
分层区域穷举的中文嵌套命名实体识别方法
2022-09-16 07:16:50余诗媛郭淑明黄瑞阳张建朋
计算机技术与发展 2022年9期
余诗媛,郭淑明,黄瑞阳,张建朋,胡 楠
(1.郑州大学 软件学院,河南 郑州 450001;2.国家数字交换系统工程技术研究中心,河南 郑州 450002)
0 引 言
命名实体识别(Name Entity Recognition,NER)是信息抽取的标准任务之一,其主要目的是抽取出自然语言文本中具有特定含义的命名实体,例如:组织名、地名、人名等。命名实体识别往往被视为一个序列标注任务,即对于指定字符序列,命名实体识别模型需要预测每个字符对应的命名实体标签。嵌套命名实体是一类特殊形式的命名实体,其内部包含一个或者多个命名实体,最外层的命名实体称为外部命名实体,嵌套在其内部的实体称为内部命名实体。由于单个词条可能拥有两个及以上的标签,传统的命名实体识别模型无法完整地识别出具有嵌套结构的内部命名实体,从而难以精确捕捉文本中存在的细粒度语义信息及结构信息。
当前,只有少数研究针对英文嵌套命名实体识别。Ju等人[1]提出Layered-BiLSTM-CRF模型,该模型动态堆叠平面NER层以识别内部命名实体,并运用充分的内部命名实体编码信息识别外部命名实体,最终在ACE 2005、GENIA数据集上分别获得了72.2%、74.7%的F1值。但该方法存在层与层之间的错误传播,若无法识别外部命名实体,则无法检测到内部命名实体。Sohrab等人[2]提出了神经穷举模型,其关键思想是列举所有可能的区域或跨度作为潜在的实体提及,并用深层神经网络对它们进行分类,该方法简单有效,但是外部命名实体信息和内部命名实体信息完全没有交互。中文嵌套命名实体识别任务目前缺少被广泛认可的数据集,《人民日报》数据集虽然含有部分嵌套命名实体的标注信息,但是这些命名实体信息不完整且存在错标漏标现象,如“[中共中央/nt 顾问/n 委员会/n]nt”转化为“[中共中央]nt”及“[中共中央顾问委员会]nt”,漏标了“[中共]nt”。
结合自动生成及手工标注方法,首先,基于《人民日报》数据集构建了新的中文嵌套命名实体识别数据集NEPD(Nested Entity of the People’s Daily);其次,提出了一种结合动态堆叠平面及神经穷举的嵌套命名实体识别方法,即根据实体长度分层枚举所有可能的区域或组合,使用卷积神经网络将短组合实体的词嵌入与相邻字符的词嵌入聚合形成长组合实体的词嵌入;然后,利用BiLSTM预测出每一个组合的标签;最后,在中文嵌套命名实体识别数据集上对该方法进行实验验证。
1 相关工作
嵌套命名实体具有结构复杂多变,嵌套颗粒度与嵌套层数缺乏规律性等特点,例如,“中共北京市委宣传部”的外部命名实体“[[[中共]nt[北京]ns市委]nt宣传部]nt”包含“[中共]nt”、“[北京]ns”和“[中共北京市委]nt”三个内部命名实体。
当前,嵌套命名实体识别研究工作主要基于英文基准数据集(ACE语料[3-4]、GENIA语料[5]、NNE数据集[6]、KBP2015语料库等)。ACE语料用于自动内容提取技术评估,标注了包含7种主要的命名实体类型:地理命名实体(GPE)、组织(ORG)、人(PER)、地点(LOC)、车辆(VEH)、设施(FAC)和武器(WEA);GENIA语料是最早标注的生物医学文献集合,主要有五种命名实体类型:DNA、RNA、蛋白质、细胞系和细胞类型;NNE数据集标注了华尔街日报的细粒度、嵌套命名实体,包含114种实体类型,嵌套深度高达6层。
