
联邦学习在无线网络中的应用
2022-09-09 01:45刘姿杉李建武
无线电工程 2022年9期
刘姿杉,程 强,李建武
(1.中国信息通信研究院,北京 100191;2.北京理工大学 前沿技术研究院,山东 济南 250300)
0 引言
目前,许多科研机构和产业界都发布面向6G网络的愿景[1-4],业界已经对于人工智能应用于6G网络来实现网络内生智能初步形成共识。利用人工智能技术,可以实现无线网络的端到端性能优化、运维效率的提升、创新应用和智能服务,实现对网络本身和整个行业服务的升级[1-5]。然而,传统基于中央服务器(通常部署在云数据中心)的模型训练框架正遭受越来越多的数据隐私和安全挑战,集中式数据传输和处理带来巨大的传输开销,难以实现网络无处不在的内生智能[6]。与此同时,无线系统将支持超密集设备节点,尤其是面向智能网联汽车和物联网等密集终端场景时,数据通常以分布式的形式产生和存储在不同用户设备中。因此,如何实现较低的通信开销、较好的收敛性、安全和隐私保护的分布式训练和推理就变得尤为重要。联邦学习[7]作为一种分布式机器学习框架,允许在不泄露本地数据的前提下进行多方的模型训练,且模型效果与集中式训练趋同,并能够提高网络中算力的分布式利用效率,成为移动网络智能化发展的潜在关键技术。
将联邦学习引入无线网络目前已经受到研究界与工业界的广泛关注。文献[8]探索了将联邦学习应用于5G网络的潜在应用场景,并提出无线通信背景下联邦学习研究的开放性问题。文献[9]对将联邦学习应用于6G网络的方法、挑战与未来研究方向进行了总结。本文简述了联邦学习相关技术原理及其分类,探索了联邦学习在无线网络中的应用场景,并通过考虑无线网络应用联邦学习的性能因素来重点分析联邦学习在网络中应用的现有成果。最后,提出联邦学习与未来通信网络系统的发展建议。
1 联邦学习技术背景
1.1 联邦学习技术原理
联邦学习的概念最早在2016年由谷歌提出,本质上是一种分布式机器学习的框架,如图1所示。联邦学习场景一般由一个参数服务器(中央服务器)和多个客户端组成。每个客户端都有自己的本地数据集,在训练开始前从参数服务器下载初始的全局模型,然后在保留数据本地化的前提下进行本地模型的训练,并将模型更新数据上传至参数服务器,由参数服务器负责聚合多个模型训练参与方的本地模型。参数服务器加权聚合本地模型,得到全局模型。经过以上多轮迭代更新后,得到最终的聚合模型,和集中式训练的模型相比,性能几乎无损。
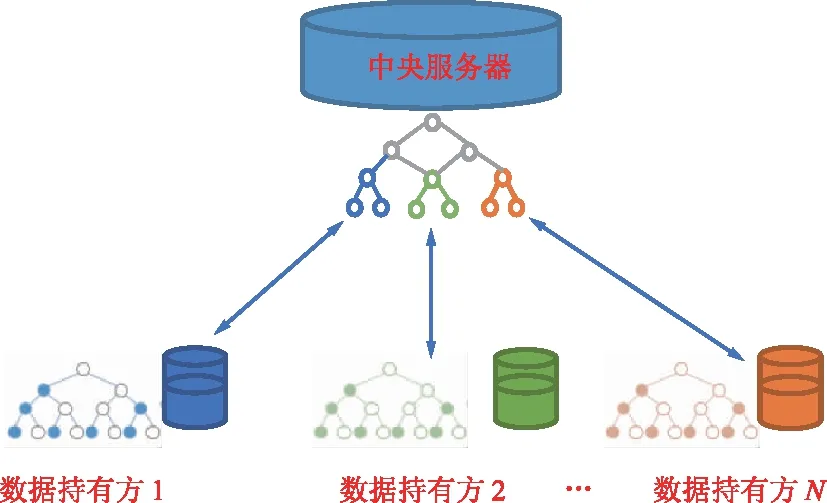
图1 联邦学习示例Fig.1 Illustration of federated learning
联邦学习算法的原理简述如下:将参与联邦学习的客户端集合记为C,每个客户端c∈C持有本地数据集Dc={Xc,Yc}。其中,Xc∈|Dc|×d表示客户端c的训练数据的特征空间向量,Yc∈|Dc|×m表示客户端c的训练数据的标签矩阵。为了确定最优的模型参数集,必须优化损失函数。将具有参数w的模型对训练样本{xi,yi}产生的损失函数记为l(w;xi,yi),w为神经元间的权重矩阵,因此对客户端本地数据集Dc的损失函数计算为:因此,中央服务器的目标函数通常记为其中是所有客户端数据量的总和。
联邦学习的目标优化算法中,通常利用随机梯度下降(Stochastic Gradient Descent,SGD)算法来进行模型权重的更新,客户端c在第t轮次的模型权重更新为:wt,c=wt-1,c-ηfc(w),中央服务器的模型参数聚合更新为:
