
一种端到端的考场多目标行为识别算法
2022-09-16 07:16:52郭志林
计算机技术与发展 2022年9期
姚 捃,郭志林
(成都理工大学 工程技术学院,四川 乐山 614000)
0 引 言
行为识别是人工智能和计算机视觉领域最热门的研究话题之一,应用于安防安检、火灾预警、考场监控、婴幼儿看护、病床报警等重要场合。
早期的行为识别基于手工提取特征的方法,利用特征描述符包括轨迹特征、梯度直方图特征(HOG)、光流直方图特征(HOF)、混合动态纹理、光流场、人体关节点等构建特征空间,进而使用机器学习的方法进行行为的识别。张恒鑫等[1]借助OpenPose得到人体区域中关节点的二维坐标构建骨架模型,提取基于关节向量的多种动作时空特征,采用kNN模型进行行为识别,在MIT及Weizmann数据集上取得了不错的效果。
由于视频场景的复杂性、光线变化、人体遮挡等问题,手工提取特征的方法具有一定的局限性,渐渐被深度学习方法所替代,如卷积神经网络、快慢信息网络、TSN双流网络、3D卷积神经网络、双流与LSTM结合的混合网络等。这些网络利用深度学习强大的特征提取能力,从各个角度提取出行为识别所需要的人体外观和人体运动的高级时空特征(如光流特征、3D时空特征),能更有效地进行行为识别。
何嘉宇等[2]构建了特征金字塔层次结构以增强网络检测不同持续时长的行为片段的能力,在公开数据集上获得了先进的识别性能。董琪琪、王昊飞等[3-6]利用3D卷积神经网络,有效提取行为识别所需要的时序信息与空间信息,展现了较好的性能。窦雪婷、陈京荣等[7-10]利用LSTM长短记忆网络,对数据之间的联系进行有选择的记忆与遗忘,仅保留对识别结果有益的数据,取得了良好的识别率。
基于深度学习提取时空特征的行为识别算法存在硬件需求过高、时效性不足、复杂场景准确率偏低等问题。叶黎伟、窦刚等[11-15]利用YOLOv3网络在没有提取时序信息的基础上,通过改进的网络进行了行为识别,解决了推理速度过慢的问题,取得了不错的效果。
Gharahdaghi、Gutoski等[16-19]利用LSTM、TSN、3DCNN等提取高级时空信息进行行为识别,在可穿戴设备、教育教学、电子广告、物联网等领域取得了良好的应用。
在很多应用场景下,不能实现实时识别是行为识别算法并未得到有效应用的主要原因。
因此在考场的环境下,提出一种利用视频帧以多目标检测和多目标行为判别结合的行为识别算法,算法基于两点前提:
(1)在考场这种特殊场景下,没有明显光照变化、场景单一、摄像头角度固定、人体没有明显遮挡,因而可以采集到相对高清的视频图像。
(2)建立目标检测与行为判别两个本地数据集,利用非常成熟的YOLOv3算法,可以实现实时的多目标检测;同时将行为判别任务作为YOLOv3的分类标签输出,完成端到端的多目标行为识别。
实验结果表明,算法在特定场景具有良好的鲁棒性、高效性和准确率。
1 算法设计
YOLOv4和YOLOv5虽然是在YOLOv3基础上进一步改进,但都是在细枝末节上进行的优化,反而丢失了YOLOv3在工业界的普遍适用性。所以总体思路是利用YOLOv3进行多目标检测,同时将行为判别作为各个目标的分类标签,并根据实际任务对输出网络加以修正。
1.1 数据准备
要实现考场任务的多目标检测,并将各目标行为作为分类标签在YOLOv3同时输出,必须提前设计好本地任务的目标检测和行为判别数据集。
利用部署在考场的高清摄像头采集本地视频数据,并进行视频筛选滤除长时的正常视频。对视频数据中典型的正常行为与违规行为进行人体框标注,打上对应行为标签。考场主要行为标签如表1所示。
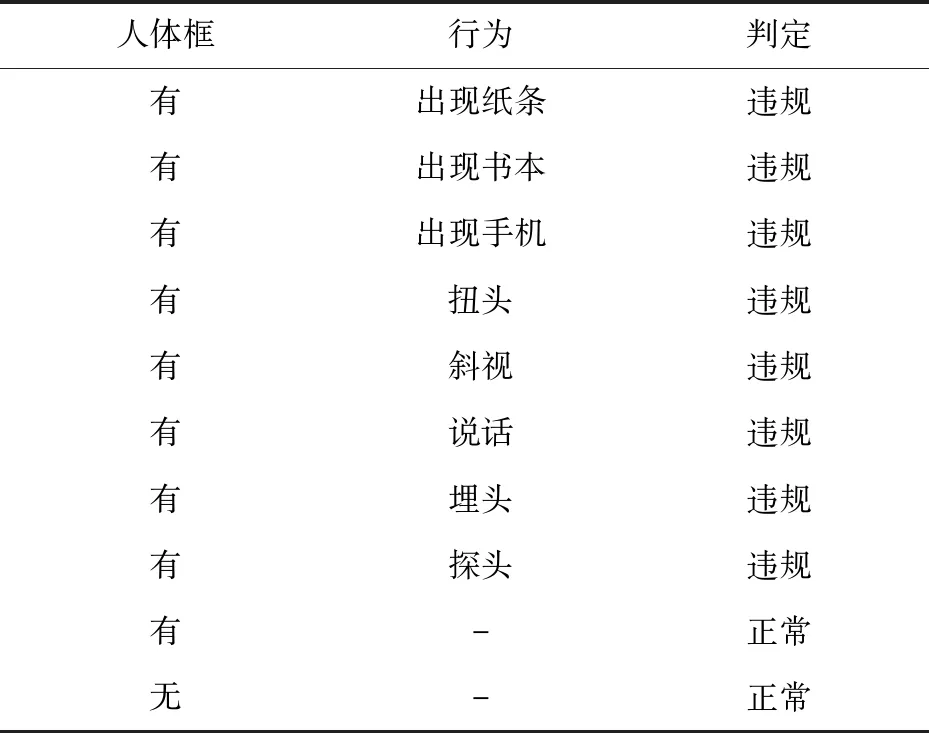
表1 行为标签
由于多目标检测任务和行为判别任务需要YOLOv3网络同时输出结果,因此要对两个任务的数据集进行整体性标注,将各种考场行为设计为目标的类别标签。整体性标注过程如图1所示。