针对英文嵌套命名实体识别,文献[1]充分运用内部命名实体编码信息识别外部命名实体,提出了一种动态堆叠平面NER层以识别嵌套命名实体的模型,若检测到命名实体,该模型的平面NER层首先获取LSTM层的上下文表示,其次将该表示作为输入传递到新的平面NER层,最后将上下文表示提供给CRF层进行标签预测,当没有检测到命名实体时,模型停止堆叠,直至完成命名实体识别;文献[2]提出了神经穷举模型,首先从参数共享的BiLSTM中获取区域表示,将每个区域表示输入到修正线性单元中作为激活函数,并把激活层的输出传递到softmax输出层,以识别该区域是否为特定的命名实体类型或非命名实体;文献[7]提出了一种基于超图表示的模型,称为提及超图(Mention Hypergraph,MH),该模型首先使用节点和有向超边共同对命名实体及其组合进行表示,紧凑地将一个句子中不同类型且无限长度的嵌套命名实体表示出来,以解决嵌套命名实体检测难的问题,在ACE 04和ACE 05数据集上的F1值达到62.8%及62.5%;文献[8]提出了一种利用边界预测命名实体分类标签的边界感知模型。该模型将嵌套命名实体识别分为了两个任务,首先用序列标注模型来发现命名实体的位置;其次,用基于跨度的模型对序列标注发现的候选命名实体跨度进行实体类型的分类;最后采用了多任务损失算法同时训练两个任务,以获取边界检测模块和命名实体分类预测模块的底层依赖关系;文献[9]提出了一种基于机器阅读理解(Machine Reading Comprehension,MRC)的方法统一解决非嵌套和嵌套命名实体识别问题,在ACE04和MSRA等8个中英数据集上均取得了显著的识别成果。
由于缺乏规范统一的语料库,当前中文嵌套命名实体识别工作缺乏横向比较的基准。文献[10]引入实体语素概念,基于机器学习方法构建汉语命名实体的双层模型,很大程度上解决了嵌套命名实体边界识别错误问题;文献[11]提出并设计了一种联合模型对嵌套命名实体进行识别,可联合处理分词问题、命名实体的边界确定问题、类别确定问题。
2 中文嵌套命名实体识别数据集构建
2.1 数据集构建
《人民日报》语料库是对一九九八年一月至六月出版的人民日报纯文本语料进行分词和词性标注后制作而成,该文分析了语料库中嵌套命名实体统计分布规律,该语料中共106 430个名词,主要包含人名实体、地名实体以及组织机构名实体;其中,嵌套命名实体总数为7 993,占所有命名实体总数的18.5%。
为了减少标注工作复杂度,该文自动抽取语料中已经标注的部分嵌套命名实体,然后人工标注漏标的命名实体,并修订标注错误的命名实体,保证原始数据的清洁与专业性,主要步骤如下:
(1)自动抽取:从《人民日报》语料库中抽取出命名实体,保留原有的命名实体标注,例如:“[中共/j 上海/ns 市委/n]nt”提取后变成“[中共[上海]ns市委]nt”;
(2)人工调整:基于自动抽取的结果,人工增添未标注命名实体,并对部分错误标注命名实体进行调整,例如:“[中共[上海]ns市委]nt”经人工调整后为“[[中共]nt[上海]ns市委]nt”;
(3)一致性验证:使用一致性分数衡量标注的一致性,一致性分数通过标注一致的标签除以标签总数得到;
(4)人工验证:人工对标注数据复查,核查数据一致性与准确性。
2.2 数据集统计