1.2 联邦学习技术分类
联邦学习技术分类说明如表1所示。根据联邦学习客户端数据集的特征,联邦学习可被分为横向联邦学习、纵向联邦学习和联邦迁移学习[7]。针对每个客户端的数据集Dc,假设I表示数据集中的样本ID,X表示数据集中的特征类别,Y表示数据集中的标签类别。其中,横向联邦学习适用于参与方的数据特征重叠部分较多,但样本ID重叠较少的情况。横向联邦学习在无线网络中典型的应用场景,例如在5G网络不同的UPF之间通过内置的网络数据分析功能(Network Data Analytics Function,NWDAF),各自利用不同用户的数据来进行横向联邦学习,可以实现数据不出局要求下的准确业务识别。

表1 联邦学习技术分类说明
纵向联邦学习适用于参与方之间的训练数据的样本ID重叠较多,但数据特征有较大不同的场景。一般来说,纵向联邦学习主要由两边进行合作,其中一方掌握了训练数据的标签信息,各方拥有自己的特征信息。典型的应用场景,例如运营商A运用自己的网络数据(例如网络接入时延、带宽等)与可以提供业务数据(例如视频卡顿时间/频率等)的业务服务商B进行模型的联合训练,从而实现更精准的用户体验质量(Quality of Experience,QoE)评估和预测。
联邦迁移学习将联邦学习与迁移学习的概念加以结合,以实现在用户特征与用户ID重合度都很低的数据集之间的协同建模。联邦迁移学习一般给定目标域Dt和目标任务Tt,利用源域Ds的源任务Ts所训练的模型,通过安全与数据隔离的方式进行模型的迁移,来提升Tt中模型的训练效率和效果。典型的应用场景,例如无线网络中不同业务间的用户ID和用户特征可能重合度都很低,采用联邦迁移学习将语音业务的MOS模型迁移到视频业务或者支付业务MOS模型训练中。
2 无线网络中联邦学习应用场景
联邦学习有望在未来电信网络的多个潜在场景中得到应用,并通过与物联网、边缘计算、5G/6G等技术相结合,来支持更多智能化应用的开展,对网络性能进行全局优化,推动实现网络内生智能。
2.1 物联网
机器学习在管理、部署、数据分析和决策等方面为物联网的成功做出了重大贡献。尽管如此,物联网中机器学习的应用也受到了来自隐私问题的阻碍。此外,随着物联网设备的数量呈指数级增长,集中式存储和处理这些数据将变得非常困难和低效。另一方面,随着物联网被高带宽、低时延、边缘计算等5G和6G网络技术的赋能,使得物联网设备能够有效利用边缘的计算资源以更快和性能更好的方式在本地进行模型的训练。联邦学习在物联网中可以潜在应用于多个场景,包括家居、医疗、交通和工业等。例如,Moradipari等[10]提出基于实时交通和天气数据的车队联邦动态调度框架。苹果的研发人员[11]提出具有差分隐私能力的联邦学习模型,以改进智能家居设备上语音认证模型的性能,同时降低原始用户数据泄露的风险。文献[12]从联邦学习方法出发,为移动边缘计算辅助工业物联网设计了一种高效、灵活的管理方案。在所考虑的工业物联网(Industrial Internet of Things,IIoT)中,所有设备都有一些计算任务需要借助一些计算接入点进行计算。虽然IIoT的性能可以通过基于一些集中式方案的资源分配来优化,但这种解决方案既不高效也不灵活。为了解决集中式资源分配与计算的效率与灵活度不高的问题,采用基于深度强化学习算法的联邦学习来调整任务卸载率、带宽分配率和发射功率,从而使归一化系统代价最小化,同时降低通信代价。IIoT设备收集的数据与商业价值高度相关,这使得隐私保护变得重要。例如,窃听者可从IIoT用户的用电量推断其制造能力。为应对上述挑战,Lu等[13]针对IIoT提出了基于区块链的联邦学习共享框架,利用区块链来记录联邦学习过程中模型参数的更新过程,实现对参与者模型更新的可追溯与可验证,其结果证实了联邦学习在IIoT中的应用效率。
