 凤凰山隧道超前钻探作业示意图(单位: m)Fig. 1 Schematic of advance drilling operation of Fenghuangshan tunnel (unit: m)
根据前期已积累的超前钻探地质预报数据,共收集包括YK109+118~+130(1号孔)、YK109+215~+235(1号孔)等钻探采样数据11 233条,数据涵盖的隧道长度累计约160 m,涉及到的数据标签在完整程度方面包括较完整、较破碎、破碎岩体及软泥填充空腔共4类,在围岩级别方面包括Ⅲ级、Ⅳ级与Ⅴ级共3类。
1.2 钻探数据分析
在隧道超前钻探过程中,随钻测量系统随进尺变化进行随机数据采样,每m采集数据约50条。每条采样数据除深度外主要包括4项一级指标: 推进速度、推进力、转矩与旋转速度。其中,推进力与旋转速度在钻探之前根据围岩质量进行预设,并在钻探过程中根据推进的难易程度进行适当调节。隧道超前钻探原始采样数据(一级指标)如图2所示。

(a) 推进速度(b) 推进力(c) 转矩(d) 旋转速度图2 隧道超前钻探原始采样数据(一级指标)Fig. 2 Raw sampling data of advance drilling (first-level index)
通过对一级指标的结构特征进行定性分析可知,其主要具备以下3个特点:
1)采样阶段性。采样过程呈现出明显的阶段划分,即钻探采样开始的上升段及采样过程中的稳定段。其中,上升段通常集中在0~0.5 m的进尺范围内,该范围主要涉及空钻及初喷混凝土钻探,对围岩质量评价无参考意义。
2)数据非线性。各定量指标之间呈现较为明显的非线性相关,4项一级指标随深度的采样数据取值变化趋势缺乏统一性与规律性。
3)离散程度大。推进速度、转矩与旋转速度指标的采样数值都表现出了较大的离散性,具体的离散程度与不同质量的围岩密切相关。
超前钻探一级指标数据相关性分析如图3所示,是通过定量的方法对所收集的4项一级指标数据进行分析。其中,主对角线以外的子图表示推进速度、推进力、转矩、旋转速度两两指标之间的散点图,主对角线上的图形表示各项指标的核密度估计。由图3可知: 1)4项一级指标之间相关性较差,这点由位于对角线两侧的散点图中的拟合关系线可以明显看出; 2)由核密度估计分布图像可以看出,各项一级指标对应围岩完整程度与围岩级别的区分度较差,即在同一分类标签下,各指标的分布范围存在大量的重叠。
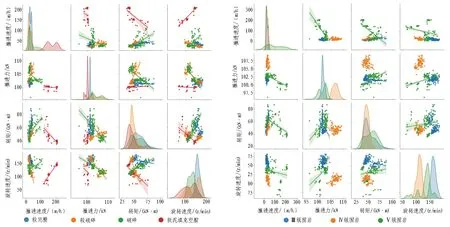
(a) 标签完整程度数据相关性分析 (b) 标签围岩级别数据相关性分析图3 超前钻探一级指标数据相关性分析Fig. 3 Correlation analysis of first-level index data of advance drilling
综上可知,想要达到较为理想的多分类效果,仅依赖一级指标是不够的,应对原始采样数据进行预处理,以提高数据质量。
2 钻探数据预处理
2.1 一级指标数据降噪
