
类比算法的提出以及在人工智能发展中的应用研究
2022-09-07 03:40焦正张强通信作者韩清华李明远
电子元器件与信息技术 2022年7期
焦正,张强(通信作者,韩清华,李明远
1.枣庄学院 人工智能学院,山东枣庄,277160;2.伊尔库茨克国立理工大学,俄罗斯伊尔库茨克州,664074
0 引言
人类在接触一个新事物的时候,会把新事物分为两类:已知和未知。分辨的依据就是我们脑海中已有的知识,通过与脑海中已知事物进行特征比对,可以很快地辨别出,新事物以前是否见过。如果匹配,则会将脑海里有关这个事物的所有知识全部调用出来;如果不匹配,下一步则会想,这个新事物和这个已知的事物有多少特征相似,然后通过已知事物的特征来标记未知事物,然后通过各种渠道搜集资料和信息,得到新事物的一个定义,然后结合刚刚的特征,就会把这个未知事物转化为已知事物,进而成为储存在脑海里的知识。这就是人类接触一个新事物的时候,大脑中的一个简单的连锁反应。
1 “类比算法模型”概念的提出
1.1 类比思维模式
人认知世界的过程中就是在不断地给各种事物打上各种各样的标签:高、矮、胖、瘦……打的标签越多,我们对这个世界的认知就越全面,对世界的认知也就更容易。数据标注,就是在给数据打标签。目前的数据标注,大部分工作还是需要人力来完成,所需人力资源庞大[1]。为了解决这个问题,我们通过类比思维模式提出了一个算法概念。首先,该算法可以通过已知事物的标签来标注未知事物,数据库中的数据越多,标签的定义也就越详细,通俗来讲就是已有标注数据越多,对新数据的标注工作也就越轻松。该算法就是在模拟人接触新事物的一个思维过程——类比思维模式。
此算法虽然基于机器学习,但不同于现有的算法,此算法会对已经储存的数据进行一个简单的运用:通过储存的知识让标签的定义更加完善;更加完善的标签则可以更好地完成数据标注的工作,这样就构成了一个良性循环,它更符合人的思考方式。在人类学习知识的过程中,有这样一个概念:“归属学习”,而“归属学习”还分为上位学习和下位学习,上位学习是指新学习的知识在概括程度上高于认知结构中已有的知识,下位学习则与之相反,认知结构中已有的知识可以概括新知识,而通过类比算法来学习的一个概念就是下位学习。标签可以囊括我们所需要标注的内容,而标注的内容则能更好的丰富标签的定义,使标签愈发完善。
相比于目前主流机器学习算法,该算法更注重的是数据的“运用”、智能结构的搭建以及如何不断完善和更新。对数据的运用并不是简单的存储和调用,通过这些数据的存储可以很好的完善所搭建的“智能结构”。
1.2 类比算法模型的提出
本文基于类比思维模式,提出了一种实现机器学习数据集半自动标注的算法模型——“类比算法模型”,人类认知事物的基本逻辑是给予各个事物以标签,包括:外貌、名称、特征等。并通过这些标签和已知事物来与未知事物进行类比,相似的标签,将直接挪用在未知事物上,未知的特征,将通过各种渠道了解,然后再标注。
我们把人当作一个算法模型,其认知事物的过程可以这样描述:首先数据库中存在已标注的数据集,且这些数据集可以随时调用,然后输入一个新数据,算法模型将调用数据集中与新数据相似度高于80%(该参数会随着模型的训练趋近于一个稳定的值)的数据,并与之进行对比,判断相似的地方,然后直接挪用标签,剩余未知的内容与以标注的内容同时输出,由人工复检,人工复检需要检查标注的内容是否正确,然后再标注未知的内容,标注未知的内容过程与人工标注的方式相同。这一过程的流程如图1所示。
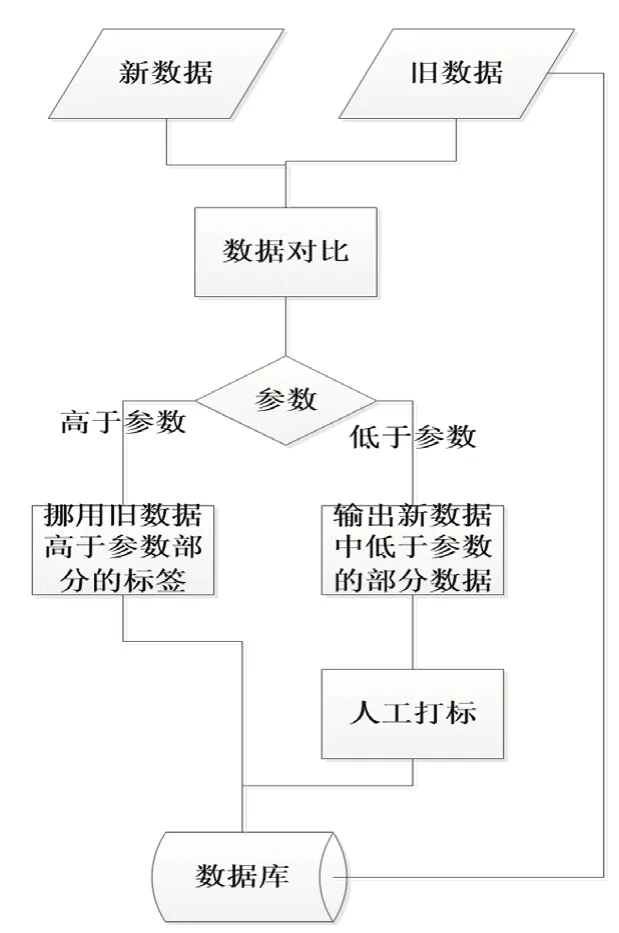
图1 类比算法流程图
2 人工智能的发展现状与未来发展方向的论述