2.2 边缘计算
随着人工智能技术发展,新一代基础设施的AI赋能,使得边缘节点具备了参与AI计算与决策的能力。边缘计算分布式的特点天然与联邦学习框架相匹配,因而可以在不侵犯用户隐私的前提下,利用边缘节点进行模型的联合训练,充分利用边缘设备的算力资源,极大地提高了边缘计算系统中模型学习的效率。联邦学习对边缘计算的赋能场景包括边缘缓存、计算卸载和网络攻击检测等。例如,文献[14]提出了基于联邦学习的主动内容缓存方案,在保护用户隐私的前提下来预测业务内容的流行度,优化边缘缓存服务。Liu等[15]提出了一种协作入侵检测机制,将训练模型卸载到分布式边缘设备,从而降低了中央服务器的资源利用率,同时确保了安全性和隐私性。针对新冠病毒诊断,文献[16]通过分析和评估在边缘智能处理临床视觉数据的潜力,利用聚类联邦学习在保护用户隐私前提下,进行新型冠状病毒肺炎的自动诊断,从而使缺乏先进诊断设施的远程医疗中心可以受益于多模式数据带来的模型效益。文献[17]研究了基于参与者—批评家联邦学习用于5G多址边缘计算的细粒度任务卸载。边缘节点可以利用本地数据来训练本地模型,并通过集中汇聚后获得对每个节点最优的动作策略,结果证明可以提高计算效率和电量使用效率等。
2.3网络性能分析与优化
随着5G和AI技术的融合发展,网络智能化已经成为5G/6G网络发展的必然趋势。集中式机器学习存在个人信息保护、跨域数据和端到端数据难以集中获取等问题,联邦学习允许网络以及用户之间分布式的方式共同参与机器学习,进一步推动机器学习在网络性能分析与优化中的应用。例如,考虑5G网络中不同厂家的用户面功能(User Plane Function,UPF)数据难以集中共享、不同的UPF业务分布不均等问题,依靠单一UPF的业务样本数据进行业务识别模型训练难以达到精准识别要求。通过内置NWDAF的UPF之间进行横向联邦学习,可以实现数据不出局要求下的业务识别准确率提升[18]。联邦学习还可用于任务调度与资源分配等可以将决策权力下放到各个网络节点的场景,用户或基站以分布式的方式来计算本地收集到的数据,进一步推动了机器学习在无线网络优化问题中的应用。例如,基于联邦强化学习,可以使得每个基站在功率控制方案和效用值之间建立关系,以寻找最优功率控制方案,并通过基站之间交换本地模型参数来实现整网的功率控制优化[19]。
2.4 垂直业务与服务体验提升
基于联邦学习,运营商或设备厂商等可以与垂直行业以及业务服务商进行联合建模,一方面可以实现对网络用户体验的提升,另一方面可以实现对垂直领域业务的支持与多样化发展。例如,通过纵向联邦学习,运用运营商的网络数据(如速率、网络接入时延等)和业务服务商的应用数据(如MOS评分、卡顿时间/频率等)进行模型的联合训练,运营商可以进行更精准的QoE评估和预测,从传统以网络为中心的关键绩效指标(Key Performance Indicator,KPI)管理模式向以用户为中心的管理模式转变,从而提高用户体验满意度和网络运营能力。在垂直业务领域(例如金融领域),为了更精准、更全面地刻画用户信用情况,运营商与金融机构可以利用各自的用户数据,利用联邦学习在数据隐私的前提下共建风控模型,来识别个人和企业背后的复杂关系链条及欺诈风险,为金融客户融资鉴权和增信提供准确判断。