图1 数据集整体标注
1.2 模型训练
训练阶段,神经网络模型主要采用了以特征金字塔和Darknet53相结合作为backbone的YOLOv3算法,并基于考场监考的任务特点在YOLOv3网络结构基础上进行了如下5点改善:
(1)考场只检测人体目标,同时考虑到坐姿下人体目标大小基本一致,因此YOLOv3只需设定1个anchor box,对这个anchor box进行行为类别的分类输出,极大地提升了检测效率。
(2)修改任务输出,将YOLOv3输出的80个类别的分类置信度向量改为本任务所需的8种行为标签向量,每个人体目标框后携带8个行为标签的置信度(出现纸条、出现书本、出现手机、扭头、斜视、说话、埋头、探头),修改后的输出与YOLOv3输出对比如图2所示。

图2 修改后的输出向量
(3)加入注意力机制,行为判别时主要行为都发生在人体上半身区域,因此利用注意力机制能很好地提升考场监考任务准确率。
CBAM(Convolutional Block Attention Module)模块,给定中间特征图,CBAM按顺序推导出沿通道和空间两个独立维度的注意力图,然后将注意图相乘到输入特征图进行自适应特征细化。通道注意力聚焦在“什么”是有意义的输入图像,为了有效计算通道注意力,需要对输入特征图的空间维度进行压缩,对于空间信息的聚合,常用的方法是平均池化。空间注意力聚焦在“哪里”是最具信息量的部分,这是对通道注意力的补充。为了计算空间注意力,沿着通道轴应用平均池化和最大池化操作,然后将它们连接起来生成一个有效的特征描述符,如图3所示。