在钻探作业过程中,受作业环境、钻机机械、钻探人员操作等客观因素影响,采集的大量一级指标数据中难免存在异常数据以及一些特殊推进状态的数据。因此,在进行机器学习模型的训练之前,需要对已有数据进行降噪处理。针对超前钻探原始采样数据,主要进行的降噪处理措施有以下3项:
1)上升段数据剔除。将原始采样数据中的上升段(0~0.5 m)数据剔除,消除上升段无解译价值数据对后续模型训练的影响。
2)缺失值数据填充。在钻探数据采集时,有时会因为机手的操作导致个别指标的数据出现少量缺失,针对这种数据缺失的情况,采用均值填充策略对缺失值进行填充。
3)贯入度异常的数据过滤。由于施工现场存在电磁噪声和强机械振动,即使在正常掘进工作状态,也有部分不正常的数据点,非正常数据点的特征为数据的贯入度异常大或者异常小[19]。贯入度
P=v1/v2。
(1)
式中:v1为推进速度;v2为旋转速度。
根据贯入度的定义,对共计11 233条钻探原始采样数据的贯入度进行计算,最终计算及统计结果如图4所示。

图4 一级指标数据贯入度统计图Fig. 4 Statistics of penetration degree of first-level index data
由图4可知: 1)贯入度取值为0~2.5(因>2.5部分频次过少,不予统计),且大致以P=1为分界点,右侧为软泥填充空腔的一级指标原始采样数据,左侧为其余围岩情况的一级指标原始采样数据,且二者均近似呈正态分布;2)由累计频率统计可以明显发现,贯入度多集中于0~0.9及1.2~1.8,前者累计92%,后者累计7.3%,二者共计99.3%。以此为依据并结合工程实际经验,将贯入度P(0.9~1.2)及P>1.8的数据进行过滤。
选取YK109+215 ~ +235(1号孔)中前10 m的推进速度原始采样数据进行举例说明,其数据降噪前后如图5所示。

(a) 降噪前
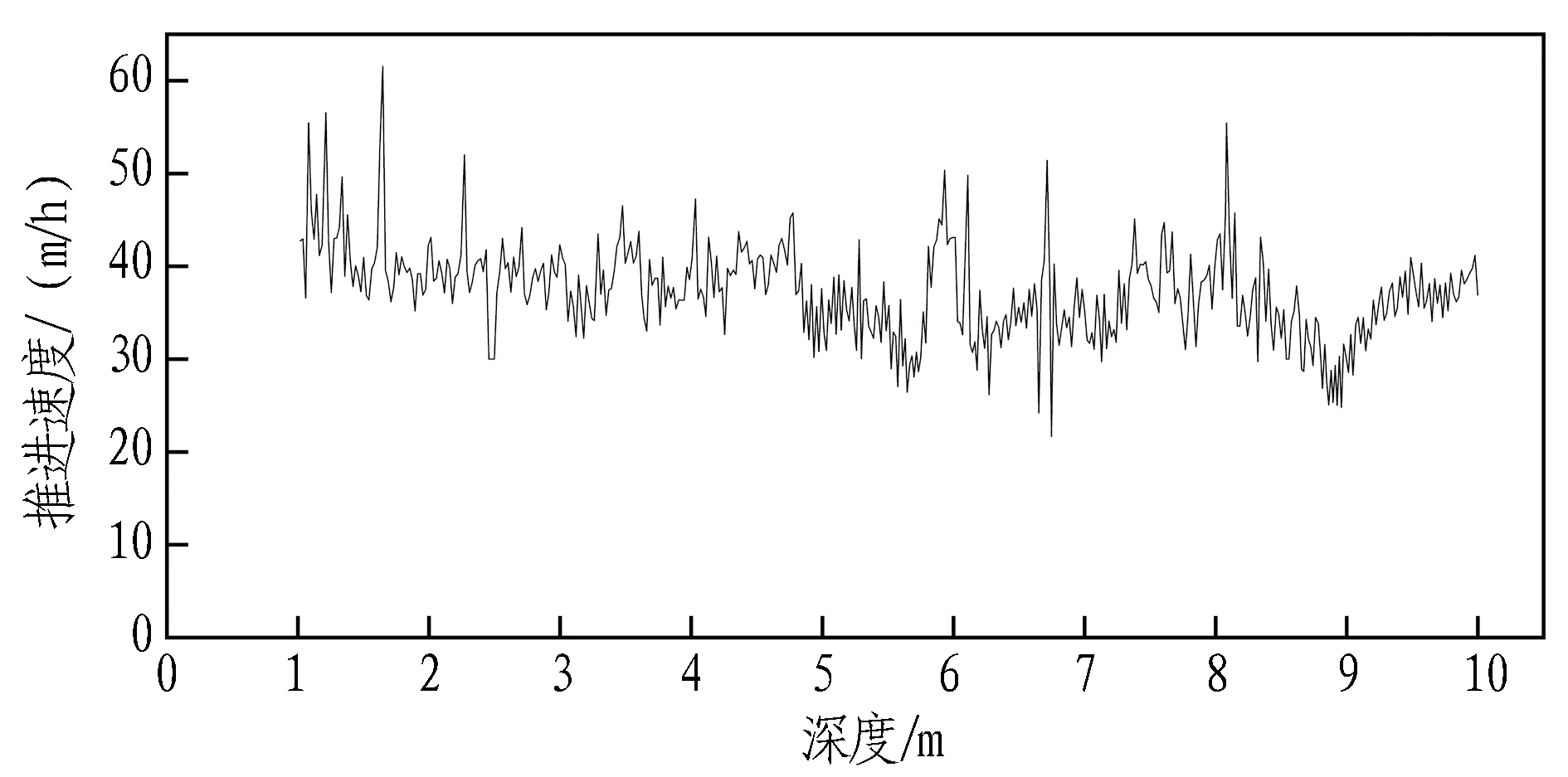
(b) 降噪后图5 一级指标数据降噪效果(推进速度为例)Fig. 5 Noise reduction effect of first-level index data (drilling rate)
2.2 数据等距分割及二级指标计算
为实现以段落为单位对围岩质量进行评价的目的,在完成一级指标数据的降噪处理后,进行钻探数据的等距分割。
考虑实际工程经验与预报精确度,将数据分割间距定为0.5 m。同时,为深度挖掘钻探数据对应不同围岩质量的数据规律,对指标各自分割段内的数据进行二次计算,形成二级指标作为最终机器学习模型数据集的特征。本文选取均值与方差作为二级指标,理由如下:
1)均值。不同围岩质量的钻探数据都存在一定的取值范围,均值是该取值范围的重要体现,且通过取均值的方式可以降低分割间距内异常数据对整体真实数据的影响,从而提高预测结果的准确率。均值
(2)
式中n为样本数量。
2)方差。原始采样数据会出现不同程度的振幅,即离散程度,离散程度的大小与不同质量围岩密切相关。通过取方差的方式可以较为科学与合理地反映各类围岩的采样数据离散程度,从而提高预测结果的准确率。方差