人工智能简单来说就是类人化的一个系统,可以模仿人类除了创造类的所有行为[4]。要想让它实现“独立思考”,就要先探讨人的独立思考是如何形成的。人与生俱来就有自己独立的思维,但是,人类认知这个世界的过程却不是仅仅依靠自己来摸索的,在人类认知世界的过程中,会有老师、父母、朋友等来进行引导和影响,简单来说,老师和父母会把他们认知的世界传输给你,然后通过自己的自我化,转化为自己的知识,从而形成对这个世界的概念,然后以此为基础来对接触的新事物打标签、下定义。这是我们认知世界的一个大致过程。机器学习就是让我们人类来当人工智能的老师,把我们的世界观灌输给人工智能,通过大量的数据训练,使它能实现某一方面的“智能化”[6]。但这一方式有一个缺点,它不能进行数据的自我更新,训练完的模型并不会因为它处理的数据越多从而越智能[5]。因此,这一类模型依然是人工智能方面的一个“工具”,并没有形成一个可以“自我完善”的良性循环。
让人工智能拥有独立思考的能力,还有很长一条路要走,但是让人工智能“类人化”却并非无法实现,人类认知世界的过程是基于已有的知识来记忆新知识,但是目前的人工智能并没有很好的“运用”存储的知识,它没能通过知识来“获取”知识。人类是通过类比来不断丰富对这个世界的认知,所以,构建人工智能框架时,可以借鉴这一思考方式。首先要使人工智能的框架呈开放性,可以随时进行更新、完善、填充以及更改。然后把储存的数据打上各种标签以便进行特征查找和比对。无数的标签构成了所需要的知识网络,扩大知识网络就是在不断创建新的标签,充实知识网络的内容,就是在不断丰富标签下的数据。
人工智能的实现依然离不开对算法的开发,算法是人工智能的基础,就像是人类认识世界的一个底层逻辑,判断是非对错、判断特征等。给事物打上标签是人类认识世界最普遍的手段,然后随着自己的理解越来越多,再进行标签的增加与删除。所以,我们不能把系统看做一个处理事务的工具,为了处理事务而被写出来的人工智能系统,并不能称得上是真的人工智能,大多数智能系统都是通过使用大量的数据训练模型,当模型达到要求的时候,“成品”就出来了,但是这样的“成品”,后期的更新与维护,依然需要人工来添加数据和模块,然后再进行训练。不能是为了让它处理数据而处理数据,要做到,处理数据的同时,能不断完善自身的系统,当系统真正能脱离人工的辅助,方能成为“人工智能”。
3 “类比算法”在人工智能中的应用
类比算法是通过观察人类认识世界的过程总结出来的,与现有的大多数算法不同,类比算法并不是为了处理数据而提出,它更倾向于对数据的一种“使用”,通过对数据的处理来不断完善。这个过程依然需要人工辅助,不过可以肯定的是通过不断处理数据,不断完善自身,可以使其对人工辅助的依赖性越来越弱,无限趋近于“真正的人工智能”,本人通过类比算法提出了一个文本类半自动化数据标注系统,模型流程图如图2所示。

图2 文本类半自动标注系统流程图
在丰富标签构成的过程中有一个完整的反馈环,可以很好地根据标记的内容去不断完善标签的定义。但是该过程依然需要人工的干预,例如:当该内容直接被模型定义,且与人工复检一致,则不需要该内容定义,记作“容易”;如果该内容直接被模型定义,但是与人工复检不一致,则由该内容完善标签的定义,记作“中等”;当该内容不被模型定义,即模型已有的标签无法标记该内容,则由人工干预,增加新的标签,记作“困难”[3]。
通过这个完整的反馈环,可以不断地去增加新的标签,不断地完善已有的标签,即“越标记,越准确”。在不断增加和完善标签定义的过程中,通过各种类,将各个标签关联起来,实现相互关联的知识网络。