3 无线网络中联邦学习关键技术
无线网络下非独立正交和非均衡的用户数据、异质和能量受限的设备、隐私与安全需求以及不稳定的通信条件,都使得高效的无线网络中分布式机器学习成为挑战[20]。因此,相关的研究实践要全面考虑网络和数据特征,从数据隐私、传输性能和模型训练效率等维度进行性能分析与优化设计。目前,无线网络联邦学习的关键技术研究包括通信效率提升、客户端选择与调度、训练性能优化、隐私保护与安全增强、节点激励与个性化联邦等方面。
3.1 通信效率提升
针对联邦学习在无线网络中的通信提升,目前已有研究成果中对于网络场景和限制的考虑包括:信道衰落与噪声影响[21-22]、信道接入技术[23]、大规模MIMO[24]以及设备电量与通信资源限制[25-26]等,相关的技术方法包括:模型梯度的量化与稀疏化[21,23,26]、随机选参[25]、局部计算[26]、参数冻结[27]和蒸馏技术[28-29]等。
模型梯度的量化与稀疏化只保留一部分模型梯度的张量,或通过对模型参数进行权重量化后上传低精度的参数值,从而减少每轮通信有效载荷的大小,缺点是牺牲了一部分模型梯度的精度。随机选参的思想是在每轮进行模型参数上报时,通过随机选取(或策略选举)的方式选取一部分参与方进行模型参数的上传。局部计算允许每个参与者在每2次全局模型参数同步之间进行更多的本地计算,从而减少全局模型更新的回合,降低总体通信载荷。文献[27]指出,在联邦训练过程中,大部分模型在参与最终模型收敛之前已经逐渐稳定,因此可以在不影响模型准确性的情况下,通过降低参数上传频率来减少通信开销。然而,挑战在于全局同步中排除的局部参数可能在不同的客户端上存在差异,同时一些参数可能只是暂时稳定。为了应对这些挑战,提出了一种自适应参数冻结的新方案,通过自适应冻结已经稳定的模型参数来降低通信成本,广泛的实验结果证明该方案可以将数据传输减少60%以上。文献[29]提出压缩联邦蒸馏(Compressed Federated Distillation,CFD)方法,利用协同蒸馏的关键原理,并在文本检测等任务中,将实现固定性能目标,所需的累积通信量从8 570 MB 降低至0.81 MB,极大地提高了联邦学习过程的通信效率。
文献[21]针对无线瑞利衰落信道下的联邦学习,提出了分布式随机梯度下降方案,在每次模型迭代时根据当前的信道条件随机选择节点进行参数传输,并基于当前的带宽与信道状态将梯度量化为可以成功传输的位数发送给中央服务节点。Chang等人[23]提出结合信道接入感知的梯度量化方案,各参与方根据所处信道条件,基于信道接入的容量区域进行模型参与的传输优化,这种基于信道感知的参数量化方案与均匀量化相比,能够更好地利用信道提高传输效率,但方案需要较为精确的信道状态信息。文献[25]提出了一种FedCS算法,通过在每轮更新中利用贪心算法的协议机制选择模型迭代效率最高的客户端进行模型的聚合,从而提高收敛效率,进而降低通信代价。然而,该方案在客户端数据非独立同分布的情况下,公平性保证较差并有可能降低模型收敛效率,反而增加通信次数。文献[26]提出在异构边缘设备之间进行集成局部计算与梯度稀疏化2种通信压缩方法,来均衡联邦学习过程中的通信性能与设备耗电量。Ahn等[28]指出,经典的分布式训练方法通常假定无噪声且理想的无线信道,然而当把联邦学习下沉到网络连接层时,可以基于信道编码和联合信源信道编码等技术实现数字化的联邦学习和联邦蒸馏技术。联邦蒸馏技术对于通信成本的降低都是以由局部知识蒸馏引起的计算开销为代价的,其鲁棒性与模型收敛性能等方面还存在进一步研究的空间。