(3)
最终所形成的二级指标体系包括: 推进速度均值、推进力均值、转矩均值、旋转速度均值、推进速度方差、推进力方差、转矩方差、旋转速度方差共8项。
2.3 标签编码
为使机器学习模型识别所设置的标签,需要对数据集分类标签进行编码设置,具体为: 双层标签,即围岩完整程度与围岩级别分别编码为Y1与Y2,前者按照较完整、较破碎、破碎与泥质填充空腔的顺序将标签依次编码为“0”、“1”、“2”、“3”;后者按照Ⅲ、Ⅳ、Ⅴ级的顺序将标签依次编码为“0”、“1”、“2”。
最终,二维评价标签组合形式及分布情况如表1所示。

表1 二维评价标签组合形式及分布情况Table 1 Combination form and distribution of two-dimensional evaluation labels
2.4 特征相关性分析
在完成二级指标的计算后,对8项二级指标进行相关性分析以剔除较高相关性的指标,其相关性分析热力图如图6所示。由图6可知,8项指标之间相关性最高的2组为推进速度方差与转矩方差,相关系数为0.55,整体相关性较低,8项指标均保留。

图6 二级指标相关性分析热力图Fig. 6 Secondary index correlation analysis heat map
3 相关模型及算法理论
3.1 XGBoost多分类模型
作为集成算法中提升法(boosting)的代表算法,XGBoost通过在数据上逐一构建多个弱评估器,经过多次迭代逐渐累积并汇总多个弱评估器的建模结果,以获取比单个模型更好的回归或分类表现[20]。这种以单个决策树作为弱评估器的叠加策略,可表示成一种加法的形式,如式(5)所示[21]。
(5)
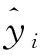
XGBoost引入了模型复杂度来衡量算法的运算效率。因此,目标函数Obj由传统损失函数与模型复杂度2部分构成,如式(6)所示。
(6)
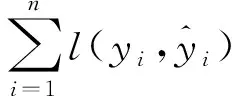
目标函数的最小值Objmin是衡量模型好坏的一个重要指标,其最小值越小,就认为该模型的表现越好。Objmin运算过程中共涉及的模型超参数多达近30个,其中对模型影响程度最大[22]的主要有n_estimators、max_depth、learning_rate等6项。
3.2 genetic algorithm遗传算法
针对XGBoost模型超参数众多、人工调参无法发挥模型最优性能的问题,需要对其进行全局参数自动寻优。遗传算法(genetic algorithm,GA)是一类通过模拟自然界生物自然选择和自然进化的随机搜索算法,目前常被用于模型寻参及寻找最优解的问题之中[23],其算法伪代码如图7所示。

图7 遗传算法伪代码Fig. 7 Pseudo-code transmission algorithm