实现这一目标有一大难点:文本特征如何抓取。如果没有办法抓取文本特征,那么定义标签则无法进行,要想抓取文本特征,就要搞明白什么是文本特征,这是一个很飘渺的东西,尤其是中国文化博大精深,同一句话用不同的语气读,意思完全不一样。受小学语文试卷中精简句子题的启发,我发现“文本特征”就是“文本”。我们要做的任务就是缩减句子,尽可能地缩减句子,越简单越好,直到句子成分只有主语、动词、宾语、谓语。即,对文本的概括就是我们要找的文本特征。当然这仅仅是文本特征的一部分,更多的标签还囊括了很大一方面,如:文本类型、篇幅长短、刊登地址。
为满足多人并发同步访问,标注平台的服务器部分采用Nginx实现[2]。主要业务逻辑部分基于类比算法模型框架实现,并采用NoSQL数据库实现原始文本数据、标签数据的存储。为实现友好的用户界面,平台的前端基于BootStrap框架实现,并通HTML和CSS控制页面的美观性。同时,利用Python的requests程序包实现爬虫模块,从互联网中获取合法的辅助提示信息。系统的整体框架如图3所示。

图3 系统整体框架
本文所提出的文本类半自动化标注系统包含5个模块:基于BootStrap的前端表示层,基于“类比算法模型”的核心业务逻辑,基于Nginx的Web服务器,基于requests 库的网络爬虫,以及基于NoSQL数据库的数据库集群模块。各个模块的具体实现功能如下所述。
(1)基于 BootStrap 的前端表示层:该模块负责为用户提供友好易用的可视化界面。每个具体页面通过 HTML 控制界面的布局,并通过CSS 批量控制多个页面的样式。同时,该模块负责处理数据标注师与页面中的交互,如提交数据、刷新界面等。
(2)基于“类比算法模型”核心业务逻辑:该模块负责整体协调其他各模块的输入输出数据,实现标注系统的核心逻辑。
(3)基于 Nginx 的 Web 服务器:该模块负责处理更底层的业务。如根据配置对不同的请求做出不同的转发。
(4)基于NoSQL的数据库:该模块负责将原始数据、标注后的数据、用户的数据存储在服务器主机的磁盘中。在标注与查询过程中,该模块根据收到的请求对标注数据进行查询、修改、新增、删除等操作。
(5)爬虫模块:该模块基于Python的requests程序库实现。该模块将原始的文本数据进行处理,封装成网络数据包,并以标准化的格式传送给业务逻辑层。整套网站系统的开发与调试基于 PyCharm集成环境。
4 结语
类比模型的提出,并不仅仅局限在文本标注工作中,类比模型的核心是“通过已有的知识,类比未知的知识,从而减少工作量”。这一概念就可以运用在如自然语言处理,人工智能语音识别模块,文字识别模块等众多场合。
类比模型给予了系统一个思考方式:这个东西是不是和我认知中(数据库中)的东西一致,不一致的话,那有哪里相似?然后完全未知的部分就会输出,由人工来定义标签。“类比”是人类认知过程中很重要的一个思考方式,人工智能的发展依然离不开对人类思考方式的一种模仿,所以类比模型给人工智能提供了一个“砖”,人类的思考方式多种多样,所以人工智能的思考方式,即模型,也应该是多种模型结合而来的,当遇到不同的情况时,可以调用不同模型来应对,而这些模型,也应该是由人类的思考方式演变而来的。
猜你喜欢
幼儿教育·父母孩子版(2022年4期)2022-05-08
文苑(2020年8期)2020-11-22
华人时刊(2020年13期)2020-09-25
VOGUE服饰与美容(2020年9期)2020-09-02
四川文学(2020年10期)2020-02-06
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
中学生天地·高中学习版(2014年10期)2014-10-27