3.2 客户端选择与调度
在实际网络进行联邦学习过程中,由于受限于网络节点状态与通信环境等,在每轮迭代训练中往往只选择一部分客户端节点参与联邦训练过程。客户端节点的选择对联邦学习过程中计算效率、通信效率、最终模型效果及公平性等方面的影响至关重要。
文献[30]采用分布式随机梯度下降法时,局部参数更新的质量由更新的方差来衡量。考虑到此,提出了一种高效的动态用户选择算法,根据用户的通信和计算成本自适应选择参与的用户及其小批量的数据。结果表明,针对独立同分布数据的情况,在每轮选择一组通信成本最低的用户,并在下一轮中选择更多具有较大数据量的用户进行模型的训练是最优的。文献[31]研究了无线环境下联邦学习的客户端调度和资源块的分配问题,以在不完美的信道状态信息和有限的本地计算资源下,在预定义的训练时限内利用联邦学习提高模型训练的性能。将训练损失最小化与客户端调度和资源块分配之间的关系抽象为随机优化问题,并利用李雅普诺夫优化来求解,通过基于高斯过程回归的信道预测方法来学习和跟踪无线信道,从而将预测结果纳入客户端的调度决策。仿真结果表明,与最先进的客户端调度和资源块分配方法相比,提出的方法将训练精度损失的差距减少40.7%。
随着强化学习技术的发展,一些学者与研究人员开始考虑将强化学习用于联邦学习的客户端调度与策略决策过程中,在环境信息存在未知的情况下,通过强化学习来进行参与节点的选择,从而优化联邦学习长期的性能。例如,Zhang等[32]提出了在工业互联网场景下,利用深度多智能体强化学习的联邦学习来选择参与设备,并为训练和传输模型参数分配计算和频谱资源,从而在满足延迟和长期能耗要求的同时最小化联邦学习模型的评估损失。文献[33]考虑了参与节点可以接入的信道数小于客户端设备数的联邦学习场景,并提出在无法获知无线信道状态信息与客户端资源动态使用情况的情况下,基于多臂老虎机框架在线进行联邦学习客户端的选择,从而最小化整个训练过程的时间消耗。仿真结果显示,通过增加每轮参与的客户数量可以提高理想情况下的收敛速度,但在非理想情况下,每轮参与的客户端数量会影响模型收敛性能。文献[34]提出了一种基于多准则的联邦学习客户端选择的方法——FedMCCS,在每一轮更新迭代中,同时考虑每个客户端资源及其成功训练和发送模型更新数据量的能力,将选择的客户端数量最大化。
3.3 训练性能优化
无线网络环境下,联邦学习模型的收敛、精确度与通信成本等需要考虑用户数据的非独立同分布性、设备的异质与电量受限和通信环境不稳定等非理想影响因素来进行深入的评估,以及相应的自适应调整和优化,例如训练过程中学习频率的调整、模型自适应聚合以及利用异步学习提高对于节点连接不稳定的适应能力等。目前针对无线联邦学习的训练优化过程,已有一些相关的研究工作出现。