在图7的输入参数中,maxf(X)为所要求解的最大约束优化问题;d为问题的规模或维数;N为初始种群个体;pc和pm分别为交叉与变异过程中的交叉概率与变异概率; MaxIt为该算法的迭代进化次数;P1(t)与P2(t)为迭代生成的临时种群;Zi(t)与B(t)为第t次迭代后遗传进化产生的个体及其中的最优个体。
3.3 classifier chains分类器链
分类器链(classifier chains,CC)模型[24]作为一种最典型的基于问题转换策略的多标签分类算法,因其简单易用而得到广泛的应用和发展[25],它通过将前面分类器的结果添加到当前分类器来实现分类器的串行连接,克服了模型在训练数据中忽略标签间相关关系的局限性,从而获得了较好的预测性能。其主要步骤如下:
1)令X⊆Rk为k维实例输入特征空间,Y={l1,l2,…,lq}标签的集合。由n个样本数量组成的训练样本集D,表示为D={(xi,yi)},i=1,2,…,n。xi=(xi,1,xi,2,…,xi,k)∈X是一个k维特征向量,xi,j代表特征向量xi的第j个元素,j=1,2,…,q。yi=(yi,1,yi,2,…,yi,q)∈{0,1}q表示一个q维的标签向量,其中yi,j=1表示标号lj与xi相关,而yi,j=0则表示与xi无关。设Yi⊆Y是与xi相关的标记组成的集合,则有Yi={lj|yi,j=1,1≤j≤q}。
2)在训练准备阶段,首先,根据order命令,生成一个新的标签序列,记为{1,2,…,q}; 然后,CC模型按照分类器链的序列训练一组二元分类器f1,f2,f3,…,fq。
3)在训练阶段,每个二元分类器fj:X→{0,1}(j=1,2,3,…q)都是基于当前标签lj同前j-1个标签l1,l2,…,lj-1的关联性,从特定的派生训练数据集Dj={(xi,yi,1,yi,2,…,yi,j)}中训练得到的。该训练数据集Dj中的每个实例都是由原始数据集D中相对应的实例(xi,yi)派生得到的。
3.4 CC-GA-XGBoost双标签链式分类模型
实际工程经验可知,随着围岩由较完整到破碎发展,总体上围岩级别越来越高,且在探测到泥质填充空腔的情况下直接判定为Ⅴ级围岩。基于这种标签之间存在相关性的情况,本文在XGBoost分类模型与GA遗传算法的基础上,结合分类器链组成CC-GA-XGBoost双标签链式分类模型,通过对完成预处理的超前钻探数据进行学习训练,以实现对围岩的双层质量评价。具体流程如图8所示。

图8 CC-GA-XGBoost模型构建及应用流程Fig. 8 CC-GA-XGBoost model construction
4 模型训练及评估
4.1 模型超参数寻优
首先将数据集导入GA-XGBoost模型,以完整程度为基准进行超参数自动寻优处理。根据XGBoost模型寻参个数以及数据集复杂程度,设置初始种群数量为30,使用均匀交叉的方法进行种群迭代,适应度值定义为5折交叉验证的准确率(accuracy),计算公式如式(7)所示。
accuracy=(TP+TN)/(TP+TN+FP+FN)。