图3 CBAM模块
CBAM可以无缝集成到任何CNN架构中,开销可以忽略不计,并且可以与基础CNN一起进行端到端训练。对于考场特殊环境下的考试人员,违规行为集中在上半身区域,因此加入CBAM模块,尤其是CBAM中的空间注意力图将有效地提升目标检测与行为判别的准确率,在残差网络中加入CBAM模块,如图4所示。

图4 残差网络中加入CBAM模块
(4)改善损失函数计算,训练所用到的损失函数L应为人体目标置信度损失Lt、人体目标坐标损失Lc和人体目标行为判别损失La之和。其中Lt为二分类交叉熵损失,存在人体目标时标签值为1,不存在人体目标时标签值为0,由于大部分网格没有人体目标,加入λ项来平衡损失值。Lc为MSE损失,只有存在人体目标时才计算这部分损失。La也在有人体目标时才计算,损失函数二分类交叉熵。具体公式如式(1)~式(4)。
L=Lt+Lc+La
(1)
(2)
(3)
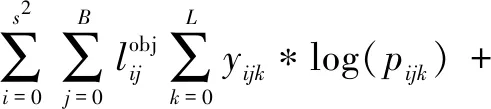
(1-yijk)*log(1-pijk)
(4)
(5)进行预训练,本地采集视频数据非常耗时,为了提高人体行为判别最后的准确率,需要利用主流数据集的预训练模型来初始化网络参数。结合考场任务的需求,最终选择了COCO数据集,COCO数据集是标准的YOLOv3数据集,一共包含20万个图像,80个类别中有超过50万个目标标注,平均每个图像的目标数为7.2,是最广泛公开的目标检测数据集。COCO数据集与其他数据集对比见表2。

表2 目标检测数据集对比
预训练模型输出使用COCO数据集格式,YOLOv3会利用特征金字塔进行上采样,并产生三种不同维度的输出。任务需要根据数据集选择合适的维度和anchor box。每个维度输出3个anchor box,每个anchor box携带80个类别的标签向量。在YOLOv3每一个残差块后添加一个CBAM模块,以提升整体准确率。
预训练完成后初始化网络,输出修改为任务所需的1个anchor box并携带8个行为判别标签向量,在本地数据集上进行再次训练,获得最终模型。
1.3 模型部署
模型运行阶段,利用部署在考场的高清摄像头采集视频数据流,并接入到视频处理设备。视频处理设备主要进行视频解帧与帧图像预处理,以符合神经网络数据输入。
将模型导入考场边缘设备中,接入视频处理设备的输出数据帧,将视频处理设备的输出视频帧作为输入数据,边缘设备同时输出所有考场人员目标检测框和8个行为类别判断,并根据类别判断的结果做出实时的考场行为判断,整体部署如图5所示。

图5 整体部署
2 实 验
实验运行部分结果如图6所示,可以发现,只有当8种行为类别均未检出才会判定为正常行为;如果检测出1条或多条行为类别,将判定为违规行为。

图6 模型运行结果
为了更好地分析模型在实际监控中的效率与准确性,利用COCO数据集、本地采集小数据集、COCO+本地数据集三种数据组合分别测试了算法Faster RCNN、SSD、RetinaNet和本实验改进的YOLOv3模型(简称Model)表现。
4种方案都需要在COCO数据集上进行预训练并作本地数据集的迁移学习,才能在实际的考场视频上进行行为的识别。四种方案训练迭代过程对比如图7所示,其中横坐标表示迭代次数,纵坐标表示损失值。