表1、表2分别列出了修订后的《人民日报》嵌套命名实体数据集的层次结构统计及实体比例分布情况,表中括号内为原数据集的实体比例分布。由表1、表2可知,调整后的数据集包含19 980个人名实体、23 937个地名实体、12 445个组织机构名实体;其中,嵌套命名实体总数为11 757,占所有命名实体总数的20.9%,最深层次达到四层,如:“[[[[长沙市]ns 公安局]nt交警支队]nt 党委]nt”。由于人名中含嵌套命名实体的数量非常少,可以忽略不计,所以含有嵌套结构的命名实体主要存在于地名、机构名之中,结构多为地名+地名+其他+后缀词、组织名+组织名+其他+后缀词,如:“[[中国]ns驻[南非]ns大使馆]nt”、“[[中共]nt中央]nt 统战部]nt”。

表1 嵌套命名实体层次结构统计

表2 嵌套命名实体比例分布情况
3 中文嵌套命名实体识别方法
针对现有的嵌套命名实体识别方法忽略嵌套实体内部信息关联关系而导致准确性下降的问题,提出了分层区域穷举模型(Layered Regional Exhaustive Model,LREM),分层区域穷举模型利用神经网络详尽地列举了句子中所有的区域或组合。该模型建立在多层内部编码层以及解码层之上,编码层由卷积神经网络(Convolutional Neural Networks,CNN)构成,解码层由双向长短时记忆网络(Bi-directional Long Short Term Memory Network,BiLSTM)构成,本节将详细描述LREM的体系结构,如图1所示。

图1 LREM的体系结构
3.1 词嵌入
给定输入的句子序列X={x1,x2,…,xn},其中xi为第i个字符,n为句子序列中的字符数。该文参考文献[12]中的方法,使用Word2Vec[13]在自动分词的Chinese Giga-Word数据集上对词嵌入进行预训练,并使用预训练后的词嵌入初始化输入句子序列的词嵌入W={w1,w2,…,wn},其中wi为第i个字符的词嵌入。
3.2 编码层
分层区域穷举模型的编码层由n层内部编码层构成,每一层内部编码层由卷积神经网络构成,用于构建固定长度的区域表示,即第L层编码层用于构建字符长度为L的组合实体的区域表示,1≤L≤n。首先,利用卷积神经网络聚合两个相邻的区域表示及词嵌入,将聚合得到的区域表示传递给相应长度的解码层;同时,将聚合得到的区域表示与邻接词嵌入拼接得到新的嵌入序列,将该序列传递至更高编码层。通过卷积神经网络,分层区域穷举模型可以遍历文本中所有的组合实体,获取低层编码层的词嵌入信息融入高层编码层,使邻接编码层之间实现信息交换。
设Hi,i+l为以i为起点且长度为l的组合实体的区域表示,则其计算如公式(1)所示。
Hi,i+l=conv1(Hi,i+l-1,wi+l)
(1)
3.3 解码层
传统的层叠模型[14-16]在嵌套命名实体识别过程中容易产生层迷失问题,即模型在错误的嵌套层输出嵌套命名实体,例如:从第一层识别出嵌套命名实体“[[中共]nt中央]nt[台湾]ns工作办公室]nt”。虽然命名实体边界与类别均正确,但这会导致模型趋向于不预测内部的嵌套命名实体,从而影响召回率。分层区域穷举模型通过使用多层解码层,使长度为L的命名实体仅在第L层预测来防止层迷失现象以及层与层之间的错误传播现象产生。将经过编码层获得的词向量输入到BiLSTM中进行进一步处理,得到其预测标注序列。