(7)
式中: TP为正例预测正确的个数; FP为负例预测错误的个数; TN为负例预测正确的个数; FN为正例预测错误的个数。
在迭代过程中,根据适应度值每次从上一代中选择出最优的3个个体直接进入下一代,突变概率设置为0.1,数据集划分比例为7∶3,即70%数据用作训练,剩余30%用作预测。最终GA-XGBoost调参过程适应度值的迭代变化如图9所示。

图9 最佳适应度(accuracy)变化趋势图Fig. 9 Best fitness (accuracy) change trend chart
由图9可知,经过18次迭代之后,后续种群中个体适应度的最大值、最小值与均值达到最高并保持稳定。其中,最优个体的适应度值(最大值)为0.959 1,即个体所携带的XGBoost超参数组合使得模型预测准确率为95.91%。具体参数如表2所示。

表2 XGBoost模型超参数取值Table 2 XGBoost model hyperparameter values
4.2 模型性能评估
以参数寻优后的XGBoost模型为基础,将钻探数据的数据集导入CC-XGBoost进行训练并预测双标签多分类结果,训练集链式关系设置为order=[0,1],数据划分与4.1节保持一致。最终98例预测集样本的双标签预测结果如图10所示,并根据式(8)—(10)对各准确率进行求解。
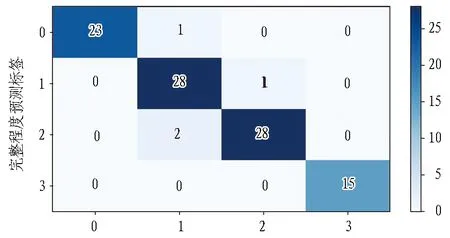
(a) 完整程度标签
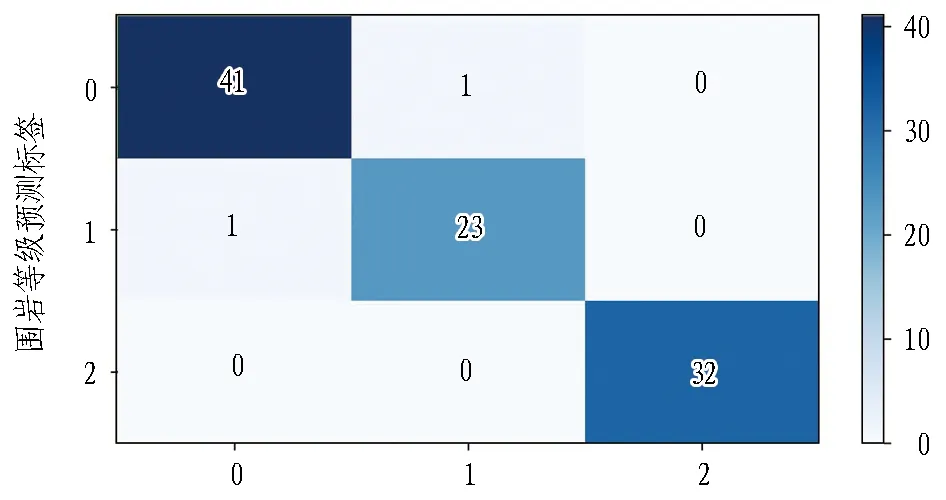
(b) 围岩级别标签图10 CC-GA-XGBoost模型二维标签预测情况Fig. 10 CC-GA-XGBoost model forecast
accuracy(Y1)=A1/N。
(8)
accuracy(Y2)=A2/N。
(9)
accuracy(综合)=A3/N。
(10)
式(8)—(10)中:A1为预测集中Y1标签预测正确的样本数量;A2为预测集中Y2标签预测正确的样本数量;A3为预测集中Y1、Y2标签全部预测正确的样本数量;N为预测集中的总体样本数量。
根据图10与式(8)—(10)可得,围岩完整程度标签下样本错判4例,分类准确率为95.91%;围岩级别标签下样本错判2例,分类准确率为97.95%;二维标签共错判6例,最终综合二维质量评价准确率为93.88%。通过对误差数据进行分析可知,在围岩完整程度方面,模型错判集中在较破碎~破碎,在围岩级别方面集中在Ⅲ~Ⅳ级围岩,实际工程中二者分类界限存在较强的模糊性,因此模型分类结果也与实际经验相符。
同时,为了说明GA与CC对XGBoost模型双标签多分类的优化效果,分别将CC-GA-XGBoost与XGBoost、GA-XGBoost与CC-XGBoost模型进行性能对比,结果如表3所示。

表3 XGBoost模型超参数取值Table 3 XGBoost model hyperparameter values