图7 模型训练过程对比
可以发现Model相比SSD、Faster RCNN和RetinaNet,具有优良的训练曲线,曲线在中前段就很快收敛到低值,中后段也更加平稳,反映出模型泛化推理阶段具有更好的鲁棒性。
将4种方案部署于考场,并对考场行为视频长时运行汇总后进行分析评价,评价指标采用目标检测常用的mAP(mean Average Precision),并比较了四种方案在COCO+本地数据集上的推理速度,实验分析结果见表3。
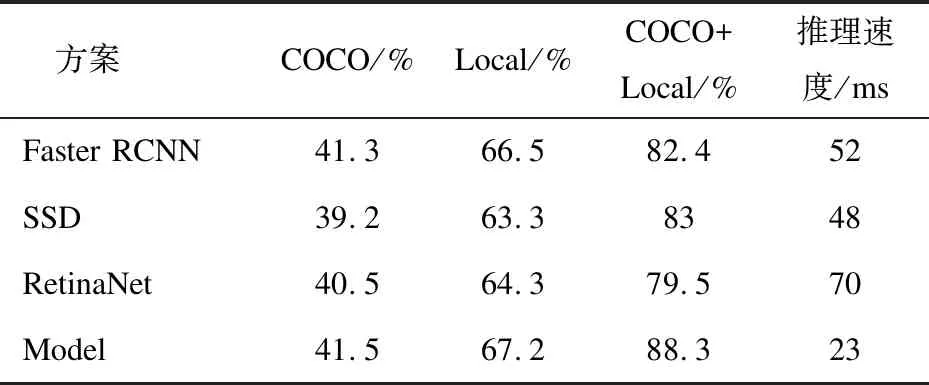
表3 行为识别对比实验分析mAP
可以看到模型的mAP在三组数据下均超过了其他方法,且具有最快的推理速度,具体原因可以总结如下:
(1)YOLOv3是一种集成了SSD(多尺度预测)、FCN(全卷积)、FPN(特征金字塔)、DenseNet(特征通道)等多种特性的快速目标检测算法;
(2)改进的网络中加入了CBAM注意力模块,提取了丰富的人体局部特征,能有效地提升准确率和效率;
(3)具有单一评价指标的端到端训练很好地弥补了YOLOv3先天准确率上低于其他多阶段模型的缺点;
(4)本地小数据集采集自室内环境、场景单一、没有明显遮挡、只有1个anchor box、输出类别数量只有8个等因素,使得COCO+Local的迁移学习方案获得了良好的效果。
对各种行为判别准确率的进一步分析可以发现,由于加入了通道注意力和空间注意力机制,在COCO数据集上可以提取到非常良好的人体上半身局部特征,因此最终在扭头、说话、埋头、斜视、探头等与人体局部特征相关的行为判别上表现明显好于其他非人体局部特征的行为,如图8所示。

图8 各行为判别对比
3 结束语
虽然行为识别领域由于问题场景的复杂性、拍摄角度不同、相同目标类内差异巨大、光线变化、类内和类间遮挡等问题,使得行为识别在自然采集的数据集上仍然存在很大的挑战。但是在实际的考场监控场景中,由于摄像头角度固定、室内无明显光学变化、检测的目标单一、类内无遮挡等天然的优势,使得利用YOLOv3改进后的模型能较好地同时执行多目标人体检测和行为判别任务。
端到端的多目标行为识别算法也具有一些不可避免的缺点:
(1)由于问题的特殊性,需要对本地采集数据进行精心的标注;
(2)由于数据集数量有限,导致无法胜任实际应用,需要借助其他数据集的预训练参数;
(3)算法属于静态帧的行为判别方法,没有加入时序信息,在一些情况下会造成错误的判定,比如捡东西、举手等。鉴于此应加入人工复核机制,或增加采集到的视频时长,这些措施无疑都提高了算法的复杂性与操作的难度。
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26 14:21:08
大科技·百科新说(2021年10期)2021-12-31 07:24:02
基层中医药(2021年5期)2021-07-31 07:58:34
中学生数理化·七年级数学人教版(2021年4期)2021-07-22 03:16:02
新世纪智能(语文备考)(2019年3期)2019-01-12 09:08:04
车迷(2018年11期)2018-08-30 03:20:32
学苑创造·B版(2018年7期)2018-08-07 09:31:24
特别健康(2018年3期)2018-07-04 00:40:10
快乐语文(2018年13期)2018-06-11 01:18:28
海峡姐妹(2018年3期)2018-05-09 08:21:02