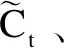
遗忘门将细胞状态中的信息选择性遗忘,其计算过程如公式(2)所示。
ft=σ(Wf·[ht-1,xt]+bf)
(2)
其中,ht-1表示t-1时刻的隐层状态,xt表示当前时刻t的输入词,σ表示sigmod函数。
记忆门决定将在细胞状态中存储的新信息范畴,首先使用记忆门的sigmod层决定需要更新的信息,然后利用tanh层创建包含新候选值的向量,最后,将这两部分联合更新细胞状态,其计算过程如公式(3)、(4)、(5)所示。
it=σ(Wi·[ht-1,xt]+bi)
(3)
(4)
(5)
输出门将基于细胞状态决定输出值,首先使用sigmod层确定是否将细胞状态的某个部分输出,然后,将细胞状态通过tanh进行处理并将其与sigmod的输出相乘,从而仅输出决定输出的部分,其计算过程如公式(6)、(7)所示。
ot=σ(Wo[ht-1,xt]+bo)
(6)
ht=ot·tanh(Ct)
(7)
BiLSTM由前向LSTM与后向LSTM构成,能够更好地学习双向的语义依赖。BiLSTM网络结构如图2所示。向前隐含层计算并保存输入序列中t时刻以及之前时刻的信息,向后隐含层计算并保存输入序列中t时刻以及之后时刻的信息,最后将每个时刻向前隐含层和向后隐含层输出的结果向量经过连接、相加或平均值等方式处理得到最终的隐层表示。

图2 BiLSTM网络结构
4 实验结果与分析
4.1 实验环境配置
实验基于Tensorflow平台搭建,实验硬件环境配有Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz的浪潮服务器,同时装载8块型号为NVIDIA Corporation GP102的GPU。软件环境为Debian 10操作系统、Cuda10.2、Python3.6.5以及Teansorflow Keras 2.2.5版本。
4.2 实验参数设置
根据以往命名实体识别相关研究[17]以及参数调优过程,具体的参数值如下:词向量维度大小设置为50;卷积核尺寸为2;Dropout设置为0.5,学习率采用warmup与余弦退火策略动态调整,采用随机下降梯度(SGD)进行模型参数优化,设置初始学习率为5e-4。
4.3 实验结果
4.3.1 嵌套命名实体识别效果
该文采用准确率(Precision)、召回率(Recall)、F1值(F1-Measure)三项基本测评指标来评估嵌套命名实体识别的效果。将修订后的《人民日报》数据集的70%作为训练集,30%作为测试集,对嵌套命名实体的识别结果如表3所示。实验结果显示:LREM模型对嵌套组织机构名的识别召回率比较低,导致整体组织机构名F值下降,而对地名的识别效果在准确率和召回率均保持稳定的效果,最后地名、组织机构名的F值分别是89.05%、77.82%,LREM模型在没有外部知识资源的情况下,全部嵌套命名实体识别的F1值达到87.19%。

表3 嵌套命名实体识别结果
4.3.2 层数分析
表4显示了不同层数L对不同长度命名实体识别结果的影响。由统计结果可知,2-3字符长度的命名实体数量占全部命名实体的79.91%,这些命名实体的识别结果对整体命名实体识别的效果有较大的影响。随着L的增长,模型识别效果逐渐增强,当L大于5时,出现过拟合现象,导致模型识别效果有所下降,但总体上依然优于普通命名实体识别效果。

表4 不同层数对不同长度命名实体的识别结果 %