由表3可知: XGBoost模型在默认超参数组合的状态下,Y1完整程度与Y2围岩级别的分类准确率分别为91.84%与92.85%,双标签综合分类准确率仅为88.78%;在配合GA超参数寻优后,各项分类准确率均有所提高,分别为95.91%、96.93%与90.81%;与GA-XGBoost模型相比,CC-XGBoost仅能在默认参数组合的前提下建立完整程度与围岩级别之间的相关性,因此完整程度的分类准确率仍与单独的XGBoost模型保持一致,为91.84%,但其优化效果将围岩级别的分类准确率提高至94.90%;本文CC-GA-XGBoost模型综合了GA与CC模型的优化效果,3项分类准确率最高。
最后,利用XGBoost所集成的树模型特性对所用8项特征的重要度进行分析,具体如图11所示。
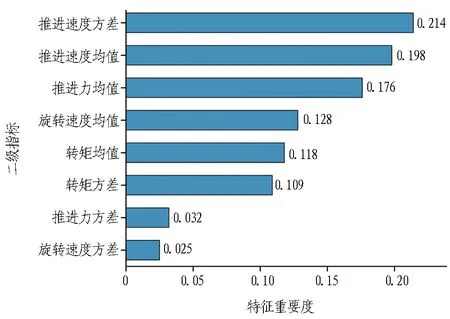
图11 钻探参数二级指标特征重要性分析Fig. 11 Analysis on importance of secondary index of drilling
由图11可知: 在模型所用的8项特征中,较为重要的有推进速度方差、推进速度均值以及推进力均值,三者重要度均在0.15以上,其中,推进速度方差的重要度最大达到了0.214;旋转速度均值、转矩均值与转矩方差重要度一般,分别为0.128、0.118与0.109;推进力方差与旋转速度方差重要度最低,均低于0.1。通过分析不难发现,除推进力方差与旋转速度方法外,其余6项特征在经过模型学习与训练后均占有较高的分类参考权重。推测原因为在钻探作业中,推进力与旋转速度2项钻探参数通常是在钻进之前机手根据掌子面质量情况进行预设,且在钻探过程中仅进行微调,导致二者在同一钻探区间、不同分割间距的方差数值波动较小,无法在不同围岩质量的情况下形成明显的差异性。
5 实际工程应用
为实际验证CC-GA-XGBoost隧道围岩双层质量评价模型的可用性,在凤凰山隧道YK109+960 ~ +980里程段超前钻探作业结束后,提取其钻探数据进行预测及说明。该里程段的原始采样数据如图12所示。

图12 YK109+960~+980一级指标数据Fig. 12 First-level index data of section YK109+960~+980
提取该里程段的一级指标原始采样数据,按照2.1—2.3节流程进行数据预处理后,导入模型进行围岩双层质量评价,同时与该里程段的常规技术人员钻探预报结果以及地质雷达预报结果进行对比。该里程段围岩质量评价情况如表4所示(为方便展示,将模型预测结果中相同标签里程段进行合并)。

表4 YK109+960~ +980里程段围岩质量评价情况Table 4 Surrounding rock quality evaluation of section YK109+960~+980