文献[35]将无线网络中的联邦学习描述为一个优化问题,其中主要考虑联邦学习精度、通信延迟以及用户能耗之间的均衡,并提出了获得最优学习时间、精度水平和终端能量消耗的优化问题的闭式解。文献[36]通过经验和数学分析观察到设备上训练数据的分布与基于这些数据训练的模型权重之间的隐含联系,从而根据其上传的模型权重来分析该设备上的数据分布,并提出了一种叫做Favor的经验驱动控制框架,它基于强化学习算法来智能地选择参与每一轮联邦学习的客户端,以抵消用户非独立同分布数据引入的偏差,并加速收敛速度。通过在PyTorch中进行的大量实验表明,与联邦平均算法相比,在MNIST数据集上所提算法所需的通信轮数可以减少高达49%,在FashionMNIST数据集上减少23%,在CIFAR-10数据集上减少42%。为了解决无线网络中用户训练数据非独立同分布所带来的联邦学习性能严重下降的问题,Zhao等[37]提出了一种联邦平均方案来减小非独立同分布数据的分布散度,并将数据共享与无线网络中的联邦学习相结合,进一步协调数据分布差异,来保持模型精度和成本之间的精确平衡。文献[38]则考虑同时优化本地训练与全局聚合的过程,首先通过选择参与者子集并自适应调整其批量大小来减轻非独立同分布数据带来的负面影响,并提出基于深度强化学习实现自适应控制局部模型训练和全局聚合阶段的方法,通过实验表明,与最先进的方法相比,所提方法可以将模型精度提高30%。
3.4 隐私保护与安全增强
联邦学习过程容易受到拜占庭攻击、数据投毒和模型反推理等攻击的影响,从而导致模型准确率降低或隐私保护受损等,尤其是在无线网络开放的环境中[39]。目前学术界已经出现针对无线网络联邦学习过程的安全与隐私增强相关的工作,其中安全增强主要是设计对攻击的防御策略,隐私增强则是通过差分隐私或同态加密等机制来实现。
文献[40]对目前针对数据投毒和模型投毒的防御策略进行了总结,包括鲁棒性更高的随机聚合方法、基于余弦相似度和准确度检验等进行模型异常检测的方法以及多种方法结合的混合机制等。为了进一步提高无线网络下联邦学习的隐私性能,差分隐私是在联邦学习中应用较多的隐私保护机制。文献[41]提出无线设备以非编码的方式同时传输其模型更新,从而更有效地利用可用频谱,同时可以为传输设备提供差分隐私性能,并实现更快速的模型收敛,类似的工作也出现在文献[42]中。利用区块链的可追溯和不可篡改等优势,与分布式的联邦学习相结合,可以很好地解决联邦学习过程中网络节点之间的不可信以及模型参数传输受损等问题,这一思路已经在一些研究成果中得到应用[13,43-44]。但无线网络中节点计算资源和通信资源受限,需要结合密码学和共识机制研究以更适用于无线边缘展开联邦学习的轻量级区块链架构。
3.5 节点激励与个性化联邦
在无线网络中,联邦学习通过分布式学习所有参与的网络设备或终端设备的本地数据而获得更泛化的全局模型,但同时缺少了捕获每个客户端或设备个性化信息的能力。个性化联邦学习通过在设备、数据和模型级别上进行个性化处理,来减轻异构性并考虑每个客户端所获得的个性化模型,文献[45]将个性化联邦机制总结为迁移学习[45]、元学习[46]、多任务学习[47]和分层多模型[48]等。其中,迁移学习通过将全局共享模型迁移到网络边缘设备上,并进一步对模型进行个性化处理,从而减轻无线网络中设备之间的异构性问题。联邦元学习将元学习中的相似任务作为设备的个性化模型,通过协作学习实现客户端模型的个性化处理。分层多模型联邦学习中的模型采用分层结构,首先对所有层进行全局训练,每层有多个功能相同的模块。同层的不同模块可以使用不同的神经网络,也可以使用不同的计算学习算法。因此可以根据不同参与方的性能差异选择不同的模块或算法进行个性化实现。