表5显示了在不同层数L下的推理速率。实验结果显示:推理速率随层数的增加而下降。这是因为LREM模型的时间复杂度为O(mn),其中m为字符数量,n为层数。当需要识别出长字符的命名实体时,意味着需要进行更多层次的堆叠,这需要更多的计算成本。

表5 不同层数L的推理速率对比
4.3.3 消融实验
为了证明利用短组合实体构建长组合实体表示方法的有效性,该文设置了消融实验,结果如表6所示。实验证明,利用低层编码层的词嵌入信息,使邻接编码层之间实现信息交换的有交互卷积方法优于直接将邻接字符卷积的无交互卷积方法。

表6 消融实验结果
4.3.4 非嵌套命名实体识别效果
为了对文中模型做出更客观的评价,在通用的《人民日报》数据集上进行实验,该数据集不包括嵌套命名实体,采用LSTM-CRF、BiLSTM、BiLSTM+CRF和LREM模型进行性能分析,实验结果如图3所示。
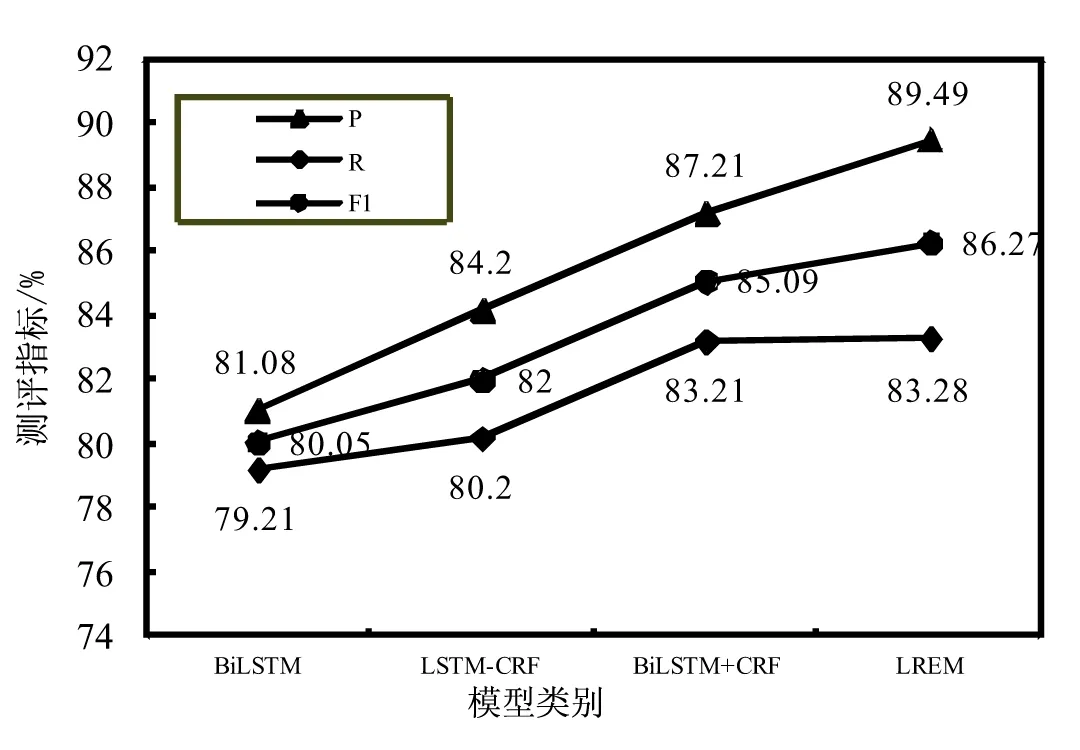
图3 非嵌套命名实体识别结果
实验结果显示:BiLSTM+CRF识别结果的F1值比LSTM-CRF高出3.09%,这是因为BiLSTM能够利用双向结构获取上下文的语义信息,所以BiLSTM+CRF优于LSTM-CRF的识别效果;通过比较BiLSTM与BiLSTM-CRF的实验结果,增加CRF模块后,F1值提高了5.04%,这归因于CRF能够充分考虑标签间的联系,避免不准确标签的出现,例如:预测的标签序列为“B-Organization I-Person”,由于LREM模型考虑的是片段标签,无需考虑标签间的联系,所以无需增加CRF模块进行实验比较;与以上方法相比,该文提出的分层区域穷举模型的非嵌套命名实体识别也取得较好的效果,准确率、F值分别比BiLSTM-CRF提升了2.28%、1.18%。
5 结束语
基于《人民日报》数据集构建了新的嵌套命名实体数据集,提出了一种分层区域穷举模型,该模型利用多层内部解码层遍历文本中所有长度的组合实体,结合短组合实体的词嵌入信息构建长组合实体的区域表示,实现了邻接编码层的交互;使用多层解码层分别预测长度为L的命名实体防止层迷失现象发生。最后,利用分层区域穷举模型在嵌套命名实体识别数据集上进行识别。实验表明,该模型能够从所有可能的区域中识别出嵌套命名实体,且对于非嵌套命名实体识别也取得了较好的效果。
对于未来的工作有两方面考虑:(1)考虑使用字词融合信息来提高嵌套命名实体识别性能;(2)考虑嵌套命名实体与关系联合抽取,利用嵌套命名实体中存在的额外信息作为辅助特征以增强关系抽取的效果。
猜你喜欢
系统工程学报(2021年4期)2021-12-21 06:21:24
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
数学学习与研究(2020年18期)2020-12-28 01:53:38
新教育时代·教师版(2018年33期)2018-10-26 10:14:26
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
电脑知识与技术(2015年20期)2015-10-19 13:49:18
电脑知识与技术(2014年22期)2014-09-17 14:40:02
计算机工程(2014年6期)2014-02-28 01:25:29
河南科技(2014年23期)2014-02-27 14:19:17