根据表4,从围岩完整程度及围岩级别2个层次,对YK109+960 ~+980里程段共20 m范围的超前地质预报总结如下: 1.0~5.5 m完整程度为较破碎,围岩级别为Ⅲ级; 5.5~13.0 m完整程度为较破碎—破碎,围岩级别为Ⅳ级; 13.0~13.5 m疑似软泥填充空腔,围岩级别为Ⅴ级; 13.5~14.0 m整体完整程度为较破碎,围岩级别为Ⅳ级; 14.0~20.0 m整体完整程度为破碎,围岩级别为Ⅴ级,其中,16~16.5 m疑似软泥填充空腔。
显然,对比常规的超前钻探预报结果以及地质雷达预报结果,CC-GA-XGBoost隧道围岩双层质量评价模型在实际工程应用中可提供较为详尽的预报解译信息,根据数据等距分割的设定,最小精度为0.5 m,这对全面掌握隧道超前岩体的地质信息较为有利。同时,技术人员可以以双层质量评价结果为参考,对超前钻探地质预报进行信息整合,以提高预测精度。目前,该方法已作为常规超前钻探预报的辅助解译技术在广西地区的一些灰岩隧道中进行使用,预报准确率满足工程实际的需求。
6 结论与讨论
本研究提出一种基于超前钻探随钻定量数据与机器学习算法,对隧道完整程度与围岩级别进行双层质量评价的方法,并有如下结论:
1)针对隧道超前钻探数据的定量解译问题,通过对钻探采样数据进行定性与定量分析,以推进速度、推进力、转矩与旋转速度作为一级指标体系,以围岩完整程度与围岩级别作为多分类双标签,并在此基础上通过数据降噪、等距分割、二级指标计算等数据预处理措施,有效提高了数据集质量,为模型高精度预测提供了良好的数据基础。
2)以XGBoost为分类器模型,结合遗传算法以及分类器链构成GA-CC-XGBoost围岩双层质量评价模型,高效实现了复杂机器学习模型的超参数自动寻优问题以及双标签多分类问题中各标签内在相关性的考虑,最终所构建模型对完整程度与围岩级别的分类准确率分别为95.91%与97.95%,综合分类准确率为93.88%。
3)将所构建模型应用于实际隧道工程的超前钻探地质预报中,结果表明,预报效果优于常规钻探预报与地质雷达预报。但应当注意到,模型预测效果与所提供钻探数据的真实性、有效性密切相关。
本文仅对单一灰岩隧道的围岩双层质量评价进行了研究,当实际隧道工程地质条件更为复杂,如穿越多种岩性地层、隧道地下水发育时,如何考虑不同岩性的钻探数据特征,以及地下水对超前钻探数据特征的影响方式,对数据预处理措施及分类模型进行调整,是下一步需要研究的重点。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中华建设(2019年12期)2019-12-31 06:47:58
车迷(2018年11期)2018-08-30 03:20:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
海峡姐妹(2018年3期)2018-05-09 08:21:02
江西建材(2018年4期)2018-04-10 12:37:22
公民与法治(2016年10期)2016-05-17 04:12:58
江西煤炭科技(2015年1期)2015-11-07 03:06:32