已有一些研究利用激励机制或博弈论来对参加者进行激励。文献[49]利用信誉值来衡量无线系统中移动设备参与联邦学习的可靠性和可信赖度的指标,通过提出一种有效的激励机制来激励具有高质量、高信誉的移动设备参与模型训练过程。Zhan等[50]针对物联网场景提出一种基于深度强化学习的激励机制,使得边缘服务器学习最优的定价策略,从而激励边缘节点参与联邦学习过程。
4 未来展望与发展建议
尽管关于无线网络中联邦学习的应用目前已经有越来越多的研究工作与落地应用正在开展,在标准建设、架构接口和生态建设等方面仍需要更多的投入与推进。因此,对于无线网络中联邦学习的发展应用提出以下建议。
4.1 加强无线网络联邦学习关键需求与技术研究
无线网络中,联邦学习的应用受到节点的数据、算力与通信资源的异构性等方面的限制,与此同时网络不同设备在模型训练的参与度、模型个性化与安全性等方面存在多样化需求。因此,应加强对适用于网络及其细分场景的联邦学习应用的开展流程、通信需求、数据需求、算力要求与所需关键技术的研究,重点开展面向联邦学习异构计算资源池化、调度与管理的相关研究工作。
4.2 重视无线网络联邦学习标准与测评工作开展
通过对无线网络联邦学习的功能体系、性能评估与应用场景进行标准化,可以对网络联邦学习的应用起到引导作用。开展网络联邦学习的标准化与测评工作,应重点关注网络应用联邦学习形成的智能化产品及新服务模式的相关标准化工作,发展网络联邦学习的性能评估指标体系与安全评估体系,建立无线通信领域联邦学习能力成熟度模型,推动无线通信领域联邦学习的评测用例与性能基准的开源建设。
4.3 加快无线网络联邦学习落地应用与产业发展
联邦学习在无线网络中的应用优势最终需要落地实践来证明,因此无线网络中联邦学习的发展需要积极开展工程探索与应用示范,拓展垂直领域联邦学习应用,并展开对网络联邦学习的试验与性能验证,发展实践与验证渠道。发展无线网络与人工智能技术相关的复合型人才,推动未来网络与人工智能的融合发展,助力网络智能化发展。
5 结束语
人工智能当前面临“数据孤岛”及隐私监管力度加大的巨大挑战,联邦学习的出现为人工智能的进一步发展提供了新的解决方案。通过联邦学习的架构方案设计及隐私保护技术应用,可使多个数据拥有方协同建立共享模型,达到模型训练与隐私保护双赢的目的。联邦学习在未来的网络自动驾驶、边缘计算、物联网、车联网、用户体验提升以及垂直行业等领域具备广阔的应用前景。通过开展电信联邦学习在技术、标准、测评、应用示范与产业合作等多方面的工作,推动无线网络联邦学习的发展,加速人工智能技术的创新发展,催生以运营商为中心的跨领域生态合作,全面提升网络性能,推动网络的内生智能。
猜你喜欢
新作文·高中版(2022年5期)2022-11-22
——稳就业、惠民生,“数”读十年成绩单
人民周刊(2022年17期)2022-10-21
网络安全与数据管理(2022年1期)2022-08-29
载人航天(2021年5期)2021-11-20
现代电子技术(2021年7期)2021-04-08
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
电子技术与软件工程(2019年8期)2019-07-16
电子制作(2019年24期)2019-02-23
声屏世界(2015年7期)2015-02-28
